RAG入门:从零构建检索增强生成系统(第一节,向量化函数)
从零理解检索增强生成(Retrieval-Augmented Generation)
标签:RAG · LLM · Embedding · ChromaDB · Python · AI应用开发
前言
大语言模型(LLM)虽然强大,但有一个致命弱点:它的知识是静态的,来自训练数据,无法获取最新信息,也无法直接访问私有文档库。当你问它"我们公司昨天的会议纪要是什么?制度是什么?",它一无所知。
RAG(Retrieval-Augmented Generation,检索增强生成)正是为解决这一问题而生。它的核心思路是:先检索,再生成。把"回答问题"这件事拆成两步:
- 第一步:从知识库中检索与问题最相关的内容片段
- 第二步:把检索到的内容拼进 Prompt,让 LLM 基于这些内容生成回答
|
一句话理解RAG:给大模型配上"外部记忆",让它能随时查阅资料再回答你的问题,而不是凭空捏造。 |
本文是 RAG 系列的第一课,带你从零理解 RAG 的完整流程、核心概念、向量数据库选型,以及如何用 Python 实现一个最小可用的 RAG 系统。
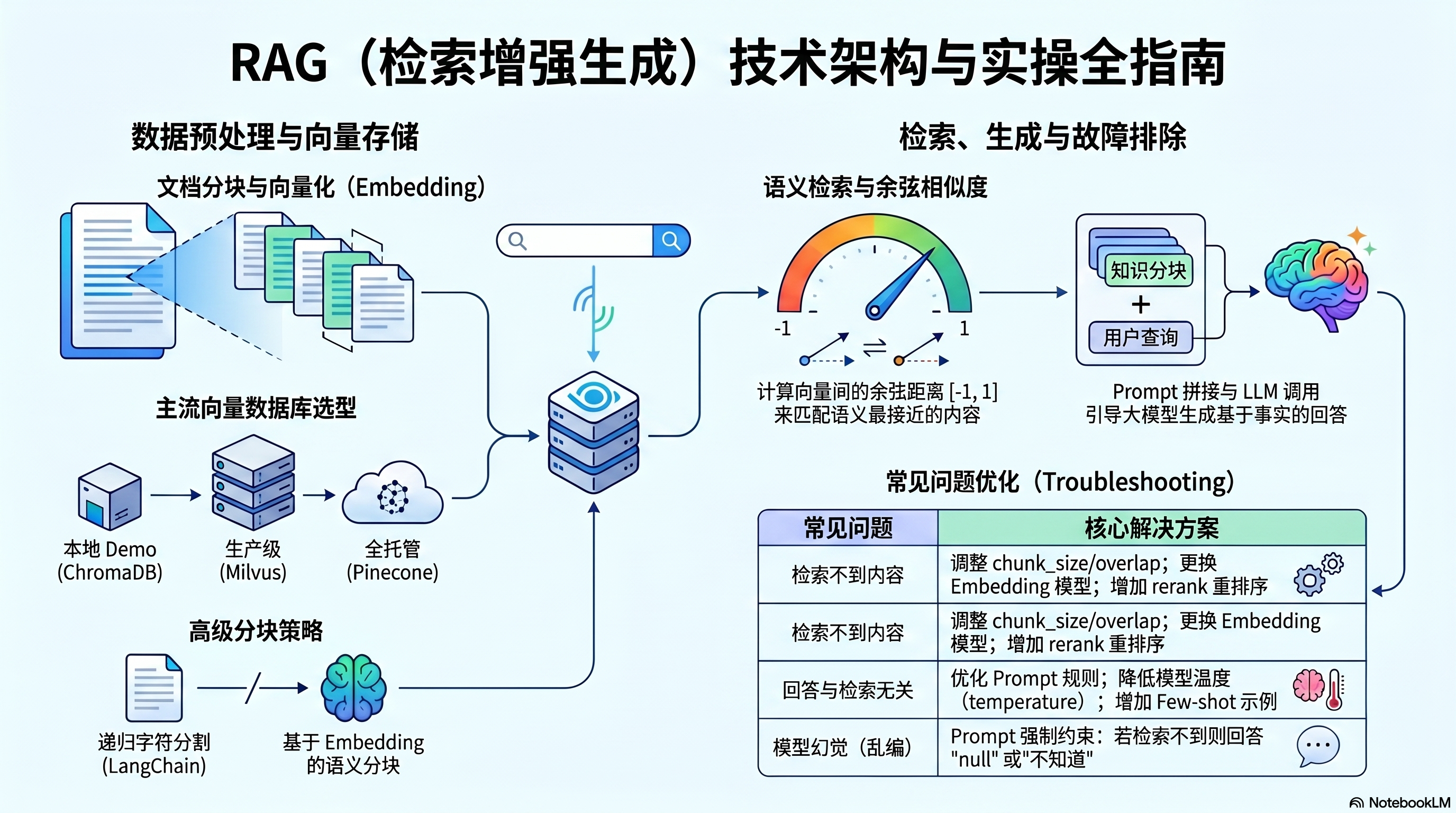
一、RAG 整体流程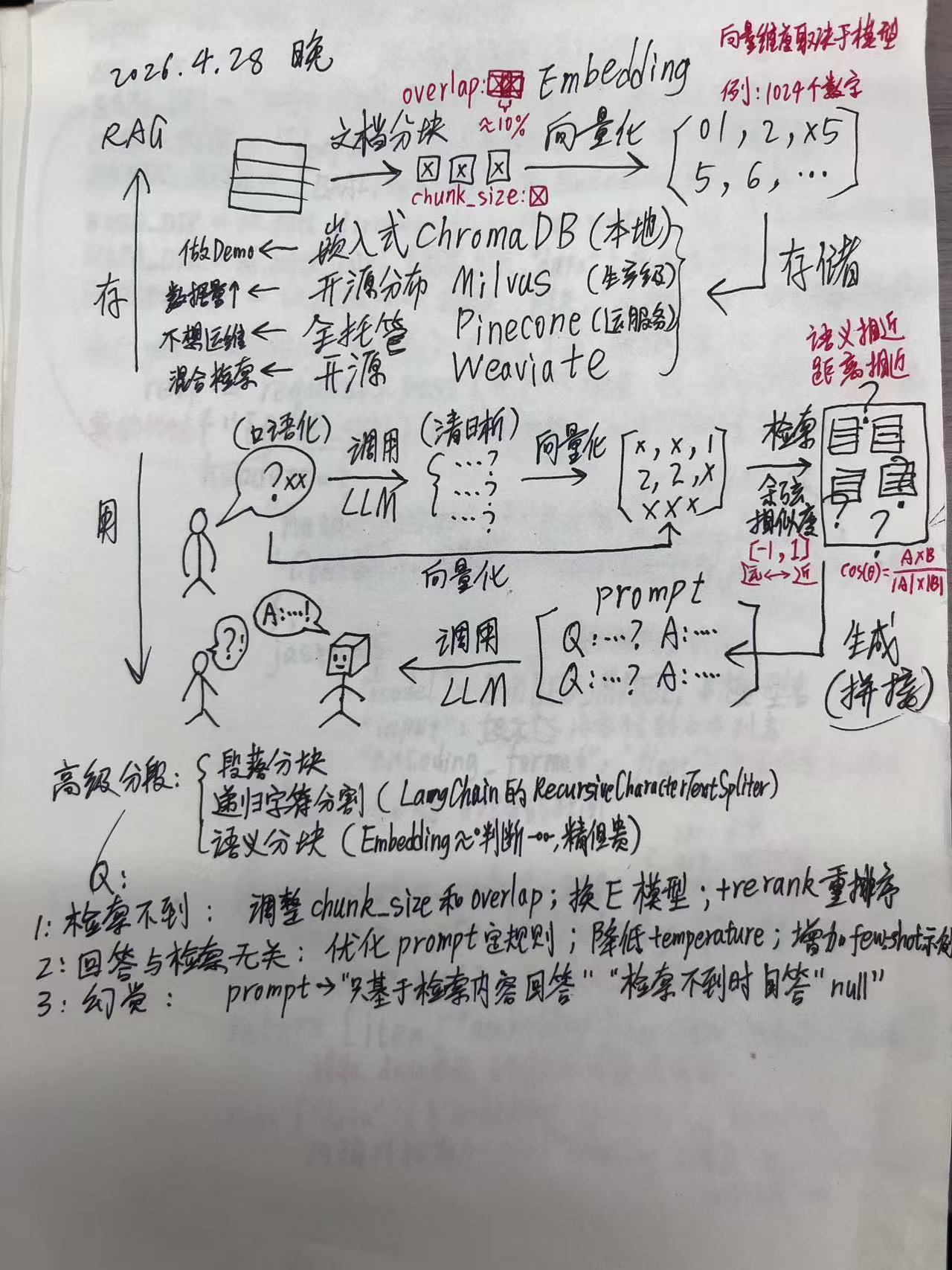
RAG 的完整流程分为两个阶段:索引阶段(预处理)和检索-生成阶段(在线处理)。
1.1 索引阶段(离线 / 一次性)
这一阶段是对知识库文档的预处理,需要提前完成:
- 文档分块(Chunking):将长文档切割成若干小块(Chunk),每块大小由 chunk_size 决定,相邻块之间有 overlap(重叠)约 10%,防止语义在块边界断裂。
- 向量化(Embedding):用 Embedding 模型将每个 Chunk 转换为高维数值向量(如 1024 维)。这个向量代表了该文本的语义信息。
- 存储到向量数据库:将所有 Chunk 的向量和原文存入向量数据库(如 ChromaDB),供后续检索使用。
|
关键参数: • chunk_size:每块文本的长度(字符数或 Token 数) • overlap:相邻块之间的重叠长度,通常为 chunk_size 的 10% |
1.2 检索-生成阶段(在线 / 每次问答)
用户提问后,系统实时执行以下步骤:
- 问题向量化:将用户的问题也用同一个 Embedding 模型转为向量。
- 相似度检索:在向量数据库中,用余弦相似度计算问题向量与所有 Chunk 向量的距离,找出最相似的 Top-K 个 Chunk。
- 拼接 Prompt:将检索到的 Chunk 原文和用户问题组合成 Prompt,发送给 LLM。
- LLM 生成回答:LLM 基于 Prompt 中的参考内容,生成最终回答。
|
相似度计算公式(余弦相似度): cos(θ) = (A·B) / (|A| × |B|) 值域 [-1, 1],越接近 1 越相似,越接近 -1 越相反。 |
二、核心概念详解
2.1 Embedding(文本向量化)
Embedding 是 RAG 的灵魂。它的作用是把自然语言映射到高维向量空间,使得语义相近的文本,在向量空间中距离也相近。
例如,"苹果手机很好用" 和 "iPhone 使用体验不错" 虽然字面不同,但 Embedding 后的向量会非常接近;而 "苹果手机很好用" 和 "今天天气不错" 的向量则差距较大。
