AI Agent 架构深度解析:从本地“养龙虾到云端蜂群作战
AI Agent 架构深度解析:从本地“养龙虾”到云端“蜂群作战”
摘要
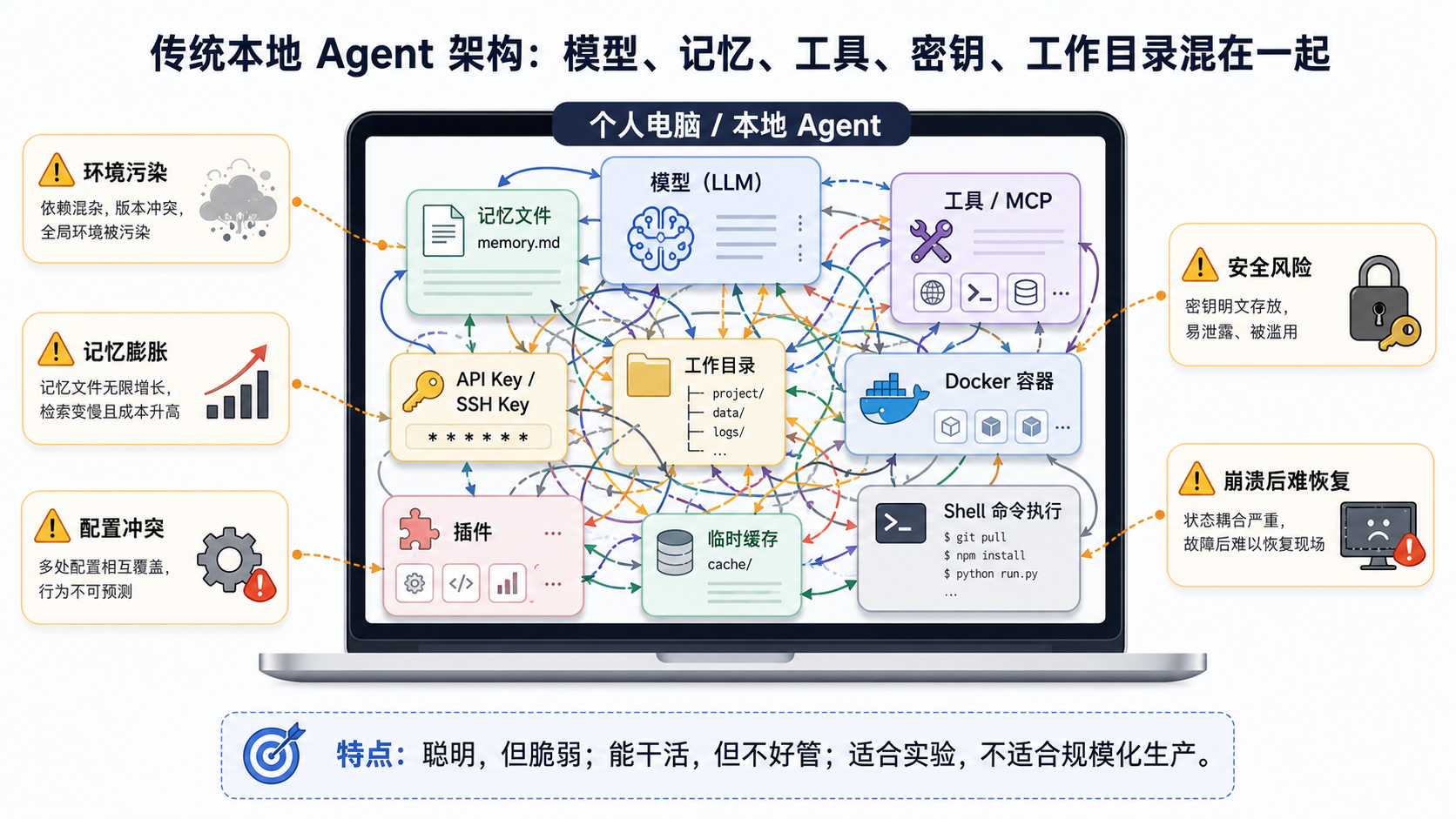
过去我们使用 AI Agent,更像是在个人电脑里“养一只很聪明但很脆弱的宠物”:环境要自己配,插件要自己装,记忆文件越跑越大,Docker、MCP、CLI、API Key、工作目录混在一起,一旦配置错乱或者上下文污染,整个系统就容易崩掉。
但 Agent 的工程化方向正在发生变化。新的趋势不是继续在本地堆更多模型、更多插件、更多脚本,而是把 Agent 变成一种类似大数据任务调度的基础设施:可销毁、可恢复、可并行、可审计、可弹性扩展的智能 Worker。
一句话概括:
AI Agent 正在从“本地工具”进化为“云原生智能任务调度系统”。
Anthropic 在 2026 年 4 月 8 日发布的 Managed Agents 工程文章中提出了一个非常关键的思想:Decoupling the brain from the hands,也就是把“大脑”和“双手”解耦。其中,大脑负责规划、推理、决策,双手负责代码执行、文件操作、工具调用、沙盒运行。Anthropic 还明确提到,旧的 agent harness 往往会把对模型能力的假设写死,而随着模型能力提升,这些假设会迅速过时。(Anthropic)

一、为什么说传统本地 Agent 是“养宠物”?
