SpringAI(二)Models 模型介绍
Chat Models
Spring AI 的 Chat Model API 提供一套统一接口,方便开发者在应用中集成 AI 聊天完成功能。它支持切换不同厂商的聊天模型,如 OpenAI、Anthropic、Google Gemini、Amazon Bedrock、Ollama 等,多数实现支持流式输出和函数调用等功能。
如下以Deepseek模型为例,演示ChatModel相关功能,更多模型的使用方式参考:https://docs.spring.io/spring-ai/reference/api/chatmodel.html
基本聊天
参考Spring AI快速上手案例部分。核心代码如下:
@GetMapping("/generate")
public String generate(@RequestParam(value = "message", defaultValue = "给我讲个笑话") String message) {
System.out.println("收到消息:"+message);
String result = chatModel.call(message);
//模型返回的内容
System.out.println(result);
return result;
}
Stream流式聊天
Spring AI中使用对话模型时,也支持流式聊天。以Deepseek为例,在“SpringAIQuickStart”项目的“/controller/ChatController.java”代码中准备如下方法:
//流式获取模型返回的内容,获取返回的 ChatResponse 对象内容
@GetMapping("/generateStream1")
public Flux<ChatResponse> generateStream1(@RequestParam(value = "message", defaultValue = "给我讲个笑话") String message) {
System.out.println("收到消息:"+message);
var prompt = new Prompt(new UserMessage(message));
return chatModel.stream(prompt);
}
//流式获取模型返回的内容,获取返回的 Text 内容
@GetMapping("/generateStream2")
public Flux<String> generateStream2(
@RequestParam(value = "message", defaultValue = "给我讲个笑话") String message,
HttpServletResponse response) {
// 避免返回乱码
response.setCharacterEncoding("UTF-8");
System.out.println("收到消息:"+message);
var prompt = new Prompt(new UserMessage(message));
Flux<String> result = chatModel.stream(prompt)
.map(chatResponse -> chatResponse.getResult().getOutput().getText());
return result;
}
以上代码中注意如下几点:
- “generateStream1”方法返回Flux<ChatResponse>对象,Flux<T>表示“0到N个元素”的异步数据流,用于模型返回异步数据的输出。
- ChatResponse对象内容如下:
[
{
"result":{
"metadata":{"finishReason":"","contentFilters":[],"empty":true},
"output":{"messageType":"ASSISTANT","metadata":{"finishReason":"","id":"e392c615-9d42-4a8f-a819-1640cd3a7d68","role":"ASSISTANT","messageType":"ASSISTANT"},"toolCalls":[],"media":[],"prefix":null,"reasoningContent":null,"text":""}},
"metadata":{"id":"e392c615-9d42-4a8f-a819-1640cd3a7d68","model":"deepseek-chat","rateLimit":{"requestsRemaining":0,"requestsReset":"PT0S","requestsLimit":0,"tokensReset":"PT0S","tokensRemaining":0,"tokensLimit":0},"usage":{"completionTokens":0,"promptTokens":0,"nativeUsage":{},"totalTokens":0},"promptMetadata":[],"empty":false},
"results":[{"metadata":{"finishReason":"","contentFilters":[],"empty":true},"output":{"messageType":"ASSISTANT","metadata":{"finishReason":"","id":"e392c615-9d42-4a8f-a819-1640cd3a7d68","role":"ASSISTANT","messageType":"ASSISTANT"},"toolCalls":[],"media":[],"prefix":null,"reasoningContent":null,"text":""}}]
},
{
"result":{"metadata":{"finishReason":"","contentFilters":[],"empty":true},"output":{"messageType":"ASSISTANT","metadata":{"finishReason":"","id":"e392c615-9d42-4a8f-a819-1640cd3a7d68","role":"ASSISTANT","messageType":"ASSISTANT"},"toolCalls":[],"media":[],"prefix":null,"reasoningContent":null,"text":"好的"}},
"metadata":{"id":"e392c615-9d42-4a8f-a819-1640cd3a7d68","model":"deepseek-chat","rateLimit":{"requestsRemaining":0,"requestsReset":"PT0S","requestsLimit":0,"tokensReset":"PT0S","tokensRemaining":0,"tokensLimit":0},"usage":{"completionTokens":0,"promptTokens":0,"nativeUsage":{},"totalTokens":0},"promptMetadata":[],"empty":false},
"results":[{"metadata":{"finishReason":"","contentFilters":[],"empty":true},"output":{"messageType":"ASSISTANT","metadata":{"finishReason":"","id":"e392c615-9d42-4a8f-a819-1640cd3a7d68","role":"ASSISTANT","messageType":"ASSISTANT"},"toolCalls":[],"media":[],"prefix":null,"reasoningContent":null,"text":"好的"}}]
},
....
]
- generateStream2方法返回Flux<String>对象,这里获取ChatResponse对象中模型返回的text内容。
- 启动项目后,可以在浏览器输入“http://localhost:8080/ai/generateStream2?message=你是谁”查看模型Stream流式返回结果。
运行时参数设置
Spring AI 使用模型时,可以通过项目中application.properties配置文件来设置关于模型的全局默认参数,示例如下:
spring.ai.openai.base-url: https://api.deepseek.com
spring.ai.openai.api-key: ${DEEPSEEK_API_KEY}
spring.ai.openai.chat.options.model: deepseek-chat
spring.ai.openai.chat.options.temperature: 0.7
... ...
对于一些请求可能需要不同的行为参数,例如:模型回复更高的随机性,这时候就需要在项目运行时进行参数覆盖,这就是Spring AI的运行时参数设置。
在运行时设置参数时,可以在调用模型时,创建一个prompt,并嵌入一个新的DeepSeekChatOptions 来覆盖启动配置。
在“SpringAIQuickStart”项目的“/controller/ChatController.java”代码中准备如下方法:
@GetMapping("/runtimeOptions")
public String runtimeOptions(
@RequestParam(value = "message") String message,
@RequestParam(value = "temp", required = false) Double temp
) {
System.out.println("收到消息:"+message);
Prompt prompt;
if (temp != null) {
// 构建带 temperature 的 DeepSeekChatOptions,覆盖默认 temperature
var opts = DeepSeekChatOptions.builder()
.temperature(temp)
.build();
prompt = new Prompt(message, opts);
System.out.println("使用运行时覆盖 temperature=" + temp);
} else {
// 无 temperature 传入时,使用默认配置
prompt = new Prompt(message);
System.out.println("使用默认 temperature");
}
ChatResponse resp = chatModel.call(prompt);
String result = resp.getResult().getOutput().getText();
