Medical Thinking with Multiple Images论文精读
·
这篇论文题为 《Medical Thinking with Multiple Images》 ,提出了一个名为 MedThinkVQA 的专家标注的多图像医学推理评测基准。以下是对论文核心问题与解决方法的详细解析。
一、论文提出的核心问题
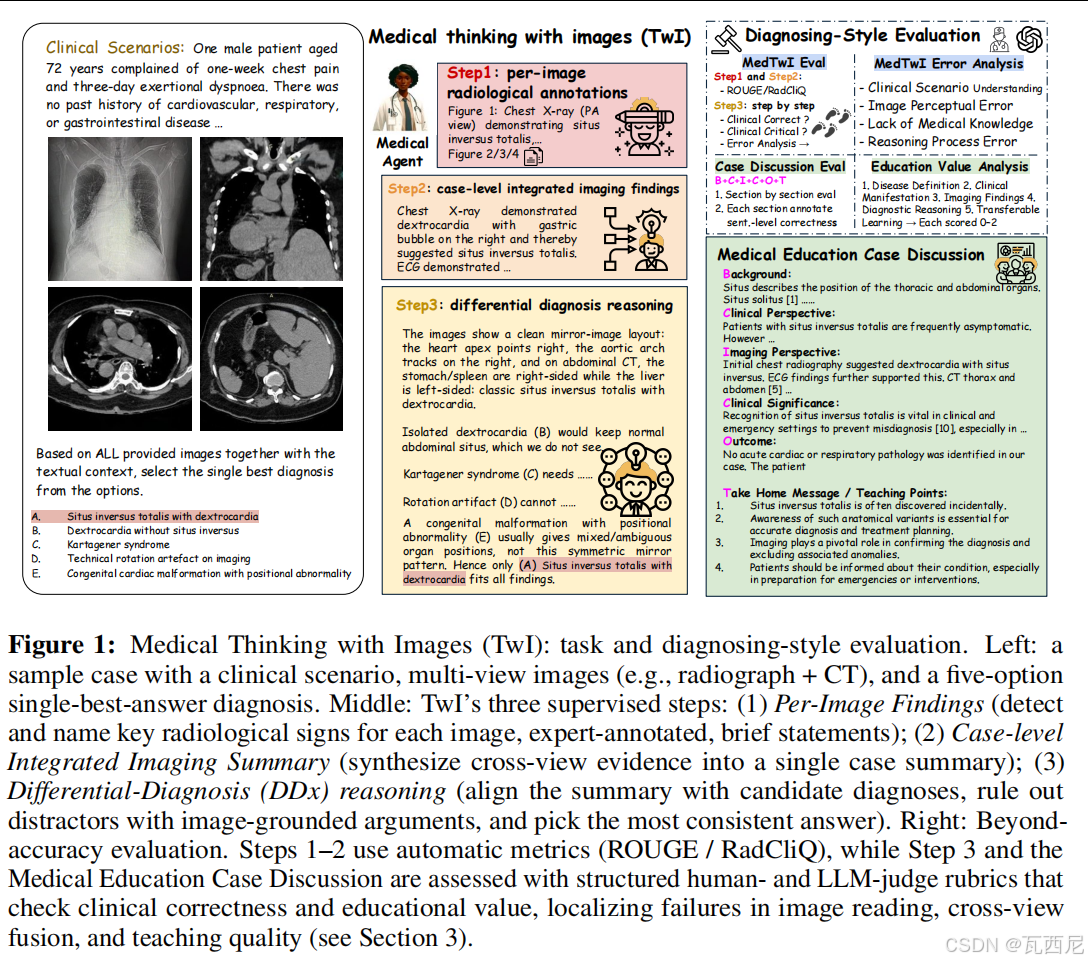
1. 现有医学 VQA 基准的局限性
- 大多数医学视觉问答(VQA)基准只包含单张图像的问题,而真实临床诊断往往需要综合多张图像(如不同模态、不同时间点)的证据。
- 现有模型虽然在单图像/单模态任务上表现良好,但在多图像推理中暴露出严重短板,尤其是在:
- 图像证据提取(grounding)
- 跨图像证据对齐(alignment)
- 多视图信息融合(composition)
2. 最终答案准确率 ≠ 真正的临床推理能力
- 许多模型在最终答案上表现不错,但在中间推理步骤(如影像发现、综合摘要、鉴别诊断)中存在严重错误。
- 缺乏对推理过程的细粒度评估,导致模型在临床真实场景中不可靠。
3. 缺乏高质量的多图像医学推理基准
- 现有数据集(如 MMMU、MedXpertQA 等)要么是非专家标注,要么是单图像,要么缺乏中间推理监督。
- 论文提出需要一种专家标注、多图像、带推理步骤、支持教育评估的基准。
二、提出的解决方案:MedThinkVQA
1. 数据集构建
- 来源:Eurorad(欧洲放射学会的同行评审教学病例库)
- 规模:8,067 个病例,其中测试集 720 例
- 图像密度:平均每例 6.62 张图像(远超此前基准的 ≤1.43)
- 多模态覆盖:包括 CT、MRI、X 光、超声、病理、内镜等 9 种模态
- 纵向病例:30.4% 的病例包含多个时间点的随访影像
2. 三步骤推理结构(Think-with-Images, TwI)
每个病例被结构化地拆解为三个可监督的推理步骤:
- Per-Image Findings
对每张图像提取关键影像学发现(专家标注) - Case-Level Integrated Imaging Summary
综合所有图像的发现,形成统一的影像学总结 - Differential-Diagnosis Reasoning
基于总结,排除干扰项,选择最可能的诊断
3. 医学教育讨论任务
- 模型需生成结构化的教学讨论(背景、临床、影像、预后、关键点)
- 评估其教育价值和临床实用性
4. 超越准确率的评估体系
