扩散模型 2
一、加速扩散模型采样:DDIM 与渐进蒸馏
问题:DDPM 太慢
DDPM 需要 T=1000 步去噪,生成50k张32×32图像需要20小时,而GAN只需不到1分钟。
方法一:跳步采样(Nichol & Dhariwal)
最简单的加速方式:不每一步都走,而是每隔 ⌊T/S⌋步跳一次,从 1000 步压缩到 S 步。
但治标不治本,跳步会损失精度,因为 DDPM 本质上是马尔可夫链,每步依赖上一步。
方法二:DDIM——重新推导采样公式
DDIM 的核心思路是:不改变训练,只改变采样方式。关键在于把采样公式重新参数化,引入一个控制随机性的超参数
1、把 写成
和噪声 ε 的形式,这是整个 DDIM 的基础。
![]()
表示当前噪声图其实是 原图+某个总噪声。其中:原图保留多少,
:噪声占多少
DDPM中,模型学习![]() ,即当前
,即当前里的总噪声是什么,有了
和
,就可以反推
:
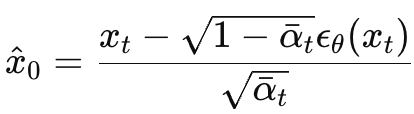
同理,![]() ,
,
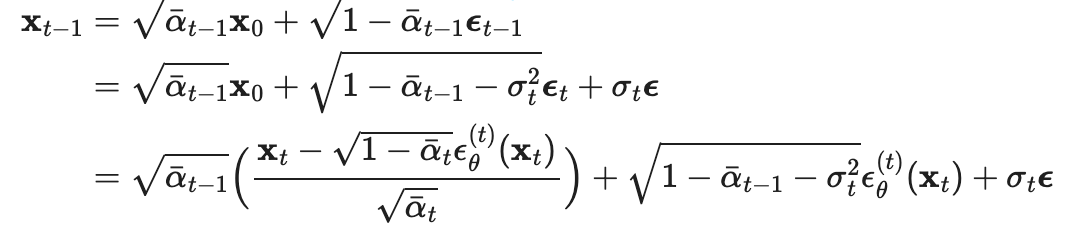
作者把拆成
![]()
第一个:
是模型预测出的“方向”。表示:当前图里主要的噪声结构,是确定性的。
第二个:
是新加入的随机噪声。
即DDPM 里那种:每一步随机抖一下
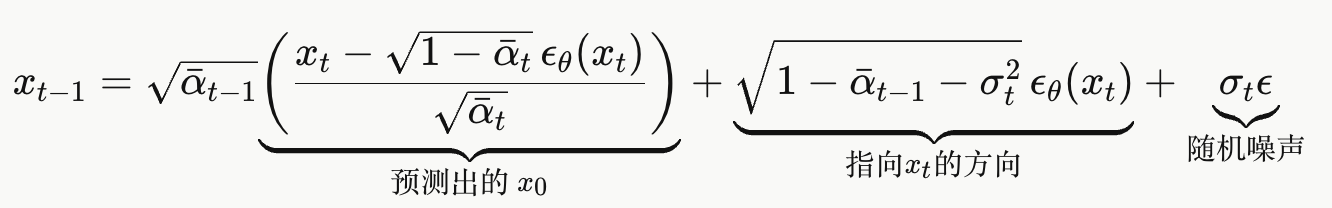
公式分三部分:
- 第一项:用当前
和预测噪声反推出
的估计,再按
缩放
目标是构造出"t−1 时刻应该有多少原始信号",因为正向过程中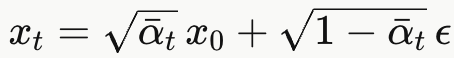
t 时刻,原始信号
倍混入
倍。
- 第二项:从估计的
- 第三项:加入随机噪声(可控)
η 参数:控制随机性
令,通过调整 η 来控制采样的随机程度:
| η | 效果 |
|---|---|
| η = 1 | 退化为原始 DDPM,完全随机 |
| 0 < η < 1 | 介于两者之间 |
| η = 0 | 完全确定性,这就是 DDIM |
当 η = 0 时,采样过程变成一个确定性的常微分方程(ODE),给定同一个初始噪声 必然生成同一张图像。

DDIM 的三大优势
1. 更少步数,更好质量
从表格可以看到,η=0(DDIM)在 S=10∼50步时 FID 远低于 η=1(DDPM)。DDPM 步数少时质量急剧下降,而 DDIM 用 20 步就能达到 DDPM 1000 步的近似效果。
2. 一致性(Consistency)
因为采样是确定性的,同一个初始噪声 总是生成同一张图。这意味着