System.out.println("模型返回:"+ result);
return result;
}
以上代码编写好后,重启项目,可以传入不同的参数:
“http://localhost:8080/ai/runtimeOptions?message=1加1等于几&temp=0.1”,模型返回如下:

“http://localhost:8080/ai/runtimeOptions?message=1加1等于几&temp=2”,模型返回如下:

Embedding Models
Embedding 介绍
Embedding 是一种将文本(也可扩展至图像、视频)转换成数字向量的技术,这些向量表示了输入内容在语义空间中的位置,能够反映它们之间的相似度——向量距离越近,内容越相似。
Spring AI 通过其 EmbeddingModel 接口提供一套统一、简单、可替换的访问方式,支持多种底层模型(如 OpenAI、Titan、Azure、Ollama、智谱等),这样可以统一接口,切换模型仅需要改配置,不改调用逻辑。
Spring AI 中的Embedding 使用场景如下:
- 相似度计算/语义搜索:将查询和文档全部转换为向量,构建向量数据库进行近邻检索;
- 聚类与分类:将文本转换为向量后,使用传统算法进行聚类或分类;
- 检索增强生成(RAG):先用向量搜索获取相关知识,再结合生成模型回答;
- 推荐系统:如问答推荐、内容推荐等;
- 异常检测:语义异常内容检测。
智普AI Embedding 使用示例
智普AI(北京智谱华章科技有限公司)是清华大学知识工程实验室成果转化成立的大模型研发公司,专注于构建“认知智能”体系。其产品线包括文字对话模型(如 ChatGLM、GLM-4)、图像乃至视频理解模型(如 GLM-4V-Plus)以及文本视频生成模型(如 CogVideoX/“清影”)等,覆盖文字、图像、音视频等多种模态。
使用智普AI需要在以下网站中进行注册并充值。智普AI相关网站如下:
- 智普AI官网地址:https://open.bigmodel.cn/
- 智普AI Key地址:https://open.bigmodel.cn/usercenter/proj-mgmt/apikeys
- 智普AI 充值地址:https://open.bigmodel.cn/finance/pay
- 智普AI相关模型费用地址:https://www.bigmodel.cn/pricing,可以看到相关种类模型的费用,也包含一些免费模型。
- 智普AI 文档地址:https://open.bigmodel.cn/dev/howuse/introduction
在Spring AI 中使用Embedding时,需要对应的AI模型支持Embedding,deepseek中目前没有Embedding模型,这里使用智普AI的“embedding-2”模型来演示Embedding使用。以下示例中演示如何在SpringBoot中配置智普AI作为Embedding模型,并对文本数据向量化操作。
1) 创建SpringBoot项目,命名为“SpringAIEmbedding”
2) 配置项目pom.xml
pom.xml内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.5.0</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.example</groupId>
<artifactId>SpringAIEmbedding</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>SpringAIEmbedding</name>
<description>SpringAIEmbedding</description>
<properties>
<java.version>17</java.version>
</properties>
<!-- 导入 Spring AI BOM,用于统一管理 Spring AI 依赖的版本,
引用每个 Spring AI 模块时不用再写 <version>,只要依赖什么模块 Mavens 自动使用 BOM 推荐的版本 -->
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>1.0.0-SNAPSHOT</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-zhipuai</artifactId>
</dependency>
<!-- spring-ai-client-chat 中包括 TokenTextSplitter、TextReader、Document 等工具 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-client-chat</artifactId>
<version>1.0.0</version>
</dependency>
</dependencies>
<!-- 声明仓库, 用于获取 Spring AI 以及相关预发布版本-->
<repositories>
<repository>
<id>spring-snapshots</id>
<name>Spring Snapshots</name>
<url>https://repo.spring.io/snapshot</url>
<releases>
<enabled>false</enabled>
</releases>
</repository>
<repository>
<name>Central Portal Snapshots</name>
<id>central-portal-snapshots</id>
<url>https://central.sonatype.com/repository/maven-snapshots/</url>
<releases>
<enabled>false</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
</repositories>
</project>
特别注意:需要在“SpringAIEmbedding”项目的pom.xml中导入“spring-ai-starter-model-zhipuai”依赖。“spring-ai-client-chat”依赖包需要对文档进行切分处理时所使用的依赖包。
3) 配置resources/application.properties
spring.application.name=SpringAIEmbedding
server.port=8080
#使用 智普AI Embedding 模型,需要在pom.xml中引入对应依赖
spring.ai.zhipuai.api-key=d...GA4
spring.ai.zhipuai.base-url=https://open.bigmodel.cn/api/paas
spring.ai.zhipuai.embedding.options.model=embedding-2
#使用 智普AI Chat 模型,需要在pom.xml中引入对应依赖
spring.ai.zhipuai.chat.options.model=GLM-4-Flash
4) 创建Controller包并创建EmbeddingController类
在“SpringAIEmbedding”项目中创建“controller”包,在该包下编写“EmbeddingController.java”类,该类中实现embed方法来将用户输入的文本内容通过智普AI Embedding进行向量化。
import com.example.springaiembedding.service.EmbeddingService;
import org.springframework.ai.embedding.EmbeddingModel;
import org.springframework.ai.embedding.EmbeddingResponse;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import java.util.Map;
@RestController
@RequestMapping("/ai")
public class EmbeddingController {
@Autowired
private EmbeddingModel embeddingModel;
//测试 embedding
@GetMapping("/embedding")
public Map embed(@RequestParam(value = "message", defaultValue = "给我讲个笑话") String message) {
// 调用 embed 方法,将文本转换成向量,默认向量维度为 1024
float[] vector = embeddingModel.embed(message);
return Map.of(
"message", message,
"vector", vector
);
}
}
以上代码中对用户输入的文本内容向量化,只需要调用“embeddingModel.embed(文本)”即可,如果对多条文本进行向量化转换,可以调用“embeddingModel.embed(List<T>)”操作。
5) 启动项目并测试
启动项目后,浏览器输入“http://localhost:8080/ai/embedding?message=今天天气很好”,可以看到输出内容如下:
{"message":"今天天气很好","vector":[-0.07260562,0.005600141,-0.0378431,-0.034070812,-0.018191425,-0.0034634115,-0.029991228,0.038196057,0.025889568,0.001633238,-0.016376244,-0.040188957,-0.017353531,0.047503855,-0.018386343,0.014544255,-0.021725116,0.002996758,-0.011191875,0.011162163,-0.019570969,0.017660921,0.03319585,-0.065318294,-2.5312623E-4,-0.067810364,0.013731177,0.008502983,0.02763537,-0.009782783,0.011306662,0.005104383,0.00480137,0.04124188,-0.012842868,0.039708782,-0.02221145...]}
可以看到通过智普AI的“embedding-2”模型将用户输入的文本进行进行了向量化。
Embedding案例1:查找相似文本
本案例中实现通过智普AI 的Embedding模型实现对用户输入文本的向量化,然后通过余弦相似度与已有的本地知识内容进行匹配,查找并输出与用户输入相似的文本内容。
该案例实现思路如下:
1) SpringBoot中创建Service,当服务启动时,将所有本地知识批量通过embed(List<T>)转换为向量。在Service中定义queryBastMatch方法,该方法对传入的文本进行向量化,然后与本地知识转换的向量通过余弦相似度计算,找出最相似的本地知识内容。
2) SpringBoot中创建Controller,用户通过浏览器URL访问到Controller中similarity方法,该方法调用到Service中queryBestMatch方法,返回给用户最相似的本地知识内容。
余弦相似度
余弦相似度是一种衡量两个向量方向相似程度的度量方法,通过计算它们夹角的余弦值来评估相似性,广泛应用于文本分析、数据挖掘等领域。
余弦相似度的数学本质是向量空间模型中夹角的余弦值,计算公式为两个向量的点积除以它们的模长乘积。对于n维向量A和B,公式可表示为:
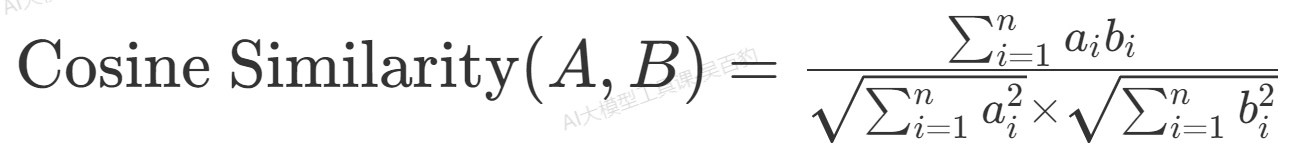
其值范围在-1到1之间,1表示完全相同,-1表示完全相反,0表示无关。
余弦相似度典型应用场景如下:
- 文本相似度计算:将文档转化为词频向量后,通过余弦相似度比较内容相似性。
- 聚类分析:衡量数据点在高维空间中的分布方向是否相近,常用于推荐系统或异常检测。
案例实现
1) 准备Service及对应方法
在“SpringAIEmbedding”项目中创建“service”包,并在该包中创建“EmbeddingService.java”类,写入如下内容:
import org.springframework.ai.embedding.EmbeddingModel;
import org.springframework.stereotype.Service;
import java.util.List;
@Service
public class EmbeddingService {
private EmbeddingModel embeddingModel;
private final List<float[]> docVectors;
// 1. 准备知识库文本内容
private final List<String> docs = List.of(
"美食非常美味,服务员也很友好。",
"这部电影既刺激又令人兴奋。",
"阅读书籍是扩展知识的好方法。"
);
public EmbeddingService(EmbeddingModel embeddingModel) {
this.embeddingModel = embeddingModel;
// 2. 启动时,将所有文档向量化
this.docVectors = this.embeddingModel.embed(docs);
}
/**
* 输入用户查询,返回最相似文档的索引 (使用余弦相似度计算)
* @param query 用户输入的查询文本
* @return 最相似的知识库文本
*/
public String queryBestMatch(String query) {
//将用户的输入通过EmbeddingModel转换成向量
float[] queryVec = embeddingModel.embed(query);
int bestIdx = -1; //记录目前最匹配文档在列表中的索引位置
double bestSim = -1; //记录目前的最高相似度
// 遍历所有文档对应的向量,计算与查询向量的相似度
for (int i = 0; i < docVectors.size(); i++) {
//计算余弦相似度
double sim = cosineSimilarity(queryVec, docVectors.get(i));
if (sim > bestSim) {
bestSim = sim;
bestIdx = i;
}
}
return docs.get(bestIdx);
}
// 余弦相似度实现
// 计算两个向量之间的余弦相似度,数值范围在 [-1, 1] 之间
// 相似度越高,越接近1,越接近0,越不相似
private double cosineSimilarity(float[] a, float[] b) {
double dot = 0, na = 0, nb = 0;
for (int i = 0; i < a.length; i++) {
dot += a[i] * b[i];
na += a[i] * a[i];
nb += b[i] * b[i];
}
return dot / (Math.sqrt(na) * Math.sqrt(nb));
}
}
2) 准备Controller及对应方法
在“SpringAIEmbedding”项目中的“controller/EmbeddingController.java”类中注入如下依赖和增加如下方法:
@Autowired
private EmbeddingService service;
//文本相似检测
@GetMapping("/similarity")
public Map<String, String> similarity(@RequestParam("query") String query) {
String ans = service.queryBestMatch(query);
return Map.of("query", query, "answer", ans);
}
3) 启动项目并测试
启动Spring Boot项目,浏览器中输入如下内容进行相似文本查找:
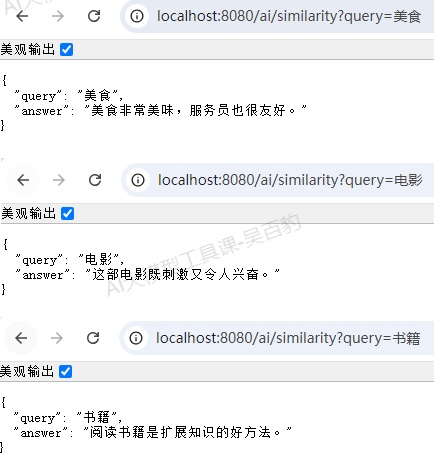
#输入http://localhost:8080/ai/similarity?query=美食
{
"query": "美食",
"answer": "美食非常美味,服务员也很友好。"
}
#输入http://localhost:8080/ai/similarity?query=电影
{
"query": "电影",
"answer": "这部电影既刺激又令人兴奋。"
}
#输入http://localhost:8080/ai/similarity?query=书籍
{
"query": "书籍",
"answer": "阅读书籍是扩展知识的好方法。"
}
测试结果:
Embedding案例2:RAG本地知识库检索
什么是RAG
检索增强生成(Retrieval-Augmented Generation,简称 RAG)是一种将大型语言模型(LLM)与外部知识源相结合的人工智能技术。通过在生成响应前检索相关信息,RAG 能够为模型提供最新且特定领域的知识,从而提高回答的准确性和相关性。
RAG的工作原理如下:
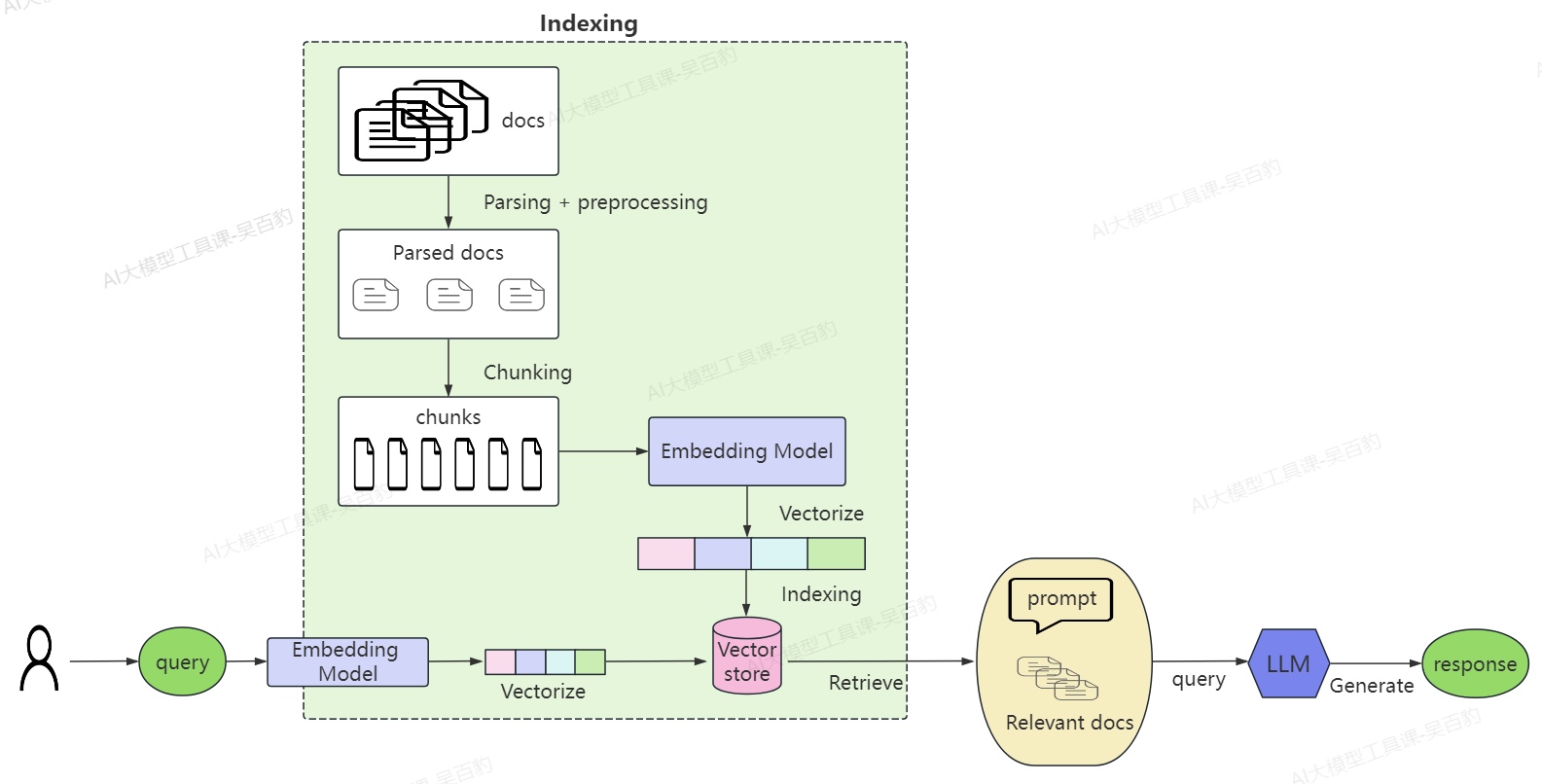
我们有自己的文档(url、pdf、txt、数据库等),这些文档就是用户本地的知识库,经过解析处理为chunks(小块)文档,然后这些文档通过嵌入模型(Embedding Model)将这些文本信息转换成向量(Vector),即转换成数字表示,这就是嵌入的含义,这些向量保存在向量数据库中,这个过程我们称为indexing(索引)。
当用户提出问题时,这些问题也会通过Embedding Model转换成向量,然后去向量数据库中去检索(Retrieve),检索到与问题相关的文档,然后把这些内容打包,结合提示词(Prompt)一起传递给大模型,这样大模型就有了如何回答该问题的上下文概念,结合大模型的推理能力,形成连贯答案返回给用户,这就是RAG工作流程。
案例实现
如下是一个完整的RAG(Retrieval-Augmented Generation)案例,该案例中使用Spring AI 、智普AI Embedding、智普 Chat Model来完成。
该案例实现思路如下:
-
本地知识库文件放入到项目resources资源目录中,在项目中通过ClassPathResource加载。
-
将文档按照指定的符号进行拆分,分成多个片段,然后使用智普AI Embedding 进行向量化处理,向量化内容保存在内存中。
-
当用户输入问题时,通过智普AI Embedding进行向量化,然后找出与本地知识向量化内容最相似的Top2内容。
-
将查找到与用户问题最相关的Top2本地内容和用户问题作为prompt交由智普AI Chat模型进行统一回复。
下面按照以上步骤在“SpringAIEmbedding”项目中实现RAG本地知识库信息检索。
1) 准备智普AI Chat模型配置
在“SpringAIEmbedding”项目的resources/application.properties中加入如下chat模型配置,该chat模式将用于整合知识片段回复。
#使用 智普AI Chat 模型,需要在pom.xml中引入对应依赖
spring.ai.zhipuai.chat.options.model=GLM-4-Flash
2) 准备本地知识
在“SpringAIEmbedding”项目的resources资源目录下放入“古代诗歌常用意向.txt”文件,该文件内容如下:
古代诗歌中常用的意象
----
1.植物类
草:生命力强、生生不息、希望、荒凉、离恨、卑微。
黄叶:凋零、别离、美人迟暮、新陈代谢。
绿叶:生命力、长久、活力、希望。
梧桐:悲秋、凄苦、感伤,还可表达高贵。
芭蕉:孤独、离别。
柳:送别、思亲、挽留、操守(介之推)。
花开:青春、希望、人生的美好。
花落:惜春、凋零、失意、事业的挫折、对美好事物的留恋。
禾黍:黍离之悲(国家衰败)。
杨花:漂泊、流散、无情。
牡丹:富贵、美好、憧憬。
莲:怜、爱、纯洁。
梅子:少女怀春。
丁香:愁思、情结。
虞美人:罂粟科一年生草本花卉,亦称丽春、赛牡丹。相传此花系西楚霸王项羽爱妾虞姬自刎垓下碧血所化,故有闻虞兮歌而起舞之说。历代文人雅士歌咏此花,多涉及这一悲壮传说。
红豆:《南州记》称为海红豆,《本草》称其为“相思子”。常用以象征爱情或相思。
豆蔻:豆蔻是一种多年生草本植物。后来称女子十三四岁的年纪为豆蔻年华。
岁寒三友:指古诗文中经常提到的松、竹、梅。松,是耐寒树木,终冬不凋,常被看做刚正节操的象征。竹,也经冬不凋,且自成美景,它刚直、谦逊、不卑不亢,潇洒处世,常被看做不同流俗的高雅之士的象征。梅,迎寒而开,美丽绝俗,是坚忍不拔的人格的象征。
花中四君子:古诗人中常提到的梅、兰、竹、菊。兰,一则花朵色淡香清,二则多生于幽僻之处,故常被看做是谦谦君子的象征。菊,它不仅清丽淡雅、芳香袭人,而且具有傲霜斗雪的特征;它艳于百花凋后,不与群芳争艳,故历来被用来象征恬然自处、傲然不屈的高尚品格。(“梅、竹”见上条。)
----
2.动物类
鹧鸪:行不得也哥哥、离愁、物是人非。
燕:家园、物是人非。
鹰:自由、强劲、人生搏击、事业成功。
乌鸦:小人、奸臣、俗客庸夫、哀伤。
沙鸥:飘零、无依、伤感。
鱼:自由、惬意。
鲤鱼:尺素书、信。
寒蝉:悲秋、高洁之士。
鸡狗:田园、世俗生活。
猿猴:凄清、哀伤、荒远。
马:追求、仕途、漂泊(瘦马)。
鸿雁:《汉书·苏武传》载有大雁传书事,后因以之喻书信。
鸿鹄:鸿鹄飞得很高,常用来比喻志气高远的人。
杜鹃:杜鹃鸟俗称布谷,也叫子归、子鹃。春夏季节,杜鹃彻夜不停啼鸣,啼声清脆而短促,唤起人们多种情思。杜鹃口腔上皮和舌部都为红色,古人误以为它们啼得满嘴流血,凑巧杜鹃高歌之时,正是杜鹃花开之际,人们见杜鹃花开得那样鲜红,便把这种颜色说成是杜鹃啼的血。
