00:RAG 概述与核心概念
学习笔记:详述 RAG 的定义起源、工作流程、架构组件以及解决的问题
目录
- 概述
- RAG 的起源与定义
- 为什么需要 RAG
- RAG 的核心工作流程
- 架构组件详解
- 文本分块策略
- 高级 RAG 技术
- RAG 优化策略
- RAG 评估方法
- RAG 的优势与局限
- 主流框架与工具
- 参考资料
概述
RAG(Retrieval-Augmented Generation,检索增强生成) 是一种结合检索与生成能力的技术框架。其核心思想是让大语言模型(LLM)在生成回答时,能够动态检索外部知识库中的相关信息作为参考,从而提升回答的准确性、时效性和可靠性。RAG 架起了静态模型知识与动态外部数据之间的桥梁,是当前落地最广泛的 LLM 应用架构之一。
RAG 的起源与定义
- 提出时间:2020 年
- 提出机构:Facebook AI Research(Meta)
- 原始论文:《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》
RAG 的本质是将检索模块与生成模块串联,让 LLM 在生成每一条回复时,都能先从外部知识库中"查阅资料",再基于检索到的上下文进行回答。
为什么需要 RAG
| 问题 | 传统 LLM 的局限 | RAG 方案的优势 |
|---|---|---|
| 知识时效性 | 训练数据有截止日期,无法回答新信息 | 可接入最新知识库,实时获取新知识 |
| 幻觉问题 | 可能生成看似合理但实际错误的信息 | 基于检索到的真实文档,减少幻觉 |
| 专业知识 | 缺乏垂直领域知识,泛化能力有限 | 可注入专业领域知识,构建垂直专家 |
| 数据安全 | 需微调才能注入新知识,成本高且风险大 | 无需训练,通过检索安全可控地使用数据 |
RAG 让 LLM 从"知识封闭"走向"知识开放",无需重新训练即可持续吸收新知识。
RAG 的核心工作流程
RAG 的工作流程分为索引、检索、生成三个阶段:
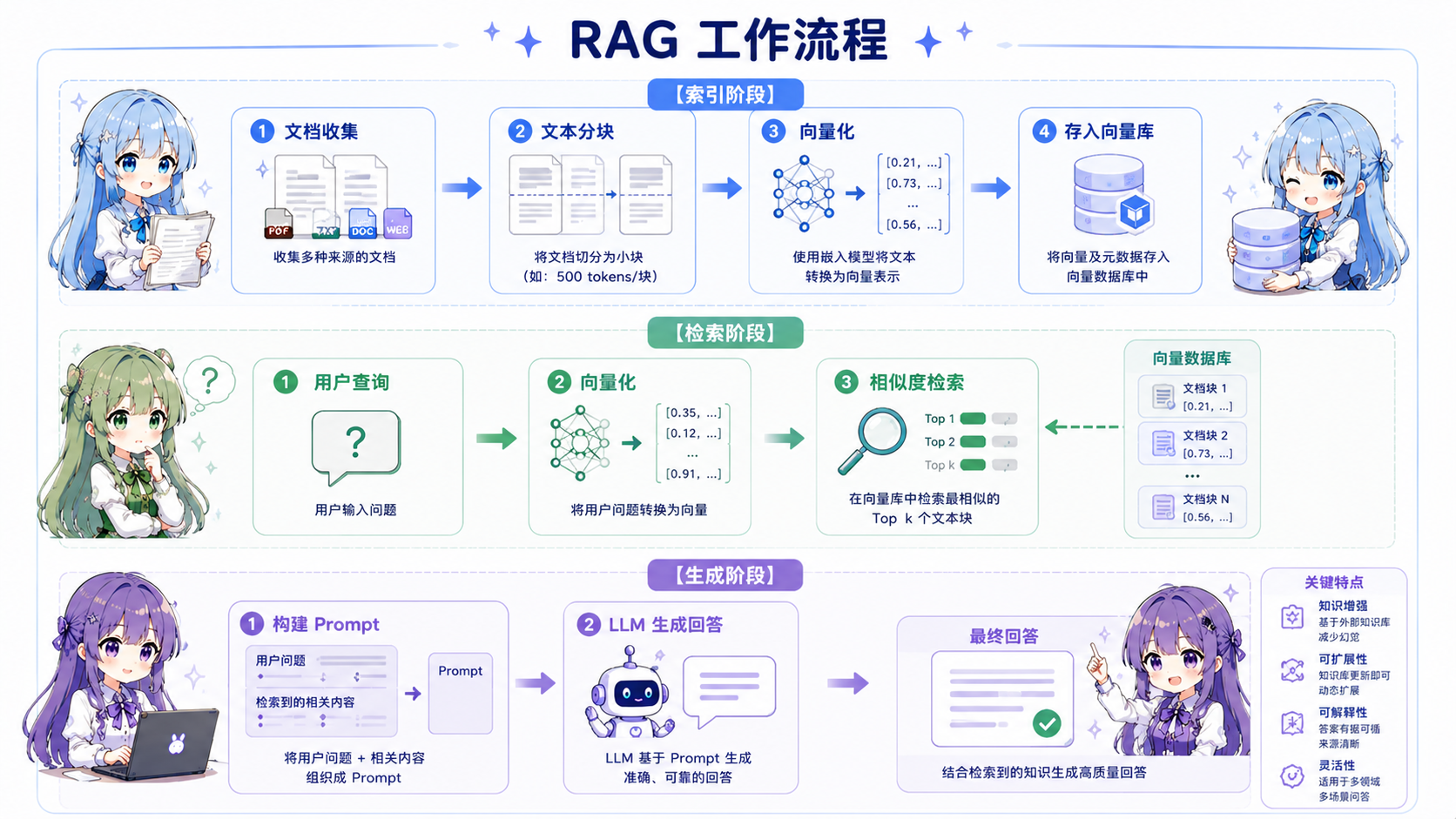
1. 索引阶段(Indexing)
- 文档收集:读取 PDF、Markdown、HTML 等各类文档
- 文本分块:将长文档切分为合适大小的 chunk(通常 512~2048 tokens)
- 向量化:使用 Embedding 模型将文本转换为高维向量
- 存入向量库:将向量及其元数据存储到向量数据库
2. 检索阶段(Retrieval)
- 查询向量化:将用户查询转换为向量表示
