大模型收费从来不是统一价?输入、输出、缓存命中各算各的,这背后到底藏着什么门道?
你向大模型发起一次 API 调用,账单上却可能出现三种 token:输入 token、输出 token、缓存命中 token。它们看起来都叫 token,单价却常常不同。第一次看到这类价格表时,很多人的直觉是:既然都是文本,为什么不按“问一次多少钱”或者“总 token 数多少钱”统一结算?
原因不在价格表,而在推理过程。大模型计费不是给“聊天”这个动作定价,而是在给不同阶段的算力、显存、带宽、延迟占用和缓存复用能力分别定价。输入阶段要把上下文读进模型,输出阶段要一个 token 一个 token 地生成结果,缓存命中阶段则是在复用过去已经算过的一段前缀。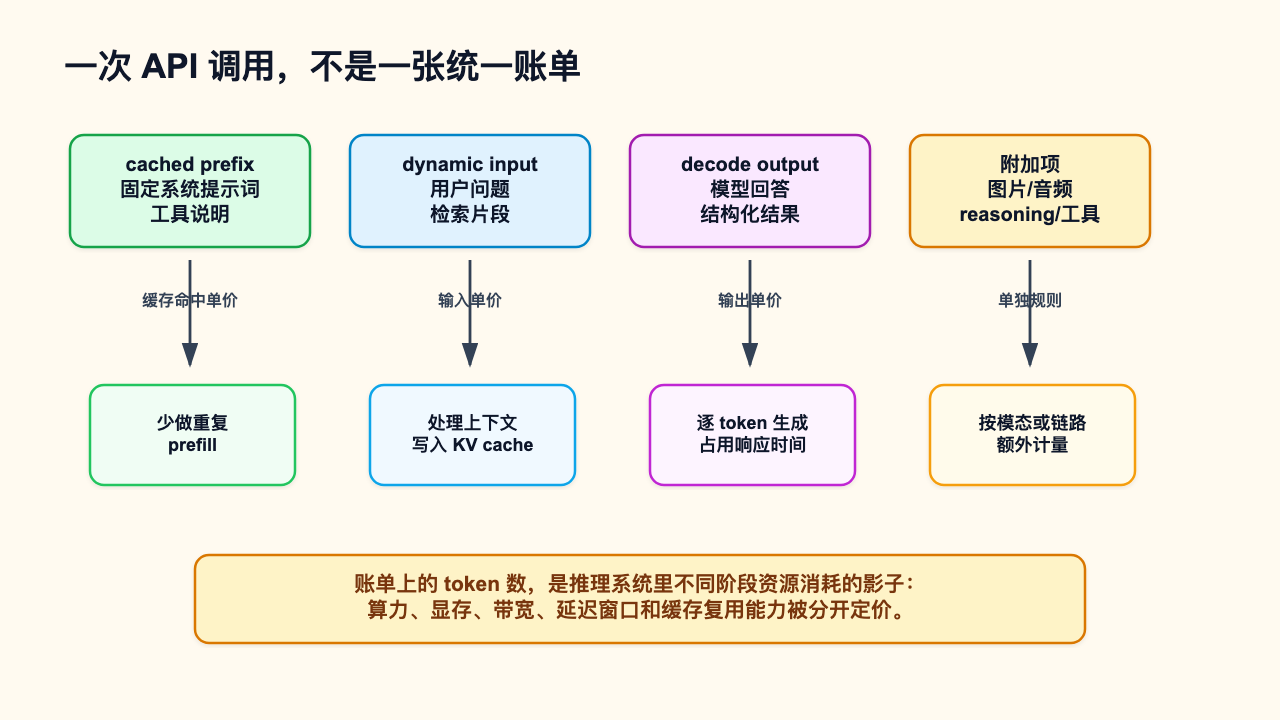
这张图要表达的要点很清楚:一次调用不是一整包文本进来、再一整包文本出去,而是几类工作量沿着不同路径进入账单。固定系统提示词和工具说明可能命中缓存;用户问题和检索片段通常是普通输入;模型回答属于输出;图片、音频、reasoning token 或工具链路可能还有额外计量规则。
先把一次调用拆成几张账单
想象一个企业知识库问答助手。它的 system prompt 很长,里面写着回答边界、安全规则、引用格式和业务术语;它还带着一大段工具说明,用来告诉模型如何调用搜索、查表和生成结构化 JSON。用户真正输入的问题可能只有一句:“上季度华东区续费率下降的主要原因是什么?”
