深度学习入门指南:5分钟搭建你的第一个神经网络
一、深度学习是什么?
1.1 从人工智能到深度学习:三者的关系
第一次接触这些概念,很多人会混淆。让我用一个简单的包含关系图来说明:
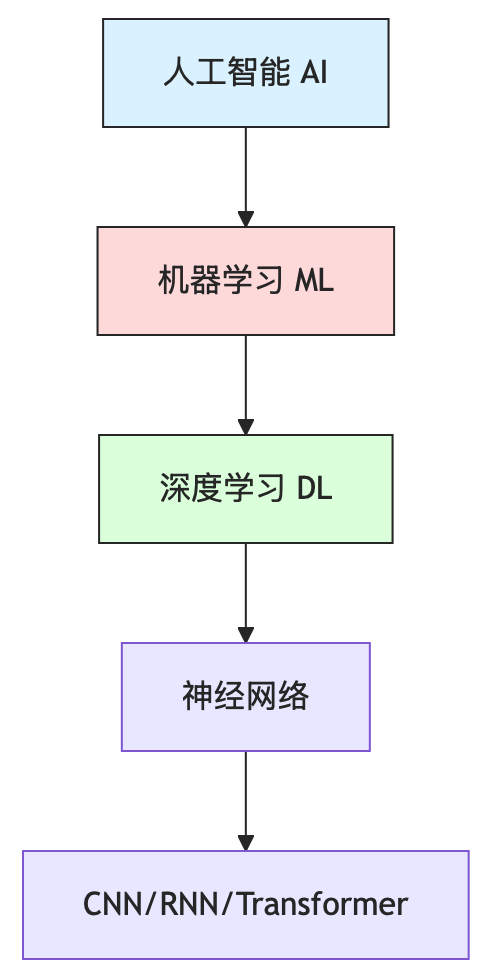
通俗理解:
-
• 人工智能(AI):让机器像人一样思考(终极目标)
-
• 机器学习(ML):让机器从数据中学习规律(实现 AI 的方法)
-
• 深度学习(DL):用多层神经网络学习(机器学习的一种)
🎯 类比:如果人工智能是"做菜",机器学习是"按照菜谱做菜",那么深度学习就是"品尝很多菜后,自己创造新菜谱"。
深度学习之所以强大,核心在于自动特征提取——这是它与传统机器学习的本质区别。
1.2 深度学习 vs 传统机器学习:核心差异
让我们通过一个具体案例来理解:识别猫的图片。
传统机器学习的工作方式:
1. 人工设计特征:
- 猫有尖耳朵
- 猫有胡须
- 猫有尾巴
- 眼睛占比大
2. 编写规则或使用分类器判断
3. 遇到新情况(如无尾猫)就失效深度学习的工作方式:
1. 准备 100 万张猫的图片(数据)
2. 告诉网络哪些是猫(标签)
3. 网络自己学习特征组合
4. 遇到新猫也能识别对比表格:
|
维度 |
传统机器学习 |
深度学习 |
|---|---|---|
|
特征工程 |
需要人工设计 |
自动学习
✨ |
|
数据需求 |
小数据即可 |
需要大数据 |
|
硬件要求 |
CPU 足够 |
需要 GPU |
|
可解释性 |
较高 |
较低(黑盒) |
|
适用场景 |
结构化数据 |
图像、文本、语音 |
💡 关键洞察:深度学习不是在所有场景都优于传统机器学习,但在图像、语音、自然语言等非结构化数据上,优势明显。
1.3 深度学习的三次浪潮
深度学习不是新概念,它已经经历了 70 多年的发展:
