AI | Java工程师视角看大模型应用四件套:RAG、Agent、微调、提示词工程
·
关注CodingTechWork
引言
作为 Java 工程师,你可能已经被 ChatGPT、Copilot 刷屏了。但真要把大模型用到公司的业务里,你会发现:模型再强,不懂你的业务数据,也不会替你干活。
这就需要给大模型配“外挂装备”:
- 提示词工程:写好说明书,告诉模型怎么回答
- RAG:给它开卷考试,允许翻书查资料
- Agent:给它双手和工具,让它能干活
- 微调:给它上培训班,让它成为专家
提示词工程:写好调用文档
一句话理解
就像你写 API 接口文档,调用方按文档传参,接口才能稳定返回正确结果。
通俗示例
不好的提示词(就像没写清楚参数的接口):
帮我写一段产品描述
好的提示词(结构化、有示例、有约束):
【角色】:你是资深电商文案
【任务】:为“智能保温杯”写50字卖点
【风格】:年轻、口语化
【示例】:"续航7天,戴着洗澡都不怕"(智能手表)
【输出格式】:JSON {"title": "", "slogan": ""}
核心概念(Java 类比)
| 术语 | 解释 | Java 类比 |
|---|---|---|
| Zero-shot | 不给例子直接问 | 调用一个方法,不传任何配置 |
| Few-shot | 给几个例子再问 | 传一个配置对象,里面有示例 |
| CoT(思维链) | 让模型先输出推理步骤 | 在方法里打 log,输出中间过程 |
| 结构化输出 | 要求返回 JSON/XML | 定义明确的 DTO 作为返回值 |
原理图
