我用 Tushare + Codex,把本地股票数据库补上了前后复权行情(已开源)
🔗 开源项目地址:https://github.com/zer0quant/zer0share
这是本地股票数据系统系列的第二篇。上一篇讲的是怎么用 Tushare 搭建基础数据同步系统,这一篇继续补上复权行情。
上一篇文章里,我用 Tushare + Claude Code 搭了一套本地股票数据同步系统,先把最基础的几类数据跑通了:
- 股票基础信息
- 交易日历
- 日线行情
- 本地 Parquet 存储
- CLI 同步入口
但上一篇留下了一个很重要的问题:日线行情默认是不复权的。
如果只是看看某一天的开盘价、收盘价,不复权数据当然没问题。但如果要做 K 线分析、计算历史收益率、做动量因子、做回测,不处理复权就很容易出问题。
所以这篇文章就接着往下讲:怎么在本地数据系统里合成前复权和后复权行情。
一、为什么日线行情不能直接拿来做研究?
股票价格不是一条天然连续的时间序列。
因为上市公司会发生各种公司行为,比如:
- 现金分红:除息日当天,股价会下调对应的股息金额;
- 送股 / 转增股:股本变大,每股价格会按比例下降;
- 配股:用低于市价的价格增发,也会影响除权后的价格。
这些变化并不一定代表公司价值真的发生了同等幅度的变化。很多时候,它只是股本结构或者现金分配方式变化带来的价格调整。
如果不做复权,历史 K 线图上就会出现很多看起来很吓人的“跳空缺口”。更麻烦的是,收益率也会失真。
比如一只股票昨天收盘 10 元,今天除息 0.5 元,除息后的参考价变成 9.5 元。表面上看价格跌了 5%,但如果你持有这只股票,其实你同时拿到了 0.5 元现金分红。这个“跌幅”并不是真正意义上的市场亏损。
所以,复权要解决的核心问题就是:
把分红、送股、转增、配股等公司行为造成的价格跳变消掉,让历史价格在同一套口径下可比。
二、前复权和后复权,到底差在哪?
常见的复权方式主要有两种:前复权和后复权。
简单说:
| 前复权 | 后复权 | |
|---|---|---|
| 基准点 | 以最新价格为基准,向历史调整 | 以最早价格为基准,向未来调整 |
| 最新价格 | 和当前市场价格一致 | 通常和当前市场价格不同 |
| 历史价格 | 会被调整 | 早期价格相对保持原始基准 |
| 常见用途 | 看 K 线、和当前价格对比 | 收益率计算、因子研究、回测 |
前复权更适合看图,因为最新价格和真实市场价格一致。你打开行情软件看一只股票的历史走势,通常看到的就是前复权。
后复权更适合做研究,因为它把后面的价格按复权因子一路抬上去,更方便保持长期收益序列的连续性。
但不管是前复权还是后复权,背后的关键都不是“价格加减多少”,而是一个更重要的东西:
复权因子。
三、复权为什么不能简单做减法?
一开始很容易产生一个直觉:既然每股分红 0.5 元,那把除权日前的所有历史价格都减掉 0.5 元,不就行了吗?