比翼鸟:传说中的一种鸟,雌雄老在一起飞,古典诗歌里用作恩爱夫妻的比喻。
----
3.景象类
草原:辽阔、人生境界、人的胸襟。
海:辽阔、深邃、力量、胸襟、人生的起伏。
江水:时光流逝、岁月短暂、愁苦绵长。
烟雾:情感朦胧、命运惨淡、前途迷惘、理想幻灭。
小雨:春景、生机活力、希望、伤感、潜移默化式的教化。
暴雨:热情、动荡、巨变、政治斗争、恶势力、荡涤污秽的力量。
狂风:作乱、恶势力、摧毁旧世界的力量。
东风:春风、欢愉、希望、美好、时光。
西风:悲秋、落寞、惆怅、衰败、游子思归。
霜:打击、考验、变易、挫折、社会环境恶劣,恶势力猖狂、人生路途坎坷。
雪:纯洁、美好、寒冷、环境恶劣、恶势力。
露:人生短促、生命易逝。
阴:压抑、愁苦、寂寞。
晴:欢景、光明、希望。
云:游子、飘泊、归隐、轻浮。
夕阳:迟暮、失落、消沉、美好而短暂的事物。
月亮:圆满、缺憾、思乡、思亲、变易、离别。
破晓:清静、迷茫、希望。
暮夜:愁思、怀旧、孤独、清冷。
天地:人的渺小、人生短暂、心胸广阔、情感孤独。
秋水:秋水,喻指眼睛,形容盼望的迫切。
----
4.人文类
英雄:历史风云人物、功业有成者、令人追慕者、让人自愧不如者。
小人:奸人、被鄙夷的、被鞭挞的、使人反思者。
古迹:古营垒、旧楼台,衰败、萧条、怀旧明志、昔盛今衰。
乡村:思归、世俗、田园风光、生活气息、纯朴宁静的生活。
南浦:送别、感伤。
亭:长亭短亭,送别、挽留、依恋。
都市:市井繁荣、富贵奢华、世俗名利。
仙境:飘逸、忘尘厌俗、幻想、虚幻。
酒:长久、送别、欢悦、得意、失意、愁苦。
云帆:抱负、离别、思乡。
琴瑟:(1)比喻夫妇感情和谐,亦作“瑟琴”。(2)比喻兄弟朋友的情谊。
梨园:梨园原是皇帝禁苑中的果木园圃,唐玄宗开元年间,将其作为教习歌舞的地方,且在这里培养出了大批优秀的音乐舞蹈表演人才,在历史上产生了深远的影响。因此,后世的戏曲班社常以“梨园”为其代称,戏曲艺人称“梨园弟子”。
神器:指地位、政权。
月老:传说唐朝韦固月夜里经过宋城,遇见一个老人坐着翻检书本。韦固前往窥视,一个字也不认得。向老人询问后,才知道老人是专管人间婚姻的神仙,翻检的书是婚姻簿。(见《续幽怪录·定婚店》)后来因此称媒人为月下老人,或月老。
陶朱:春秋时越国大夫范蠡的别号。相传他帮助勾践灭吴后,离开越国到陶,善于经营生计,积累了很多财富,后世因此以“陶朱”或“陶朱公”来称富商。
祝融:传说中楚国唐诉祖先,为高辛氏帝喾的火正(掌火之官),以光明四海而成为祝融,后世祀为火神。由此,火灾称为祝融之灾。
青梅竹马:出自李白的《长干行》:“郎骑竹马来,绕床弄青梅。同居长干里,两小无嫌猜。”后来用“青梅竹马”形容男女小的时候天真无邪,也指幼小时就相识的伴侣。
问鼎:《左传·宣公三年》:“楚子伐陆浑之戎,隧至于雒观兵于周疆。定王使王孙满劳楚子,楚子问鼎之大小轻重焉。”三代以九鼎为传国宝,楚子问鼎,有觊觎周室之意。后遂以问鼎比喻图谋帝王权位。
逐鹿:《汉书·蒯通传》:“且秦失其鹿,天下共逐之。”颜师古注引张晏曰:“以鹿喻帝位。”后来用逐鹿比喻群雄并起,争夺天下。
三尺:三尺,也叫“三尺法”,是法律的代名词。古代把法律写在三尺长的竹简上,所以称“三尺法”。
杜康:《说文解字·巾部》:“古者少康初作箕帚,少康,杜康也。”后即以杜康作为酒的代称。
秦晋:春秋时,秦晋两国世为婚姻,后因称两姓联姻为“秦晋之好”。
彭祖:传说故事人物,生于夏代,至殷末时已八百余岁,旧时把彭祖作为长寿的象征,以“寿如彭祖”来祝人长寿。
谢家:唐诗宋词不达意之处常用“谢家”之典,其意有:
(1)用谢安、谢玄家事,意指人有风度。
(2)专指谢安侄女谢道韫之事,表示有才有貌之美女。
(3)指山水诗人谢灵运事。
婵娟:婵娟,姿态美好,多用来形容女子;因人们常喻月为美女,故月亮称为婵娟。
献芹:《列子·杨朱》有一个故事说,从前有一个人在乡里的豪绅面前大肆吹嘘芹菜如何好吃,豪绅尝了之后,竟“蜇于口,惨于腹”。后来就用“献芹”谦称赠人的礼品菲薄,或所提的建议浅陋。也说“芹献”。
执牛耳:古代诸侯订立盟约,要每人尝一点牲血,主盟的人亲自割牛耳取血,故用“执牛耳”指盟主。后来指在某一方面居领导地位。
3) 准备Service及对应方法
在“SpringAIEmbedding”项目中创建service/RagService.java文件,写入如下内容:
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.embedding.EmbeddingModel;
import org.springframework.core.io.ClassPathResource;
import org.springframework.core.io.Resource;
import org.springframework.stereotype.Service;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.List;
@Service
public class RagService {
private final EmbeddingModel em; //嵌入模型,用于生成文本的向量
private final ChatClient chatClient; // 聊天客户端,用于与 AI 进行交互
private final List<String> docs = new ArrayList<>();//存储本地文档内容
private final List<float[]> vectors = new ArrayList<>();//存储本地文档向量
public RagService(EmbeddingModel embeddingModel, ChatClient.Builder chatBuilder) throws IOException {
this.em = embeddingModel;
this.chatClient = chatBuilder.build(); // 创建 智普AI Chat 聊天客户端
// 加载本地文档
Resource res = new ClassPathResource("古代诗歌常用意象.txt");
String content = new String(res.getInputStream().readAllBytes(), StandardCharsets.UTF_8);
// 分割文档内容并生成向量
for (String part : content.split("----")) {
System.out.println("part: " + part);
if (part.isBlank()) continue;
docs.add(part);// 存储切分的文档内容
vectors.add(em.embed(part)); // 将文档生成 embedding 并存储
}
}
// 对用户输入的问题进行回答
public String answer(String q) {
// 生成用户问题的向量
float[] qv = em.embed(q);
// 最相似两个文档的索引
int index1 = -1, index2 = -1;
// 最相似两个文档的相似度
double v1 = -1, v2 = -1;
// 找到最相似的两个文档
for (int i = 0; i < vectors.size(); i++) {
// 计算用户问题向量与切分的每个文档向量的余弦相似度
double sim = cosineSimilarity(qv, vectors.get(i));
if (sim > v1) {
index2 = index1;
v2 = v1;
index1 = i;
v1 = sim;
} else if (sim > v2) {
index2 = i;
v2 = sim;
}
}
//获取两个最相似文档的内容,拼接在一起作为上下文
String ctx = docs.get(index1) + (index2 >= 0 ? "\n---\n" + docs.get(index2) : "");
//构建 AI 模型的提示信息,包含上下文和用户问题
String prompt = "以下是知识内容:\n" + ctx + "\n请基于上述知识回答用户问题:“" + q + "”";
// 使用 ChatClient 流式构建
var response = chatClient
.prompt()
.system("你是知识助手,结合上下文回答问题") // 添加系统提示
.user(prompt) // 用户 + 上下文
.call(); // 发起同步调用
// 获取内容文本
return response.content();
}
// 余弦相似度实现
// 计算两个向量之间的余弦相似度,数值范围在 [-1, 1] 之间
// 相似度越高,越接近1,越接近0,越不相似
private double cosineSimilarity(float[] a, float[] b) {
double dot = 0, na = 0, nb = 0;
for (int i = 0; i < a.length; i++) {
dot += a[i] * b[i];
na += a[i] * a[i];
nb += b[i] * b[i];
}
return dot / (Math.sqrt(na) * Math.sqrt(nb));
}
}
特别注意:以上代码中用户自己将本地知识库文件切分并通过Embedding 模型转换成向量,然后获取与用户输入问题向量最相似的Top2文档交给大模型处理。
4) 准备Controller及对应方法
在“SpringAIEmbedding”项目中创建controller/RagController.java文件,写入如下内容:
import com.example.springaiembedding.service.RagService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import java.util.Map;
@RestController
@RequestMapping("/rag")
public class RagController {
@Autowired
private RagService ragService;
@GetMapping("/ask")
public Map<String, String> ask(@RequestParam("question") String question) {
String answer = ragService.answer(question);
return Map.of("question", question, "answer", answer);
}
}
5) 启动项目并测试
重新启动“SpringAIEmbedding”项目,然后浏览器输入如下内容进行RAG本地知识库检索测试:
http://localhost:8080/rag/ask?question=古代诗歌常用意象有哪些?
