Higress AI网关终于搞懂了!安装、服务来源、路由配置、插件全解
Higress 介绍
Higress 是阿里内部为解决 Tengine reload 对长连接业务有损,以及 gRPC/Dubbo 负载均衡能力不足而诞生。
AI 网关的本质依然是 API 网关,AI 原生的意义在于,在这样的 API 网关里,AI 是一等公民。API 研发,API 供应,API 消费,以及 API 观测都基于 AI 场景下的需求,演进出全新的能力。
核心优势:
1、生产等级
脱胎于阿里巴巴多年生产验证的内部产品,支持每秒请求量达数十万级的大规模场景。
彻底摆脱 Nginx reload 引起的流量抖动,配置变更毫秒级生效且业务无感。对 AI 业务等长连接场景特别友好。
2、便于扩展
提供丰富的官方插件库,涵盖 AI、流量管理、安全防护等常用功能,满足90%以上的业务场景需求。
主打 Wasm 插件扩展,通过沙箱隔离确保内存安全,支持多种编程语言,允许插件版本独立升级,实现流量无损热更新网关逻辑。
3、安全易用
基于 Ingress API 和 Gateway API 标准,提供开箱即用的 UI 控制台,WAF 防护插件、IP/Cookie CC 防护插件开箱即用。支持对接 Let’s Encrypt 自动签发和续签免费证书,并且可以脱离 K8s 部署,一行 Docker 命令即可启动,方便个人开发者使用。
4、流式处理
支持真正的完全流式处理请求/响应 Body,Wasm 插件很方便地自定义处理 SSE (Server-Sent Events)等流式协议的报文。在 AI 业务等大带宽场景下,可以显著降低内存开销。
使用场景
AI 网关:
Higress 能够用统一的协议对接国内外所有 LLM 模型厂商,同时具备丰富的 AI 可观测、多模型负载均衡/fallback、AI token 流控、AI 缓存等能力。
Kubernetes Ingress 网关:
Higress 可以作为 K8s 集群的 Ingress 入口网关, 并且兼容了大量 K8s Nginx Ingress 的注解,可以从 K8s Nginx Ingress 快速平滑迁移到 Higress。
支持 Gateway API 标准,支持用户从 Ingress API 平滑迁移到 Gateway API。
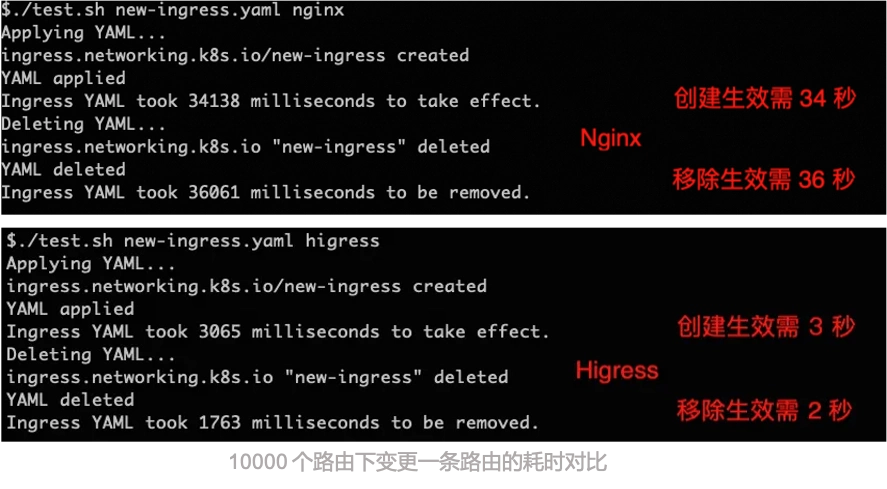
相比 ingress-nginx,资源开销大幅下降,路由变更生效速度有十倍提升:
微服务网关:
Higress 可以作为微服务网关, 能够对接多种类型的注册中心发现服务配置路由,例如 Nacos, ZooKeeper, Consul, Eureka 等。
并且深度集成了 Dubbo, Nacos, Sentinel 等微服务技术栈,基于 Envoy C++ 网关内核的出色性能,相比传统 Java 类微服务网关,可以显著降低资源使用率,减少成本。
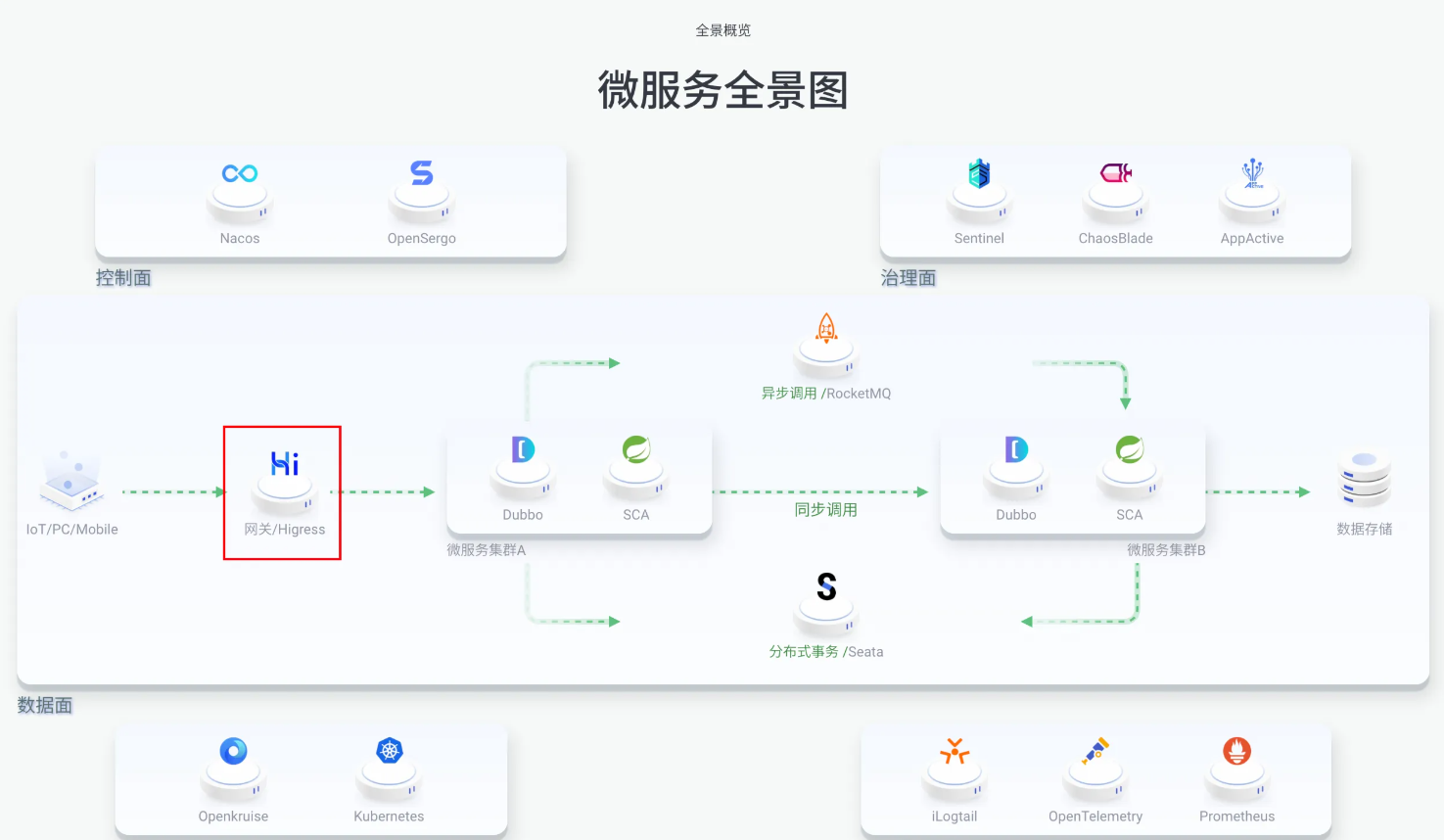
作为系统的统一入口,Higress 网关为我们提供了以下核心能力:
- 统一入口:为所有微服务提供统一的访问入口,简化客户端的调用复杂度。
- 请求路由:根据请求的路径、参数等信息,将请求路由到正确的微服务实例。
- 负载均衡:在多个服务实例之间分发请求,提高系统的可用性和性能。.