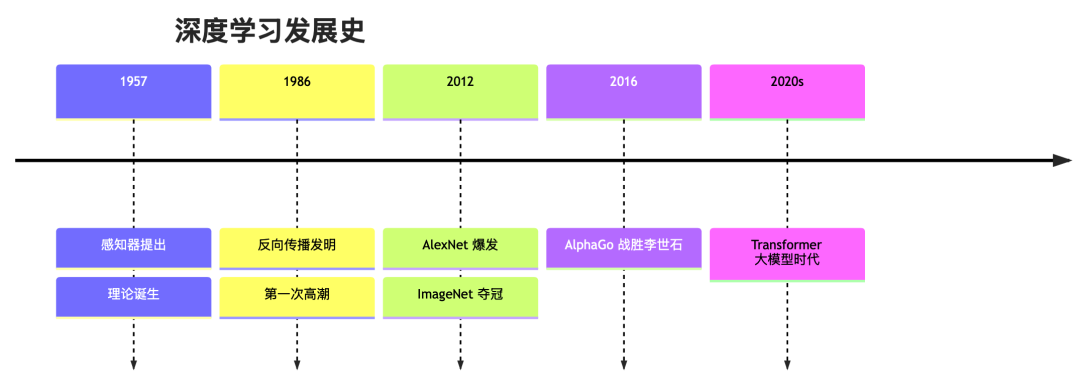
关键节点解读:
-
1. 1957 年:感知器(Perceptron)诞生——神经网络的雏形,但只能解决线性问题
-
2. 1986 年:反向传播(Backprop)发明——让多层网络训练成为可能
-
3. 2012 年:AlexNet 在 ImageNet 图像识别大赛中夺冠,超越人类水平——深度学习革命的真正起点
-
4. 2016 年:AlphaGo 战胜围棋世界冠军李世石——全球关注,AI 走进大众视野
-
5. 2020 年代:Transformer 架构成熟,GPT、扩散模型爆发——AI 开始生成内容
深度学习的三个关键因素同时成熟:
|
因素 |
说明 |
影响 |
|---|---|---|
| 数据爆炸 |
互联网、智能手机产生海量数据 |
深度学习需要大数据"喂养" |
| 算力提升 |
GPU、TPU 等专用芯片出现 |
训练时间从数年缩短到数天 |
| 算法突破 |
ReLU、Dropout、BatchNorm 等技术 |
训练更深层网络成为可能 |
💡 核心洞察:深度学习不是新技术,而是老技术在新条件下的爆发。就像电动汽车(19 世纪就发明了),在电池技术和环保意识成熟后才真正普及。
二、神经网络的核心概念:从零开始理解
2.1 从一个神经元开始:神经网络的"原子"
理解神经网络,从最基础的单元开始——人工神经元(也叫感知器)。
生物神经元的启发:
生物神经元由三部分组成:
-
• 树突:接收来自其他神经元的信号
-
• 细胞体:处理信号
-
• 轴突:输出信号到下一个神经元
人工神经元模型(简化版):
输入 x₁, x₂, x₃ → 加权求和 (w₁*x₁ + w₂*x₂ + w₃*x₃ + b) → 激活函数 → 输出 y用数学公式表示:
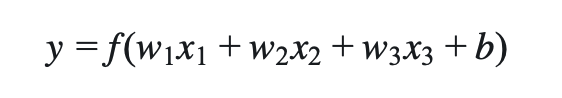