就是图像的"编码",可以把它当作潜在表示来使用。
3. 潜在空间插值
由于一致性,可以在两个 之间做插值,生成的图像也会在语义上平滑过渡——这是 DDPM 做不到的,因为 DDPM 每次采样都不同。
二、渐进蒸馏
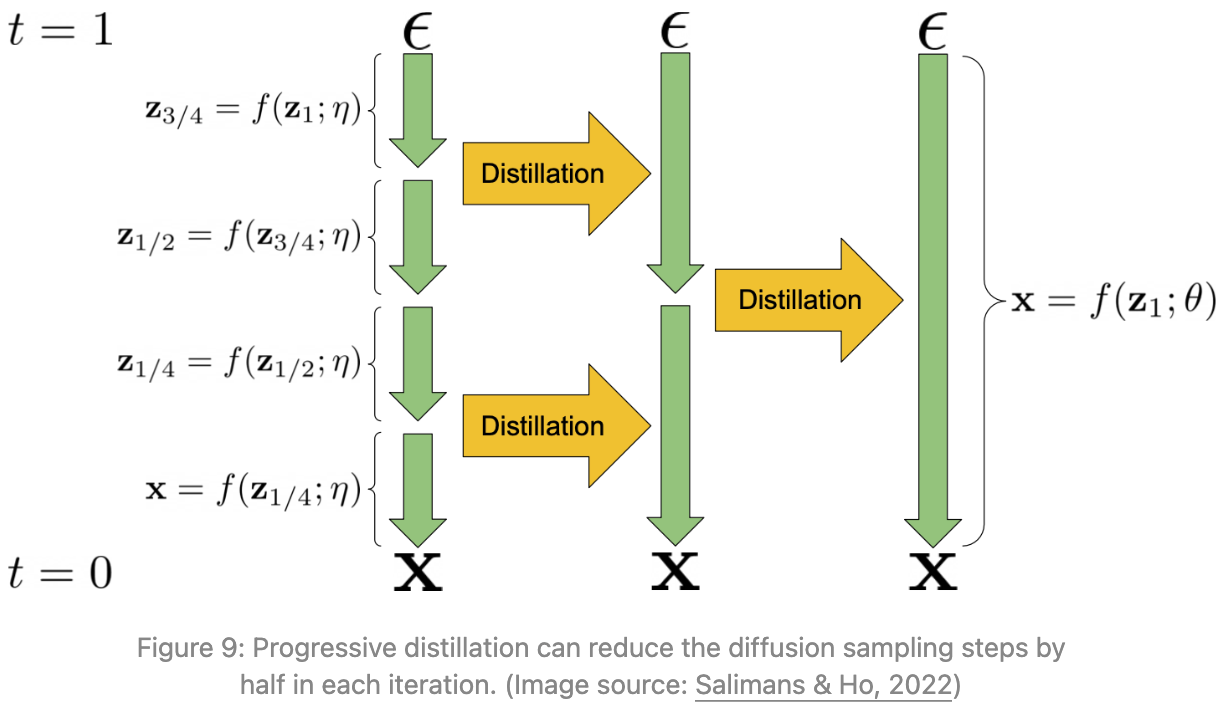
变量含义
图中的 不是不同图片,而是同一张图在不同“噪声时间”下的状态,是 diffusion 论文里一种“连续时间写法”。
表示t=1 时的状态,也就是最强噪声,接近纯高斯噪声。
而(图里最终的 x)表示 t=0 时的状态。即:最终清晰图像。
:时间走到 0.75 时的图。噪声比
少一点。
:噪声更少,图像更清晰。
与普通diffusion的不同
普通 diffusion的target 是 x,真实图。
而 distillation的 target 不再是真实图,而是teacher model 的结果。
student 不再学习:“怎么恢复真实图”。而是学习:“如何一步模仿 teacher 的两步”。
背景与动机
DDPM 采样需要上千步,太慢。DDIM 虽然改善了,但步数仍然不少。渐进蒸馏通过知识蒸馏的方式,把步数指数级压缩。
核心思想
用知识蒸馏的方式训练一个学生模型,让它一步实现教师模型两步的结果。每轮蒸馏步数减半,反复迭代:
1000步→500步→250步→⋯→1步
与普通蒸馏的区别
普通蒸馏是让学生模型模仿教师对原始数据 的预测。
Progressive Distillation 不一样:学生的训练目标不是 ,而是教师走两步之后的结果。
具体来说,给定当前 :
- 教师走第一步:
- 教师再走一步:
- 从
反推出等价的
作为目标
- 让学生一步从
直接达到这个目标
关键设计:
"局部轨迹对齐"而不是"最终结果对齐"
如果只要求学生的最终生成质量和教师一样,约束太弱,学生需要在巨大的搜索空间里自己摸索,很难训练。
"每步对齐教师两步"的约束强得多——教师为学生规划了每一步具体应该走到哪里,学生只需要学会"抄近路",任务明确,训练稳定。
训练流程
每轮 K 次迭代:
初始化:学生从教师模型权重出发(θ←η)
两层循环:
外层(每轮产生新的师生关系):
- 用当前教师权重初始化学生(学生从一个已经很好的起点出发,只需微调)
- 内层训练学生收敛
- 学生成为下一轮教师,步数减半
内层(训练当前学生):
- 采样数据 x,构造带噪
- 教师从
- 从
- 训练学生一步预测这个目标,最小化
每轮结束:
学生变成下一轮的教师(η←θ)、步数减半(N←N/2)
为什么学生从教师权重初始化
