深入理解 DPDK:为什么说内存管理机制才是性能的核心
在使用 DPDK 进行高性能网络开发时,很多人首先关注的是收发包接口,例如 rte_eth_rx_burst() 和 rte_eth_tx_burst()。
但在实际工程中,如果只把 DPDK 理解为“高速收发包框架”,往往会忽略它真正的核心:内存管理体系。
事实上,DPDK 的高性能很大程度上来自其精心设计的内存模型。
一、为什么内存才是瓶颈
在现代服务器中,CPU 主频提升已经放缓,但网络速率持续增长:
- 10G
- 25G
- 40G
- 100G
- 200G
高速网络系统中,真正限制性能的往往不是算力,而是:内存访问效率。
尤其在数据面应用中,每个报文都涉及:
- 缓冲区申请
- 缓冲区释放
- 数据读写
- 跨核传递
- cache 一致性
如果内存模型设计不好,即使 CPU 很空闲,吞吐也上不去。
二、DPDK 内存设计目标
DPDK 的内存体系主要解决三个问题:
1. 避免频繁 malloc/free
普通程序常见:
buf = malloc(size);
free(buf);这种方式在高速转发场景中完全不可接受。
原因:
- 锁竞争
- 碎片化
- 系统调用开销
2. 提升缓存命中率
CPU 实际处理速度很快,但:
如果频繁访问主存,性能会急剧下降。
因此必须尽量保证:
- 数据连续
- cache friendly
- 避免跨核访问
3. 支持 DMA
网卡直接通过 DMA 访问物理内存:
所以内存必须:
- 连续
- 可映射
- 可固定
三、Hugepage:DPDK 的第一层基础
DPDK 默认使用 hugepage。
常见大小:
- 2MB
- 1GB
相比普通页:
| 类型 | 大小 |
|---|---|
| normal page | 4KB |
| hugepage | 2MB |
| hugepage | 1GB |
为什么使用大页
1. 减少 TLB miss
TLB 缓存虚拟地址映射。
普通页太小:
一个大内存池需要大量页表项。
大页减少:
- 页表项数量
- 地址转换次数
2. 提高 DMA 连续性
网卡喜欢连续物理内存。
hugepage 更适合:
- DMA 映射
- mbuf 池管理
配置 hugepage
