[菜鸟教程] 机器学习教程第三课
# 示例:使用 Pandas 和 Matplotlib 进行基础数据分析
# 示例:使用 Pandas 和 Matplotlib 进行基础数据分析
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
matplotlib.use('TkAgg')
# -------------------------- 设置中文字体 start --------------------------
plt.rcParams['font.sans-serif'] = [
# Windows 优先
'SimHei', 'Microsoft YaHei',
# macOS 优先
'PingFang SC', 'Heiti TC',
# Linux 优先
'WenQuanYi Micro Hei', 'DejaVu Sans'
]
# 修复负号显示为方块的问题
plt.rcParams['axes.unicode_minus'] = False
# -------------------------- 设置中文字体 end --------------------------
# 1. 读取数据
data = pd.read_csv('house_prices.csv')
print("数据前5行:")
print(data.head())
# 2. 查看数据基本信息
print("\n数据信息:")
print(data.info())
# 3. 绘制房屋面积与价格的散点图
plt.figure(figsize=(10, 6))
plt.scatter(data['面积'], data['价格'], alpha=0.5)
plt.title('房屋面积 vs 价格')
plt.xlabel('面积 (平方米)')
plt.ylabel('价格 (万元)')
plt.grid(True)
plt.show()输出
数据前5行:
面积 价格 房龄 卧室数 城市
0 45 120 15 1 北京
1 60 180 12 2 北京
2 75 260 8 2 北京
3 90 320 6 3 北京
4 110 420 5 3 北京
数据信息:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 24 entries, 0 to 23
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 面积 24 non-null int64
1 价格 24 non-null int64
2 房龄 24 non-null int64
3 卧室数 24 non-null int64
4 城市 24 non-null object
dtypes: int64(4), object(1)
memory usage: 1.1+ KB
None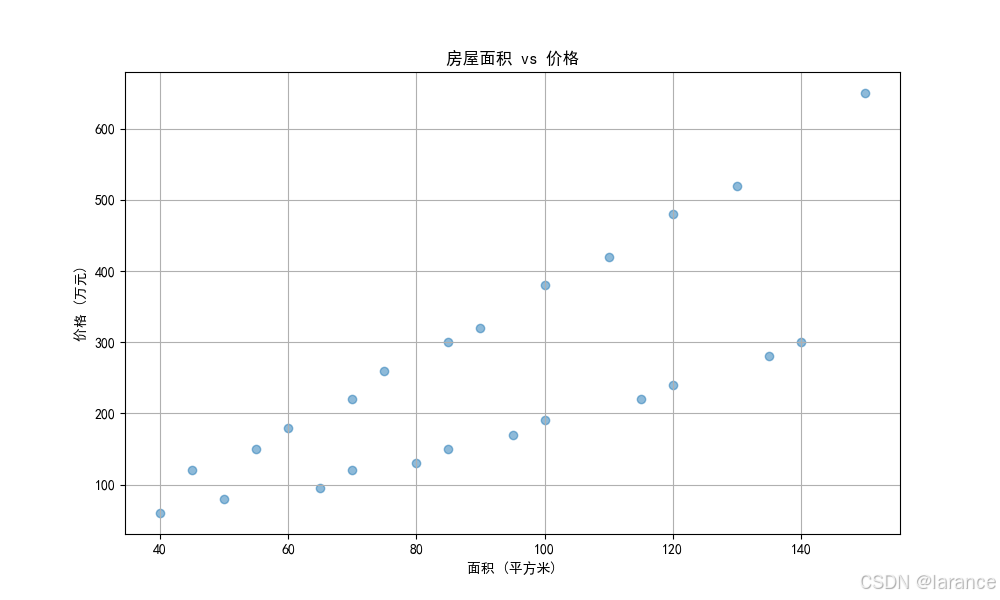
逻辑回归和报告
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report
from sklearn.metrics import confusion_matrix
# =========================
# 1. 构造可运行的测试数据
# 场景:是否通过考试(1=通过,0=未通过)
# 特征:学习时长、出勤率、作业完成率
# =========================
X = np.array([
[2, 60, 50],
[3, 65, 55],
[4, 70, 65],
[5, 75, 70],
[6, 80, 75],
[7, 85, 80],
[8, 90, 85],
[9, 92, 88],
[10, 95, 90],
[11, 97, 92],
[1, 50, 40],
[2, 55, 45],
[3, 60, 50],
[4, 65, 55],
[5, 70, 60],
[6, 75, 65],
[7, 80, 70],
[8, 85, 75],
[9, 90, 80],
[10, 95, 85]
])
y = np.array([
0, 0, 0, 0, 1,
1, 1, 1, 1, 1,
0, 0, 0, 0, 0,
1, 1, 1, 1, 1
])
# =========================
# 2. 划分训练集和测试集
# =========================
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42
