Hermes Agent 自进化架构解析:从聊天助手到数字分身
摘要:Hermes Agent 试图通过闭环学习、持久化存储及架构解耦,解决当前 AI 聊天助手“无状态、无成长”的困境,使其从被动工具走向能沉淀工作习惯的成长型数字分身。
上个会话刚默契地帮你写完一套复杂的部署脚本,关掉窗口重开,它立马又患上了“赛博失忆症”,变成一个对你一无所知的陌生人。这不是某个模型的缺陷,而是当前主流 AI 对话机器人的结构性问题——它们本质上是无状态的计算器,对话结束,一切归零。
2026 年 2 月,Nous Research 发布了 Hermes Agent,发布三个月内 GitHub 星标即突破 14 万。它的定位很明确:不是一个聊天窗口,而是一个部署在你服务器上、会通过学习不断升级的数字化分身,正如 GitHub 上的项目介绍——“The agent that grows with you”。
本文将从三个维度拆解它的实现路径:自进化能力、持久化存储、架构解耦。
闭环学习:从任务执行到能力沉淀
传统 Agent 的运行模式是线性的:接收指令 → 执行任务 → 返回结果。任务完成,经验随之清零。以目前最流行的开源 Agent 框架 OpenClaw 为例,它虽然拥有庞大的 Skill 生态,但技能创建和管理仍以开发者主导为主。Hermes Agent 在这条线的末端加了一个"回路"——任务成功完成后,它会自动触发学习循环,将刚刚解决的问题凝练成一份可复用的技能文件。
整个闭环分三步:首先,Agent 从完成任务的过程中提取关键步骤和决策逻辑;然后,将这些经验写入结构化的 Skill 文件(Markdown 格式),包含触发条件、执行步骤和注意事项;最后,当再次遇到类似任务时,Agent 直接加载已有 Skill,跳过冗长的推理过程。
Skill 文件不是简单的日志记录。它使用变量模板,具备参数化复用能力。比如一份 Docker 部署 Skill 会包含 {image_name}、{tag} 等占位符,适配不同的项目场景。所有 Skill 兼容 agentskills.io 开放标准,可以在不同 Agent 之间分享和移植。
更进一步,Hermes Agent 还集成了自我进化管道。它使用由 UC Berkeley、Stanford 的研究者联合开发的 GEPA(Genetic-Pareto Prompt Evolution)进化算法,对 Skill 文件、工具描述和系统提示进行自动优化。GEPA 采用类反向传播的方式迭代提示词,其训练效率比 GRPO 等主流 RL 方法高出 35 倍以上。整个过程不需要 GPU 训练,全部通过 API 调用完成。优化结果通过 PR 形式提交,由人工审查后才合并生效,避免 Agent 在无人监督下偏离原始意图。
三层记忆系统:内置持久记忆、会话检索与外部插件
