python_pandas
文章目录
一、pandas介绍
参考文章:https://blog.csdn.net/qq_42415326/article/details/89678833
1:Pandas 看作是 Python 版的 excel
2: 分类
- Series:一维数组
- DataFrame:二维的表格型数据结构
3:安装
pip install pandas
import pandas
二、Series
1.使用
pandas.Series( data, index, dtype, name, copy)
数据, 行标签
2.生成表
import pandas
# (一):列表
a = ['zhangsan', 18, 'sex', 'play games']
name = ['姓名', '年龄', '性别', '爱好']
data = pandas.Series(a, name)
print(data)
# (二):字典
b = {'name': 'lisi', 'age': 14, 'sex': 'man', 'hobby': 'listen jay'}
datab = pandas.Series(b)
print(datab)
# 1:读取数据, 索引/[]/. 都可以
print(datab[0])
print(datab['sex'])
print(datab.hobby)

3:简单计算
# 2:计算
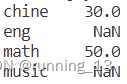
series1 = pandas.Series([20, 20, 40], ['chine', 'math', 'eng'])
series2 = pandas.Series([10, 30, 60], ['chine', 'math', 'music'])
print(series1 + series2)
print(series1 - series2)
三、DateFrame
1.使用
首先,二维数据
pandas.DataFrame( data, index, columns, dtype, copy)
数据,行标签,列标签,数据类型统一
2:生成表
#(一):二维数组
a = [['zhangsan',10,'man','school1'],['lisi',11,'man','school2'],['wamgwu',12,'man','school1']]
data = pandas.DataFrame(a, index=['qq','ww','ee'], columns=['name','age','sex','school'])
print(data)
#(二)ndarray
b = {'name':['zs','ls','ww'], 'age':[11,12,13], 'sex':['man','women','man']}
datab = pandas.DataFrame(b)
print(datab)
#(三)字典
c=[{'name':'zs','age':11,'school':'school1'},{'name':'ls','age':12,'school':'school1'}]
datac = pandas.DataFrame(c)
print(datac)
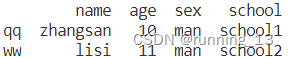
①:行名称和列名称
data.index
data.columns
2:行列 loc[]
区别:是否 使用loc
- 单行:loc[]
- 多行:loc[[ ]]
- 行与列:loc[[‘行’],[‘列’]]
- 列:直接调用 []
1:显示数据
#读取数据
print(data.loc['qq']) #一行数据
print(data.loc[['qq','ww'],['name','age']]) #多条行与列数据
print(data.loc[['qq','ee']]) #多行
print(data[['name','sex']]) #多列数据

2:增加数据
#添加一行
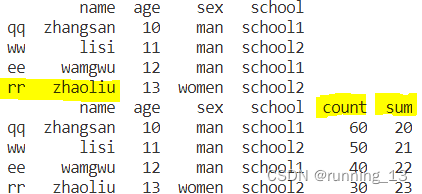
data.loc['rr'] = ['zhaoliu',13,'women','school2']
#添加一列
data['count'] = pandas.Series([30,40,50,60], index=['rr','ee','ww','qq'])
data['sum'] = data['age']+10
3:删除数据,drop
原数据不变
参数:字段名,+ 行axis=0 列axis=1 永久删:inplace=True
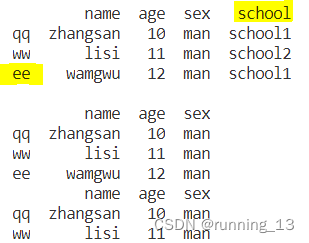
# 删除数据
data_drop = data.drop('school', axis=1)
data_drop1 = data_drop.drop('ee', axis=0)
4:筛选数据
data[]
data[data[‘age’]>=11]
5:重置索引 set_index(‘xxx’)
3:缺失、空值 dropna()
①:删除 dropna()
②: 填充 fillna(0)
4:分组统计 groupby()
先分组groupby() ,再求和,平均数,中位数,标准差
1:单个
#分组统计 平均值mean() 个数count() 最小值min() max() 中位median() 和 众数mode()
#[]指定某一项
pingjun = data.groupby('school').mean()['score']
count = data.groupby('school').count()[['sex','age']]