很多人刚开始玩 Agent,通常是这样的架构:
个人电脑
├── Claude Code / Codex / OpenClaw
├── 本地工作目录
├── MCP 配置
├── API Key
├── Docker 容器
├── 临时缓存
├── memory.md
├── 插件目录
└── 各种脚本
这个阶段很有趣,也很适合个人探索。但问题也非常明显。
1. 环境污染严重
Agent 会跑命令、装依赖、改代码、生成文件、调用插件。时间一长,本地环境里可能出现:
- npm / pnpm / pip 依赖混乱;
- Docker 容器残留;
- MCP 配置冲突;
- 临时文件越来越多;
- 工作目录被反复修改;
- 插件版本互相影响。
最终结果是:这个 Agent 不是越用越稳定,而是越用越脏。
2. 记忆越来越臃肿
很多本地 Agent 的记忆方式很粗糙,要么靠聊天上下文,要么靠一个不断追加的 memory.md,要么靠本地缓存文件。
刚开始还行,跑久了就会出现:
记忆越来越长
上下文越来越乱
Prompt 越来越脏
模型越来越容易误判
这就是所谓的“记忆膨胀”。
3. 失败恢复能力弱
本地 Agent 一旦中途崩溃,经常会遇到:
- 当前任务状态丢失;
- 文件改了一半;
- 测试跑了一半;
- 上下文断掉;
- 只能人工接着排查。
这和企业系统里的任务调度完全不是一个级别。
4. 安全边界模糊
Agent 一旦能执行代码,就必须考虑安全问题。模型生成的代码并不天然可信。如果执行环境里同时放着 Git 密钥、API Key、生产配置,就存在很大的风险。
所以,传统本地 Agent 的本质是:
聪明,但脆弱;能干活,但不好管;适合实验,不适合规模化生产。
二、什么叫“从养宠物到养牛马”?
