【领域驱动设计 打通DDD的最小闭环】一 DDD的开发过程 & 模型的建立-事件风暴
现在开始阶段一的学习,本阶段的目标是打通一个“需求 - 模型 - 代码”的最小闭环,让大家对 DDD的设计及落地过程有一个初步的感觉。
DDD的基本开发过程
领域驱动设计里“领域”这个词,指的是软件要解决的那些业务问题,所以也可以叫业务领域,英文叫 Business Domain。所以DDD的开发过程就是围绕业务领域进行的,是一种将现实世界中的业务运转过程映射到虚拟世界的方法。
那我们怎么用一套系统化的方法,一步一步地把现实世界落实到代码呢?主要是通过如下的开发过程:
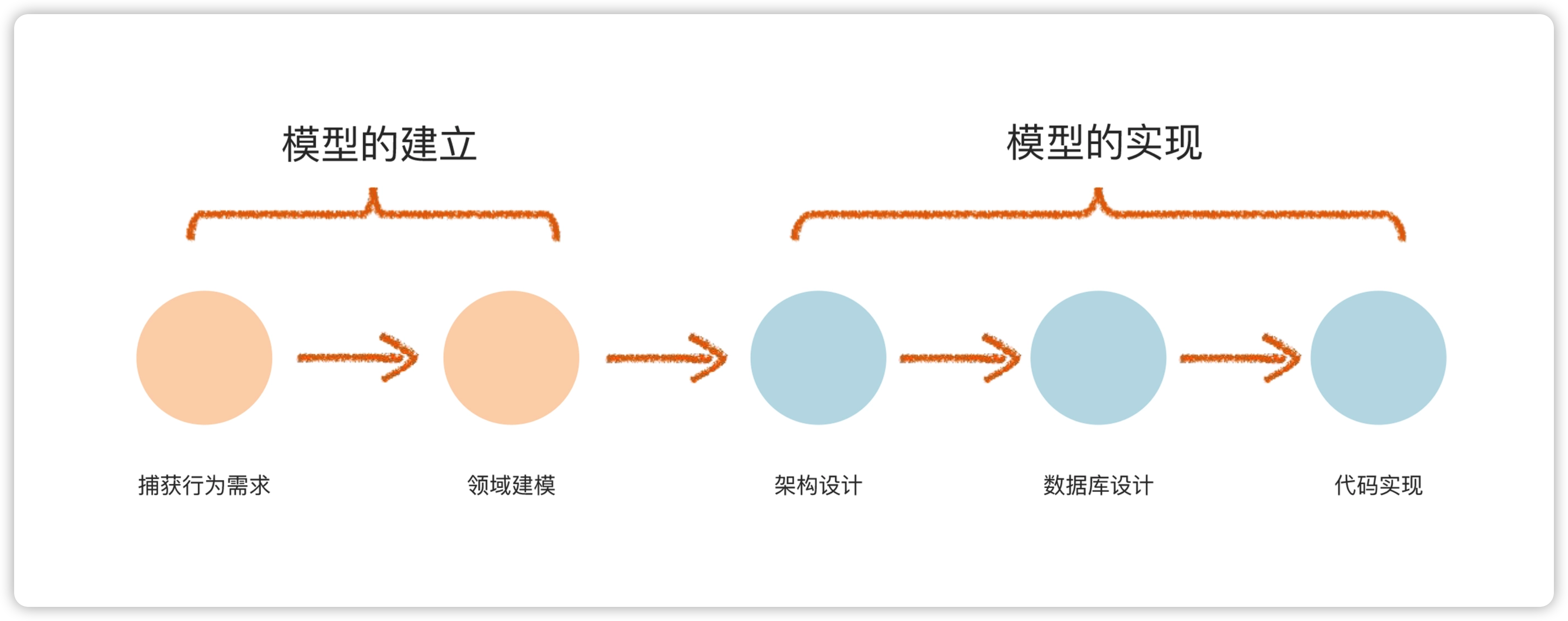
- 首先要获取现实世界的行为需求,我们要识别需求中有哪些流程、哪些功能,每个功能由什么人操作,会产生什么结果。常用的方法有很多,比如事件风暴、用户故事等。
- 接下来,就可以进行领域建模了。也就是通过建立领域模型,把需求里的主要业务知识描述清楚。
- 之后,基于领域模型,可以做架构设计。
- 最后,根据领域模型进行数据库设计、代码实现。
