Spatial Reasoning with Vision-Language Models in Ego-Centric Multi-View Scenes论文精读
·
这篇论文《Spatial Reasoning with Vision-Language Models in Ego-Centric Multi-View Scenes》主要解决的是视觉语言模型在“以自我为中心的多视角场景”中的3D空间推理能力不足的问题。以下是论文的问题定义与解决方法的核心解析:
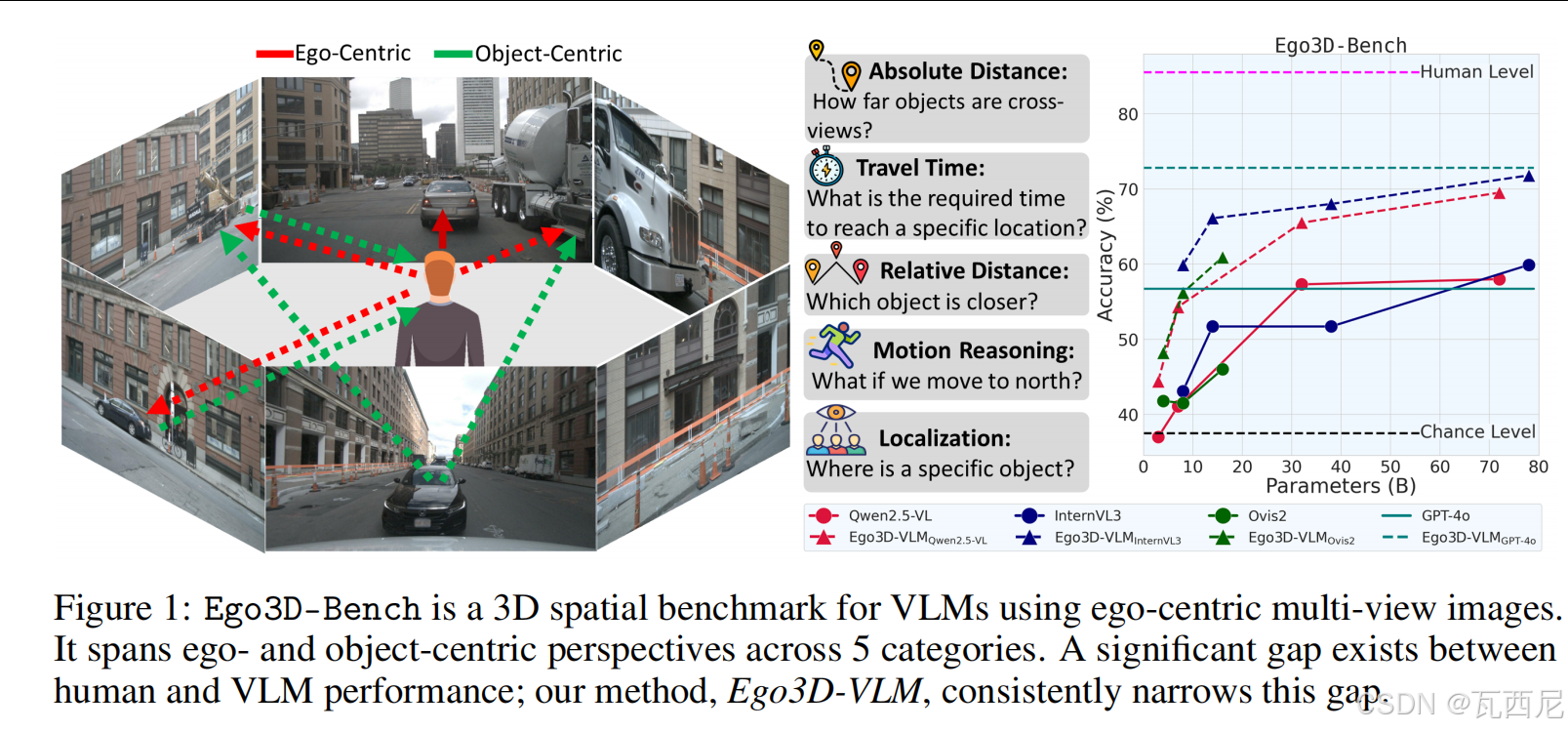
一、论文提出的问题
1. 现有空间推理基准的局限性
- 大多数现有的空间推理数据集(如VSI-Bench)基于单张图像或室内静态场景的视频。
- 这些数据不符合真实世界中具身智能体(如自动驾驶汽车、机器人)的感知方式——后者依赖的是多视角、以自我为中心、动态变化的场景。
- 现有基准缺乏对“多视角空间语义一致性”和“随时间变化的动态空间推理”的评估。
2. 现有VLM在空间推理上的不足
- 即使是SOTA模型(如GPT-4o、Gemini-1.5-Pro)在复杂多视角3D空间任务上表现远低于人类水平。
- 模型难以构建统一的空间世界模型,尤其是在缺乏显式3D坐标和视角变换能力的情况下。
二、论文提出的解决方案
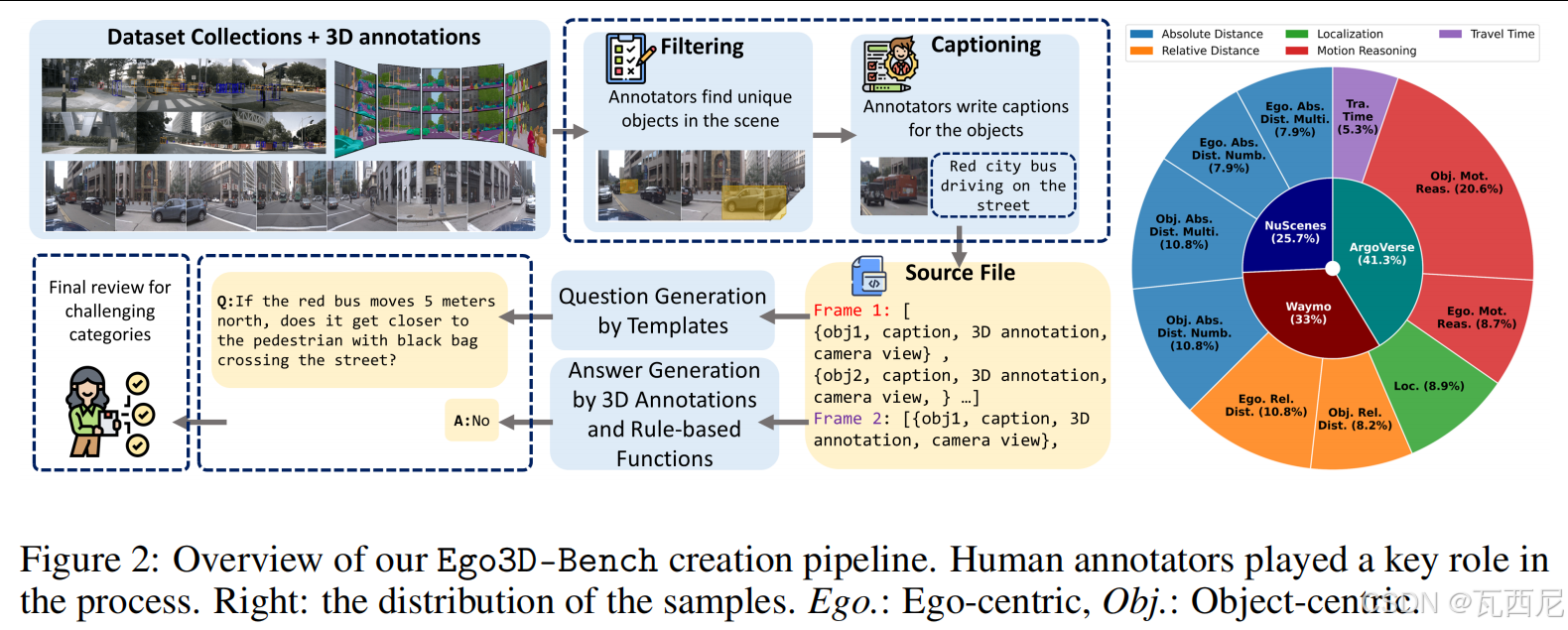
1. 提出新基准:Ego3D-Bench
- 从三个公开数据集(nuScenes、Waymo、Argoverse)中构建了8,600+个QA对。
- 包含5类任务:
- 绝对距离估计(ego-centric / object-centric)
- 相对距离比较
- 定位(从对象的视角)
