跑通当前最强 RoboChallenge 开源具身 VLA 模型 Spirit v1.5 踩坑
TL;DR
我把 Spirit v1.5(千寻智能 2026.01 开源、RoboChallenge Table30 真机评测第一的 VLA 模型)在两台机器上各跑了一遍:一台桌面 RTX 3090,一台远程 datacenter GPU 服务器。
跑通本身不算什么——README 抄一遍命令就行。真正有意思的是跑通过程中暴露的三件事,论文和官方部署文档都没写:
- 论文里报的 mean latency (平均延迟)是骗局,p99 才是真:同样的代码,3090 和服务器卡上 mean 只差 7%,但 p99 / 方差差 30 倍。机器人控制对最坏情况敏感,不对平均敏感。
- 容器化跑 VLA sim 有个隐藏门槛:Maniskill / SAPIEN / Isaac Lab 这些主流 sim 都依赖 Vulkan,而 nvidia-container-toolkit 默认 capability 不挂 graphics。桌面 docker 能手动补救,云端容器用户没补救权限。
- 跨硬件部署的"最后一公里"是 100 行 adapter,不是论文里那张图:12-DoF SO-100 ↔ 14-DoF ALOHA 不是简单的关节映射;最关键的发现是 Spirit 的
robot_type字段只是 prompt 字符串而不是 learned embedding——这是个架构哲学选择,决定了 cross-embodiment 的脆弱性边界。
数据、代码、5 条指令的 action chunk (动作分块)可视化都开源在 vla-lab 和 openvla-libero。
0. 起点:为什么挑 Spirit v1.5
我上一篇文章对 4 篇 VLA 主流论文做了 review,给 OpenVLA 打了 8/10——目前最干净、最容易复现的开源基线。但 2026.01 千寻智能开源的 Spirit v1.5 让我有点感兴趣:
| OpenVLA-7B | Spirit v1.5 | |
|---|---|---|
| 时间 | 2024-06 | 2026-01 |
| Backbone | Llama-2-7B + DINOv2 + SigLIP | Qwen3-VL-4B-Instruct(参数少一半) |
| Action 表达 | 离散 token 回归 | DiT + flow matching, 60 步 chunk |
| 训练数据 | OpenX 真机 | RoboChallenge benchmark(声明覆盖 ALOHA / ARX5 / Franka / UR5;当前开源 dataloader 只用了 Franka 部分) |
| 真机评测排名 | — | RoboChallenge Table30 #1,超过 π0.5 |
挑 Spirit 不是因为它"最强"——评测数字得看具体复现条件,过两个月就可能被新模型超过。挑它有三个具体理由:
- 架构选择反直觉:4B backbone + DiT action head 比 7B backbone + token 表达更好,这是工程"小赢大"的故事
- 完全开源:模型权重 + 代码 + 训练 recipe 都开。