)
# =========================
# 3. 创建并训练模型
# =========================
model = LogisticRegression(max_iter=1000)
model.fit(X_train, y_train)
# =========================
# 4. 进行预测
# =========================
y_pred = model.predict(X_test)
# =========================
# 5. 评估模型性能
# =========================
print(f"模型准确率:{accuracy_score(y_test, y_pred):.2f}")
print("\n详细分类报告:")
print(classification_report(y_test, y_pred))
print(confusion_matrix(y_test, y_pred))导入库分析
| 导入的库 | 作用 |
|---|---|
numpy as np |
处理数值数组,创建特征矩阵X和标签向量y |
train_test_split |
将数据随机划分为训练集和测试集 |
LogisticRegression |
逻辑回归分类器(用于二分类问题) |
accuracy_score |
计算模型预测的准确率 |
classification_report |
生成详细的分类评估报告(精确率、召回率、F1值等) |
X(特征矩阵):20行 × 3列
-
每一行代表一个学生
-
三列特征分别是:学习时长(小时)、出勤率(%)、作业完成率(%)
y(标签向量):
-
1 → 通过考试
-
0 → 未通过考试
数据划分
| 参数 | 含义 | 本代码的值 |
|---|---|---|
X, y |
特征和标签 | 全部20个样本 |
test_size |
测试集占比 | 0.3 = 30% |
random_state |
随机种子 | 42(固定随机结果,复现实验) |
划分结果:
-
训练集(70%):约14个样本,用于训练模型
-
测试集(30%):约6个样本,用于评估模型
模型训练
model.fit(X_train, y_train)
max_iter=1000:最大迭代次数(默认100可能不够,提高确保收敛)
`.fit()`` 的作用是训练模型:
-
输入训练数据(X_train,y_train)
-
逻辑回归算法学习特征与标签之间的关系
-
找到最优的决策边界(一组系数,即每个特征的权重)
学习到的关系示例(假设结果):
“学习时长越长、出勤率越高、作业完成率越高 → 通过考试的概率越大”
预测
用训练好的模型在测试集上进行预测:
-
输入:X_test(模型从未见过的6个学生数据)
-
输出:y_pred(预测的标签,0或1)
输出说明
准确率:预测正确的样本数 ÷ 总测试样本数
| 指标 | 含义 |
|---|---|
| 精确率 (Precision) | 预测为“通过”的人中,实际真的通过的比例 |
| 召回率 (Recall) | 实际通过的人中,被模型正确找出的比例 |
| F1值 | 精确率和召回率的调和平均(综合指标) |
| 支持度 (Support) | 各类别的实际样本数量 |
输出报告
模型准确率:0.83
详细分类报告:
precision recall f1-score support
0 0.67 1.00 0.80 2
1 1.00 0.75 0.86 4
accuracy 0.83 6
macro avg 0.83 0.88 0.83 6
weighted avg 0.89 0.83 0.84 6
[[2 0]
[1 3]]
报告解读
这份分类报告看起来是从你之前那个“预测学生是否通过考试”的逻辑回归模型输出的。因为它只有 6 个测试样本(support 总和为 6),而且测试集里恰好有 2 个“未通过”(0) 和 4 个“通过”(1)。
下面我一步步帮你解读这些指标的含义,以及它们在实际中意味着什么。
第一步:理解四个核心概念
在解读数字之前,先记住这四个基础定义:
-
TP (True Positive):实际是 1(通过),模型也预测为 1 → ✅ 猜对了
-
TN (True Negative):实际是 0(未通过),模型也预测为 0 → ✅ 猜对了
-
FP (False Positive):实际是 0(未通过),模型却预测为 1 → ❌ 误报(模型“太乐观”)
-
