机械学习算法思想和数学思想汇总
一、线性回归:找一条"最像"的直线
核心思想(一句话)
你有一堆散点,想画一条直线穿过它们,让所有点到这条直线的垂直距离之和尽量小。
通俗理解
想象你在墙上钉了一堆钉子,现在要用一根橡皮筋尽量贴近所有钉子。你不能让橡皮筋随意弯曲(那是后面的非线性模型),只能拉直。那怎么算"最贴近"?
最自然的想法:测量每个钉子到橡皮筋的垂直距离,把这些距离加起来,找使总和最小的那条橡皮筋。
数学思想(大白话版)
模型公式:
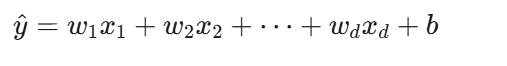
翻译成人话:预测值 = 每个因素乘以一个重要性权重,再加一个基准值。
比如预测房价:

目标函数(最小二乘法):
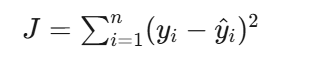
人话:真实值和预测值的差距,平方后全部加起来。为什么要平方?
-
不加绝对值是因为平方好求导(数学上光滑)
-
平方会惩罚大误差——差1厘米罚1分,差10厘米罚100分,这样模型就不敢对某些点偏差太大
正规方程(一步到位求最优解):
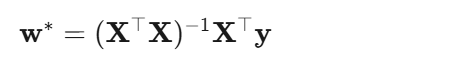
人话:把所有数据排成一个大方阵,通过矩阵运算直接算出最优权重。就像解一个线性方程组,只不过未知数很多。
梯度下降(一步一步爬下山):
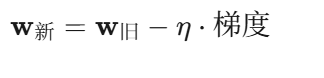
人话:如果直接求逆矩阵算不出来(数据太大或矩阵不可逆),那就一步一步调整权重。想象你在山上,每次往最陡的下坡方向走一步,步长是 η (学习率)。走多了,就走到山底(误差最小处)。
二、逻辑回归:不是回归,是"概率分类器"
核心思想(一句话)
先用线性回归算出一个分数,再用一个"S型函数"把这个分数压缩成0到1之间的概率,然后按概率分类。
通俗理解
逻辑回归解决的是分类问题(比如"这封邮件是不是垃圾邮件"),但它名字里带"回归"是因为内部先做了一个线性打分。
你可以把它想象成一个概率转换器:
-
先把各种特征(邮件里"免费""中奖"等词的出现次数)加权求和,得到一个原始分数(比如 +3.5 或 -1.2)
-
这个分数范围是 (−∞,+∞) ,但概率必须在 (0,1) 之间
-
所以用一个"S型曲线"(Sigmoid)把它压扁到0-1之间
数学思想(大白话版)
Sigmoid 函数:
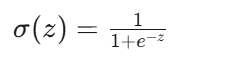
人话:无论 z 是多大或多小的数字,输出永远在0和1之间。z=0 时输出0.5;z 越大越接近1;z 越小越接近0。
预测概率:
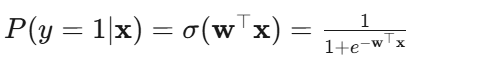
人话:给定一组特征,模型算出"这是正类"的概率。
对数几率(Log-odds):
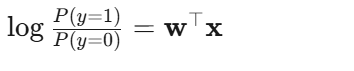
人话:线性回归直接预测数值;逻辑回归预测的是"对数几率"。什么叫几率?就是"发生的概率除以不发生的概率"。对数几率是线性可加的,所以可以用线性模型来拟合。
损失函数(交叉熵):
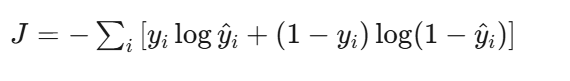
人话:这是极大似然估计的结果。通俗说——如果真实标签是1(垃圾邮件),模型预测的概率越接近1,损失越小;如果预测成0.1,损失就很大。这个公式就是在惩罚"猜错且猜得很离谱"的情况。
梯度:
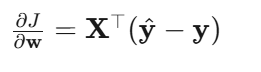
人话:梯度就是"预测值减去真实值"再乘以特征。如果预测比真实大,就把权重往下调;预测小了,就往上调。非常直观。
三、决策树:像玩"20个问题"一样做判断
核心思想(一句话)
通过一系列是非题(比如"年龄是否大于30?")把数据不断分成更纯的小群体,直到每个小群体里的样本差不多是一类人。
通俗理解
想象你在玩"猜人物"游戏。你心里想一个人,我问你:"是男性吗?""身高超过1米7吗?""戴眼镜吗?"——每个问题都把可能性空间切掉一半。
决策树就是这个逻辑:
-
每个内部节点是一个判断题(某个特征是否满足某条件)
-
每个分支是"是"或"否"
-
每个叶子节点是最终判断(分类结果或回归值)
关键问题是:先问哪个问题最好?