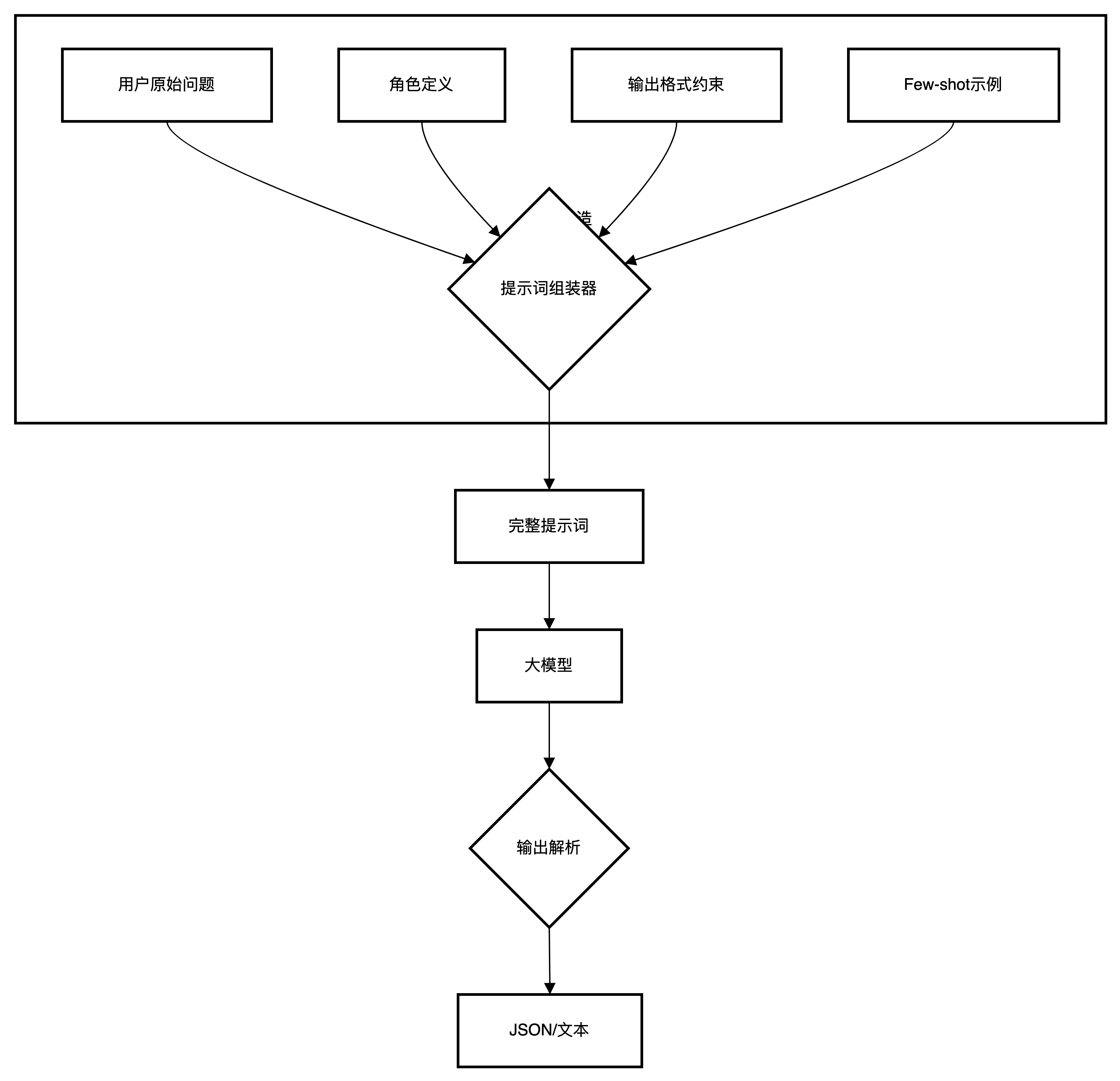
使用场景
- 快速验证想法,几分钟见效
- 不需要频繁调用,成本敏感
- 多租户场景,每个客户想要不同语气
RAG:给大模型配一个“公司知识库”
一句话理解
就像你写代码时,不用记住所有 API 文档,而是随时可以 Ctrl+Shift+F 全局搜索。
为什么需要 RAG?
大模型的问题:
- 不知道你公司 2024 年的报销制度
- 不知道最新的产品手册
- 会把不存在的法条“编”出来(幻觉)
RAG 的解决思路:
- 把公司文档提前切碎、存进向量数据库
- 用户提问时,先去库里搜索相关片段
- 把问题和搜索结果一起交给模型回答
核心概念(Java 类比)
| 术语 | 解释 | Java 类比 |
|---|---|---|
| Embedding | 把文本转成向量(一堆数字) | 把对象序列化成字节数组 |
| 向量数据库 | 存向量,支持相似度搜索 | Redis / Elasticsearch,但按向量搜 |
| 相似度检索 | 找到最相似的 Top-K 片段 | List.sort() 按相似度排序后取前 K 个 |
| 混合检索 | 向量 + 关键词一起搜 | WHERE text LIKE '%xx%' OR vector_sim(...) |
| 重排序 | 对检索结果再精细排序 | 先用索引粗筛,再精排 |
原理图
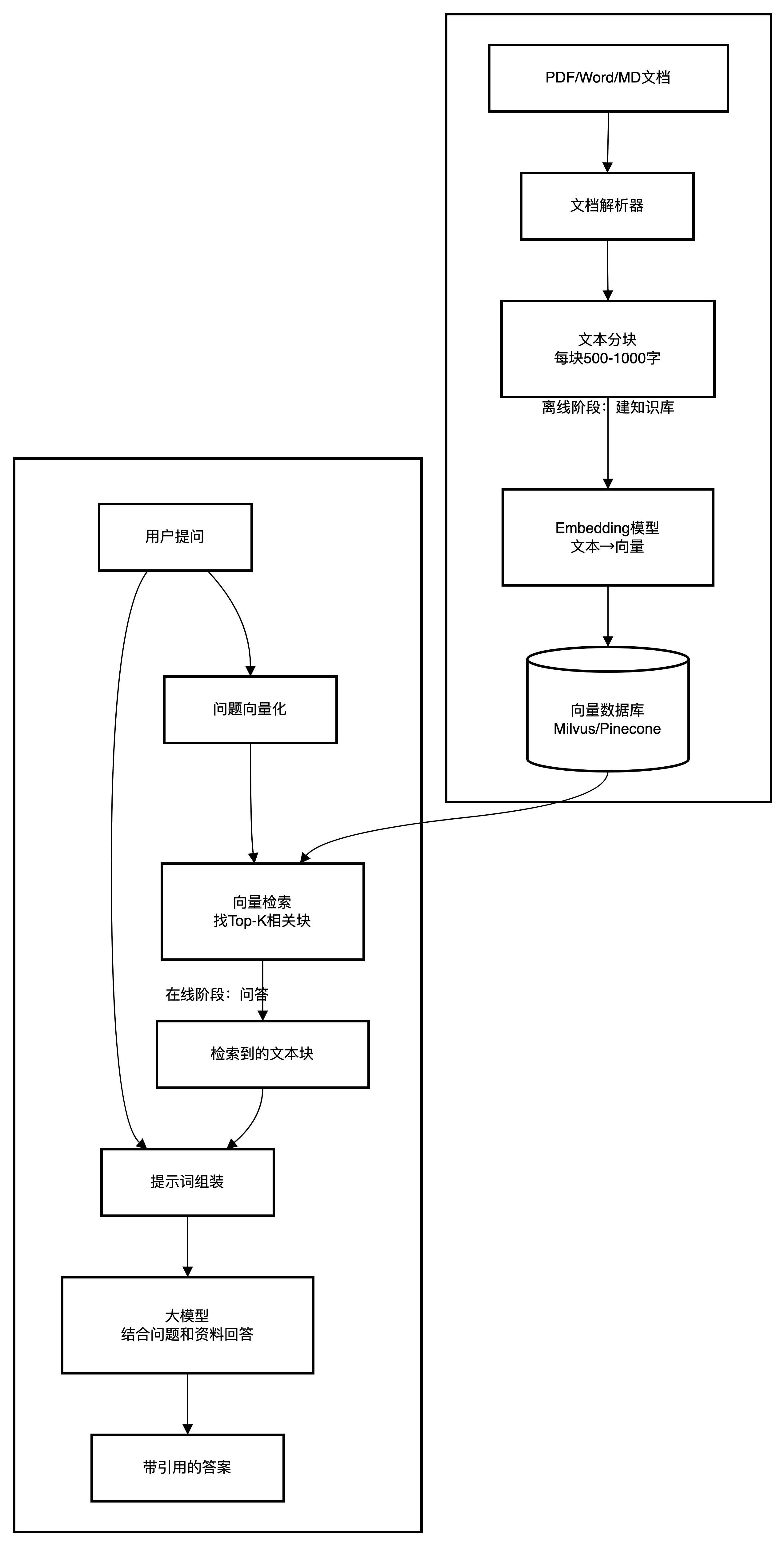
代码伪示例
// RAG 问答服务
public class RAGService {