这个想法看起来很自然,但它会破坏收益率。
假设除权日前有两个历史价格:
- 某天价格是 5 元
- 后来涨到 10 元
原始收益率是 100%。
如果都减掉 0.5 元,就变成:
- 4.5 元
- 9.5 元
这时候收益率变成了 111.11%。也就是说,简单平移会改变历史价格之间的比例关系。
而复权真正要保持的是:
历史价格之间的收益率关系不变。
所以复权不能靠加减法,只能靠等比例缩放。
用公式表达就是:
P~=f⋅P\tilde{P} = f \cdot PP~=f⋅P
其中:
- PPP 是原始价格
- P~\tilde{P}P~ 是复权后的价格
- fff 是复权因子
如果除权日前一天收盘价是 P1P_1P1,除权后参考价是 P2P_2P2,那么这次单次调整因子可以理解为:
f=P2P1f = \frac{P_2}{P_1}f=P1P2
如果历史上发生过多次除权除息,就把这些因子按时间累乘起来。
这也是为什么做复权行情时,我更倾向于存原始日线行情 + 复权因子,而不是直接存一张“前复权价格表”。
因为每次发生除权除息后,前复权的历史价格都可能随着最新基准重新调整。如果提前把前复权价格落盘,后面就要不断重算和覆盖历史数据,维护成本反而更高。相比之下,原始价格和复权因子更稳定,查询时再按口径计算会更干净。
四、Tushare 的日线行情里,其实已经藏了一个重要线索
先看 Tushare 的日线行情输出:

这里面有一个很关键的字段:pre_close。
这个字段不是简单的“昨天真实收盘价”,而是复权口径下的昨收价。也就是说,如果今天发生了除权除息,pre_close 会使用调整后的昨收价,让当天的涨跌幅消除除权缺口的影响。
所以我们可以用一个很直接的方式检查是否发生了复权调整:
如果昨天的
close和今天的pre_close不一致,通常就说明中间发生了除权除息等调整。
进一步地,也可以从这里推导出一次除权除息带来的单次前复权调整因子:
单次前复权调整因子=今天的pre_close昨天的close单次前复权调整因子 = \frac{今天的 pre\_close}{昨天的 close}单次前复权调整因子=昨天的close今天的pre_close
这个因子的作用,是把除权除息之前的历史价格按比例往下调整。沿着时间往回看,把后面发生过的这些调整因子累乘起来,就能得到某一天对应的累计前复权因子。
不过,Tushare 其实还提供了一个专门的 adj_factor 复权因子接口。这里就需要先确认一件事:Tushare 返回的这个因子,到底是前复权累计因子,还是后复权累计因子?
我一开始不确定这个因子到底是什么口径,于是先让 Claude Code 帮我做了一版本地计算逻辑,再拿它和 Tushare 返回的因子做对比。

验证结果基本能对上:
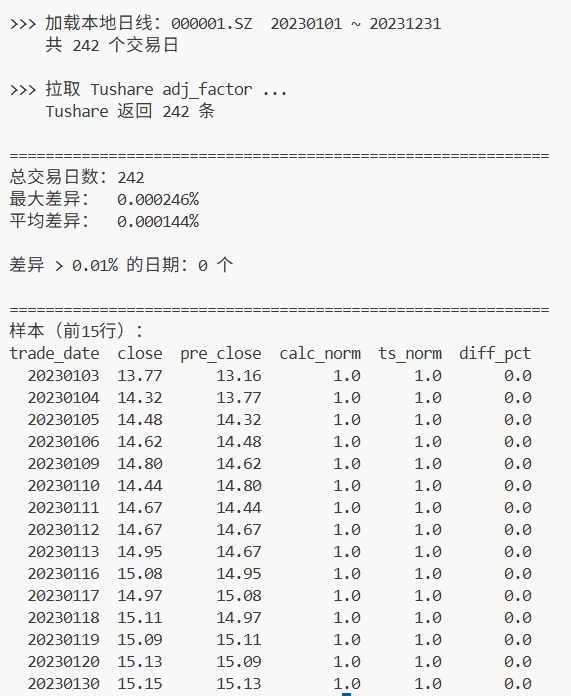
这说明一件事:Tushare 的复权因子可以直接看作后复权累计因子。
有了这个结论,后面的工程实现就清晰多了。
五、已知后复权因子,怎么合成前复权因子?
现在我们已经有了 Tushare 的后复权因子。问题变成:
能不能只用后复权因子,自己算出前复权因子?
