清华&小米最新的4D世界动作模型,延迟直降4.5倍!多任务协同有解了
「基于视频先验与异步去噪的统一4D世界动作建模技术解读」
目录
03 异步噪声采样平衡视频与动作处理差异,解决训练与推理脱节问题
X-WAM是由清华大学、小米机器人、北京大学与中科院相关研究人员共同提出的统一4D世界动作模型。
该模型聚焦机器人场景中的多任务协同需求,在视频生成、空间重建与动作执行的一体化实现上提出了全新路径,针对性破解了当前机器人建模领域的四项主要痛点,同时突破了业界常规解决思路的局限,形成了兼具创新性与实用性的技术方案。
其中,4D世界动作建模是一种能够同时捕捉空间三维信息与时间维度变化,并且关联机器人动作的建模方式,这种建模方式可让机器人更全面地感知环境并做出响应。
01 统一框架设计破解多任务协同难题
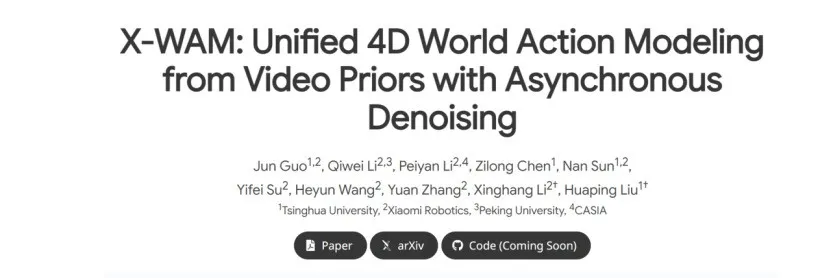
当前机器人操作场景中,主要痛点之一是需同时实现高保真视频生成、3D空间重建与实时策略执行,三者的协同实现直接影响机器人的实际实用性。
高保真视频生成是能够还原场景细节、符合真实物理规律的视频输出方式,这种方式可以帮助机器人预判场景变化、规划动作路径;
3D空间重建是将二维视觉信息转化为三维空间结构的过程,这个过程能让机器人准确感知周围环境的空间布局,比如物体的位置、大小与距离;
实时策略执行是机器人根据场景信息快速做出动作响应、完成指定任务的能力,这种能力影响着机器人在实际场景中的适用程度。
业界常规解决思路中,多采用分离的架构模块,将视频生成、3D空间重建、动作执行拆分为独立模块,各模块通过数据传递实现协同,这种方式不仅增加了模块间的衔接成本,更难以实现三者的深度协同,无法满足机器人多任务一体化需求。
针对这一痛点与常规思路的局限,X-WAM的主要创新点是构建单一统一框架,将高保真视频生成、3D空间重建与实时策略执行三项主要任务整合其中,无需拆分模块,实现了视觉生成、空间建模与动作执行的深度协同。
原文中明确提到,X-WAM是“a unified 4D World Action Model that simultaneously targets high-fidelity video generation, 3D spatial reconstruction, and real-time policy execution”,这句话的含义是,X-WAM作为统一的4D世界动作模型,能够同时面向高保真视频生成、3D空间重建与实时策略执行这三项任务。
采用统一框架将多个任务整合在同一个模型结构内,无需拆分独立模块的设计方式,这种设计方式可减少模块间的衔接成本。通过这样设计,意在从根本上缓解分离式架构模块衔接成本高、效率低的问题,让机器人能够同步完成视觉感知、空间认知与动作执行,一定程度上提升了多任务协同效率。
02 轻量级深度适配,替代额外标记景深
深度信息是实现3D空间重建的核心数据,能够反映物体与机器人之间的距离关系,但常规处理方式存在明显效率短板。业界普遍将深度信息作为额外标记加入模型序列,以此提取空间特征,这种思路将深度数据与彩色视频数据(RGB数据)分开处理,拼接后输入模型。
RGB数据是机器人获取的场景彩色图像信息,是视觉感知的基础数据,将深度数据与RGB数据拼接输入,虽能实现深度信息的利用,但会直接导致序列长度翻倍,增加模型计算量,进而产生额外延迟,影响机器人动作的实时执行效率,制约了3D空间重建与实时执行的协同实现。
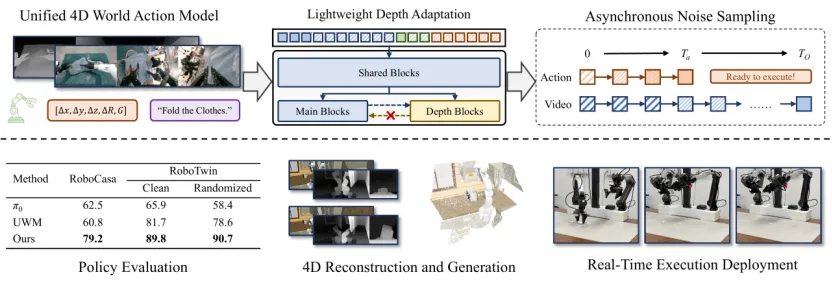
为破解这一效率痛点,X-WAM采用轻量级深度适配设计,摒弃了“额外标记”的常规思路,提出复制预训练扩散Transformer的最后若干模块,构建专用的深度预测分支。