如果只站在产品界面看,这就是一次问答。如果站在服务端看,请求会被拆成几段:稳定的前缀、动态的用户问题、检索系统塞回来的文档片段、模型生成的回答,以及可能发生的校验和重试。每一段进入模型的方式不同,造成的资源消耗也不同。
一组虚构单价可以帮助建立直觉。假设普通输入是每百万 token 10 元,缓存命中输入是每百万 token 2 元,输出是每百万 token 40 元。某次请求里有 8000 个固定前缀 token、1200 个动态输入 token、700 个输出 token。第一次请求没有缓存命中,费用约为:
第一次调用成本 ≈ (8000 + 1200) × 10 / 1,000,000
+ 700 × 40 / 1,000,000
= 0.092 + 0.028
= 0.120 元
第二次请求复用了同样的固定前缀,8000 个 token 按缓存命中单价计算,动态输入和输出仍按普通规则计算:
第二次调用成本 ≈ 8000 × 2 / 1,000,000
+ 1200 × 10 / 1,000,000
+ 700 × 40 / 1,000,000
= 0.016 + 0.012 + 0.028
= 0.056 元
这些数字不是任何厂商的真实价格,只是为了说明账单结构。真正重要的是这个比例关系:稳定前缀一旦可复用,输入侧的重复计算会明显减少;输出仍然贵,因为它还得逐步生成;动态内容不会因为旁边有缓存就自动变便宜。
token 是计费单位,但不是字符计数
token 是模型处理文本的基本颗粒,但它不是自然语言里的“词”,也不是字符数。tokenization 会把中文、英文、代码、JSON、标点、空格和特殊符号切成模型词表里的片段。两段内容看起来字数差不多,进入账单时的 token 数可能相差很大。
例如,“退款失败”这四个中文字符,可能被切成一个或几个 token;refund_failed 这种蛇形命名可能会被拆成 refund、_、failed 一类片段;一段压缩后的 JSON、日志、Base64 或栈追踪,字符密度很高,token 数也可能迅速膨胀。开发者如果只用字符数估算成本,很容易低估代码、表格、日志和混合语言输入。
下面这个表不是 tokenizer 的精确输出,而是展示几类文本为什么会让账单直觉失灵:
| 内容类型 | 看起来的长度 | token 估算容易出错的原因 |
|---|---|---|
| 普通中文问题 | 很短 | 中文切分方式由词表决定,不等于一个字一个 token |
| 英文长句 | 中等 | 常见词可能合并,罕见词或拼写错误可能拆得更碎 |
| JSON 配置 | 不一定长 | 引号、冒号、逗号、字段名和重复结构都会占 token |
| 代码和日志 | 经常很长 | 缩进、符号、路径、变量名、栈信息会形成大量片段 |
| Base64 或哈希 | 字符很多 | 对模型语义价值低,但 token 账单可能很高 |
