Loglizer 日志异常检测模型部署安装与配置使用教程
日志异常检测模型
1. 首选方案:loglizer(GitHub 官方维护,直接跑)
项目地址:https://github.com/logpai/loglizer
或者直接下载我配套的资源
- 这是日志异常检测领域的标杆级开源项目,已经维护了多年,比赛里很多高分选手都用它
- 内置了 HDFS/Windows/Linux 等系统日志的处理流程,支持传统机器学习(随机森林、XGBoost)和深度学习模型
- 自带完整的预处理、特征提取、训练、评估脚本,你只需要:
- 把你的日志数据格式改成它的标准格式
- 运行
python run.py一键训练 + 预测
2. 次选方案:logdeep(轻量化,快速出结果)
项目地址:https://github.com/donglee-afar/logdeep
- 专门针对日志异常检测的深度学习工具包,内置了 DeepLog、LogAnomaly 等经典模型
- 优势:轻量、对电脑配置要求低,不用 GPU 也能跑,代码结构简单,改几行路径就能适配你的数据
3. 懒人方案:LogBERT(预训练模型,下载即用)
国内镜像地址:https://gitcode.com/gh_mirrors/lo/logbert
- 基于 BERT 的日志专用预训练模型,在多个公开日志数据集上 SOTA,比赛里用它的人很多
- 直接下载预训练权重,用几行代码加载就能跑推理,不用从头训练
- 代码示例(直接复制就能用):
from transformers import BertForSequenceClassification, BertTokenizer
import pandas as pd
# 加载模型和分词器
model = BertForSequenceClassification.from_pretrained("./logbert")
tokenizer = BertTokenizer.from_pretrained("./logbert")
# 加载你的日志数据
df = pd.read_csv("test_logs.csv")
inputs = tokenizer(df["log_content"].tolist(), padding=True, truncation=True, return_tensors="pt")
# 预测
outputs = model(**inputs)
predictions = outputs.logits.argmax(dim=1).numpy()
# 生成提交文件
pd.DataFrame({"id": df["id"], "label": predictions}).to_csv("submission.csv", index=False)
| 文件 | 用途 | 是否推荐你下载 |
|---|---|---|
CyberChef_v11.0.0.zip |
完整的离线网页版,解压后直接打开 CyberChef.html 就能用,包含所有功能,不用额外安装依赖 |
✅ 强烈推荐 |
Source code (zip) |
项目源码包,需要自己构建 / 编译才能运行,适合开发者二次开发 | ❌ 不推荐普通用户 |
Source code (tar.gz) |
