LLM基础知识
大语言模型 (LLM)
大语言模型 (英文:Large Language Model,缩写LLM) 是一种人工智能模型, 旨在理解和生成人类语言. 大语言模型可以处理多种自然语言任务,如文本分类、问答、翻译、对话等等.
通常, 大语言模型 (LLM) 是指包含数千亿 (或更多) 参数的语言模型(目前定义参数量超过10B的模型为大语言模型),这些参数是在大量文本数据上训练的,例如模型 GPT-3、ChatGPT、GLM、BLOOM和 LLaMA等.
语言模型 (Language Model, LM)
语言模型(Language Model)旨在建模词汇序列的生成概率,提升机器的语言智能水平,使机器能够模拟人类说话、写作的模式进行自动文本输出。
用来计算一个句子的概率的模型,也就是判断一句话是否是人话的概率.
你可以把语言模型理解成一个 **“会猜下一个词” 的 AI**。
比如你说:
“黑马程序____”
语言模型会根据大量文本经验,算出后面接 “员” 的概率最高,接 “来”“学习” 的概率很低,所以它会帮你补全成 “黑马程序员”。
- 词典里只有这几个词:
{黑马、程序、员、来、学习} - 语言模型的目标:给任意一串词(比如
W1,W2,...,Wn),算出它是一句合理中文的概率 P (S)
举个例子:
- 句子 A:
黑马 程序 员→ 这是合理的,P (S) 高 - 句子 B:
员 来 黑马→ 这是乱的,P (S) 低
语言模型的核心,就是给不同的词序列打分(算概率),以此判断哪个句子更通顺。
方法1
统计数据集中,某个句子出现的次数 n,除以总句子数 N,就是 P (S)=n/N
比如:
- 数据集里有 1000 个句子,
黑马程序员出现了 10 次,那它的概率就是 10/1000=0.01 - 但如果有一个句子,数据集中从来没出现过,比如
黑马来学习,那 n=0,P (S)=0
❌ 这个方法的致命问题:现实中,大部分通顺的句子,一辈子都不会在训练数据里重复出现。比如你说一句很普通的话,AI 之前没见过,按这个方法就会判它概率为 0,显然不合理。
方法2
概率论的链式法则
为了解决上面的问题,我们把整个句子的概率,拆成 **“一个词一个词猜” 的概率相乘 **,也就是图片里的公式:
\(P(S) = P(W_1,W_2,...,W_n) = P(W_1) \times P(W_2|W_1) \times ... \times P(W_n|W_1,...,W_{n-1})\)
用大白话解释:
- \(P(W_1)\):句子第一个词是
黑马的概率(比如语料里 10% 的句子以 “黑马” 开头) - \(P(W_2|W_1)\):在第一个词是
黑马的前提下,第二个词是程序的概率(比如语料里,“黑马” 后面 90% 接的是 “程序”) - \(P(W_3|W_1,W_2)\):在前面是
黑马 程序的前提下,第三个词是员的概率(几乎是 100%)
把这些概率乘起来,就得到了整个句子的概率。
这样就算是从没见过的新句子,也能通过 “前面的词猜后面的词” 算出概率,不会直接判为 0 了。
每一步都在根据前面的内容,算 “下一个词的概率分布”,选概率最高的词输出,再接着算下一个,以此类推生成整段话。
假设我们要算句子黑马 程序 员的概率:
- 第一步:选第一个词,P (黑马)=0.1
- 第二步:在 “黑马” 后面,选第二个词,P (程序 | 黑马)=0.9
- 第三步:在 “黑马 程序” 后面,选第三个词,P (员 | 黑马,程序)=0.99
- 整个句子的概率 = 0.1 × 0.9 × 0.99 = 0.0891
这个值越高,说明句子越通顺合理。
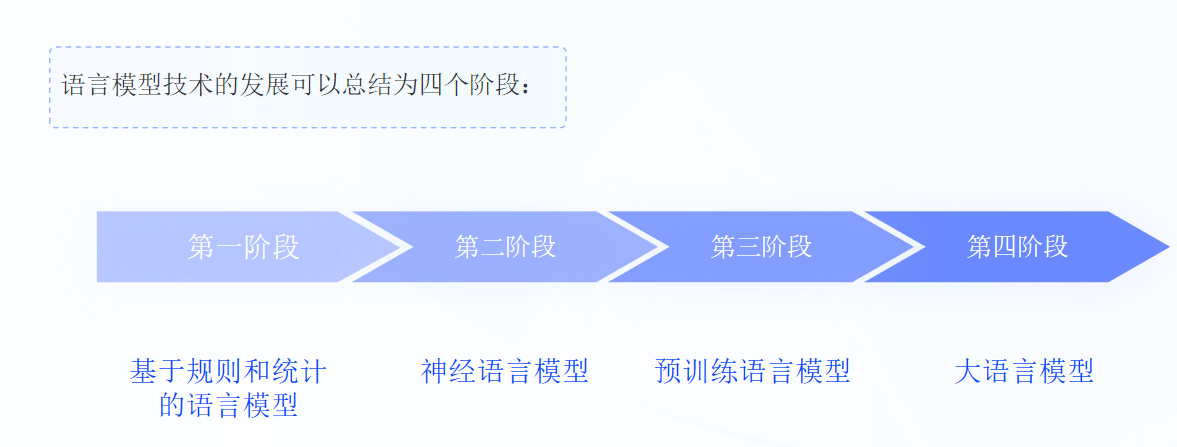