- 安全认证:统一处理身份验证、权限控制等安全相关功能。
- 限流熔断:实现请求限流、服务熔断等保护机制,防止系统过载。
- 监控日志:收集请求日志、监控指标等信息,便于系统运维和问题排查。
安全防护网关:
Higress 可以作为安全防护网关, 提供 WAF 的能力,并且支持多种认证鉴权策略,例如 key-auth, hmac-auth, jwt-auth, basic-auth, oidc 等。
Higress安装
安装要在Docker环境下,可以直接安装Docker Desktop,它会自动安装Docker和可视化管理软件。要在windows系统运行Docker需要安装WSL(Linux子系统),建议直接到Github上下载WSL安装包,或者在虚拟机上跑Docker。
安装好docker后可以在本地输入以下命令启动Higress:
docker run -d --rm --name higress-ai -v ${PWD}:/data -e O11Y=on \
-p 8001:8001 -p 8080:8080 -p 8443:8443 \
higress-registry.cn-hangzhou.cr.aliyuncs.com/higress/all-in-one:latest监听端口说明:
- 8001端口:Higress UI控制台入口
- 8080端口:网关HTTP协议入口
- 8443端口:网关HTTPS协议入口
可以用 docker ps 命令查看启动状态。
- 停止该容器的命令:
docker stop higress-ai - 下次启动该容器的命令:
docker start higress-ai
启动成功,可以在 docker desktop 中看到容器:
通过8001端口访问Higress控制台:http://localhost:8001/
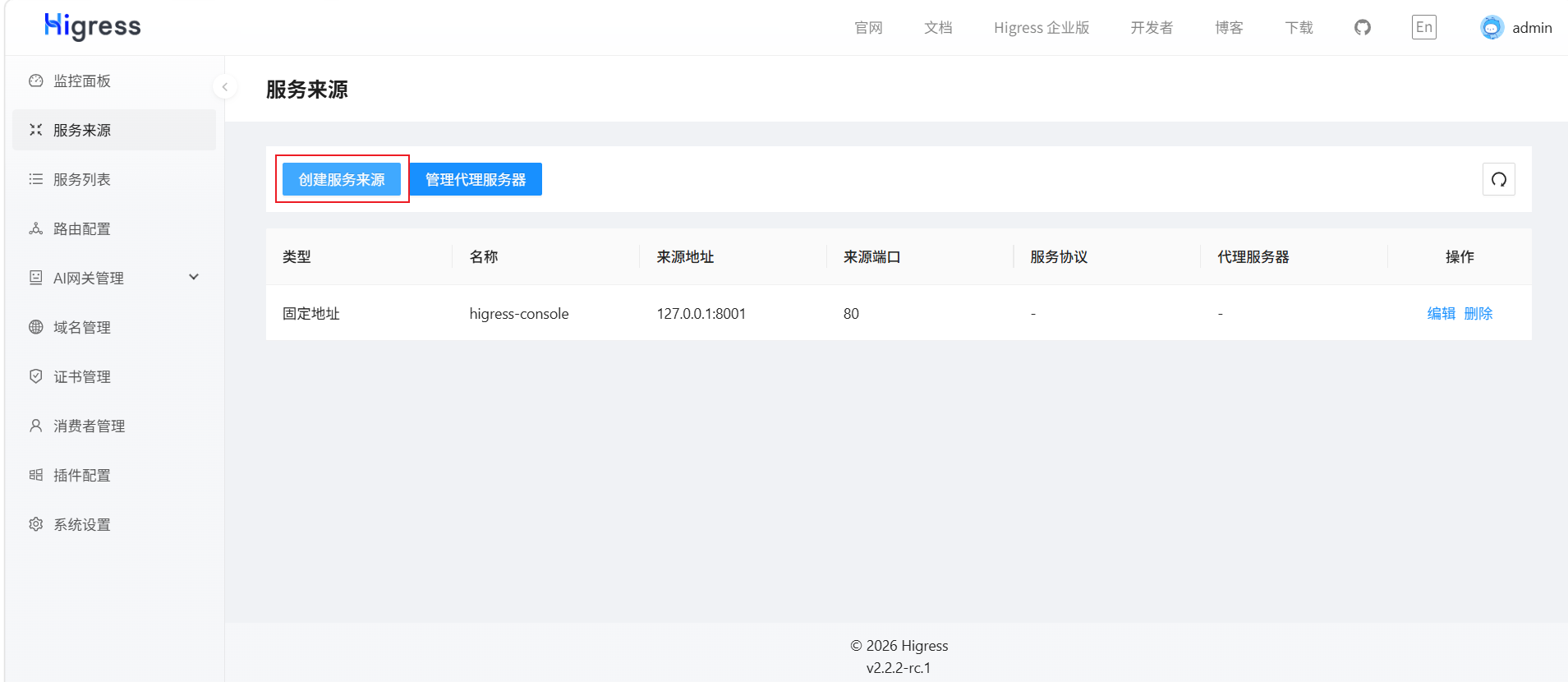
配置服务来源
注意:注册中心地址是使用我们本机的内网地址(通常是192.168.开头),而不是使用localhost或127.0.0.1,
Windows系统可以打开命令行通过如下命令进行查看,Mac系统直接在系统的网络设置中查看:
ipconfig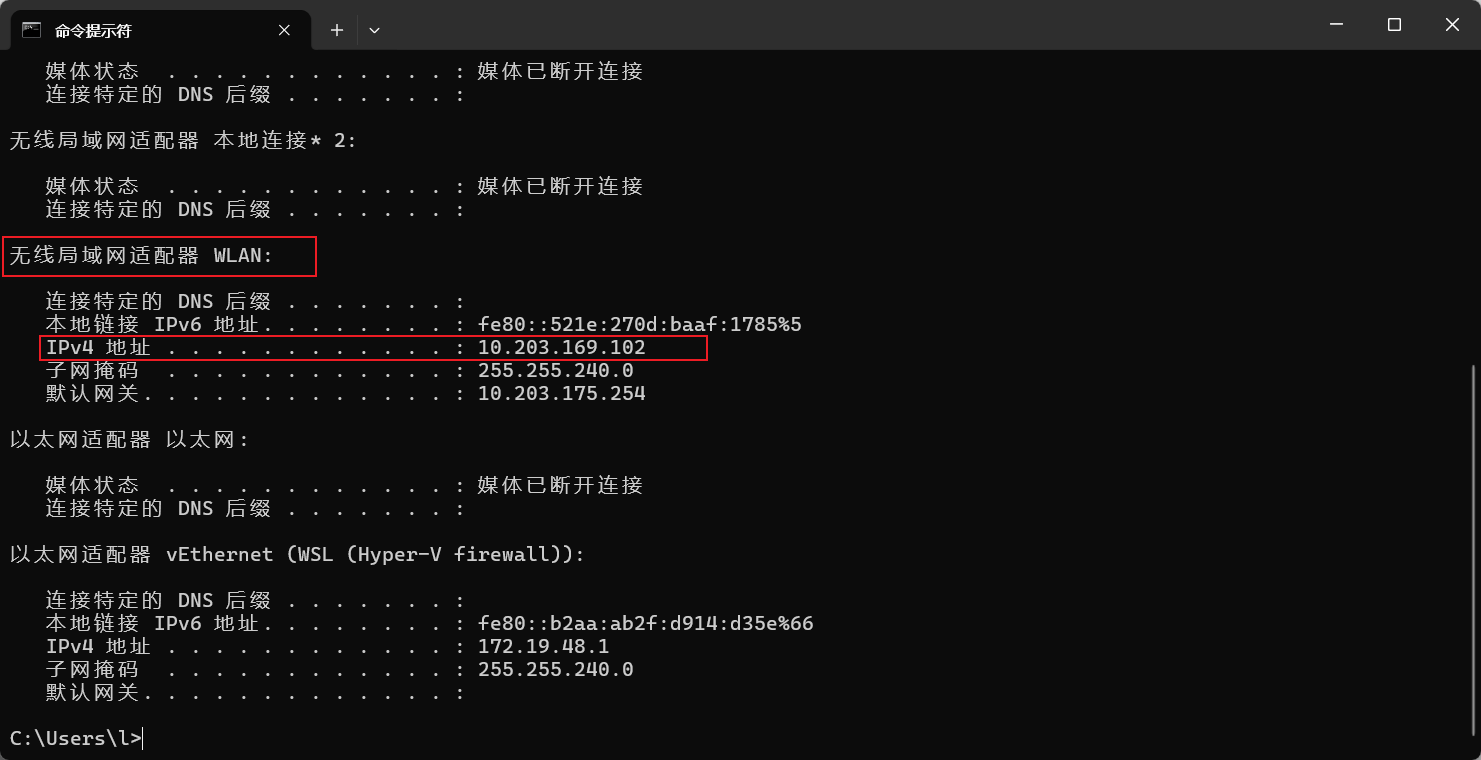
填写服务来源配置参数:
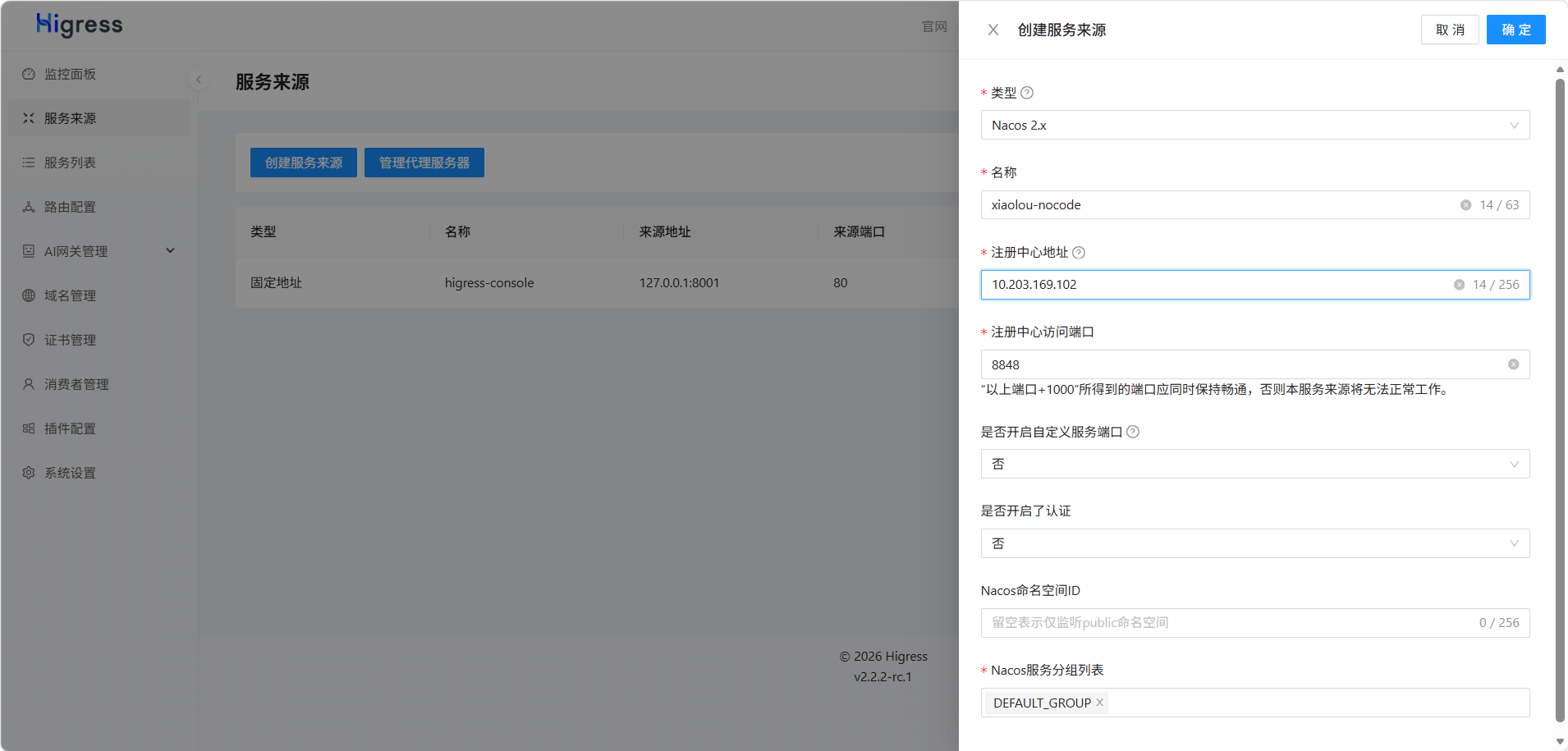
配置完成后,启动后端的微服务,Higress会自动发现所有注册在Nacos的上微服务:
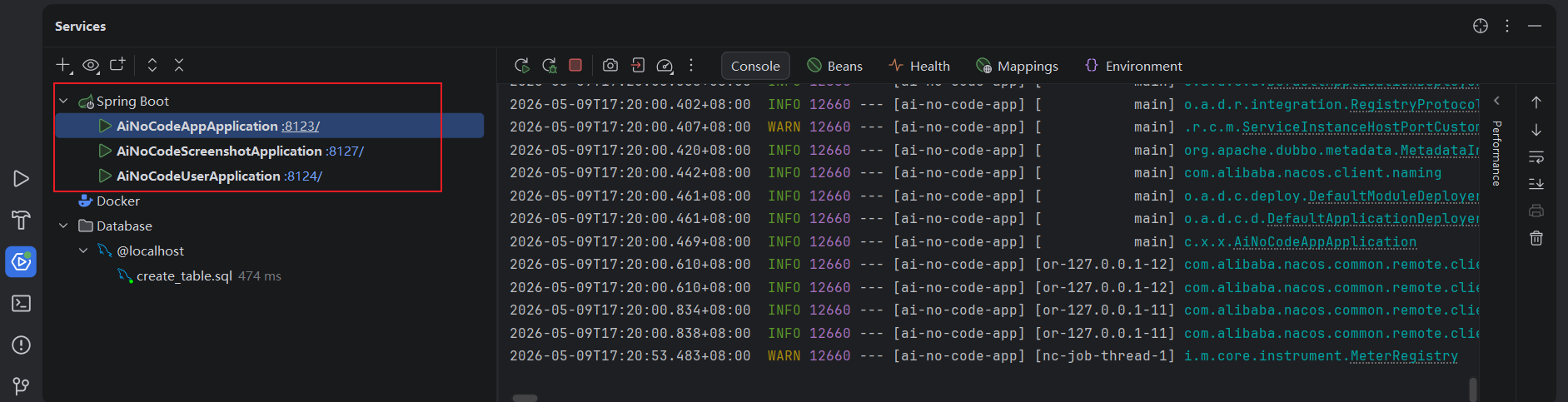
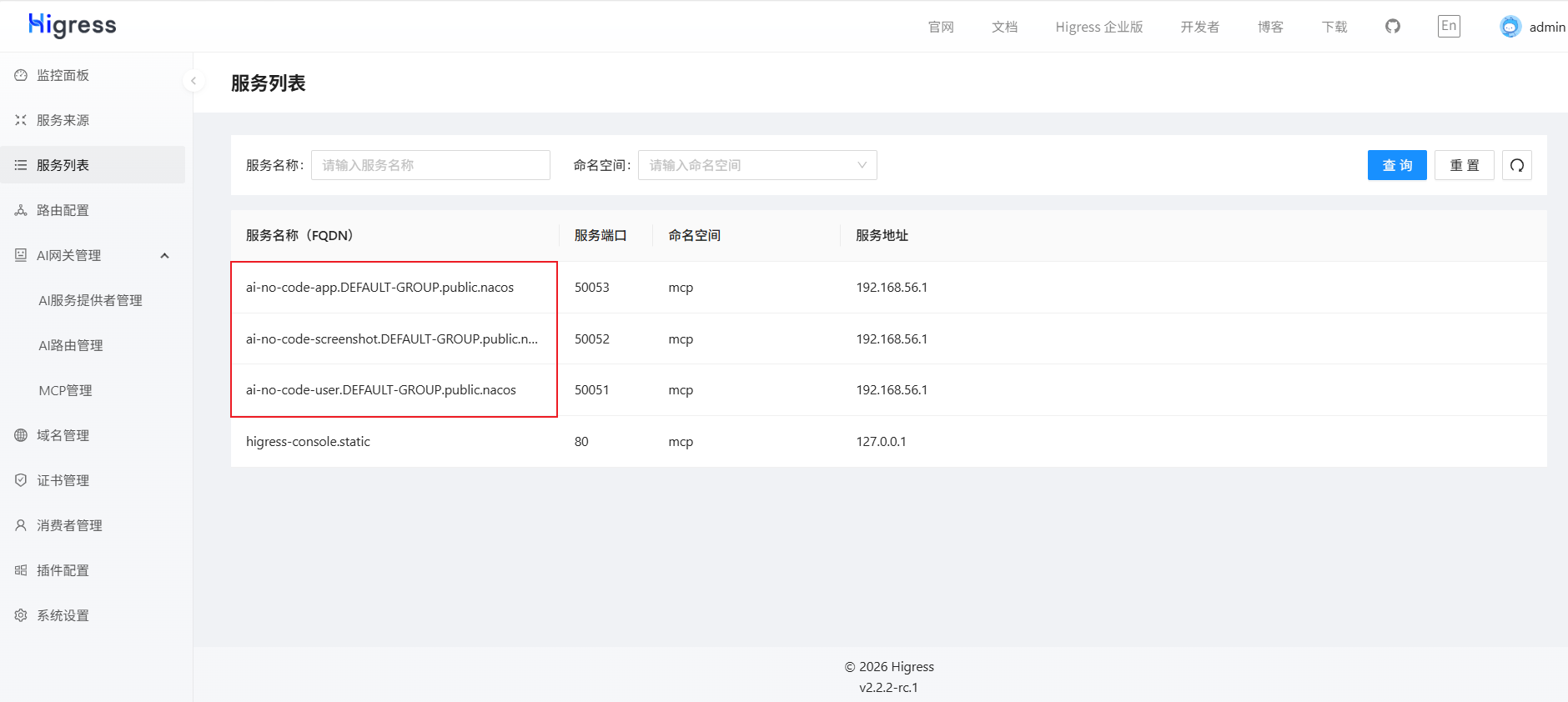
但是,由于使用的是Dubbo + Nacos,它默认是只注册Dubbo服务RPC接口,不注册HTTP接口,因此我们需要给这3个服务手动进行注册,让提供给外部的服务被发现,创建服务来源:
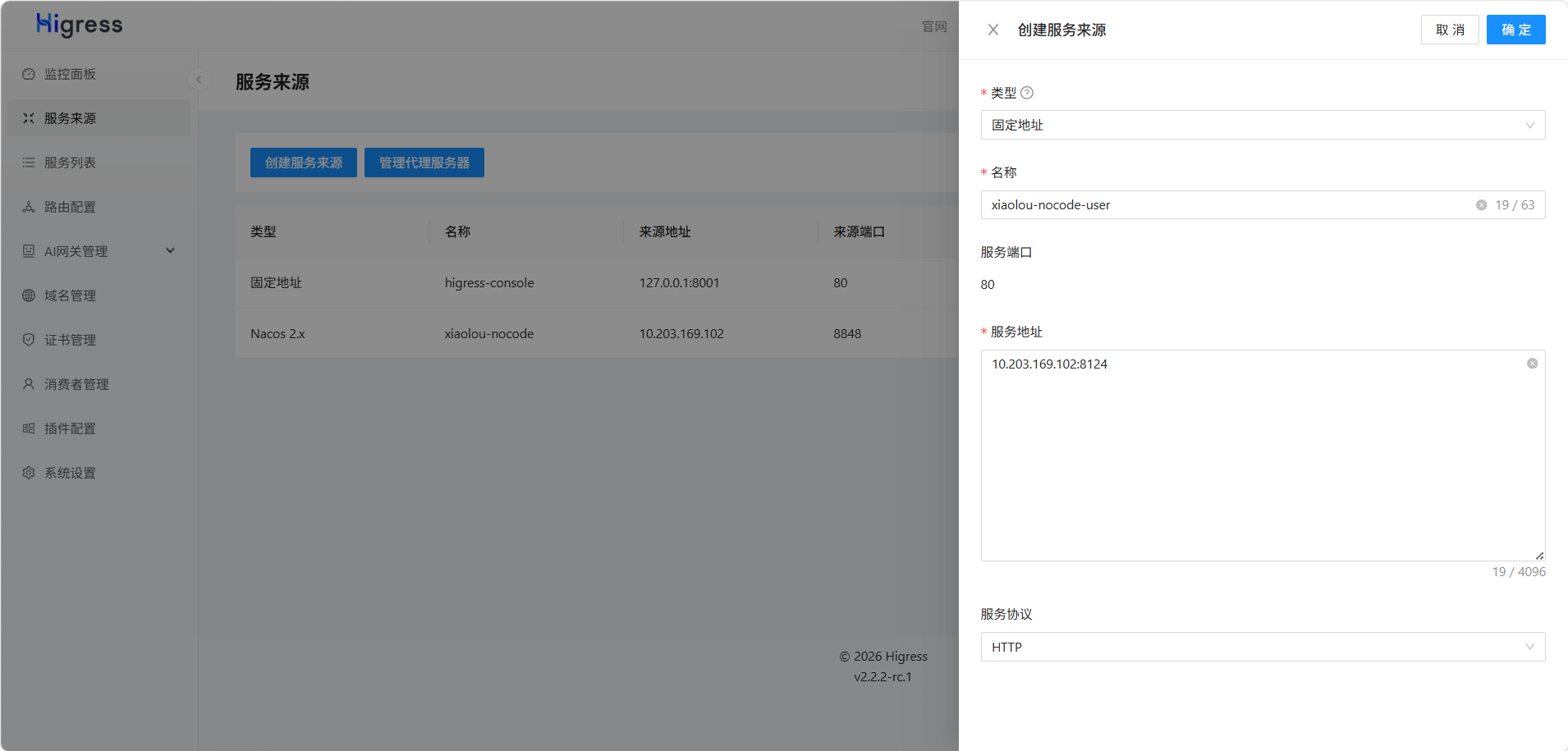
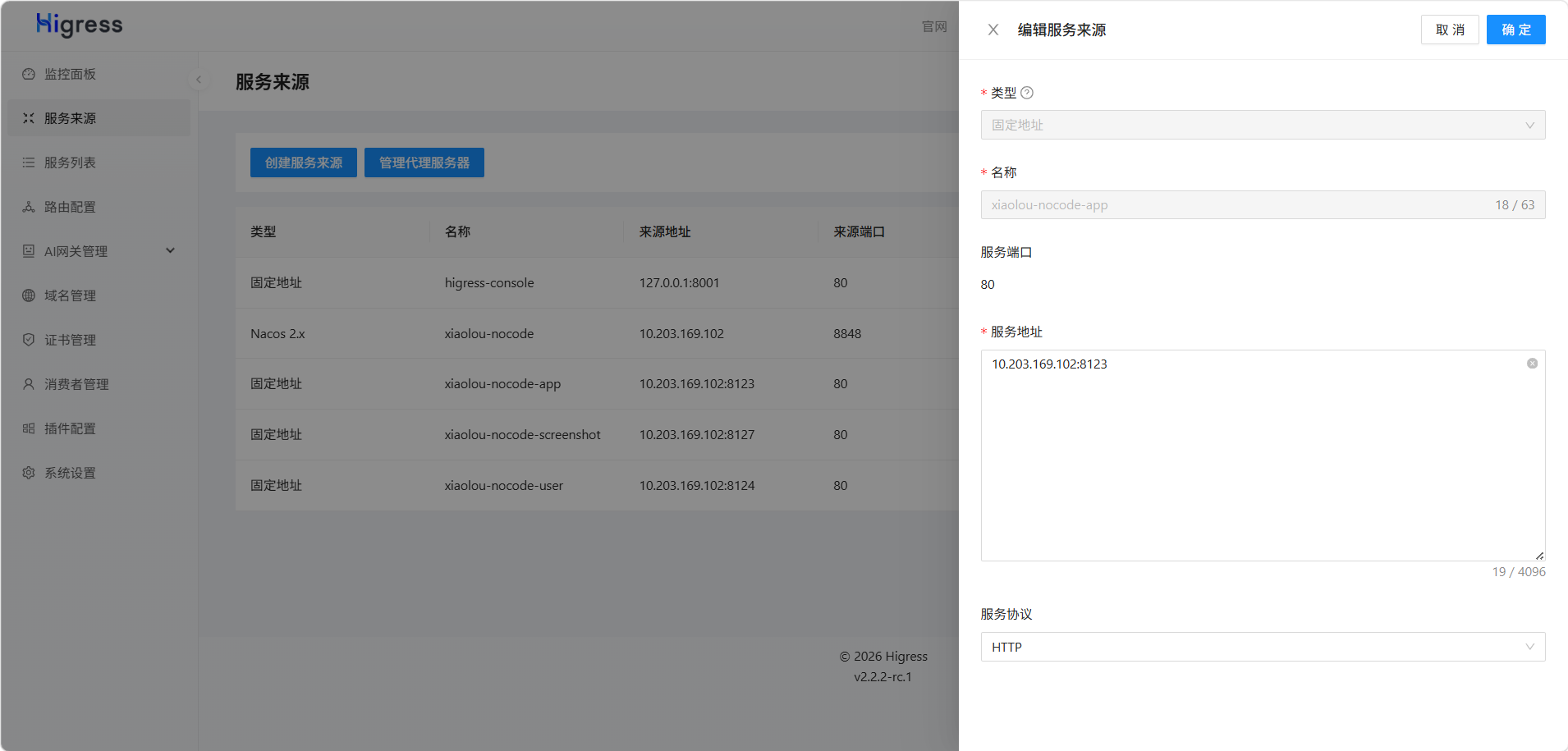
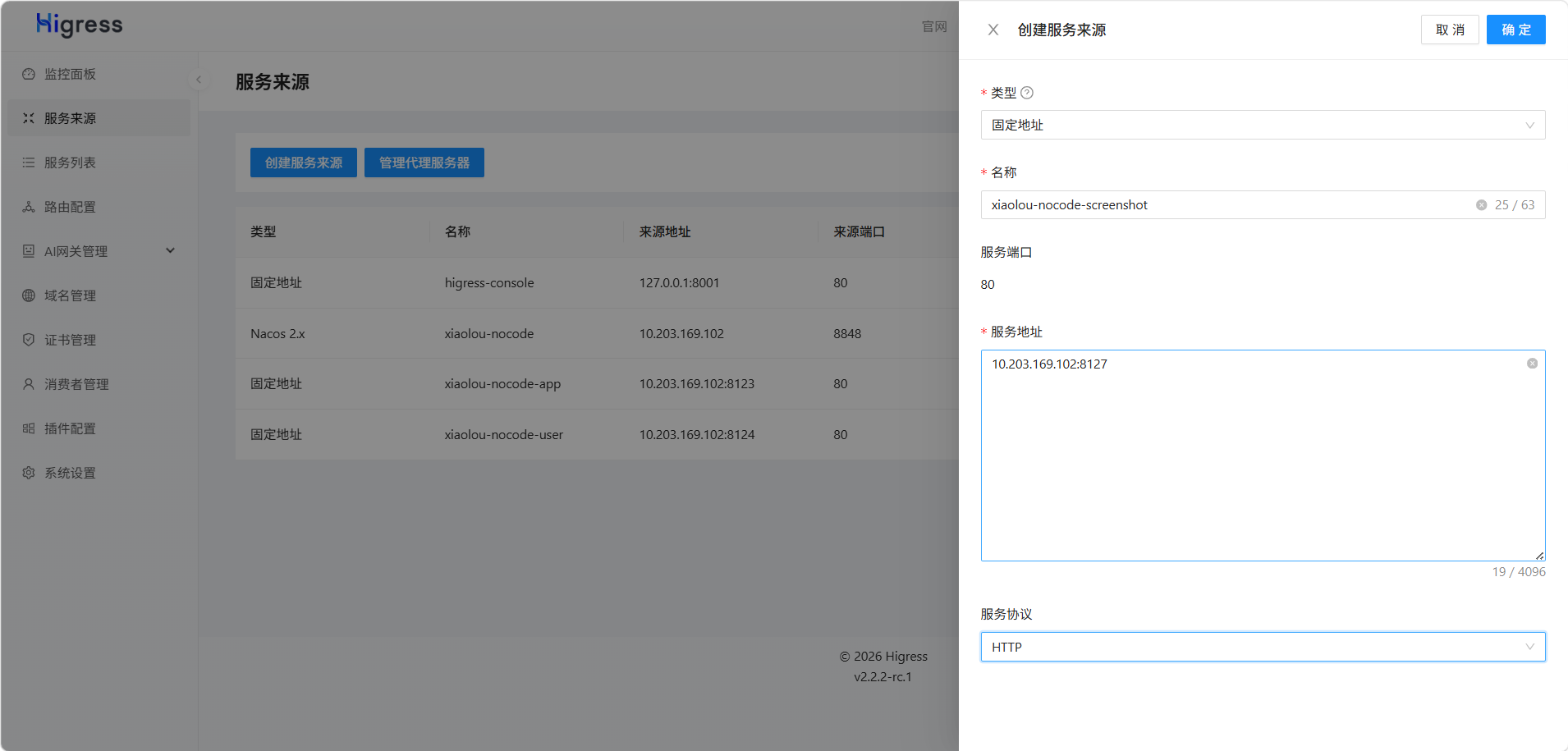
搞定:
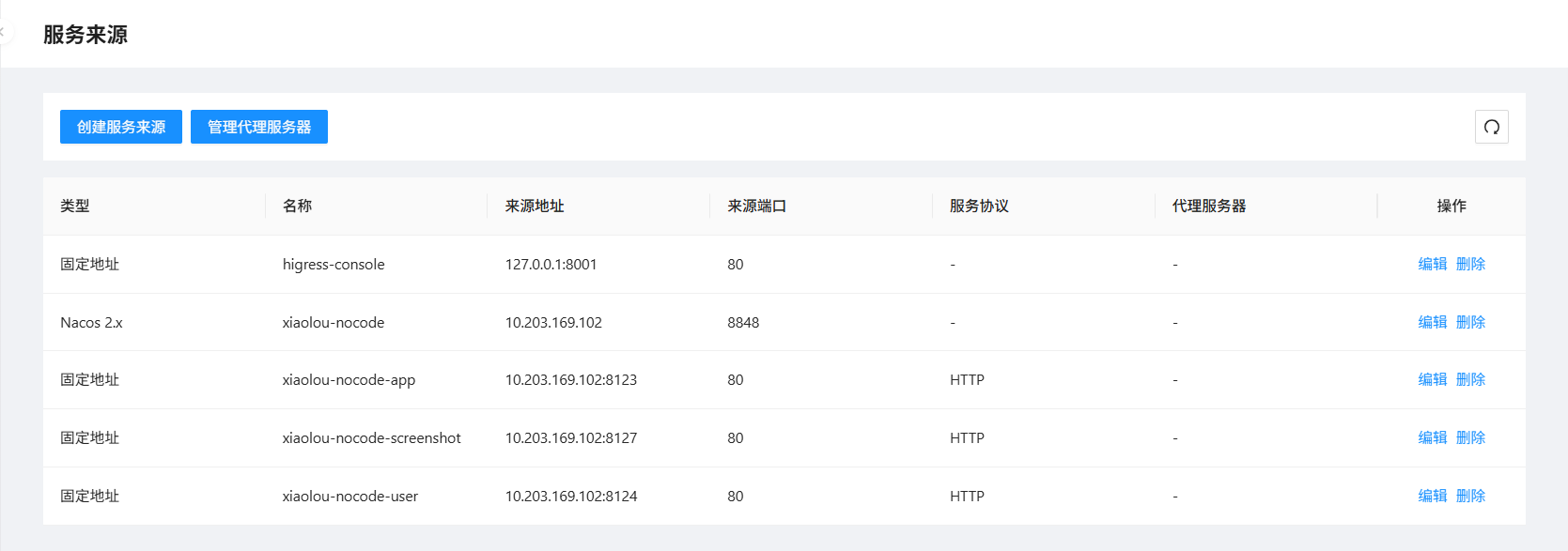
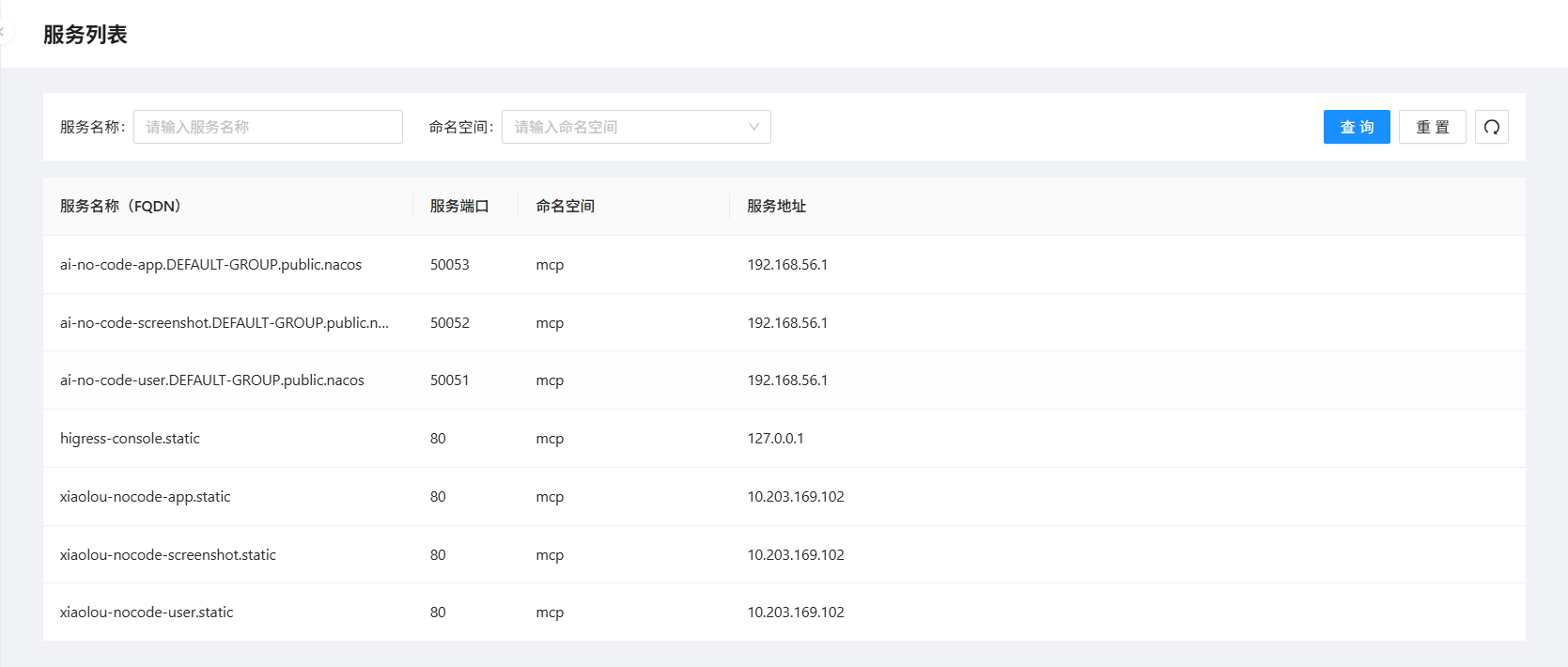
路由配置
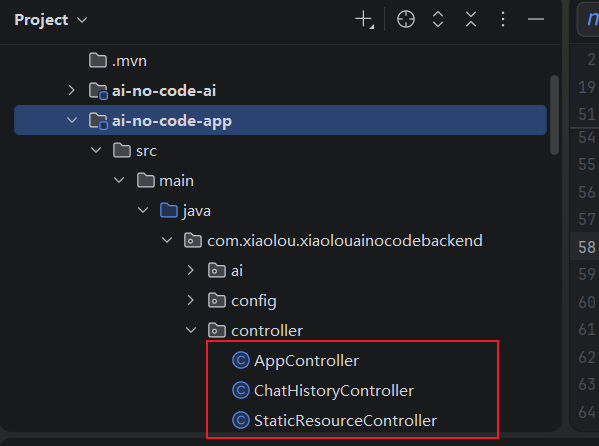
为每个有controller接口的子服务手动创建路由:
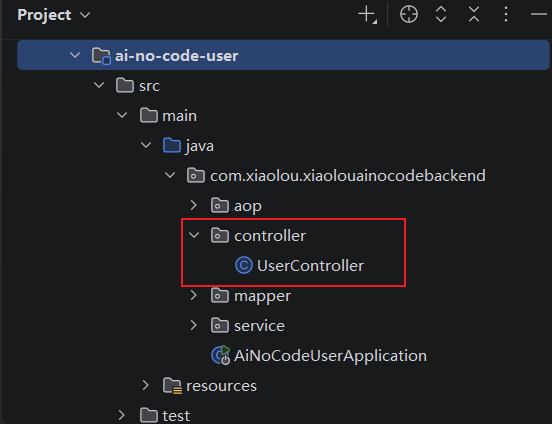
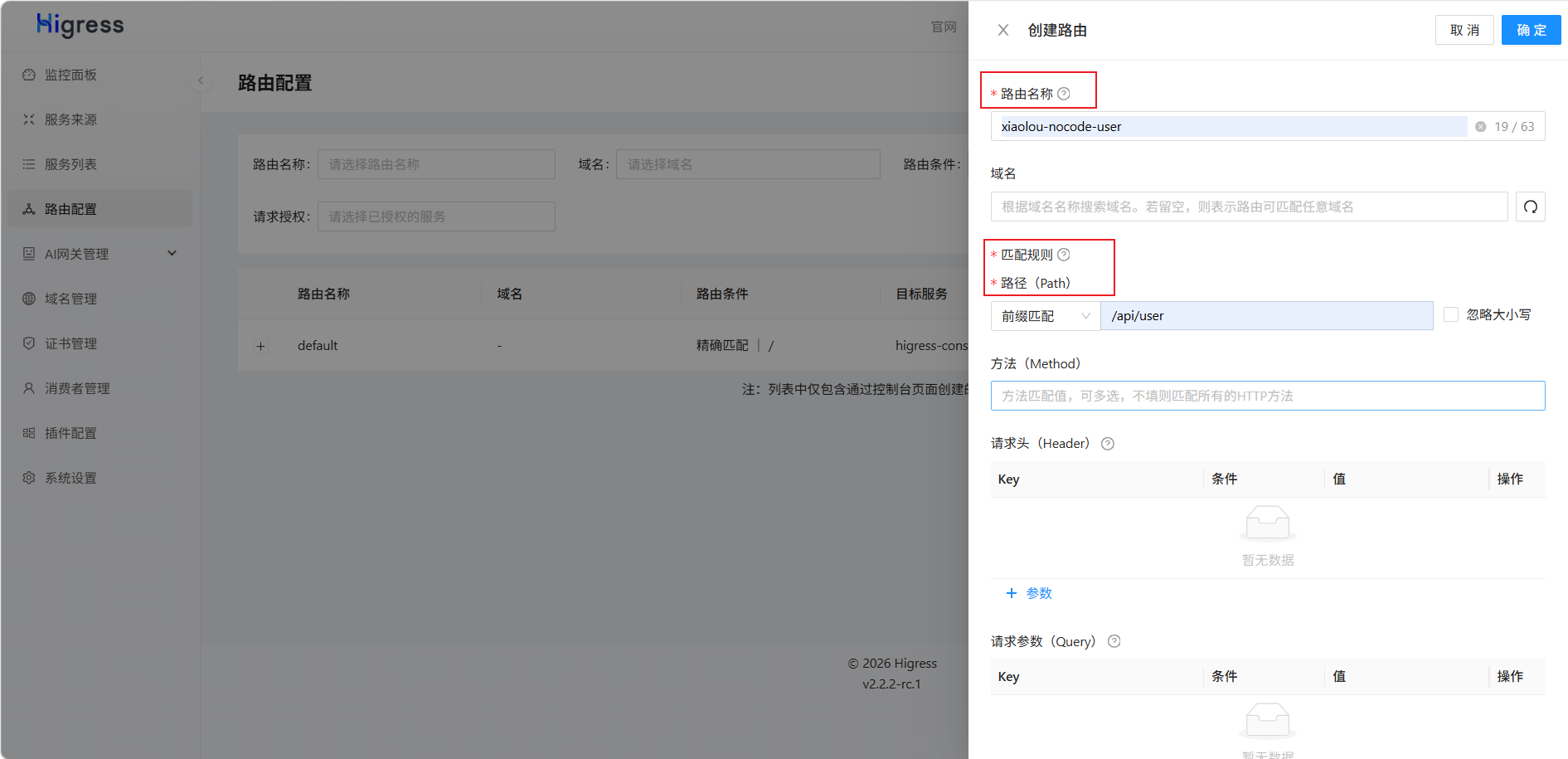
配置路由规则:
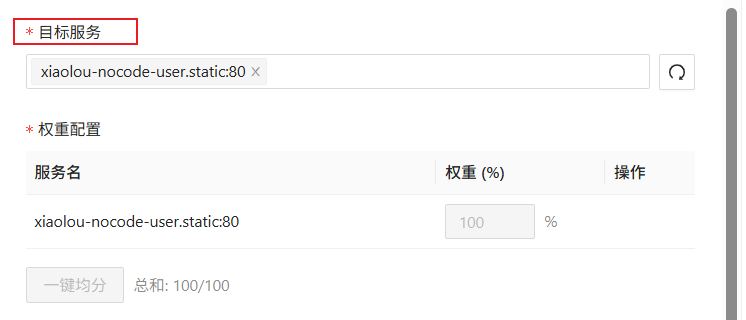
同理,把其它几个接口的路由都配置一下。
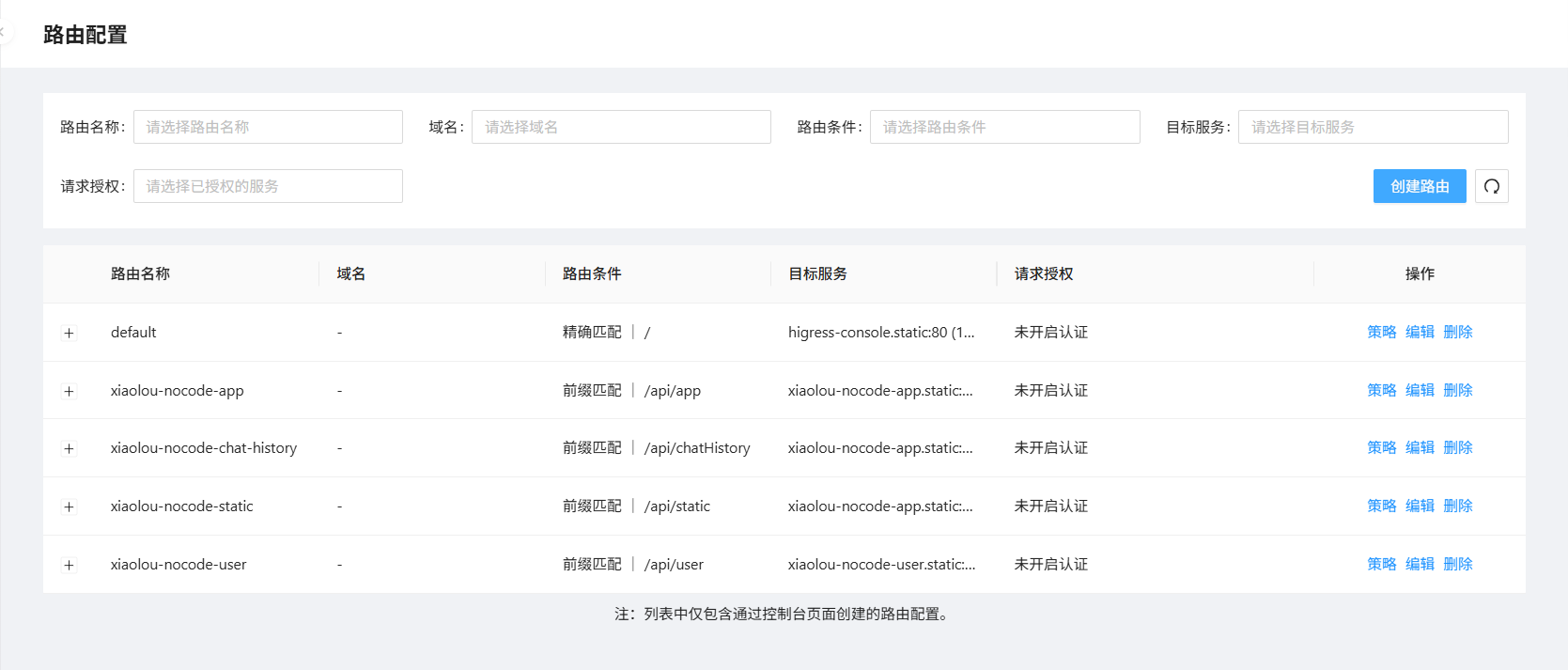
这样,前端访问我们的网关地址,就会自动转发到对应的访问,如访问localhost:8080/api/user/xxx转发到localhost:8124/api/user/xxx。
补充说明:如果你使用了Spring Cloud作为服务发现(如OpenFeign而不是Dubbo),可以参考https://nacos.io/docs/latest/ecology/use-nacos-with-spring-cloud/,来整合Nacos快速发现服务。