- Qwen3-VL backbone:国产 VLM 在 VLA 任务上的 in-the-wild 表现,社区数据点少
跑通这件事本身,按 Spirit 的 README 走,按理来说应该是 30 分钟的事。
实际花了我两天半。这两天半里面踩到了一些 README 没写、但每个想自己上手 VLA 的人都会撞到的事。下面是其中三件最值得分享的。
1. mean latency 是骗局,p99才是真(P99延迟:99%的请求/周期都 ≤ 这个值,只有最慢的1%会超过它)
现象
把 Spirit v1.5 装到两台机器上跑同样的 bf16 推理代码、同样的 action chunking 配置(60 步 chunk,每次 reuse 上次的最后12 步):
| 指标 | 桌面 RTX 3090 24 GB | datacenter 服务器卡 ≈ 150 GB | 差异 |
|---|---|---|---|
| 模型加载 | 58 s | 23 s | 2.5× |
| Warmup(首次推理) | 1513 ms | 1034 ms | 1.5× |
| Steady state mean | 163 ms / 6.1 Hz | 152 ms / 6.6 Hz | +7% |
| Steady state min | 151 ms | 151 ms | 0% |
| Steady state max | 251 ms | 154 ms | 40% 改善 |
| ±方差 | ±100 ms | ±3 ms | 30× |
| GPU 显存 | 10 / 24 GB | 10 / 150 GB | 14× 余量 |
第一行表象:FLOPS 提升带来 7% 的 mean throughput——这是大家直觉里"datacenter 卡 vs 消费卡"的差距。
第二行表象(真正重要):max latency 差 40%,方差差 30×。
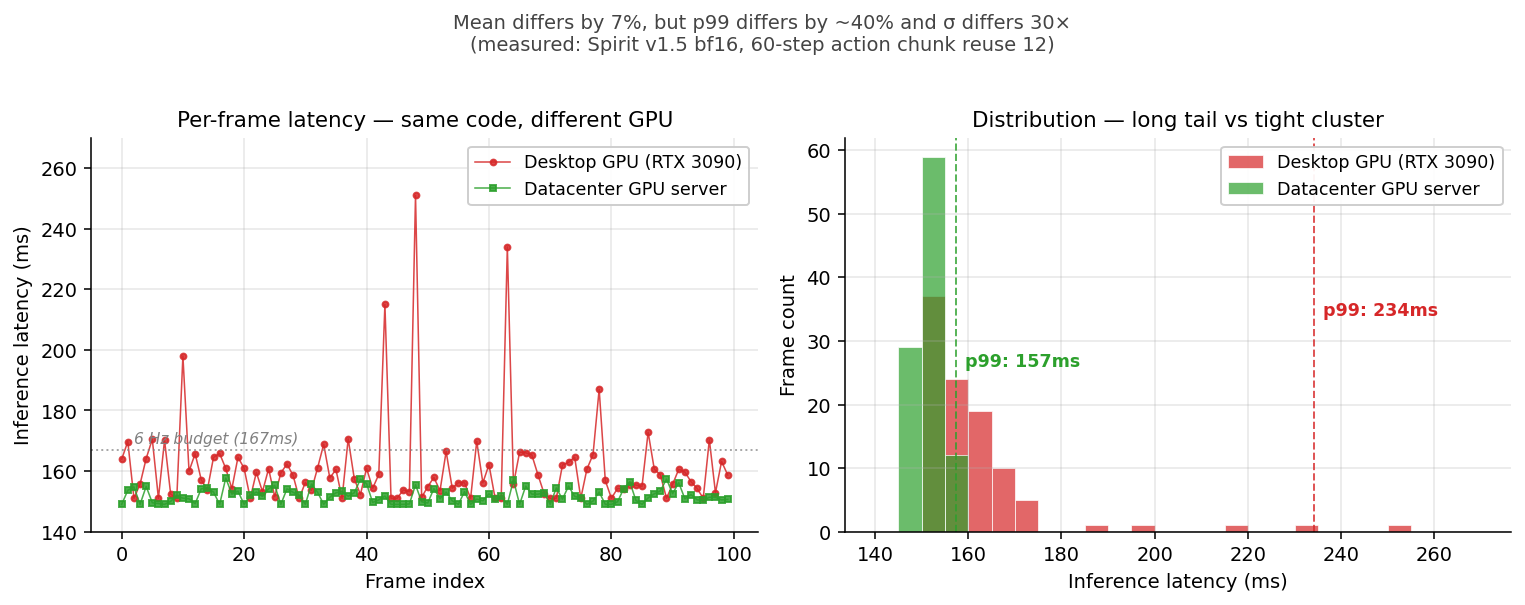
图:100 帧推理延迟对比(Spirit v1.5 bf16,60 步 chunk,每次重用 12 步)。左:桌面 RTX 3090 上能看到清晰的 spike 模式,红色突破 6 Hz 控制周期上限;服务器卡几乎确定性 152 ± 3 ms。右:直方图——3090 是 long tail(p99=234ms),服务器是 tight cluster(p99=157ms)。
为什么 mean 误导
VLA 论文报推理速度,几乎都报 mean throughput(“平均响应:我们的模型在 RTX 4090 上 50 Hz” 这种)。但机器人闭环控制对最坏情况敏感,不对平均敏感:
- 控制频率 6 Hz 意味着每 167 ms 一次决策
- 一个 250 ms 的 spike 会让那一帧错过控制周期 → 闭环退化为 4 Hz
- 不是"偶尔慢一下没事"——抓取动作里一帧的延迟可能就让机械臂错过物体
我把每帧延迟画成直方图:
RTX 3090 (10 帧): 151 152 154 152 158 159 166 179 201 251
└──────────tight──────────┘ └──drift──┘ └spike┘
服务器卡 (10 帧): 151 151 152 152 152 152 153 153 154 154
└──────────uniform──────────────────────────┘