在云原生和大规模运维领域,有一个经典说法:Pets vs Cattle。
- 宠物式服务器:每台机器都有名字,坏了要修,不能随便删。
- 牛马/牲畜式服务器:实例无状态,坏了就销毁,重新拉起一个。
这个思想放到 Agent 上,就是:
旧模式:Agent 是宠物
- 本地维护
- 状态混杂
- 配置复杂
- 崩了要修
新模式:Agent 是 Worker
- 无状态
- 可销毁
- 可重建
- 可恢复
- 可并发调度
Anthropic 的 Managed Agents 文章中也提到,解耦后容器变成了 cattle:如果容器死掉,harness 可以把失败当成一次工具调用错误返回给 Claude,如果需要重试,就重新初始化一个新的容器。(Anthropic)
这就是 Agent 架构的核心转变:
不再精心维护某一个 Agent,而是构建一套可以不断创建、销毁、恢复、调度 Agent 的系统。
三、核心架构思想:大脑与双手解耦
传统 Agent 的问题,是把所有东西塞在一起:
模型 + 工具 + 文件 + 沙盒 + 记忆 + 执行环境
新架构要拆开:
大脑:LLM + Harness + Planner
双手:Sandbox + Tools + MCP + Shell
记忆:Session Store + Event Log
产物:Artifact Store
权限:Vault + Policy + Proxy
图 1:传统本地 Agent 架构
这个架构最大的问题是:所有状态都耦合在一个本地 Agent 里。
图 2:新一代 Agent 云原生架构
新架构里,Agent 不直接拥有全部状态,而是通过接口访问外部能力。
Anthropic 对 Managed Agents 的抽象也类似:把 session 定义为发生过的一切的追加日志,把 harness 定义为调用 Claude 并路由工具调用的循环,把 sandbox 定义为 Claude 可以运行代码和编辑文件的执行环境。这样,每个部分都可以独立替换。(Anthropic)
四、四层架构模型:从单 Agent 到蜂群 Agent
可以把新一代 Agent 平台拆成四层。
第一层:Agent 与 Sandbox
这一层解决的是:谁思考,谁执行。
Agent Brain
负责:
- 理解任务
- 拆解步骤
- 调用工具
- 判断结果
- 继续规划
Sandbox Hands
负责:
- 执行 shell
- 修改文件
- 跑测试
- 构建项目
- 调用外部工具
核心原则是:
大脑不直接污染环境,双手不保存核心记忆。
这样做的好处非常明显:
- 沙盒坏了可以重建;
- 工具出错可以重试;
- 执行环境可以隔离;
- Agent 不被某一个本地目录绑定;
- 安全权限可以统一代理。
第二层:Coordinator 协调者
一个复杂任务往往不是一个 Agent 能高效完成的。
比如你让 AI 完成一个 Java 项目的重构,它可能涉及:
- 需求理解;
- 代码阅读;
- 接口设计;
- 数据库调整;
- 代码修改;
- 单元测试;
- 安全检查;
- 文档生成;
- 发布说明。
这时就需要 Coordinator。
图 3:Coordinator 多 Agent 调度模型
Anthropic 的 Claude Managed Agents 文档中,multiagent sessions 支持配置 coordinator,并把任务委派给 agent roster 中的其他 agent。文档中还提到,multiagent.agents 最多可以列出 20 个唯一 agent,coordinator 也可以调用同一 agent 的多个副本。(Claude)
这就很像一个小型团队:
主 Agent = 项目经理
子 Agent = 开发、测试、审查、文档、数据分析等角色
第三层:Session 会话
Session 不只是聊天记录,而是一次任务执行的完整现场。
它应该记录:
Session
├── 用户原始需求
├── Agent 拆解过程
├── 工具调用记录
├── Shell 执行结果
├── 文件修改记录
├── 错误日志
├── 中间产物
├── 人工确认记录
└── 最终交付结果
也就是说,Session 是 Agent 系统的“任务上下文”。
Anthropic 文档中也提到,session 级别的 event stream 是主线程,可以看到跨线程活动的压缩视图;而 session thread 可以深入查看某个具体 agent 的活动。multiagent session 最多支持 25 个并发线程。(Claude)
这说明,Agent 平台已经不是简单的“聊天窗口”,而是在做类似任务流、事件流、线程流的工程化管理。
第四层:Session Store / Event Log
这是整个架构最关键的部分。
以前的本地 Agent 记忆通常是:
聊天上下文 + 本地文件 + 临时缓存
新架构应该是:
Session Store
├── session_id
├── agent_id
├── event_id
├── event_type
├── input
├── output
├── tool_call
├── artifact_ref
├── status
└── created_at
换句话说,Agent 的记忆不应该只依赖模型上下文,而应该变成可查询、可恢复、可审计的事件日志。
Anthropic 在工程文章中提到,session log 放在 harness 外部后,harness 崩溃时不需要保留内部状态,新的 harness 可以通过 sessionId 获取事件日志并继续执行。(Anthropic)
这就是“无状态 Agent”的关键。
五、为什么说它像“大数据任务调度”?