| 语言模型技术发展四个阶段特点与进化特点 | ||
| 发展阶段 | 核心特点 | 进化特点 |
| 第一阶段:基于规则和统计的语言模型 | 1. 核心建模方法:基于n-gram概率统计模型,通过词序列频率预测下一个词,采用极大似然估计训练参数 2. 优势:参数易训练,可解释性强,实现了从人工规则到数据驱动的初步转变 3. 局限:受限于维度灾难,无法有效处理长距离依赖;数据稀疏问题严重,泛化能力差,存在明显的OOV(未登录词)问题 |
1. 奠定了语言模型的基础理论框架,首次实现了基于统计的序列概率建模,为后续语言模型发展提供了核心基础 2. 突破了早期纯人工规则语言模型的泛化能力瓶颈,实现了语言建模从人工设计到数据驱动的第一次范式升级 |
| 第二阶段:神经语言模型 | 1. 核心建模方法:基于深度学习神经网络,引入词嵌入(Word Embedding)技术,将词映射到连续向量空间,解决数据稀疏性问题 2. 核心结构:采用RNN/LSTM/ELMo等网络结构,实现了上下文感知的动态语义表征,能更好捕捉词语间的复杂语义关系 3. 局限:可解释性下降,训练成本提升,长距离依赖问题仍未完全解决,并行训练效率低 |
1. 实现了从离散统计建模到连续语义空间建模的关键跨越,彻底解决了统计语言模型的数据稀疏核心痛点 2. 首次实现了上下文相关的动态词向量表征,大幅提升了模型对自然语言语义的理解能力,为后续预训练模型的发展奠定了深度学习技术基础 |
| 第三阶段:预训练语言模型 | 1. 核心范式:采用"预训练+微调"的全新任务范式,在海量通用语料上完成预训练,再通过少量微调适配不同下游任务 2. 核心架构:基于Transformer架构,引入自注意力机制,彻底解决了长距离依赖问题,实现了高效的并行训练 3. 核心优势:模型迁移能力大幅增强,一个模型可服务多个NLP任务,无需人工构造特征,模型规模从亿级扩展到百亿级,涌现出初步的通用语言能力 |
1. 彻底颠覆了NLP领域的传统任务范式,实现了从"单任务单模型"到"通用预训练+下游微调"的革命性转变 2. Transformer架构的引入解决了长程依赖和并行训练的核心技术痛点,大幅提升了模型的训练效率和语义建模能力 3. 首次实现了通用语言能力的初步涌现,为大语言模型的爆发式发展提供了核心技术支撑和范式基础 |
| 第四阶段:大语言模型 | 1. 规模特征:模型规模实现指数级扩张,从百亿级参数扩展到万亿级参数,采用大规模自回归预训练模式 2. 能力特征:涌现出强大的涌现能力,包括少样本/零样本学习、指令跟随、逻辑推理、多模态理解、复杂任务规划等类人智能能力 3. 应用特征:无需微调即可适配大量下游任务,实现了通用人工智能的初步落地,可覆盖文本生成、知识问答、代码编写、逻辑推理等全场景应用 4. 局限:训练和推理成本极高,对算力和数据规模有极高要求,模型可解释性进一步下降,存在幻觉输出、安全合规等伦理与技术挑战 |
1. 实现了语言模型从"专用语言处理"到"通用人工智能"的根本性跨越,模型能力从单一的语言理解与生成,扩展到多领域的通用智能任务处理 2. 涌现能力的出现突破了传统语言模型的能力边界,首次实现了类人的逻辑推理和复杂开放任务的处理能力,重新定义了AI技术的能力上限 3. 推动了AI技术的全场景商业化落地,开启了通用人工智能的新时代,同时也带来了全新的技术研发、安全合规与伦理治理挑战 |
| 阶段 | 核心方法 | 代表模型 | 关键优势 | 主要局限 |
|---|---|---|---|---|
| 1️⃣ 规则 / 统计 | 人工规则 + 词频统计 | N-gram | 原理简单、计算快 | 参数爆炸、数据稀疏、无法处理长文本 |