自进化能力的实现,依赖一个关键前提:记忆不能随会话结束而消失。Hermes Agent 的持久记忆系统分三层。
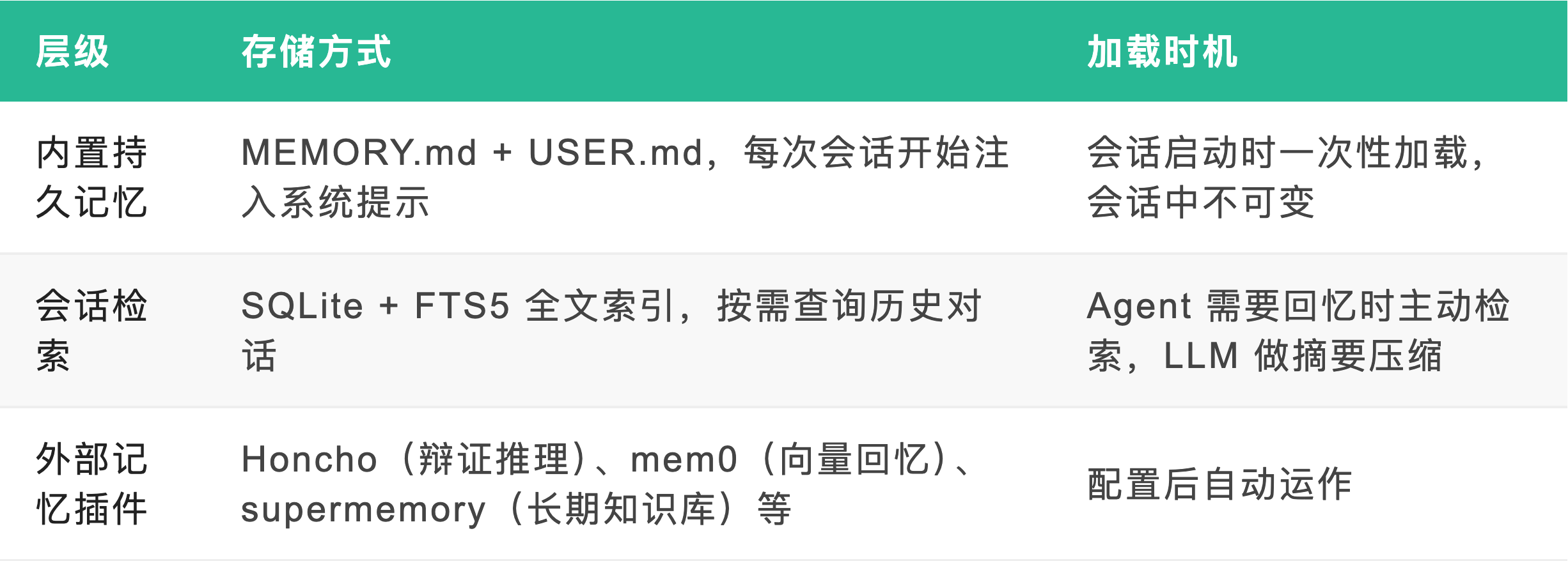
第一层记忆由两个结构化 Markdown 文件承载:MEMORY.md 和 USER.md,存储在本地 ~/.hermes/memories/ 目录下。MEMORY.md 记录 Agent 自身的工作记录——环境配置、项目约定、踩过的坑;USER.md 记录用户画像——沟通偏好、技术背景、工作习惯。Agent 通过 memory 工具自主增删改,无需人工干预。
这两个文件在每次会话启动时作为快照注入系统提示,整个会话期间保持不变。会话中 Agent 写入的新记忆只落盘,不刷新当前系统提示,这是为了保持 LLM 前缀缓存稳定,同时防止会话中途的记忆修改导致上下文波动。新记忆要等到下一轮会话才会生效。
第二层记忆是跨会话持久存储:所有 CLI 和消息会话写入 SQLite 数据库(~/.hermes/state.db),通过 FTS5 建立全文索引。当 Agent 判断需要回溯历史时,调用 session_search 接口检索相关片段,再由 LLM 做摘要压缩,与 MEMORY.md/USER.md 的快照合并,形成完整的记忆上下文。
两层记忆各有分工:静态记忆容量固定(约 1300 token),但每次会话即时可用,适合存放必须始终在线的关键事实;FTS5 检索容量无上限,但需要搜索和摘要,适合"上周我们讨论过什么"这类回溯查询。相比之下,OpenClaw 同样支持本地记忆文件,但缺少结构化的全文检索和跨会话自动召回机制,记忆的利用效率高度依赖开发者手动整理。
第三层是外部记忆插件。Hermes Agent 支持 8 个外部记忆 Provider——Honcho、Mem0、Hindsight、RetainDB 等,作为对内置记忆的补充,提供知识图谱、语义搜索、自动事实抽取和跨会话用户建模等能力。这些插件与内置记忆并行运行,不替代 MEMORY.md/USER.md,而是通过统一的 memory 接口接入,按需调用。
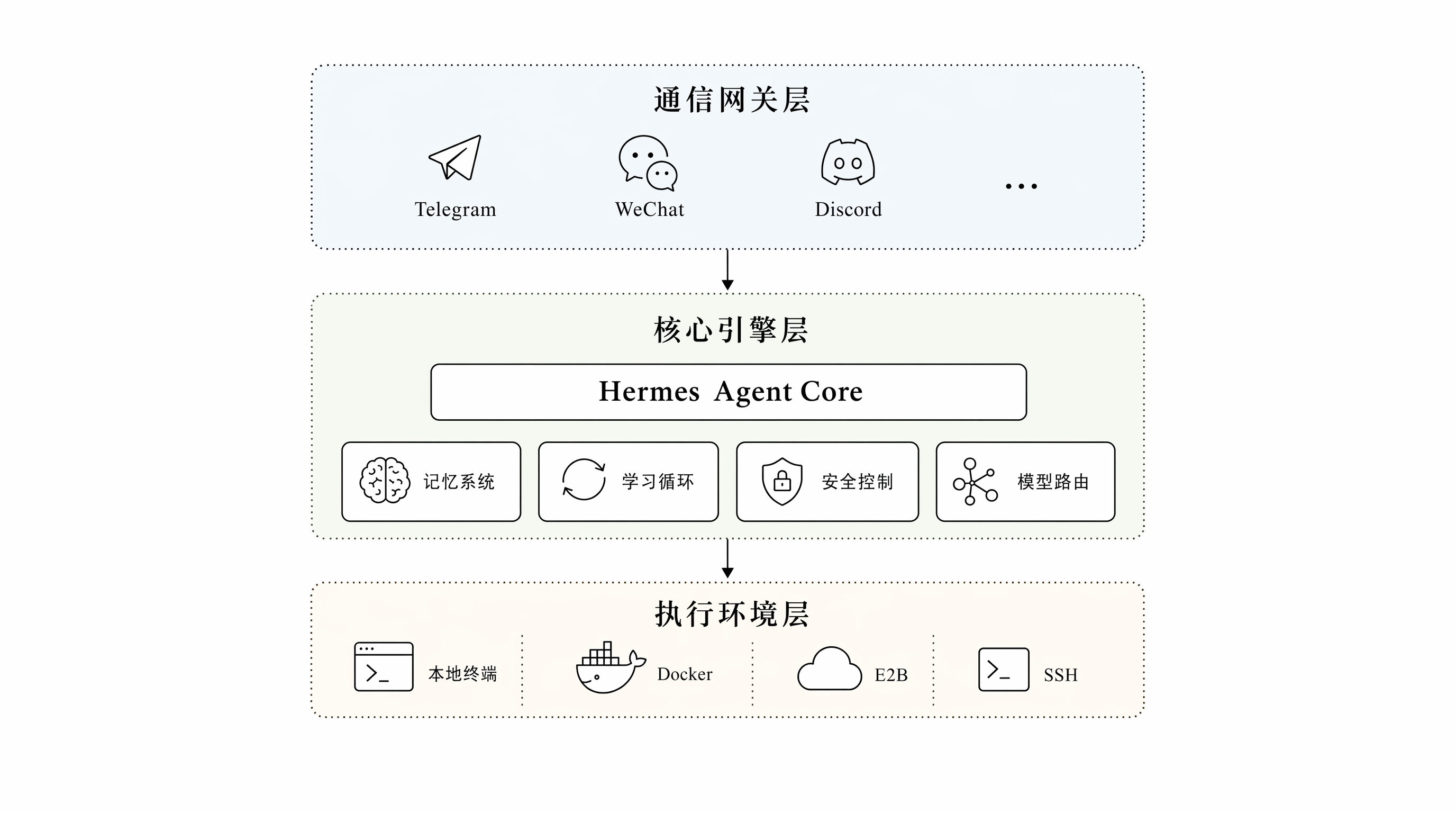
架构解耦:通信、引擎与执行的三层分离
当前多数 Agent 框架仍受限于高耦合的单体思维。当开发者试图将终端侧的 Agent 迁移至 Slack 等协作平台,或将执行环境由本地切换至云端沙箱时,往往面临底层代码的推翻重构。为了打破这种局限,Hermes Agent 转向了边界清晰的三层解耦范式:通信层负责处理多端协议差异,核心引擎层统筹会话、记忆与模型路由,执行层负责在本地或云端环境中执行具体任务。