预训练扩散Transformer是经过大量数据训练后具备基础视觉处理能力的模型结构,其最后若干模块是负责提取高层视觉特征的部分;深度预测分支是专门用于预测深度信息的模型分支,可独立完成深度数据的处理与输出;轻量级深度适配是一种不增加模型复杂度、不额外占用过多计算资源,同时能实现深度信息高效处理的适配方式。
原文中指出,X-WAM通过“lightweight structural adaptation: replicating the final few blocks of the pretrained Diffusion Transformer into a dedicated depth prediction branch for the reconstruction of future spatial information”,即轻量级结构适配就是将预训练扩散Transformer的最后若干模块进行复制,形成专门的深度预测分支,用于未来空间信息的重建。通过这样的轻量级结构适配,无需增加序列长度,就能高效获取空间信息,既可以避免序列翻倍带来的计算延迟,又能较为精准地完成3D空间重建,实现了空间感知与实时执行的高效协同。
03 异步噪声采样平衡视频与动作处理差异,解决训练与推理脱节问题
机器人建模中另一大主要痛点是视频数据和机器人动作的处理差异,两者需要的去噪处理步数有较大区别。
去噪处理是视频生成与动作解码过程中的必要步骤,去噪处理是消除数据中的干扰信息,保证输出结果准确性的过程,其合理性直接影响输出结果的准确性。视频数据的高保真生成需要完整的去噪步骤,才能还原连贯的视觉效果;而机器人动作的实时执行则需要快速完成去噪解码,避免因处理步骤过多导致动作延迟。
针对这一差异,业界常规思路是对视频和动作的去噪时间步做独立或解耦采样,去噪时间步是模型对带噪声的数据进行逐步去噪、还原真实信息的过程步骤,解耦采样是将两种数据的采样过程分开进行、互不干扰的方式,这种方式虽能分别保证单一任务的效果,但会导致训练过程中的采样分布与实际推理时的分布不一致,进而影响模型在实际应用中的表现。
X-WAM提出独特的异步噪声采样(ANS)策略,这种策略可以平衡两者的处理差异,同时缓解训练与推理脱节的问题。异步噪声采样(ANS)是一种针对视频和动作去噪步骤差异设计的采样策略,其核心是在不同阶段采用不同的去噪节奏,兼顾两者的需求。其中,推理阶段是模型经过训练后,实际处理任务、输出结果的阶段;训练阶段是模型通过数据学习、调整参数,以适配任务需求的阶段。
原文提到,X-WAM的Asynchronous Noise Sampling (ANS)“applies a specialized asynchronous denoising schedule during inference, which rapidly decodes actions with fewer steps to enable efficient real-time execution, while dedicating the full sequence of steps to generate high-fidelity video”,大意是,异步噪声采样(ANS)在推理阶段采用专门的异步去噪调度方式,通过较少的步骤快速解码动作,以实现高效的实时执行,同时将完整的步骤用于生成高保真视频,这样的设计可以完美适配两者的处理需求。
同时,在训练阶段,“ANS samples from their joint distribution to align with the inference distribution”,也就是异步噪声采样(ANS)从视频与动作噪声等级的耦合联合分布中进行采样,耦合联合分布是将视频和动作的噪声等级结合在一起形成的分布,这种采样方式可以确保训练分布与推理分布保持一致,这与业界解耦采样的常规思路有所不同,能够缓解常规方法中训练与推理脱节的主要局限。
04 联合去噪与预训练微调
