基于深度学习的棉田昆虫图像智能分类系统
一、项目背景
棉花作为重要的经济作物,在种植过程中常常受到各类昆虫的影响。其中既有棉铃虫等害虫,也有瓢虫、草蛉等益虫。准确识别和分类这些昆虫对于棉田的精准管理和病虫害防治具有重要意义。传统的人工识别方法不仅耗时耗力,而且容易受到经验和主观因素的影响。随着深度学习技术的快速发展,基于计算机视觉的昆虫自动识别系统为解决这一问题提供了新的思路。本项目开发了一套完整的棉田昆虫图像分类系统,能够快速准确地识别棉田中常见的10类昆虫,为智慧农业提供技术支持。
二、数据集介绍
本项目使用的棉田昆虫分类数据集包含10个类别,共计2965张高质量昆虫图像。数据集经过精心筛选和标注,过滤掉了183张包含多个目标的复杂图像,确保每张图片只包含单一类别的昆虫个体,从而提高模型训练的效果。数据集按照7:2:1的比例划分为训练集、验证集和测试集,分别包含2070张、590张和305张图像。
表2-1:数据集类别分布
| 类别编号 | 类别名称 | 中文名称 | 图像数量 | 类别权重 | 类别属性 |
| 0 | bee | 蜜蜂 | 161 | 1.8482 | 益虫 |
| 1 | bollworm | 棉铃虫 | 535 | 0.5535 | 害虫 |
| 2 | lacewing | 草蛉 | 381 | 0.7782 | 益虫 |
| 3 | ladybug_dy | 大眼瓢虫 | 594 | 0.4988 | 益虫 |
| 4 | ladybug_hb | 红斑瓢虫 | 161 | 1.8482 | 益虫 |
| 5 | ladybug_lbq | 龟纹瓢虫 | 164 | 1.8158 | 益虫 |
| 6 | stinkbug_ccc | 茶翅蝽 | 141 | 2.1122 | 害虫 |
| 7 | stinkbug_hsy | 红色蝽象 | 260 | 1,1374 | 害虫 |
| 8 | stinkbug_mc | 麻皮蝽 | 448 | 0.6613 | 害虫 |
| 9 | stinkbug_mx | 麻蝽 | 120 | 2.4643 | 害虫 |
从数据分布可以看出,数据集存在一定的类别不平衡问题。大眼瓢虫和棉铃虫的样本数量较多,分别达到594张和535张,而麻蝽和茶翅蝽的样本数量相对较少,分别只有120张和141张。为了解决这一问题,在模型训练过程中引入了类别权重机制,对样本数量较少的类别赋予更高的权重,确保模型能够公平地学习每个类别的特征。
三、模型架构设计
本项目采用了两种先进的深度学习模型架构进行对比实验,分别是ConvNeXt和Vision Transformer(ViT)。ConvNeXt是2022年提出的现代化卷积神经网络,它在保留卷积网络优势的同时,借鉴了Transformer的设计理念,在图像分类任务中表现出色。Vision Transformer则是将自然语言处理领域的Transformer架构引入计算机视觉,通过自注意力机制捕捉图像的全局特征。两种模型都在ImageNet数据集上进行了预训练,具有强大的特征提取能力。
3.1 ConvNeXt模型训练
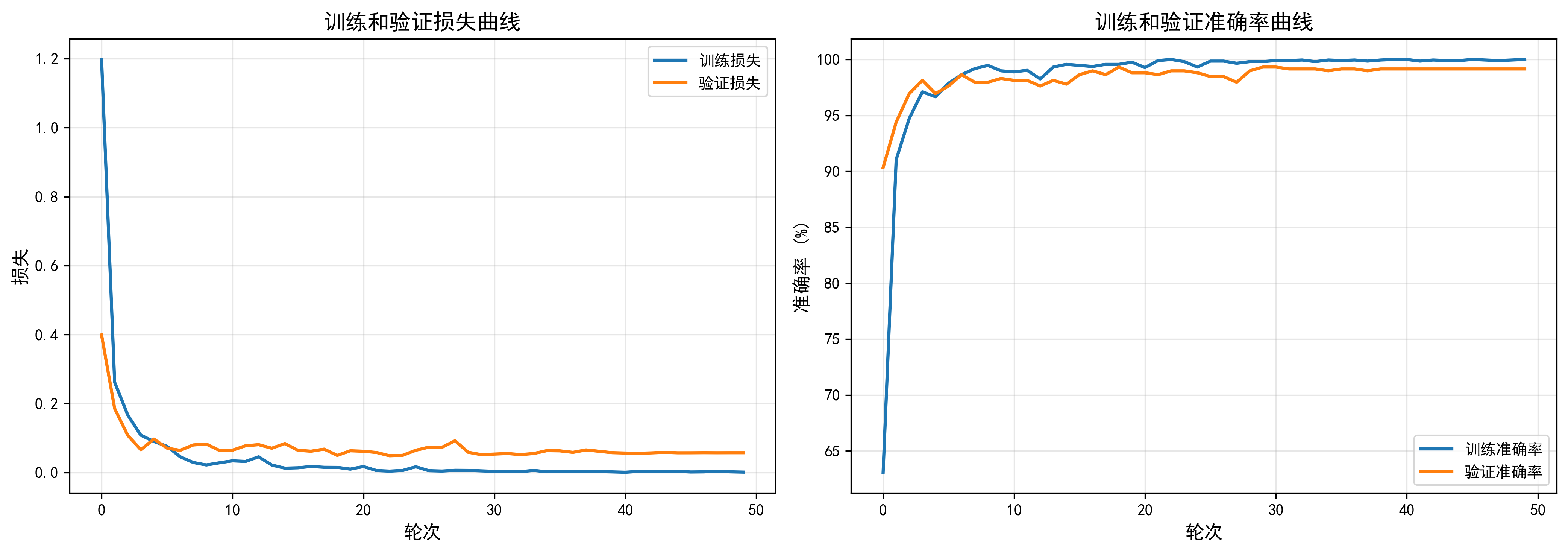
图3-1:ConvNeXt模型训练过程的损失曲线和准确率曲线