FN (False Negative):实际是 1(通过),模型却预测为 0 → ❌ 漏报(模型“看走眼”)
基于这 4 个值,我们来看报告中的几个主要指标。
第二步:逐行解读你的报告
| 标签 (class) | precision (精确率) | recall (召回率) | f1-score | support (真实数量) |
|---|---|---|---|---|
| 0 (未通过) | 0.67 | 1.00 | 0.80 | 2 |
| 1 (通过) | 1.00 | 0.75 | 0.86 | 4 |
1. 对标签 0(未通过)的解读
-
recall = 1.00:真实未通过的 2 个学生,模型 全部找出来了(100% 的召回率)。这一点做得很好,没有漏掉任何一个可能不及格的学生。
-
precision = 0.67:模型预测为“未通过”的学生里,只有 67% 是真的未通过。这意味着模型发出过 3 次“不及格”警告,其中有 1 次其实是“冤枉”了学生(他实际通过了)。这也是所谓“宁可错杀,不可放过”的体现。
2. 对标签 1(通过)的解读
-
precision = 1.00:模型预测为“通过”的学生,100% 都真的通过了。这一点非常可靠,它从不“误报”好消息。
-
recall = 0.75:真实通过的 4 个学生里,模型只找出了 3 个(75%),有 1 个被漏掉了,错误地预测成了“未通过”。
3. 模型的整体表现
-
accuracy = 0.83:在 6 个测试样本中,模型总共 猜对了 5 个(6 × 83% ≈ 5)。从整体看,这个准确率还算不错。
第三步:结合你的场景来分析
-
这个模型能用吗?
能用,但效果一般。准确率 83% 对学生考试预测来说不算高。主要问题是漏掉了一个“通过”的学生(把他判成“未通过”),以及错判了一个“未通过”的学生(把他归为“通过”)。 -
模型的主要问题是什么?
样本不平衡(2 个 0 和 4 个 1)是小样本测试中容易出现的情况。相比之下,更明显的短板是对“未通过”的预测不够精准(precision 只有 0.67)。这可能会在实际应用中带来一些困扰。
第四步:两个加权平均值是什么?
-
macro avg (宏平均):直接计算两个类别指标的平均值,不考虑类别数量。
-
precision = (0.67 + 1.00) / 2 = 0.83
-
这里的作用是平等看待“通过”和“未通过”。
-
-
weighted avg (加权平均):按各类别的
support(样本数)来加权计算平均值。-
由于“通过”(1) 有 4 个样本,“未通过”(0) 只有 2 个,因此最终结果会更偏向“通过”那一类。这里
weighted avg对precision的打分更高(0.89 > 0.83),正是因为“通过”类预测得更好,且样本更多。
-
第五步:总结与建议
一句话概括:
模型找“通过”的学生非常准(precision=1.00),但找不全(recall=0.75);找“未通过”的学生找得全(recall=1.00),但有时会误判(precision=0.67)。
混淆矩阵解读
第一步:理解矩阵的排列
在 scikit-learn 中,默认的混淆矩阵格式如下:
-
行 (axis=0):真实的标签。
-
列 (axis=1):预测的标签。
-
顺序:按标签值从小到大排列。在你的问题中,
0(未通过) 在前,1(通过) 在后。
所以,这个矩阵可以解读为:
| (真实 \ 预测) | 预测为 0 (未通过) |
预测为 1 (通过) |
|---|---|---|
真实为 0 (未通过) |
2 (左上角) | 0 (右上角) |
真实为 1 (通过) |
1 (左下角) | 3 (右下角) |
第二步:代入专业术语 (TN, FP, FN, TP)
混淆矩阵 的标准公式:
-
TN (True Negative) ——
真实=0,预测=0:左上角 = 2 -
FP (False Positive) ——
真实=0,预测=1:右上角 = 0 -
FN (False Negative) ——
真实=1,预测=0:左下角 = 1 -
TP (True Positive) ——
真实=1,预测=1:右下角 = 3
第三步:结合实际场景解读
现在,我们把上面这些数字放到 预测“考试通过” 的场景里来分析:
| 指标 | 数值 | 实际含义 |
|---|---|---|
| TN (正确拒斥) | 2 | ✅ 有 2 个 学生没通过考试,模型也正确地预测他们 “未通过”。 |
| FP (错误报警) | 0 | ⚠️ 没有真正的“未通过”学生被模型误判成“通过”。 |
| FN (漏报) | 1 | ❌ 有 1 个 学生实际上通过了考试,但模型却错误地预测他 “未通过”。这就是之前召回率不是100%的原因。 |