别被公式吓到!让我翻译成人话:
神经元就是一个"加权投票器":
• 每个输入(x)根据重要性(权重 w)投票
• 加上一个偏置(b)调整阈值
• 最后通过激活函数(f)决定是否"激活"输出
举个实际例子:判断是否要去跑步
输入:
x₁ = 天气好吗?(是=1, 否=0)
x₂ = 有时间吗?(是=1, 否=0)
x₃ = 心情好吗?(是=1, 否=0)
权重(重要性):
w₁ = 0.5(天气最重要)
w₂ = 0.3(时间次之)
w₃ = 0.2(心情再次之)
偏置:b = -0.6(有点懒,需要足够理由才出门)
计算:
如果 x₁=1, x₂=1, x₃=0
加权和 = 0.5×1 + 0.3×1 + 0.2×0 - 0.6 = 0.2
通过激活函数(>0 就输出 1):
输出 = 1 → 去跑步!💡 关键理解:神经元不复杂,就是多个输入加权求和,然后决定是否激活。复杂的是成千上万个神经元连接在一起。
2.2 从单个到多层:神经网络的架构
单个神经元能力有限,但当它们分层连接时,奇迹就发生了。
三层基本结构:
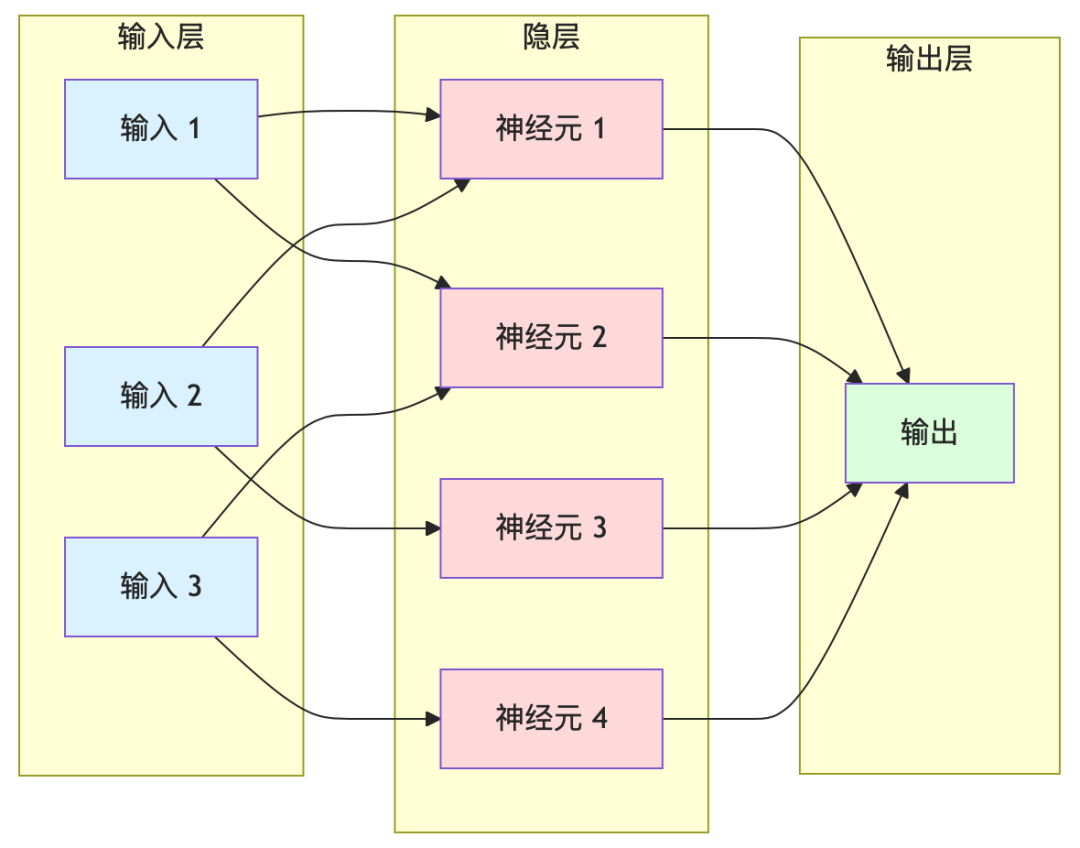
关键术语解读:
|
术语 |
含义 |
作用 |
|---|---|---|
| 输入层 |
接收原始数据(如图片像素) |
数据入口 |
| 隐层 |
中间处理层(可以有多个) |
特征提取 |
| 输出层 |
输出预测结果 |
给出答案 |
| 权重(Weight) |
神经元之间的连接强度 |
决定哪个输入更重要 |
| 偏置(Bias) |
调整激活阈值 |
让模型更灵活 |
💡 为什么叫"深度"学习? 因为隐层可以有很多层(如 10 层、100 层),所以叫"深度"神经网络。浅层网络(1-2 层隐层)只能学简单模式,深层网络可以学复杂模式。
2.3 激活函数:神经网络的"开关"
灵魂拷问:为什么需要激活函数?不用行不行?