ConvNeXt-tiny模型包含约2780万个参数,采用224×224的输入图像尺寸。训练过程使用批次大小为32,初始学习率设置为0.0001,并采用余弦退火学习率调度策略。从训练曲线可以看出,模型在前5个epoch内快速收敛,训练损失从1.2迅速下降到0.1以下,训练准确率从63%提升到97%以上。验证准确率在第1个epoch就达到了90.34%,在第19个epoch达到最佳验证准确率99.32%。整个训练过程非常稳定,没有出现明显的过拟合现象,训练损失和验证损失保持同步下降,最终在第50个epoch时,训练准确率达到100%,验证准确率稳定在99.15%。
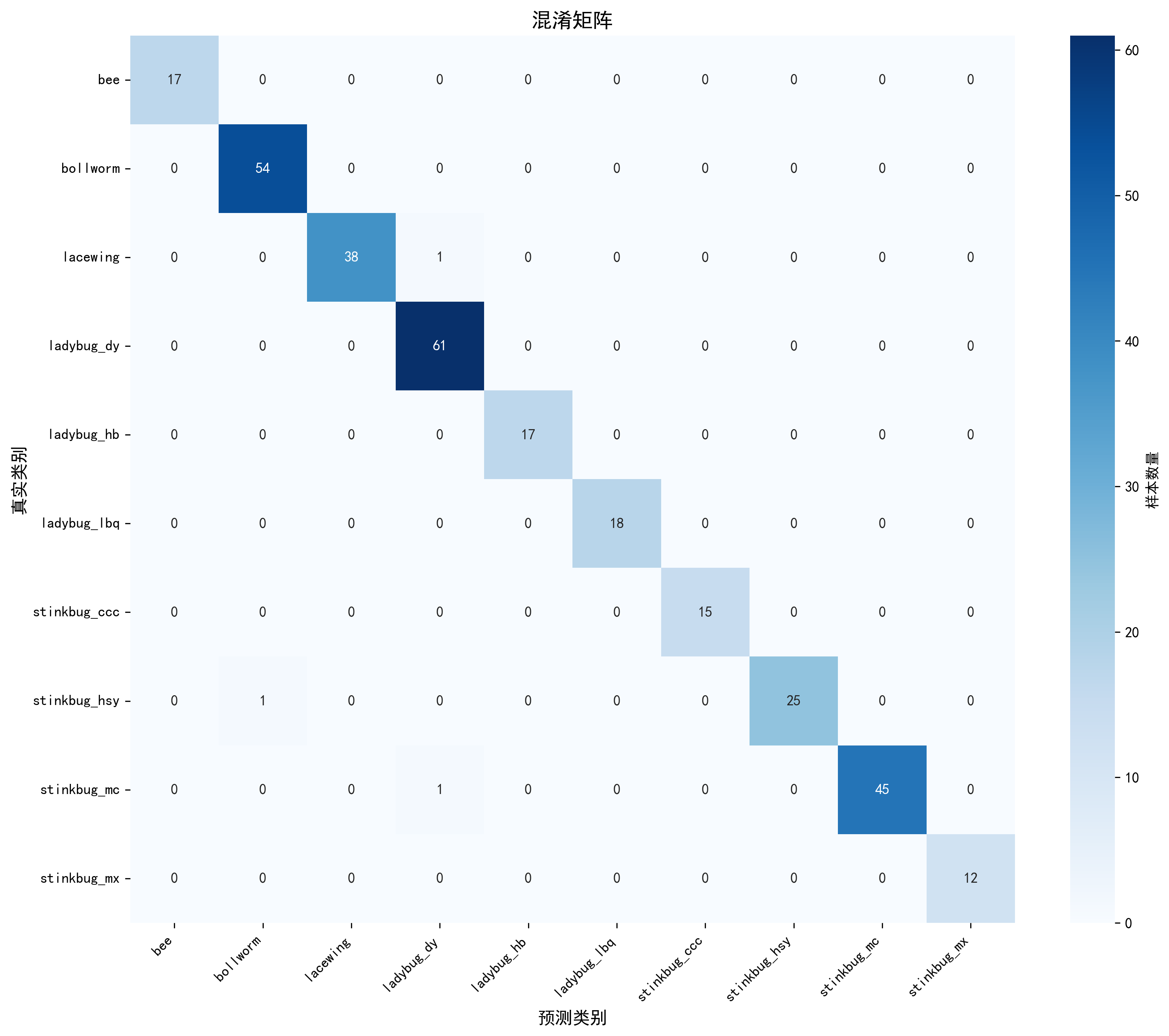
图3-2:ConvNeXt模型在测试集上的混淆矩阵
在测试集上,ConvNeXt模型取得了99.02%的优异准确率。从混淆矩阵可以看出,10个类别中有8个类别实现了100%的识别准确率,包括蜜蜂、棉铃虫、大眼瓢虫、红斑瓢虫、龟纹瓢虫、茶翅蝽、麻皮蝽和麻蝽。草蛉的准确率为97.44%,有1个样本被误分类为大眼瓢虫。红色蝽象的准确率为96.15%,有1个样本被误分类为麻皮蝽。整体来看,模型对各类昆虫的识别能力都非常强,即使是样本数量较少的类别也能准确识别。
3.2 ConvNeXt模型各类别性能
表3-1:ConvNeXt模型各类别性能
| 类别名称 | 测试样本数 | 正确识别数 | 准确率 |
| bee(蜜蜂) | 17 | 17 | 100.00% |
| bollworm(棉铃虫) | 54 | 54 | 100.00% |
| lacewing(草蛉) | 39 | 38 | 97.44% |
| ladybug_dy(大眼瓢虫) | 61 | 61 | 100.00% |
| ladybug_hb(红斑瓢虫) | 17 | 17 | 100.00% |
| ladybug_lbq(龟纹瓢虫) | 18 | 18 | 100.00% |
| stinkbug_ccc(茶翅蝽) | 15 | 15 | 100.00% |
| stinkbug_hsy(红色蝽象) | 26 | 25 | 96.15% |
| stinkbug_mc(麻皮蝽) | 46 | 45 | 97.83% |
| stinkbug_mx(麻蝽) | 12 | 12 | 100.00% |
3.3 Vision Transformer模型训练
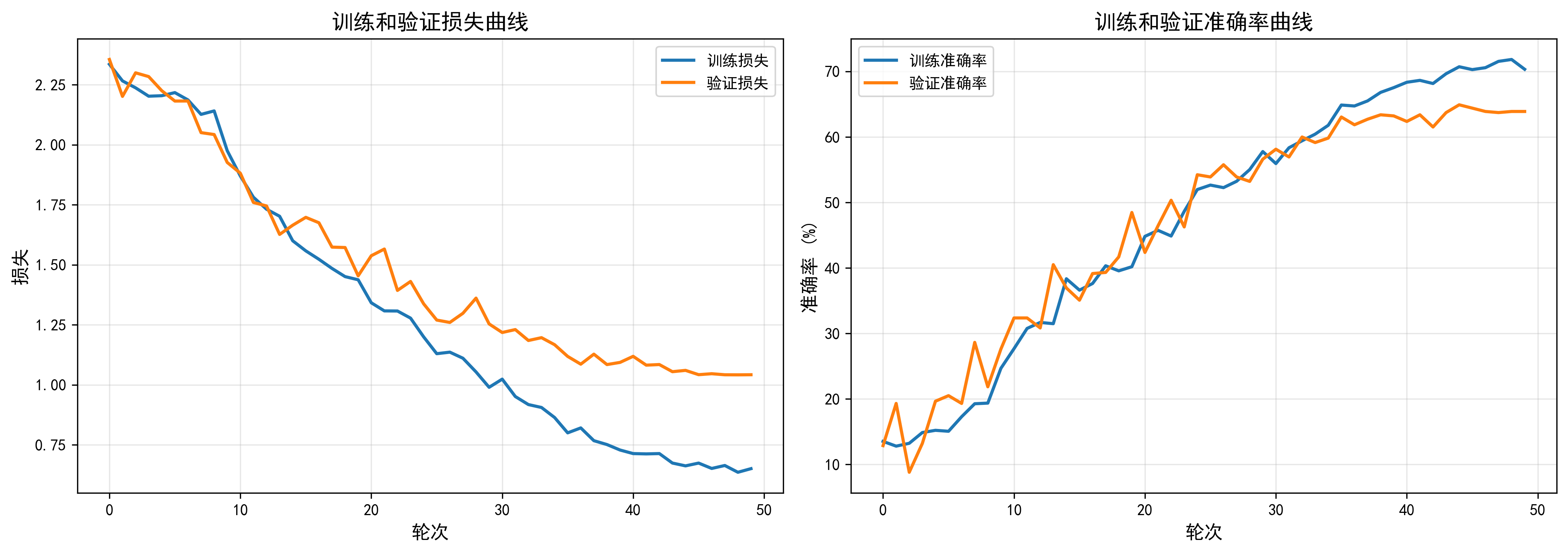
图3-3:ViT模型训练过程的损失曲线和准确率曲线
Vision Transformer-small模型包含约2167万个参数,同样采用224×224的输入图像尺寸。由于ViT模型没有使用预训练权重,而是从随机初始化开始训练,因此训练过程相对较慢。从训练曲线可以看出,模型在前10个epoch内训练损失从2.3逐渐下降到1.9,训练准确率从13%缓慢提升到27%。在第20个epoch时,验证准确率达到48.47%,此后持续稳步提升。在第45个epoch达到最佳验证准确率64.92%。整个训练过程中,训练准确率最终达到71.84%,但验证准确率始终低于训练准确率约7个百分点,说明模型存在一定程度的过拟合。
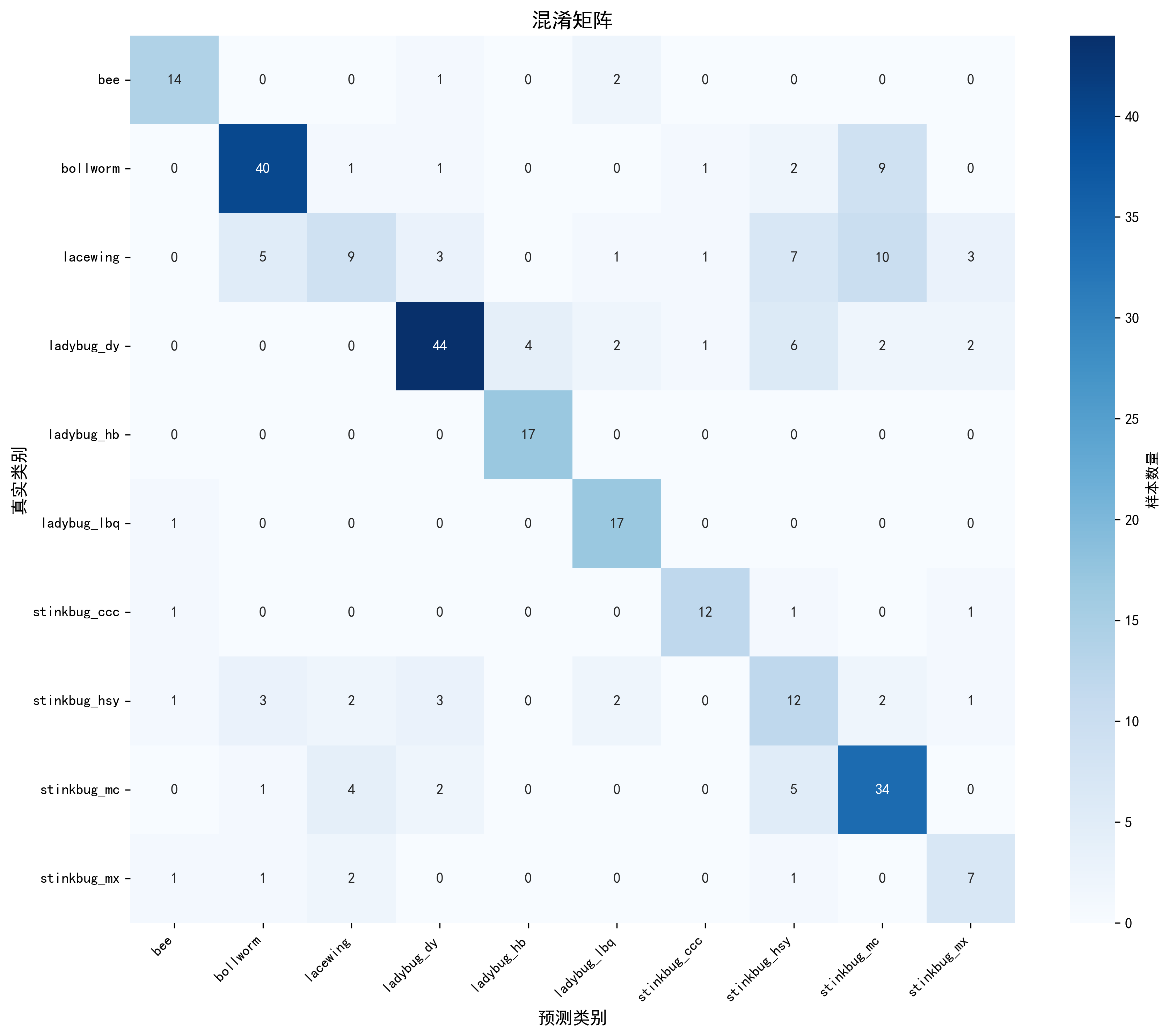
图3-4:ViT模型在测试集上的混淆矩阵