世界状态建模和机器人动作执行的协同优化,是机器人建模的另一大难点,这种协同优化是让两项任务在统一框架内完成,同时保留预训练模型的视觉先验。预训练视频扩散模型具备强大的视觉先验,视觉先验是模型在大量数据上训练得到的、对视觉场景的准确认知能力,这种能力可以帮助模型快速、准确地处理视觉信息。
业界常规思路中,要么只注重利用视觉先验提升视频生成质量,忽略了空间重建与动作执行的需求;要么在加入空间重建和动作执行模块时,破坏了预训练模型的视觉先验,导致视频生成质量下降,难以实现三者的平衡兼顾。
针对这一难点,X-WAM以预训练视频扩散模型为基础,通过微调实现多类数据的联合去噪,这种方式可以实现协同优化与视觉先验保留的双重目标。微调是在预训练模型的基础上,通过少量数据进一步训练,使模型适配特定任务的过程;联合去噪是将多种类型的数据放在一起,同步进行去噪处理的方式;预训练视频扩散模型是经过大量视频数据训练,具备基础视频处理和视觉特征提取能力的模型。
原文明确说明,“X-WAM is built upon a pretrained video diffusion model (Wan2.2-5B) and fine-tuned to jointly denoise multi-view RGB videos, proprioceptive states, and robot actions within a single unified sequence”,即X-WAM依托Wan2.2-5B预训练视频扩散模型,经过微调后,在单一统一序列中,同时对多视角RGB视频、本体感受状态和机器人动作进行联合去噪。其中,多视角RGB视频是从不同角度获取的场景彩色视频信息,本体感受状态是机器人对自身关节、肢体位置的感知信息,机器人动作是机器人完成任务时的肢体运动指令,单一统一序列是将多种类型的数据整合为一个连续的数据序列,供模型统一处理。
这种联合去噪方式,让模型能够同时学习视觉信息、自身状态与动作指令之间的关联,既可以充分保留预训练模型的视觉先验,保证高保真视频生成效果,又能实现世界状态建模与动作执行的协同优化,避免了两者脱节的问题。
05 总结
统一的4D世界动作模型是一种能够整合多任务、兼顾视觉与动作需求的建模框架,可让机器人在感知环境的同时快速做出动作响应。
X-WAM依托预训练视频扩散模型的视觉先验,结合异步噪声采样与轻量级深度适配等创新设计,构建了统一的4D世界动作模型。该模型的主要价值在于打破了业界常规思路的局限,以单一统一框架整合了高保真视频生成、3D空间重建与实时策略执行三项主要能力,无需拆分模块,实现了多任务的深度协同,能够缓解常见的计算延迟、训练与推理脱节、模块衔接成本高、视觉先验利用不充分等问题。
RoboCasa与RoboTwin 2.0是机器人领域常用的基准测试场景;真实机器人部署是将训练好的模型应用到实际机器人上,让机器人完成具体任务的过程;精密操作任务是对动作精度要求较高的机器人操作任务,比如小型物品的组装、摆放等,X-WAM是让真实机器人拿起小物件耳机,包括不同颜色,新奇的摆放方式,还会增加分心物来干扰采用X-WAM的机器人

从实验效果来看,X-WAM在RoboCasa与RoboTwin 2.0基准测试中表现优于现有方法,在4D重建与生成上具备更优的视觉与几何指标(视觉指标关注画面的真实度和连贯性,几何指标关注空间结构的准确性);在真实机器人部署中(操作耳机盒),能够完成各类操作任务,具备良好的泛化能力与扩展性,能够平稳从仿真环境迁移到真实世界,同时在精密操作任务中能够输出更平滑的动作。
总体上,X-WAM通过一体化的技术路径,为机器人4D世界建模与实时动作执行提供了新的解决方案。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献49条内容
已为社区贡献49条内容

所有评论(0)