教师已经是能生成高质量图像的好模型,学生从它出发只需微调来适应步数减半的目标,比从随机初始化训练快得多也更稳定。
一句话总结
渐进蒸馏的本质是"接力压缩":每轮用局部轨迹对齐的方式训练学生抄教师的近路,步数指数级减少,最终实现极少步数的高质量生成。
三、Consistency Models:直接从任意噪声一步还原原图
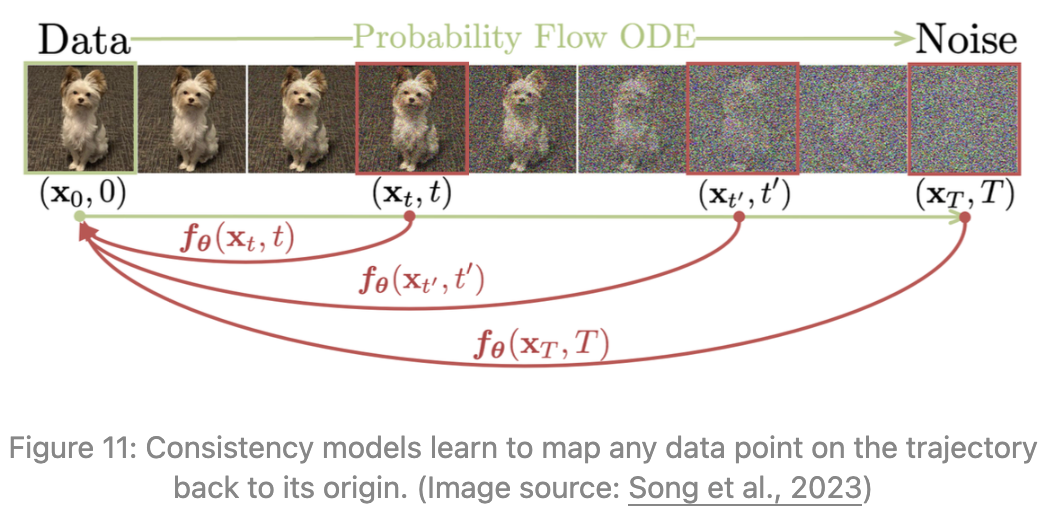
核心思想
不再学习“下一步怎么走”,而是学习“无论现在在哪,直接告诉你最终图像是什么”,模型直接输出,即最终干净图(ϵ是一个很小的、接近0的正数)
扩散模型的采样轨迹上,每一个点 理论上都对应同一个原始图像
。
Consistency Model 就是学习这个映射:
对轨迹上任意 t 成立
这就是"自洽性"(self-consistency)的含义——同一条轨迹上所有点都映射到同一个 。
模型结构

不是让网络从0开始预测,而是保留输入的一部分+网络只负责修正
为了保证边界条件( t=ϵ 时模型应该是恒等映射,即 ),模型被设计成:
其中 ,
,保证在 t=ϵ 时退化为恒等函数。此时
![]() ,意思是:图像几乎没有噪声时(t 接近0),模型应该直接返回输入本身,不做任何改变——这是最自然的约束。
,意思是:图像几乎没有噪声时(t 接近0),模型应该直接返回输入本身,不做任何改变——这是最自然的约束。
此处的ϵ不代表噪声,而是一个很接近0的正数,如0.002,是时间起点
Consistency Model 的时间轴是从 ϵ 到 T、,而不是从 0 到 T。
原因是 t=0 时理论上图像完全无噪声,恒等映射是trivial的但在数值上不稳定,所以用一个很小的 ϵ作为起点来避免这个问题。
两种训练方式
1. Consistency Distillation(CD):从预训练扩散模型蒸馏
预训练的扩散模型已经知道如何逐步去噪,于是consistency model 学如何直接到终点
思路:同一条轨迹上相邻两点 和
应该映射到同一个
,所以让两者的模型输出尽量一致:
![]()
其中:
是用预训练扩散模型(ODE solver)从
走一步得到的
是 θ 的 EMA 版本,起到稳定训练的作用(类似 DQN 的目标网络)
- d(⋅ , ⋅)是距离度量函数,实验发现 LPIPS 效果最好
ODE:Ordinary Differential Equation,常微分方程:本质是在描述一个状态如何连续变化,通常是
需要预训练的扩散模型,但蒸馏后采样极快。
2. Consistency Training(CT):独立训练,不依赖预训练模型
不需要预训练模型,用 score function 的无偏估计 来替代,损失函数类似:
![]()
完全从头训练,不依赖任何外部模型。
与渐进蒸馏的对比
| 渐进蒸馏 | Consistency Distillation | |
|---|---|---|
| 目标 | 学生一步 = 教师两步 | 轨迹上任意两点映射到同一 |
| 约束范围 | 局部(相邻两步) | 全局(整条轨迹) |
| 自洽性 | 无 | 有,可以多步精炼 |
采样的灵活性
Consistency Model 支持两种采样模式:
一步生成:直接 ,极快但质量略低。
多步精炼:生成 后,加少量噪声再还原,反复迭代,用更多计算换更好质量——这是渐进蒸馏做不到的灵活性。
实验结论
- ODE solver 用 Heun(二阶)比 Euler(一阶)好,估计误差更小
- 距离度量用 LPIPS 比
、
好(更符合人类感知)
- N 较小收敛快但质量差,N 较大收敛慢但质量好;自适应 N 是较好的折中
总结
Consistency Model 通过强制同一条去噪轨迹上所有点都映射到同一个原图,学会了"从任意噪声程度一步直达原图"的能力,同时保留了多步精炼的灵活性。
四、提升生成分辨率与质量
1、级联扩散模型(Cascaded Diffusion Models)
直接生成大图,因为像素太多,使用diffusion容易结构混乱、细节崩、算力爆炸,所以作者想到“先画草图,再逐步细化”,设计了多阶段diffusion pipeline。
核心思路: 用多个扩散模型串联,逐步提升图像分辨率。
如图15所示,流程为:
类别ID → 32×32(模型1)→ 64×64(模型2)→ 256×256(模型3)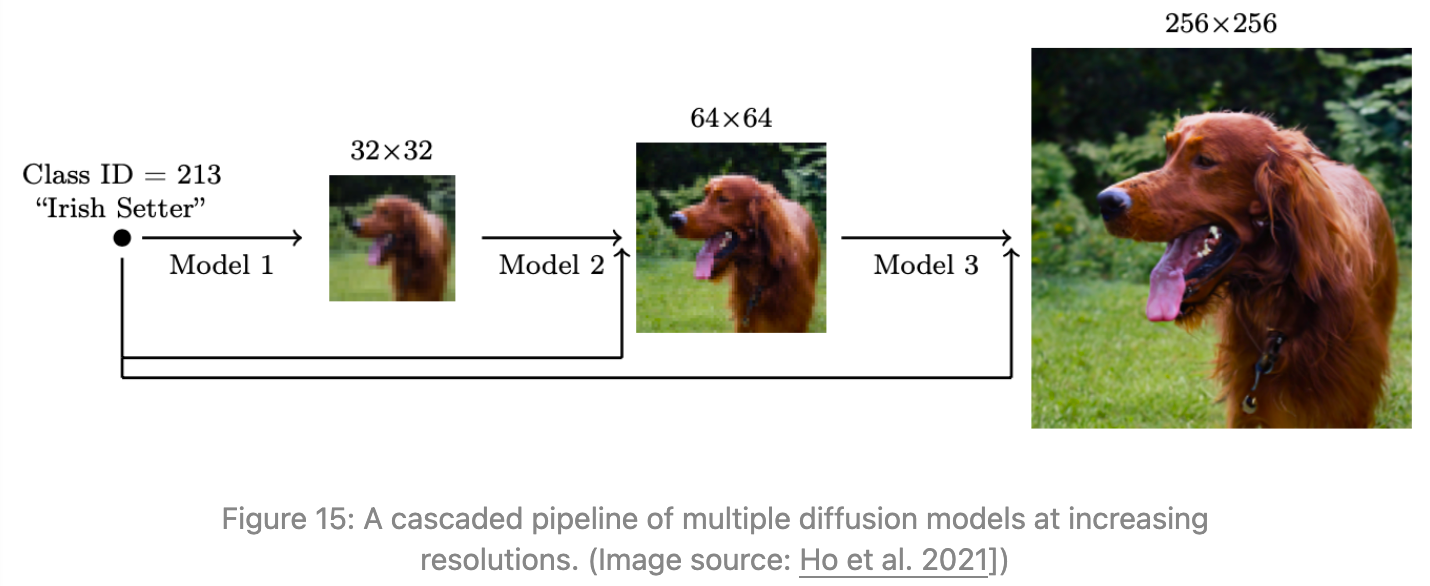
后面的模型不是重新生成图像,而是条件生成高分辨率细节
低分辨率负责构图、姿态、大结构,高分辨率负责毛发、纹理、眼睛等细节。
因为super-resolution 模型很容易“过拟合完美低清输入”,所以给低分辨率图加高斯噪声、模糊、
corruption,让模型学会面对不完美输入也能修复。
噪声条件增强(Noise Conditioning Augmentation) :
- 对每个超分辨率模型的条件输入 z 施加强数据增强
- 目的是减少级联过程中的误差累积
- 常用 U-Net 作为模型架构
两种增强策略:
| 策略 | 说明 |
|---|---|
| 截断式 | 在步骤 t > 0 时提前停止扩散过程(低分辨率用) |
| 非截断式 | 跑完完整的低分辨率逆过程,再对结果加噪后送入超分模型 |
2、unCLIP:用 CLIP 做图像生成
CLIP 是什么?