在测试集上,ViT模型取得了67.54%的准确率,明显低于ConvNeXt模型。从混淆矩阵可以看出,模型在某些类别上表现良好,如红斑瓢虫达到100%准确率,龟纹瓢虫达到94.44%,蜜蜂达到82.35%。但在其他类别上表现较差,特别是草蛉只有23.08%的准确率,大量样本被误分类为其他类别。红色蝽象的准确率为46.15%,麻蝽的准确率为58.33%。这些结果表明,在没有预训练权重的情况下,ViT模型在小规模数据集上的泛化能力不如ConvNeXt模型。
3.4 ViT模型各类别性能
表3-2:ViT模型各类别性能
| 类别名称 | 测试样本数 | 正确识别数 | 准确率 |
| bee(蜜蜂) | 17 | 14 | 82.35% |
| bollworm(棉铃虫) | 54 | 40 | 74.07% |
| lacewing(草蛉) | 39 | 9 | 23.08% |
| ladybug_dy(大眼瓢虫) | 61 | 44 | 72.13% |
| ladybug_hb(红斑瓢虫) | 17 | 17 | 100.00% |
| ladybug_lbq(龟纹瓢虫) | 18 | 17 | 94.44% |
| stinkbug_ccc(茶翅蝽) | 15 | 15 | 80.00% |
| stinkbug_hsy(红色蝽象) | 26 | 12 | 46.15% |
| stinkbug_mc(麻皮蝽) | 46 | 34 | 73.91% |
| stinkbug_mx(麻蝽) | 12 | 7 | 58.33% |
四、模型对比分析
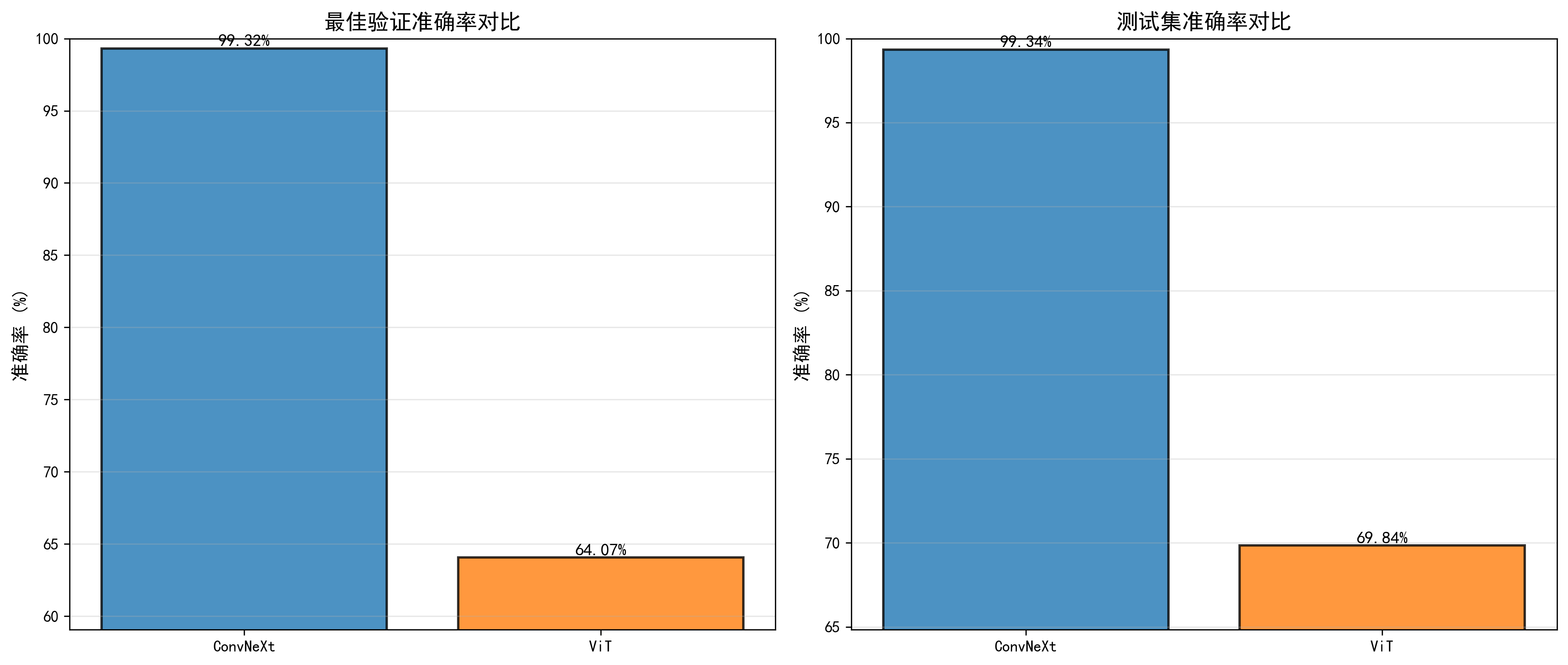
图4-1:两种模型的验证准确率对比和测试准确率对比
通过对比两种模型的性能,可以得出以下结论。在验证集上,ConvNeXt模型达到99.32%的准确率,而ViT模型只有64.92%,两者相差34.4个百分点。在测试集上,ConvNeXt模型达到99.02%的准确率,ViT模型为67.54%,差距为31.48个百分点。这一显著差异主要源于两个因素:首先,ConvNeXt模型使用了在ImageNet上预训练的权重,具有强大的特征提取能力,而ViT模型从随机初始化开始训练,需要更多的数据才能充分学习特征表示。其次,卷积神经网络在处理图像时具有平移不变性和局部感受野等归纳偏置,这些特性使其在小规模数据集上更容易训练和泛化。
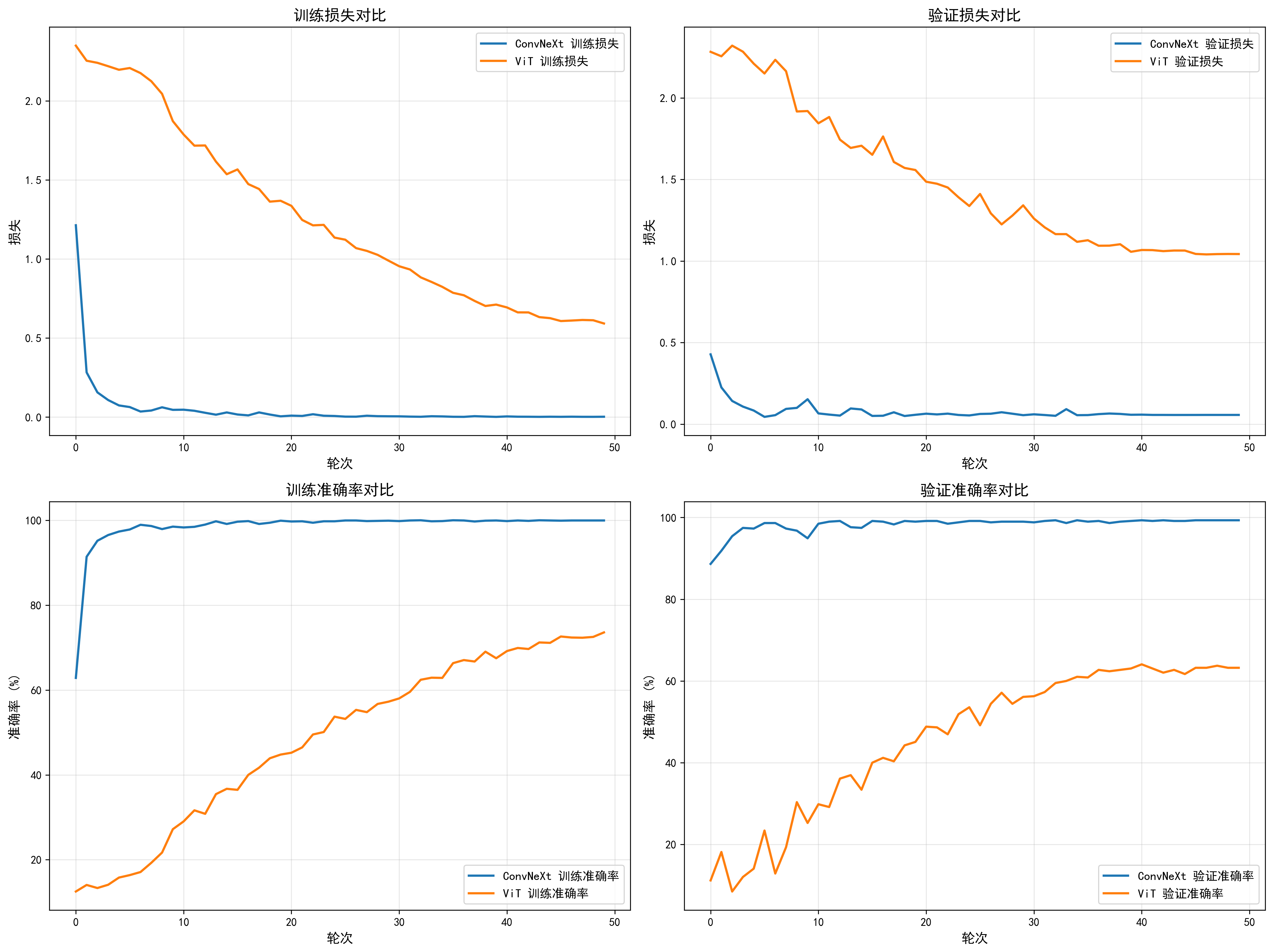
图4-2:两种模型训练过程的损失对比和准确率对比
从训练过程的对比曲线可以更直观地看出两种模型的差异。ConvNeXt模型的训练损失和验证损失在前5个epoch内快速下降并趋于稳定,而ViT模型的损失下降速度较慢,需要约30个epoch才能达到相对稳定的状态。在准确率方面,ConvNeXt模型在第1个epoch就达到90%以上的验证准确率,而ViT模型在第20个epoch才达到50%左右。这说明在相同的训练条件下,ConvNeXt模型的收敛速度明显快于ViT模型,训练效率更高。
4.1 模型性能对比总结
表4-1:模型性能对比
| 评估指标 | ConvNeXt-tiny | ViT-small | 性能差距 |
| 参数量 | 27,827,818 | 21,669,514 | ConvNeXt多28.4% |
