别再死磕外链了:用Python+搜索API实现Google SEO自动化内容生产
做Google SEO的人都有一个共同感受:越来越难了。
以前发发外链、堆堆锚文本就能上去,现在不行了。Google的算法从"匹配关键词"进化到了"匹配搜索意图"。外链权重从60%降到30%,内容质量成了核心排名因素。
但问题是:手动写内容太慢,关键词又太多,怎么批量覆盖?
这篇帖子分享我目前在用的四个方法,全部基于Python + 搜索API实现半自动化/全自动内容生产。代码可直接复用。
方法一:写之前先搜,做内容去重
很多人写SEO文章的流程是:找关键词 → 写文章 → 发布 → 等排名。
错。
正确的流程是:找关键词 → 搜这个关键词 → 看前10名在写什么 → 找到他们没覆盖的角度 → 写差异化内容 → 发布。
Google现在的排名逻辑是:它会看当前搜索结果的前10名都在写什么,然后判断"用户对这个话题还缺什么信息"。如果你的内容恰好补上了这个缺口,你就能上去。
不需要外链,不需要锚文本,只需要你的内容比现有结果更好、更新、更完整。
代码实现
import requests
API_KEY = "your_serpbase_api_key"
URL = "https://api.serpbase.dev/google/search"
def search_google(query, gl="us", hl="en"):
"""搜索Google,返回前10条结果"""
payload = {"q": query, "gl": gl, "hl": hl, "page": 1}
headers = {"Content-Type": "application/json", "X-API-Key": API_KEY}
resp = requests.post(URL, json=payload, headers=headers, timeout=15)
data = resp.json()
if data.get("status") != 0:
print(f"Error: {data.get('status')}")
return []
return data.get("organic", [])
def analyze_top10(query):
"""分析前10名的内容,找缺口"""
results = search_google(query)
print(f"\n关键词:{query}")
print(f"前10名标题:\n")
titles = []
for r in results[:10]:
title = r.get("title", "")
snippet = r.get("snippet", "")
titles.append({"title": title, "snippet": snippet})
print(f"[{r.get('rank')}] {title}")
print(f" 摘要:{snippet[:80]}...")
print()
return titles
# 用法
titles = analyze_top10("python web framework comparison")
拿到前10名的标题和摘要后,手动分析一下:哪些角度没人写?哪些问题没人回答? 那个"缺口"就是你的切入点。
方法二:蹭热点,用实时搜索数据找选题
你说"不知道写什么",这是大部分SEO人的常态。
解法很简单:不知道写什么,就看别人在写什么。
具体操作:
- 每天花10分钟搜你的核心关键词,看有没有新出现的结果
- 搜Google News,看你的行业有没有新闻
- 看Reddit、Twitter上你的目标用户在讨论什么
如果某个话题突然多了很多新内容,说明这个话题正在"热"。你也写一篇,但角度要比别人深。
代码实现
def search_news(query, gl="us", hl="en"):
"""搜索Google News,找热点话题"""
payload = {"q": query, "gl": gl, "hl": hl, "page": 1}
headers = {"Content-Type": "application/json", "X-API-Key": API_KEY}
# SerpBase的news端点
resp = requests.post(
"https://api.serpbase.dev/google/news",
json=payload, headers=headers, timeout=15
)
data = resp.json()
if data.get("status") != 0:
return []
return data.get("news", [])
def find_hot_topics(keywords):
"""批量搜索关键词,找热点话题"""
hot_topics = []
for kw in keywords:
news = search_news(kw)
for item in news[:3]:
hot_topics.append({
"keyword": kw,
"title": item.get("title"),
"source": item.get("source"),
"time": item.get("time"),
"link": item.get("link"),
})
return hot_topics
# 用法:批量搜索你关注的关键词
keywords = ["python framework", "AI tools", "SEO update"]
hot = find_hot_topics(keywords)
for t in hot:
print(f"[{t['keyword']}] {t['title']}")
print(f" 来源:{t['source']} | 时间:{t['time']}")
print()
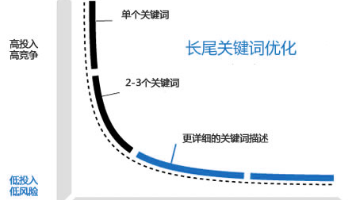
方法三:程序化覆盖长尾词