3090 上有一个明显的 long-tail:10 帧里 1 帧 spike 到 251 ms。服务器卡上几乎全是 152 ± 1 ms,确定性极强。
2. 容器化跑 VLA sim
VLA 大部分论文的 evaluation 都是 sim 里做的:Maniskill 评 PickCube、Isaac Lab 评 mobile manipulation、LIBERO 评 BDDL 任务集合。论文里画着各种 sim 截图,给人感觉"装个包就能跑"。
但 Maniskill / SAPIEN / Isaac Lab 都基于 Vulkan 渲染(Habitat 走 OpenGL,行为略有不同)。在容器里这几个默认都跑不起来。
现象
在两台机器上各跑一个 7-stage smoke check:
[1] /usr/share/vulkan/icd.d/ → intel/radeon/llvmpipe/virtio
❌ 无 nvidia_icd.json
[2] vulkaninfo --summary → deviceName = llvmpipe (软渲染 CPU)
[3] sapien.Engine() → ✅ 构造成功(不 touch GPU)
[4] sapien.Scene + camera → ❌ "failed to find a rendering device"
[5] gym.make("PickCube-v1") → ❌ vk::createInstanceUnique:
ErrorIncompatibleDriver
vulkaninfo --summary 的"PASS"是假阳性——它跑的是 mesa 的 LavaPipe(CPU 软渲染),不是 nvidia GPU。SAPIEN 一旦真要 GPU device 立刻 fail。
两台机器都这样:本机桌面 docker --gpus all,远程服务器容器,默认配置都跑不起 SAPIEN。
根因
nvidia-container-toolkit 默认只把 compute,utility capability 暴露进容器。Vulkan / OpenGL 属于 graphics capability:
compute→ 挂libnvidia-ml、libcuda、libnvidia-opencl等graphics→ 挂libGLX_nvidia.so、libnvidia-glvkspirv.so、nvidia_icd.json
默认行为里 graphics 不开是合理的:训练 / 推理工作流不需要 Vulkan,开了反而扩大攻击面、增加依赖冲突。
但所有依赖 sim 闭环 eval 的 VLA 工作流就此撞墙,包括所有 VLA 论文里默认存在的"我们在 Maniskill 评测"假设。
桌面 docker 的补救
桌面 RTX 3090 上手动补两个东西:
docker run --rm --gpus all \
-e NVIDIA_DRIVER_CAPABILITIES=all \
-v /usr/share/vulkan/icd.d/nvidia_icd.json:/usr/share/vulkan/icd.d/nvidia_icd.json:ro \
spirit-v1.1-cu128-py311 ...