这样,就形成了一个基于 DDD 的开发闭环,包括获取行为需求 - 领域建模 - 架构设计 - 数据库设计 - 代码实现。其实,在实际操作中,这些步骤不是线性的,而是反复迭代、互相穿插的。
DDD 是以领域模型为核心的。所以,我们可以把上面说的步骤分成模型的建立和模型的实现两部分。
- 模型的建立阶段,使用的都是业务术语,是通过领域专家(十分了解业务知识本质的人)和开发人员的协作共同完成的,他们对领域模型的划分达成了共识。
- 而模型的实现,则是业务人员不需要理解也不关注的,会包含技术实现方面的内容。
捕获行为需求(深入了解现实世界)
下面就要开始模型设计的第一步了,获取现实世界的行为需求。
捕获行为需求的适用场景
在介绍具体的捕获行为方法之前,不知道大家有没有这样一个疑问,了解现实世界的行为需求是DDD的必须环节吗?什么样的情况需要了解现实世界的行为呢?我觉得有两种情况推荐使用:
- 对于需求不清晰、或者理解不一致的情况,可以通过协作的方式理清业务、达成一致;
- 遗留系统改造的情况:如果这个系统的知识已经流失得很严重,那就可以使用事件风暴。但如果大家对这个系统的业务知识很清楚,只是要进行架构改造,那么事件风暴的意义就不大了。