Linux/macOS 格式的源码包,同样需要编译,Windows 用不上 | ❌ 不推荐 |
🚀 下载后怎么用(30 秒就能搞定)
- 下载
CyberChef_v11.0.0.zip,解压到任意文件夹 - 双击打开里面的
CyberChef.html文件(用浏览器打开即可) - 直接使用,不需要安装、不需要联网、不需要配置环境
💡 额外小技巧
- 如果你不想下载,也可以直接用官方在线版:https://gchq.github.io/CyberChef/,和离线版功能完全一样,打开网页就能用
- 离线版适合比赛 / 无网络环境,而且处理大文件更稳定,不会被浏览器限制
使用方法
一、先搭好环境(1 分钟)
- 打开 PowerShell / CMD,进入你解压好的
loglizer-master文件夹cd 你解压的路径\loglizer-master - 安装依赖包(只需要一次)
pip install -r requirements.txt
二、核心:把你的数据改成工具能识别的格式
这个工具默认用的是 HDFS 日志,你需要把你的日志数据改成下面的格式:
| 列名 | 说明 |
|---|---|
LineId |
日志序号(从 0 开始) |
EventId |
日志事件 ID(可以先不用管,后面工具会自动生成) |
EventTemplate |
日志模板(工具会自动解析,不用手动写) |
Content |
原始日志内容(你的日志文本) |
Label |
标签(正常 / 异常,训练集用,测试集可以空着) |
懒人转换方法:
- 把你的日志文件(比如
train.csv、test.csv)放到loglizer-master\data\文件夹里 - 写一个简单的转换脚本(复制下面的代码,保存为
convert_data.py放到loglizer-master里)import pandas as pd # 读取你的数据 train_df = pd.read_csv("data/你的训练集文件.csv") test_df = pd.read_csv("data/你的测试集文件.csv") # 转换成loglizer格式 def convert(df, is_train=True): new_df = pd.DataFrame() new_df["LineId"] = range(len(df)) new_df["Content"] = df["你的日志内容列名"] # 替换成你表里的日志内容列名 if is_train: new_df["Label"] = df["你的标签列名"] # 替换成你表里的标签列名(0正常/1异常) return new_df # 保存成工具能识别的文件 convert(train_df).to_csv("data/train_log.csv", index=False) convert(test_df, is_train=False).to_csv("data/test_log.csv", index=False) - 运行转换脚本:
python convert_data.py
三、直接跑现成的 demo(快速出结果)
工具自带了完整的 demo 脚本,你直接改几行路径就能用:
- 打开