| 2️⃣ 神经语言模型 | 神经网络 + 词向量 | NNLM、RNN-LM | 解决稀疏问题、能学词的语义 | 模型容量小、处理长文本能力差 |
| 3️⃣ 预训练语言模型 | Transformer + 预训练 + 微调 | BERT、GPT-1/2 | 通用知识迁移、适配多任务 | 模型规模不足、能力仍有限 |
| 4️⃣ 大语言模型 | 超大规模预训练 + 涌现能力 | GPT-3/4、LLaMA、文心一言 | 通用智能、复杂推理、多轮对话 | 训练成本极高、推理成本高、有幻觉问题 |
语言模型的评估指标
| 指标分类 | 指标名称 | 测的是什么(大白话) | 怎么看好坏 | 核心适用场景 | 关键注意事项 / 补充 |
|---|---|---|---|---|---|
| 基础分类指标(所有 AI 模型通用,LLM 分类任务可用) | Accuracy(准确率) | 模型整体猜对的比例,也就是猜对的样本数占总样本数的多少 | 数值越高越好,最高 100% | 各类分类任务的整体正确率评估 | 样本不均衡时会 “骗人”:比如 100 个样本里 99 个是 A 类,模型全猜 A 也能有 99% 准确率,但实际没学会分类能力 |
| 基础分类指标(所有 AI 模型通用,LLM 分类任务可用) | Precision(精确率 / 查准率) | 模型说 “是正类” 的结果里,真正是正类的比例,也就是模型猜的正结果里,有多少是真的对的 | 数值越高越好,最高 100% | 需要控制 “误报” 的场景,比如阳性检测、垃圾邮件识别 | 代表模型猜得准不准,数值越高,误报的情况越少 |
| 基础分类指标(所有 AI 模型通用,LLM 分类任务可用) | Recall(召回率 / 查全率) | 所有真正的正类里,被模型成功找出来的比例,也就是真实的正样本里,有多少被模型抓到了 | 数值越高越好,最高 100% | 需要控制 “漏报” 的场景,比如疾病筛查、违规内容识别 | 代表模型找得全不全,数值越高,漏报的情况越少 |
| 生成类任务专用指标(LLM 生成任务标配) | BLEU 分数 | 专门评估机器翻译的质量,把模型生成的译文和人工标准答案对比,看连续的词块(n-gram)重合度有多少 | 取值 0~1,越接近 1 越好,数值越高说明译文和人工翻译越一致,质量越好 | 机器翻译任务的质量评估 | 会同时看 1-4 个连续词的重合度,再加权计算总分,是翻译领域的通用核心指标 |
| 生成类任务专用指标(LLM 生成任务标配) | ROUGE 指标 | 主要评估文本摘要、问答生成的质量,看模型生成的内容,覆盖了多少参考答案里的关键信息 | 取值 0~1,越接近 1 越好,数值越高说明生成的内容越贴合参考答案,关键信息越完整 | 文本摘要、问答生成、文案创作等生成类任务 | 常见有 ROUGE-N(看连续词块重合度)、ROUGE-L(看最长公共子序列长度),是生成类任务的核心评估指标 |
| 语言模型特有指标 | PPL(困惑度) | 衡量语言模型对句子的预测能力,也就是模型觉得这句话有多通顺、多合理 | 数值越低越好,数值越小,说明模型越确定这句话是通顺合理的,模型的基础语言能力越好 | 语言模型基础能力的通用评估,是 LLM 预训练阶段的核心优化指标 | 本质是基于句子概率计算的,句子出现的概率越高,PPL 越低,模型表现越好;比如通顺的句子 PPL 低,混乱的句子 PPL 高 |
| 指标 | 主要用途 | 好坏标准 |
|---|---|---|
| Accuracy | 分类任务整体正确率 | 越高越好 |
| Precision | 看 “猜的准不准”,控制误报 | 越高越好 |
| Recall | 看 “找的全不全”,控制漏报 | 越高越好 |