对于系统的业务过程非常清晰、领域建模已经达成统一的团队来说,可以直接进行模型的实现环节。
事件风暴概览
捕获行为需求的方法有好几种,但Eric Evans 在《领域驱动设计》这本书里,并没有规定捕获行为需求的具体方法。直到 2013 年,一位叫 Alberto 的 DDD 专家提出了“事件风暴”(Event Storming),也就是领域事件的头脑风暴。
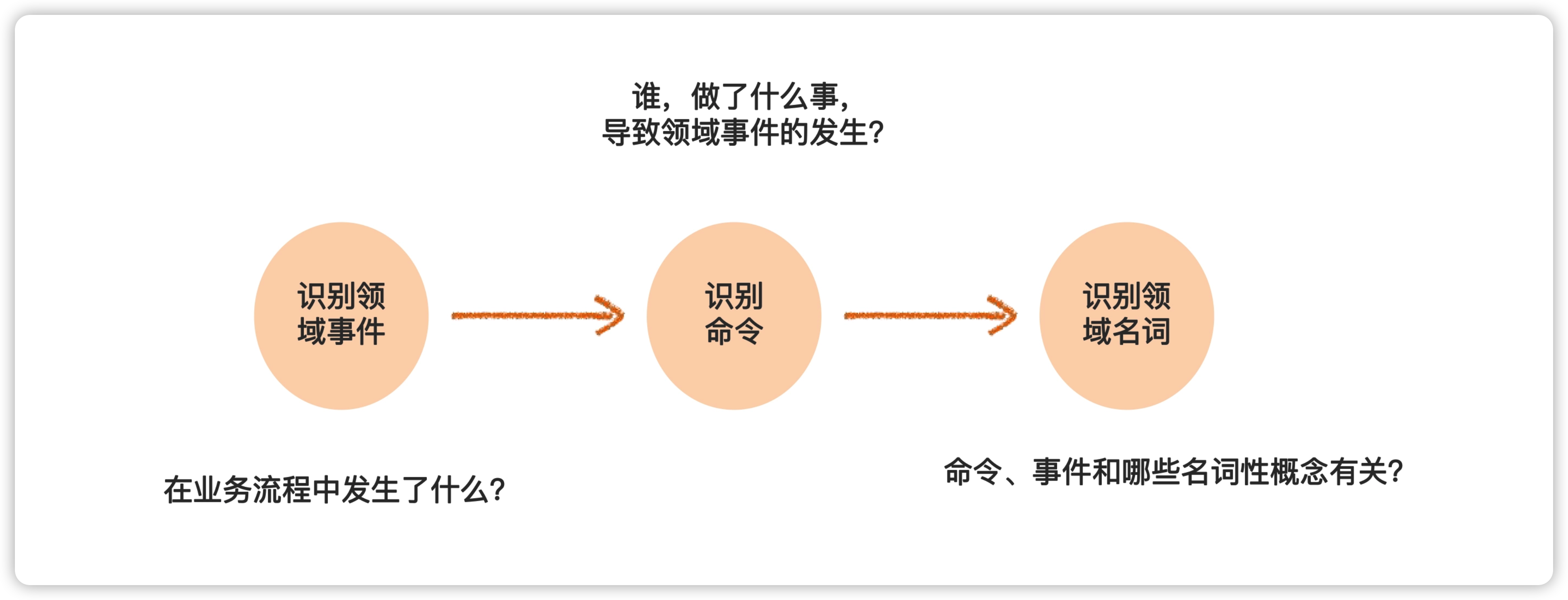
事件风暴是一种通过协作的方式捕获行为需求的方法,在这个过程里,业务人员和技术人员一起消化领域知识、形成统一语言、并为领域建模奠定基础,充分体现了 DDD 中沟通协作、统一语言等要点,所以逐渐开始流行起来。事件风暴的主要过程为:
- 识别领域事件:找到业务流程中发生了哪些事情;
- 识别命令:进一步说明是什么角色,做了什么操作,导致上述事情的发生;
- 识别领域名词:从领域事件和命令中找到名词性概念,为进一步的领域建模打下基础。
事件风暴的前提