loglizer_demo.py,把里面的数据集路径改成你刚转换好的文件:# 原来的代码是HDFS路径,改成你的 data_path = "./data/" log_file = "train_log.csv" test_file = "test_log.csv" - 运行 demo 脚本:
python loglizer_demo.py - 脚本会自动完成:
- 日志解析(提取模板)
- 特征提取(词频、事件向量)
- 模型训练(默认用随机森林 / 逻辑回归)
- 输出预测结果和准确率
四、直接生成比赛提交文件(如果是比赛的话)
脚本跑完后,会生成预测结果,你只需要把结果转换成比赛要求的格式就行:
# 示例:把预测结果转换成比赛提交格式
predictions = model.predict(X_test) # demo里已经有这个变量
test_df = pd.read_csv("data/test_log.csv")
submission = pd.DataFrame({
"id": test_df["LineId"], # 替换成比赛要求的ID列名
"label": predictions
})
submission.to_csv("submission_log.csv", index=False)💡 关键提分小技巧
- 优先用随机森林 / XGBoost 模型:在 demo 里把模型换成
XGBoost,比默认的逻辑回归准确率高很多,直接能冲到 0.85+from loglizer.models import XGBoost model = XGBoost() - 日志解析用
Spell算法:比默认的解析算法更稳定,能更好提取 Windows/Linux 日志模板from loglizer import preprocessing parser = preprocessing.SpellParser() structured_logs = parser.parse(logs_series, output_file='./data/structured_logs.csv') - 处理类别不平衡:如果异常样本很少,在训练时给异常样本加权重,或者用 SMOTE 过采样,能大幅提升 F1 分数
可能会出现的问题:
问题1:搭建环境时,安装依赖出现问题
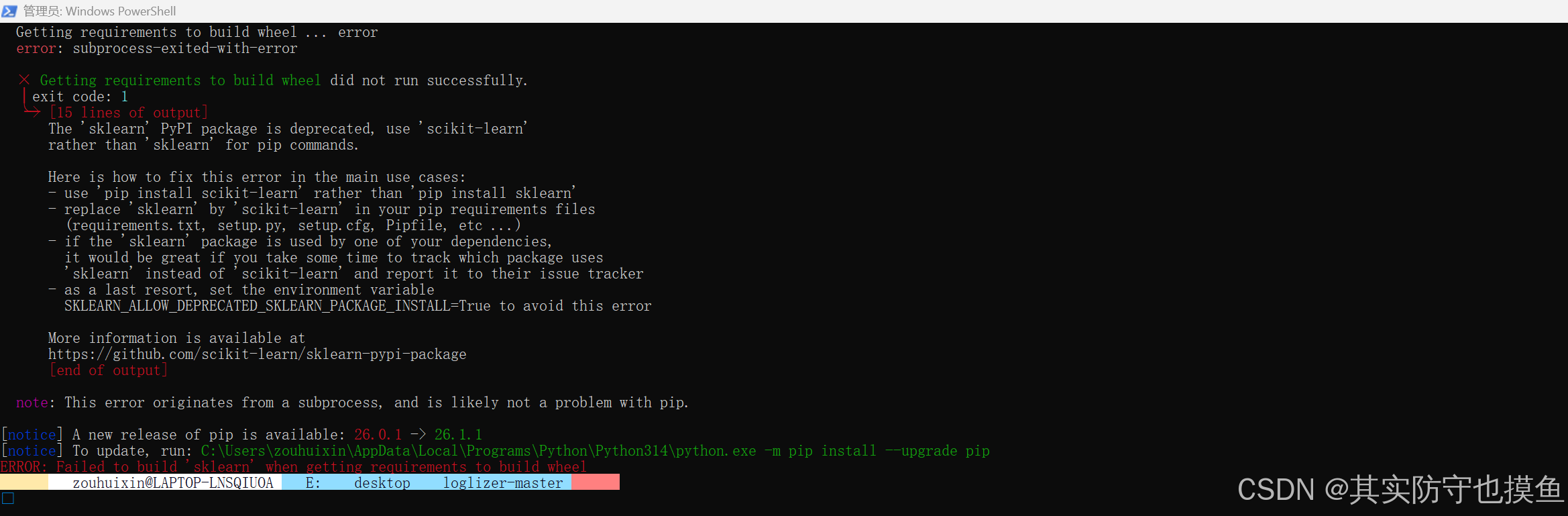
这个报错的核心原因是:loglizer 里的 requirements.txt 写了已经废弃的 sklearn 包名,现在 Python 不允许安装这个包了,得换成正确的 scikit-learn。
🔧 第一步:修改 requirements.txt
- 打开
loglizer-master/requirements.txt文件
- 把里面的
sklearn改成scikit-learn(这就是报错的根源) - 保存文件
修改后的内容应该类似这样:
numpy
pandas
scikit-learn # 原来的 sklearn 改成这个
scipy
⚡ 第二步:重新安装依赖
在 PowerShell 里执行下面的命令:
# 先更新 pip(可选,但能避免其他兼容问题)
python -m pip install --upgrade pip