可以看到答案如下,我们发现关于用户提问的回复并不是太精准,只是返回的部分内容,主要原因详见下个小节。

Embedding案例3:RAG本地知识库检索升级
手动切分文档存在问题
上个案例中,对于用户的提问,RAG本地知识库检索的结果并不理想,原因是:用户提问向量化后在与本地知识库内容匹配时匹配到的片段只有top2前两个,当本地知识库较大且用户的问题可能覆盖多个知识片段时,仅仅返回“最相关的Top2”文档内容导致最终模型回复效果很差,并且仅仅返回的两个知识片段还有可能由于切分规则导致语义不完整,这样也导致模型回复效果很差。
对于以上这个问题,可以通过以下方式改进效果:
1. 调整Chunk分段策略
如果分片过大(例如:长文本全部),里面可能包含多个主题内容,但用户查询embedding更聚焦于某一小主题,这样导致检索不够精准;分片过小(几行文字)又无法捕获完整含义。建议分片中等大小,可以几句话到一小段,长度建议200~500字符,根据文档结构灵活切分。
2. 根据相似阈值来确定获取的知识分片
将用户问题对应的向量与知识库中知识向量进行相似度计算时,可以指定一个相似度,将大于该相似度的知识片段都加入到上下文,也可以基于此基础上获取TopK相关知识片段,防止更多噪声影响,如Top5/Top10 的相关片段作为上下文。
注意:当知识库大或问题普遍,相似度大于指定阈值的片段可能很多,导致拼接的prompt 超过最大上下文长度,影响性能甚至报错,过多片段也会引入无关或弱相关内容,模型容易“分心”(噪声)。
3. 获取相关知识片段的相邻片段
获取相关知识分片时,不仅仅获取相关分片,也将该分片前后相邻的1~2个分片一并加入到上下文,以提升整体连贯性。这样做的原因主要是单片段上下文往往不够,可能丢失前后语境,加上它的前后相邻段可以增强语境连贯性。例如:“春风又绿江南岸”,如果拆分拆到“春风又绿…” 和“…江南岸”两个片段,单独都不完整,将两块合并才有完整意义。
所以解决手动切分文档出现的以上问题,可以从改进文档分段逻辑(每段大小均衡,更好捕获语义边界)+指定关联相似度阈值(排除低相关结果,避免噪声上下文干扰)+TopK相关知识片段限制(可选,可以进一步降低噪声)+增加相关知识片段前后段(前后端补全上下文,提高语义连贯性) 四个方面进行。
案例实现
1) 准备智普AI Chat模型配置及导入依赖
在“SpringAIEmbedding”项目的resources/application.properties中加入如下chat模型配置,该chat模式将用于整合知识片段回复。
#使用 智普AI Chat 模型,需要在pom.xml中引入对应依赖
spring.ai.zhipuai.chat.options.model=GLM-4-Flash
在项目pom.xml中导入如下依赖,该依赖将用于文档切分操作。
<!-- spring-ai-client-chat 中包括 TokenTextSplitter、TextReader、Document 等工具 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-client-chat</artifactId>
<version>1.0.0</version>
</dependency>
2) 准备本地知识
在“SpringAIEmbedding”项目的resources资源目录下放入“古代诗歌常用意向.txt”文件,该步骤在上个案例中已经操作,可忽略。
3) 准备Service及对应方法
在“SpringAIEmbedding”项目中创建service/RagService2.java文件,写入如下内容:
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.document.Document;
import org.springframework.ai.embedding.EmbeddingModel;
import org.springframework.ai.reader.TextReader;
import org.springframework.ai.transformer.splitter.TokenTextSplitter;
import org.springframework.core.io.ClassPathResource;
import org.springframework.stereotype.Service;
import java.util.ArrayList;
import java.util.List;
import java.util.Set;
import java.util.TreeSet;
import java.util.stream.Collectors;
@Service
public class RagService2 {
private final EmbeddingModel em;//嵌入模型,用于生成文本的向量
private final ChatClient chatClient;// 聊天客户端,用于与 AI 进行交互
private final List<String> docs = new ArrayList<>(); //存储本地文档内容
private final List<float[]> vectors = new ArrayList<>(); //存储本地文档向量
public RagService2(EmbeddingModel embeddingModel, ChatClient.Builder chatBuilder) throws Exception {
this.em = embeddingModel;
this.chatClient = chatBuilder.build();// 创建 智普AI Chat 聊天客户端
// 1. 从 resources 读取长文本文档
var resource = new ClassPathResource("古代诗歌常用意象.txt");
// 创建 TextReader 并读取文档内容
TextReader reader = new TextReader(resource);
List<Document> rawDocs = reader.read();
// 2. 使用 TokenTextSplitter 工具将长文本拆分为合理大小片段
TokenTextSplitter splitter = TokenTextSplitter.builder()
.withChunkSize(800) // 拆分每段最多 800 token
.withMinChunkSizeChars(400) // 每段最小允许 400 字符
.withKeepSeparator(true) // 保留分隔符,提高上下文连贯
.build();
//按照设置的参数拆分长文本为多个Chunk
List<Document> chunks = splitter.apply(rawDocs);
// 3. 遍历每个 chunk,生成 embedding 并存储
for (Document d : chunks) {
// 获取文本内容,并去除首尾空白
String text = d.getText().strip();
System.out.println("text: " + text);
if (text.isBlank()) continue;
docs.add(text);// 存储切分的文档内容
vectors.add(em.embed(text));// 将文档生成 embedding 并存储
}
}
public String answer(String q) {
// 4. 将用户提问 embedding
float[] qVec = em.embed(q);
// 5. 计算每个 chunk 与提问的相似度,并找出前 K 高
int K = 5;
double threshold = 0.05; // 相似度阈值
// 该列表用于存储 大于阈值的 chunk 信息(chunk索引和相似度)
List<IndexSim> sims = new ArrayList<>();
for (int i = 0; i < vectors.size(); i++) {
// 计算用户问题向量与切分的每个文档向量的余弦相似度
double sim = cosineSimilarity(qVec, vectors.get(i));
if (sim >= threshold) {
sims.add(new IndexSim(i, sim));
}
}
// 按相似度降序排序
sims.sort((a, b) -> Double.compare(b.sim, a.sim));
// 取相似度最高的前 K 个片段
List<IndexSim> topKs = sims.stream().limit(K).collect(Collectors.toList());
// 6. 扩展上下文范围:在每个匹配片段基础上加入其前后相邻片段
// 为了避免重复,使用 TreeSet 来存储所有需要的片段索引,TreeSet 会自动去重并排序,保持从小到大顺序
Set<Integer> idxSet = new TreeSet<>();
for (IndexSim is : topKs) {
idxSet.add(is.index);
if (is.index - 1 >= 0) idxSet.add(is.index - 1);
if (is.index + 1 < docs.size()) idxSet.add(is.index + 1);
}
// 7. 将这些片段拼接成最终上下文内容,用于生成回答
String context = idxSet.stream()
.map(docs::get)
.collect(Collectors.joining("\n---\n"));
String prompt = "以下是相关知识片段:\n" + context + "\n请基于这些内容回答问题:“" + q + "”";
// 8. 调用 ChatClient 生成回答
var response = chatClient
.prompt()
.system("你是一个知识助手,请结合上下文进行回答")
.user(prompt)
.call();
// 返回大模型的回答结果
return response.content();
}
// 辅助类:记录 index 与 相似度
static class IndexSim {
int index;// 文档索引
double sim;// 相似度
IndexSim(int index, double sim) {
this.index = index;
this.sim = sim;
}
}
// 余弦相似度实现
// 计算两个向量之间的余弦相似度,数值范围在 [-1, 1] 之间
// 相似度越高,越接近1,越接近0,越不相似
private double cosineSimilarity(float[] a, float[] b) {
double dot = 0, na = 0, nb = 0;
for (int i = 0; i < a.length; i++) {
dot += a[i] * b[i];
na += a[i] * a[i];
nb += b[i] * b[i];
}
return dot / (Math.sqrt(na) * Math.sqrt(nb));
}
}
以上代码中使用TextReader读取文档内容并通过TokenTextSplitter指定文本拆分规则,相比于上个案例改进了文档分段逻辑。并且在用户输入问题后,进行向量相似度比对时加入了0.05阈值,基于此只获取Top5相关分段且获取这些片段的前后相关片段都作为上下文交由模型组织回复。
注意:以上代码中“.withChunkSize(800) 设置的是 token 最大数”,TokenTextSplitter会按最多 800 个 token 为单位去切片(允许适当 overlap),以确保每段不超过模型输入限制,拆分得到的若干 tokenchunk,还会进行合并,合并后,“.withMinChunkSizeChars(400) ”会被用作 字符下限检查,如果合并后一段文本少于 400 个字符,它会尝试和下一段合并,确保至少满足最小字符要求。
4) 准备Controller及对应方法
在“SpringAIEmbedding”项目中创建controller/RagController.java文件,写入如下内容:
@Autowired
private RagService2 ragService2;
@GetMapping("/ask2")
public Map<String, String> ask2(@RequestParam("question") String question) {
String answer = ragService2.answer(question);
return Map.of("question", question, "answer", answer);
}
5) 启动项目并测试
重新启动“SpringAIEmbedding”项目,然后浏览器输入如下内容进行RAG本地知识库检索测试:
http://localhost:8080/rag/ask2?question=古代诗歌常用意象有哪些?