private VectorDatabase vectorDb; // 存文档块
private EmbeddingModel embedModel; // 文本→向量
private LLMClient llm; // 大模型客户端
public String ask(String question) {
// 1. 问题转向量
float[] questionVector = embedModel.embed(question);
// 2. 检索相关文档块
List<Chunk> topChunks = vectorDb.search(questionVector, topK = 5);
// 3. 拼装提示词
String prompt = buildPrompt(question, topChunks);
// 4. 调用大模型
return llm.chat(prompt);
}
private String buildPrompt(String question, List<Chunk> chunks) {
return """
请根据以下参考资料回答问题。
如果资料中没有答案,就说“未找到相关信息”。
【参考资料】
%s
【问题】
%s
""".formatted(joinChunks(chunks), question);
}
}
使用场景
- 企业知识库问答(规章制度、产品手册、历史工单)
- 文档量大、频繁更新(加新文档即可,不用重新训练)
- 对幻觉零容忍的场景(如医疗、法律咨询)
Agent:让大模型长出“手和脚”
一句话理解
就像你写了一个主控程序,它自己决定调用哪个工具、执行哪个方法、按什么顺序做。
Agent 的核心循环
思考 → 行动 → 观察 → 思考 → 行动 → 观察 → ... → 完成
核心概念
| 术语 | 解释 | Java 类比 |
|---|---|---|
| Tool | 模型可以调用的外部能力 | 一个接口 Tool,有 execute() 方法 |
| ReAct | 推理+行动交替进行 | while 循环里先 reason() 再 act() |
| Planning | 把大任务拆成小步骤 | 递归分解,类似分治算法 |
| Memory | 记住之前说了什么、做了什么 | 维护一个对话历史 List |
交互图
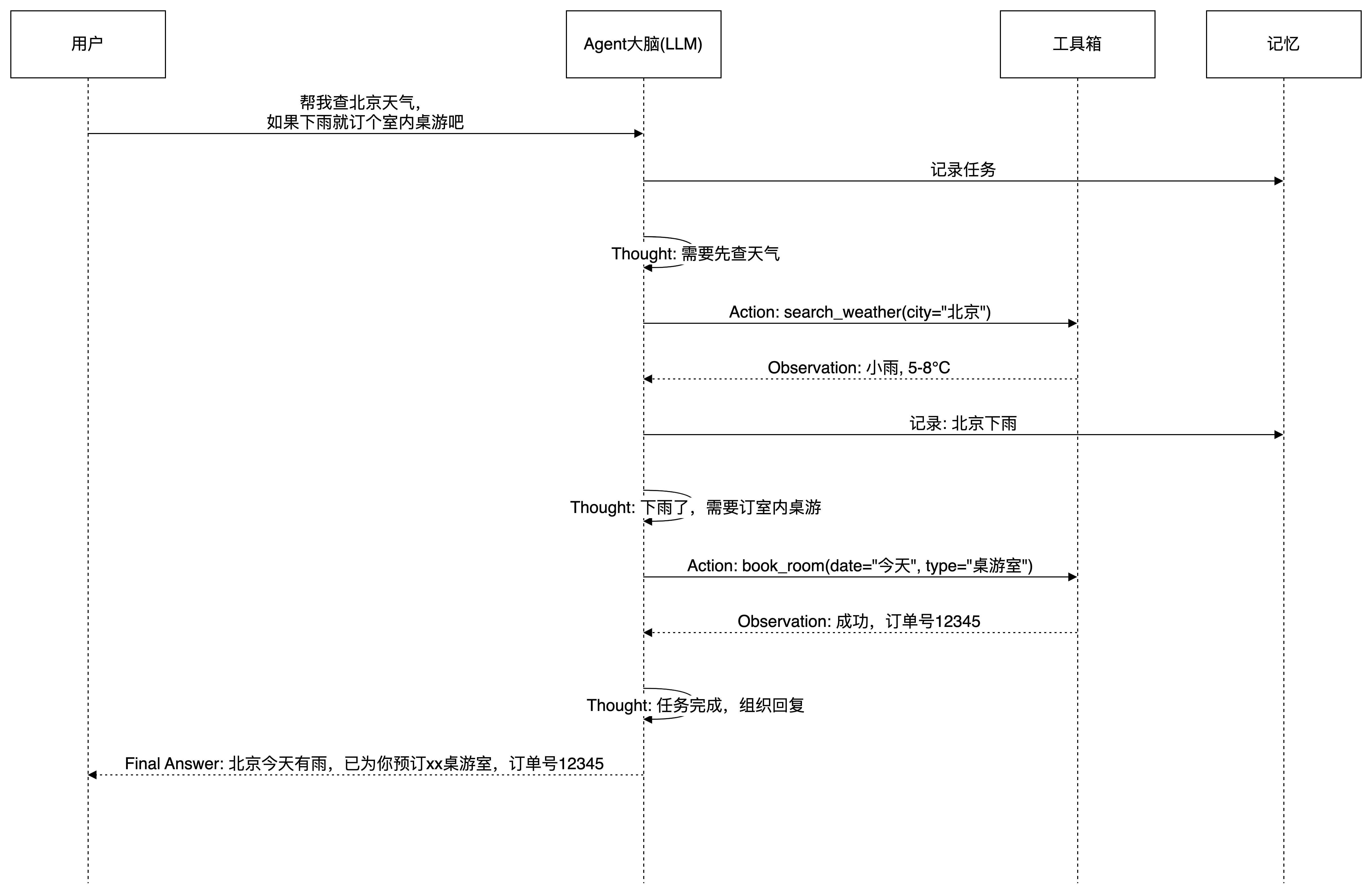
Tool 接口设计
// 工具接口
public interface Tool {
String getName();
String getDescription(); // 告诉模型这个工具是干嘛的
String execute(String input);
}
// 具体工具:天气查询
public class WeatherTool implements Tool {
@Override
public String getName() { return "search_weather"; }
@Override
public String getDescription() { return "查询城市天气,输入城市名"; }
@Override
