深度学习论文: Per-Pixel Classification is Not All You Need for Semantic Segmentation
深度学习论文: Per-Pixel Classification is Not All You Need for Semantic Segmentation
Per-Pixel Classification is Not All You Need for Semantic Segmentation
PDF: https://arxiv.org/pdf/2107.06278
PyTorch代码: https://github.com/shanglianlm0525/CvPytorch
PyTorch代码: https://github.com/shanglianlm0525/PyTorch-Networks
1 概述
现有的语义分割方法将分割视为逐像素的分类,本文提出了MaskFormer,把分割转化为预测一系列的mask以及为这些mask预测一个global类别,这样可以很方便地将语义分割与实例分割、全景分割等任务统一起来。实验证明MaskFormer在语义分割与全景分割任务上达到了SOTA。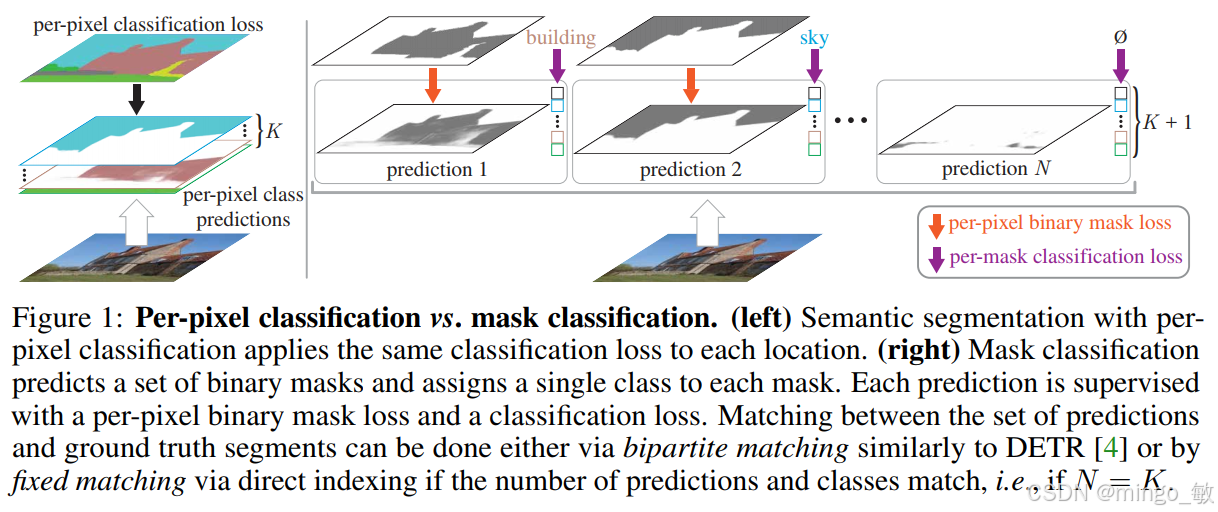
2 MaskFormer
MaskFormer——一种基于掩码分类的新模型。该模型输出 N 个概率-掩码对,每个对包含一个类别概率分布和一个二值掩码。模型整体由三个模块组成:
- 像素级模块:提取逐像素的特征嵌入,用于后续生成二值掩码。