最后要修改一下前端代码中Vite的请求代理地址为网关地址8080端口:
最后可以进行前后端联调测试一下是否可行。
Higress插件配置
为什么需要插件?
面试官:"你们公司有 100 多个开发在调大模型 API,你怎么管?"
我不屑:"每人发一个 Key 呗,还能怎么管?"
面试官笑了笑:"那 Token 费用谁统计?有人一天烧掉 50 万 Token 怎么限流?多个模型供应商挂了怎么自动切?用户问重复问题每次都重新调模型?"
我沉默了。
面试官喝了口水,淡定地说:"用 Higress 的 AI 插件体系,一个都不少地搞定。"
今天,我就把这段时间研究 Higress 插件的成果整理出来,带你彻底看懂 Higress 插件到底能干吗、怎么干。
让它真正区别于传统 API 网关(如 Nginx、Kong)的,是它的 Wasm 插件体系。
传统网关的痛点
传统 API 网关(比如 Nginx),扩展功能基本上靠:
- Lua 脚本:性能差、调试难、容易有安全漏洞
- 自研模块:用 C 写,门槛高不说,改一次代码得重新编译整个网关,上线还要 reload(有损)
Higress 的做法完全不一样:用 Wasm(WebAssembly)写插件。
Wasm 的好处是什么?
|
特性 |
说明 |
|
沙箱隔离 |
插件挂了不会拖垮网关,内存安全 |
|
多语言 |
Go / Rust / C++ / JS 都能写,不用学新语言 |
|
热更新 |
更新插件不需要重启网关,流量无损 |
|
独立版本 |
每个插件独立构建、独立发布、独立升级 |
|
流式处理 |
天然支持处理 SSE 等流式协议 |
一句话总结:Wasm 插件 = 把网关的能力从"预定义的几个功能"变成了"你想加什么就加什么"。
Higress 插件全览:50+ 官方插件一图看懂
Higress 目前提供了 50+ 个官方内置 Wasm 插件,覆盖三大领域:
AI 网关系列
核心插件,实现"AI 一等公民"的网关能力:
|
插件名 |
一句话描述 |
|
ai-proxy |
统一协议对接 OpenAI、通义千问、百度文心、Claude 等所有 LLM 厂商 |
|
ai-cache |
AI 响应缓存,支持语义缓存和精确匹配缓存,相同问题秒返回 |
|
ai-token-ratelimit |
基于 Token 的限流,按 API Key / IP / Consumer 精确控制 Token 消耗 |
|
ai-load-balancer |
LLM 感知的负载均衡:KV Cache 亲和、vLLM Metrics、最小请求数 |
|
ai-prompt-decorator |
在请求前后注入 prompt,支持变量替换和内容脱敏 |
|
ai-prompt-template |
Prompt 模板引擎,支持参数化和模板化管理 |
|
ai-transformer |
用 LLM 来转换请求 / 响应的格式和内容 |
|
ai-statistics |
Token 用量统计,谁用了多少一目了然 |
|
ai-quota |
AI 配额管理,按时间 / 总量限制用量 |
|
ai-rag |
RAG(检索增强生成)能力,对接知识库 |
|
ai-security-guard |
AI 安全防护,检测和过滤敏感内容 |
|
ai-intent |
意图识别,自动路由到不同的后端服务 |
|
ai-json-resp |
强制 LLM 输出 JSON 格式 |
|
ai-image-reader |
图片内容识别,多模态输入处理 |
|
ai-history |
对话历史管理 |
|
ai-search |
AI 搜索集成 |
|
ai-agent |
AI Agent 编排 |
|
model-router |
模型路由,按请求特征选择不同模型 |
安全防护系列
|
插件名 |
一句话描述 |
|
waf |
Web 应用防火墙,SQL 注入、XSS 等攻击防护 |
|
bot-detect |
防爬虫和恶意机器人 |
|
request-block |
自定义 URL / 请求头 / 请求体拦截 |
|
key-auth |
基于 API Key 的认证 |
|
jwt-auth |
JWT Token 认证鉴权 |
|
hmac-auth |
HMAC 签名认证 |
|
basic-auth |
