AI音乐下半场:Mureka跨过生产可用门槛,让模型像作曲家一样思考,开发者又可以有哪些新可能?
上周大模型圈子有个很魔幻的场面,傅盛、孙宇晨、特朗普家族,三个八竿子打不着的人,开始扎堆做大模型中转站的生意。
说明了一个问题,现在AI模型的供给侧,依旧是没有看起来的那么成熟。
大多数人只关注到LLM,其实AI音乐的情况更野蛮,更荒谬。。
Suno,全球用户量最大的AI音乐产品,融了2.5亿美金,月活千万级别。但直到今天,它都没有开放官方API。Udio,也没有。
一条冷知识:
几乎所有头部AI音乐产品,都不卖API。
我也是最近调研这个选题才知道的。
这意味着什么?全球想在自己产品里接AI音乐能力的企业,只剩一条路:灰产中转。没有SLA(服务等级协议,不承诺服务质量)、没有售后、生成质量开盲盒,出了问题找不到人。
所以AI音乐在B端一直很尴尬。C端卷上天了,各种产品月活都在涨。但B端始终没真正跑起来。
最近这个局面出现了裂口。
北美一个增长很猛的AI音乐创作平台Sondo,之前也吃灰产,今年初却做了个反直觉的动作:接入Mureka,替换Suno。哪怕单价贵出一截,也要把灰产全砍了。
一家精打细算的增长期公司,却主动选更贵的方案。光是这个决定本身,已经能说明问题了。
据介绍,Sondo全量切换到Mureka后,双方的合作体量增长超过70%。Sondo的音乐核心业务翻倍增长。