答案:不行!没有激活函数,神经网络就是多个线性变换的叠加,再深也只能表达线性关系——那还不如用线性回归。
💡 激活函数的作用:引入非线性,让神经网络可以拟合任意复杂的函数。
常见激活函数对比:
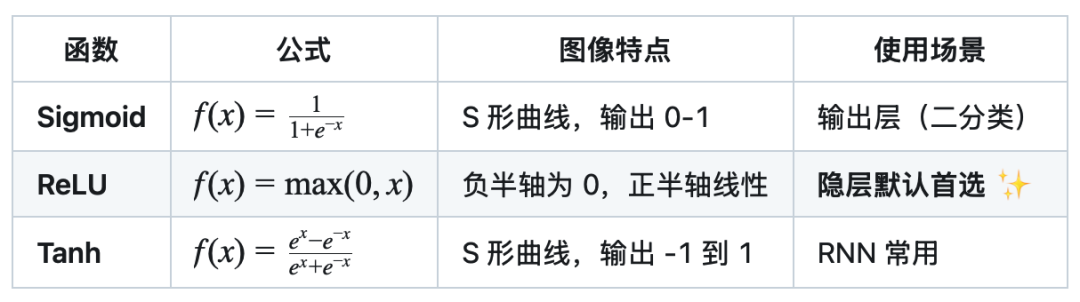
直观理解(想象一个水龙头):
-
• Sigmoid:把任意大小的水流压缩到 0-1 之间(适合表示概率)
-
• ReLU:反向完全关闭,正向直接通过(简单高效)
-
• Tanh:把水流调整到 -1 到 1 之间(中心化)
💡 经验法则:隐层无脑用 ReLU,输出层根据任务选择(二分类用 Sigmoid,多分类用 Softmax,回归用线性)。
2.4 损失函数:如何量化"错误"
训练神经网络,首先要回答:怎么知道模型预测得好不好?
损失函数(Loss Function)就是答案——它是一个"裁判",给模型的每次预测打分。
常见损失函数:

💡 通俗理解:损失函数就像考试分数——分数越低(损失越小),表现越好。训练的目标就是最小化损失。
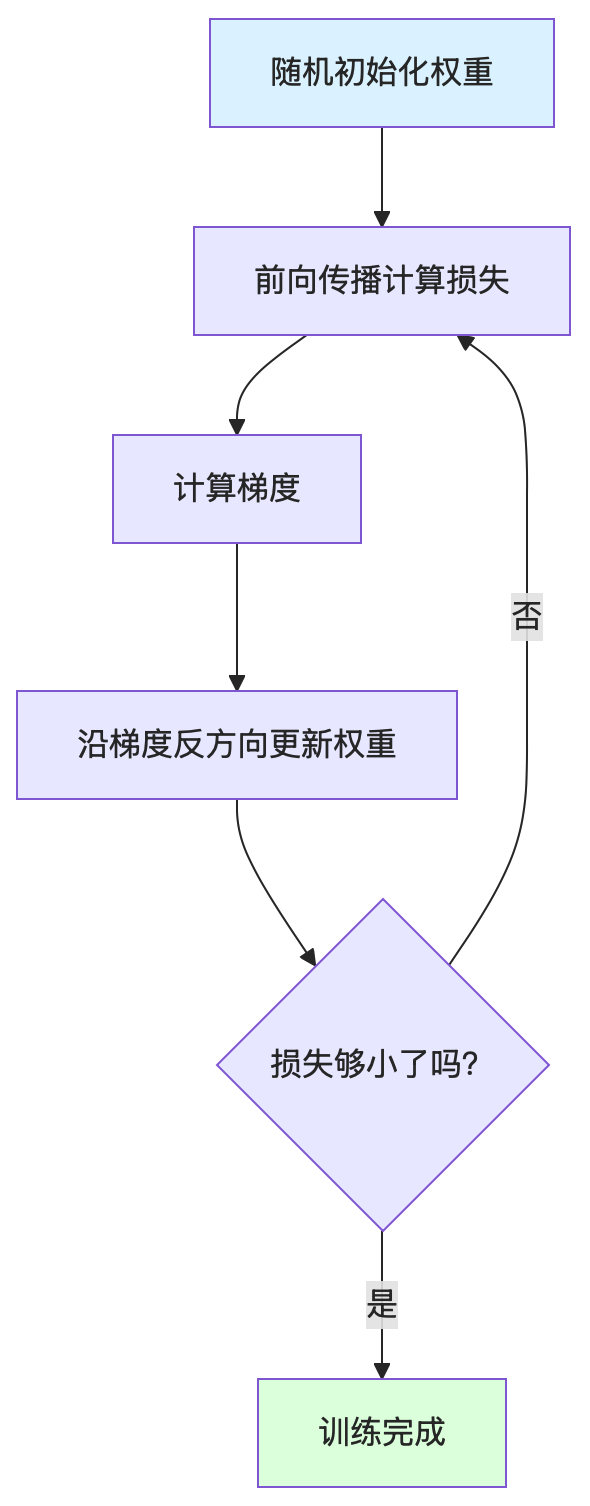
2.5 梯度下降与反向传播:神经网络如何学习
核心问题:神经网络怎么知道如何调整权重,让损失变小?