HTTP Basic 认证 |
|
oidc |
OpenID Connect 单点登录 |
|
opa |
Open Policy Agent 策略引擎 |
|
ext-auth |
对接外部认证服务 |
|
geo-ip |
根据 IP 获取地理位置信息 |
|
ip-restriction |
IP 白名单 / 黑名单 |
|
replay-protection |
防重放攻击 |
|
request-validation |
请求参数校验 |
流量管理系列
|
插件名 |
一句话描述 |
|
cors |
跨域资源共享配置 |
|
custom-response |
自定义响应 |
|
cache-control |
HTTP 缓存控制 |
|
cluster-key-rate-limit |
集群级别的 Key 限流 |
|
key-rate-limit |
单实例 Key 限流 |
|
transformer |
HTTP 请求 / 响应转换 |
|
traffic-tag |
流量打标,灰度发布 |
|
traffic-editor |
流量编辑策略 |
|
frontend-gray |
前端灰度发布 |
|
http-call |
HTTP 外部调用 |
|
mcp-router |
MCP 协议路由 |
|
mcp-server |
MCP 服务端 |
|
api-workflow |
API 工作流编排 |
|
de-graphql |
GraphQL 解构 |
|
jsonrpc-converter |
JSON-RPC 转换 |
核心 AI 插件深度拆解
光看列表不过瘾,我们挑几个最关键的上手实战。
ai-proxy:让所有 LLM 厂商都说"同一种语言"
问题:公司用了三个模型供应商——通义千问、OpenAI、Claude。每个厂商的 API 格式都不一样,改一次代码要给所有供应商都适配一遍。
ai-proxy 的解法:所有厂商统一用 OpenAI 格式调用,插件在网关上自动转换。
apiVersion: extensions.higress.io/v1alpha1
kind: WasmPlugin
metadata:
name: ai-proxy
namespace: higress-system
spec:
matchRules:
- config:
provider:
type: qwen # 后端是通义千问
apiTokens:
- "sk-your-api-token-here"
modelMapping: # 模型映射:OpenAI 名称 → 实际模型
'gpt-3': "qwen-turbo"
'gpt-35-turbo': "qwen-plus"
'gpt-4-turbo': "qwen-max"
'*': "qwen-turbo" # 兜底
ingress:
- qwen
- config:
provider:
type: openai # 第二个后端:OpenAI
apiTokens:
- "sk-your-openai-key"
ingress:
- openai
url: oci://higress-registry.cn-hangzhou.cr.aliyuncs.com/plugins/ai-proxy:1.0.0配置完成后,所有客户端统一用 OpenAI 的 /v1/chat/completions 接口,你传 gpt-4-turbo,Higress 会自动转成 qwen-max 发给通义千问。
这就是"协议统一"的力量——客户端零改动,网关帮你翻译一切。
ai-cache:相同问题别再浪费 Token
问题:用户反复问"你是谁?""今天几号?"这种高频问题,每次都要调模型,Token 哗哗地烧。
ai-cache 的解法:支持两种缓存模式——
模式一:精确匹配缓存(基于 Redis)
apiVersion: extensions.higress.io/v1alpha1
kind: WasmPlugin
metadata:
name: ai-cache
namespace: higress-system
spec:
defaultConfig:
cache:
type: redis
serviceName: redis.dns
servicePort: 6379
cacheTTL: 3600 # 缓存 1 小时
cacheKeyStrategy: "allQuestions" # 把所有历史问题拼接起来做缓存 key