echo 1024 > /sys/kernel/mm/hugepages/hugepages-2048kB/nr_hugepages挂载:
mount -t hugetlbfs nodev /mnt/huge四、mempool:高性能对象池
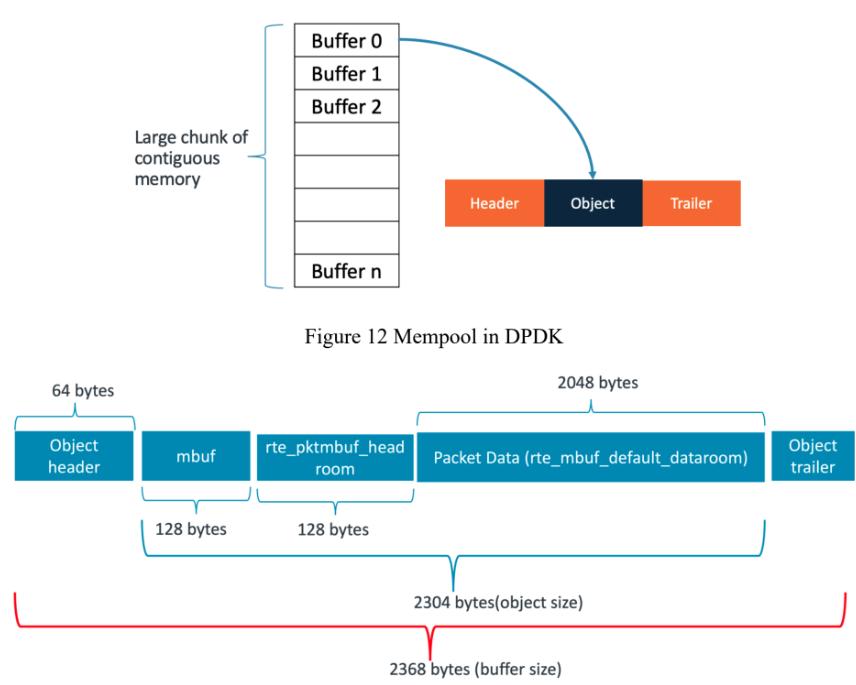
DPDK 不使用 malloc。而是:mempool。
本质:对象池。
创建方式
struct rte_mempool *mp = rte_pktmbuf_pool_create(
"MBUF_POOL",
8192,
256,
0,
RTE_MBUF_DEFAULT_BUF_SIZE,
rte_socket_id()
);设计思想
一次性预分配:
[mbuf][mbuf][mbuf][mbuf][mbuf]运行过程中:
只做:
- acquire
- release
而不做动态分配。
优势
1. 无碎片
固定大小对象。
2. lockless
内部 ring 管理。
3. cache 优化
支持 per-core cache。
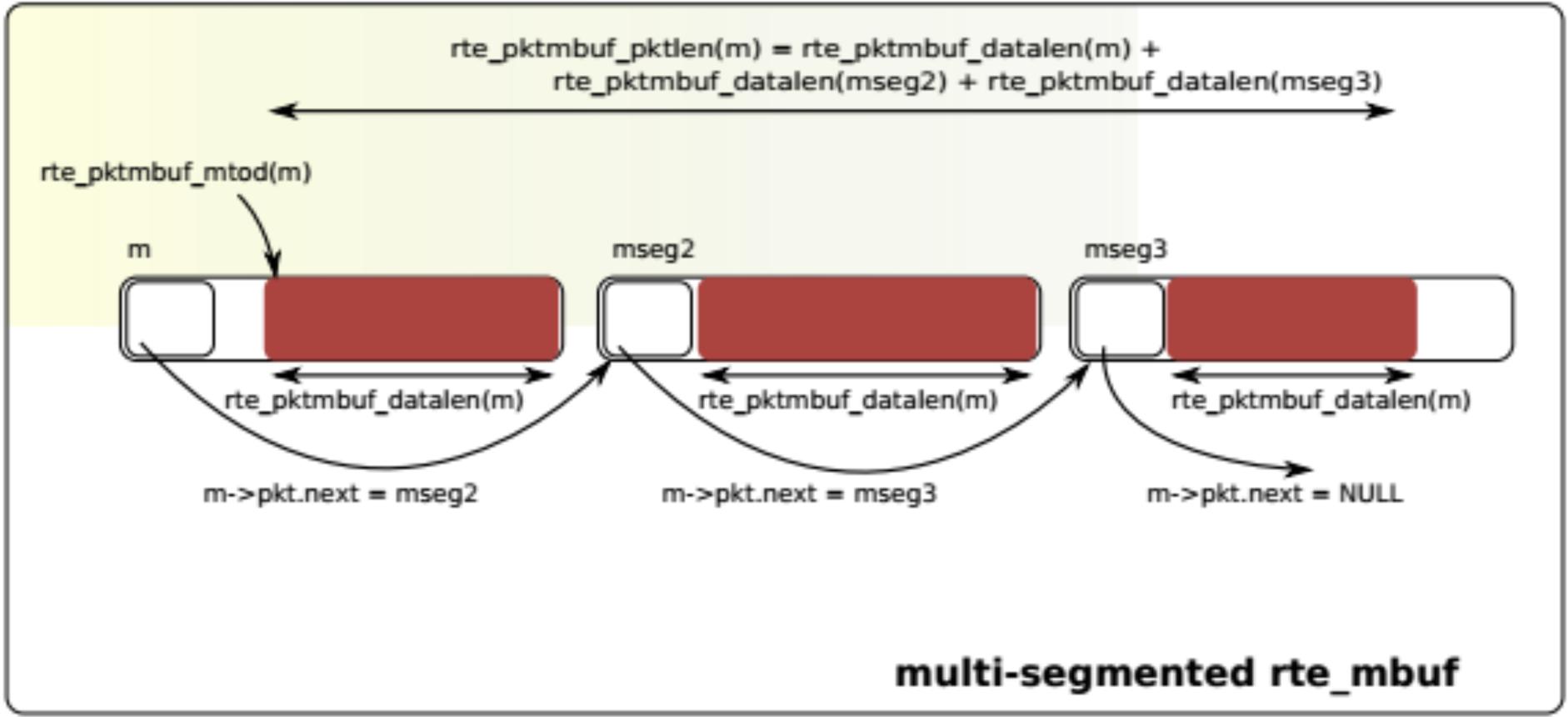
五、mbuf:DPDK 的报文载体
所有报文都封装在:
rte_mbuf
中。
这是最关键的数据结构。
mbuf 结构
简化如下:
struct rte_mbuf {
void *buf_addr;
uint16_t data_off;
uint16_t pkt_len;
uint16_t data_len;
uint64_t ol_flags;
};作用
描述:
- 报文地址
- 长度
- 元信息
- offload 状态
实际内存布局
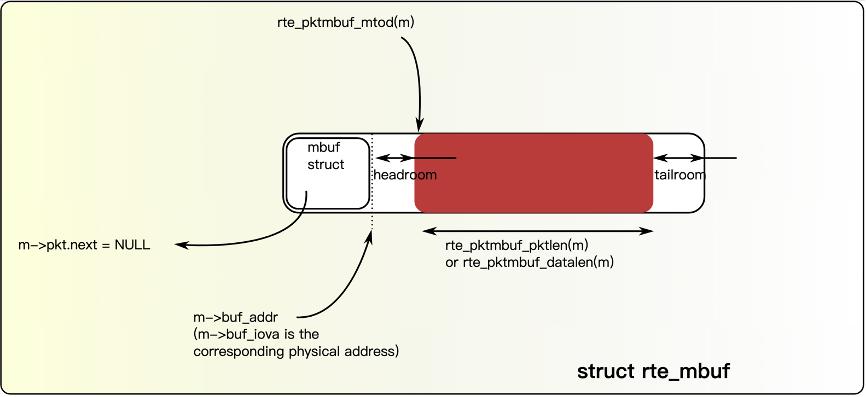
+----------------+
| rte_mbuf |
+----------------+
| headroom |
+----------------+
| packet data |
+----------------+
| tailroom |
+----------------+六、为什么要有 headroom
很多人第一次看不理解。
headroom 的作用非常重要。
例如:增加 VLAN 标签:
Ether + VLAN + IP需要在前面插入数据。
如果没有 headroom:必须重新拷贝。
有 headroom:直接前移指针。
极高效。
七、per-core cache 设计
这是 DPDK 非常精妙的地方。
问题
假设所有 core 共用一个池:
多个核同时申请:
core0 -> alloc
core1 -> alloc
core2 -> alloc会导致:
- cache line 抖动
- 自旋锁争用
解决方案
每个核本地缓存:
core0 local cache
core1 local cache
core2 local cache先从本地取。
本地空再去全局池。
优势
性能提升非常明显。
通常:10% ~ 40%
八、实际项目中的典型问题
1. mbuf 泄漏
最常见问题。
错误:
if (drop)
return;忘记释放:
rte_pktmbuf_free(m);后果:
- mempool 用尽
- 收包停止
- 业务中断
2. mbuf 二次释放
也非常危险。
例如:
rte_pktmbuf_free(m);
rte_pktmbuf_free(m);结果:
- 崩溃
- 内存损坏
3. cache 配置错误
例如:
cache_size = 0;性能会明显下降。
建议:
256
512我常用。
九、工程优化经验
推荐配置
小流量低延迟
mempool = 4096
cache = 128
burst = 16高吞吐
mempool = 65535
cache = 512
burst = 32大规模网关
mempool = 262143
cache = 512十、总结
很多人认为 DPDK 的核心是 PMD。
其实从工程角度看:真正决定性能上限的是:内存系统设计。
包括:
- hugepage
- mempool
- mbuf
- per-core cache
- NUMA 绑定
这些共同构成 DPDK 的性能基础。
可以说:如果不了解这些机制,即使会写 DPDK 程序,也只是“会调用 API”。
而真正理解之后,你会发现:DPDK 更像一个:用户态高性能运行时系统。
而不仅仅是一个网络库。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)