token 数只是账单入口,不等于全部成本。相同数量的 token,如果处在输入阶段、输出阶段或缓存命中阶段,背后的计算路径不同,服务商给出的价格自然也可能不同。把 token 当成“统一燃料”会误导设计判断;更准确的理解是,同一种颗粒在不同机器段里消耗方式不同。
输入 token 的成本主要发生在 prefill 阶段
模型收到 prompt 后,第一件事不是直接回答,而是先理解整段上下文。推理系统会把输入 token 送入 Transformer,计算每一层的中间表示,并生成后续解码阶段会用到的 KV cache。这个阶段通常叫 prefill。
prefill 的特点是可以批量处理输入序列。假设你传入 10,000 个 token,模型可以相对并行地处理这段上下文,而不是像输出那样必须一个接一个吐字。并行不等于免费。每个输入 token 仍然要参与矩阵计算,仍然要经过多层网络,仍然会产生后面解码要读取的缓存状态。
账单层面可以先用一个简化公式理解:
输入成本 ≈ 输入 token 数 × 输入单价
这个公式只解释价格表上的计算方式,不代表服务端真实成本完全线性。模型尺寸、上下文长度、批处理效率、硬件利用率、服务等级和请求并发都会影响服务商的实际成本。对开发者而言,最直接的结论是:长 system prompt、完整历史对话、大段文档、RAG 检索片段和工具说明都会推高输入侧费用。
一个常见错误是认为“模型还没开始输出,所以应该没花什么钱”。事实上,模型在第一个输出 token 出现之前,已经做完了大量上下文处理,并把 KV cache 准备好了。你在界面上看到的是几百毫秒或几秒的等待,服务端看到的是一段 prefill 计算,以及一块会持续到 decode 结束的显存占用。
输出 token 更贵,通常是因为它被逐个生成
输出阶段通常叫 decode。模型不是一次性生成整段回答,而是根据当前上下文预测下一个 token,再把这个 token 放回上下文,继续预测下一个。回答越长,这个过程重复越多。
输入像把一批材料一次性送进流水线预处理,输出像机器每走一步都要看上一步的结果再决定下一步。这个差异直接影响单价:decode 有强顺序依赖。第 300 个输出 token 的生成,必须等前 299 个 token 已经确定。服务端很难把同一个请求里的输出过程完全并行化。
这也解释了为什么大模型输出倾向使用 streaming。既然服务端本来就是逐 token 解码,与其等整段回答生成完再一次性返回,不如把已经生成的 token 立刻推给客户端。streaming 不会让模型“同时生成后面的字”,也不一定降低完整回答的总计算量;它真正改善的是等待方式。用户可以在第一个片段返回后就开始阅读,前端可以逐步渲染,长回答不必把连接挂在一个没有反馈的空白状态里。如果用户看到方向不对,还可以提前停止请求,后面的 token 就不再继续生成,实际账单和延迟都有机会被截断。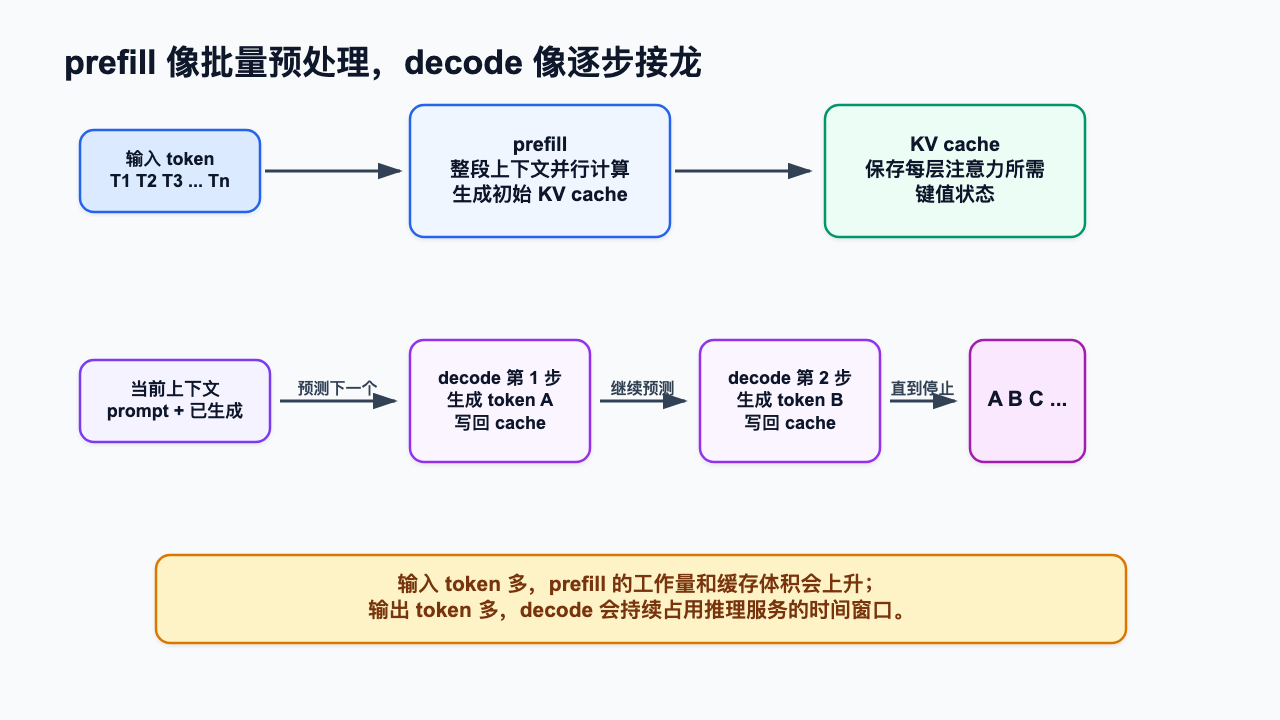