CLIP 是 OpenAI 训练的模型,将文字和图像映射到同一个向量空间,使得"一只猫"的文字嵌入和猫的图片嵌入在空间上非常接近。
unCLIP
第一阶段:文本 → 图像嵌入(Prior)

- 输入文字 y,CLIP 文本编码器对齐文本和图像embedding 生成文本嵌入
- Prior 模型(扩散模型或自回归模型)以文本嵌入为条件,输出图像嵌入
。其训练目标来自 冻结的 CLIP Image Encoder:对于训练数据中的每一对 (x,y),用 CLIP Image Encoder 提取真实图片的图像嵌入
作为 GT,监督 Prior 的输出
第二阶段:图像嵌入 → 真实图像(Decoder)
![]()
- Decoder 以图像嵌入为条件,从噪声图像(训练阶段是对CLIP中输入的真实图像随机加噪得到的
- 也可以输入一张真实图片的嵌入,生成风格/语义相似的变体图
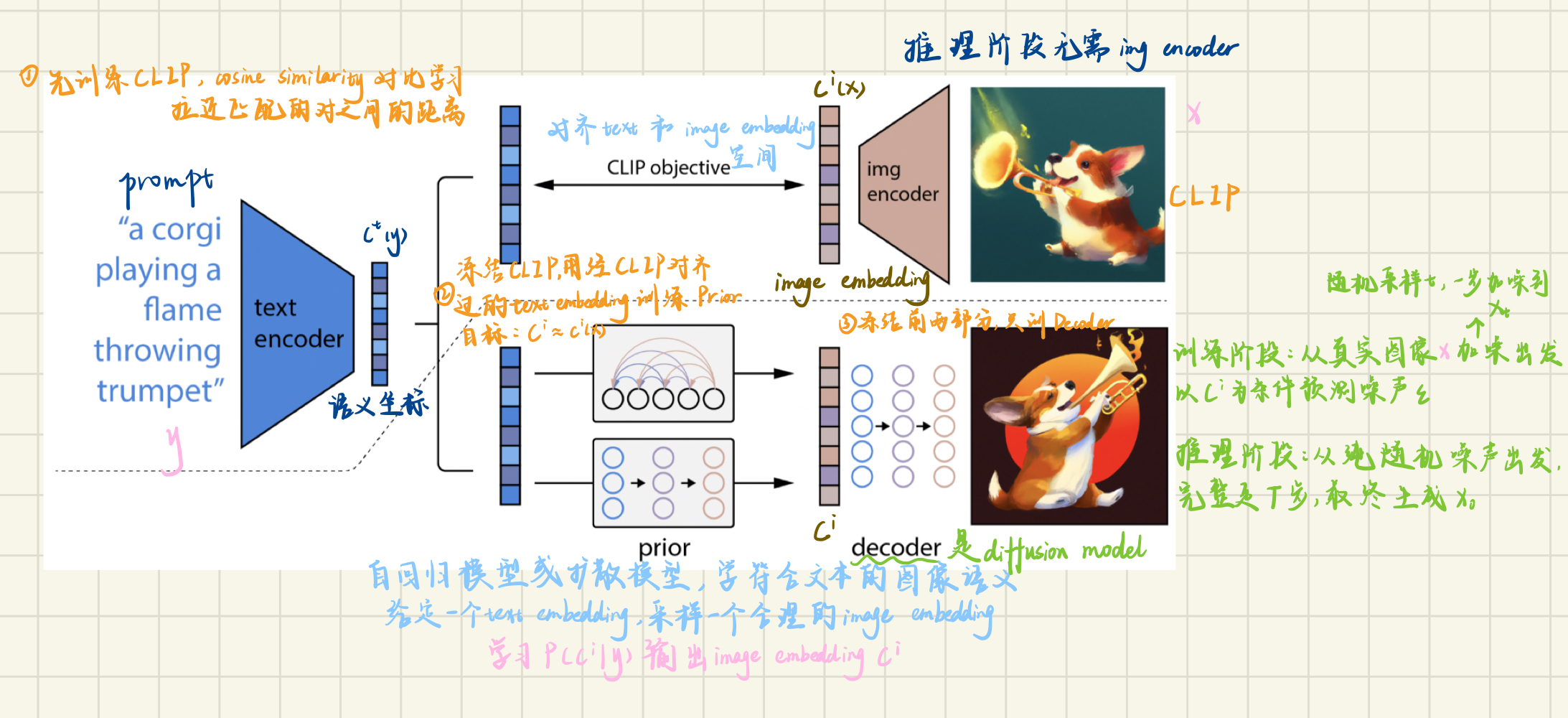
为什么叫"unCLIP"?