数学思想(大白话版)
熵(不确定性度量):
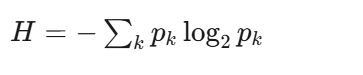
人话:熵描述的是混乱程度。
-
一个盒子里全是红球(p红=1 ),熵 = 0,完全不混乱,你随便抓都知道是红的。
-
一半是红一半是蓝,熵 = 1,最混乱,你完全猜不准。
-
这个公式就是量化这种"猜不准的程度"。
信息增益:

人话:问了一个问题后,混乱程度降低了多少?降低越多,这个问题越有价值。决策树每次选信息增益最大的特征来分裂。
基尼指数(CART用):
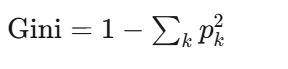
人话:基尼指数也是衡量纯度的。如果一类占100%,基尼=0(最纯);两类各50%,基尼=0.5(最乱)。基尼计算比熵快一点,所以CART默认用它。
回归树的MSE分裂:
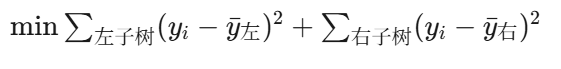
人话:对于回归问题,找一个切分点,让左边和右边各自内部差异(方差)最小。就像把一群身高各异的人分成两堆,让每堆内部身高尽量接近。
四、随机森林:"三个臭皮匠顶个诸葛亮"
核心思想(一句话)
建很多棵略有不同的决策树,让它们投票,用群体的智慧抵消个体的错误。
通俗理解
一棵决策树容易过拟合(对训练数据记得太死,新数据一来就傻眼)。但如果我建100棵树,每棵树看的数据略有不同、用的特征也略有不同,然后让它们投票,错误就会被"平均"掉。
这就像让100个专家独立判断一只股票涨跌,虽然每个人可能都有偏见,但综合起来往往比一个人准。
数学思想(大白话版)
Bootstrap采样(有放回抽样): 从原始数据(比如1000条)中随机抽1000条,抽完放回去再抽。这样有些样本会被重复抽到,有些永远抽不到。
人话:抽不到的那些样本(约36.8%)叫OOB样本,可以用来当"考试卷"测试模型,不用额外划分验证集。
两阶段随机性:
-
样本随机:每棵树用不同的Bootstrap样本训练
-
特征随机:每棵树分裂节点时,只从所有特征中随机挑一部分(比如总共50个特征,每次只挑7个来选最佳分裂)
人话:如果所有树长得太像,它们会犯同样的错误,投票就没意义了。特征随机性强迫每棵树"管中窥豹",从不同角度看问题,这样错误就不相关了。
方差降低原理: 假设单棵树的预测方差是 σ2 ,树与树之间的相关性是 ρ ,那么 T 棵树平均后的方差:
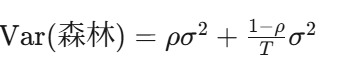
人话:树越多(T 大),第二项越小;但如果树之间太像(ρ 接近1),第一项降不下去。所以随机森林的关键不是树要多,而是树之间要"各抒己见"。
五、XGBoost:一个"纠错委员会",越纠越准
核心思想(一句话)
按顺序训练多棵树,每棵新树专门学习前面所有树犯过的错误(残差),逐步把预测值修正到真实值。
通俗理解
想象你在教一个学生做题:
-
第一轮:学生凭直觉做,错了不少
-
第二轮:你专门教他上一轮错在哪里,他进步了一些
-
第三轮:再教他前两轮共同剩下的错误
-
……最后把所有轮次的答案加起来,就是最终答案
XGBoost就是这个逻辑。它不是像随机森林那样"平行投票",而是串行纠错。
数学思想(大白话版)
加法模型:
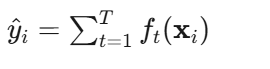
人话:最终预测是 T 棵树的预测值加总。每棵树 ft 输出一个数(分类问题输出的是log-odds,回归问题直接是数值)。
二阶泰勒展开(XGBoost的神来之笔): 第 t 轮时,已有模型预测 y^(t−1) ,新树要加 ft 。损失函数展开:
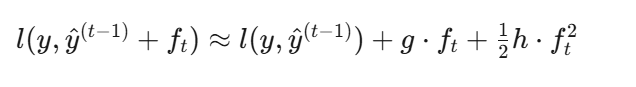
人话:泰勒展开就是用抛物线近似曲线。g 是梯度(一阶导,告诉你往哪走),h 是Hessian(二阶导,告诉你走多快会过头)。XGBoost不仅看"往哪走",还看"路有多陡",所以比只用梯度(传统Gradient Boosting)更精准。
目标函数:
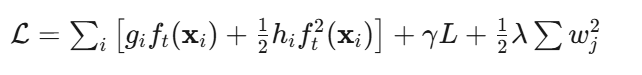
人话:前两项是"拟合残差"(让新树纠正错误),后两项是惩罚:
-
γL :树叶子越多,罚得越重(防止树太深太复杂)
-
λ∑wj2 :叶子输出值太大也罚(防止某棵树一家独大)
最优叶子权重:
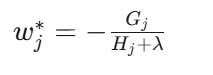