- Transformer 模块:利用堆叠的 Transformer 解码层,计算 N 个代表不同图像片段的嵌入向量。
- 分割模块:根据上述两类嵌入,产生最终的预测结果(即 N 个概率-掩码对)。在推理阶段,这些概率和掩码会被组合成最终的分割输出。
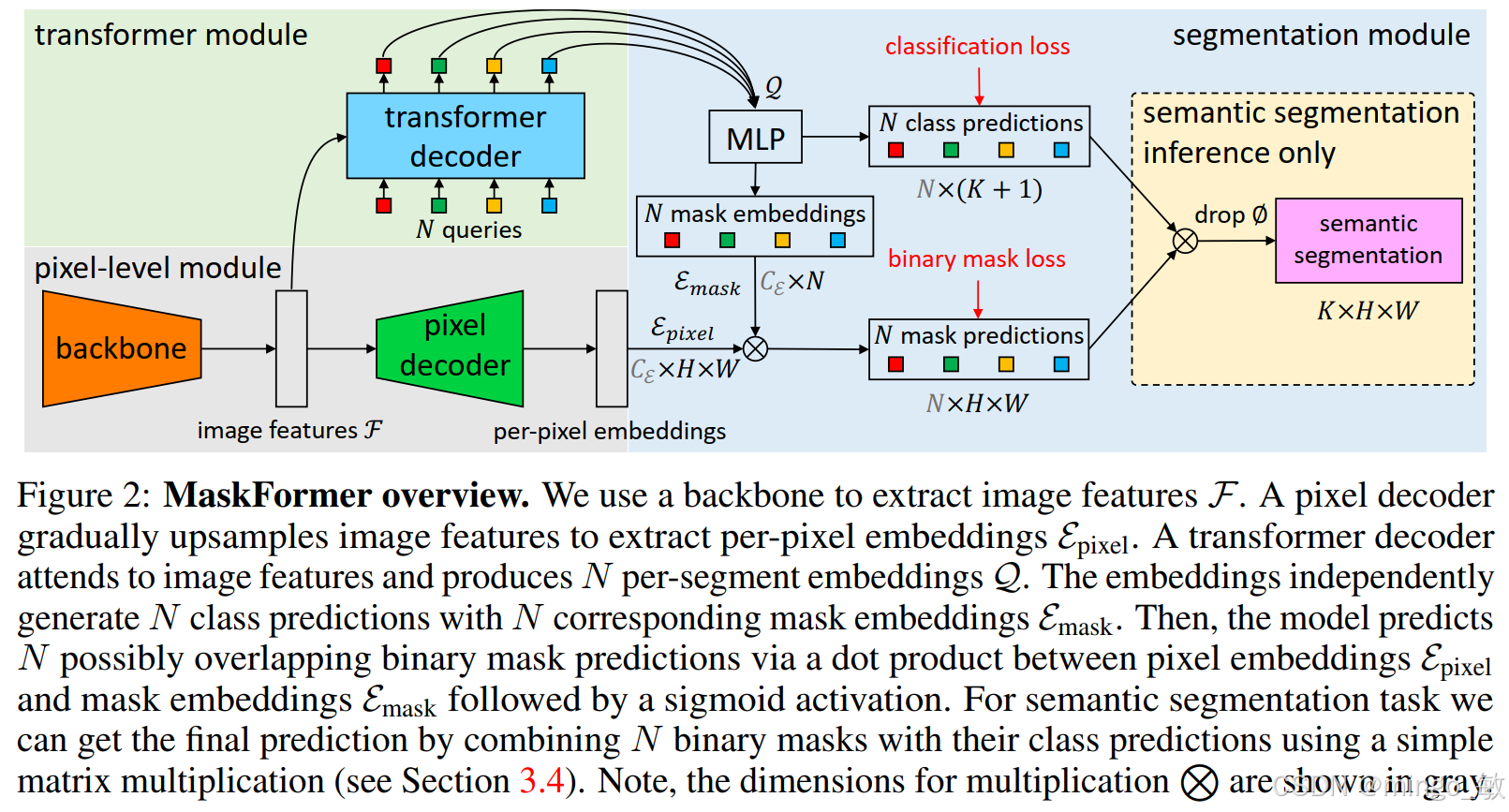
像素级模块
该模块以原始图像为输入。首先,一个主干网络生成一张低分辨率的特征图,其通道数和下采样步长取决于具体网络结构(本文中步长设为 32)。接着,一个像素解码器逐步对特征图进行上采样,生成与原始图像分辨率一致的逐像素嵌入。
Transformer 模块
该模块采用标准 Transformer 解码器。解码器的输入包括两部分:一是像素级模块输出的图像特征,二是 N 个可学习的位置嵌入(即查询向量)。解码器输出 N 个逐片段嵌入,每个嵌入编码了对应片段的全局信息。与 DETR 类似,所有片段的嵌入是并行计算得到的。
分割模块
该模块负责从逐片段嵌入生成最终的预测。首先,对每个片段嵌入应用一个线性分类器和 softmax 函数,得到该片段属于每个类别(包括一个额外的“无物体”类别)的概率。然后,通过一个两层多层感知机将片段嵌入转换为掩码嵌入。每个掩码预测的计算方式如下:将对应掩码嵌入与像素级模块得到的逐像素嵌入进行逐位置点积,再经过 sigmoid 激活函数,从而得到一张取值在 0 到 1 之间的二值掩码图。
实验发现,不强制要求不同掩码之间互斥(即不使用 softmax)反而对性能有益。训练时,模型的损失函数由两部分组成:每个片段的交叉熵分类损失和二值掩码损失。为简化实现,本文采用了与 DETR 相同的掩码损失,即焦点损失和 Dice 损失的加权和。