CLIP 是将图像→嵌入(编码),unCLIP 是将嵌入→图像(解码),方向相反,故名。
3、ControlNet:给扩散模型加条件控制
背景
原始扩散模型只能接受文字作为条件,但很多时候需要更精确的空间控制:
"帮我生成一张人物图" ← 文字控制,结果随机性很大
更精确的需求:
给定人体骨骼姿态图 → 生成对应姿态的人物
给定边缘检测图 → 生成对应结构的场景
给定深度图 → 生成对应空间关系的图像ControlNet 就是为了解决这个问题——在不破坏原模型的前提下,注入额外的空间条件控制。
ControlNet 的四步操作
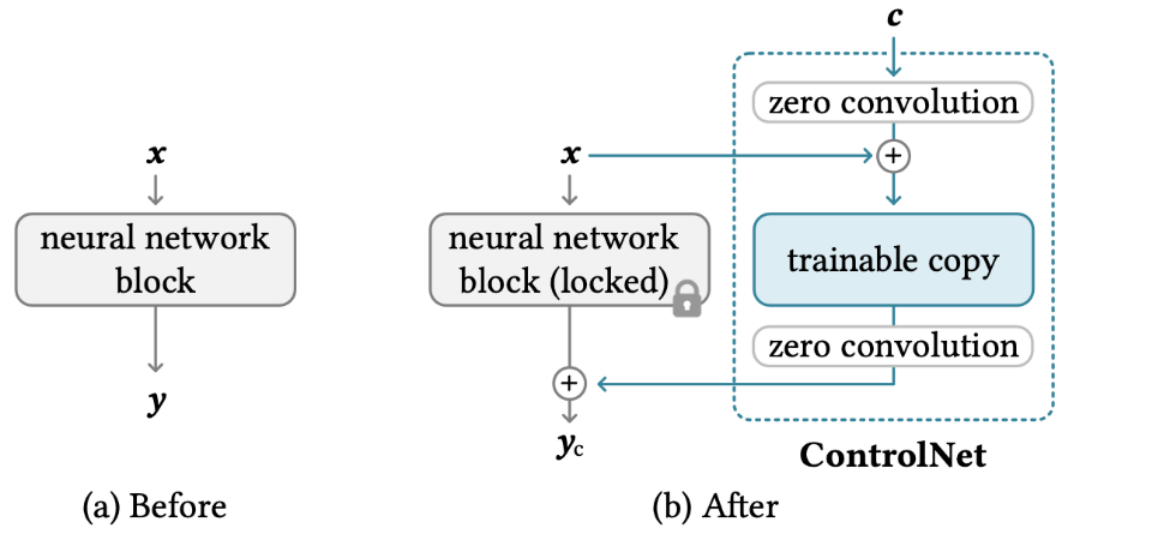
对照图18(b),逐步解释:
Step 1:冻结原始模型
原始 U-Net 的参数 θ 全部冻结
保证原有的生成能力不被破坏Step 2:克隆一个可训练副本
将原始 U-Net 的每个编码器块完整复制一份
副本参数可以被训练更新
额外接收条件输入 c(如骨骼图、边缘图)
Step 3:用零卷积层连接两个分支
零卷积(Zero Convolution)是 1×1 卷积,初始化时权重和偏置全为 0:
为什么要用零卷积?