- 相似度计算:在向量空间中计算相似度(常用 cosine similarity)
- 返回结果:检索 top-k 最相关的文档片段
3. 生成阶段(Generation)
- 构建 Prompt:将检索到的上下文与用户查询组合
- LLM 生成:将 Prompt 提交给 LLM,生成最终回答
架构组件详解
核心组件一览
| 组件 | 职责 | 常见技术选型 |
|---|---|---|
| Embedding 模型 | 将文本转换为向量 | OpenAI Ada、Cohere、HuggingFace Sentence Transformers |
| 向量数据库 | 存储与检索向量 | Pinecone、Weaviate、ChromaDB、FAISS、Milvus、Qdrant |
| 检索器(Retriever) | 语义检索相关文档 | BM25、密集检索、Dense Passage Retrieval |
| 生成器(Generator) | 基于上下文生成回答 | GPT-4、Claude、Llama 2、Mistral |
| 数据处理管道 | 文档加载与分块 | LangChain、LlamaIndex |
Embedding 模型
- 将文本映射到稠密向量空间
- 语义相近的文本在向量空间中距离更近
- 决定检索质量的关键因素之一
向量数据库
- 专门用于存储和检索高维向量
- 支持亿级向量的快速相似度搜索
- 相比传统数据库,在语义检索场景下性能优势明显
文本分块策略
文本分块(Chunking)是 RAG 系统的关键预处理步骤,直接影响检索质量。
分块策略对比
| 策略 | 原理 | 优点 | 缺点 |
|---|---|---|---|
| 固定长度分块 | 按字符/ token 数量硬性切分 | 简单高效 | 可能切断语义单元 |
| 递归字符分块 | 按段落→句子→词语层级递归切分 | 保持语义完整性 | 需要调参 |
| 语义分块 | 基于句子边界或主题变化切分 | 语义连贯 | 计算成本较高 |
| 结构分块 | 按 Markdown/HTML 标题层级切分 | 保留文档结构 | 依赖文档格式 |
分块大小选择
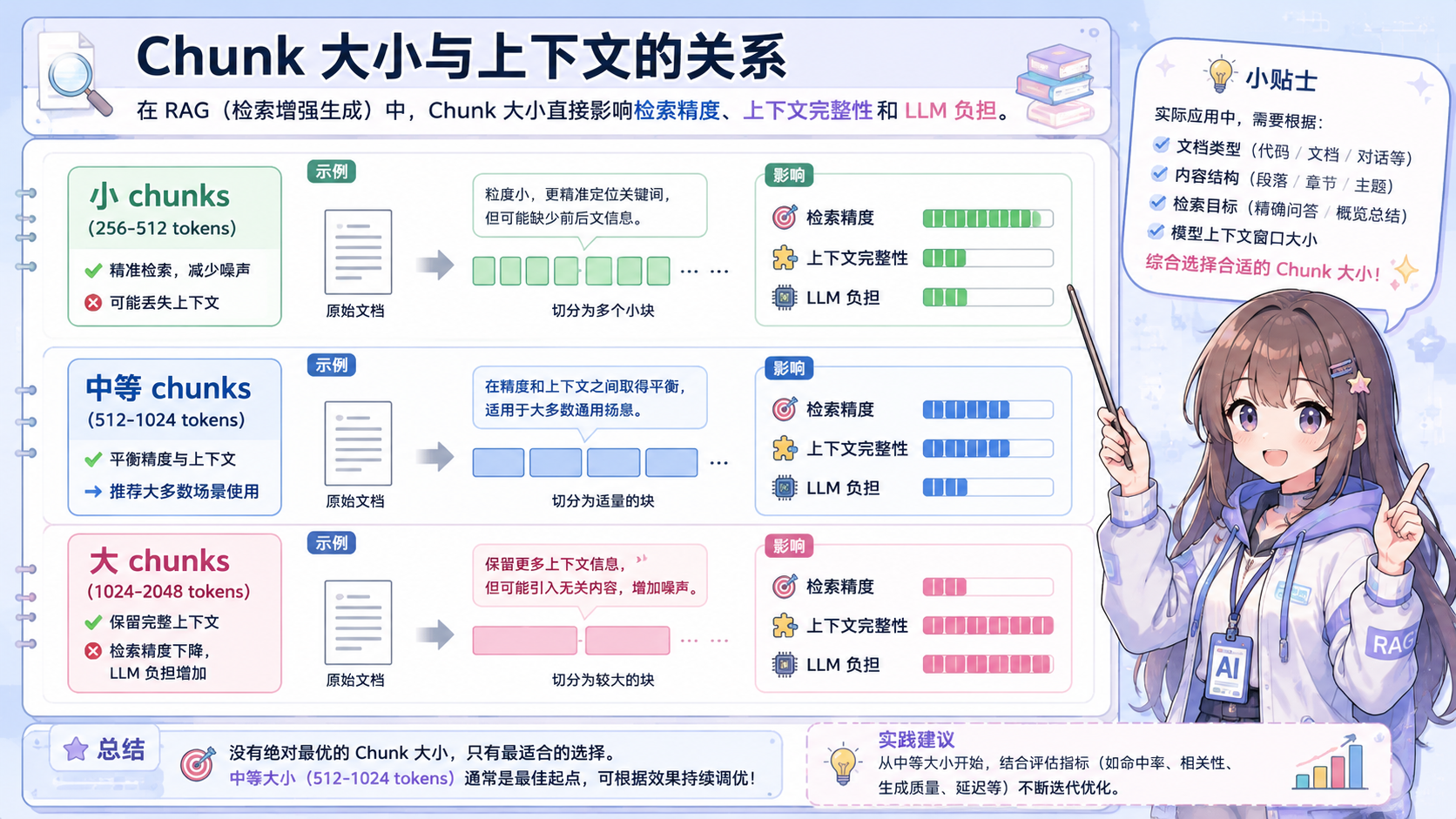
重叠分块(Overlap)
- 在相邻 chunks 之间添加重叠区域(通常 10-20%)
- 避免关键信息被切断,提高检索召回率
高级 RAG 技术
1. 混合检索(Hybrid Search)