向量通常包含几百到几千个数字,例如 BAAI/bge-m3 模型输出 1024 维向量,即一段文本被表示为 1024 个浮点数组成的列表:[0.1, 0.2, 0.5, …]
|
本课使用的 Embedding 模型:BAAI/bge-m3 特点:中英双语,语义理解强,适合 RAG 场景,通过 SiliconFlow API 免费调用。 |
2.2 文档分块策略
分块是 RAG 中容易被忽视但非常关键的步骤。分块质量直接影响检索效果。常见策略包括:
- 固定长度分块:按字符数或 Token 数均匀切割,简单直接,适合均匀文本。
- 递归字符分割(LangChain 的 RecursiveCharacterTextSplitter):优先按段落、句子等自然边界分割,语义保留更好。
- 语义分块(Semantic Chunking):用 Embedding 判断语义边界,精细度高但计算开销大,适合质量要求高的场景。
2.3 向量数据库
向量数据库专为高效存储和检索高维向量设计,支持语义近邻搜索(ANN)和语义距离计算。以下是常见选项对比:
|
名称 |
类型 |
易用性 |
适用场景 |
费用 |
|
ChromaDB |
嵌入式本地 |
✅ 极易 |
适合Demo/原型 |
开源免费 |
|
Milvus |
开源分布式 |
⚡ 中等 |
生产级大规模 |
开源,需部署 |
|
Pinecone |
全托管云服务 |
✅ 简单 |
快速上线,无运维 |
按量付费 |
|
Weaviate |
开源混合检索 |
⚡ 中等 |
语义+关键词混合 |
开源免费 |
本课使用 ChromaDB,它可以完全在本地运行,零配置,非常适合入门 Demo 和原型开发。
2.4 相似度检索
检索时系统需要在数百万甚至更多的向量中快速找到最相似的几条,主要有两种度量方式:
- 余弦相似度(Cosine Similarity):衡量向量方向的夹角,值域 [-1, 1],与向量长度无关,适合文本语义匹配。
- 欧氏距离(L2 Distance):衡量向量在空间中的绝对距离,适合图像等需要考虑量级的场景。
RAG 场景中,余弦相似度是最常用的选择。
三、代码实战:最小可用 RAG 系统
3.1 环境配置
本课使用 SiliconFlow API,国内可直接访问,无需翻墙,提供 DeepSeek-V3 和 BAAI/bge-m3 的免费额度。(本节主要看get_embedding函数的笔记)
|
pip install requests chromadb |

3.2 基础配置
|
import os, sys, io, json, requests # ===== 基础配置 ===== API_KEY = "sk-xxx" # 你的 SiliconFlow API Key BASE_URL = "https://api.siliconflow.cn/v1" # API 地址(兼容 OpenAI 格式) CHAT_MODEL = "deepseek-ai/DeepSeek-V3" # 大语言模型名称 EMBED_MODEL = "BAAI/bge-m3" # Embedding 模型名称 # ===== 路径配置 ===== BASE_DIR = os.path.dirname(os.path.abspath(__file__)) # 当前文件所在目录 DATA_DIR = os.path.join(BASE_DIR, "data") # 文档存放目录 CHROMA_DIR = os.path.join(BASE_DIR, "chroma_db") # 向量数据库存储目录 |
3.3 Embedding 函数实现