- 运动推理(ego / object)
- 行程时间估计
- 每类任务都分为多选问答或绝对数值估计两种形式。
- 数据构建过程中大量依赖人工标注,确保质量与多样性。
2. 提出增强方法:Ego3D-VLM
- 是一个即插即用的后训练框架,不改变原VLM结构。
- 核心思想:生成文本形式的“认知地图”,而不是点云或BEV图像。
具体步骤:
- 使用REC模型(如Grounding-DINO)定位目标对象的2D边界框。
- 使用深度估计模型(如Depth-Anything-V2)获取每个目标的距离信息。
- 将2D点转换为3D点(相机坐标系 → 全局坐标系)。
- 构建“文本认知地图”,包含:
- 目标的3D坐标
- 视角(如front-view、left-view)
- 对象描述
- 将认知地图与原始多视角图像一起输入VLM进行最终问答。
3. 实验结果
- Ego3D-VLM在多个VLM上(GPT-4o、Qwen2.5、InternVL3等)实现了:
- 平均12%的准确率提升(多选问答)
- 56%的RMSE下降(绝对距离估计)
- 显著缩小了VLM与人类之间的空间推理差距。
三、论文的贡献总结
| 贡献 | 说明 |
|---|---|
| 新基准 | 首个面向“以自我为中心的多视角动态场景”的3D空间推理基准 |
| 新方法 | 提出轻量、高效的“文本认知地图”增强方法,避免点云/ BEV的高计算成本 |
| 实验全面 | 评测16个SOTA VLM,包括闭源、开源、3D专用模型 |
| 可插拔性 | Ego3D-VLM可无缝集成到任意VLM中,无需重新训练 |
数据集开源地址

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)