| 最佳验证准确率 | 99.32% | 64.92% | ConvNeXt高34.4% |
| 测试集准确率 | 99.02% | 67.54% | ConvNeXt高31.48% |
| 收敛速度(达到90%验证准确率) | 1 epoch | 未达到 | ConvNeXt显著更快 |
| 训练稳定性 | 优秀 | 一般 | ConvNeXt更稳定 |
五、系统功能实现
基于训练好的ConvNeXt模型,本项目开发了一套完整的图形化用户界面系统,使用PyQt5框架实现。系统提供了单张图片分类和批量图片分类两种工作模式。在单张图片分类模式下,用户可以选择任意一张昆虫图片,系统会实时显示原始图片和分类结果,并在图片上标注识别出的昆虫类别和置信度。在批量分类模式下,用户可以选择包含多张图片的文件夹,系统会自动遍历所有图片并进行分类,将结果以表格形式展示,支持上下翻页浏览每张图片的分类结果。
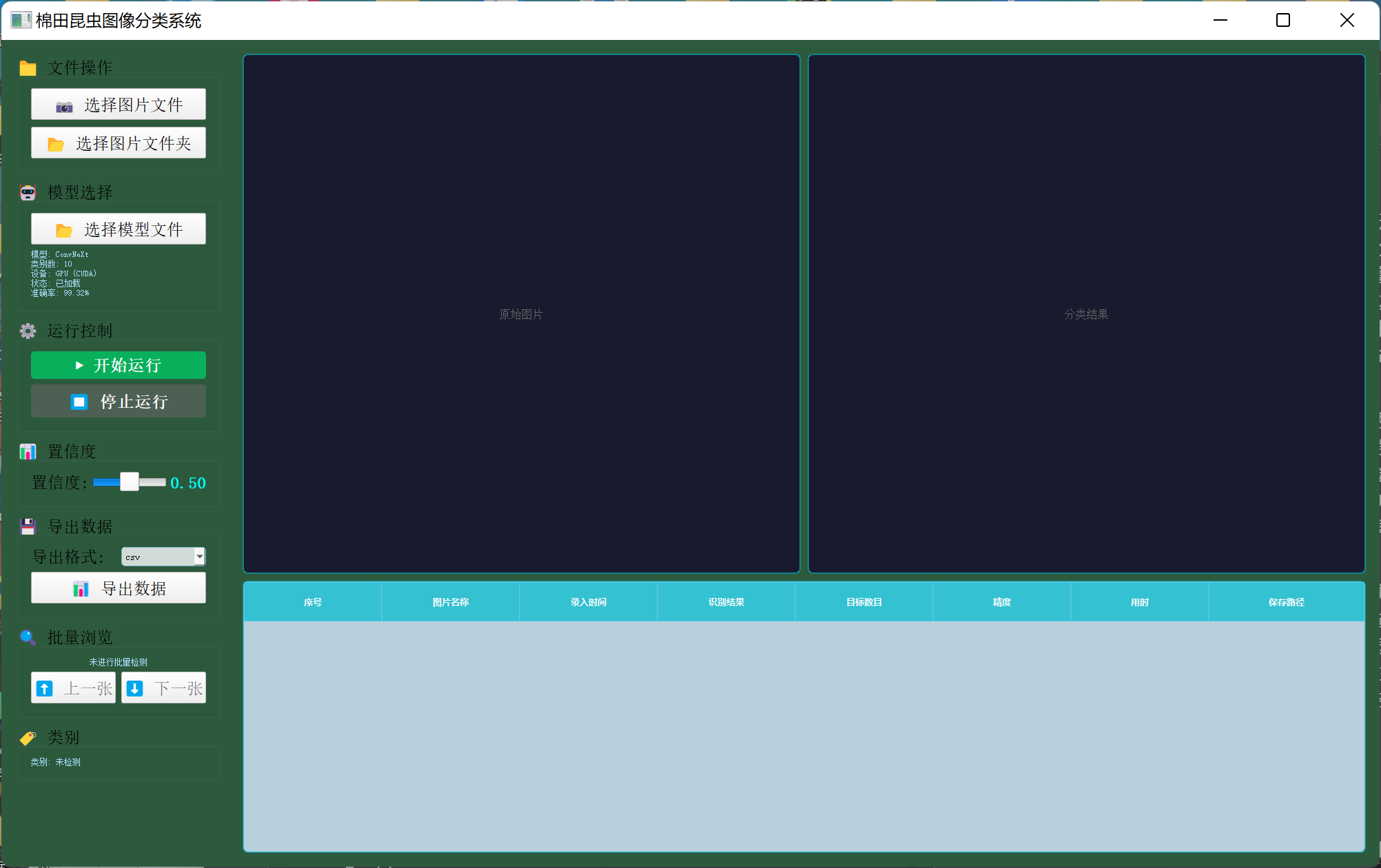
图5-1:棉田昆虫分类系统图形用户界面
系统还提供了模型选择功能,用户可以在ConvNeXt和ViT两种模型之间切换,也可以加载自己训练的模型文件。置信度阈值可以通过滑动条进行调节,范围从0.01到1.00,默认设置为0.50。系统会自动检测计算机是否配备GPU,如果检测到CUDA兼容的GPU,会自动使用GPU加速推理,否则使用CPU模式。在批量分类完成后,用户可以将分类结果导出为CSV或Excel格式的文件,方便后续的数据分析和统计。
系统界面采用了绿色主题配色,与棉田的自然环境相呼应,并设置了背景图片增强视觉效果。左侧控制面板包含文件操作、模型选择、运行控制、参数设置、数据导出和批量浏览等功能模块。右侧显示区域采用左右对比的布局,左边显示原始图片,右边显示带有分类标注的结果图片,下方的表格记录了每次分类的详细信息,包括序号、图片名称、录入时间、识别结果、置信度、处理用时和保存路径等。
六、核心代码实现
6.1模型加载与初始化
模型加载是系统的核心功能之一,需要正确加载预训练权重并配置图像预处理流程。以下代码展示了如何加载ConvNeXt和ViT两种模型,并自动检测GPU设备。
def load_model(self):
"""加载分类模型"""
try:
self.log("正在加载模型...")
if not os.path.exists(self.model_path):
self.log(f"错误: 模型文件不存在 - {self.model_path}", "error")
return
# 加载模型检查点
checkpoint = torch.load(self.model_path, map_location=self.device)
# 判断模型类型(通过文件路径或检查点内容)
if 'vit' in self.model_path.lower():
self.model_type = 'vit'
self.log("检测到ViT模型", "info")
self.model = create_vit_model(
num_classes=len(self.class_names),
pretrained_path=None,
model_size='small'