url: oci://higress-registry.cn-hangzhou.cr.aliyuncs.com/plugins/ai-cache:1.0.0这个模式下,完全相同的请求直接走缓存,不调用模型。
模式二:语义缓存(基于向量数据库)
defaultConfig:
embedding:
type: dashscope # 用阿里云的 embedding 服务
apiKey: "sk-xxx"
model: "text-embedding-v2"
vector:
type: dashvector # 阿里云的向量数据库
collectionID: "your-collection-id"
apiKey: "your-key"
topK: 3 # 返回最相近的 3 个结果
threshold: 0.85 # 相似度阈值
thresholdRelation: "gt" # 大于阈值才认为是命中语义缓存比精确匹配更聪明:就算用户换个问法("你好" vs "嗨你是谁"),只要语义相近,就能命中缓存。
实际效果:某 AI 客服系统开启语义缓存后,模型调用量直降 40%,响应速度从 3 秒变成 50 毫秒。
ai-token-ratelimit:谁用超了精确到 Token
问题:运营说这个月 API 费用暴涨,但不知道是谁用超了,也不知道哪个场景消耗最大。
普通限流(QPS 限流)对 AI 场景有个致命缺陷:一次请求可能消耗 10 个 Token,也可能消耗 10000 个 Token,用 QPS 限流根本不准确。
ai-token-ratelimit 的做法:按实际消耗的 Token 数来限流。
apiVersion: extensions.higress.io/v1alpha1
kind: WasmPlugin
metadata:
name: ai-token-ratelimit
namespace: higress-system
spec:
defaultConfig:
rule_name: "default_limit_by_apikey"
rule_items:
- limit_by_param: "apikey" # 按 URL 参数 apikey 来区分用户
limit_keys:
- key: "vip-user-key"
token_per_minute: 10000 # VIP 用户每分钟 10000 Token
- key: "normal-user-key"
token_per_minute: 1000 # 普通用户每分钟 1000 Token
redis:
service_name: redis.dns
service_port: 6379
rejected_code: 429 # 被限流时返回 429
rejected_msg: '{"code":-1,"msg":"Token用量超限,请稍后再试"}'
url: oci://higress-registry.cn-hangzhou.cr.aliyuncs.com/plugins/ai-token-ratelimit:1.0.0它支持多种限流维度:
|
维度 |
说明 |
配置字段 |
|
URL 参数 |
按 |
|
|
请求头 |
按 |
|
|
IP 地址 |
按来源 IP 限流 |
|
|
Consumer |
按 Higress 的 Consumer 限流 |
|
|
Cookie |
按 Cookie 中的字段限流 |
|
|
正则批量 |
按正则匹配动态 Key 分组 |
|
而且,它需要在 ai-statistics 插件的配合下工作——插件会自动解析 LLM 的返回值,提取 usage.total_tokens,然后精确扣减。
ai-load-balancer:让 LLM 负载均衡不再"平均主义"
问题:你部署了 3 个 vLLM 实例。普通轮询算法的结果是:Pod A 处理一个耗时 10 秒的大请求,Pod B 处理一个 0.1 秒的小请求,请求还继续平均分配,Pod A 越来越堵。
Higress 提供了三种 LLM 感知的负载均衡策略:
策略一:全局最小请求数
defaultConfig:
lb_type: endpoint
lb_policy: global_least_request
lb_config:
serviceFQDN: redis.static
servicePort: 6379
username: default