快歌,国内头部AI音乐生成应用,也选择了Mureka,其海外版未来也会选择Mureka。另有一家海外头部AI artist平台,接入后消耗规模翻了6倍。
三家企业,诉求各不相同—Sondo要质量,快歌要中文,海外平台要合规,都同时做了同一个动作,切换模型API。
所以,这里面有一个问题值得追问:凭什么是Mureka?
◈MusiCoT:从猜音符到读懂整首歌
CoT,Chain-of-Thought,思维链,是大模型领域这两年最重要的概念之一,核心就一句话,让AI先想再答,不要上来就蒙。加上“Let's think step by step”一句提示,模型的推理能力就能跳一个台阶,因为它强制把模型的思考过程摊开了。
这个思路在文本领域已经被验证得很充分了。Mureka做的事情是把它搬到了音乐里。
之前AI音乐的生成方式,本质上是猜下一个音符。模型写完第一个音,根据概率猜第二个,再猜第三个,一路猜到结尾。这个过程没有规划、没有全局观,运气差走到一半副歌直接崩掉。
MusiCoT做的事,是让AI在写第一个音符之前,先想清楚整首歌。
它同时建模四个维度的关系:歌词段落在哪里切分、每段歌词的语义重心落在哪个词、音乐结构怎么对应、声音表达怎么配合情绪走向。这四条线不是分开处理的,是协同推演的——技术路线叫作多尺度多维度CoT。
这个范式的变化直接体现在了V9的五项升级上,而且每一项都精准对应企业生产中最头疼的问题:
-