答案是可以,而且公式非常简单。
设第 iii 个交易日的原始价格为:
PirawP_i^{raw}Piraw
后复权因子为:
fipostf_i^{post}fipost
前复权因子为:
fipref_i^{pre}fipre
那么:
Pipost=Piraw×fipostP_i^{post} = P_i^{raw} \times f_i^{post}Pipost=Piraw×fipost
Pipre=Piraw×fipreP_i^{pre} = P_i^{raw} \times f_i^{pre}Pipre=Piraw×fipre
这两条式子里,原始价格是同一个。区别只在于乘上的因子不同。
把两条式子相除,可以把原始价格消掉:
PiprePipost=Piraw×fiprePiraw×fipost=fiprefipost\frac{P_i^{pre}}{P_i^{post}} = \frac{P_i^{raw} \times f_i^{pre}}{P_i^{raw} \times f_i^{post}} = \frac{f_i^{pre}}{f_i^{post}}PipostPipre=Piraw×fipostPiraw×fipre=fipostfipre
也就是说,前复权价格和后复权价格之间的比例,等于前复权因子和后复权因子之间的比例。
接着看关键点:前复权和后复权本质上来自同一组除权除息事件。每发生一次除权除息,两套因子都会按照同一件事情做比例调整,只是选择的基准点不同。
所以,对同一只股票来说,前复权因子和后复权因子之间不会每天随机变化,它们之间只差一个固定比例。我们把这个比例记为常数 CCC:
fiprefipost=C\frac{f_i^{pre}}{f_i^{post}} = Cfipostfipre=C
于是:
fipre=fipost×Cf_i^{pre} = f_i^{post} \times Cfipre=fipost×C
现在问题就变成了:这个常数 CCC 到底是多少?
前复权的定义是:最新一天价格不调整。
也就是说,最新交易日 nnn 的前复权因子应该是 1:
fnpre=1f_n^{pre} = 1fnpre=1
把最新交易日代入刚才的式子:
fnpre=fnpost×Cf_n^{pre} = f_n^{post} \times Cfnpre=fnpost×C
因为 fnpre=1f_n^{pre} = 1fnpre=1,所以:
1=fnpost×C1 = f_n^{post} \times C1=fnpost×C
也就得到:
C=1fnpostC = \frac{1}{f_n^{post}}C=fnpost1
再把 CCC 代回去,前复权因子就可以写成:
fipre=fipostfnpost\boxed{f_i^{pre} = \frac{f_i^{post}}{f_n^{post}}}fipre=fnpostfipost
翻译成人话就是:
每一天的前复权因子 = 当天后复权因子 / 最新一天后复权因子。
于是:
- 后复权价格 = 原始价格 × Tushare 复权因子
- 前复权价格 = 原始价格 × 前复权因子
- 前复权因子 = Tushare 复权因子 / 最新 Tushare 复权因子
这个公式也和 Tushare 文档里的复权行情合成逻辑一致。

到这里,数学部分就够用了。接下来要做的就是把它落到本地数据系统里。
六、工程上我没有存复权价格,而是存复权因子
做工程实现时,有两种方案。
第一种是直接把前复权行情、后复权行情都算好,然后分别落盘。
第二种是只存原始行情和复权因子,查询时再动态合成前复权 / 后复权价格。
我最后选的是第二种。
原因很简单:复权价格是派生数据,复权因子才是基础数据。
如果把前复权、后复权都提前存下来,会有几个问题:
- 存储冗余;
- 最新交易日变化后,前复权历史价格可能整体变化;
- 后续如果修正复权因子,需要重算大量价格表;
- 查询口径容易越来越多,系统复杂度会被放大。
所以更干净的设计是:
- 同步原始日线行情;
- 同步 Tushare 复权因子;
- 查询时根据
adj参数实时合成价格。
这样系统里保留的是更稳定、更底层的数据,前复权和后复权只是查询层的一种输出口径。
七、先把复权因子同步进本地数据系统
有了设计之后,第一步就是增加复权因子同步模块。
这个部分不需要重新发明一套架构,直接沿用上一篇文章里已经搭好的同步系统:
- 数据源还是 Tushare;
- 存储还是本地 Parquet;
- 同步方式还是 CLI;
- 增量逻辑仍然围绕交易日历展开;
- 文档和测试继续补齐。
我把需求交给 Claude Code,让它按现有项目规范补一个 adj_factor 模块。