prefill 负责处理输入并写出初始 KV cache;decode 每生成一个 token,都要读取已有 KV cache、完成本步推理、再把新 token 的状态写回 cache。输出 token 常常更贵,不只是因为“生成文字更复杂”,更因为它直接占用推理服务的响应时间窗口,影响并发容量和用户感知延迟。
这也是为什么 max_tokens 或类似输出上限参数不是摆设。如果一个客服机器人本来只需要回答“已为你提交退款申请,预计 3 个工作日内处理”,却生成了 800 token 的长篇解释,费用和延迟都会被拉高。输出长度越接近产品目标,账单越可控,体验也更稳定。
缓存命中为什么便宜,但不是免费
prompt caching 或 prefix caching 的思路并不神秘:当多个请求共享相同前缀时,服务端可以复用此前已经计算好的部分 KV cache,不必从头处理这段输入。固定 system prompt、长工具说明、固定文档前缀、多轮对话中不变的历史片段,都可能成为缓存收益来源。
缓存命中便宜,是因为它减少了重复 prefill 计算。缓存命中不是免费,是因为缓存本身仍然占用资源。系统要判断前缀是否一致,要管理缓存生命周期,要处理缓存淘汰,要在不同机器、不同请求和不同租户之间控制隔离与一致性。命中一次缓存,看似只是“少算了一段”,背后仍然有存储、显存、索引和调度成本。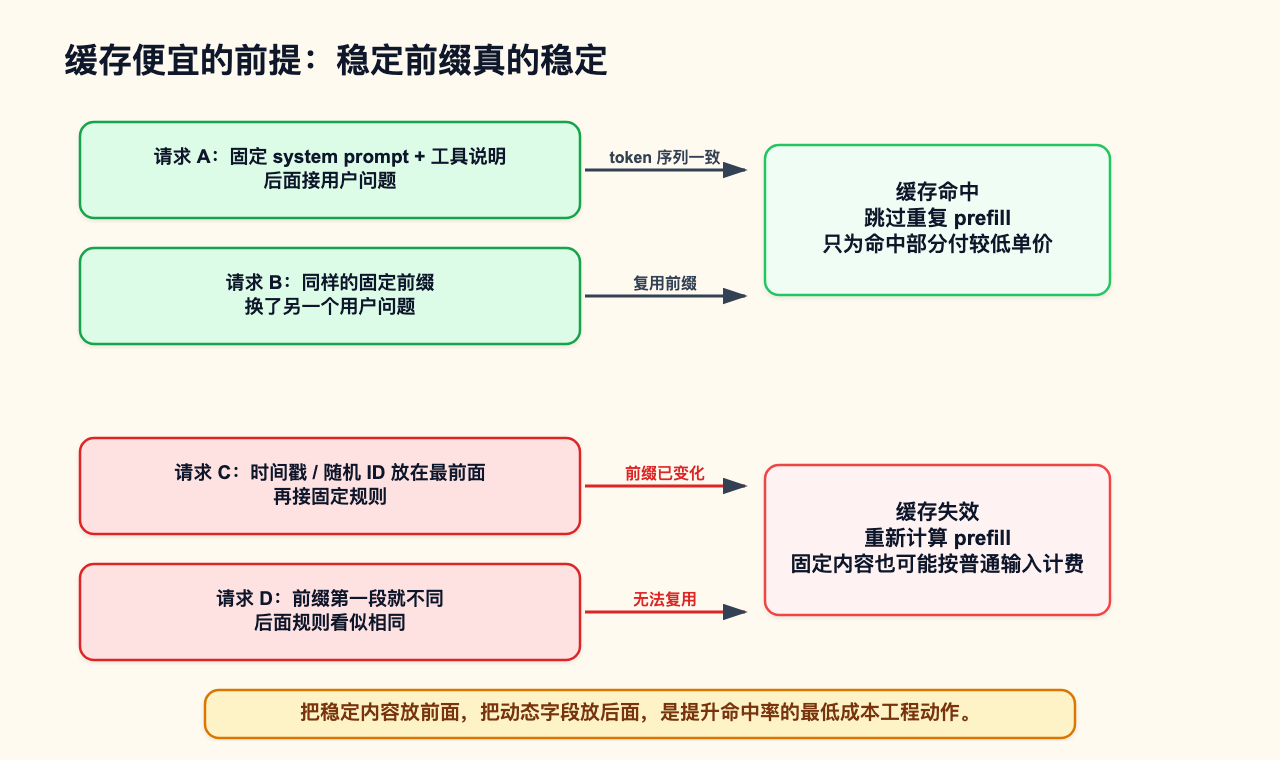
缓存命中的工程前提可以概括为一句话:前缀要稳定,token 序列要一致。注意这里说的是 token 序列一致,不是肉眼看起来差不多。提示词开头多一个时间戳、请求 ID、用户昵称、随机 nonce,后面的固定规则哪怕完全相同,也可能因为前缀变化而无法复用。
这会反过来影响 prompt 结构。稳定内容应该放在前面,例如 system prompt、安全规则、工具说明和固定输出规范。动态内容应该放在后面,例如当前时间、用户问题、会话变量、临时检索片段和用户专属字段。不要把“今天是 2026-05-12,request_id=xxx”放在最前面,再接 8000 token 的固定规则;这种写法会让每次请求从第一段就不同,缓存命中率自然上不去。
不同服务商对最小缓存长度、缓存保留时间、命中统计口径和计费方式会有差异。文章里的机制解释可以帮助你设计请求结构,但最终仍然要以实际 API 文档、响应 usage 字段和账单为准。
长上下文不是“把内容塞进去”这么简单
长上下文让产品设计变得省心:用户给一份几十页文档,开发者把全文塞进 prompt,模型看起来就能回答问题。问题是,长上下文不会绕过推理成本。长输入会增加 prefill 工作量,也会扩大 KV cache;长输出会让 decode 持续更久。价格表可能按 token 线性展示,系统层面却存在吞吐、显存和延迟压力。