段落级文本控制——歌词的情绪重心能准确落在你想让它爆发的位置。以前是歌词被唱出来了,现在是歌词在对的段落被准确表达了。
-
混音与音质——人声和伴奏的层次分开,接近母带级,不是糊成一团的廉价感。
-
人声表达——演唱变得克制,减少了莫名其妙的飙高音和杂音干扰。听起来像一个真人在唱,而不是AI在炫技。
-
生成效率——推理链路优化之后,试错成本下降。企业不用再花大量时间反复抽卡。
-
生成多样性——同一个方向下能探索更多可能性,不会生成五次出来五首差不多的歌。
这五项升级叠在一起的效果是:从生成之后人工二次处理,变成了生成即可发布。
所以Sondo对Mureka的评价是:
“人声效果更具真人感,可以直接对接产研团队。”
老版本V7.6的评价是“差强人意”,新版本V8的评价是“可以直接对接产研团队”。
转变是在今年1月份,Mureka V8上线之后。Sondo内部做了一轮覆盖多场景的A/B测试,Mureka稳定胜出,所以渐渐拿到了音乐模型调用量的绝对大头,现在是全量切换。
不是Sondo突然降低了标准,是Mureka的输出质量超过了生产线的及格线。AI生成的素材不用人工再过一道了,是流水线的一环。
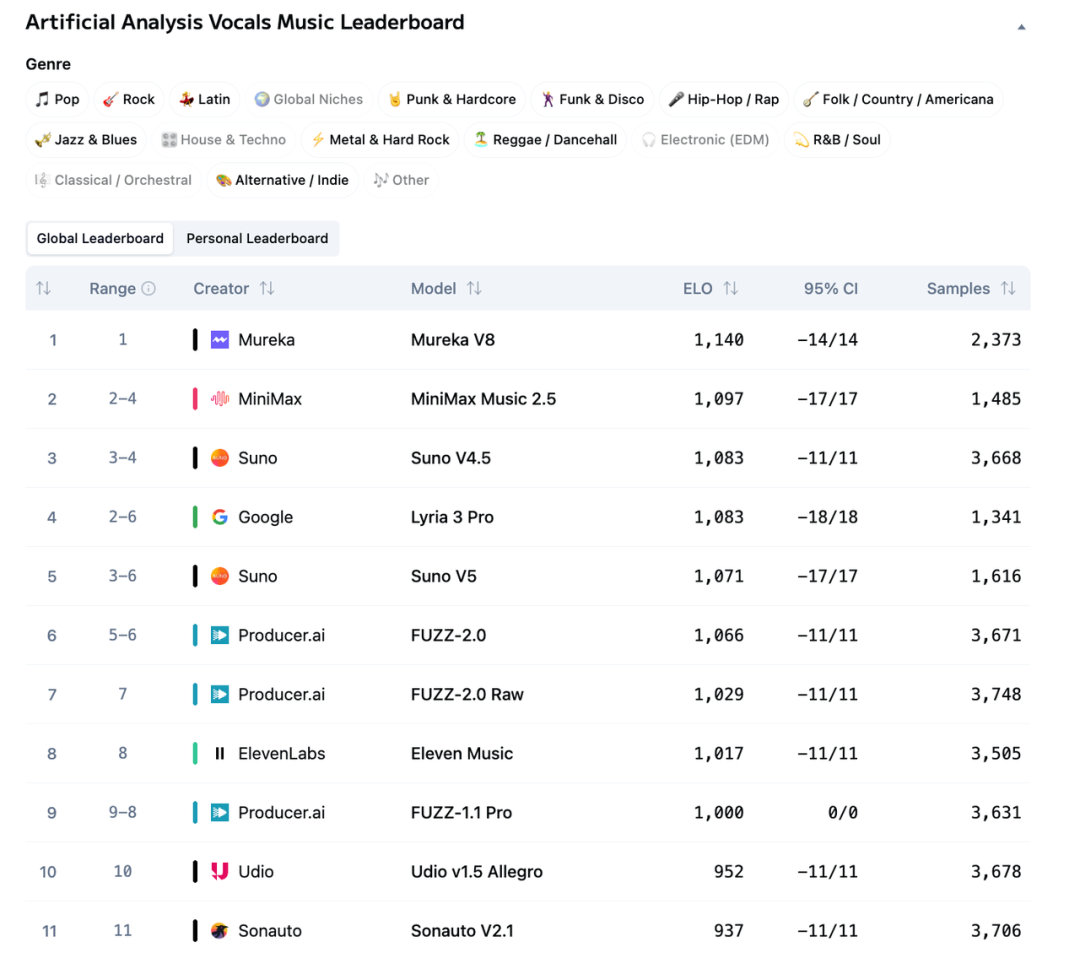
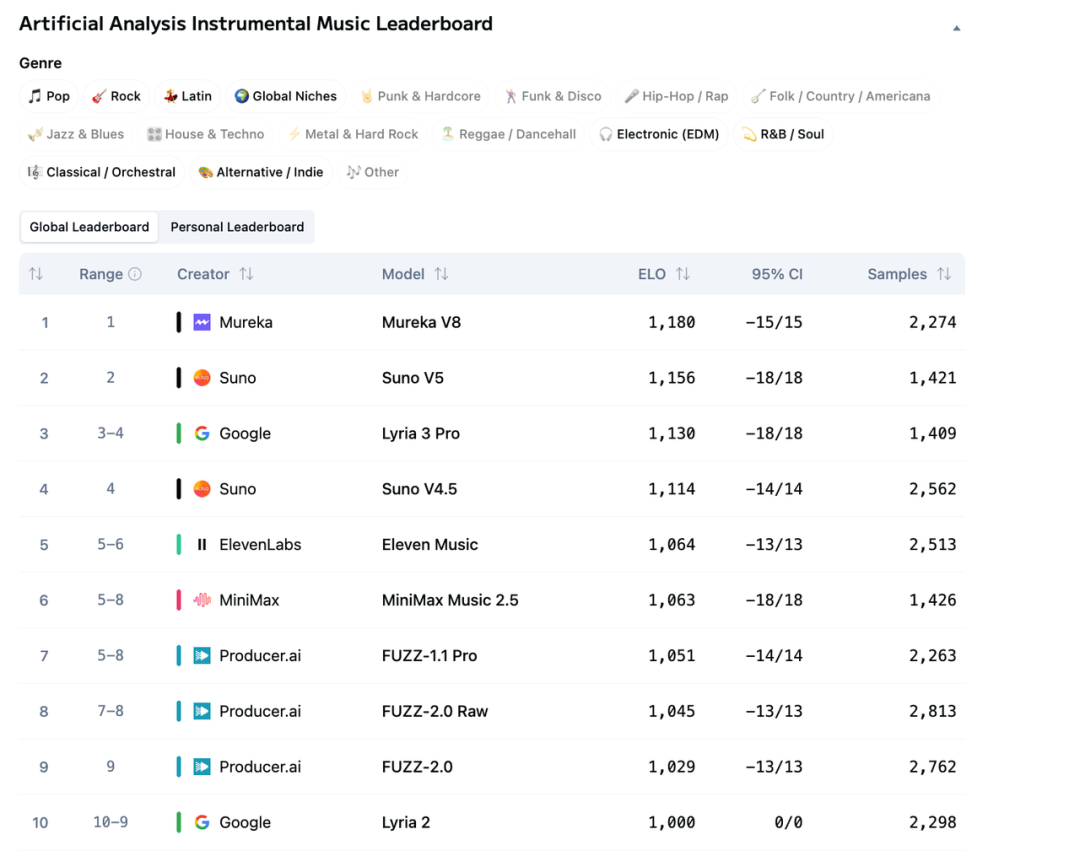
榜单成绩也在验证这个结论。今年3月,搭载MusiCoT框架的Mureka V8在Artificial Analysis Music Arena上拿下人声和器乐双榜第一,综合超越Suno、Udio、Google Lyria等一众主流竞品。