public String execute(String city) {
// 调用真实天气API
return weatherApi.get(city);
}
}
// Agent 核心循环
public class Agent {
private List<Tool> tools;
private LLMClient llm;
public String run(String userInput) {
String thought = userInput;
int maxSteps = 10;
for (int step = 0; step < maxSteps; step++) {
// 让模型决定:是继续调用工具,还是直接回答
AgentDecision decision = llm.decide(thought, tools);
if (decision.isFinalAnswer()) {
return decision.getAnswer();
}
// 调用工具
Tool tool = findTool(decision.getToolName());
String observation = tool.execute(decision.getToolInput());
// 把观察结果喂给下一次思考
thought = "上一步结果:" + observation;
}
return "任务超时,未能完成";
}
}
使用场景
- 需要调用外部系统(数据库、API、发邮件、创建工单)
- 多步骤任务(数据分析 → 汇总 → 发送报告)
- 需要条件判断的场景(if 下雨 then 订室内 else 订户外)
微调:给大模型“开小灶”
一句话理解
就像你们团队来了个实习生,基础不错,但需要用公司真实数据训练几天,才能上手干活。
微调 vs RAG
| 对比项 | RAG | 微调 |
|---|---|---|
| 知识存储 | 外部向量库 | 写入模型权重 |
| 更新速度 | 秒级(改文档就行) | 小时级(重新训练) |
| 推理成本 | 检索+生成,略高 | 只生成,低 |
| 适合场景 | 知识频繁变动 | 固定风格/专业术语 |
核心概念(Java 类比)
| 术语 | 解释 | Java 类比 |
|---|---|---|
| SFT | 监督微调,用问答对训练 | 用标注好的训练集训练模型 |
| LoRA | 只更新一小部分参数,省显存 | 只改配置文件的几个字段,不动核心代码 |
| QLoRA | 4-bit 量化 + LoRA,更省 | 在低配机器上跑大服务 |
| 灾难性遗忘 | 学新知识忘了旧的 | 过度优化导致原有功能坏掉 |
微调原理图(LoRA 视角)
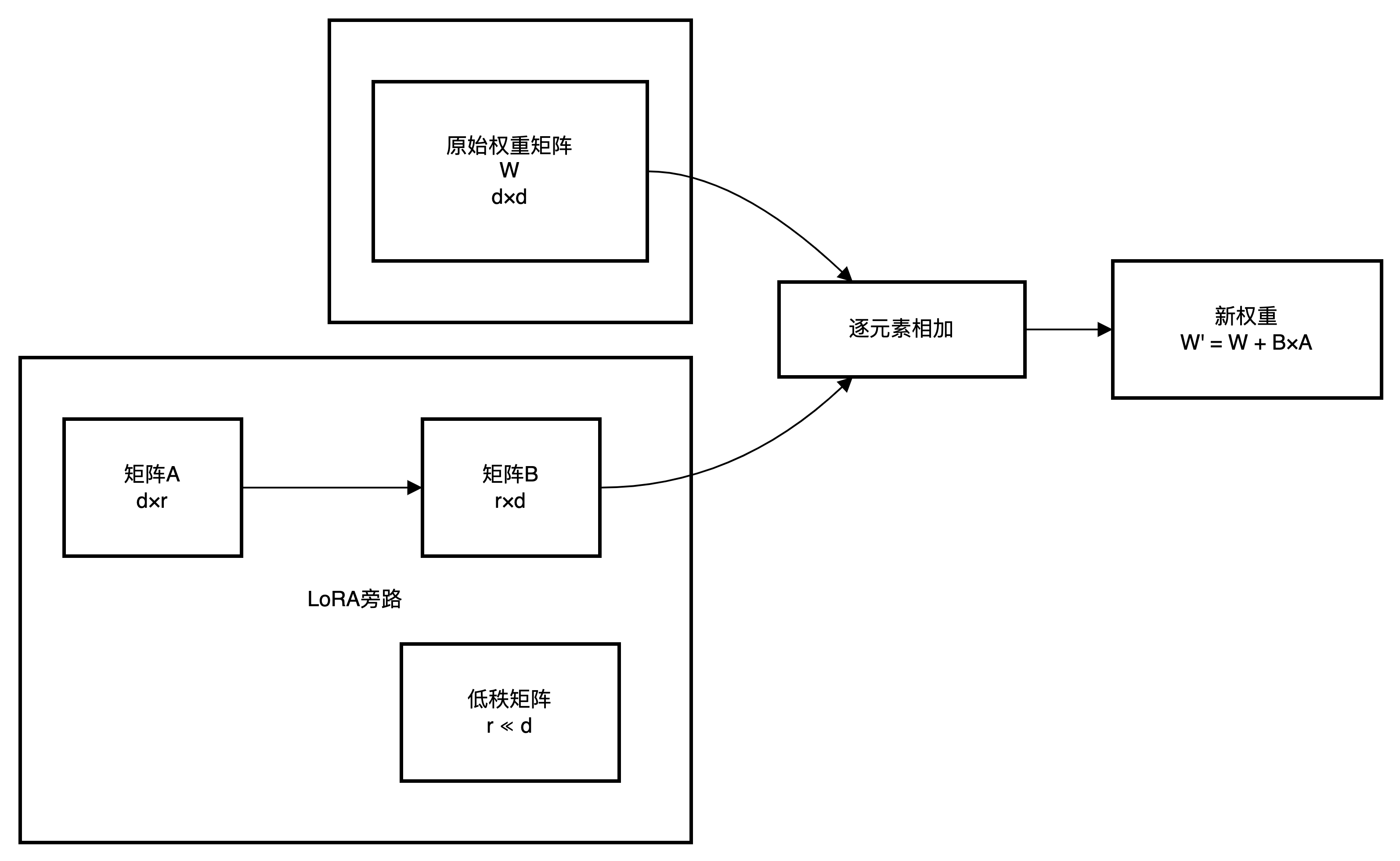
白话解释:
- 原始模型权重 W 很大(比如 70B 参数),全量微调太贵
- LoRA 在旁边加两个小矩阵 A×B,只训练这两个小东西
- 最终效果 ≈ 全量微调,但显存从 140GB 降到 24GB
使用场景
- 需要模型记住特定术语
- 需要固定输出格式(比如必须是某种 JSON 结构)
- 高频调用,希望推理速度快、成本低
- 数据隐私要求高,不能每次带外部资料
如何选择?