对做过数据平台的人来说,这套 Agent 架构其实非常熟悉。
| 大数据系统 | Agent 系统 |
|---|---|
| DolphinScheduler / Airflow | Coordinator |
| DAG 任务图 | Task Graph |
| Worker / TaskManager | Agent Worker |
| YARN Container / K8s Pod | Sandbox |
| Checkpoint | Session Store |
| Event Log | Agent 执行日志 |
| HDFS / 对象存储 | Artifact Store |
| Ranger / Kerberos | 权限与密钥管理 |
| 任务重试 | Agent 重试 |
| 任务审计 | Agent 行为审计 |
所以这句话非常关键:
从个人电脑里维护几个脆弱 Agent,升级为像调度大数据任务一样调度一群可销毁、可恢复、可并行、可审计的智能 Worker。
这不是比喻,而是一种真实的架构变化。
以前我们问的是:
哪个模型更强?
哪个插件更好用?
哪个 CLI 更顺手?
以后更应该问的是:
Agent 怎么调度?
Session 怎么恢复?
Sandbox 怎么隔离?
权限怎么控制?
行为怎么审计?
Token 成本怎么统计?
失败怎么重试?
产物怎么追踪?
六、企业级 Agent 平台应该长什么样?
如果自己设计一个企业级 Agent 平台,可以参考下面这个架构。
图 4:企业级 Agent Runtime 架构
这个平台至少要包括以下模块。
| 模块 | 作用 |
|---|---|
| Task API | 接收用户任务 |
| Coordinator Service | 拆解任务、分配 Agent |
| Agent Registry | 管理不同 Agent 的模型、Prompt、工具 |
| Task Graph Engine | 编排任务 DAG |
| Sandbox Manager | 创建、销毁、恢复执行环境 |
| MCP Gateway | 管理工具调用 |
| Session Store | 保存任务上下文 |
| Event Log | 保存完整执行轨迹 |
| Artifact Store | 保存代码、报告、日志、文件 |
| Vault / Policy | 管理密钥和权限 |
| Observability | 监控 Token、耗时、失败率、行为审计 |
Palantir AIP 也是类似方向。Palantir 官方文档中描述,AIP 连接 AI 与企业数据和业务操作,支持自动化运营流程,并提供用于构建生产级 AI workflows、agents 和 functions 的工具。它还强调安全、审计、资源管理、可观测性以及与企业数据平台的结合。(palantir.com)
七、沙盒为什么会成为 Agent 基础设施的核心?
Agent 一旦能执行代码,就一定需要沙盒。
原因很简单:模型生成的代码不一定安全。
它可能会:
- 删除文件;
- 修改配置;
- 读取敏感目录;
- 执行危险命令;
- 访问不该访问的网络;
- 误用 API Key;
- 安装不可信依赖。
所以,Agent 的执行环境必须隔离。
传统 Docker 可以解决一部分问题,但在高并发、强隔离、快速启动场景下,Docker 不是唯一选择。腾讯云开源的 CubeSandbox 就是一个面向 AI Agent 的高性能沙盒项目。它基于 RustVMM 和 KVM,兼容 E2B SDK,项目 README 中宣称可以在 60ms 内创建具备完整服务能力的硬件隔离沙盒,并保持低于 5MB 的内存开销。(GitHub)
可以简单理解为:
| 方案 | 特点 |
|---|---|
| 本地 Shell | 快,但极不安全 |
| Docker | 较轻量,但隔离有限 |
| 传统 VM | 隔离强,但启动重 |
| MicroVM / CubeSandbox | 目标是兼顾速度、隔离和密度 |
未来 Agent 系统很可能会把沙盒当成标准基础设施,就像大数据平台里的 YARN Container、K8s Pod 一样。
八、最小可落地版本:个人开发者怎么做?
