新加坡国立大学最新研究:冻结Backbone,激活潜能:解耦多模态模型中的潜变量优化与利用
训多模态大模型(MLLM)的时候,明明模型参数越来越大,为啥还是经常『看图说话』翻车,甚至出现幻觉?最近翻了篇论文,发现这可能是个优化层面的『Bug』。作者发现,在联合训练中,模型为了走捷径,会有意无意地“压抑”中间过程的视觉推理能力。
作者把这个现象命名为 “沉默的视觉潜变量”(Silenced Visual Latents)。更绝的是,他们提出一个只在推理阶段动动手脚的骚操作,不改模型参数,就能『唤醒』这些被压抑的潜能,在一些任务上性能直接飙升。

现在主流的潜变量推理方法(Latent Visual Reasoning),基本都是在训练时,把一些连续的“视觉潜变量”(可以理解为模型思考的中间步骤)和最终的答案预测放在一起联合优化。
但这里有个极其头疼的问题:模型的自回归预测目标(Autoregressive Objective)天生喜欢走捷径。它发现直接看原始图片就能猜个八九不离十,干嘛还费劲去理解你那些复杂的潜变量呢?
结果就是,潜变量虽然在训练中被优化的越来越好,但在最后做决策时却被“晾在一边”,逐渐沦为“传声筒”,失去了实际的推理作用。这篇论文就问了:能不能把“优化潜变量”和“利用潜变量”这两个互相打架的目标解耦开?顺着这个思路,他们搞了个新框架。
为了帮助大家更好地研究,我整理了这篇论文的完整架构图 + 核心算法和零上手复现教程。
关注公众号“LLM炼丹炉”,回复“B460”
核心方法拆解
这篇论文的核心思路非常直给:既然训练时联合优化会让两个目标打架,那干脆分开。模型参数在训练好后就冻结,只在推理(Inference)的时候,针对每一个具体问题,实时地去优化那一小撮视觉潜变量。
整个过程分为两步,像一套组合拳:先“预热”,再“强化”。
3.1 第一阶段:视觉潜变量“预热”(Visual Latent Warm-up)
这个阶段的目标是提升潜变量自身的“语义质量”,让它包含更多和问题相关的信息。
简单说,就是给潜变量“划重点”。具体做法是,基于用户的问题(Query),计算图片里每个图像块(Patch)和问题的相关性分数。然后,把最相关的几个图像块作为“正样本”,最不相关的几个作为“负样本”。
接下来,通过一个对比学习的目标,把每个潜变量往相关的图像块“拉”,同时把它从不相关的图像块上“推”开。为了防止所有潜变量都学成一样的东西,论文还设计了一个分块(chunk-wise)策略,保证每个潜变量关注不同的视觉区域。
这一步操作下来,潜变量就变得“见多识广”且“立场分明”了,为第二阶段的强化利用打好了基础。
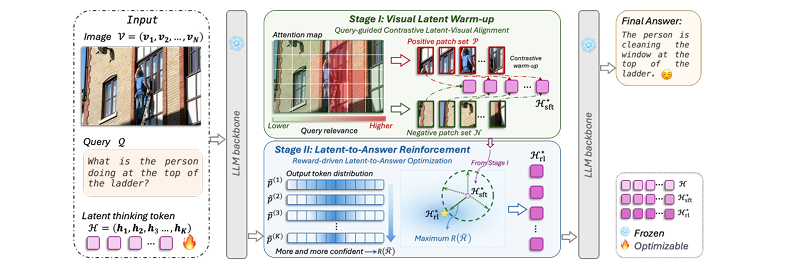
Figure 4,展示两阶段优化流程
3.2 第二阶段:潜变量到答案的“强化”(Latent-to-Answer Reinforcement)
“预热”好的潜变量虽然质量高了,但模型还是可能不用它。第二阶段的目标就是“按着模型的头让它用”。
这里的玩法非常巧妙,作者设计了一个叫 “置信度递进奖励”(Confidence-Progression Reward) 的机制。这个机制的灵感来源很符合直觉:就像我们思考问题,一步步下来,思路会越来越清晰,结论会越来越确定。