训练刚开始时:
零卷积输出 = 0
ControlNet 分支对原模型的影响 = 0
→ 原模型行为完全不变,生成质量有保证
随着训练进行:
零卷积的权重从 0 开始慢慢学习
ControlNet 分支逐渐发挥作用
→ 平滑地引入条件控制,不会引入噪声梯度破坏训练两个零卷积的位置:
第一个
:在条件 c 进入可训练副本之前
作用:对条件信号做尺度调整第二个
:在可训练副本输出之后
作用:对副本输出做尺度调整,再加回原模型
Step 4:最终输出公式
![]()
拆解来看:
← 原始冻结模型的输出(不变)
← 条件 c 经第一个零卷积处理
← 原始输入 与 处理后的条件 相加
(把条件信息融入输入)
← 可训练副本处理融合后的输入
← 副本输出经第二个零卷积缩放
最终输出 = 原模型输出 + 副本输出 ← 残差式融合
ControlNet 支持的条件类型
| 条件类型 | 输入形式 | 控制效果 |
|---|---|---|
| Canny 边缘 | 边缘检测二值图 | 控制物体轮廓和结构 |
| Hough 线条 | 直线检测图 | 控制建筑、几何结构 |
| 人体骨骼 | 关键点连线图 | 控制人物姿态 |
| 深度图 | 灰度深度图 | 控制三维空间关系 |
| 分割图 | 语义分割标注 | 控制各区域内容 |
| 用户涂鸦 | 手绘草图 | 按草图生成图像 |
设计精妙之处总结
原始模型(冻结) ControlNet 分支(可训练)
↓ ↓
保留生成能力 学习理解条件输入
↓ ↓
└──────────── + ────────────┘
↓
受控的生成结果ControlNet 最聪明的地方在于:
- 零卷积初始化 → 训练初期完全不干扰原模型,避免灾难性遗忘
- 残差式融合 → 条件控制以"增量"形式加入,原能力完整保留
- 克隆而非修改 → 原模型权重永远不变,可以随时插拔 ControlNet
五、Diffusion Transformer (DiT)
之前讲的扩散模型都用 U-Net 作为骨干网络,但 U-Net 有一个明显的局限:
U-Net 的问题:
规模扩展性差——增大模型很麻烦,需要手动设计每一层
卷积结构天然是局部感受野,捕捉全局关系能力弱
Transformer 的优势:
规模扩展性极好——只需堆叠更多 Block
Self-Attention 天然是全局感受野
在语言、视觉领域已被反复证明"越大越好"DiT 的核心思想就是:把扩散模型的 U-Net 骨干换成 Transformer,同时在隐空间(Latent Space)操作,也就是 LDM(Latent Diffusion Model)的设计。
流程
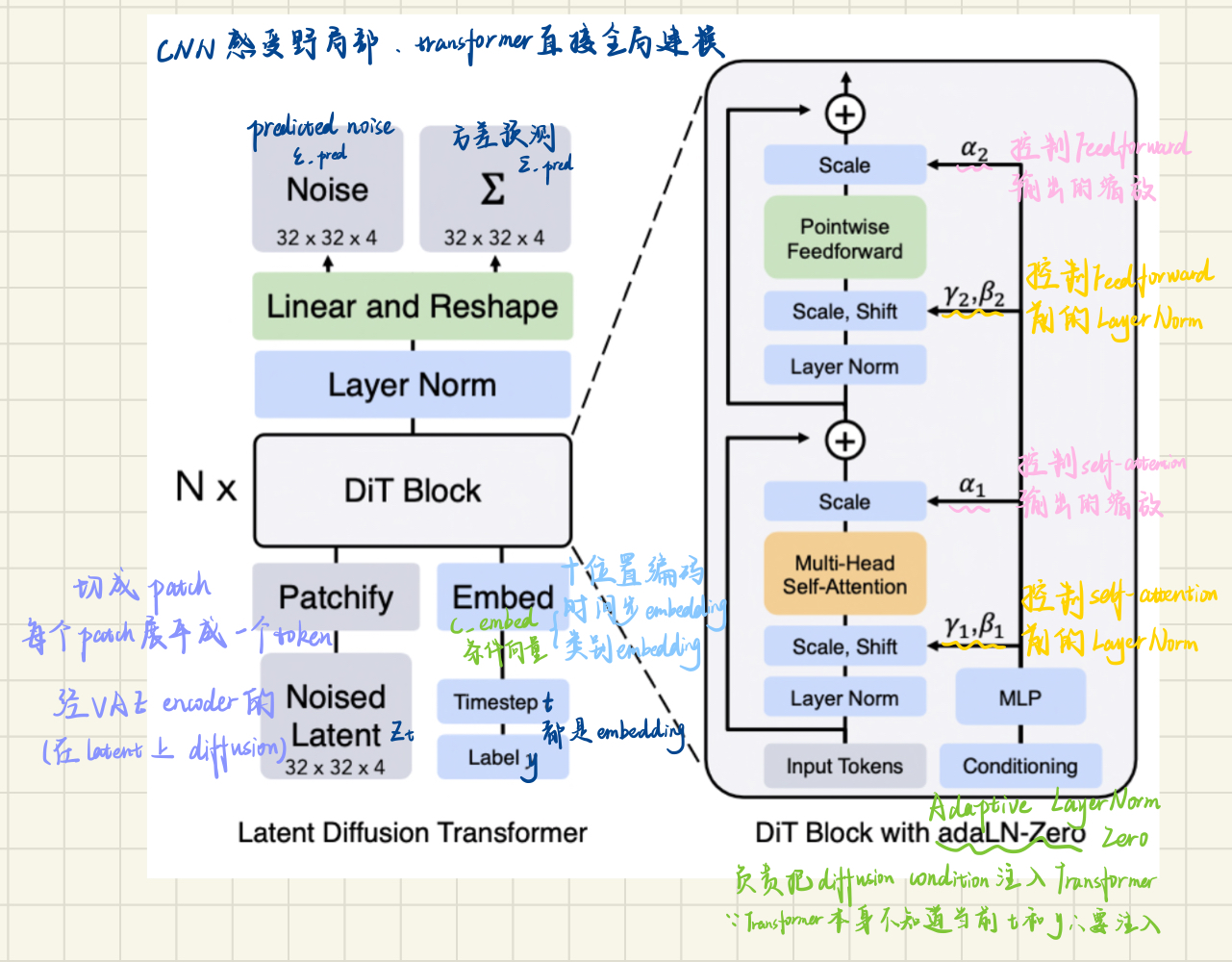
DiT Block 的改动:adaLN-Zero
普通 Layer Norm 的归一化参数(scale γ 和 shift β)是固定的可学习参数,与输入无关。
Adaptive Layer Norm(adaLN) 的关键改进:
条件向量 c_embed(由 t 和 y 的嵌入相加得到)
↓ MLP 回归
↓
γ₁, β₁ → 控制 Self-Attention 前的 Layer Norm
γ₂, β₂ → 控制 Feedforward 前的 Layer Norm
α₁ → 控制 Self-Attention 输出的缩放
α₂ → 控制 Feedforward 输出的缩放具体计算:
adaLN 的归一化过程:
普通 LN: output = γ · normalize(x) + β
(γ、β 是固定参数)
adaLN: output = γ(c) · normalize(x) + β(c)