password: '123456'原理:用 Redis 记录每个后端 Pod 当前正在处理的请求数,每次选择请求数最少的 Pod。比轮询聪明多了。
策略二:KV Cache 亲和
defaultConfig:
lb_type: endpoint
lb_policy: prefix_cache
lb_config:
serviceFQDN: redis.static
servicePort: 6379
username: default
password: '123456'
redisKeyTTL: 1800 # 缓存映射保留 30 分钟这是 LLM 场景的杀手级策略——它根据请求的 prompt 前缀来选择 Pod。
为什么重要?因为 LLM 推理有个特性叫 KV Cache:同一个对话的后续请求会复用前面的 KV Cache,如果能路由到同一个 Pod,响应速度能快 3-5 倍。
简单说:你第一次问"写个短故事",它去 Pod 1;你追问"再加 100 字",它还去 Pod 1,直接复用缓存,不用重新计算。
策略三:基于 vLLM Metrics
defaultConfig:
lb_type: endpoint
lb_policy: metrics_based
lb_config:
metric_policy: least # 选择指标值最小的节点
target_metric: vllm:num_requests_waiting # 看排队请求数
rate_limit: 0.6 # 单个节点最多承载 60% 的请求插件会定期拉取每个 vLLM 实例的 /metrics 接口,根据实时指标做路由决策:
vllm:num_requests_waiting:按排队请求数最少分配
vllm:num_requests_running:按正在运行的请求数最少分配
vllm:gpu_cache_usage_perc:按 GPU 缓存使用率最低分配
策略四:跨集群负载均衡
defaultConfig:
lb_type: cluster
lb_policy: cluster_metrics
lb_config:
mode: LeastFirstTokenLatency # 路由到首包 RT 最低的服务
queue_size: 100
rate_limit: 0.6
service_list:
- outbound|80||llm-svc-1.dns
- outbound|80||llm-svc-2.static支持三种模式:
LeastBusy:路由到并发请求最少的服务
LeastTotalLatency:路由到总 RT 最低的服务
LeastFirstTokenLatency:路由到首包延迟最低的服务(对 TTFB 敏感的场景非常有用)
ai-prompt-decorator:不写代码就能注入和优化 Prompt
问题:法务要求所有 AI 输出必须加上免责声明,产品要求统一用英文回答,但前端团队说"改不动了"。
ai-prompt-decorator 的解法:
defaultConfig:
prepend: # 在请求前插入
- role: system
content: "请使用英语回答问题"
append: # 在请求后追加
- role: user
content: "每次回答完问题,尝试进行反问"
replace: # 内容替换
- pattern: "竞品A" # 品牌词归一
replacement: "优秀的行业解决方案"
- pattern: "1[3-9]\\d{9}" # 手机号脱敏
replacement: "[手机号已隐藏]"
regex: true
- pattern: "sk-[A-Za-z0-9]+" # API Key 脱敏
replacement: "[APIKEY已隐藏]"
regex: true
url: oci://higress-registry.cn-hangzhou.cr.aliyuncs.com/plugins/ai-prompt-decorator:1.0.0这样,原始请求:
{"role": "user", "content": "你是谁?"} 经过插件处理后变成:
[
{"role": "system", "content": "请使用英语回答问题"},
{"role": "user", "content": "你是谁?"},
{"role": "user", "content": "每次回答完问题,尝试进行反问"}