核心思想:结合关键词检索与语义检索的优缺点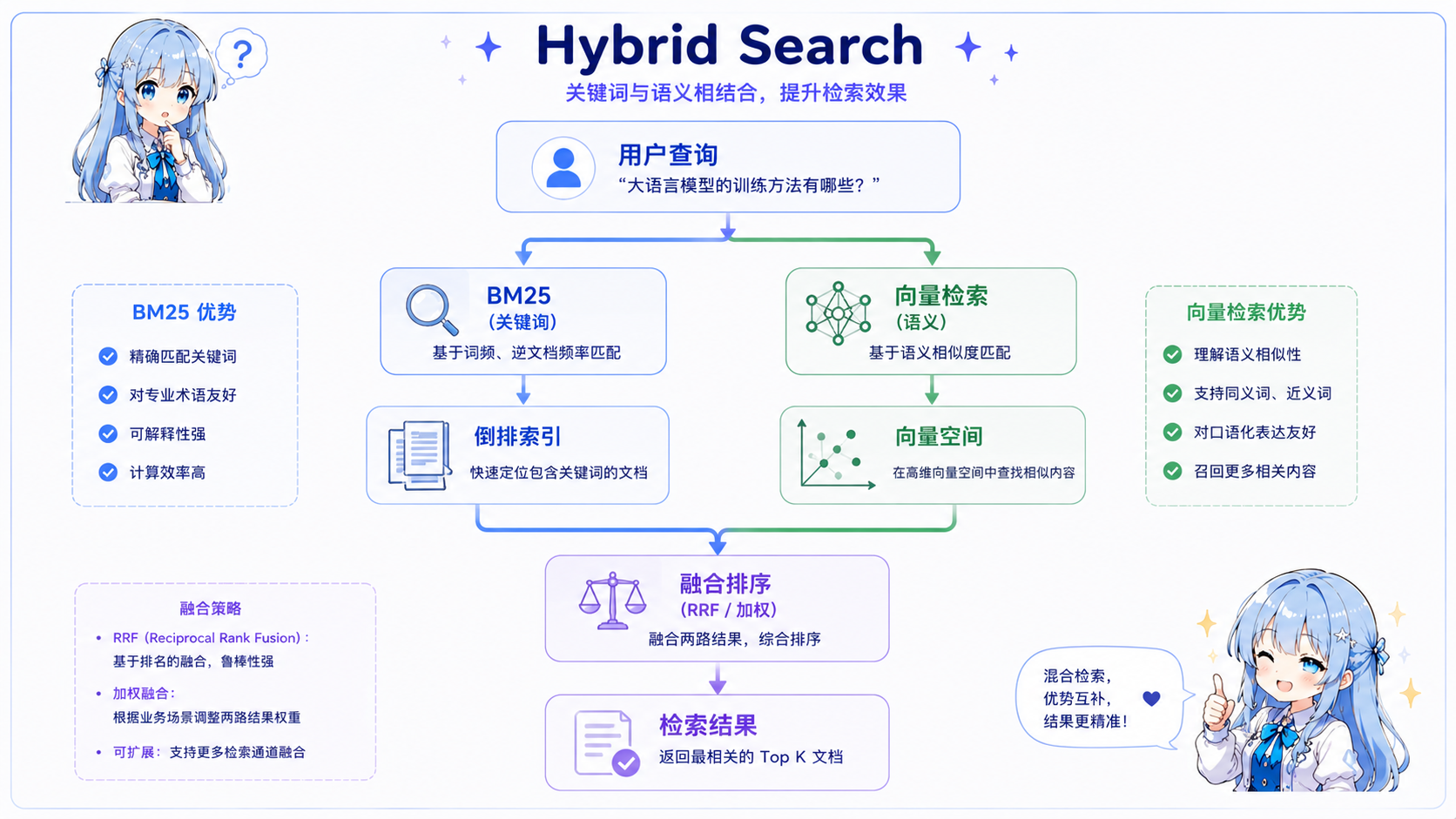
- BM25:擅长精确匹配、专有名词、专业术语
- 向量检索:擅长语义理解、同义词扩展
- 融合方式:倒数排名融合(RRF)、加权融合
2. 图 RAG(Graph RAG)
核心思想:利用知识图谱增强检索的实体关系理解
| 传统 RAG | Graph RAG |
|---|---|
| 孤立的文本片段 | 实体 + 关系 + 上下文 |
| 难以处理多跳问题 | 支持复杂关系推理 |
| 扁平化检索 | 层级化图遍历 |
适用场景:
- 需要理解实体关系的问答
- 多跳推理问题(如"A 的 CEO 是谁的朋友")
- 文档之间存在复杂引用关系
3. 多向量检索(Multi-vector RAG)
核心思想:使用多层次、多粒度的向量表示
| 层级 | 作用 |
|---|---|
| 文档级向量 | 整体主题匹配 |
| 段落级向量 | 细粒度检索 |
| 句子/短语级向量 | 精确匹配 |
优势:支持更灵活的检索策略,提高精度
4. 重排序(Reranking)
两阶段检索:
第一阶段:粗粒度检索
向量数据库 → 召回 top-100 相关文档
第二阶段:精排序
Cross-Encoder 模型 → 重排 top-10 最终结果
常用模型:
- BGE Reranker
- Cohere Rerank
- Cross-Encoder (交叉编码器)
RAG 优化策略
检索前优化(Pre-retrieval)
| 策略 | 说明 |
|---|---|
| 查询改写 | 使用 LLM 重写查询,使其更清晰、更适合检索 |
| 查询扩展 | 生成多个相关查询,提高召回率 |
| 意图识别 | 路由到不同的知识库或检索策略 |
| HyDE | 用 LLM 生成假设文档,提升检索效果 |
检索优化(Retrieval)
| 策略 | 说明 |
|---|---|
| 相似度调优 | 调整相似度阈值,控制召回/精确平衡 |
| 元数据过滤 | 基于时间、类型等元数据过滤 |
| 混合检索 | 结合 BM25 与向量检索 |
| 上下文压缩 | 去除检索结果中的冗余信息 |
检索后优化(Post-retrieval)
| 策略 | 说明 |
|---|---|
| 重排序 | 用更强大的模型重新排序 |
| 上下文压缩 | LLM 总结或压缩检索内容 |
| 信息融合 | 将多段检索结果整合 |
自我反思 RAG(Self-RAG)
- 核心思想:训练模型自主判断何时需要检索
- 机制:
- 模型判断是否需要检索