可以看到答案如下,本次经过优化的RAG本地知识库检索回复比较全面:

Image Models
Spring 的图像模型 API 旨在提供一个简单且可移植的接口,用于与各种专注于图像生成的 AI 模型交互。该 API 允许开发者在不同的图像模型之间切换时,仅需做最小的代码修改。
Spring AI通过配套类如 ImagePrompt(用于封装输入)和 ImageResponse(用于处理输出),图像模型 API 实现了与图像生成 AI 模型之间通信的统一化,向开发者提供直接简洁的 API 接口来调用图像生成功能。
Image Models案例-生成图片
如下在Spring AI 中使用智普AI来生成图片,按照如下步骤实现。
1) 创建SpringBoot项目,命名为“SpringAIImage”
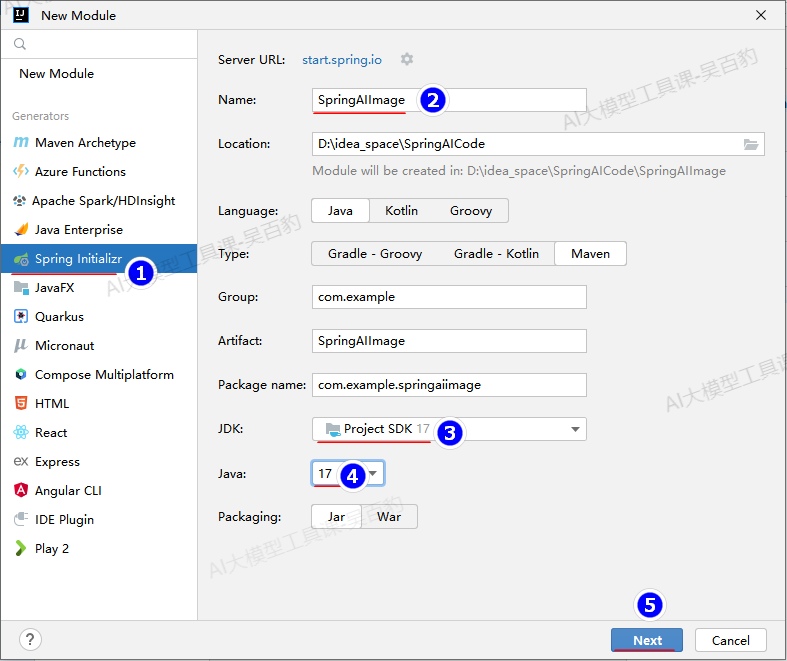
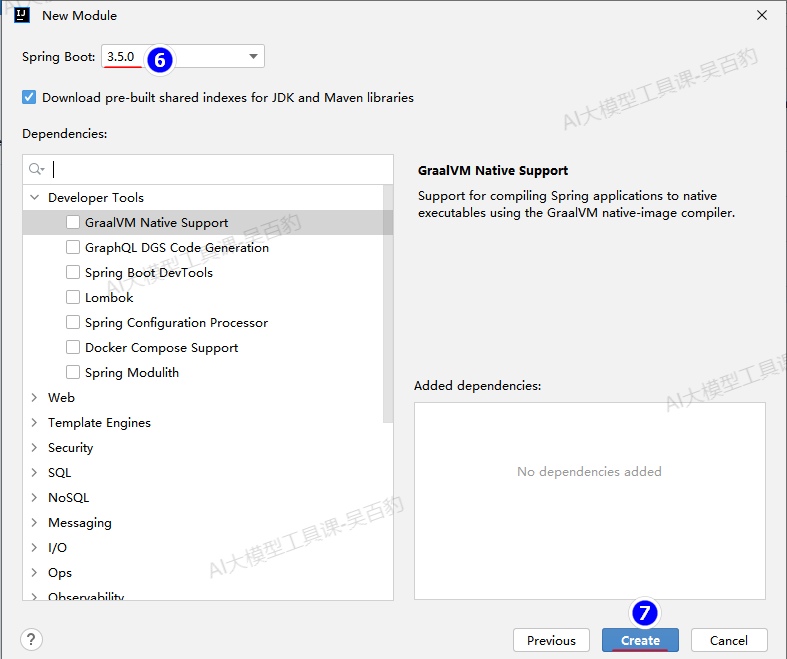
2) 配置项目pom.xml
pom.xml内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.5.0</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.example</groupId>
<artifactId>SpringAIImage</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>SpringAIImage</name>
<description>SpringAIImage</description>
<properties>
<java.version>17</java.version>
</properties>
<!-- 导入 Spring AI BOM,用于统一管理 Spring AI 依赖的版本,
引用每个 Spring AI 模块时不用再写 <version>,只要依赖什么模块 Mavens 自动使用 BOM 推荐的版本 -->
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>1.0.0-SNAPSHOT</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-zhipuai</artifactId>
</dependency>
</dependencies>
<!-- 声明仓库, 用于获取 Spring AI 以及相关预发布版本-->
<repositories>
<repository>
<id>spring-snapshots</id>
<name>Spring Snapshots</name>
<url>https://repo.spring.io/snapshot</url>
<releases>
<enabled>false</enabled>
</releases>
</repository>
<repository>
<name>Central Portal Snapshots</name>
<id>central-portal-snapshots</id>
<url>https://central.sonatype.com/repository/maven-snapshots/</url>
<releases>
<enabled>false</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
</repositories>
</project>
特别注意:需要在“SpringAIImage”项目的pom.xml中导入“spring-ai-starter-model-zhipuai”依赖。
3) 配置resources/application.properties
spring.application.name=SpringAIImage
#使用 智普AI Image 模型,需要在pom.xml中引入对应依赖
spring.ai.zhipuai.api-key=ddd2557084494c46ss6xxxGFUGA4
spring.ai.zhipuai.base-url=https://open.bigmodel.cn/api/paas
# CogView-3-Flash 为免费图像生成模型,其他模型需要付费,具体可以参考:https://www.bigmodel.cn/pricing
spring.ai.zhipuai.image.options.model=CogView-3-Flash
4) 创建Service包并创建ImageService类
在“SpringAIImage”项目中创建“service”包,在该包下编写“ImageService.java”类,该类中实现generateImage方法来将用户输入的文本内容通过智普AI Image模型生成图片。
package com.example.springaiimage.service;
import org.springframework.ai.image.*;
import org.springframework.ai.zhipuai.ZhiPuAiImageModel;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
@Service
public class ImageService {
@Autowired
private ZhiPuAiImageModel imageModel;
public Image generateImage(String prompt) {
ImageOptions options = ImageOptionsBuilder.builder()
//.model("cogview-3")
.N(1) // 生成的图片数量
.width(512) // 图片宽度
.height(512)// 图片高度
.build();
// 创建 ImagePrompt 对象,用于封装本次图像生成请求
ImagePrompt ip = new ImagePrompt(
java.util.List.of(new org.springframework.ai.image.ImageMessage(prompt)),
options
);
//调用 ZhiPuAiImageModel 的 call() 方法,传入 ImagePrompt
ImageResponse resp = imageModel.call(ip);
System.out.println("返回图片信息"+resp.getResult().getOutput());
return resp.getResult().getOutput();
}
}
5) 创建Controller包并创建ImageController类
在“SpringAIImage”项目中创建“controller”包,在该包下编写“ImageController.java”类,该类中实现genRedirect方法,该方法会将用户输入的文本内容调用ImageService.generateImage方法生成图片,并将该图片的url返回给浏览器进行重定向。
package com.example.springaiimage.controller;
import jakarta.servlet.http.HttpServletResponse;
import org.springframework.ai.image.*;
import com.example.springaiimage.service.ImageService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import java.io.IOException;
import java.util.Map;
@RestController
@RequestMapping("/ai")
public class ImageController {
@Autowired
private ImageService svc;
@GetMapping("/generateImage")
public void genRedirect(
@RequestParam(value = "prompt", defaultValue = "画一只小狗") String prompt,
HttpServletResponse response
) throws IOException {
//调用service生成图片 Image 对象
Image image = svc.generateImage(prompt);
//获取图片的url
String url = image.getUrl();
//直接将浏览器重定向到该URL
if (url == null) {
response.sendError(HttpServletResponse.SC_NOT_FOUND, "图片生成失败");
} else {
// 直接重定向,浏览器会去加载该 URL 并展示图像
response.sendRedirect(url);
}
}
}
6) 启动项目并测试
启动项目后,浏览器输入“http://localhost:8080/ai/generateImage?prompt=两个中国美女”,可以看到项目返回图片内容如下:
返回图片信息Image{url='https://aigc-files.bigmodel.cn/api/cogview/202506181536164147c44d280d478f_0.png', b64Json='null'}
浏览器重定向显示图片如

Audio Models
Spring AI 中的Audio Models部分分为两部分:文本转语音(Text-to-Speech)和音频转文字(Transcription)。目前这两部分主要对Open AI 供应商支持,通过Open AI中的 TTS 模型(tts-1/tts-1-hd)将文本转语音,通过 OpenAI中的 Whisper-1 模型将音频转文字,两者均通过统一配置、bean 自动注入、同步/流式调用方式提供易用、可扩展的 API 接口。
关于Open AI 的Api Key 可以通过OpeanAI 官网购买(国内有封号风险),这里也可以某宝自行搜索Api Key 获取一些商家提供的中转key,也可以使用Open AI相关模型。
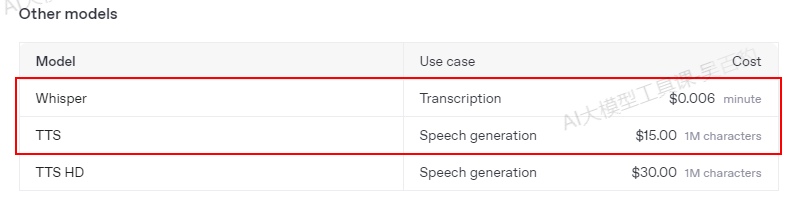