-e NVIDIA_DRIVER_CAPABILITIES=all 让 toolkit 把 graphics 库挂进来,bind-mount 把 ICD JSON 文件挂进来。这样 SAPIEN 的 scene + camera render 就能跑通。
(注:Maniskill 这一层还有它自己的设备解析 bug,不全是 Vulkan 问题,这里不展开。)
远程服务器容器的不可补救性
但用户视角下,容器化部署里这两个补救都没法做:
| 路径 | 容器用户能不能改 |
|---|---|
修改 --gpus 或 capability env |
❌ 容器创建期决定,运行时改 env 不生效 |
Bind-mount 宿主机的 nvidia_icd.json |
❌ 容器没法访问宿主机文件系统 |
| 用 SAPIEN 自带的 fallback ICD | ❌ ICD 指向 libGLX_nvidia.so.0,但容器里根本没这个 lib(toolkit 没挂) |
要让 SAPIEN 在容器里跑通,必须由平台 admin 改 deployment 模板:
env:
- name: NVIDIA_DRIVER_CAPABILITIES
value: "compute,utility,graphics"
单个用户改不动。这是论文不会写但部署里会卡你 24 小时的事:
-
论文里画的"我们在 Maniskill 评测"是在作者们自己配好的环境里
-
你要把那套 eval 流程搬到任何容器化部署,要先和平台谈妥 graphics capability
-
退路是 LIBERO:基于 mujoco + osmesa CPU 软渲染,不依赖 Vulkan,在标准容器里能跑。我用同样的容器在远程服务器上验证过 LIBERO 的
OffScreenRenderEnv能正常输出 128×128 RGB 的 agentview + eye-in-hand 图像这件事的 actionable take:闭环 eval 的 stack 选型先看你能控制什么。Vulkan-based sim(Maniskill / SAPIEN / Isaac Lab)依赖容器配置;mujoco + osmesa 的 LIBERO 在哪里都能跑。后者是 cloud-friendly 的默认。
3. 跨硬件实际部署
VLA 模型的卖点之一是 cross-embodiment——同一个模型应该能在不同机器人上工作。Spirit 训了 ALOHA / ARX5 / Franka / UR5 四种构型,OpenVLA 用了 OpenX 跨 24 种机器人。论文里都画了那张"我们能跨各种机器人"的图。
我手上能用的硬件是 XLeRobot——HuggingFace LeRobot 生态原生支持的开源双臂,亚马逊上 660 美元就能买到,4 小时组装,12-DoF(两条 SO-100 单臂各 6-DoF),只有头部相机。
把 14-DoF + 3 摄像头训练的 Spirit 跑在 12-DoF + 1 摄像头的 SO-100 上,理论上"cross-embodiment"应该有用。实际是 100 行 adapter + 一个非平凡的架构发现。
3.1 关节映射不是论文那张图
Spirit 期望的 ALOHA 单臂 7-DoF(7自由度):
[waist, shoulder, elbow, forearm_roll, wrist_angle, wrist_rotate, gripper]
XLeRobot 的 SO-100 单臂 6-DoF:
[shoulder_pan, shoulder_lift, elbow_flex, wrist_flex, wrist_roll, gripper]
差一个 forearm_roll——不是关节命名差异,是 SO-100 这个 $300 单臂物理上没有这个自由度。
我写的 adapter 用零填充:
XLE_TO_SPIRIT_ARM = [0, 1, 2, None, 3, 4, 5] # forearm_roll slot 填 0
State padding 12→14 容易,难的是 action unpadding 14→12 怎么处理 forearm_roll 这一维:直接丢?投影回最近的 wrist 关节?我目前选最简单的"丢",但这意味着模型预测的 forearm 旋转动作完全被忽略——是个潜在的 quality 损失,需要 finetune 修。
摄像头数也差:ALOHA 训练时有头部 + 左右腕共 3 个 240×320 视角,SO-100 只有头部一个。我 zero-shot 阶段把头部图复制 3 份塞进 3 个相机 slot(tile_cam_high=True)。这就是为什么我在博客末尾写 “zero-shot 数值看着对,但几乎肯定不能真机执行”——模型从未见过"左腕和右腕图像完全相同"这种输入分布。

图:SO-100 → ALOHA 关节和相机映射。每条 ALOHA 单臂 7 自由度,SO-100 单臂 6 自由度(缺 forearm_roll),用零填充补齐。摄像头是另一个 gap:ALOHA 训练时有 3 个视角,SO-100 只有头部相机,zero-shot 阶段我把头部图复制到 3 个 slot——这是模型从未见过的输入分布。
3.2 真正有意思的发现:robot_type 不是 learned embedding
Spirit 的 batch 里要传 robot_type 字段:
batch["robot_type"] = ["aloha"] # 或 "ARX5", "franka", "ur5"
我最初以为这是个 learned hardware embedding——模型有个 lookup table,根据 robot_type 给出不同的 hardware-conditioned 表达。
读源码后发现完全不是。在 utils/vlm_utils.py:get_user_prompt:
def get_user_prompt(language_instruction, robot_type):
if robot_type == "aloha":
prompt = f"You are controlling an ALOHA bimanual robot..."