]还能和 geo-ip 插件联动,自动注入用户地理位置:
prepend:
- role: system
content: "提问用户当前地理位置:国家=${geo-country},省份=${geo-province},城市=${geo-city}"用户问"今天天气怎么样?",模型就自动知道他在哪个城市,直接给出准确的天气。
ai-transformer:用 AI 来改造 AI
问题:后端接口返回的是 XML,但客户端只接受 JSON。你又要写一套转换逻辑。
ai-transformer 的解法:让 LLM 来干格式转换,你只需要用自然语言描述需求。
defaultConfig:
request:
enable: false # 不改请求
response:
enable: true
prompt: "帮我修改以下 HTTP 应答:1. content-type 改为 application/json;2. body 从 XML 转为 JSON;3. 移除 content-length。"
provider:
serviceName: qwen.dns
domain: dashscope.aliyuncs.com
apiKey: "sk-xxx"
url: oci://higress-registry.cn-hangzhou.cr.aliyuncs.com/plugins/ai-transformer:1.0.0请求变 XML → 响应变 JSON,中间全是 AI 自动转换,你一行代码都不用写。
插件怎么用?从入门到精通
部署方式:一行 Yaml 搞定
Higress 插件通过 WasmPlugin CRD 来声明和部署:
apiVersion: extensions.higress.io/v1alpha1
kind: WasmPlugin
metadata:
name: my-plugin # 插件实例名
namespace: higress-system
spec:
defaultConfig: # 全局默认配置
some_key: some_value
matchRules: # 细粒度匹配规则(可选)
- ingress: # 按路由匹配
- default/my-ingress
config: # 该路由专有配置
some_key: special_value
- domain: # 按域名匹配
- "*.example.com"
config:
some_key: domain_value
url: oci://higress-registry.cn-hangzhou.cr.aliyuncs.com/plugins/<plugin-name>:<version>
phase: AUTHN_PHASE # 执行阶段(可选)
priority: 100 # 执行优先级(可选)核心机制:matchRules
- 支持按 Ingress 名称(路由级)和 域名 匹配
- 规则按顺序匹配,命中第一个后停止
- 没命中任何规则时,使用
defaultConfig
- 不同路由可以用同一个插件的不同配置
执行阶段与优先级
插件有明确的执行阶段:
|
阶段 |
说明 |
典型应用 |
|
|
认证阶段 |
jwt-auth、key-auth,在这里拒绝未认证请求 |
|
|
鉴权阶段 |
opa、ext-auth,验证权限 |
|
|
默认阶段 |
大多数业务插件 |
在 同一阶段内,插件按 priority 排序执行。数字越小越先执行。
举个例子:
AUTHN_PHASE:
ai-cache (priority=10) # 先检查缓存,命中了直接返回
jwt-auth (priority=100) # 再验证身份
UNSPECIFIED_PHASE:
geo-ip (priority=1000) # 先获取地理位置
ai-prompt-decorator (priority=450) # 再注入地理信息到 prompt
ai-token-ratelimit (priority=600) # Token 限流插件镜像生态
所有官方插件都托管在阿里云的镜像仓库:
higress-registry.cn-hangzhou.cr.aliyuncs.com/plugins/<plugin-name>:<version>例如:
ai-proxy:1.0.0
ai-cache:1.0.0
jwt-auth:2.0.0
waf:1.0.0
插件版本独立管理,升级一个插件不影响其他插件运行。
如何自己写插件?
