AI Engineering (3)
我们简单说一下多模态大模型
LLM本质上是在做token的接龙,根据前面的token预测后面的token
单一模态的大模型只支持以文本作为输入,而多模态大模型支持以图片、视频、音频、文件等作为输入
当以非文本作为输入时,例如图片,要经历以下流程:
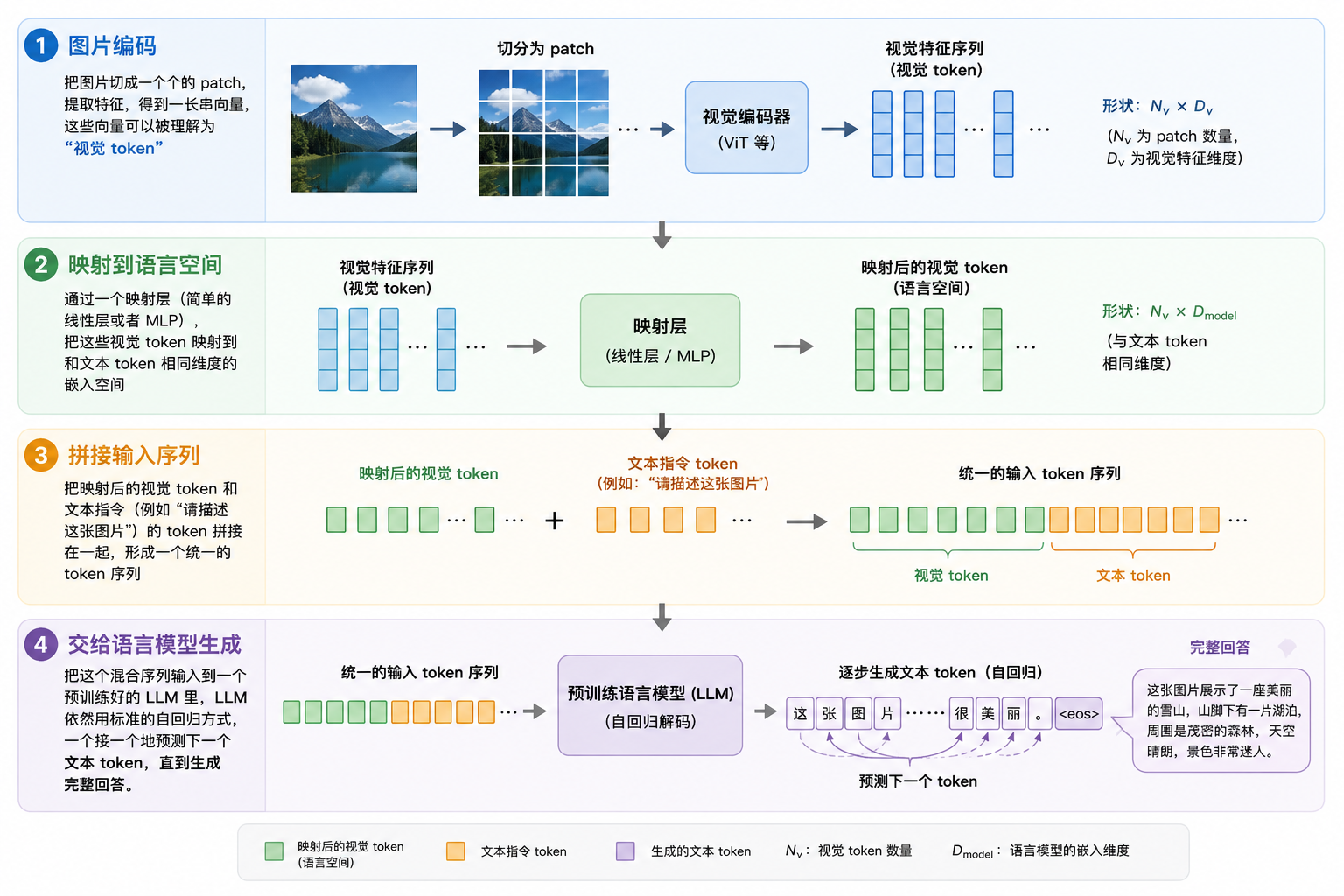
1.图片编码:
把图片切成一个个的patch,提取特征,得到一长串向量,这些向量可以被理解为“视觉token”
2.映射到语言空间:
通过一个映射层(简单的线性层或者MLP),把这些视觉token映射到和文本token相同维度的嵌入空间
3.拼接输入序列
把映射后的视觉 token 和文本指令(例如 “请描述这张图片”)的 token 拼接在一起,形成一个统一的 token 序列,就像下面这样:[视觉token, 视觉token, ..., 文本token, 文本token, ...]