你说"有很多关键词",这个"很多"如果是几百上千个,靠一篇一篇手写不现实。
这时候就需要程序化内容(Programmatic SEO)。
原理很简单:有些关键词的搜索意图是结构化的。比如"best [城市] [服务]“、”[产品] vs [产品]“、”[工具] pricing"——这些词的搜索结果格式是固定的,你可以用模板批量生成。
代码实现
import csv
from datetime import datetime
def generate_content_batch(keywords_file, template):
"""批量生成内容骨架"""
with open(keywords_file, "r", encoding="utf-8") as f:
reader = csv.DictReader(f)
keywords = list(reader)
articles = []
for kw in keywords:
# 搜索该关键词的前10名
top10 = search_google(kw["keyword"])
top3_titles = [r.get("title", "") for r in top3[:3]] if (top3 := top10[:3]) else []
# 生成文章骨架
article = {
"keyword": kw["keyword"],
"title": template["title_format"].format(keyword=kw["keyword"]),
"sections": template["sections"],
"competitor_titles": top3_titles,
"generated_at": datetime.now().isoformat(),
}
articles.append(article)
return articles
# 模板示例
template = {
"title_format": "Best {keyword} in 2026: Complete Guide",
"sections": [
"What is {keyword}?",
"Top 5 {keyword} compared",
"How to choose the right {keyword}",
"Common mistakes to avoid",
"FAQ",
],
}
# 用法
# articles = generate_content_batch("keywords.csv", template)
关键点:程序化内容不等于垃圾内容。 每篇必须有独特的、对用户有价值的信息。Google现在对"AI批量生成的低质内容"打击很狠,但对"结构化、有用、覆盖长尾需求"的内容依然友好。
方法四:全自动工作流(n8n + 搜索API)
前三个方法可以手动执行,但如果你想让内容生产在你睡觉的时候也能跑,就需要自动化。
我目前用的是 n8n + SerpBase 的组合:
- 定时触发:每天早上8点自动执行
- 搜索热点:调用SerpBase搜索Google News
- AI分析:让LLM分析热点,生成文章大纲
- AI写作:基于大纲生成完整文章
- 人工审核:推送到飞书/Slack,审核后发布
n8n工作流节点
Schedule Trigger (每天8点)
↓
HTTP Request (调SerpBase搜索热点)
↓
Code (提取标题和摘要)
↓
HTTP Request (调LLM生成文章大纲)
↓
HTTP Request (调LLM生成完整文章)
↓
Slack/飞书 (推送到审核频道)
核心代码节点
// n8n Code节点:提取搜索结果
const items = $input.all();
const results = items[0].json.organic || [];
const signals = results.slice(0, 10).map(r => ({
title: r.title,
snippet: r.snippet,
link: r.link,
rank: r.rank,
}));
return signals.map(s => ({json: s}));
SerpBase请求配置
{
"method": "POST",
"url": "https://api.serpbase.dev/google/search",
"headers": {
"Content-Type": "application/json",
"X-API-Key": "{{$env.SERPBASE_API_KEY}}"
},
"body": {
"q": "{{$json.keyword}}",
"gl": "us",
"hl": "en",
"page": 1
}
}
注意:
- SerpBase的搜索接口是POST,不是GET
- 认证用
X-API-Key头部 - 返回JSON里
status为0才是成功 - 有机结果字段名是
rank和link,不是position和url
成本估算
| 方法 | 每月成本 | 适合场景 |
|---|---|---|
| 方法一:内容去重 | $1-3 | 手动写高质量文章 |
| 方法二:蹭热点 | $2-5 | 每天找选题 |
| 方法三:程序化 | $5-15 | 批量覆盖长尾词 |
| 方法四:全自动 | $10-30 | 全自动内容生产 |
搜索API成本:$0.30/1000次查询。每月跑10万次也就$30。
总结
外链权重从60%降到30%了。SEO现在是内容产品,不是技术活。
四个方法的核心逻辑是一样的:用搜索数据驱动内容决策,用自动化提升效率。
- 方法一:搜了再写,做差异化
- 方法二:搜热点,蹭流量
- 方法三:搜长尾词,批量覆盖
- 方法四:全自动化,睡觉也在跑
工具是杠杆,不是答案。核心还是你对用户需求的理解。但有了这些自动化流程,你可以把更多时间花在"理解需求"上,而不是"手动搜索"上。
有其他问题欢迎评论区交流。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)