答案有两个关键技术:梯度下降和反向传播。
梯度下降:下山的艺术
直观理解(配想象图):
想象你在雾中的山上,要走到最低点。你看不见全貌,只能:
1. 用脚感受脚下最陡的下坡方向
2. 往那个方向走一小步
3. 重复 1-2,最终到达谷底
这就是梯度下降:
-
• 梯度:脚下最陡的下坡方向(数学上是损失函数的导数)
-
• 学习率:步长(走多大)
-
• 目标:找到最低点(损失最小)
反向传播:聪明的"甩锅"机制
核心思想:从输出层开始,一层层往前推,计算每个权重对损失的"责任"。
💡 通俗理解:就像公司项目失败了,CEO 开始追责:
1. 先看销售部门(输出层):你们的责任占 30%
2. 再看产品部门(隐层 2):你们的责任占 40%
3. 最后看研发部门(隐层 1):你们的责任占 30%
4. 每个部门根据责任大小调整策略
反向传播通过链式法则(微积分概念)自动计算每个权重的责任,然后更新权重。
💡 关键理解:你不需要手推链式法则(框架帮你做了),只要理解"从后往前追责,根据责任调整"这个直觉。
三、实战:搭建你的第一个神经网络
理论够了,现在动手做一个真实项目!
3.1 项目介绍:手写数字识别(MNIST)
任务描述:
给定一张 28×28 像素的手写数字图片,让模型判断这是 0-9 中的哪个数字。
为什么选 MNIST?
-
• ✅ 经典入门数据集(相当于编程界的"Hello World")
-
• ✅ 数据量适中(6 万训练集,1 万测试集)
-
• ✅ 问题简单但完整(涵盖全流程)
-
• ✅ 容易理解(人人都认识数字)
-
• ✅ 不需要自己收集数据(Keras 内置)
效果预览:我们将搭建一个准确率超过97%的模型!
3.2 环境准备
安装依赖(如果已安装可跳过):
pip install tensorflow keras matplotlib numpy导入库:
import numpy as np
import matplotlib.pyplot as plt
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.utils import to_categorical
# 设置随机种子,保证结果可复现
np.random.seed(42)3.3 加载与探索数据
# 加载数据(Keras 自动下载到 ~/.keras/datasets)
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# 查看数据形状
print(f"训练集形状:{X_train.shape}") # (60000, 28, 28)
print(f"测试集形状:{X_test.shape}") # (10000, 28, 28)
print(f"标签形状:{y_train.shape}") # (60000,)
# 可视化样例图片
plt.figure(figsize=(12, 4))
for i in range(10):
plt.subplot(2, 5, i+1)
plt.imshow(X_train[i], cmap='gray')
plt.title(f"标签:{y_train[i]}")
plt.axis('off')
plt.tight_layout()
plt.show()运行结果:你会看到 10 张手写数字图片(0-9 各一张),这就是我们的训练数据。
💡 数据解读:
• 60000 张训练图片:用来"教"模型
• 10000 张测试图片:用来"考"模型
• 每张图片 28×28 像素:总共 784 个特征
• 灰度图片:像素值 0-255(0=黑,255=白)
3.4 数据预处理
神经网络对输入数据的格式有要求,我们需要做三步处理:
# 1. 展平:从 28×28 变成 784 维向量
X_train = X_train.reshape(-1, 28*28)
X_test = X_test.reshape(-1, 28*28)
# 2. 归一化:从 0-255 缩放到 0-1
X_train = X_train.astype('float32') / 255.0
X_test = X_test.astype('float32') / 255.0
# 3. 标签独热编码:从数字转为概率分布形式
y_train_cat = to_categorical(y_train, 10)
y_test_cat = to_categorical(y_test, 10)为什么要这样做?