| TP (正确命中) | 3 | 🎉 有 3 个 学生通过了考试,模型也正确地预测他们 “通过”。 |
第四步:结合之前那份报告总结
结合之前解读的 classification_report,现在可以更清晰地看到模型的特点:
-
模型在识别“通过者”时很谨慎:
-
FP = 0,说明模型从不会把“差生”错判为“优等生”。正因如此,它的精确率才达到了 1.00。换句话说,模型预测的“通过”名单非常可信。
-
-
模型在识别“未通过者”时要求较严:
-
FN = 1,说明模型误“卡”了一名实际上能通过的学生。这导致召回率降低到了 0.75。
-
简而言之,面对 6 个学生的测试集,这个模型的表现是:
-
未通过 (0) —— 组:模型识别出了 2 人中的 2 人。
-
通过 (1) —— 组:模型识别出了 4 人中的 3 人。
-
结论:模型比较可靠地找出了可能不及格的学生(2/2);但在满分的严谨性上,错过了一名可能考得不错的学生(3/4)。
在实践中,这个模型的性能已经不错,但如果目标是 “不埋没任何一个有潜力通过的学生”,那么那个 FN = 1 的情况就需要想办法改进
# 示例:使用 Keras 快速构建一个简单的神经网络
# 示例:使用 Keras 快速构建一个简单的神经网络
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.Dense(64, activation='relu', input_shape=(input_dim,)), # 隐藏层1
layers.Dropout(0.2), # 丢弃层,防止过拟合
layers.Dense(32, activation='relu'), # 隐藏层2
layers.Dense(1, activation='sigmoid') # 输出层,用于二分类
])
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
model.summary() # 打印模型结构
# 之后可以使用 model.fit 进行训练一、代码整体功能
这是一个全连接前馈神经网络,用于解决二分类问题(输出是或否,比如垃圾邮件判断、客户流失预测、通过/不通过考试等)。
二、逐行代码解析
1. 导入模块
python
from tensorflow import keras from tensorflow.keras import layers
-
keras:TensorFlow 的高级 API,用于快速搭建神经网络。 -
layers:包含各种网络层(全连接层、Dropout 层、激活函数等)。
2. 创建顺序模型
python
model = keras.Sequential()
-
Sequential:顺序模型,层与层之间按顺序线性堆叠。上一层的输出就是下一层的输入,适合大多数前馈网络场景。
三、网络层详细分析
第 1 层:隐藏层 1
python
layers.Dense(64, activation='relu', input_shape=(input_dim,))
| 参数 | 含义 | 本层的设置 |
|---|---|---|
Dense |
全连接层 | 每个输入神经元与下一层的 64 个神经元全部相连 |
64 |
神经元数量 | 本层有 64 个神经元 |
activation='relu' |
激活函数 | ReLU(Rectified Linear Unit),公式:f(x)=max(0,x) |
input_shape=(input_dim,) |
输入形状 | 特征数量为 input_dim(比如原代码中 X 有 3 个特征,则 input_dim=3) |
ReLU 的作用:
-
引入非线性(否则多层线性变换等价于一层)
-
计算简单,能缓解梯度消失问题
-
让一部分神经元输出 0(稀疏激活),有助于模型专注重要特征
本层参数量:
text
(input_dim + 1) × 64
其中 +1 是偏置项。如果 input_dim=10,则参数 = (10+1)×64 = 704 个。
第 2 层:Dropout 层(正则化)
python
layers.Dropout(0.2)
| 参数 | 含义 |
|---|---|
0.2 |
Dropout 比例,意味着随机丢弃 20% 的神经元 |
工作原理(仅在训练时生效):
-
对上一层的 64 个输出,以 20% 的概率随机将它们置为 0。
-
剩余的 80% 的神经元的值会按比例放大(除以 0.8),保持整体数值范围。
为什么需要 Dropout?