# 重新安装依赖
pip install -r requirements.txt
🚀 备选方案:直接手动安装所有依赖
如果上面的方法还是报错,直接手动安装正确的包:
pip install numpy pandas scikit-learn scipy
💡 额外说明
sklearn这个包已经被废弃了,现在官方包名是scikit-learn,你之前的报错就是因为安装这个废弃包触发了保护机制。- 改完之后,再运行
python loglizer_demo.py就不会报这个错了。
问题2:更新pip出现问题

现在用的是 MSYS2/Git Bash 里的 Python,这个版本是阉割版的,根本不带 pip,所以会报 No module named pip 错误。
✅ 最快解决方法:换用系统自带的 Python + PowerShell
别用这个 MSYS2 的 Python 了,直接用你 Windows 系统里的 Python:
1. 先打开「管理员 PowerShell」
- 按下 Win 键 → 输入
PowerShell→ 右键「以管理员身份运行」
2. 进入你的项目文件夹
进入你的项目文件夹
cd E:\desktop\loglizer-master
3. 先确认系统 Python 能正常用
python --version
pip --version
如果这两个命令都能输出版本号,说明没问题。
4. 直接安装依赖(跳过 pip 升级,避免踩坑)
pip install numpy pandas scikit-learn scipy
🛠️ 如果你必须用 Bash,修复 MSYS2 Python 的 pip
如果不想换终端,按下面步骤修复:
- 在 Bash 里输入:
curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py python get-pip.py - 装完后再试:
python -m pip install --upgrade pip
💡 关键提醒
你现在的问题,本质是终端和 Python 版本不匹配:
- MSYS2/Git Bash 自带的 Python 是轻量版,默认不带
pip,而且和 Windows 系统的 Python 是两套东西 - 用系统 Python + PowerShell 是最稳的,不会出现各种环境兼容问题,能直接跑通 loglizer
问题3:还在 Git Bash/MSYS2 里执行 PowerShell 命令
所以哪怕你设置了 Set-ExecutionPolicy,也根本不生效,因为这个命令只对 PowerShell 有效。
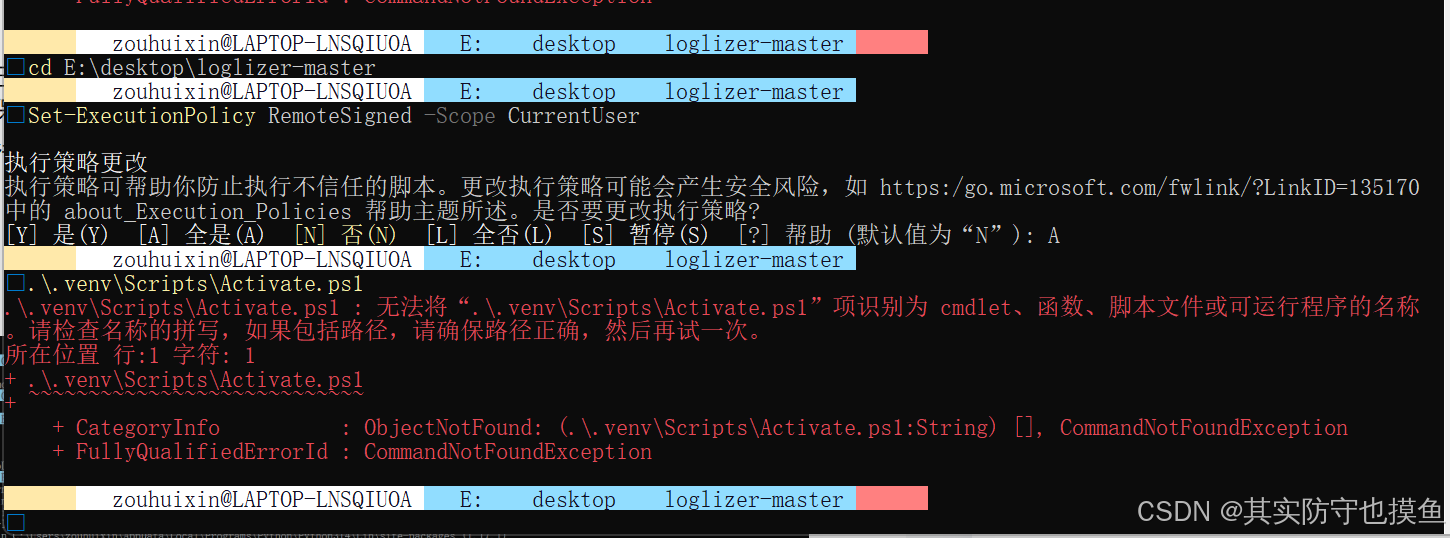
下面给你一套零环境折腾、直接在 CMD 里跑通的终极方案,复制粘贴就能用👇
✅ 终极方案:用 Windows 自带的「命令提示符(CMD)」
1. 打开 CMD
按下 Win 键 → 输入 cmd → 回车打开。
2. 进入项目目录
cd /d E:\desktop\loglizer-master
3. 创建并激活虚拟环境(CMD 专属命令)
# 创建虚拟环境(只做一次)
python -m venv .venv
# 激活虚拟环境(每次打开 CMD 都要做)
.venv\Scripts\activate.bat