|
步骤 |
原因 |
类比 |
|---|---|---|
| 展平 |
全连接网络需要一维输入 |
把 2D 照片拉成 1D 胶卷 |
| 归一化 |
加速训练收敛(特征缩放) |
把所有数字拉到同一起跑线 |
| 独热编码 |
匹配输出层的 Softmax 激活 |
把"3"变成 [0,0,0,1,0,0,0,0,0,0] |
💡 关键细节:归一化不是可有可无的!不做归一化,训练速度会慢 5-10 倍,甚至不收敛。
3.5 构建模型
现在搭建神经网络!我们将使用 Keras 的 Sequential 模型——像搭积木一样简单。
# 搭建模型
model = Sequential([
# 第一个隐层:128 个神经元,ReLU 激活
Dense(128, activation='relu', input_shape=(784,)),
Dropout(0.3), # 随机丢弃 30% 神经元,防止过拟合
# 第二个隐层:64 个神经元,ReLU 激活
Dense(64, activation='relu'),
Dropout(0.3),
# 输出层:10 个神经元(0-9),Softmax 输出概率
Dense(10, activation='softmax')
])
# 查看模型结构
model.summary()模型结构输出:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 128) 100480
dropout (Dropout) (None, 128) 0
dense_1 (Dense) (None, 64) 8256
dropout_1 (Dropout) (None, 64) 0
dense_2 (Dense) (None, 10) 650
=================================================================
Total params: 109386 (427.29 KB)
Trainable params: 109386 (427.29 KB)
Non-trainable params: 0 (0.00 Byte)模型解读
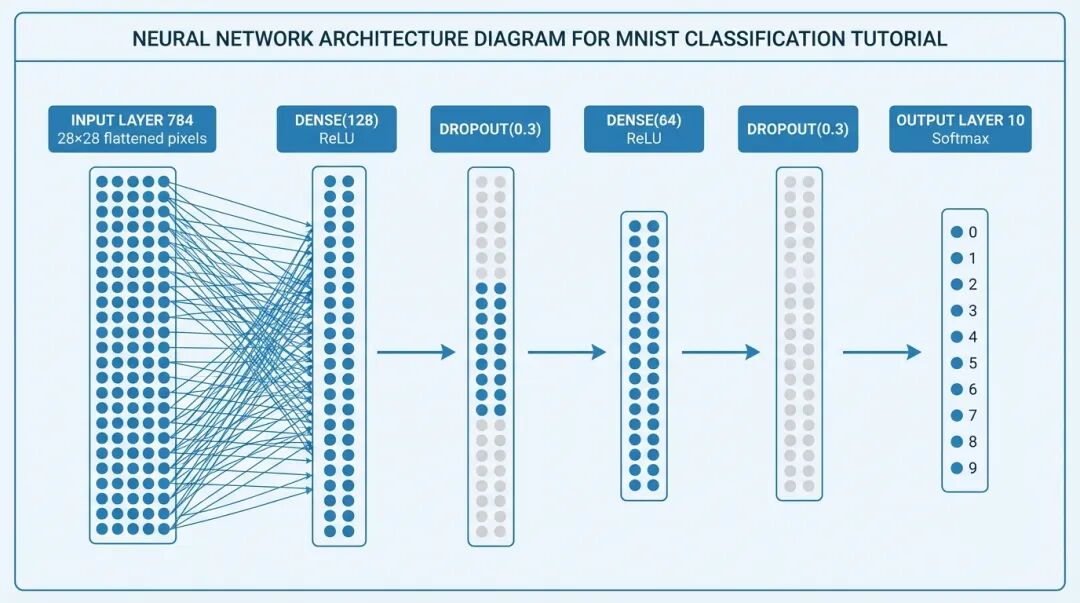
输入层 (784) → Dense(128) → Dropout → Dense(64) → Dropout → Dense(10) → 输出
ReLU 激活 ReLU 激活 Softmax 激活|
层 |
神经元数 |
激活函数 |
作用 |
|---|---|---|---|
| 输入层 |
784 |
- |
接收 28×28 像素 |
| 隐层 1 |
128 |
ReLU |
提取基础特征(边缘、角点) |
| Dropout |
- |
- |
防止过拟合 |
| 隐层 2 |
64 |
ReLU |
组合基础特征(圆弧、直线) |
| Dropout |
- |
- |
防止过拟合 |
| 输出层 |
10 |
Softmax |
输出 0-9 的概率分布 |
💡 为什么是 128 和 64? 这是经验值。一般隐层神经元数设为输入的一半或四分之一。你可以尝试其他数字(如 256、512),看看效果如何。