实现过程比较顺:

全量同步大概跑了 1 小时左右,所有复权因子同步完成。
同步模块完成后,我又让它把文档补上。
到这里,本地数据系统里就多了一类非常关键的基础数据:复权因子。
八、再实现一个对标 Tushare 的本地查询接口
同步只是第一步。真正要用起来,还需要查询接口。
我的查询层主要用 DuckDB 去读本地 Parquet 文件,包括:
- 交易日历
- 股票基础信息
- 日线行情
- 复权因子
这里我做了一个刻意的设计:接口命名尽量对标 Tushare。
比如 Tushare 里有 daily、stock_basic、trade_cal 这些接口,本地查询层也尽量保持相近的调用方式。
这么做有两个好处:
第一,自己迁移成本低。之前怎么调 Tushare,后面就可以用类似方式调本地数据。
第二,后续更适合 AI agent 接管。如果本地接口和 Tushare 的接口形态接近,那么未来基于 Tushare 官方 skill 做本地化适配,或者让 agent 自动查询本地数据时,都不需要重新理解一套全新的命名体系。
这一步我顺手试了一下 GPT-5.5,让 Codex 先设计查询层方案。

方案出来后,又让它补了 example,方便我手工验证查询结果。
测试跑下来也没什么问题:
九、最后补上前复权和后复权行情查询
最后一步,就是让本地查询接口支持复权行情。
我参考了 Tushare 的复权行情文档,也顺手让 Codex 去看 Tushare SDK 源码,尽量把本地行为做得和 Tushare 接近。
最终查询层支持了类似这样的口径:
adj=None:返回不复权行情;adj="qfq":返回前复权行情;adj="hfq":返回后复权行情。
内部逻辑其实就是前面推导的那几条:
后复权价格=原始价格×后复权因子后复权价格 = 原始价格 \times 后复权因子后复权价格=原始价格×后复权因子
前复权因子=当天后复权因子最新后复权因子前复权因子 = \frac{当天后复权因子}{最新后复权因子}前复权因子=最新后复权因子当天后复权因子
前复权价格=原始价格×前复权因子前复权价格 = 原始价格 \times 前复权因子前复权价格=原始价格×前复权因子
然后再把开高低收、昨收、涨跌额、涨跌幅这些字段按对应口径处理好。
为了验证查询结果,我又补了 examples 和测试。跑完之后,本地已经可以查询:
- 交易日历
- 股票基础信息
- 不复权日线行情
- 前复权日线行情
- 后复权日线行情
到这一步,日线级别研究常用的数据底座就比较完整了。
十、这次补复权,我最大的体感
复权这件事,表面上看只是“把价格调整一下”。
但真正放进数据系统里,它会牵出一整套工程判断:
- 到底存价格,还是存因子?
- 前复权价格是不是应该提前落盘?
- 查询接口要不要对标 Tushare?
- 最新交易日变化后,历史前复权价格怎么处理?
- 本地数据和上游数据如何验证一致性?
我这次最后形成的判断是:
本地数据系统应该尽量存基础事实,而不是过早存派生结果。
原始行情是基础事实,复权因子也是基础事实。
前复权价格和后复权价格,则是基于这些基础事实计算出来的不同视角。
这样设计之后,系统会更轻,也更容易扩展。后面如果继续加指数、ETF、分钟线、因子数据,整体思路也可以保持一致:
同步层负责把基础数据沉淀下来,查询层负责按使用场景组合和计算。
这也是我做这个本地数据系统时越来越明确的一点。
十一、写在最后
到这里,这套基于 Tushare 的本地股票数据系统已经从“能同步日线行情”,往前走了一步:
- 支持同步复权因子;
- 支持用 DuckDB 查询本地 Parquet 数据;
- 支持不复权、前复权、后复权三种行情口径;
- 查询接口尽量对标 Tushare;
- 已经可以支撑一部分日线级别动量因子、回测和策略验证。
这篇文章补上的不是一个孤立功能,而是数据底座里非常关键的一块。
没有复权,很多历史价格分析都会失真。
有了复权因子和本地查询层,后面再做因子研究、回测,或者让 AI agent 直接和本地数据交互,就会顺很多。
下一篇,我会继续讲讲怎么用 OpenClaw / Hermes Agent 和这套本地数据系统做交互。
如果这篇文章对你有帮助
- ⭐ Star 一下项目:https://github.com/zer0quant/zer0share
- 关注公众号,后续继续更新本地数据系统和 AI agent 交互
- 有想法、有 bug、有功能建议,欢迎在 GitHub 提 Issue 或直接 PR
我们下篇见。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)