elif robot_type == "ARX5":
prompt = f"You are controlling an ARX5 robot..."
# ...
return prompt + language_instruction
robot_type 只是被拼进 prompt 字符串。Spirit 通过 VLM 的语言理解能力来"知道"硬件差异,不是用 learned embedding。
这是个让我来回想了一会的设计选择。几个推论值得讨论:
为什么 SO-100 伪装成 “aloha” 居然有点用:因为 Qwen3-VL 在预训练时看过大量"ALOHA is a bimanual robot"这类语义。即使 SO-100 不是真正的 ALOHA,它也是双臂的,VLM 能给出大致合理的 attention pattern。
这种设计的脆弱性:
- 如果你的硬件 VLM 没"听说过",spoof 一个相近名字可能 work,但没有任何机制保证
- 如果你想加一种新硬件,没有 finetune 友好的 path——得改 prompt template + 重新训
- VLM 对 “ALOHA bimanual” 的理解可能和 RoboChallenge 数据里的 ALOHA 实际行为不一致——前者来自互联网文本,后者是 teleop 轨迹
对比 OpenVLA:OpenVLA 没有 robot_type 字段。它的方法是 OpenX 数据混训——不告诉模型"这是哪种机器人",让它从 visual + action 模式中学。哲学上更"end-to-end"。
哪种好?没人知道。两种范式都没在 cross-embodiment 上做严格对照实验。
4. 跑通的样子
§1 已经讲了延迟数字。这一节给一些"模型在干什么"的视觉证据。
5 条指令的 action chunk
跑 5 条不同的指令做 zero-shot 推理,每条产生一个 (60, 14) 的 action chunk:
- “pick up the red cube and place it on the blue plate”
- “put the coffee cup into the cabinet”
- “fold the white towel in half”
- “open the drawer and put the apple inside”
- “pour the contents of the bottle into the glass”
可视化每个 DoF 的轨迹曲线:
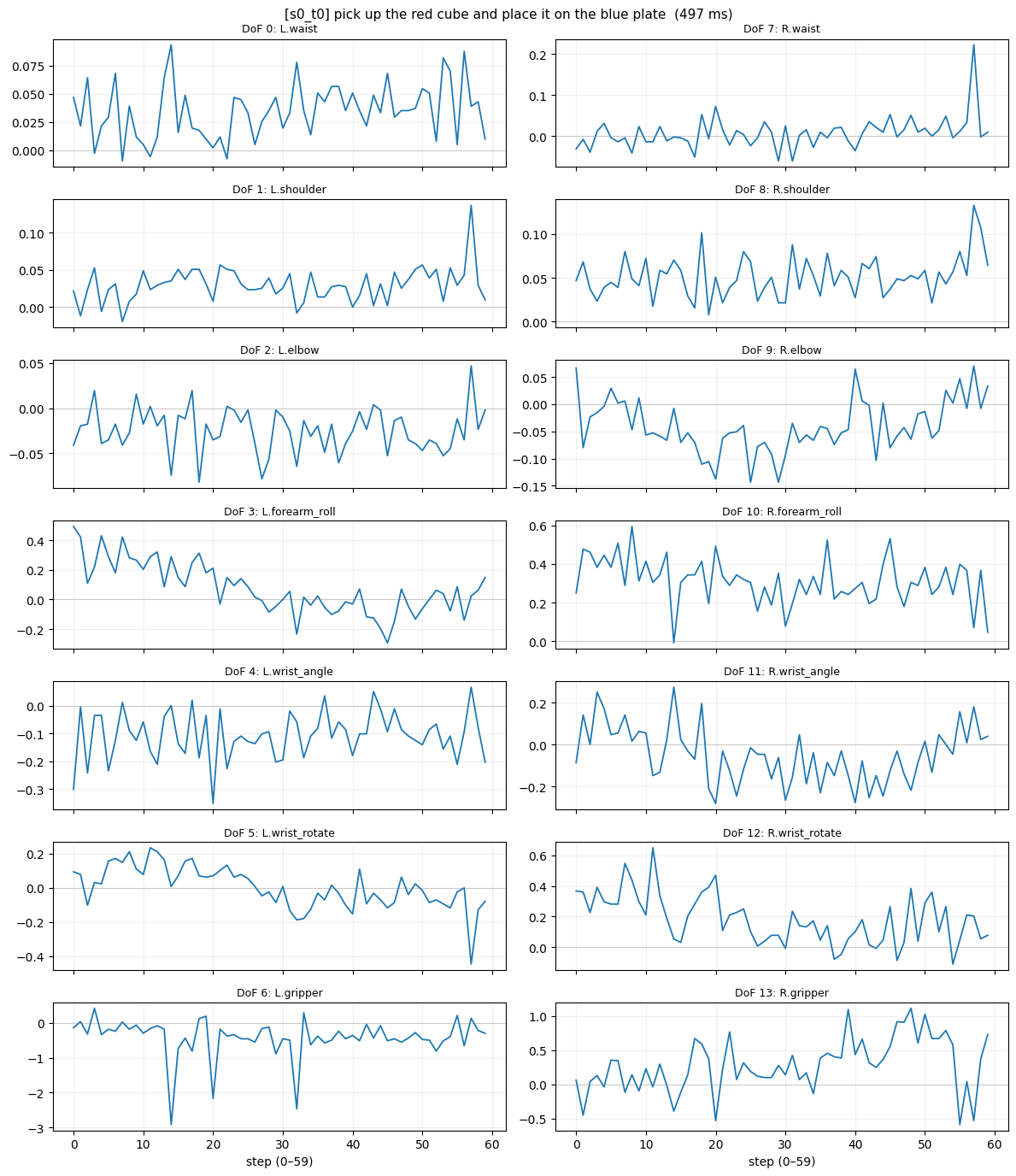