在正式开始事件风暴之前,我们还要先做一些准备工作。
- 首先是人员准备。事件风暴要求业务和技术人员共同协作。
- 其次是场地准备。我们需要找一个比较大的会议室,或者至少有一面足够长的墙。
- 最后是器材准备。我们需要几套彩色的便利贴,到时候我们会把事件风暴的主要内容写在上面。
事件风暴第一步:识别领域事件
领域事件是在业务过程中,业务人员关注的那些已经发生的事情;它是业务流程中每个步骤引发的结果,用的是业务术语。比方说,对于电子商务系统,订单已提交、商品已签收等等,都是领域事件。事件风暴的作者认为,从结果入手来梳理需求,比从操作入手,更容易把业务想清楚。
识别领域事件的过程可以分成两步:
- 第一步是参加的人,各自写出领域事件;
- 第二步是一起讨论,统一理解。
这个过程是反复迭代的。另外,在识别领域事件的过程中,要注意一些识别的要点:
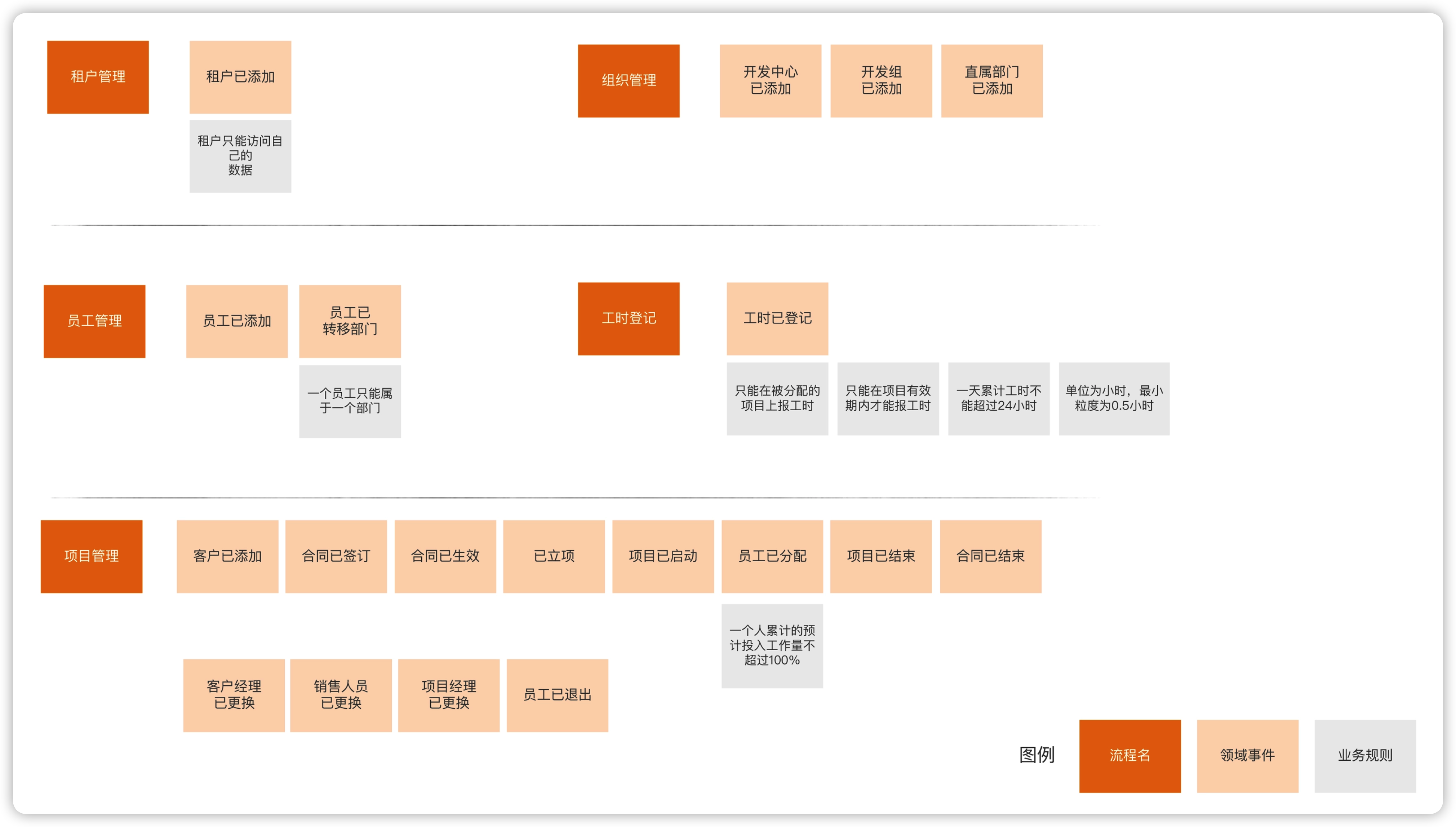
