创新实训(8)—— 问答系统(RAG优化1)
针对传统 RAG 在多轮对话中容易出现的上下文指代不明的问题,我主要通过查询重写机制以及结构化 Prompt 进行了改进,并设计了相关测试来验证优化效果。
一、原始RAG的实现
目前问答系统中引入了RAG,使得模型的回答能更能针对408考研这一领域,具体实现流程如下:爬取 408 笔记 → 清洗文本 → 图片转文字 → 向量化存入本地库 → 用户提问时检索相关知识 → 交给大模型生成专业答案。
具体而言,在接收到用户的问题后,先把用户发的图片/文件链接从问题里删掉,只保留干净的问题文本,避免文件链接干扰检索;随后将用户问题变成向量,在chroma库里找最相似的2条知识,返回格式化的参考资料;然后给模型设定严格身份,RAG规则,并将检索到的知识库内容+文件内容+用户内容拼在一起,从而将增强后的Prompt发给大模型,实现检索增强。
二、 改进说明
1. 引入基于历史记忆的查询重写
存在的问题: 多轮对话中,用户常使用代词或省略主语(例如前一轮问“TCP三次握手”,下一轮问“为什么不能是两次?”)。若直接将短句送入 ChromaDB 检索,无法召回有效资料。
解决方案: 在进行向量检索前,增加了一个判定与重写逻辑。若用户输入字数较短(<20字)且存在历史对话,则调用一次大模型,结合最近的几轮历史记录,将当前提问重写为一个包含完整主语的独立搜索词,然后再进行检索。
Python
# 判定与重写逻辑简述
if not history_messages or len(current_query) > 20:
return current_query
# 提取近期历史并让模型重写
system_prompt = "你是搜索关键词优化专家。根据历史对话,将用户的最新简短回复重写为一个清晰、完整、包含主语的独立搜索问题..."
2. 使用 XML 伪标签结构化 Prompt
存在的问题: 之前将检索到的参考资料、文件内容与用户提问进行简单的纯文本拼接,大模型在处理时容易混淆信息边界,产生幻觉。
解决方案: 采用了类似 XML 的标签格式,对不同的上下文内容进行物理隔离,并给定了严格的答题前置规则。
Python
# 结构化 Prompt 示例
augmented_prompt += f"<用户附件内容>\n{file_text}\n</用户附件内容>\n\n"
augmented_prompt += f"<知识库检索参考>\n{rag_context}\n</知识库检索参考>\n\n"
augmented_prompt += f"<当前用户提问>\n{clean_text}\n</当前用户提问>"
3. 引入线程池解决同步阻塞问题
存在的问题: FastAPI 是基于异步事件循环的框架。如果在 async def 定义的路由中直接执行原生的 SQLAlchemy 同步查询,或是调用 ChromaDB 这种 CPU 密集的本地向量检索,会造成主线程阻塞,导致系统无法处理其他并发请求。
解决方案: 引入 fastapi.concurrency.run_in_threadpool 和 asyncio.to_thread,将耗时的同步任务交由后台线程池处理。
三、 测试对比实验流程
为了验证“查询重写”功能对多轮对话检索准确率的影响,在接口中增加了一个入参 use_optimized: bool = Query(True) 作为功能开关,并在 Swagger UI 中进行了对比测试。
1. 测试环境准备
调用 /api/chat/sessions 接口,使用同一user_id连续创建两个全新的会话(session 19、20),以保证两组测试的初始状态相互隔离,并且不受之前聊天上下文的影响。
2. 测试步骤
-
首轮对话(上下文构建):
对 Session 19 和 20 发送基础提问:“请问TCP三次握手是什么?”