Embedding 函数负责将文本列表转换为向量列表。实现原理:向 Embedding API 发送 POST 请求,解析返回的 JSON 数据,提取每条文本对应的向量数组。
|
def get_embedding(texts: list[str]) -> list[list[float]]: """ 将文本列表转为向量列表 :param texts: 需要向量化的文本列表 :return: 向量列表,每个向量是 float 数组 """ resp = requests.post( f"{BASE_URL}/embeddings", # 专门负责向量化的端点 headers={ "Authorization": f"Bearer {API_KEY}", # 鉴权(相当于门禁) "Content-Type": "application/json" # 内容格式声明 }, json={ "model": EMBED_MODEL, # 用作向量化的模型 "input": texts, # 需要转换的文本列表 "encoding_format": "float" # 返回 float 格式的向量 }, timeout=30 # 超时 30 秒 ) # HTTP 状态码:200=正常,404=Not Found,500=服务器错误 if resp.status_code != 200: raise Exception(f"Embedding API 调用失败:{resp.text}") data = resp.json() # 解析返回的 JSON,存入 data # 提取 data 里面的数字向量并返回 # 例如 data = {"data": [{"embedding": [0.1,0.2,...],"index":0}, ...]} # 用列表推导式把每个 item["embedding"] 提取出来 return [item["embedding"] for item in data["data"]] |
3.4 文档索引(离线构建)
|
import chromadb from chromadb.utils import embedding_functions def build_index(data_dir: str, chroma_dir: str): """读取文档,分块,向量化,存入 ChromaDB""" # 初始化 ChromaDB(本地持久化) client = chromadb.PersistentClient(path=chroma_dir) collection = client.get_or_create_collection( name="rag_docs", metadata={"hnsw:space": "cosine"} # 使用余弦相似度 ) # 读取 data 目录中的所有 .txt 文件 docs = [] for fname in os.listdir(data_dir): if fname.endswith(".txt"): fpath = os.path.join(data_dir, fname) with open(fpath, "r", encoding="utf-8") as f: docs.append(f.read()) # 简单分块(固定长度,带 overlap) chunk_size = 500 overlap = 50 chunks = [] for doc in docs: for i in range(0, len(doc), chunk_size - overlap): chunk = doc[i: i + chunk_size] if chunk.strip(): chunks.append(chunk) # 批量向量化 print(f"共 {len(chunks)} 个 Chunk,开始向量化...") embeddings = get_embedding(chunks) # 存入向量数据库 collection.upsert( ids=[f"chunk_{i}" for i in range(len(chunks))], documents=chunks, embeddings=embeddings ) print("索引构建完成!") return collection |
3.5 检索 + 生成(在线问答)
|
def rag_query(question: str, collection, top_k: int = 3) -> str: """ RAG 问答:向量检索 + LLM 生成 :param question: 用户问题 :param collection: ChromaDB 集合 :param top_k: 返回最相似的 Top-K 个 Chunk :return: LLM 回答 """ # Step 1:将问题向量化 q_embedding = get_embedding([question])[0] # Step 2:在向量数据库中检索最相似的 Chunk results = collection.query( query_embeddings=[q_embedding], n_results=top_k ) retrieved_chunks = results["documents"][0] # 取第一个查询的结果 # Step 3:拼接 Prompt context = "\n\n---\n\n".join(retrieved_chunks) prompt = f"""你是一个知识库助手。请仅根据以下检索到的内容回答用户问题。 如果检索内容中没有相关信息,请回答"null",不要自行编造。 【检索到的内容】 {context} 【用户问题】 {question} 【回答】""" # Step 4:调用 LLM 生成回答 resp = requests.post( f"{BASE_URL}/chat/completions", headers={"Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json"}, json={ "model": CHAT_MODEL, "messages": [{"role": "user", "content": prompt}], "temperature": 0.3 # 降低 temperature 减少幻觉 }, timeout=60 ) if resp.status_code != 200: raise Exception(f"Chat API 调用失败:{resp.text}") return resp.json()["choices"][0]["message"]["content"] # ===== 主程序 ===== if __name__ == "__main__": import chromadb client = chromadb.PersistentClient(path=CHROMA_DIR) collection = client.get_or_create_collection( name="rag_docs", metadata={"hnsw:space": "cosine"} ) # 首次运行时构建索引 # build_index(DATA_DIR, CHROMA_DIR) # 开始问答 while True: q = input("请输入问题(输入 q 退出):").strip() if q.lower() == "q": break answer = rag_query(q, collection) print(f"\n回答:{answer}\n") |