- 优先使用约定俗成的业务术语。虽然我们为领域事件命名的时候,常常用‘什么什么已什么什么’的形式,不过如果业务上已经有约定俗成的术语,我们就直接使用术语,这样更容易和业务沟通。比如 “项目已创建” 和 “已立项” 表示从同一个事情,但业务更习惯使用 “已立项”,所以使用 “已立项” 表示一个领域事件。
- 领域事件命名采用 完成时 + 被动语态。比如说,订单已提交,这个“已”字就是完成时,代表已经发生的事情。比如 “签订合同” 和 “合同已签订”,“签订合同”是个动作,不是事件,所以采用 “合同已签订” 作为领域事件。
- 业务规则可以随领域事件一起列出,但非必须。比如对于 “员工已分配”这个领域事件可以,存在 “一个人累计的预计投入工作量不超过100%” 这个业务规则。
一定要注意,“协作”才是事件风暴的精髓,而具体结果怎样呈现,反而是第二位的。
事件风暴第二步:识别命令
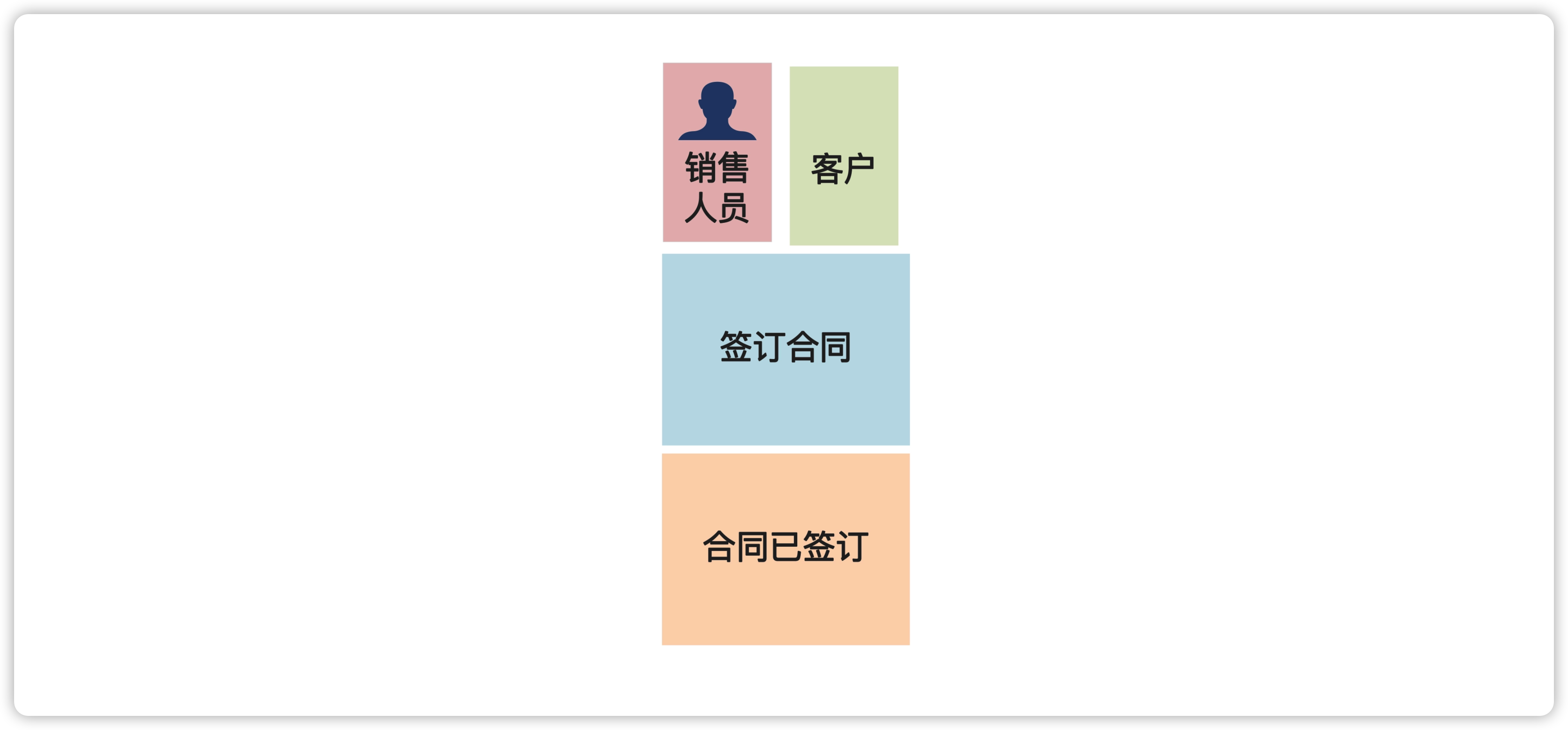
所谓命令(command),就是引发领域事件的操作,我们可以通过分析领域事件得到。除了识别出命令本身以外,我们还要识别出谁执行的命令,以及为了执行命令我们要查询出什么数据。
比如说,对于“合同已签订”这个事件,对应的命令就是“签订合同”,是由“销售人员”操作的,操作构成需要查询客户信息。