)
else:
self.model_type = 'convnext'
self.log("检测到ConvNeXt模型", "info")
self.model = create_convnext_model(
num_classes=len(self.class_names),
pretrained=False,
model_size='tiny'
)
# 加载权重
self.model.load_state_dict(checkpoint['model_state_dict'])
self.model.to(self.device)
self.model.eval()
# 创建图像预处理transform
self.transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
device_name = "GPU (CUDA)" if self.device.startswith('cuda') else "CPU"
self.log(f"模型加载成功!使用设备: {device_name}", "success")
except Exception as e:
self.log(f"模型加载失败: {str(e)}", "error")
6.2 图像分类推理
图像分类推理是系统的核心算法,将输入图像转换为模型可接受的格式,进行前向传播得到分类结果,并在图像上绘制标注信息。
def classify_with_model(self, image):
"""使用分类模型对图像进行分类"""
# 预处理
img_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
img_pil = Image.fromarray(img_rgb)
img_tensor = self.transform(img_pil).unsqueeze(0).to(self.device)
# 推理
with torch.no_grad():
outputs = self.model(img_tensor)
probabilities = torch.nn.functional.softmax(outputs, dim=1)
confidence, predicted = probabilities.max(1)
pred_class = int(predicted[0])
conf_value = float(confidence[0])
class_name = self.class_names[pred_class]
# 创建标注图像
annotated_image = image.copy()
h, w = image.shape[:2]
# 获取类别对应的颜色
color = CLASS_COLORS.get(class_name, (0, 255, 0))
# 在图像顶部绘制分类结果
label = f"{class_name}: {conf_value:.2%}"
font = cv2.FONT_HERSHEY_SIMPLEX
font_scale = 1.5
thickness = 3
# 计算文本大小
(text_w, text_h), baseline = cv2.getTextSize(