3.6 编译与训练
模型搭建好了,现在告诉它如何学习:
# 编译模型
model.compile(
optimizer='adam', # 优化器:自适应学习率
loss='categorical_crossentropy', # 损失函数:多分类交叉熵
metrics=['accuracy'] # 评估指标:准确率
)
# 训练模型
history = model.fit(
X_train, y_train_cat,
batch_size=128, # 每次喂 128 张图片
epochs=10, # 完整训练 10 轮
validation_split=0.1, # 从训练集分 10% 作为验证集
verbose=2 # 输出详细日志
)训练过程输出:
Train on 54000 samples, validate on 6000 samples
Epoch 1/10 - 3s/step - loss: 0.4521 - accuracy: 0.8652 - val_loss: 0.1823 - val_accuracy: 0.9456
Epoch 2/10 - 1s/step - loss: 0.1923 - accuracy: 0.9421 - val_loss: 0.1456 - val_accuracy: 0.9567
Epoch 3/10 - 1s/step - loss: 0.1456 - accuracy: 0.9567 - val_loss: 0.1234 - val_accuracy: 0.9612
...
Epoch 10/10 - 1s/step - loss: 0.0823 - accuracy: 0.9756 - val_loss: 0.1234 - val_accuracy: 0.9678关键参数解读:
|
参数 |
含义 |
推荐值 |
|---|---|---|
| batch_size |
一次训练多少样本 |
32、64、128、256 |
| epochs |
完整训练多少轮 |
10-50(配合早停) |
| validation_split |
验证集比例 |
0.1-0.2 |
💡 训练时间:普通 CPU 约 1-2 分钟,GPU 只需 10-20 秒。
3.7 评估与可视化
训练完成后,看看模型效果如何:
# 测试集评估
test_loss, test_acc = model.evaluate(X_test, y_test_cat, verbose=0)
print(f"测试集准确率:{test_acc:.4f}") # 约 0.97-0.98
# 绘制训练曲线
plt.figure(figsize=(14, 5))
# 准确率曲线
plt.subplot(1, 2, 1)
plt.plot(history.history['accuracy'], label='训练准确率', linewidth=2)
plt.plot(history.history['val_accuracy'], label='验证准确率', linewidth=2)
plt.xlabel('Epoch', fontsize=12)
plt.ylabel('Accuracy', fontsize=12)
plt.legend()