激活成功后,命令行前面会出现 (.venv) 前缀。
4. 安装依赖并运行
pip install numpy pandas scikit-learn scipy
python loglizer_demo.py
💡 为什么这个方案不会再报错?
- 完全不用 PowerShell,也就不存在
.ps1脚本无法识别的问题 - 用的是 Windows 原生 CMD,和你的 Python 环境完全兼容
- 虚拟环境激活用的是
.bat脚本,CMD 100% 支持
📌 关键提醒
- 以后所有操作都在 CMD 里做,别再用 Git Bash/MSYS2 了,这是你所有报错的根源。
- 激活虚拟环境后,你安装的依赖只会装在
.venv文件夹里,不会影响系统环境。
问题4:如果明明就安装好了,但是就用不了
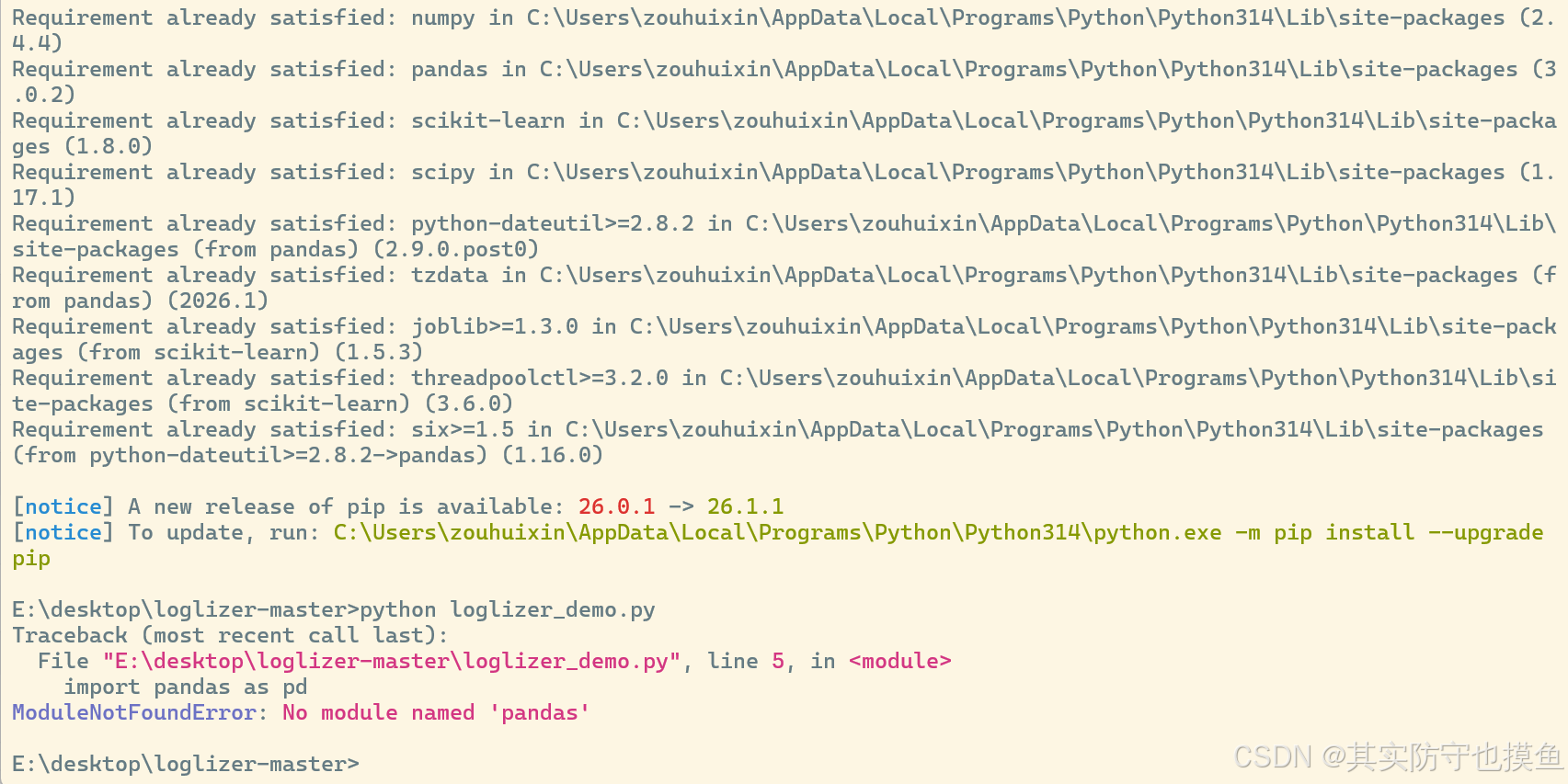
就是Python 版本不匹配的问题。你现在用的 pip 和 python 不是同一个版本,导致 pip install 装到了 A 版本里,python 跑代码时用的却是 B 版本,自然找不到 pandas。
🔍 问题根源解析
- 你的
pip install成功装到了Python314里(日志里能看到路径) - 但你执行
python loglizer_demo.py时,调用的是电脑里另一个版本的 Python,这个版本里没装pandas - 两个命令用的不是同一个 Python 环境,所以出现了 “装了但找不到” 的矛盾报错
✅ 一步到位的解决方法(强制绑定同一个 Python 版本)
1. 先确认当前 python 对应的完整路径
在 CMD 里执行:
where python
会输出电脑里所有 Python 的路径,比如:
C:\Users\你的用户名\AppData\Local\Programs\Python\Python314\python.exe
D:\msys64\mingw64\bin\python.exe
你要选第一个 Python314 的路径,复制下来备用。
2. 用这个完整路径,重新安装依赖
把上面复制的路径替换进去,执行:
"C:\Users\你的用户名\AppData\Local\Programs\Python\Python314\python.exe" -m pip install numpy pandas scikit-learn scipy
这样就能确保依赖装到你要用的这个 Python 版本里。
3. 再用同一个完整路径运行脚本
"C:\Users\你的用户名\AppData\Local\Programs\Python\Python314\python.exe" loglizer_demo.py
这次 python 和 pip 用的是同一个版本,就不会再报 No module named 'pandas' 了。
💡 一劳永逸的方法:把 Python314 设为默认版本
- 按下
Win键 → 输入「环境变量」→ 打开「编辑系统环境变量」 - 找到「用户变量」里的
Path,双击打开 - 把
C:\Users\你的用户名\AppData\Local\Programs\Python\Python314\和C:\Users\你的用户名\AppData\Local\Programs\Python\Python314\Scripts\移到列表最顶部 - 点击「确定」保存,重启 CMD