(γ、β 由条件 c 动态生成)Zero 的含义: 初始化时,所有 α(缩放参数)初始化为 0:
训练初始:
α₁ = 0 → Self-Attention 输出 × 0 = 0
α₂ = 0 → Feedforward 输出 × 0 = 0
整个 DiT Block 输出 = 输入(恒等映射)
训练过程中:
α 从 0 开始慢慢学习
Block 逐渐发挥作用这和 ControlNet 的零卷积思路完全一致——训练初期保持稳定,避免随机初始化带来的噪声梯度。
完整 DiT Block 数据流
输入 token x
│
├─ Layer Norm
│ ↓ 用 γ₁,β₁ 做自适应归一化(由条件c控制)
│ Multi-Head Self-Attention
│ ↓ 输出 × α₁(初始为0)
└──────⊕ 残差连接
│
├─ Layer Norm
│ ↓ 用 γ₂,β₂ 做自适应归一化(由条件c控制)
│ Pointwise Feedforward(MLP)
│ ↓ 输出 × α₂(初始为0)
└──────⊕ 残差连接
│
输出 token x'三种条件注入方式的对比
论文探索了三种把时间步 t 和类别 c 注入 Transformer 的方式:
| 方式 | 做法 | 问题 |
|---|---|---|
| In-context conditioning | 把 t、c 的嵌入作为额外 token 加入序列 | 条件信息与图像 token 混在一起,影响有限 |
| Cross-Attention Block | 图像 token 通过 cross-attention 查询条件信息 | 增加计算量,效果提升有限 |
| adaLN-Zero ✓ | 条件动态控制每层的归一化参数 | 无(效果最好) |
adaLN-Zero 效果最好的直觉理解:
归一化层控制着每一层"信息流的尺度和偏移"
让条件 c 直接控制这个尺度 → 条件信息渗透进每一层的特征处理
比"加几个 token"或"偶尔做 cross-attention"影响更深入、更全面DiT 相比 U-Net 的核心优势
U-Net DiT
─────────────────────────────────────────
像素/特征空间操作 隐空间操作(更高效)
卷积(局部感受野) Self-Attention(全局感受野)
手动设计各层结构 统一堆叠 Block,扩展简单
扩展性一般 扩展性极好(更大=更好)DiT 的实验结论:模型越大、计算量越多,生成质量持续提升,这正是 Transformer 架构在语言模型领域已经反复验证过的规律,现在被成功迁移到图像生成领域。这也是 Sora 等视频生成模型采用 DiT 架构的根本原因。
六、扩散模型的优缺点
优点:兼顾可解析性与灵活性
生成模型面临一个根本矛盾:
可解析模型(如高斯分布):
✓ 数学上易于分析和训练
✗ 无法描述复杂数据的丰富结构
灵活模型(如 GAN):
✓ 能拟合任意复杂分布
✗ 训练不稳定,评估困难
扩散模型:
✓ 可解析——前向加噪过程有闭合形式,训练目标简单(预测噪声)
✓ 灵活——能生成极其复杂、高质量的图像
两者兼得!缺点:采样速度慢
GAN 生成一张图:
随机噪声 → [一次前向传播] → 图像
速度极快
扩散模型生成一张图:
x_T → x_{T-1} → ... → x_0
需要 T 步(通常 50~1000 步)前向传播
速度慢很多目前有 DDIM、DPM-Solver 等加速采样方法,但仍比 GAN 慢。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)