图:指令 “pick up the red cube and place it on the blue plate” 对应的 60 步 × 14 DoF action chunk。Left arm 和 Right arm 不对称(pick-place 是单臂任务),gripper 通道后半段往闭合方向走。完整 5 张图见 仓库。
Mujoco 中的开环 rollout
把 zero-shot 的 60 步 chunk 直接 replay 到 mujoco SO-100 模型上(开环,没有反馈控制),看看模型预测的轨迹"看起来像不像在做事":

GIF:60 步 chunk 在 mujoco 里开环 replay。可以看到机械臂确实在朝桌面物体方向运动——但抓不住。这印证了上一段的判断:zero-shot 的轨迹"有方向感",但没有真机执行能力。tile cam_high 让模型在猜腕部视角,不是真正看到。这是 Phase B finetune 要解决的事。
观察到的规律:
- Left arm 和 Right arm 的轨迹对称性弱——这合理,pick-place 是单臂任务
- Gripper 通道在 chunk 后半段往正方向走——符合"先靠近、后闭合抓取"的语义
- 5 条不同指令的 chunk 明显不一样——证明语言 condition 在起作用,不是只看图
5. 接下来想做的事(teaser)
这篇博客落点是"诚实记录跑通过程",下一篇的落点是用真实算法做事:在同一套 LIBERO 4-suite 上把 OpenVLA / Spirit v1.5 / π0.5 三家 base model 各自跑 SFT baseline,再在每家上分别做 DPO 和 GRPO 两种 post-training,看看 base × algo 的交叉效应。第一个真实的 Δ 已经出来了——OpenVLA × DPO 在 Spatial suite 上把成功率从 72% 推到 78% (+6),Object suite 0 净增但 per-task 重分配出现了"DPO 救活了 SFT 完全失败的任务"的失败模式翻转。
如果你也在做 VLA post-training / DPO / GRPO 方向,欢迎在评论或仓库里聊。
6. 给 Spirit 上游的建议
读完代码我整理了 4 条向上游的提议,两条 fix 两条 docs:
- feat:
SpiritVLAPolicy.from_pretrained加torch_dtype和device参数,和 HF transformers 对齐。当前实现把 device 写进config.json,部署到消费 GPU 必须临时改 ckpt 文件。 - fix:
utils/sampling.py的sample_noise/sample_time让 dtype 参数化,跟随 autocast 状态。当前硬编码 fp32 会和 bf16 DiT 内部 mismatch。 - docs:
robot_type字段文档化——读源码才知道这是 prompt 字符串而非 learned embedding。社区做 cross-embodiment 时这个差别影响很大。 - docs:“Running on consumer GPUs” 一节,把 RTX 3090 / 4090 上需要的 6 个 dtype workaround 整理出来。
完整的 4 条 PR/issue 草稿(含 reproduce、proposed change、reference fix)我放在了仓库的 docs/upstream_contributions.md。如果千寻团队看到欢迎交流,或者直接在 GitHub 上 ping 我。
附录 A:6 个部署 bug 摘要表
按 README 跑通 Spirit 期间踩到的 6 个 bug,每个详情链接到仓库 docs/troubleshooting.md:
| # | 一句话总结 | 层 |
|---|---|---|
| 1 | config.json 把 device 写死 "cuda" 导致 21GB fp32 直接撞 24GB 显存 |
加载 |
| 2 | _embed_suffix 的 state_proj 要求 bf16 但 state 是 fp32 |
dtype |
| 3 | Image cast 成 bf16 后 (img*255).astype(uint8) 跑挂——numpy<2.1 不支持 bf16 |
dtype |
| 4 | utils/sampling.py:sample_noise 硬编码 dtype=torch.float32 |
dtype |
| 5 | DiT 内部某中间层隐式返回 fp32 → autocast 兜底 | dtype |
| 6 | 推理输出 .cpu().numpy() 失败,bf16 不被 numpy 支持 |
dtype |
每个 bug 的现象、根因、修复都在 troubleshooting.md。也有一篇配套的 CSDN 部署经验文,专门展开这些细节,搜 “Spirit v1.5 部署 bf16” 应该能找到。
附录 B:复现指引
# 1. 拉镜像(任选一 registry)
docker pull <your-registry>/spirit-v1.1-cu128-py311
# 2. 拉模型权重(约 30 GB)
huggingface-cli download Spirit-AI-Team/spirit-v1.5
huggingface-cli download Qwen/Qwen3-VL-4B-Instruct
# 3. 跑 Phase A demo(5 条指令 × action chunk 可视化)
docker run --rm --gpus all \