使用Open AI 中语音转换相关模型费用比较贵,关于Open AI中模型调用价格可以参考:https://platform.openai.com/docs/pricing
文本转语音
Spring AI 抽象出 SpeechModel 接口进行兼容未来多种模型供应商,以便进行文本转语音。目前该接口仅有OpenAiAudioSpeechModel一个实现类,只能使用Open AI中tts-1 或者 tts-1-hd 模型进行文本转语音操作。
如下案例中创建SpringBoot项目,并构建对应Controller和Service实现文本转语音操作。
1) 创建SpringBoot项目,命名为“SpringAIAudio”
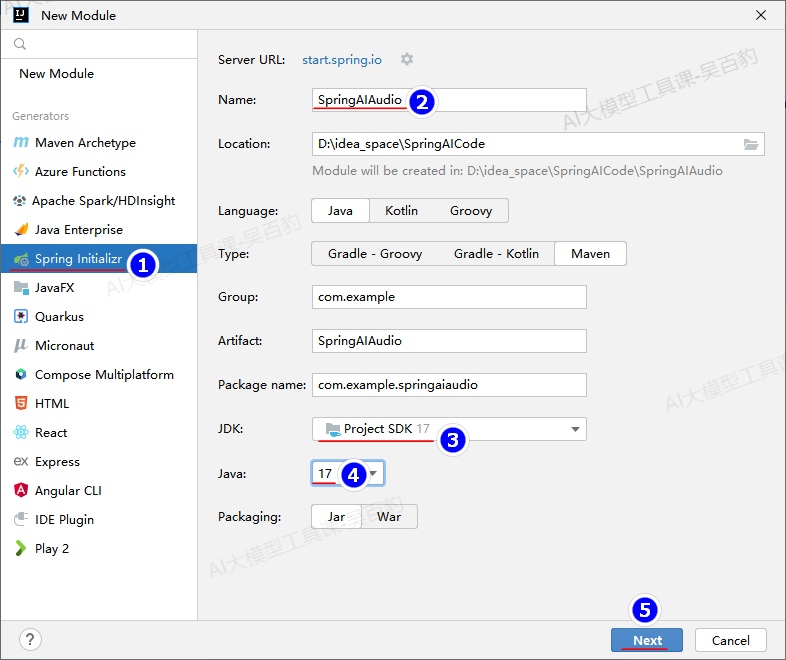
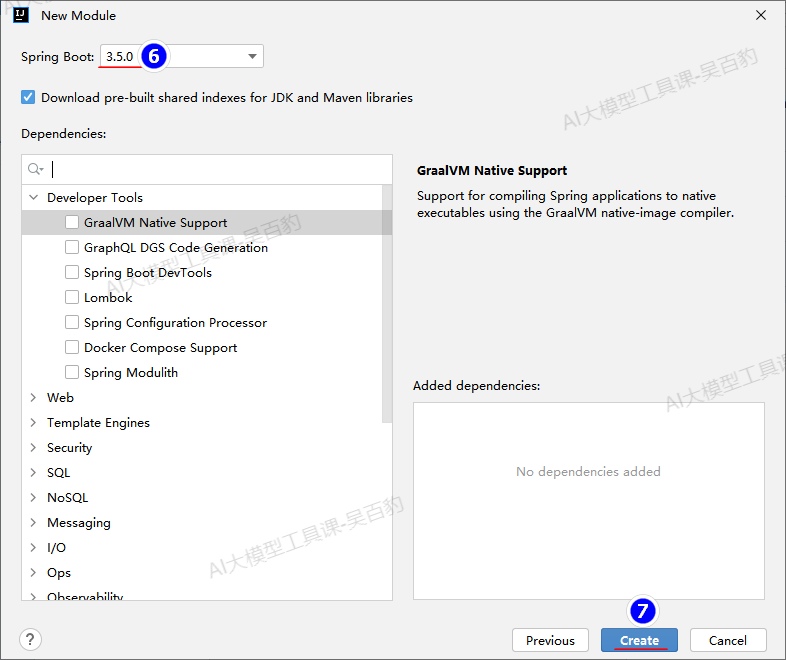
2) 配置项目pom.xml
pom.xml内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.5.0</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.example</groupId>
<artifactId>SpringAIAudio</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>SpringAIAudio</name>
<description>SpringAIAudio</description>
<properties>
<java.version>17</java.version>
</properties>
<!-- 导入 Spring AI BOM,用于统一管理 Spring AI 依赖的版本,
引用每个 Spring AI 模块时不用再写 <version>,只要依赖什么模块 Mavens 自动使用 BOM 推荐的版本 -->
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>1.0.0-SNAPSHOT</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-openai</artifactId>
</dependency>
</dependencies>
<!-- 声明仓库, 用于获取 Spring AI 以及相关预发布版本-->
<repositories>
<repository>
<id>spring-snapshots</id>
<name>Spring Snapshots</name>
<url>https://repo.spring.io/snapshot</url>
<releases>
<enabled>false</enabled>
</releases>
</repository>
<repository>
<name>Central Portal Snapshots</name>
<id>central-portal-snapshots</id>
<url>https://central.sonatype.com/repository/maven-snapshots/</url>
<releases>
<enabled>false</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
</repositories>
</project>
特别注意:需要在“SpringAIAudio”项目的pom.xml中导入“spring-ai-starter-model-openai”依赖。
3) 配置resources/application.properties
spring.application.name=SpringAIAudio
#文本转语音文件存放的路径
tts.audio-output-dir=D:\\idea_space\\SpringAICode\\SpringAIAudio\\src\\main\\audio-output
#使用 Open AI 相关模型,实现文字转语音功能、语音转文字功能
spring.ai.openai.base-url=https://api.uchat.site/
spring.ai.openai.api-key=sk-...8A
#使用 Open AI 相关模型,实现文字转语音功能
spring.ai.openai.audio.speech.options.model=tts-1
#指定合成的语音,可以设置为alloy, echo, fable, onyx, nova 和 shimmer
spring.ai.openai.audio.speech.options.voice=alloy
注意:“tts.audio-output-dir”配置项为用户自定义配置参数,指定的目录用于存储生成的音频文件。
4) 创建Service包并创建TtsService类
在“SpringAIAudio”项目中创建“service”包,在该包下编写“TtsService.java”类,该类中实现textToFile方法来将用户输入的文本转换成mp3文件存入配置的目录中。
import org.springframework.ai.openai.OpenAiAudioSpeechModel;
import org.springframework.ai.openai.OpenAiAudioSpeechOptions;
import org.springframework.ai.openai.api.OpenAiAudioApi;
import org.springframework.ai.openai.audio.speech.SpeechPrompt;
import org.springframework.ai.openai.audio.speech.SpeechResponse;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Service;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
@Service
public class TtsService {
// 注入 OpenAI 的语音模型对象
@Autowired
private OpenAiAudioSpeechModel speechModel;
// 从配置文件中读取语音输出目录
@Value("${tts.audio-output-dir}")
private String audioOutputDir;
/**
* 将文本转换为 MP3 文件并保存到配置的目录,返回文件路径
*/
public String textToFile(String text) throws IOException {
// 构建语音合成的配置项
OpenAiAudioSpeechOptions options = OpenAiAudioSpeechOptions.builder()
//.model("tts-1")
.voice(OpenAiAudioApi.SpeechRequest.Voice.ALLOY) // 使用 alloy 声音
.responseFormat(OpenAiAudioApi.SpeechRequest.AudioResponseFormat.MP3) // 音频格式为 mp3
.speed(1.0f)// 设置语速为 1.0(正常速度)
.build();
// 创建语音请求提示对象
SpeechPrompt prompt = new SpeechPrompt(text, options);
// 调用模型生成语音
SpeechResponse response = speechModel.call(prompt);
System.out.println("response: " + response);
// 获取音频二进制内容
byte[] audio = response.getResult().getOutput();
// 使用配置的目录保存文件
File dir = new File(audioOutputDir);
// 确保输出目录存在,不存在则创建
if (!dir.exists()) {
dir.mkdirs();
}
// 创建输出文件名,使用当前时间戳防止重复
File out = new File(dir, "tts-" + System.currentTimeMillis() + ".mp3");
// 将音频内容写入文件
try (FileOutputStream fos = new FileOutputStream(out)) {
fos.write(audio);
}
// 返回生成的文件完整路径
return out.getAbsolutePath();
}
}
5) 创建Controller包并创建TtsController类
在“SpringAIAudio”项目中创建“controller”包,在该包下编写“TtsController.java”类,该类中实现tts方法,该方法会将用户输入的文本内容调用TtsService.textToFile方法转换成语音文件。
import com.example.springaiaudio.service.TtsService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import java.io.IOException;
@RestController
@RequestMapping("/ai")
public class TtsController {
@Autowired
private TtsService ttsService;
@GetMapping("/tts")
public ResponseEntity<String> tts(@RequestParam("text") String text) {
try {
String filePath = ttsService.textToFile(text);
return ResponseEntity.ok("文本转语音成功,文件保存路径:" + filePath);
} catch (IOException e) {
return ResponseEntity.status(500).body("文本转语音失败:" + e.getMessage());
}
}
}
6) 启动项目并测试