此时判断为首轮对话,会跳过重写直接检索。
-
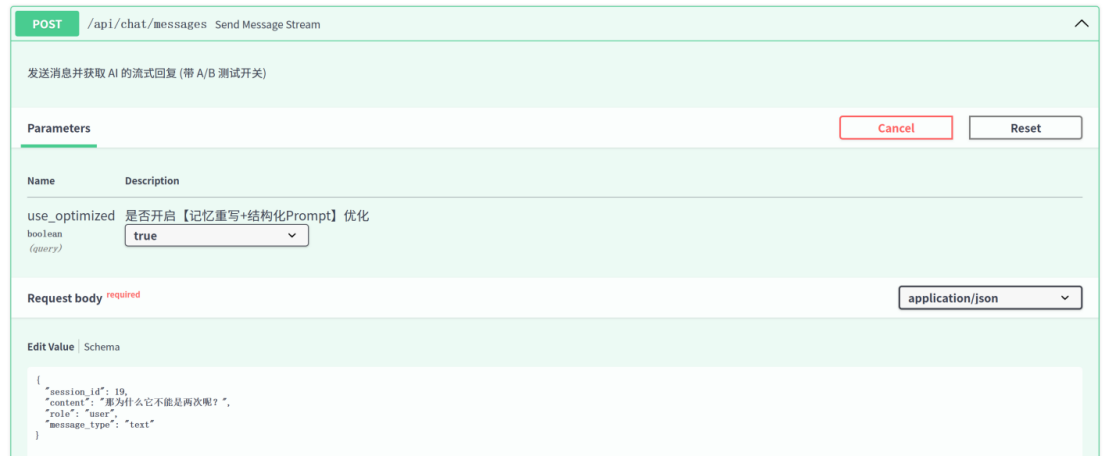
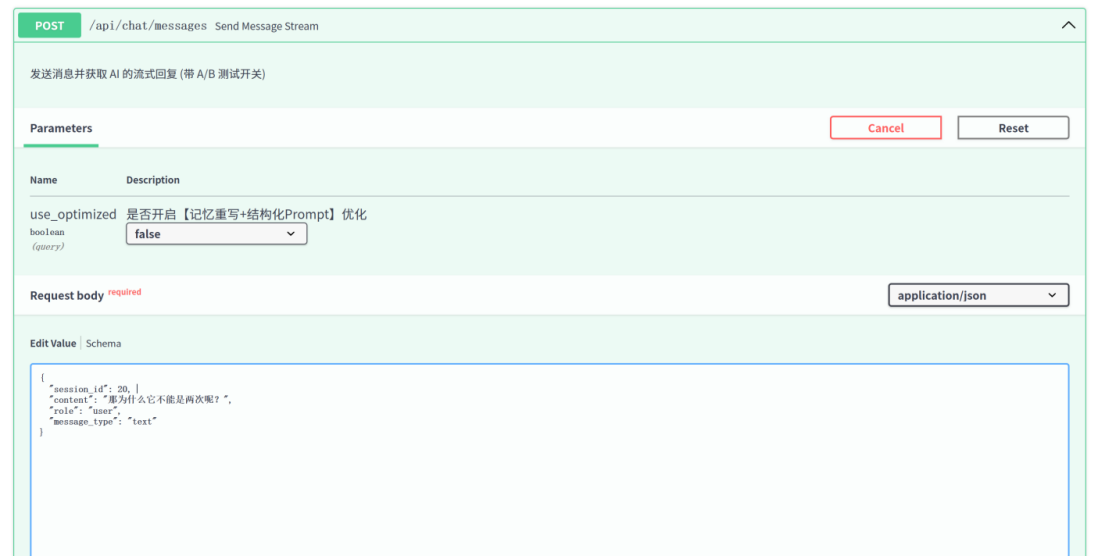
第二轮对话:
对 Session 19 和 20 发送问题:“那为什么它不能是两次呢?”
3. 测试结果对比
对照组(Session 20,原始未优化RAG):
-
执行逻辑: 系统跳过重写机制,直接使用字符串“
那为什么它不能是两次呢?”在本地 ChromaDB 中进行向量检索。 -
结果表现: 由于检索词缺失关键背景,知识库未能命中与 TCP 相关的资料。大模型最终输出的内容较为发散,缺乏针对性的回答。
-
回答结果:“无论是在计算机网络CSMA/CD协议的碰撞重传中,还是在数据结构二叉树的后序遍历中,“三次”机制都是为了确保操作的稳定性与完整性;其中第三次重传能够通过扩大延迟时间的随机选择范围,更有效地降低网络再次发生冲突的概率,而后序遍历则必须经过“先左子树、后右子树、再根节点”的第三次路过,才能保证所有节点被按序且毫无遗漏地访问,这些保障通信稳定与遍历完整的目标都是仅靠“两次”操作所无法实现的。”
优化组(Session 19,优化后RAG):
-
执行逻辑: 系统触发
rewrite_query_with_memory函数。对问题根据上下文进行重写。 -
日志输出: 终端日志显示原话被重写,原问题“
为什么它不能是两次呢?”被重写为“TCP三次握手为什么不能是两次?”。 -
结果表现: 使用重写后的查询语句进行检索,成功召回了教材中关于 TCP 连接可靠性的对应段落。给出了更针对TCP的回答。
-
回答结果:“TCP必须进行三次握手而不是两次,是为了确保双方能正确同步初始序列号,并有效防止“半打开”或“历史重复”等错误连接,从而建立真正可靠的通信环境。”
对比分析:
优化后:讨论的是【计算机网络】中的 TCP 三次握手。
优化前:讨论的是【计算机网络】的 CSMA/CD 碰撞重传 与【数据结构】的 二叉树后序遍历。
由此可见优化后RAG更能理解到用户实际想要知道的问题,回答更具针对性,但是如此限制其发散性的回答是否会存在一些弊端比如陷入一个知识点的学习,无法串起来相似知识点仍有待确认。
三、 总结
当前系统的功能验证仅依赖于单一测试用例,缺乏系统性的量化评估,难以全面评估模型在实际应用场景下的泛化能力与检索准确度。下一步,我打算构建一个小型的测试集,并引入更为客观的的量化评估指标体系。同时,为突破现有检索性能瓶颈,计划进一步调研并融合前沿的RAG技术范式(如混合检索、重排机制或 Self-RAG 等),对现有的 RAG 架构进行更深入的调优。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)