- 生成检索内容
- 判断检索结果是否相关
- 决定是否继续检索或生成答案
RAG 评估方法
评估维度
| 维度 | 指标 | 说明 |
|---|---|---|
| 检索质量 | Context Precision | 检索结果的相关性排序 |
| Context Recall | 检索召回率 | |
| Hit Rate | 命中率 | |
| MRR | 平均倒数排名 | |
| 生成质量 | Faithfulness | 回答是否忠实于检索内容 |
| Answer Relevancy | 回答与问题的相关性 | |
| Answer Correctness | 回答的准确性 |
评估框架
| 框架 | 特点 |
|---|---|
| RAGAS | 开源 RAG 评估框架,提供 Faithfulness、Answer Relevancy 等指标 |
| TruLens | 支持自定义反馈函数,可视化评估结果 |
| LangSmith | LLM 应用开发监控平台 |
RAGAS 核心指标
from ragas import evaluate
from ragas.metrics import Faithfulness, AnswerRelevancy, ContextPrecision
# 评估示例
results = evaluate(
dataset,
metrics=[
Faithfulness(), # 回答忠实度
AnswerRelevancy(), # 回答相关性
ContextPrecision(), # 检索精确度
]
)
基准测试
| 基准 | 用途 |
|---|---|
| RAGAS Benchmark | RAGAS 官方评估集 |
| RGB | Retrieval Grounded Benchmark |
| CRAG | Conversational RAG 基准 |
| HaluEval | 幻觉检测评估 |
评估最佳实践
- 人工评估:对关键案例进行人工标注
- A/B 测试:对比不同 RAG 方案的效果
- 持续监控:在生产环境中持续收集反馈
RAG 的优势与局限
优势
- 即插即用:无需重新训练 LLM,即可注入新知识
- 可解释性:回答可追溯到原始文档
- 成本可控:相比微调,维护成本更低
- 实时更新:知识库可随时更新,保持时效性
局限
- 检索质量依赖:检索不到相关内容则生成效果差
- 上下文长度限制:无法一次性利用所有文档
- 延迟较高:检索+生成需要额外时间
- 重复信息干扰:检索到噪声信息可能影响生成质量