启动项目后,浏览器输入“http://localhost:8080/ai/tts?text=在这个信息化时代,人工智能技术深刻地改变着我们的生活方式和工作模式。”,可以看到项目返回内容如下:
文本转语音成功,文件保存路径:D:\idea_space\SpringAICode\SpringAIAudio\src\main\audio-output\tts-1750sss224.mp3
检查对应的目录找到转换的mp3播放后可以听到对应输入的文字已经被转换成语音。
音频转文字
Spring AI 提供了OpenAiAudioTranscriptionModel类实现通过Open AI 的Whisper 模型将音频转换成文字,输出的格式可以为json, text, srt, verbose_json, vtt。
如下案例中在“SpringAIAudio”项目中创建对应Controller和Service实现语音转文字操作。
1) 创建SpringBoot项目
这里使用“SpringAIAudio”项目,无需重新创建。
2) 配置resources/application.properties
在resources/application.properties文件中追加了“语音转文字”的whisper模型:
spring.application.name=SpringAIAudio
#文本转语音文件存放的路径
tts.audio-output-dir=D:\\idea_space\\SpringAICode\\SpringAIAudio\\src\\main\\audio-output
#使用 Open AI 相关模型,实现文字转语音功能、语音转文字功能
spring.ai.openai.base-url=https://api.uchat.site/
spring.ai.openai.api-key=sk-xxx...P1HwVlJDjAQDACCPx8A
#使用 Open AI 相关模型,实现文字转语音功能
spring.ai.openai.audio.speech.options.model=tts-1
#指定合成的语音,可以设置为alloy, echo, fable, onyx, nova 和 shimmer
spring.ai.openai.audio.speech.options.voice=alloy
#使用 Open AI 相关模型,实现语音转文字功能
spring.ai.openai.audio.transcription.options.model=whisper-1
注意:“tts.audio-output-dir”配置项为用户自定义配置参数,指定的目录中存储之前生成的mp3音频文件。
3) 创建Service包并创建TranscribeService类
在“SpringAIAudio”项目中创建“service”包,在该包下编写“TranscribeService.java”类,该类中实现transcribeFromFile方法来将mp3音频文件转换成文字。
import org.springframework.ai.audio.transcription.AudioTranscriptionPrompt;
import org.springframework.ai.audio.transcription.AudioTranscriptionResponse;
import org.springframework.ai.openai.OpenAiAudioTranscriptionModel;
import org.springframework.ai.openai.OpenAiAudioTranscriptionOptions;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.core.io.FileSystemResource;
import org.springframework.core.io.Resource;
import org.springframework.stereotype.Service;
import java.io.File;
@Service
public class TranscribeService {
// 注入 OpenAI 音频转录模型的对象
@Autowired
private OpenAiAudioTranscriptionModel transcriptionModel;
/**
* 从文件系统中读取配置目录下的 mp3 文件进行转录,并返回对应文本
* @param fileFullPath mp3 文件全路径
* @param options 转录时的可选参数(语言、格式等)
* @return 转写后的文字结果
*/
public String transcribeFromFile(String fileFullPath, OpenAiAudioTranscriptionOptions options) {
// 根据传入路径构造 File 对象
File file = new File(fileFullPath);
// 校验文件存在且是普通文件,否则抛出异常
if (!file.exists() || !file.isFile()) {
throw new IllegalArgumentException("文件不存在: " + file.getAbsolutePath());
}
// 将 File 封装为 Resource 对象,适配模型输入
Resource audio = new FileSystemResource(file);
// 创建转录请求提示对象,包含音频资源和转录选项
AudioTranscriptionPrompt prompt = new AudioTranscriptionPrompt(audio, options);
// 调用模型处理请求,返回响应对象
AudioTranscriptionResponse resp = transcriptionModel.call(prompt);
System.out.println("response: " + resp.toString());
// 从响应中获取第一条结果的文字输出并返回(Whisper 通常只返回一条)
return resp.getResults().get(0).getOutput();
}
}
4) 创建Controller包并创建TranscribeController类
在“SpringAIAudio”项目中创建“controller”包,在该包下编写“TranscribeController.java”类,该类中实现transcribe方法,该方法会将指定目录下的mp3文件传入到TranscribeService.transcribeFromFile方法将语音转换成文本。
@RestController
@RequestMapping("/ai")
public class TranscribeController {
@Autowired
private TranscribeService service;
// 从应用配置中读取音频目录,用来存放待转录的 mp3 文件
@Value("${tts.audio-output-dir}")
private String audioOutputDir;
// 定义 GET 类型的 /ai/transcribe 接口,返回转录结果
@GetMapping("/transcribe")
public ResponseEntity<Map<String, String>> transcribe() {
// 创建 File 对象,指向配置的音频目录
File dir = new File(audioOutputDir);
if (!dir.exists() || !dir.isDirectory()) {
return ResponseEntity.badRequest()
.body(Map.of("error", "目录不存在或不是文件夹: " + audioOutputDir));
}
// 列出所有后缀为 .mp3 的文件
File[] mp3Files = dir.listFiles((d, name) -> name.toLowerCase().endsWith(".mp3"));
if (mp3Files == null || mp3Files.length == 0) {
return ResponseEntity.ok(Map.of("message", "目录下没有 MP3 文件"));
}
// 构建 OpenAI 转录选项:文本格式、温度设为 0、语言为中文(zh)
OpenAiAudioTranscriptionOptions opts = OpenAiAudioTranscriptionOptions.builder()
.responseFormat(OpenAiAudioApi.TranscriptResponseFormat.TEXT)// 设置输出为文本
.temperature(0f)// 设置温度为 0,取值范围为 0–1,确保输出稳定,越大不确定度越高
.language("zh")//指定中文音频
.build();
Map<String, String> results = new HashMap<>();
for (File f : mp3Files) {
String relPath = f.getName(); // 使用文件名作为 classpathLocation
try {
// 调用服务进行转录
String text = service.transcribeFromFile(f.getAbsolutePath(), opts);
results.put(relPath, text);
} catch (Exception e) {
results.put(relPath, "FAILED: " + e.getMessage());
}
}
// 返回所有文件的转录结果
return ResponseEntity.ok(results);
}
}
5) 启动项目并测试
启动项目后,浏览器输入“http://localhost:8080/ai/transcribe”,可以看到项目返回内容如下,已经将音频正确的转换成文字。
{
"tts-1750xxx74224.mp3": "在这个信息化时代,人工智能技术深刻地改变着我们的生活方式和工作模式。\n"
}
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 4
4 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)