HedgehogMemory:为 AI Agent 打造的刺猬式辐射状永久记忆架构(同步解决上下文窗口问题)
一、为什么 AI Agent 需要"刺猬记忆"?
当前大模型的上下文窗口有限(通常 8K~160K tokens,主流模型更高但也是有限的),长期对话或跨会话任务中,Agent 会"忘记"之前的工作。常见的解决方案有:
- 全量存储:把所有历史塞进上下文 → 很快撑爆 token 限制
- RAG 检索:向量化检索 → 依赖 Embedding 质量,且只返回片段,缺乏整体感知
- 滑动窗口:丢弃旧消息 → 真正的"失忆",永久丢失信息
HedgehogMemory 提出了第四条路:永不删除,只压缩;原点架构规则始终在上下文。最关键的是可以随时随地载入到对应的时间任务状态点进行继续开发,当一个任务完成时候,会在某条线上移动节点向后并新增一个最靠近原点的节点或者新开一条线行记录模块,然后回归原点,载入某一点的时候清空上下文(保留刺猬架构和基本信息)然后进入到对应一条或几条线,载入一个或几个点,保持不同模块的对齐。节点载入有误或者偏移,仍然因为载入了节点读取到对应的详细这个载入的节点的总结,而可以继续钻取载入其他节点或线,同时清空这一部分上下文重新载入,始终保持在最需要的地方尽可能提供最大的上下文空间。(几乎无限的记忆和上下文空间,无损耗加载)
二、刺猬式辐射状记忆架构
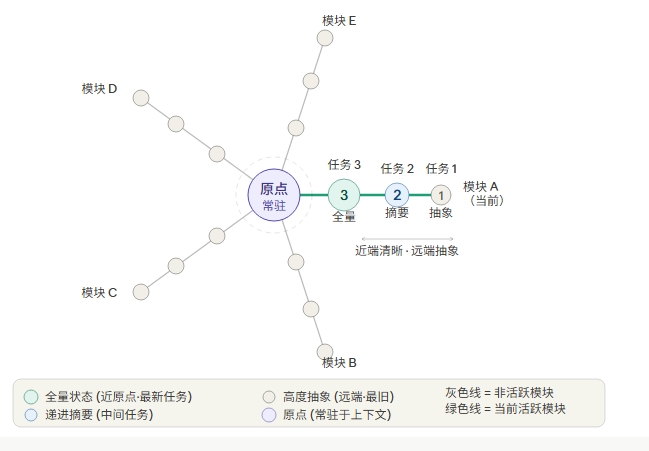
架构灵感来自刺猬的刺:每一根刺(Line)从原点向外辐射,代表一条独立的任务/话题轨迹。每条刺上挂着多个节点(Node),每个节点存储同一内容的 5 个抽象层级。
原点(Origin)
│ └─ 所有 Node 的 L0 摘要集合,约 200 tokens,每次会话开始自动加载
│
├── Line 1(主题:Python 异步调试)
│ ├── Node @ position=1 [最新]
│ ├── Node @ position=2
│ └── Node @ position=3 [最旧]
│
├── Line 2(主题:数据库优化)
│ └── Node @ position=1
└── ...
三、五层抽象压缩
每个 Node 的内容被压缩为 5 个抽象层级,按需取用:
| 层级 | 最大长度 | 用途 |
|---|---|---|
| L0 | 80 字符 | 一句话摘要,始终加载到原点 |
| L1 | 200 字符 | 导航预览,命中后展示 |
| L2 | 600 字符 | 详细摘要,drill deeper |
| L3 | 1800 字符 | 完整上下文摘要 |
| L4 | 无限制 | 原文逐字存储,永远可恢复 |
原点始终持有所有 Node 的 L0 摘要(约 200 tokens),Agent 永远知道"自己知道什么"。需要细节时,按 L1→L2→L3→L4 逐层钻取,按需消耗 token。
四、安装与快速上手
pip install hedgehog-memory
# 推荐:带 OpenAI 高质量摘要器
pip install "hedgehog-memory[openai]"
最简用法
from radial_memory import ContextWindowManager
mgr = ContextWindowManager(base_path="./memory_store")
# 1. 会话开始:获取约 200 token 的原点概览(所有 Node 的 L0 摘要)
overview = mgr.reset()
print(overview) # 注入到系统提示词
# 2. 查询相关历史
result = mgr.load("Python 异步模式")
if result.found:
print(result.content) # L1 摘要
result = result.drill_deeper() # → L2
full = result.load_full_state() # → L4 原文
# 3. 提交当前会话到记忆
mgr.commit(
topic="异步 Python 调试会话",
full_context="完整会话内容...",
tags=["python", "async"]
)
接入 OpenAI 摘要器(推荐)
from radial_memory.summarizer import OpenAISummarizer
summarizer = OpenAISummarizer(api_key="sk-...", model="gpt-4o-mini")
mgr = ContextWindowManager(base_path="./memory_store", summarizer=summarizer)
五、Agent 集成范式
import os
from radial_memory import ContextWindowManager
from radial_memory.summarizer import OpenAISummarizer
summarizer = OpenAISummarizer(api_key=os.environ["OPENAI_API_KEY"])
mgr = ContextWindowManager("./memory_store", summarizer=summarizer)
# ── 每次会话 ────────────────────────────────────────────
# Step 1: 获取原点概览,注入系统提示
system_prompt = f"""你是一个助手,以下是你的历史记忆概览(每条一句话):
{mgr.reset()}
"""
# Step 2: 用户提问后,检索相关上下文
result = mgr.load(user_question)
if result.found:
context = result.content
# 如需更多细节:
while context 不够 and result.current_level < 4:
result = result.drill_deeper()
context = result.content
# Step 3: 执行任务 ...
# Step 4: 会话结束,持久化
mgr.commit(
topic=session_summary,
full_context=full_session_log
)
六、核心设计原则
- 🦔 永不删除:只压缩,原文(L4)永远可恢复
- 🎯 原点始终在上下文:~200 tokens 的 L0 摘要集合,让 Agent 始终有全局感知
- 🔍 辐射状导航:关键词重叠匹配找到最相关 Node,按需钻取
- 🔌 摘要器可替换:OpenAI / LiteLLM / 自定义 ABC,不改变上层代码
- 📦 零强制依赖:纯 Python stdlib,内置 KeywordSummarizer 开箱即用
- 💾 单文件存储:全部记忆存在一个
origin.json,原子写入,不损坏
七、与同类方案对比
| 方案 | 永不丢失 | 全局感知 | 按需钻取 | 零依赖 |
|---|---|---|---|---|
| HedgehogMemory | ✅ | ✅ L0 原点 | ✅ L0→L4 | ✅ |
| RAG (向量检索) | ✅ | ❌ | ❌ | ❌ 需 embedding |
| 滑动窗口 | ❌ 丢弃 | ❌ | ❌ | ✅ |
| 全量上下文 | ✅ | ✅ | N/A | ✅ |
八、开源地址
- GitHub:https://github.com/vvxer/HedgehogMemory
- PyPI:
pip install hedgehog-memory - ClawHub(OpenClaw Agent 生态):https://clawhub.ai/vvxer/hedgehog-memory
欢迎 Star、Issue 和 PR!如果你在构建 AI Agent,欢迎试用并反馈。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)