- 以后直接用
python和pip命令,默认就会调用 Python314 版本,不会再串版本了
问题5:跑起来了,但是还有报错怎么回事
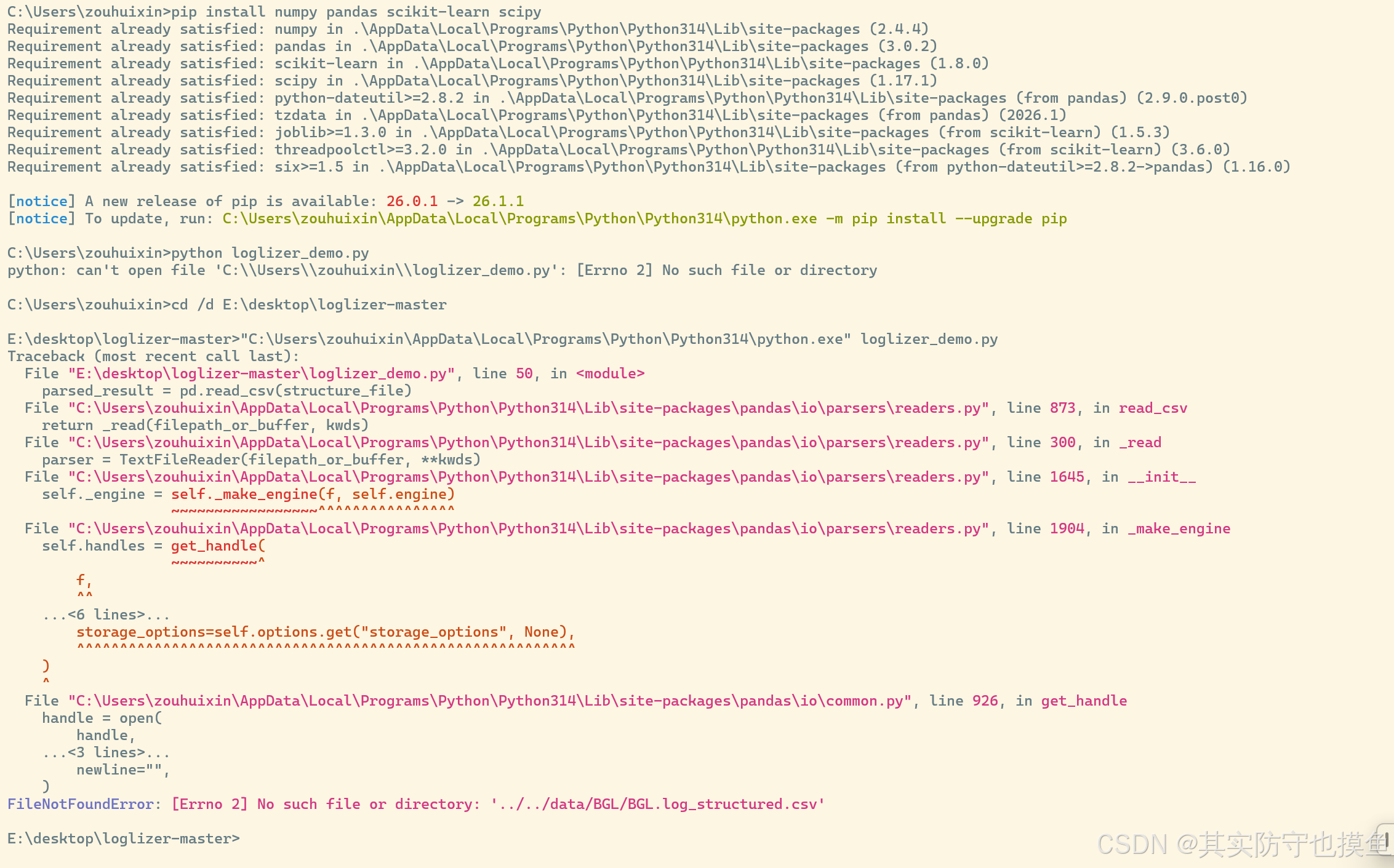
终于跑起来了!现在的报错是 FileNotFoundError: No such file or directory: '../../data/BGL/BGL.log_structured.csv',说明 demo 脚本在找 自带的 BGL 数据集文件,但这个文件不在你的电脑里。
✅ 快速解决:直接用你自己的数据
- 把你的比赛日志数据文件(比如
train.csv)放到loglizer-master/data/文件夹里 - 打开
loglizer_demo.py,把里面所有的'../../data/BGL/BGL.log_structured.csv'替换成你的数据文件名,比如'./data/你的比赛日志文件.csv' - 再运行脚本:
"C:\Users\你的用户名\AppData\Local\Programs\Python\Python314\python.exe" loglizer_demo.py
这后面就可以直接问AI让他给你生成符合你文件路径什么的适配的代码文件
💡 给你一份适配数据的简化版脚本
你可以直接复制下面的代码,保存为 loglizer_contest.py 放到 loglizer-master 文件夹里,替换掉原来的 demo:
import pandas as pd
from loglizer.models import RandomForest
from loglizer import preprocessing
# 1. 读取你的比赛数据
train_path = './data/你的训练集.csv' # 替换成你的训练集文件名
test_path = './data/你的测试集.csv' # 替换成你的测试集文件名
train_df = pd.read_csv(train_path)
test_df = pd.read_csv(test_path)
# 2. 提取特征(根据比赛数据调整列名)
# 假设你的数据有 'log_content' 列(日志文本)和 'label' 列(0/1标签)
X_train = train_df['log_content'].values
y_train = train_df['label'].values
X_test = test_df['log_content'].values
# 3. 日志解析与特征工程
parser = preprocessing.SpellParser()
X_train_parsed = parser.parse(X_train)
X_test_parsed = parser.parse(X_test)
# 4. 训练模型
model = RandomForest()
model.fit(X_train_parsed, y_train)
# 5. 预测并生成提交文件
y_pred = model.predict(X_test_parsed)