-
防止过拟合:模型过于依赖某些特定神经元时容易过拟合。通过随机丢弃,强迫模型学到更鲁棒的特征。
-
类似于集成学习:每次训练时都是不同的网络结构,最终相当于多个子网络的平均效果。
注意事项:
-
测试/预测时,Dropout 自动关闭,所有神经元都参与计算。
-
Dropout 比例通常设置在 0.2 ~ 0.5 之间。
第 3 层:隐藏层 2
python
layers.Dense(32, activation='relu')
| 参数 | 含义 |
|---|---|
32 |
神经元数量,比上一层减少一半(64 → 32) |
activation='relu' |
使用 ReLU 激活函数 |
设计思想(漏斗形结构):
-
输入层 → 64 维 → 32 维 → 输出层(1 维)
-
逐步压缩和抽象特征,提取更高层次的表示
-
可以减少参数量,防止过拟合
本层参数量:
text
(64 + 1) × 32 = 2,080
第 4 层:输出层
python
layers.Dense(1, activation='sigmoid')
| 参数 | 含义 |
|---|---|
1 |
输出 1 个值 |
activation='sigmoid' |
Sigmoid 激活函数,公式:σ(z) = 1 / (1+e^-z) |
Sigmoid 函数的输出范围:
-
将任意实数映射到 (0, 1) 区间
-
输出可以解释为 “属于正类的概率”
如何使用输出:
python
prob = model.predict(X) # 输出概率值,如 [0.85] pred_class = (prob > 0.5).astype(int) # 阈值0.5,转换为0或1
本层参数量:
text
(32 + 1) × 1 = 33
四、模型编译配置
1. Optimizer(优化器):adam
-
Adam:Adaptive Moment Estimation(自适应矩估计)
-
为什么选 Adam?
-
结合了 SGD with Momentum 和 RMSProp 的优点
-
自适应学习率,不需要手动精细调节
-
收敛快,适合大多数实际任务
-
替代选项:
-
'sgd':标准随机梯度下降(需要调学习率) -
'rmsprop':适合循环神经网络
2. Loss Function(损失函数):binary_crossentropy
-
公式:
Loss = -[y*log(p) + (1-y)*log(1-p)] -
适用范围:专用于二分类问题
-
直观理解:
-
当真实标签 y=1 时,Loss = -log(p),预测概率 p 越接近 1,损失越小
-
当真实标签 y=0 时,Loss = -log(1-p),预测概率 p 越接近 0,损失越小
-
如果误用其他损失函数会怎样?
-
用
mse:梯度更新变慢,收敛困难 -
用
categorical_crossentropy:需要 one-hot 编码输出(2 维),不适合此处
3. Metrics(评估指标):['accuracy']
-
Accuracy = (TP + TN) / (TP + TN + FP + FN)
-
只是记录和显示,不影响梯度更新(损失函数才是优化目标)
五、模型结构可视化
Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense (Dense) (None, 64) 704 _________________________________________________________________ dropout (Dropout) (None, 64) 0 _________________________________________________________________ dense_1 (Dense) (None, 32) 2080 _________________________________________________________________ dense_2 (Dense) (None, 1) 33 ================================================================= Total params: 2,817 Trainable params: 2,817 Non-trainable params: 0 _________________________________________________________________
关键信息:
-
Output Shape中的None表示批次大小(batch size),可以是任意值 -
Param #是待训练的参数数量 -
Dropout 层没有参数,只改变前向传播行为
六、训练与预测流程
训练模型
python
history = model.fit(
X_train, y_train,
epochs=50, # 训练50轮
batch_size=32, # 每批32个样本
validation_split=0.2 # 用20%训练数据作为验证集
)
评估模型
python
test_loss, test_acc = model.evaluate(X_test, y_test)
print(f"测试准确率: {test_acc:.4f}")
预测新样本
python
# 预测概率 probabilities = model.predict(new_data) # 转成类别 (0或1) predictions = (probabilities > 0.5).astype(int)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)