人话:每个叶子节点最终输出的数值,等于该叶子上所有样本的梯度之和 Gj ,除以二阶梯度之和 Hj 加上正则化 λ 。直观上,如果样本梯度很大(错得厉害),叶子输出就大(纠得猛);如果样本很杂(Hj 大),就保守一点。
分裂增益:
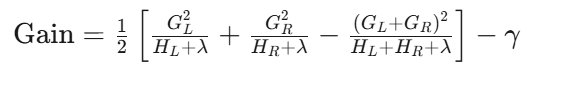
人话:分裂好不好,看"分裂后两边各自的纯度提升"减去"分裂的代价 γ "。只有当增益大于0时才分裂——这就是预剪枝。
六、LightGBM:XGBoost的"极速版"
核心思想(一句话)
保留XGBoost的"纠错"数学框架,但用直方图近似、按叶子生长和梯度采样把速度提升10倍以上。
通俗理解
XGBoost像是一个精益求精的老工匠,每个细节都手工打磨(遍历所有可能的分裂点),但太慢了。LightGBM像是一个聪明的工程师,说:"我们不用精确到毫米,精确到厘米就够了;而且不用每层都长齐,哪片叶子最有潜力就先长哪片。"
数学思想(大白话版)
直方图算法(Histogram): 把连续特征的值分成 k 个桶(比如255个),统计每个桶里有多少样本、梯度总和是多少。
人话:原来找最佳分裂点要遍历所有样本的排序值(比如年龄从18到90岁,每个值都试一遍),现在只试255个桶的边界。精度略有损失,但速度快了几十倍,而且桶的边界本身就有一定的正则化效果(不容易过拟合)。
Leaf-wise vs Level-wise:
-
Level-wise(XGBoost默认):树一层一层长,每层所有叶子一起分裂。像修剪灌木,剪得整整齐齐,但有些枝条本来就不需要长。
-
Leaf-wise(LightGBM):每次只挑分裂增益最大的那个叶子分裂。像种果树,哪根枝条挂果潜力大就修哪根,同样数量的叶子能长出更深的有效分支。
人话:假设你只有10次分裂的预算。Level-wise可能把精力浪费在已经挺纯的叶子上;Leaf-wise把钱花在刀刃上,同样复杂度下拟合能力更强。
梯度单边采样(GOSS): 保留梯度大的样本(错得离谱的,必须重点教),对梯度小的样本随机采样(已经做对的,少看几个没关系),然后给小梯度样本加权补偿。
人话:班级里有些学生错题很多(大梯度),有些几乎全对(小梯度)。老师不用给全对的学生逐题讲解,随机抽查几个确保没作弊就行,把时间省下来教差生。数据量少了,但信息量没少多少。
互斥特征捆绑(EFB): 如果两个特征几乎不会同时出现(比如"是否有游泳池"和"是否是公寓",公寓一般没泳池),就把它们捆成一个特征。
人话:1000个特征里很多是"你出现我就不出现"的死对头,把它们打包,直方图只要建几百个而不是1000个,内存和计算都省了。
总结:一张图看懂六大算法的关系
plain
复制
┌─────────────────────────────────────────────────────────────┐
│ 线性回归 ──→ 逻辑回归 │
│ (直接预测数值) (预测概率,加了个Sigmoid壳) │
│ ↓ │
│ 决策树 ───────────────────────────────────────────┐ │
│ (用是非题切分空间,非线性) │ │
│ ↓ ↓ │
│ 随机森林(Bagging) XGBoost(Boosting)│
│ (多棵树并行投票,降低方差) (多棵树串行纠错) │
│ ↓ ↓ │
│ ─────────────────────────────────────────── LightGBM │
│ (同样的数学思想,但工程上极致优化,更快更省内存) │
└─────────────────────────────────────────────────────────────┘表格
| 算法 | 通俗比喻 | 数学核心 |
|---|---|---|
| 线性回归 | 拉一根最贴近钉子的橡皮筋 | 最小化误差平方和 |
| 逻辑回归 | 先打分,再用S型曲线转成概率 | 极大似然 + 交叉熵 |
| 决策树 | 玩"20个问题"逐步缩小范围 | 信息增益 / 基尼指数 / MSE |
| 随机森林 | 100个专家独立投票 | Bootstrap + 方差分解 |
| XGBoost | 纠错委员会,越纠越准 | 二阶泰勒展开 + 正则化结构分数 |
| LightGBM | 同样的委员会,但开会效率极高 | 直方图近似 + Leaf-wise + GOSS |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)