| 你的需求 | 推荐方案 | 为什么 |
|---|---|---|
| 快速验证想法 | 提示词工程 | 改个字就能试,零成本 |
| 公司文档问答 | RAG | 文档常更新,不改模型 |
| 需要查天气/订酒店/发邮件 | Agent | 需要调用外部工具 |
| 专业术语多(医疗/法律/财务) | 微调 | 让模型内化术语 |
| 既要专业术语,又要实时知识 | 微调 + RAG | 微调提供专业度,RAG 提供新鲜度 |
| 复杂任务(数据分析+报告+发送) | Multi-Agent | 多个 Agent 分工协作 |
典型组合架构图
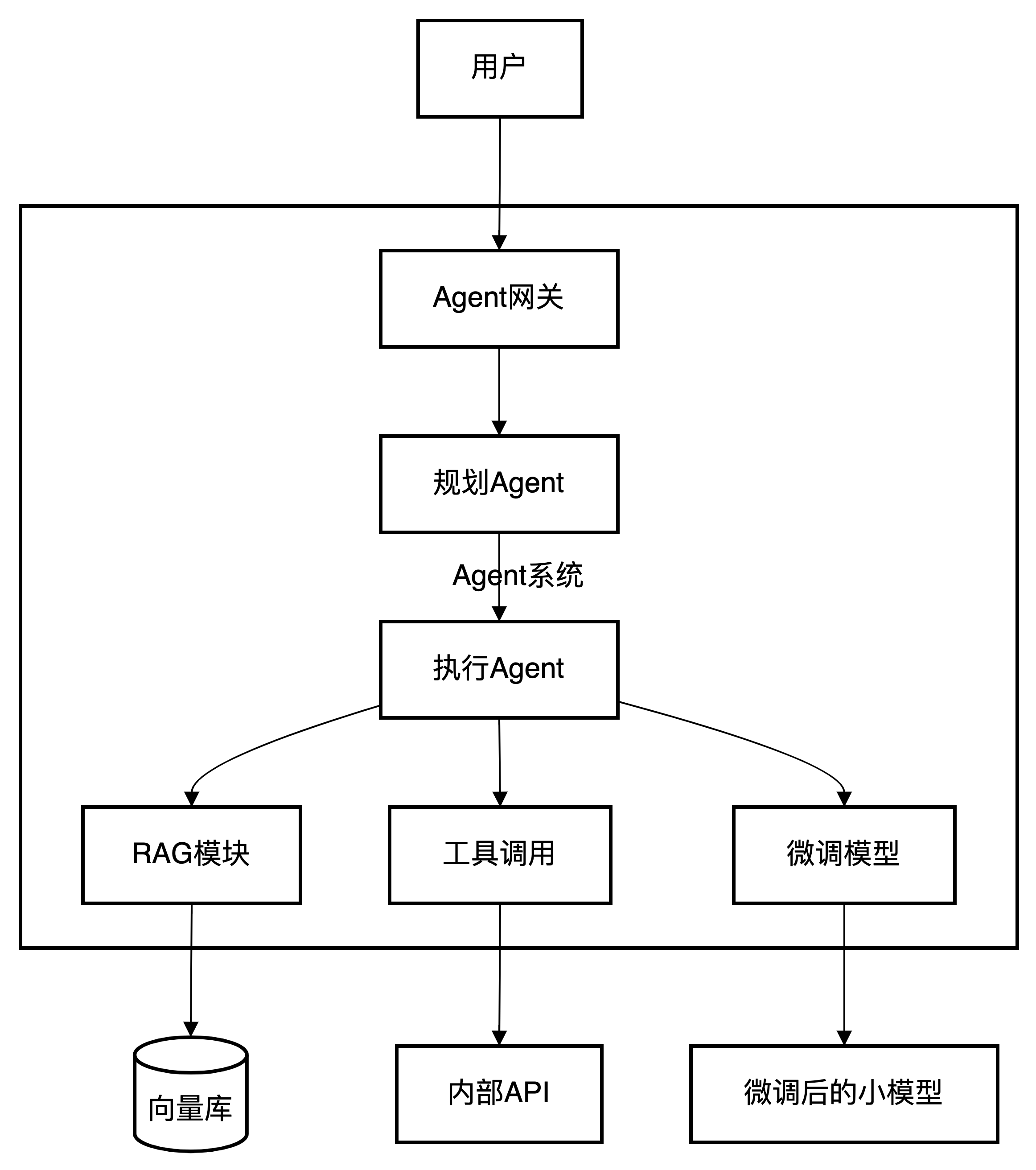
总结
把大模型当成一个特殊的依赖服务来理解:
- 提示词 = 接口文档,写清楚了才能调对
- RAG = 本地缓存 + 全文检索,让模型能查到最新数据
- Agent = 编排层 + 策略模式,让模型自己决定调用哪个工具
- 微调 = 领域适配层,相当于为模型做了定制开发

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)