掩码分类的推理
本节首先介绍一个通用推理流程,可将掩码分类输出的 N 个概率-掩码对转换为全景分割或语义分割的结果。随后介绍一个专为语义分割设计的简化推理方法。需要说明,推理策略的选择主要取决于评估指标,而非任务本身。
通用推理
该流程将每个像素分配给某个概率-掩码对,分配依据是该像素在某个对中的“最可能类别概率”与“掩码预测值”的乘积。只有两者都较高时,像素才会被分配给该对。同一对中的所有像素构成一个片段,并标记为该对的最可能类别。
- 对于语义分割,相同类别的片段会被合并。
- 对于实例分割,概率-掩码对的索引可用于区分同一类别的不同实例。
此外,为降低全景分割中的假阳性率,本文采用先前工作的策略:推理前过滤低置信度预测,并移除二值掩码中大部分区域被其他预测遮挡的片段。
语义推理
该策略专为语义分割设计,操作简单:对所有概率-掩码对进行边缘化(即对每个类别,累加每个对的类别概率与掩码值的乘积),然后选择累加值最大的类别作为像素标签。此处的取最大值操作不包含“无物体”类别,因为语义分割要求每个像素都有明确标签。
需要注意的是,该策略实际上返回了每个像素所属类别的累加概率,但本文发现直接最大化该累加概率(即逐像素分类)的效果并不好。本文推测其原因是:梯度被均匀分配到每个查询上,导致训练困难。
实现细节
主干网络
MaskFormer 可与任意主干网络架构兼容。本文中,本文使用了基于标准卷积的 ResNet 系列主干网络(R50 与 R101,分别包含 50 层和 101 层),以及近期提出的基于 Transformer 的 Swin-Transformer 主干网络。