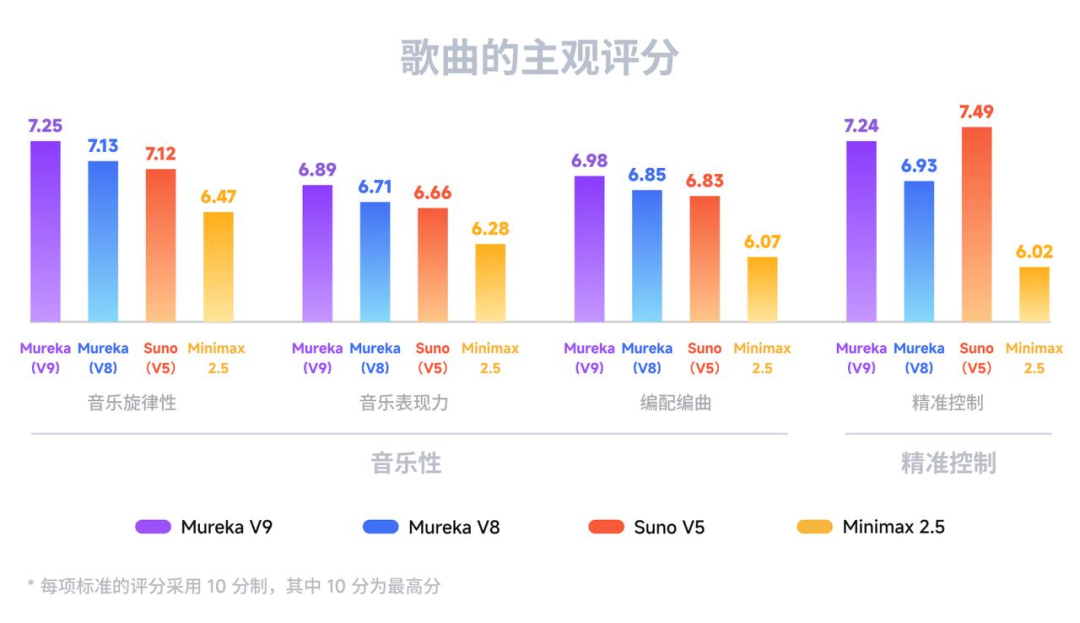
随后,V9在外部音乐专家的主观盲评中,四个评测维度领先。
如果把Mureka从V1到V9的演进串起来看,有一条不太被注意到的技术复利曲线:
-
2024年2月,V1(SkyMusic):中国首发端到端音乐生成模型,验证技术路线能跑通;
-
2025年3月,V6+O1:MusiCoT框架上线,首次达到SOTA;
-
2026年1月,V8:面向真实创作场景的整体跃迁——从「能生成」到「能发布」;
-
2026年3月,V9:从「能写出来」到「能按你想的方式写出来」。
从技术关键节点看,每一步都在推动同一件事情:让AI音乐变得可控、可信任、可量产。
◈生产力上手实测
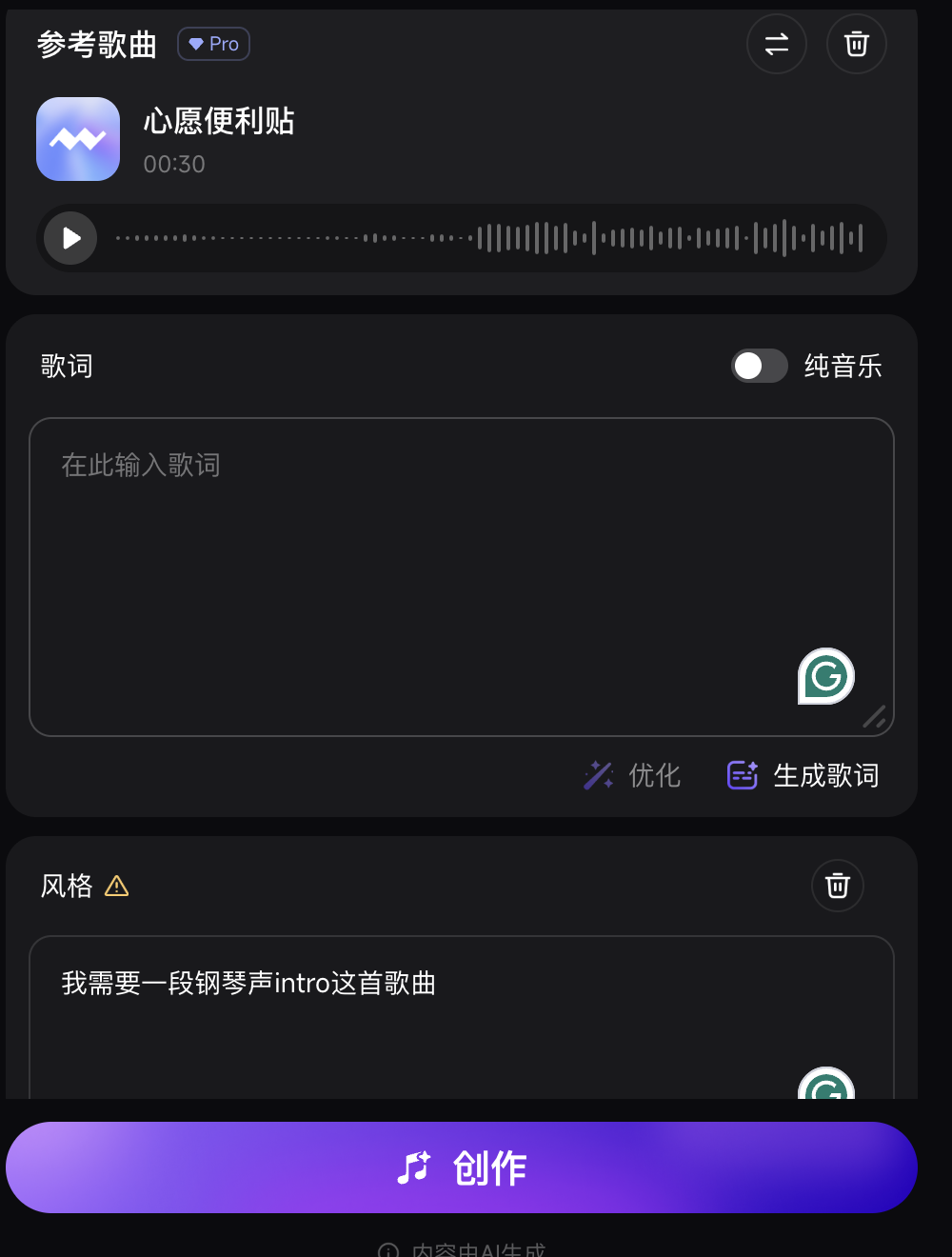
为了验证这套作曲家大脑的能力,我盘了盘它,我先给它喂了《心愿便利贴》的歌词:
以《心愿便利贴》的歌词为基础创作新的歌

整体旋律的走向、分词的逻辑感,完全没有那种廉价的机械生硬。这不是随机生成,这是懂乐理的表现。
紧接着,我加大了难度:多语种切换。
在多语种切换下,Mureka 的转调和卡点依然非常自然,韵律之间没有违和感。
如果要选出 Mureka V9 最让我兴奋的功能,那一定是【多音轨分离】。