当你发现 50+ 个官方插件还不够用时,Higress 支持你用 Go 自己写。
五分钟开发一个 Wasm 插件
环境要求:Go >= 1.24(支持 wasm 编译)
第一步:在正确的目录创建插件
把代码放到 plugins/wasm-go/extensions/<your-plugin-name>/
第二步:写插件逻辑
package main
import (
"github.com/higress-group/wasm-go/pkg/wrapper"
"github.com/tetratelabs/proxy-wasm-go-sdk/proxywasm"
"github.com/tetratelabs/proxy-wasm-go-sdk/proxywasm/types"
)
func main() {
wrapper.SetCtx(
// 插件启动时的高阶配置
"my-plugin",
wrapper.ParseConfigBy(parseConfig),
wrapper.ProcessRequestHeadersBy(onHttpRequestHeaders),
)
}
func parseConfig(json gjson.Result, config *MyConfig, log wrapper.Log) error {
// 解析你的插件配置
return nil
}
func onHttpRequestHeaders(ctx wrapper.HttpContext, config MyConfig) types.Action {
// 插件逻辑:修改请求头、限流、认证...
return types.ActionContinue
}第三步:构建插件
PLUGIN_NAME=my-plugin make build构建完成,产物就绪:
extensions/my-plugin/plugin.wasm→ Wasm 二进制
my-plugin:latest→ Docker 镜像
第四步:推送到镜像仓库,像使用官方插件一样引用
spec:
url: oci://your-registry/my-plugin:1.0.0插件单元测试
Higress 提供了完整的 Wasm 插件测试框架:
func TestMyPlugin(t *testing.T) {
test.RunTest(t, func(t *testing.T) {
// 1. 创建测试环境
config := json.RawMessage(`{"key": "value"}`)
host, status := test.NewTestHost(config)
require.Equal(t, types.OnPluginStartStatusOK, status)
defer host.Reset()
// 2. 模拟请求头
headers := [][2]string{
{":method", "GET"},
{":path", "/test"},
{":authority", "test.com"},
}
// 3. 调用插件逻辑
action := host.CallOnHttpRequestHeaders(headers)
require.Equal(t, types.ActionContinue, action)
// 4. 验证返回
host.CompleteHttp()
localResponse := host.GetLocalResponse()
assert.Equal(t, uint32(200), localResponse.StatusCode)
})
}开发 AI 插件的注意事项
- 流式处理:AI 响应大多是流式的(SSE),插件需要正确处理
OnHttpResponseBody的分帧
- Header 状态管理:如果在请求头阶段做了异步调用(如调用外部 API),需要
ActionPause等待结果
- 性能:Wasm 插件运行在 Envoy 沙箱中,避免在热路径上做重量级计算
实战:搭一套完整的 AI 网关
说了这么多,我们来实际搭一个"AI 全家桶"——
目标:客户端统一调 OpenAI 格式接口,网关自动路由到通义千问,同时提供缓存、限流、负载均衡、Prompt 注入、安全审计。
整体架构
graph LR
A[客户端 OpenAI SDK] -->|/v1/chat/completions| B[Higress AI 网关]
B -->|ai-cache 缓存检查| C{缓存命中?}
C -->|命中| D[直接返回缓存结果]
C -->|未命中| E[ai-prompt-decorator 注入 Prompt]
E --> F[ai-token-ratelimit Token 限流]
F --> G[ai-load-balancer 负载均衡]
G --> H1[通义千问实例1]
G --> H2[通义千问实例2]
G --> H3[通义千问实例3]
Yaml 配置
# 1. ai-cache:语义缓存,相同问题秒返回
apiVersion: extensions.higress.io/v1alpha1
kind: WasmPlugin
metadata:
name: ai-cache
namespace: higress-system
spec:
defaultConfig:
cacheKeyStrategy: "lastQuestion"
embedding:
type: dashscope
apiKey: "sk-xxx"
model: "text-embedding-v2"
vector:
type: dashvector
collectionID: "your-collection-id"
apiKey: "your-key"
topK: 1
threshold: 0.85
thresholdRelation: "gt"
cache:
type: redis
serviceName: redis.dns
servicePort: 6379
cacheTTL: 3600
url: oci://higress-registry.cn-hangzhou.cr.aliyuncs.com/plugins/ai-cache:1.0.0
phase: AUTHN_PHASE
priority: 10
---
# 2. ai-prompt-decorator:注入安全生产 Prompt
apiVersion: extensions.higress.io/v1alpha1
kind: WasmPlugin
metadata:
name: ai-prompt-decorator
namespace: higress-system
spec:
defaultConfig:
prepend:
- role: system
content: "你是一个专业的AI助手。回答要求:1. 内容准确、客观;2. 不提供医疗、法律建议;3. 遇到不确定的问题请如实告知。"
replace:
- pattern: "1[3-9]\\d{9}"
replacement: "[手机号]"
regex: true
url: oci://higress-registry.cn-hangzhou.cr.aliyuncs.com/plugins/ai-prompt-decorator:1.0.0
phase: UNSPECIFIED_PHASE
priority: 450
---
# 3. ai-token-ratelimit:按 API Key 精确限流
apiVersion: extensions.higress.io/v1alpha1
kind: WasmPlugin
metadata:
name: ai-token-ratelimit
namespace: higress-system
spec:
defaultConfig:
rule_name: "api-token-limit"
rule_items:
- limit_by_per_param: "apikey"
limit_keys:
- key: "regexp:^vip-.*"
token_per_hour: 100000
- key: "regexp:^free-.*"
token_per_day: 10000
- key: "*"
token_per_minute: 500
redis:
service_name: redis.dns
service_port: 6379
rejected_code: 429
rejected_msg: '{"error":"token_limit_exceeded","message":"Token用量超限"}'
url: oci://higress-registry.cn-hangzhou.cr.aliyuncs.com/plugins/ai-token-ratelimit:1.0.0
priority: 600
---
# 4. ai-load-balancer:LLM 感知的负载均衡
apiVersion: extensions.higress.io/v1alpha1
kind: WasmPlugin
metadata:
name: ai-load-balancer
namespace: higress-system
spec:
defaultConfig:
lb_type: endpoint
lb_policy: prefix_cache # KV Cache 亲和路由
lb_config:
serviceFQDN: redis.static
servicePort: 6379
username: default
password: '123456'
redisKeyTTL: 1800
url: oci://higress-registry.cn-hangzhou.cr.aliyuncs.com/plugins/ai-load-balancer:1.0.0
priority: 500
---
# 5. ai-proxy:协议统一
apiVersion: extensions.higress.io/v1alpha1
kind: WasmPlugin
metadata:
name: ai-proxy
namespace: higress-system
spec:
matchRules:
- config:
provider:
type: qwen
apiTokens:
- "sk-your-qwen-token"
modelMapping:
'gpt-3': "qwen-turbo"
'gpt-35-turbo': "qwen-plus"
'gpt-4-turbo': "qwen-max"
'*': "qwen-turbo"
ingress:
- qwen
url: oci://higress-registry.cn-hangzhou.cr.aliyuncs.com/plugins/ai-proxy:1.0.0
phase: UNSPECIFIED_PHASE
priority: 100效果对比
|
维度 |
方案一:直接调 API |
方案二:Higress AI 全家桶 |
|
客户端代码 |
需适配各厂商 API |
OpenAI 格式一把梭 |
|
相同问题 |
每次都调模型 |
走缓存,50ms 响应 |
|
Token 管控 |
月末看账单再震惊 |
实时限流,超过自动拒绝 |
|
长对话延迟 |
每次重新计算 |
KV Cache 亲和,快 3-5 倍 |
|
安全合规 |
前端实现,各地不一致 |
网关统一注入和脱敏 |
|
费用审计 |
Excel 手工统计 |
ai-statistics 自动统计每人用了多少 |
总结
Higress 的插件体系,我最大的感受就三点:
Wasm 插件的实用性
以前扩网关功能要 Lua 或者改源码,现在是 Go 写、沙箱跑、热更新。性能不说,安全性和可维护性完全不是一个量级。
AI 网关不是噱头,是真需求
AI 场景的特有问题太多了——流式处理、Token 计费、多模型统一、KV Cache 路由、Prompt 管理、安全审计……这些传统网关要么做不到,要么做得很别扭。Higress 把它做成了"一等公民",插件体系就是它的武器库。
插件组合才是真正的力量
单个插件解决单个问题,但 5 个插件串在一起,就形成了流水线:
用户请求 → 缓存检查 → Prompt 注入 → Token 限流 → 负载均衡 → LLM 推理 → 统计上报这个流水线,就是你的 AI 基础设施层——业务代码完全不感知,全部在网关上搞定。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 24
24 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)