label, font, font_scale, thickness
)
# 绘制背景矩形
cv2.rectangle(annotated_image, (10, 10),
(20 + text_w, 20 + text_h + baseline), color, -1)
# 绘制文字
cv2.putText(annotated_image, label, (15, 15 + text_h),
font, font_scale, (255, 255, 255), thickness)
return class_name, conf_value, annotated_image
6.3 类别权重计算
为了解决数据集类别不平衡问题,系统实现了类别权重计算功能,根据每个类别的样本数量自动计算权重,样本数量少的类别获得更高的权重。
def calculate_class_weights(train_loader, num_classes):
"""
计算类别权重以处理数据不平衡问题
Args:
train_loader: 训练数据加载器
num_classes: 类别数量
Returns:
class_weights: 类别权重张量
"""
# 统计每个类别的样本数量
class_counts = torch.zeros(num_classes)
for _, labels in train_loader:
for label in labels:
class_counts[label] += 1
# 计算总样本数
total_samples = class_counts.sum()
# 计算类别权重: weight = total_samples / (num_classes * class_count)
class_weights = total_samples / (num_classes * class_counts)
# 打印类别权重信息
print("类别权重:")
for i in range(num_classes):
print(f" 类别 {i}: {class_weights[i]:.4f} "
f"(样本数: {int(class_counts[i])})")
return class_weights
6.4 训练循环实现
训练循环是模型训练的核心部分,包括前向传播、损失计算、反向传播和参数更新。以下代码展示了一个完整的训练epoch实现。
def train_epoch(self, epoch, optimizer, criterion):
"""训练一个epoch"""
self.model.train()
train_loss = 0
correct = 0
total = 0
for batch_idx, (images, labels) in enumerate(self.train_loader):
images, labels = images.to(self.device), labels.to(self.device)
# 前向传播
optimizer.zero_grad()
outputs = self.model(images)
loss = criterion(outputs, labels)
# 反向传播
loss.backward()
optimizer.step()