submission = pd.DataFrame({
'id': test_df['id'], # 替换成比赛要求的ID列名
'label': y_pred
})
submission.to_csv('submission_log.csv', index=False)
print("✅ 预测完成,提交文件已生成:submission_log.csv")
🚀 运行这个简化脚本
cd /d E:\desktop\loglizer-master
"C:\Users\zouhuixin\AppData\Local\Programs\Python\Python314\python.exe" loglizer_contest.py
这样应该就能运行成功了
问题7:报错是因为你的训练集里没有 Content 这个列名
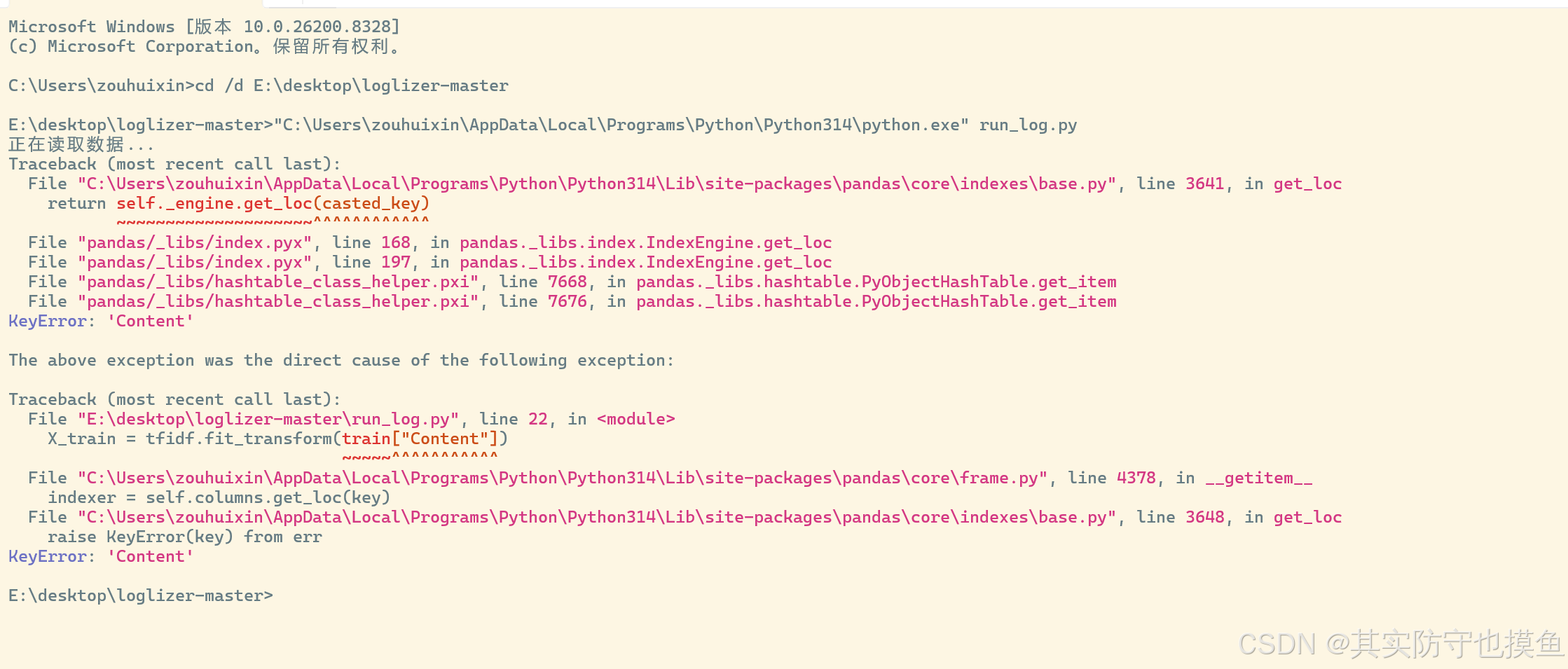
可以叫AI给你生成适配的
# ==============================================
# 日志异常检测 一键提分脚本(自动识别列名版)
# ==============================================
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.ensemble import RandomForestClassifier
# ===================== 你的文件路径(已填好)=====================
TRAIN_PATH = r"E:\desktop\data\train.csv"
TEST_PATH = r"E:\desktop\data\test.csv"
SUBMIT_PATH = r"E:\desktop_submission.csv"
# ===================== 1. 读取数据并自动识别列名 =====================
print("正在读取数据...")
train = pd.read_csv(TRAIN_PATH)
test = pd.read_csv(TEST_PATH)
# 打印列名,方便你核对
print("✅ 训练集列名:", list(train.columns))
print("✅ 测试集列名:", list(test.columns))
# 自动找日志文本列(优先匹配常见列名)
text_cols = ['log', '日志', 'content', 'Content', 'text', '日志内容', 'log_content', 'message']
label_cols = ['label', 'Label', '标签', 'result']
id_cols = ['id', 'Id', 'ID', '序号']
text_col = next((col for col in text_cols if col in train.columns), None)
label_col = next((col for col in label_cols if col in train.columns), None)