4.交给语言模型生成:
把这个混合序列输入到一个预训练好的 LLM 里,LLM 依然用标准的自回归方式,一个接一个地预测下一个文本 token,直到生成完整回答。
所以这样看,生成的步骤还是在做文字接龙,但是前三个将图片和文字向量做同质化处理的则是多模态大模型的创新
更前沿的大模型(比如统一多模态生成模型,如 Gemini 的某些版本、Emu3 等)不止追求输出文本,也可以输出图像、音频 token。这时,它们做的其实是 多模态 token 接龙:下一个预测的可能是文字 token,也可能是图像 patch token。 这更超越了“文字接龙”的范畴,变成了“任意模态 token 的接龙”。
我们来设想一种情况,当多模态大模型成为了AI AGENT的大脑,那是不是就相当于打通了agent的视觉和听觉,也让agent有了发出声音、做视频、画画的本领?
答案是肯定的,但是目前主流的方法仍是:LLM生成文本指令,调用agent的tool来实现多模态生成
比方说:
-
发出声音:大脑生成文本,调用 TTS(文字转语音),如 ElevenLabs、Edge TTS
-
画画:大脑写好 prompt,调用图像生成模型(DALL·E、Stable Diffusion、Midjourney)
-
做视频:大脑写描述或脚本,调用视频生成模型(Sora、Runway 等)
在这种情况下,decoder是外部工具,需要LLM发送工具调用指令来调用:多模态大脑本身只输出文本指令。比如,你问“昨天咱俩聊的那个穿盔甲的小猫,再画一遍”,大脑不会直接生成图像 token,而是写出一段 prompt:“白色小猫,穿着中世纪银色盔甲,油画风格……”,然后调用一个外部的图像生成工具(如 DALL·E),这个工具就是“解码器”。
更前沿的技术路线是让LLM这个大脑直接生成多模态内容:
-
语音对话:GPT-4o 的语音模式可以直接输出音频 token,中间不需要“脑内文字→TTS”的显式转换,它能保留笑声、语气、呼吸节奏。这就是 音频 token 接龙。
-
直接生图:如 Gemini 某些版本、GPT-4o 的图像生成能力(目前部分通过工具,但技术趋势是模型原生交织输出图像 token)、Emu3 等,可以把图像 patch token 当作会接的“龙”直接生成出来。
-
视频生成:类似地,以 Sora 为代表的扩散模型,或者基于 token 的自回归视频生成模型,都可以被整合进 Agent 的大脑,统一调度。
在这种情况下,decoder是内嵌进大模型的,我们就可以直接得到音频、图像和视频
-
以语音为例:
模型直接输出的“音频 token”,其实是经过压缩的声学特征码(比如神经音频编解码器中的码本序号)。模型内部就接了一个解码器,能把这些 token 实时还原成我们能听见的波形音频。
这个过程全是端到端的,大脑(LLM)发出的神经信号,直接驱动声带(解码器),中间没有“先生成文本,再调 TTS 工具”的步骤。这才能保留笑声、犹豫、呼吸等非文字信息。 -
以图像为例:
像 Gemini 或 Emu3 这类模型,输出的“图像 token”就是经过量化的图像块像素信息。模型自带的图像解码器会直接把这些 token 组合成一幅完整的图像。这类似于你用画图软件,大脑直接控制手臂和画笔,而不是大脑先写好提示词,再等待另一台 AI 打印机来执行。
此时模型就更不像一个大脑,而是变成集成大脑的功能和肢体功能的一体化端到端生成工具了

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)