四、常见问题与调优指南
4.1 检索不到相关内容
症状:明明文档里有答案,但 RAG 就是检索不到。
解决方案:
- 调整 chunk_size 和 overlap:块太大语义模糊,块太小上下文不足,建议从 300~500 字符开始调整。
- 换更好的 Embedding 模型(换 E 模型):模型的语义理解能力直接影响检索质量,如尝试 BAAI/bge-large-zh-v1.5。
- 加 Rerank 重排序:用 Reranker 模型对 Top-K 结果再次精排,进一步提升召回精度。
4.2 回答与检索内容无关
症状:检索到了正确内容,但 LLM 的回答答非所问。
解决方案:
- 优化 Prompt 约束规则:明确告诉 LLM "仅根据检索内容回答",禁止自行推断。
- 降低 temperature(如 0.1~0.3):减少模型的随机性和"创造力"。
- 增加 few-shot 示例:在 Prompt 中提供几个"检索内容→答案"的示例对,引导模型理解任务格式。
4.3 模型产生幻觉
症状:LLM 回答了问题,但答案是编造的,而非基于检索内容。
解决方案:
- 在 Prompt 中明确指令:"只基于检索内容回答,检索不到时回答 null"。
- 后处理验证:将 LLM 回答与检索到的 Chunk 做相似度比对,低于阈值时拒绝输出。
- 降低 temperature:同上,减少随机输出。
|
最佳实践:将这三个优化结合使用,可以显著提升 RAG 系统的可靠性。 |
五、高级分块策略简介
基础的固定长度分块适合入门,但在生产环境中,以下更高级的策略可以显著提升质量:
1. 固定分块(Fixed-size Chunking):最简单,按字符数/Token 数均等切割。适合格式均匀的文档,实现成本低。
2. 递归字符分割(Recursive Character TextSplitter):LangChain 提供,优先按段落 → 句子 → 单词顺序递归切割,尽量保留自然语义边界,是目前最常用的生产级方案。
3. 语义分块(Semantic Chunking):用 Embedding 模型计算相邻句子间的语义距离,当语义距离突然增大时在此处切割。精细度最高,但计算开销大,适合高质量文档处理。
六、总结与下一步
本文覆盖了 RAG 基础第一课的完整内容,包括:
- RAG 的整体架构(索引阶段 + 检索-生成阶段)
- 核心概念:Embedding、文档分块、向量数据库、余弦相似度
- 向量数据库选型:ChromaDB / Milvus / Pinecone / Weaviate
- 完整代码实现:get_embedding → build_index → rag_query
- 常见问题与调优:检索不到、回答跑偏、模型幻觉的解法
后续计划:
- 继续分享手写笔记
- LangChain 快速搭建 RAG Pipeline
- Rerank 重排序与混合检索实战
- RAG 评估指标与 RAGAS 框架

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)