在通信层,Hermes Agent 采用单一网关进程架构(gateway/run.py),一个进程同时处理所有平台的消息收发。目前已支持 22 个以上平台,包括 Telegram、Discord、Slack 等。各平台的格式差异,如 Telegram Markdown V2、Discord Embed、Slack Block Kit,全部在网关层消化。
此外,Hermes Agent 还支持跨平台会话接续。用户在 CLI 中执行 /handoff 后,可以把当前对话转移到 Telegram、Discord 或 Slack 的主频道里,同时保留同一个会话 ID 和完整历史。其核心原理是基于中心化的 SQLite 数据库统一管理所有平台的会话状态和消息历史,并通过 Handoff 机制在不同适配器之间传递活跃会话的控制权。
在核心引擎层,模型调用被抽象成统一路由。Hermes Agent 以 OpenAI 兼容 API 作为统一接口标准,可通过 OpenRouter 接入 200 多个模型,也支持 Ollama、vLLM 等本地推理方案。切换模型只需要一条 hermes model 命令,不必改通信入口或执行后端。
在外部扩展上,引擎层全面接入了开放生态。首先是 MCP 双向集成:既能化身 Server 赋能 Cursor,也能作为客户端无缝调用 GitHub、Notion 等海量现成 MCP 服务。其次是模块化工具集:内置多个工具集,涵盖约 70 个具体的原子工具,开发者仅需继承基础类即可快速扩展自定义工具,引擎自动识别加载。最后,其 Skill 格式严格遵循 agentskills.io 规范,让沉淀的经验具备跨框架迁移的能力。
在执行层,Hermes Agent 提供六种终端后端:Local(本地直接执行)、Docker(容器沙箱隔离)、SSH(远程服务器操控)、Daytona(团队协作 Serverless)、Singularity HPC(高性能计算集群)、Modal Serverless(按需唤醒,空闲近零成本)。从本地开发到生产集群,同一套 Agent 代码无需改动即可切换运行环境。
写在最后
Hermes Agent 的价值不在于某个单点功能的突破,而在于它把自我进化,持久记忆和架构解耦整合到了同一个框架里,并且给出了工程层面的完整方案。
闭环学习让它越用越熟,持久记忆让经验不再清零,架构解耦让它能自由穿梭于不同的模型与终端之间。这三个维度的咬合,标志着 AI Agent 正在跨越一道关键门槛——它不再是一个需要你每次重新配置上下文的“被动工具”,而是一个能够沉淀你的工作习惯、跟随你的业务复杂度一起成长的“数字分身”。
相关资源

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 17
17 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)