按照上述方法,得到所有领域事件的信息。
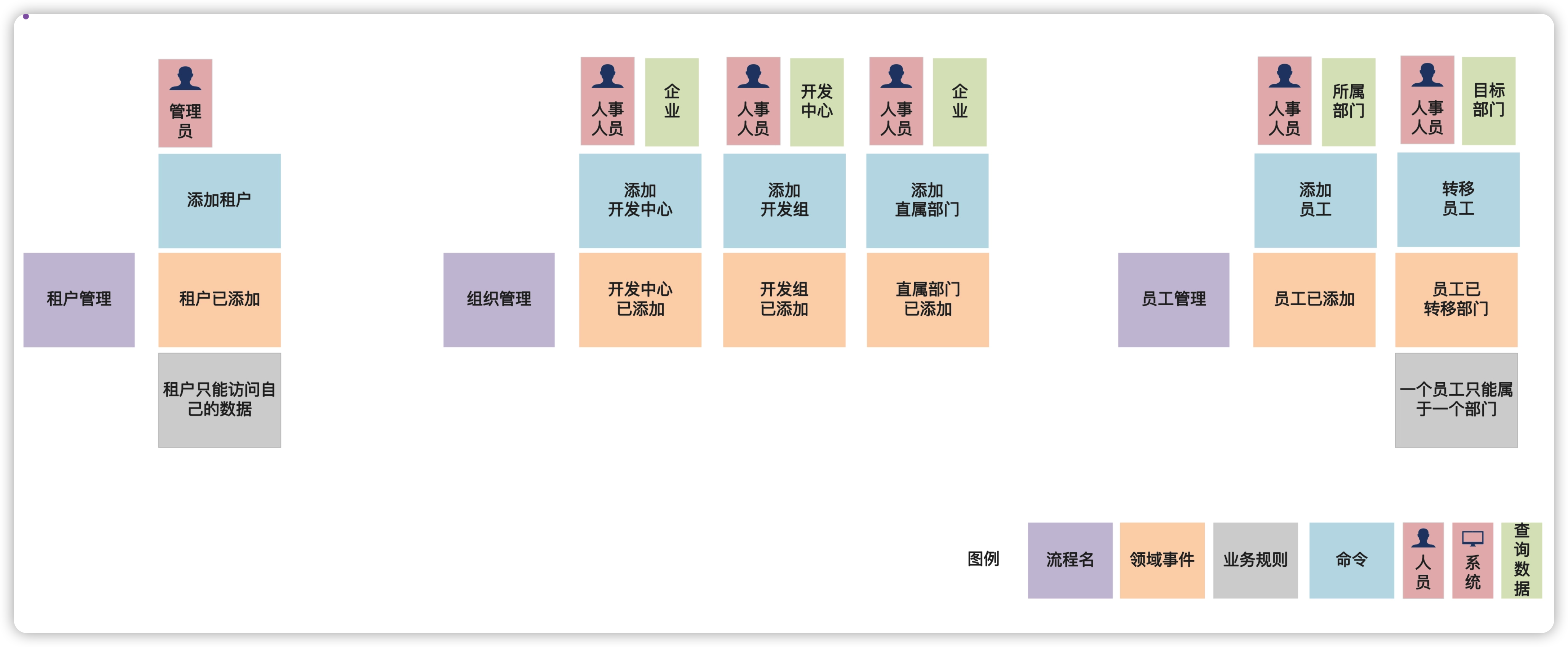
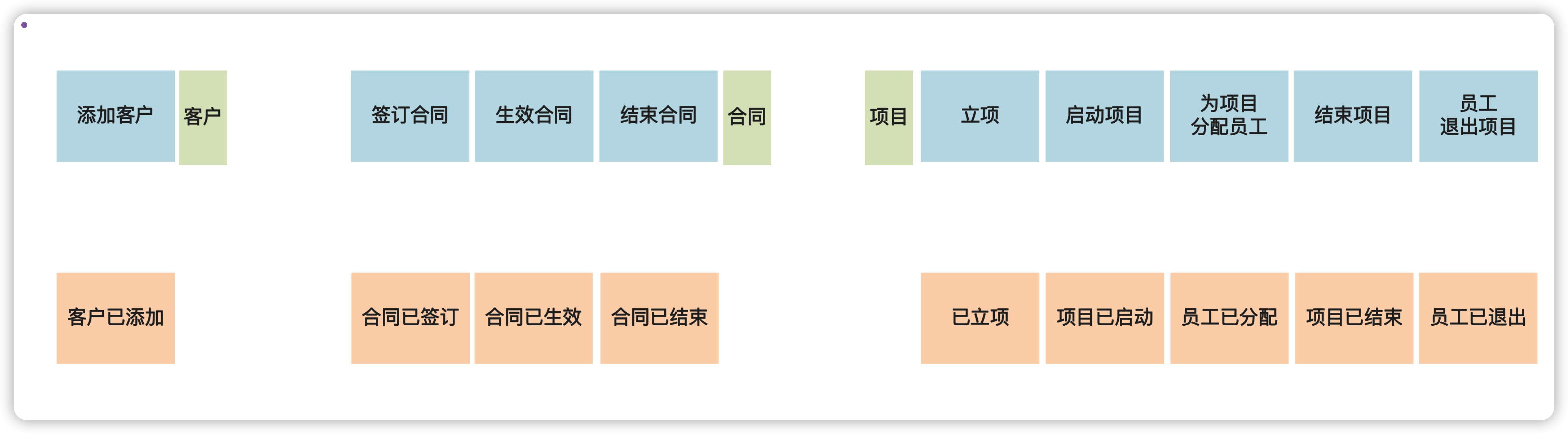
事件风暴第三步:识别领域名词
领域名词,是从命令、领域事件、执行者、查询数据里找到的名词性概念。例如,对于签订合同这个命令而言,受到影响的名词性概念是“合同”;类似地,对于合同已签订这个领域事件,是由于“合同”这个名词性概念的状态变化所导致的。
识别领域名词的可以分成两步:
- 把围绕同一个名词的命令、领域事件、执行者、查询数据摆在一起。
- 把领域名词写在大一点的黄色便利贴上,贴在每堆便利贴的中间
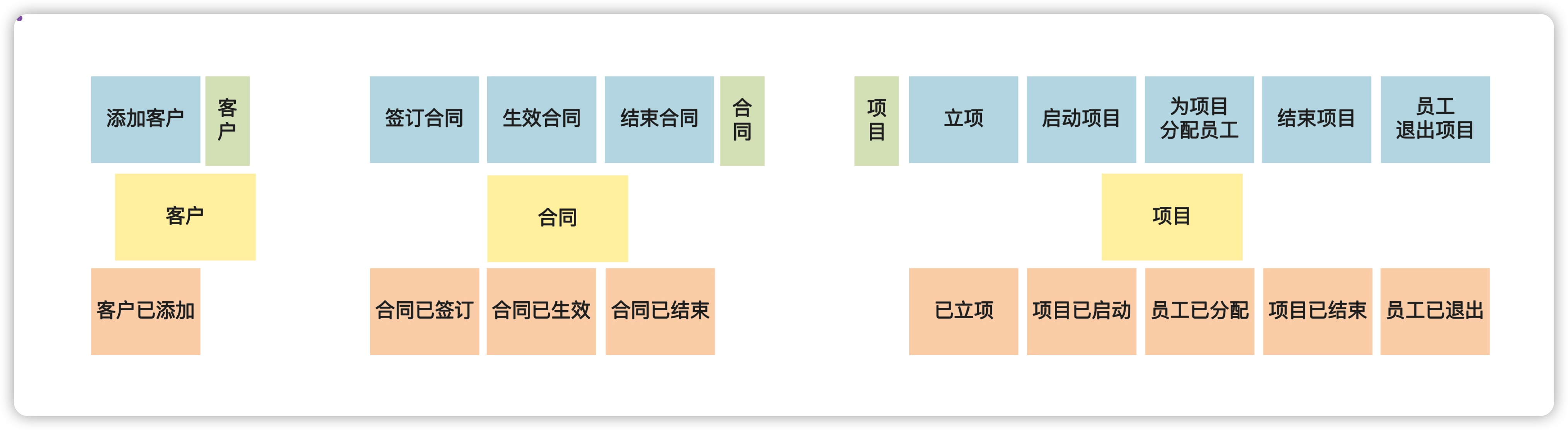
所有领域名词都识别出来后:
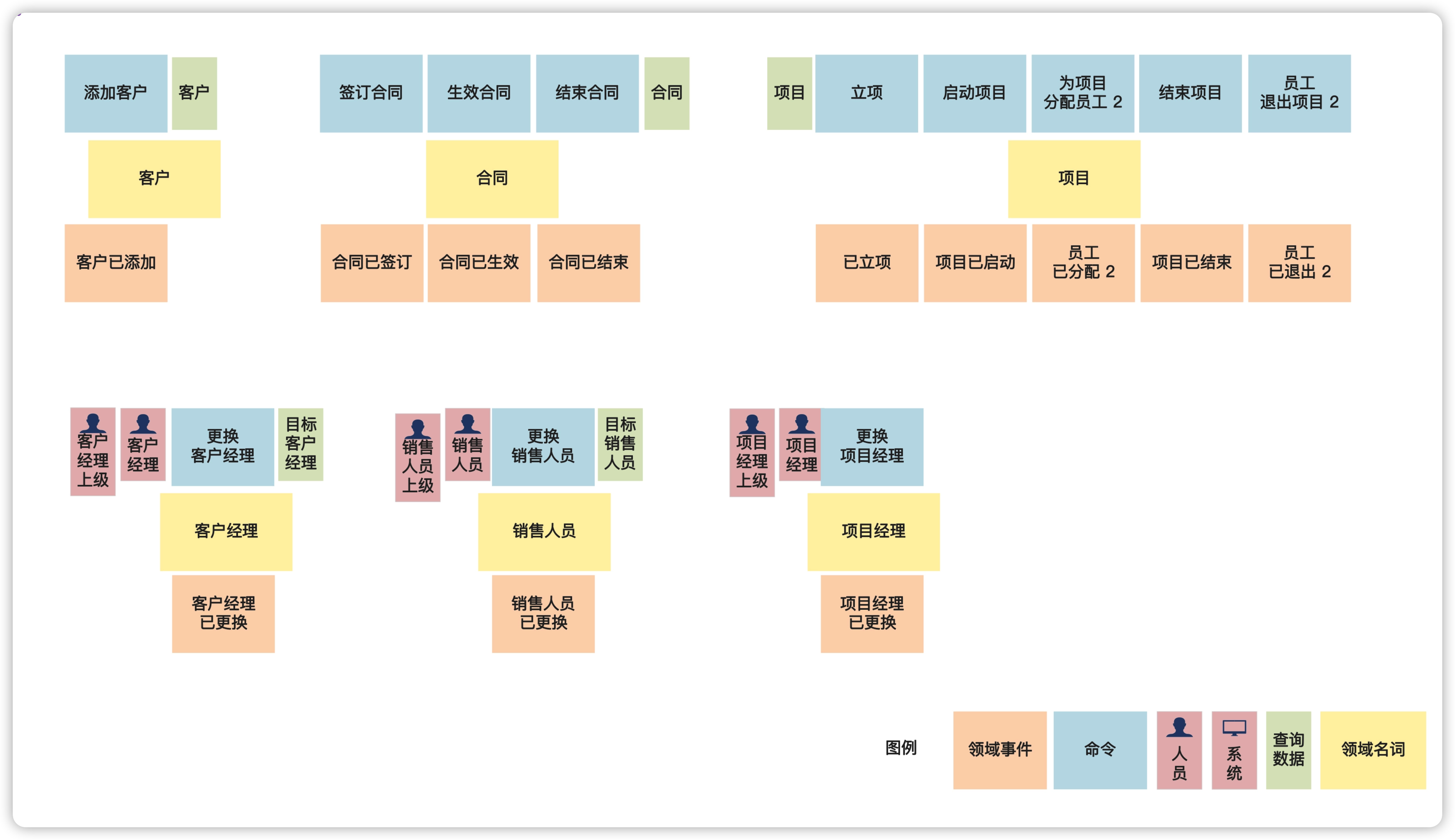
其实识别领域名词的最终目的是要找到领域模型中的对象。那么为什么我们不把这一步直接叫做识别领域对象呢?