像素解码器
图 2 中的像素解码器可采用任意语义分割解码器实现。许多逐像素分类方法会使用 ASPP或 PSP 等模块来收集和传播不同位置的上下文信息。然而,在 MaskFormer 中,Transformer 模块会关注全部图像特征,并收集全局信息用于类别预测。这一设计降低了像素级模块对大量上下文聚合的需求。因此,本文基于流行的 FPN 架构,为 MaskFormer 设计了一个轻量级的像素解码器。
具体实现上,本文沿用 FPN 的做法:在解码器中对低分辨率特征图进行 2 倍上采样,再将其与主干网络中对应分辨率的投影特征图相加。投影操作用来对齐通道数,通过一个 1×1 卷积层(后接 GroupNorm, GN)完成。随后,本文使用一个额外的 3×3 卷积层(后接 GN 和 ReLU 激活)对相加后的特征进行融合。本文从步长为 32 的特征图开始重复这一过程,直至得到步长为 4 的最终特征图。最后,通过一个 1×1 卷积层获得逐像素嵌入。像素解码器中所有特征图的通道数均设为 256。
Transformer 解码器
本文采用了与 DETR完全相同的 Transformer 解码器设计。N 个查询嵌入初始化为零向量,并为每个查询配对一个可学习的位置编码。默认配置下,解码器层数为 6,查询数量为 100,并且遵循 DETR 的做法,在每个解码器层之后都施加相同的损失函数。实验发现,对于语义分割任务,MaskFormer 仅使用单层解码器也能取得不错的效果;而对于实例级分割,则需要多层解码器来消除最终预测中的重复预测。