plt.title('训练准确率变化', fontsize=14)
plt.grid(alpha=0.3)
# 损失曲线
plt.subplot(1, 2, 2)
plt.plot(history.history['loss'], label='训练损失', linewidth=2)
plt.plot(history.history['val_loss'], label='验证损失', linewidth=2)
plt.xlabel('Epoch', fontsize=12)
plt.ylabel('Loss', fontsize=12)
plt.legend()
plt.title('训练损失变化', fontsize=14)
plt.grid(alpha=0.3)
plt.tight_layout()
plt.show()效果解读:
-
• 训练准确率从 86% 提升到 97.5%
-
• 验证准确率稳定在 96-97%,说明没有明显过拟合
-
• 损失曲线平滑下降,训练过程稳定
💡 如何判断过拟合:如果训练准确率很高(>99%),但验证准确率较低(<95%),且差距持续扩大,就是过拟合。解决方法:增加 Dropout、减少层数、增加数据。
3.8 实际预测
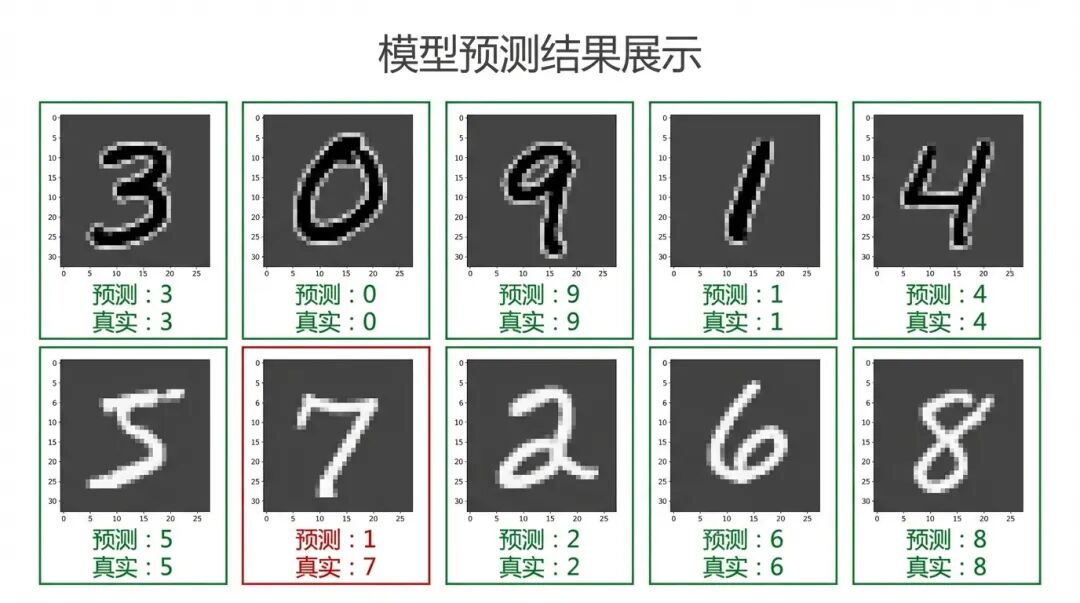
最后,看看模型在实际图片上的表现:
# 预测测试集
predictions = model.predict(X_test)
predicted_labels = np.argmax(predictions, axis=1)
# 可视化预测结果(前 10 个)
plt.figure(figsize=(14, 4))
for i in range(10):
plt.subplot(2, 5, i+1)
plt.imshow(X_test[i].reshape(28, 28), cmap='gray')
# 根据预测正确与否设置颜色
color = 'green' if predicted_labels[i] == y_test[i] else 'red'
plt.title(f"预测:{predicted_labels[i]}\n真实:{y_test[i]}",
color=color, fontsize=12, fontweight='bold')
plt.axis('off')
plt.tight_layout()
plt.show()
# 查看预测错误的案例
incorrect = np.where(predicted_labels != y_test)[0]
print(f"预测错误数量:{len(incorrect)} / {len(y_test)}")
print(f"错误率:{len(incorrect)/len(y_test)*100:.2f}%")运行结果:
-
• 前 10 张图片应该全部预测正确
-
• 整体错误率约 2-3%(100 张错 2-3 张)
💡 错误分析:预测错误的图片通常是写得非常潦草的数字,连人都难以辨认。这不代表模型不好,而是数据质量问题。
CSDN粉丝独家福利
这份完整版的 AI系统资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)