以前 AI 音乐最大的痛点是一锅粥—人声和乐器糊在一起,后期想调个均衡或者换个鼓点,门儿都没有。
而 Mureka V9 彻底解决了这个焦虑。为了测试,我假装了一回音乐总监:
开头要钢琴铺底,主歌推进,高潮必须加一串清脆的风铃提亮,结尾用悠扬的小提琴拉满情绪。

放在以前,这种复杂的结构调整对 AI 来说简直是不可能的事儿。但在 Mureka 里,我是这样做的:

-
分结构拆解
我不是让它直接生成一首完整的歌,而是按照我的设想,拆分成 Intro、主歌、带风铃的副歌、小提琴尾奏这几个独立的结构设定。
-
精准控制
针对每一轨,我提出了非常具体的要求(比如“这里风铃要脆”、“那里弦乐要悠扬”)。
比如我上传了一首参考曲子,或者直接描述:“Intro 要极简钢琴”、“副歌必须加入清脆风铃”、“尾奏的小提琴要悠扬且情绪饱满”。
-
后期组装
把这些生成好的独立音轨导入Mureka内置的 DAW(数字音频工作站),手动微调切入的时间点、对齐节拍、校准音量细节。
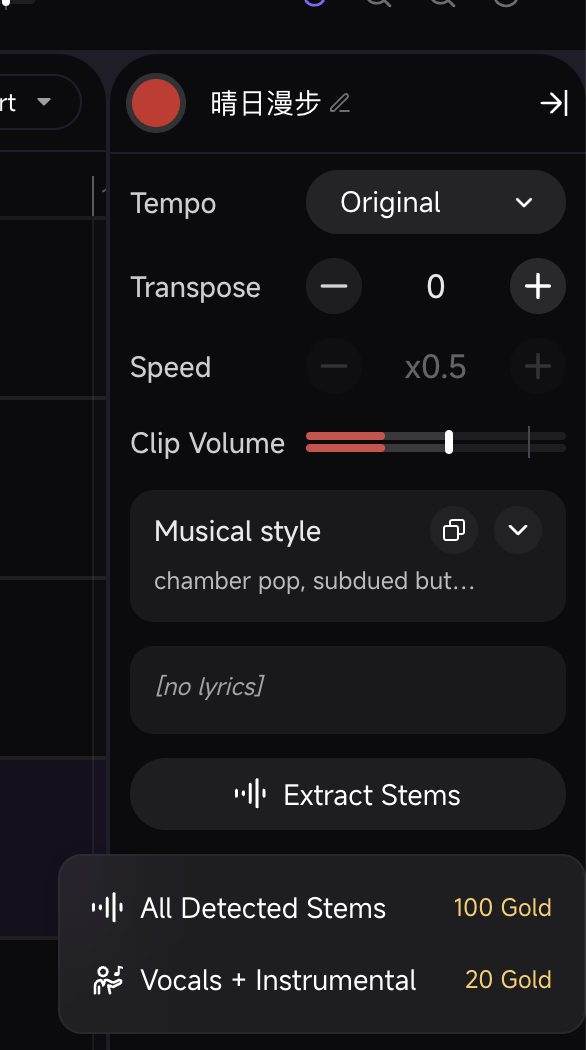
以前生成的曲子如果不满意,你只能重抽,但在 Mureka 的工作流里,你可以像拿着卡尺一样去校准:
-
移调(Transpose)
觉得伴奏分离的伴奏调不合适,可以升高或者降低。 -
节奏控制(Tempo & Speed)
可以直接锁定节奏,而不用担心加速后声音变细;