2:汇总 describe()
descri = data.groupby('school').describe() #汇总
descri_shu = data.groupby('school').describe().transpose() #竖着方便看
3:连接concat()
concat([data1, data2], axis=0)
5:多个表的连接join()
1: join() 同行

2:merge() 同列

四、常用方法
1:唯一值 unique()
#查找唯一的值和个数
val = data['score'].unique() #值的列表
print(val)
count = data['score'].nunique() #唯一值的个数
print(count)
val_count = data['score'].value_counts() #值-个数
print(val_count)

2:数据处理 apply()
格式:apply(函数())
#lambda格式 参数:计算结果为返回值
data1 = data['score'].apply(lambda x:str(x)+'分数')
data['score'] = data1 #保存修改后的结果
print(data)

3:排序 sort_values()
data.sort_values(‘score’)
4: 查找空值 isnull()
data.isnull()
结果:boolean
5: 时间格式 to_datetime()
data[‘Date’] = data.to_datetime(data[‘Date’])
5:汇总统计表pivot_table()
本质:对每列值的操作
pandas.pivot_table(data, values='', index=[''], columns=[''])
#values 列的值加减等计算
#index 行: 按列的值分组
#columns 列: 列的值分组
原始table
animals = pandas.DataFrame(data)
table = animals.pivot_table(values='d', index=['a','b'], columns=['c'])
print(table)
分组之后

五、导入文件
1:csv文件
读取:read_csv() toString()返回完整数据
写入:to_csv()
import os
print(os.getcwd()) #获取文件的当前路径
#csv文件的读取与写入
csv_file = pandas.read_csv('./Spider/spiders/nba.csv')
print(csv_file.to_string())

#导出csv, index=0,1忽略
csv_file.to_csv('./Spider/spiders/a.csv', index=False)
2:json 文件
①:读取文件
json_file= pandas.read_json('sites.json')
print(json_file.to_string())
②:从url中读取json数据
data = pandas.read_json(url)
print(data)
③:json_normalize
1:将JSON数据规范化为table表
2:
studentList = {
"school_name": "ABC primary school",
"class": "Year 1",
"detail":{"aid":123, "count":3, "data":[{
"id": "A001","name": "Tom","math": 60},{
"id": "A002","name": "James","math": 89},{
"id": "A003", "name": "Jenny","math": 79}]}}
#record_path:数据, meta:其他列, errors:数据缺失默认为NaN
dataList = pandas.json_normalize(studentList, record_path=['detail','data'], meta=['school_name','class',['一级','下一级']], errors='ignore')
print(dataList)
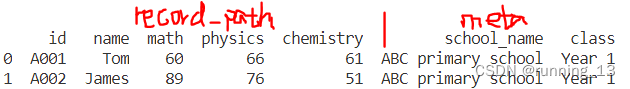
3:嵌套表示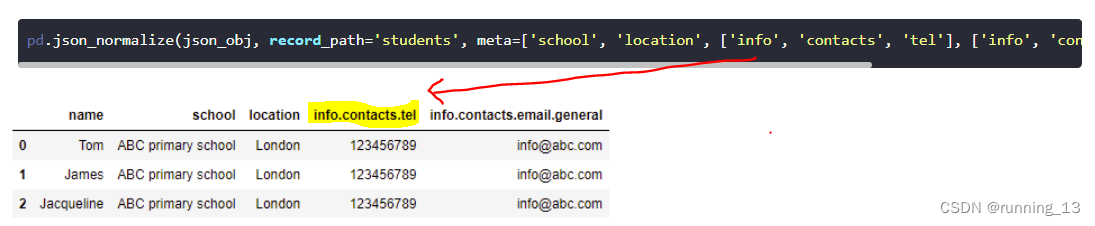
3:excel文件
#excel文件的读取与写入
excel_file = pandas.read_excel('./Spider/spiders/pand.xlsx', sheet_name='Sheet1')
print(excel_file.fillna(' '))
excel_file.to_excel('./Spider/spiders/b.xlsx', sheet_name='sheet1', index=False)
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)