不一定一上来就做复杂平台。可以先做一个最小版本。
V1:单机版 Agent 调度器
agent-platform
├── task-api
├── coordinator
├── agent-registry
├── sandbox-manager
├── session-store
├── event-log
├── artifact-store
└── web-ui
核心流程
最小数据库表
| 表名 | 说明 |
|---|---|
| agent_definition | Agent 定义,包含模型、Prompt、工具权限 |
| agent_session | 一次任务会话 |
| session_event | 所有对话、工具调用、状态变化 |
| task_node | 任务图节点 |
| sandbox_instance | 沙盒实例记录 |
| artifact | 任务产物 |
| model_usage | Token、成本、耗时统计 |
| tool_permission | 工具调用权限控制 |
九、一个具体场景:让 Agent 自动改造 Spring Boot 项目
假设用户提交任务:
给当前 Spring Boot 项目新增一个订单导出功能,要求支持分页查询、Excel 导出、权限校验和单元测试。
传统做法是一个 Agent 从头干到尾。
新架构可以这样调度:
每个 Agent 都可以独立运行在自己的沙盒中:
代码实现 Agent:负责 Controller / Service / Mapper
测试 Agent:负责单元测试和接口测试
安全 Agent:检查权限绕过和导出风险
文档 Agent:生成接口说明和变更说明
Coordinator:负责收口和冲突合并
这种方式的优势是:
- 并行执行,速度更快;
- 子任务更清晰;
- 失败可以局部重试;
- 每个 Agent 的行为可追踪;
- 最终产物可审计。
十、Token Efficiency:不是所有任务都要用最贵模型
企业级 Agent 平台还有一个非常重要的能力:Token 成本优化。
不是所有任务都要用最强模型。
可以这样分配:
| 任务类型 | 模型策略 |
|---|---|
| 复杂规划 | 强推理模型 |
| 普通代码生成 | 代码模型 |
| 日志整理 | 便宜长上下文模型 |
| 文档润色 | 通用模型 |
| 测试用例生成 | 中等模型 |
| 安全审查 | 高可靠模型 |
| 结果摘要 | 小模型 |
这就是 Token Efficiency:
用合适的模型做合适的任务,让每一份 Token 都产生最大价值。
未来 Agent 平台不仅要会“调用模型”,还要会“调度模型”。
十一、国内开发者应该重点关注什么?
很多人现在还停留在:
Claude Code 好不好?
Codex 强不强?
MiniMax 能不能写代码?
DeepSeek 便不便宜?
OpenClaw 怎么部署?
这些当然重要,但更重要的是下一层:
Agent Runtime 怎么设计?
Session 怎么持久化?
Sandbox 怎么隔离?
MCP 怎么治理?
多 Agent 怎么协同?
执行过程怎么审计?
失败任务怎么恢复?
Token 成本怎么统计?
未来真正有价值的方向,不只是“会用 Agent”,而是能设计一套 Agent 工程化平台。
这类能力会越来越像:
- 数据平台工程师;
- 调度系统工程师;
- 云原生平台工程师;
- DevOps 工程师;
- AI 应用架构师。
甚至可以出现一个新角色:
Agent Orchestration Engineer,Agent 编排工程师。
这个角色关注的不是单个模型,而是一群 Agent 如何稳定、安全、低成本地完成复杂任务。
十二、总结:Agent 的未来不是聊天框,而是智能任务系统
过去,AI Agent 更像一个本地增强工具。
现在,它正在变成一种新的基础设施。
可以用三句话总结:
1. Agent 要无状态化
Agent 本身不应该保存关键状态。状态应该放在 Session Store、Event Log、Artifact Store 里。
2. 执行环境要沙盒化
模型负责思考,沙盒负责执行。沙盒应该可销毁、可重建、可隔离、可审计。
3. 多 Agent 要调度化
未来不是一个 Agent 单打独斗,而是 Coordinator 调度多个专业 Agent,并行完成复杂任务。
最终,AI Agent 的工程化方向就是:
模型大脑
+ 沙盒双手
+ 外置记忆
+ 多 Agent 协调
+ 权限隔离
+ 事件审计
+ 产物管理
+ 成本统计
+ 失败恢复
这就是从本地“养龙虾”到云端“蜂群作战”的真正含义。
以前我们是在个人电脑里维护几个脆弱 Agent。
未来我们会像调度大数据任务一样,调度一群可销毁、可恢复、可并行、可审计的智能 Worker。
文章结尾金句
Agent 的核心竞争力,不再只是模型聪不聪明,而是能不能被稳定、安全、低成本地调度起来。
未来的 Agent 平台,本质上不是聊天工具,而是智能任务操作系统。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)