- 一键分轨(Extract Stems)
变成了一个可以反复打磨、真正能导入 DAW 的专业工具。
这种“确定性”,才是它能跨过生产可用门槛的真正原因。它不再让你在AI的控制下碰运气,而是给了你一个工业级的生产标准。
◈结语
说回开头的问题。
AI的供给侧为什么看起来成熟、实际上很脆弱。因为大部分AI产品的思路还停留在C端,做一个好玩的东西,让用户觉得好酷。
但是企业端要的是:稳定、可控、合规、有售后。
当 AI 不再是一个不可解释的黑盒,而是能够被拆解、被微调、被控制的工业单元时,它才算真正拿到了生产力的入场券。 从 2024 年首发端到端模型,到 MusiCoT 框架,再到现在的 V9,Mureka 这一路其实只在做一件事跨越鸿沟。
这条鸿沟的一边是实验室里的随机奇观,另一边是工业界的确定性产能。
据报道,全球已经有8000多家企业接入Mureka ,包括短视频内容、AI创作工具、数字素材市场、视频制作等应用场景。
B端采购是最理性的决策。不存在冲动消费,不存在为信仰充值。一家企业愿意消费,只有一个原因,算过账,划算。
这才是AI音乐真正的分水岭—模型的输出质量能跨过「生成即可用」这条线。



AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 3
3 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)