对应到模型里,就是潜变量序列从第一个到最后一个,模型在每个位置预测下一个词的“确定性”应该越来越高。这个“确定性”可以用信息熵(Entropy)来衡量,熵越低,代表分布越集中,模型越确定。
所以,奖励函数被设计成这样:
其中, 是第 个潜变量位置的预测熵。这个公式的意思是,只有当后一个潜变量的预测熵比前一个低时,才给予正奖励。
通过一个简单的随机梯度估计器,不断微调潜变量,让这个奖励最大化。这样一来,模型就被激励着必须沿着潜变量这条路走下去,并且每走一步都得更“想清楚”一点,从而杜绝了走捷径绕开潜变量的可能。
这个两阶段优化思路,其实也可以迁移到自己的项目里。想拿这个框架用在自己的数据集上?文末有完整的优化流程伪代码,可以拿来即用。
实验亮点
废话不多说,直接上数据。
4.1 主实验结果
这套操作到底有多猛?在 8 个公开基准上,吊打了一众CoT(思维链)和之前的潜变量推理方法。
就拿Qwen2.5VL-7B做底座模型来看:
-
在 IQTest 数据集上,比纯模型直接高了 8.66 个点。
-
在 RR(相对反射率)和 MMVP 这种需要精细视觉感知的任务上,也分别提升了 5.88 和 4.33 个点。
-
更离谱的是,在另一个底座模型R1 OneVision-7B上,IQTest任务的性能直接从 22.67% 飙到 36.67% ,暴涨了 14 个点。
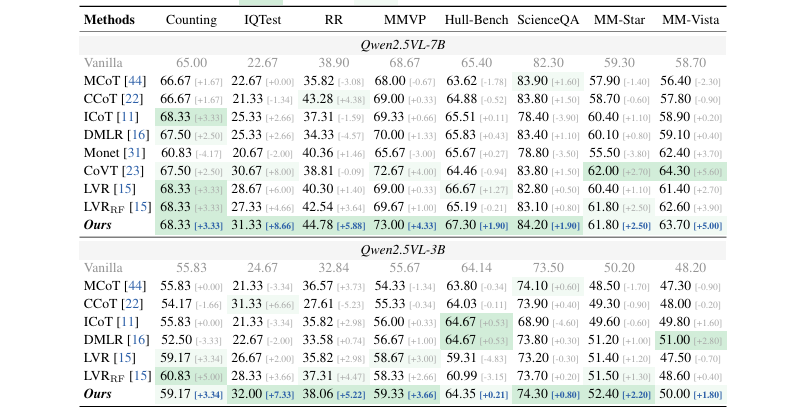
Table 1,主实验对比表,高亮Ours方法和Vanilla的对比增益
4.2 消融实验一句话
消融实验证明,两个阶段都功不可没。只用第一阶段“预热”,性能就有明显提升;加上第二阶段“强化”,效果更上一层楼,证明了“提升质量”和“强制使用”缺一不可。
4.3 效率如何?
有人可能会担心,推理时加了这么多优化步骤,会不会慢成PPT?论文也考虑到了这点。他们计算了“效率比”(性能增益/额外生成的token数),结果显示,该方法的效率比远高于其他所有需要生成额外token的推理方法。说明这是个高性价比的买卖。
启示与判断
这篇论文看完,有几个判断和大家分享。
后续判断:我觉得「推理时优化」(Inference-time Optimization)这个方向可能会成为一个新热点。过去大家都在卷模型规模和训练数据,现在开始探索如何在不重新训练的情况下,让现有模型在特定任务上“超常发挥”。这为很多算力有限的团队提供了一条新路。
实际应用建议:如果你的多模态任务卡在推理效果上,尤其是那些需要复杂视觉推理的场景,不妨试试这个思路:冻结主模型,只在推理时针对性地优化中间表达。这个框架是模型无关的,可以即插即用。
争议性观点:当然,这种“临阵磨枪”式的优化也有争议。有人会觉得它增加了推理的开销,不够“优雅”。但相比于动辄上百张卡重新训练一个模型,这种“用计算换效果”的trade-off,在很多场景下可能香得很。 毕竟,效果才是硬道理。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)