| BLEU | 机器翻译质量评估 | 越高越好(越接近 1) |
| ROUGE | 文本摘要 / 问答生成质量评估 | 越高越好(越接近 1) |
| PPL | 语言模型基础能力评估 | 越低越好 |
python实现PPL指标的计算
LLm主要模型
- 自编码模型(Encoder-only):理解文本的 “阅读理解大师”
- 自回归模型(Decoder-only):生成文本的 “写作 / 聊天大师”
- 序列到序列模型(Encoder-Decoder):先理解再生成的 “翻译 / 摘要大师”
1️⃣ 自编码模型(Encoder-only,代表:BERT)
核心玩法
它只有 Transformer 的 Encoder 部分,训练时玩的是「完形填空游戏」:
- 随机把句子里的一些词盖住(MASK)
- 让模型根据前后所有词,猜被盖住的词是什么
- 比如:“今天天气很 [MASK],适合出门” → 模型猜 “好”
特点
- 它能同时看到整句话的上下文(前后文双向都能看)
- 重点是理解语义,不是生成新句子
- 训练目标:把句子的每一个词,都学到它在语境里的含义
适合任务
所有需要 “理解文本” 的任务:
- 文本分类(情感分析、新闻分类)
- 问答(比如从文章里找答案)
- 语义相似度判断(判断两句话是不是一个意思)
2️⃣ 自回归模型(Decoder-only,代表:GPT 系列)
核心玩法
它只有 Transformer 的 Decoder 部分,训练时玩的是「接龙游戏」:
- 给模型前面的词,让它预测下一个词
- 比如:“我今天去公园____” → 模型猜 “散步”
- 生成时一个词一个词往外蹦,前面的词会影响后面的预测
特点
- 只能从左往右看文本(单向的),永远看不到还没生成的词
- 重点是生成连贯文本,而不是做理解类任务
- 你平时用的 ChatGPT、GPT-4,都是这类模型
适合任务
所有需要 “生成文本” 的任务:
- 对话聊天、写文案、写代码
- 续写、翻译、创作
- 它也能做理解任务,但本质是靠 “生成式理解”,不是原生强项
3️⃣ 序列到序列模型(Encoder-Decoder,代表:T5、BART)
核心玩法
完整的 Transformer 架构,既有 Encoder 也有 Decoder:
- Encoder(编码器):先把输入文本 “读明白”,压缩成一个向量表示
- Decoder(解码器):再根据这个向量,生成目标文本
举个例子,机器翻译:
- Encoder 读英文句子:
I love cats - 把它编码成向量
- Decoder 根据向量,生成中文:
我喜欢猫
特点
- 天生适合 “输入一段文本,输出另一段文本” 的任务
- Encoder 负责理解,Decoder 负责生成,分工明确
- 比纯 Encoder 多了生成能力,比纯 Decoder 更擅长处理输入输出不同结构的文本
适合任务
- 机器翻译(最经典的场景)
- 文本摘要(输入长文章,输出短摘要)
- 问答生成(输入问题,输出完整答案)
- 改写、润色文本
| 模型类型 | 结构 | 核心能力 | 代表模型 | 最适合场景 |
|---|---|---|---|---|
| 自编码模型 | Encoder-only | 双向理解、语义编码 | BERT、RoBERTa | 文本分类、情感分析、问答 |
| 自回归模型 | Decoder-only | 单向生成、文本续写 | GPT 系列、LLaMA | 对话、创作、代码生成 |
| 序列到序列模型 | Encoder-Decoder | 先理解再生成 | T5、BART | 机器翻译、文本摘要 |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)