- 自动评估:ROUGE / RadCliQ(影像摘要质量)
- 步骤级评估:将模型输出拆解为原子步骤,使用 LLM 判断事实性、关键性、错误类型
- 错误类型分类:
- 图像理解错误(Image Understanding Err)
- 推理错误(Reasoning Err)
- 医学知识错误(Medical Knowledge Err)
- 临床场景错误(Clinical Scenario Err)
- 人类专家验证:两位临床专家对 50 个案例进行标注,Cohen’s κ = 0.82,验证自动评估可靠性
三、主要实验结果与发现
1. 当前模型表现仍然有限
- 最佳闭源模型(Claude-4.6-Opus)准确率仅为 57.2%
- 最佳开源模型(Qwen3.5-397B)为 52.2%
- 远低于人类专家(77.1%)
2. 核心瓶颈:多图像推理能力不足
- 提供专家标注的影像文本(如综合摘要)可显著提升模型准确率(提升 2 倍+)
- 模型自己生成的影像描述反而会降低准确率(下降 3–12.5 点)
- 说明当前模型在可靠地提取和对齐多图像证据方面存在根本性困难
3. 推理长度帮助有限
- 增加推理 token(thinking mode)能提升部分模型(如 GPT-5、Qwen3.5 大模型)
- 但对小模型或视觉基础差的模型,更长推理反而放大早期错误
4. 错误集中在图像理解与跨视图融合
- 在错误步骤中,77.27% 涉及图像理解
- 即使是关键错误步骤,图像理解仍占主导(69.23%)
四、论文贡献总结
- 提出 MedThinkVQA:第一个专家标注、多图像、带中间推理监督的医学 VQA 基准
- 设计三步骤推理结构:使诊断过程可观察、可评估、可监督
- 建立多维度评估体系:包括步骤级事实性、错误类型、教育价值等
- 公开数据集与代码:提供 HuggingFace 数据集、GitHub 代码、在线排行榜
- 揭示模型关键短板:当前医学 VLM 的主要瓶颈是跨图像证据提取与融合,而非单纯推理长度不足
五、研究意义与未来方向
- 意义:推动医学 VQA 从“答题”走向“真实诊断推理”,强调过程监督而非结果导向。
- 未来方向:
- 证据级别的监督学习(evidence-level supervision)
- 多图像结构建模(view-aware memory, temporal indexing)
- 工具增强推理(检索、不确定性触发、外部知识验证)
数据集开源地址

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)