分割模块
图 2 中的多层感知机(MLP)包含 2 个隐藏层,每层 256 个通道,用于预测掩码嵌入 E m a s k E_{mask} Emask,这与 DETR 中的边界框预测头设计类似。逐像素嵌入 E p i x e l E_{pixel} Epixel 与掩码嵌入 E m a s k E_{mask} Emask 的维度均为 256。
损失权重
本文的掩码损失由焦点损失和 Dice 损失共同构成,即: L m a s k ( m , m g t ) = λ f o c a l ⋅ L f o c a l ( m , m g t ) + λ d i c e ⋅ L d i c e ( m , m g t ) L_{mask}(m, m_{gt}) = λ_{focal}·L_{focal}(m, m_{gt}) + λ_{dice}·L_{dice}(m, m_{gt}) Lmask(m,mgt)=λfocal⋅Lfocal(m,mgt)+λdice⋅Ldice(m,mgt)。超参数设置为 λ_focal = 20.0,λ_dice = 1.0。另外,参照 DETR的设置,分类损失中“无物体”类别的权重设为 0.1。
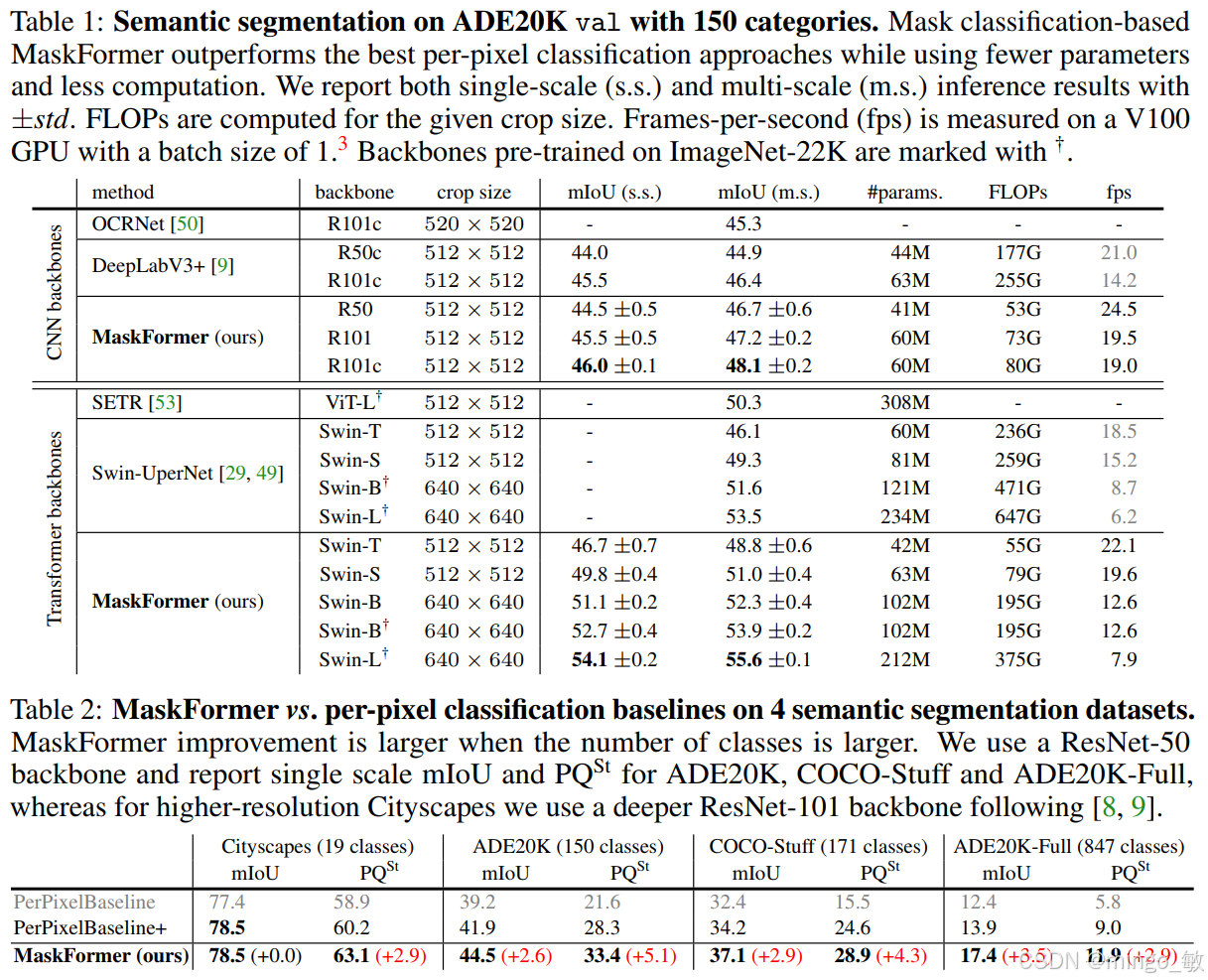
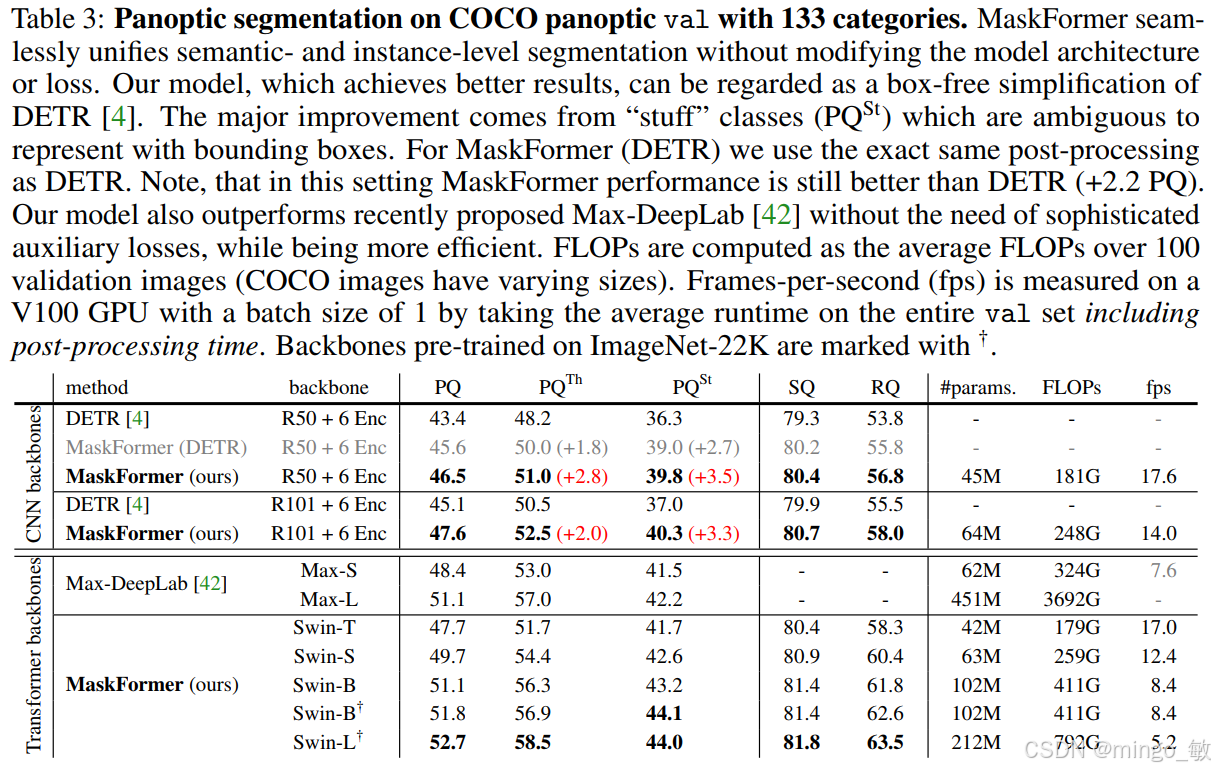
3 Experiments


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)