同一个知识库问答问题,可以有三种常见方案:
| 方案 | 请求形态 | 成本影响 | 适用判断 |
|---|---|---|---|
| 全文直接塞进 prompt | 每次输入完整文档 | 输入 token 高,缓存命中取决于文档是否稳定 | 文档很短,或问题确实依赖全文结构 |
| 先检索再提问 | 只送 Top-K 相关片段 | 输入更可控,但检索质量会影响答案 | 知识库问答、客服、内部文档搜索 |
| 先摘要再提问 | 先用模型压缩材料,再基于摘要回答 | 多了一步调用,后续请求更短 | 文档很长且会被反复查询 |
没有哪一种方案永远最省钱。全文方案保留信息最完整,但每次 prefill 都重;RAG 方案让输入变短,但可能漏掉关键信息;摘要方案把一次性成本提前支付,适合后续反复使用。成本优化不是无脑减少 token,而是在准确性、上下文完整性、缓存命中率和响应速度之间做工程取舍。
账单背后还有其他变量
输入、输出和缓存命中是最常见的三块,但产品里的实际费用常常不止这些。多模态模型可能把图片、音频、视频转成另一套 token 或计费单位;推理模型可能产生内部 reasoning token;工具调用和函数调用会把一次用户请求拆成多轮模型交互;结构化输出可能因为校验失败、重试或约束解码增加输出长度。
例如,一个“从发票图片中提取字段并写入财务系统”的功能,表面上只有一次上传和一次返回。实际链路可能包括图片理解、字段抽取、JSON 结构化生成、schema 校验、缺失字段追问、工具调用写库、写库失败后的重试。每一步都可能新增输入和输出。用户看到的是一个按钮,账单看到的是一串模型请求。
结构化输出也值得单独注意。要求模型返回严格 JSON,通常能降低后处理成本,但如果 schema 很长,它会增加输入 token;如果生成结果不合法后触发重试,它会增加输出和下一轮输入;如果约束解码让模型为了满足格式生成更多字段,输出长度也会变长。格式要求不是不能写,而是应该写得短、稳定、可缓存。
开发者应该怎样设计更可控的成本结构
成本可控不是靠月底看账单,而是靠请求结构和埋点。你需要知道每次调用为什么发生,哪些 token 是稳定前缀,哪些 token 是动态输入,输出为什么这么长,是否命中了缓存,是否触发了重试。
可以从一个简单的成本模型开始:
单次调用成本 =
uncached_input_tokens × input_price
+ cached_input_tokens × cached_input_price
+ output_tokens × output_price
+ 其他模态或推理附加项
这个模型不能替代厂商账单,但能帮团队定位费用来源。系统提示词太长,会体现在输入和缓存命中结构上;输出过度冗长,会体现在 output tokens 上;缓存命中率低,通常说明稳定前缀不稳定,或者动态字段放错了位置;重试链路过多,说明校验、工具调用或提示词约束需要重新设计。