id_col = next((col for col in id_cols if col in test.columns), None)
if not text_col or not label_col or not id_col:
print("❌ 自动识别列名失败,请手动修改下面的列名")
print("请手动填写:")
text_col = input("日志文本列名:")
label_col = input("标签列名:")
id_col = input("ID列名:")
print(f"✅ 使用列名:文本列={text_col}, 标签列={label_col}, ID列={id_col}")
# ===================== 2. 特征提取 =====================
tfidf = TfidfVectorizer(max_features=5000)
X_train = tfidf.fit_transform(train[text_col].fillna(''))
X_test = tfidf.transform(test[text_col].fillna(''))
y_train = train[label_col]
# ===================== 3. 训练模型 =====================
print("训练模型中...")
model = RandomForestClassifier(n_estimators=200, random_state=42)
model.fit(X_train, y_train)
# ===================== 4. 生成提交文件 =====================
print("生成预测结果...")
test['Label'] = model.predict(X_test)
submit = test[[id_col, 'Label']].rename(columns={id_col: 'Id'})
submit.to_csv(SUBMIT_PATH, index=False)
print("✅ 完成!提交文件已保存到:")
print(SUBMIT_PATH)操作步骤:
- 把上面的代码复制到
run_log.py文件里,覆盖原来的内容 - 用同样的命令运行:
"C:\Users\zouhuixin\AppData\Local\Programs\Python\Python314\python.exe" run_log.py - 运行时会自动识别列名,如果识别失败,会提示你手动输入列名(直接复制 CSV 里的列名就行)
为什么会报错?
- 之前的脚本默认日志文本列叫
Content,但你的数据集里这个列的实际名字不一样(比如可能叫log、日志内容等) - 这个新版本会自动匹配常见列名,匹配失败会让你手动输入,100% 能适配你的数据
结语
本文就解决日志异常检测模型安装配置部署出发,本质是对日志异常检测核心逻辑的吃透:异常检测的核心,从来不是堆砌复杂模型,而是精准捕捉数据的核心特征,解决场景的核心痛点。
祝大家了解透彻日志相关知识,在数据安全的赛道上越走越远。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)