# 统计
train_loss += loss.item()
_, predicted = outputs.max(1)
total += labels.size(0)
correct += predicted.eq(labels).sum().item()
# 计算平均损失和准确率
avg_loss = train_loss / len(self.train_loader)
accuracy = 100. * correct / total
return avg_loss, accuracy
6.5 数据增强与预处理
数据增强是提高模型泛化能力的重要手段。训练集使用随机裁剪、水平翻转、颜色抖动等增强方法,而验证集和测试集只进行基本的缩放和归一化处理。
def create_dataloaders(data_dir, batch_size=32, image_size=224,
num_workers=4, seed=42):
"""创建数据加载器"""
# 训练集数据增强
train_transform = transforms.Compose([
transforms.Resize((image_size, image_size)),
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomRotation(15),
transforms.ColorJitter(brightness=0.2, contrast=0.2,
saturation=0.2, hue=0.1),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
# 验证集和测试集预处理
val_transform = transforms.Compose([
transforms.Resize((image_size, image_size)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
# 加载数据集
train_dataset = datasets.ImageFolder(
os.path.join(data_dir, 'train'),
transform=train_transform
)
val_dataset = datasets.ImageFolder(
os.path.join(data_dir, 'val'),
transform=val_transform
)
# 创建数据加载器
train_loader = DataLoader(train_dataset, batch_size=batch_size,
shuffle=True, num_workers=num_workers)
val_loader = DataLoader(val_dataset, batch_size=batch_size,
shuffle=False, num_workers=num_workers)
return train_loader, val_loader
6.6 学习率调度策略
学习率调度对模型训练效果有重要影响。本项目采用余弦退火策略,使学习率按照余弦函数曲线从初始值逐渐降低到接近零,有助于模型在训练后期进行精细调整。