工程上建议把每次模型调用记录成可聚合事件。下面是一段 TypeScript 示例。
type LlmUsage = {
uncachedInputTokens: number;
cachedInputTokens: number;
outputTokens: number;
reasoningTokens?: number;
imageUnits?: number;
};
type PriceTable = {
inputPerMillion: number;
cachedInputPerMillion: number;
outputPerMillion: number;
reasoningPerMillion?: number;
imageUnitPrice?: number;
};
export function estimateLlmCost(usage: LlmUsage, price: PriceTable) {
const tokenCost =
(usage.uncachedInputTokens * price.inputPerMillion) / 1_000_000 +
(usage.cachedInputTokens * price.cachedInputPerMillion) / 1_000_000 +
(usage.outputTokens * price.outputPerMillion) / 1_000_000 +
((usage.reasoningTokens ?? 0) * (price.reasoningPerMillion ?? 0)) / 1_000_000;
const modalityCost = (usage.imageUnits ?? 0) * (price.imageUnitPrice ?? 0);
return {
total: tokenCost + modalityCost,
input: (usage.uncachedInputTokens * price.inputPerMillion) / 1_000_000,
cachedInput: (usage.cachedInputTokens * price.cachedInputPerMillion) / 1_000_000,
output: (usage.outputTokens * price.outputPerMillion) / 1_000_000,
reasoning: ((usage.reasoningTokens ?? 0) * (price.reasoningPerMillion ?? 0)) / 1_000_000,
modality: modalityCost,
};
}