主流框架与工具
开发框架
| 框架 | 特点 |
|---|---|
| LangChain | 功能完善,生态丰富,支持多种 LLM 和向量库 |
| LlamaIndex | 专注数据索引,结构化数据处理能力强 |
| Haystack | 端到端 RAG 框架,适合大规模部署 |
| Dify | 低代码平台,可视化构建 RAG 应用 |
向量数据库选型
| 数据库 | 适用场景 |
|---|---|
| Pinecone | 云服务托管,开箱即用 |
| FAISS | Facebook 开源,本地部署首选 |
| Chroma | 轻量级,易于上手 |
| Milvus | 开源,云原生,支持分布式 |
| Weaviate | 兼具向量检索和知识图谱能力 |
参考资料
-
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
https://arxiv.org/abs/2005.11401 -
LangChain RAG Tutorial
https://python.langchain.com/docs/use_cases/querying/question_answering -
LlamaIndex Documentation
https://docs.llamaindex.ai -
Pinecone: What is RAG?
https://www.pinecone.io/learn/retrieval-augmented-generation -
详解 RAG 架构原理与应用
https://www.restack.io/docs/rag -
Advanced RAG Techniques: Choosing the Right Approach
https://www.pinecone.io/blog/advanced-rag-techniques -
RAGAS: Evaluation Framework for RAG
https://docs.ragas.io -
Hybrid Search Explained
https://www.elastic.co/guide/en/elasticsearch/reference/current/hybrid-search.html

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 16
16 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)