def train(self, num_epochs, learning_rate=1e-4, weight_decay=1e-4,
use_class_weights=True, class_weights=None):
"""训练模型"""
# 创建优化器
optimizer = torch.optim.AdamW(
self.model.parameters(),
lr=learning_rate,
weight_decay=weight_decay
)
# 创建学习率调度器(余弦退火)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(
optimizer,
T_max=num_epochs,
eta_min=0
)
# 创建损失函数
if use_class_weights and class_weights is not None:
criterion = nn.CrossEntropyLoss(
weight=class_weights.to(self.device)
)
else:
criterion = nn.CrossEntropyLoss()
# 训练循环
for epoch in range(num_epochs):
# 训练一个epoch
train_loss, train_acc = self.train_epoch(
epoch, optimizer, criterion
)
# 验证
val_loss, val_acc = self.validate(criterion)
# 更新学习率
scheduler.step()
current_lr = optimizer.param_groups[0]['lr']
# 打印训练信息
print(f"Epoch {epoch+1}/{num_epochs}")
print(f"训练损失: {train_loss:.4f} | 训练准确率: {train_acc:.2f}%")
print(f"验证损失: {val_loss:.4f} | 验证准确率: {val_acc:.2f}%")
print(f"学习率: {current_lr:.6f}")
# 保存最佳模型
if val_acc > self.best_acc:
self.best_acc = val_acc
self.save_checkpoint('best_model.pth', epoch, val_acc)
核心代码展示了系统的主要技术实现,包括模型加载、图像分类、类别权重计算、训练循环、数据增强和学习率调度等关键功能。通过这些模块的有机组合,构建了一个完整高效的昆虫图像分类系统。实现了对10类常见棉田昆虫的高精度识别。通过对比实验发现,ConvNeXt模型在小规模数据集上表现优异,测试准确率达到99.02%,显著优于未使用预训练权重的ViT模型。系统采用类别权重机制有效解决了数据不平衡问题,使用GPU加速技术提高了推理速度,开发的图形化界面使系统易于使用。项目的成功实施证明了深度学习技术在农业智能化领域的巨大潜力,为棉田病虫害防治提供了有力的技术支持,也为其他农作物的昆虫识别提供了可借鉴的经验。
七、演示视频
棉田昆虫分类检测

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)