Spring AI
SSE协议:服务器发送事件,是一种基于HTTP的轻量级实时通信协议,允许服务器主动向浏览器推送数据流
在Spring中我们使用webFlux来优雅的实现SSE协议
Flux的流程分为:
- 创建Flux(创建一个Flux数据流,并有数据源)
- 处理数据(使用操作符对数据进行处理)
- 订阅数据(订阅Flux来消费数据,触发数据的流动)
ChatClient 和ChatModel的区别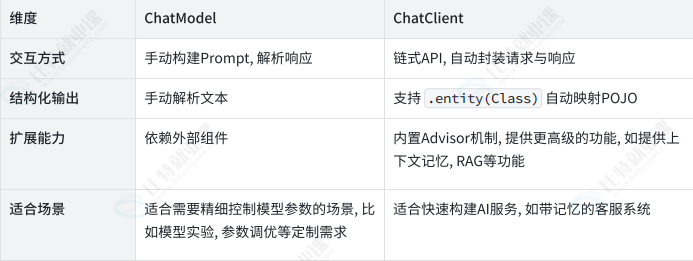
MCP(模型上下文协议)
架构:
⽤⼾
↓
[ McpClient ] ← AI助⼿ (我要点餐!)
↓
[ DefaultMcpSession ] ← 订单管家 (这是order-1001, 正在处理…)
↓
[ McpTransport ] ← 快递员 (把订单纸条交给厨房)
↓
[ McpServer ] ← 厨房+收银台 (收到!⻢上做)
传输模式:
- stdio:无网络,低延迟,不需要配端口,只能本地一对一
- Streamable:单统一端点,支持负载均衡,远程场景的选择
- SSE:已被废弃,但SSE协议降级为Streamable的流式输出的可选方式之一
消息协议:JSON‑RPC 2.0。
RAG(检索增强搜索)
RAG是一种结合信息检索和文本生成的混合架构。RAG就像给ai装了大脑,让它回答问题的时候先从外部知识库(如文档,数据库)检索相关片段,再把这些片段作为上下文输入给模型,这样ai的回答就基于真实,最新数据。
RAG 检索与生成流程:
① 离线索引:
数据源 (PDF/DB/网页/API…)
↓
[ ETL ] ← 提取+清洗+标准化 (Extract → Transform → Load)
↓
[ TextSplitter ] ← 切分 (按段落/语义分块)
↓
[ Embedding ] ← 向量化 (文本 → 向量)
↓
[ 向量库 ] ← 存储 (PGVector/Chroma/Redis…)
② 在线检索+生成:
用户提问
↓
[ Embedding ] ← 向量化 (问题 → 查询向量)
↓
[ 相似度检索 ] ← Top-K召回 (Cosine/欧氏距离)
↓
[ Prompt组装 ] ← 系统提示 + 检索片段 + 用户问题
↓
[ LLM ] ← 增强生成 (基于检索上下文)
↓
回答
流程说明:
| 阶段 | 步骤 | 做什么 |
|---|---|---|
| 离线索引 | ETL | Extract: 从 PDF/DB/网页/API 等多源提取数据;Transform: 清洗去重、格式标准化、元数据提取;Load: 输出标准文本给下游 |
| 文档切分 | TextSplitter 按 token 长度/段落/语义边界切块,块间可设 overlap | |
| 向量化 | Embedding 模型(OpenAI/text-embedding/本地模型)将文本块转为向量 | |
| 向量存储 | 写入向量数据库,建立索引(HNSW/IVF 等) | |
| 在线检索 | 查询向量化 | 用户问题用同一 Embedding 模型转为向量 |
| 相似度检索 | 在向量库中 Top-K 召回最相似的文档片段 | |
| Prompt 组装 | 将检索片段注入 prompt 模板 | |
| LLM 生成 | 大模型基于增强后的上下文生成答案,减少幻觉 |
ETL 在 RAG 中的角色:
ETL 是 RAG 的数据基座,决定了检索质量的下限。三大阶段:
- Extract(提取): 对接异构数据源 — PDF 解析(Apache PDFBox/iText)、数据库 CDC 监听、API 定时拉取、网页爬虫。Spring AI 的
DocumentReader接口承担此角色,开箱支持 PDF/JSON/Markdown/Tika。 - Transform(转换): 清洗脏数据(去 HTML 标签、去特殊字符)、格式归一化(统一编码、时间格式)、元数据标注(来源、时间戳、分类标签)。这一层 Spring AI 没有直接抽象,通常用自定义 Pipeline 或 ETL 框架(Apache NiFi/Logstash)补位。
- Load(装载): 将清洗后的标准文本提交给
TextSplitter进行切分,最终经 Embedding 写入VectorStore。
简单场景可以跳过 ETL(比如用户直接上传 txt),但生产环境多源多格式接入时,ETL 占比往往超过 50%。
重排序(Re-Ranking)
最相似的向量!=最相关的答案
重排序是指在初步检索出一批候选文档后,使用一个更加精细,专精于相关性判断的的模型,重新评估每个文档与查询之间的匹配程度,并按新得分重新排序
Spring AI 中的 RAG 关键组件:
DocumentReader → TextSplitter → VectorStore → Retriever
(读取文档) (切分文档) (存储向量) (检索召回)
↓
ChatClient / Agent
(增强生成)
DocumentReader— 支持 PDF, JSON, Markdown, 数据库等多种源TextSplitter— TokenTextSplitter / ParagraphSplitter,可配 chunk-size 和 overlapVectorStore— 统一抽象接口,实现有 PGVector, Chroma, Milvus, Redis, QdrantRetriever— VectorStoreRetriever,支持 Top-K 和相似度阈值过滤ChatClient—retrieve(Retriever)链式调用,自动完成检索+增强+生成
Spring AI中Agents的五种基础模式
- 链式工作流:将复杂的任务拆分成多个有序,依赖性强的子任务,前一步的输出作为下一步的输入
- 并行化工作流:多个独立的LLM同时进行,任务输入不同,完成后自动汇聚结果
- 路由工作流:根据输入内容类型,自动将任务“路由”到最适合处理它的LLM
- 编排器工作者模式:编排器费分析任务,分解成多个子任务,协调各个LLM执行
- 评估优化循环模式:评估器对输出进行多维度的质量评估,然后优化器根据评估结果提出改进建议,并生成更好的内容,之后不断循环,边评边改。
Observability(可观测性)
生产环境下要观测:
- 用量统计:比如不当接口导致token消耗激增
- 性能统计:当整体响应变慢时通过日志时难以判断是网络延迟,模型推理耗时增加还是向量库查询效率下降
- 优化决策:通过可观测型数据来判断是否要切换为性能或者性价比更优的的模型
Zipkin:可以使的每一次ai调用可见,每一笔费用可追溯,每一个性能问题可归因
Zipkin 核心参数:
| 参数 | 作用 |
|---|---|
| Trace ID | 一次请求的全局唯一标识,串联整条链路 |
| Span ID | 单次调用的唯一标识,一个 Span = 一次 RPC/DB/HTTP |
| Parent Span ID | 上游 Span ID,用来画调用树 |
| Duration | 该 Span 耗时,定位瓶颈用 |
| Annotations | cs/sr/ss/cr 四个时间点,算出网络耗时和服务耗时 |
常见排查:
- 超时 → 找 Duration 最长的 Span
- 报错 → 看 error Tag
- 链路断 → 对比上下游 Span 缺了谁

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)