这是因为,在这一步里识别出的名词,虽然很可能就是领域对象,但也未必。一个名词有可能只是一个对象充当的角色,或者对象的属性,还有些名词需要经过合并或拆解后,才是合理的领域对象,而这些需要等到领域建模时才能真正搞清楚。
事件风暴的一些问题
Q1:查询算不算领域事件?
查询功能不算领域事件。领域事件应该是对某样事物产生了影响,并被记录的事情。一般是某个事物的创建、修改和删除。而像“客户信息已查询”这些就不算领域事件,因为还没有对事物产生实际影响。
Q2:在事件风暴里是否要列出所有的领域事件和命令,比如修改和删除?
列出所有领域事件和命令并没有原则上的错误,可以根据自身实践情况决定。如果只有“新增”的领域事件足以用于表达和交流领域知识的话,那也是可以的。
Q3:各个领域事件需要体现严格的时间顺序吗?
只需要按照大致的顺序,贴出领域事件就可以。因为在事件风暴中,我们最终的目的是找出领域名称,领域名词的确定不依赖严格的时间顺序。
Q4:领域事件的颗粒度应该有多大?
原则上宜粗不宜细。可以先采用比较大的颗粒度,后面进行领域建模的时候再细分。
其他捕获行为方法
除了上面的事件风暴,才有其他的捕获行为的方法,比如 用户故事,具体如何实施就不详细介绍了,可以自行查阅相关资料。这里介绍对比一下两者的异同:
- 用户故事可以把系统的功能串联在一起,更加场景化一些;产物更详细,耗时更长。
- 事件风暴感觉类似于头脑风暴的过程,重心在快速了解核心业务,识别核心领域名词,粒度更粗,但广度更广,耗时相对短很多。
写在最后
再次重申,DDD是一种方法论,它的实施过程是前人经验的总结,是一个相对标准高效的开发过程,但并不是一成不变的,当你已经积累了一些经验,有了一些体感后,是可以根据自身情况进行适当调整的。
比如 捕获行为需求 这个环节就不是必须的。当你的团队对系统的业务过程非常清晰、领域建模已经达成统一的时候,就不需要执行这个环节。
同样对于获取行为需求的各种方法,也可以结合使用。比如先采用事件风暴发散,找到足够多的领域事件,然后使用用户故事将领域事件串联在一起。甚至在进行事件风暴的时候,可以不去识别业务规则,可以不识别命令和执行者,目的就是快速的识别领域事件。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)