-v $PWD/models:/workspace/models \
-v $PWD/code:/workspace/code \
spirit-v1.1-cu128-py311 \
python /workspace/code/spirit_adapter/phase_a_libero_scene_demo.py
完整的 adapter 实现、6 个 bug 修复细节、Vulkan 验证脚本都在 vla-lab/code/spirit_adapter/。
相关 repos
- vla-lab — Spirit v1.5 整合 + 跨硬件 adapter + 全部文档
- openvla-libero — OpenVLA LIBERO 4-suite 复现
- Spirit-AI-Team/spirit-v1.5 — 千寻官方
- VectorWang2/XLeRobot — $660 双臂机器人
写这篇的目的:中文 VLA 社区缺工程细节 + 诚实的 gap 记录。读论文的人多,把模型从论文搬到自己机器上、记录踩到的具体门槛的人少。希望这篇能帮到正在自己跑 VLA 的人。
如果你也在做开源 VLA / cross-embodiment / 闭环 eval,欢迎在评论区或仓库里聊。
📷 图集汇总
正文里的图按出现顺序汇总,加上彩蛋图 5。
图 1:3090 vs 服务器卡逐帧延迟对比 + p99 直方图。p99=234ms vs 157ms,σ 差 30×(论点一)。
图 2:SO-100 (12-DoF, 1 camera) → ALOHA (14-DoF, 3 cameras) 关节与相机映射。forearm_roll 0-pad;3 摄像头 slot 用 head cam tile(论点三)。
图 3:“pick up the red cube and place it on the blue plate” 指令的 60 步 × 14 DoF action chunk。Left/right arm 不对称(单臂任务),gripper 后半段闭合(§4 跑通的样子)。
图 4:60 步 chunk 在 mujoco 里开环 replay。机械臂朝物体方向运动但抓不住——zero-shot tile head cam 的代价(§4)。
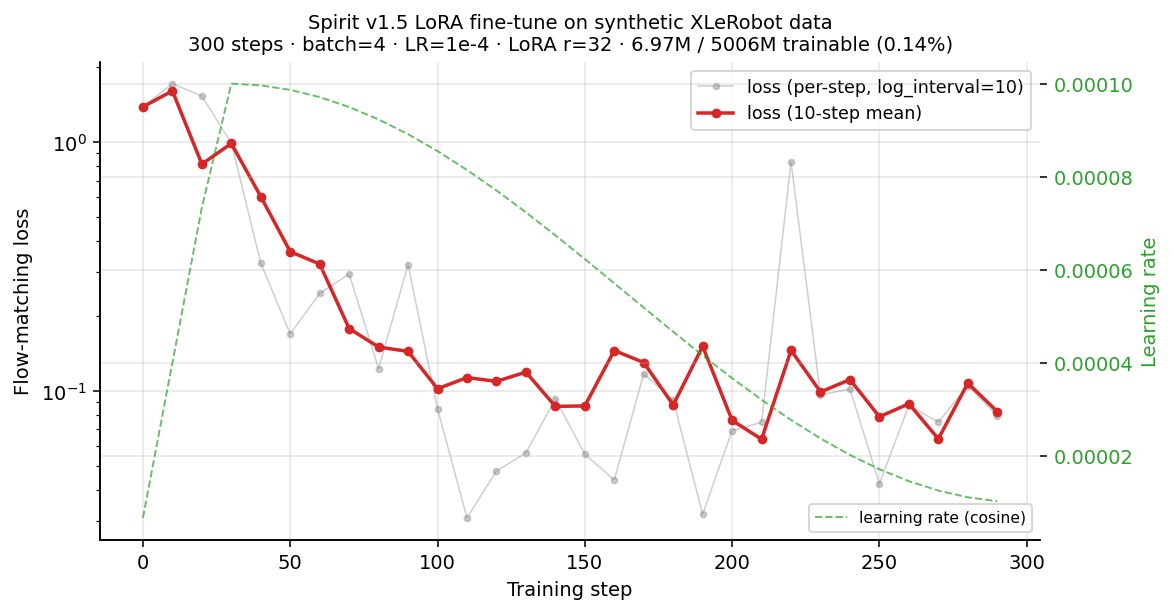
图 5(彩蛋·进度证据):Phase B-1 LoRA 在合成数据上的 smoke 训练。300 步 / 78s 内 loss 1.385 → 0.082(94%↓),证明 pipeline 可行。完整代码见 vla-lab/code/spirit_adapter/。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)