这段代码的价值不是“算得比厂商准”,而是让产品和工程团队能用同一种语言讨论成本。一次需求评审里,如果有人要把 20,000 token 的政策全文塞进每次请求,你可以估算输入成本和延迟影响;如果有人要求模型输出长篇报告,你可以估算 decode 成本;如果固定提示词占了大头,你可以检查缓存命中率,而不是先去换模型。
更具体的设计动作可以落在四个位置。第一,把稳定的 system prompt、工具说明和输出规范放在请求前缀,并保持字面内容稳定。第二,把用户输入、时间戳、请求 ID、检索片段和临时变量放在后部,避免破坏前缀缓存。第三,为输出设置合理上限,并让提示词明确回答粒度。第四,记录每次调用的目的、usage 字段、缓存命中 token、重试次数和最终业务结果。
用知识库问答把账单路径串起来
现在回到企业知识库问答助手。一次用户问题通常不是直接丢给大模型,而是先经过检索系统找到相关文档,再由模型综合回答。如果答案不合规,或者引用格式错误,还可能触发校验和重试。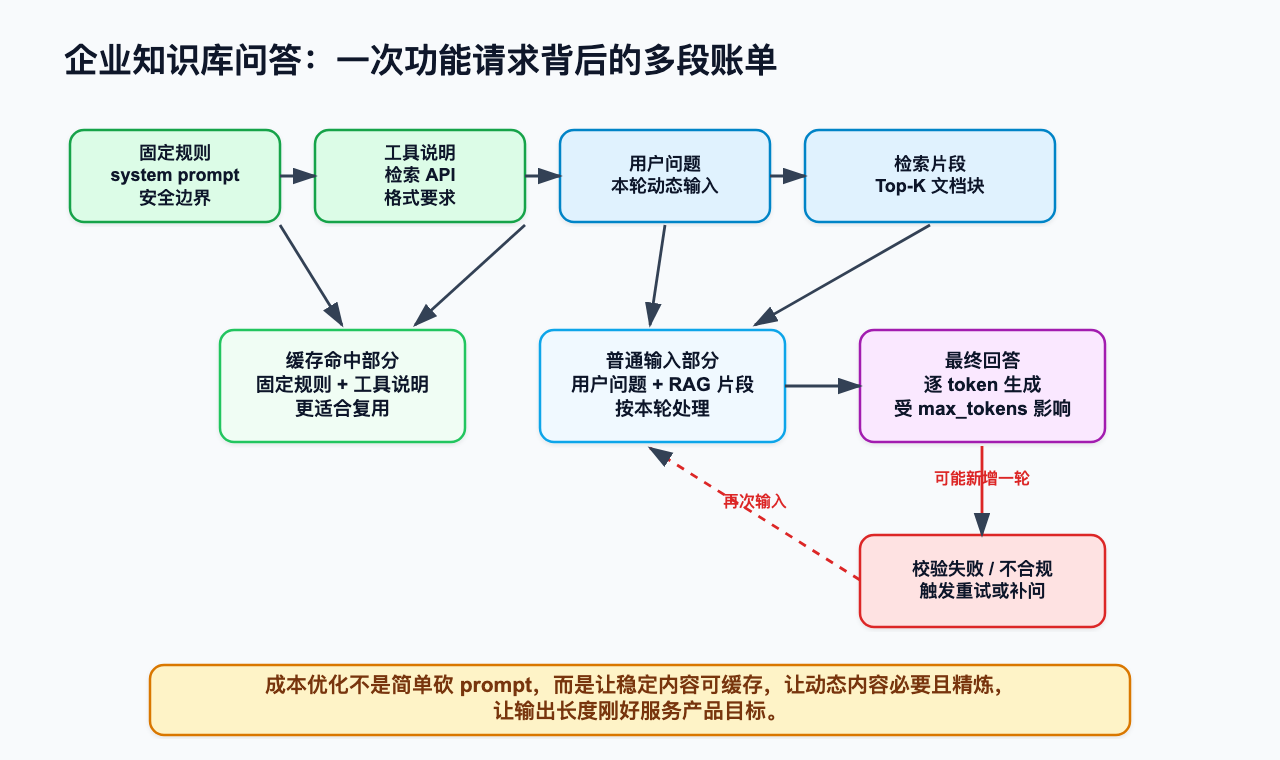
固定规则和工具说明适合缓存;用户问题和 Top-K 文档块属于本轮动态输入;最终回答属于输出;校验失败后的重试会产生新一轮输入和输出。检索片段越多,普通输入成本越高,延迟越大;但检索片段太少,答案可能缺证据,后续又会靠重试和追问把成本补回来。
假设这个助手有 6000 token 的固定规则和工具说明,检索系统每次返回 4000 token 文档片段,用户问题 100 token,模型回答 900 token。缓存命中后,固定前缀的成本下降,但检索片段和回答仍是主要变量。如果产品经理要求“为了保证准确,把 Top-K 从 5 提到 20”,输入 token 可能直接翻倍或更多。如果客服场景只需要简短答复,却让模型默认输出完整分析报告,输出成本会持续偏高。
有效的成本优化不是简单缩短 prompt。把安全规则删掉,可能让合规风险上升;把检索片段砍得太狠,可能让答案编造;把输出压得过短,可能让用户需要继续追问。更合理的方向是让稳定内容可缓存,让动态内容必要且精炼,让输出长度服务于产品目标,让重试链路少而准。
价格表背后是推理系统的资源分层
输入、输出、缓存命中分开计费,不是价格表故意复杂,而是大模型推理由不同阶段组成。输入阶段重在处理上下文和生成 KV cache;输出阶段重在逐 token 生成并持续占用推理时间;缓存命中体现的是重复计算被复用后的折扣,但它仍然需要资源管理。
如果团队想控制大模型成本,就不能只问“哪个模型便宜”。更有用的问题是:哪些 token 是必要的,哪些 token 可以缓存,哪些输出其实不该生成,哪些重试是系统设计造成的。把账单还原成推理路径之后,成本优化才会从凭感觉压缩 prompt,变成可观测、可解释、可迭代的工程工作。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 15
15 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)