第二篇:ES 核心原理 + 实战:搞懂倒排索引,再也不怕面试官问了
引言
上一篇我们踩完了 ES 安装的所有坑,成功跑通了第一个搜索服务。很多同学可能会好奇:ES 到底是怎么做到毫秒级搜索的?为什么同样是查数据,它比 MySQL 快这么多?
答案就是 ES 的灵魂 ——倒排索引。今天我就用 “查字典” 这个大家都懂的例子,把倒排索引讲透,再带大家实战 IK 分词器和字段映射,保证看完不仅能懂,还能直接用到项目里!
一、ES 的灵魂:倒排索引到底是什么?
先问大家一个问题:你查字典的时候,是从第一页开始翻,直到找到你要的字吗?
当然不是!我们都是先查目录(拼音或部首),找到这个字对应的页码,再直接翻到那一页。
这就是倒排索引的核心思想!我们来对比一下:
-
正排索引:文档 → 关键字(从第一页翻字典,先拿到文档,再找里面的关键字)
-
倒排索引:关键字 → 文档(先查目录找到关键字,再找到包含这个关键字的所有文档)
举个实际的例子
假设我们有两篇文档:
-
文档 1:
Python从入门到放弃 -
文档 2:
Java从入门到精通
ES 会先对这两篇文档进行分词,得到下面的倒排索引表:
|
关键字(Term) |
包含该关键字的文档 ID |
|
Python |
1 |
|
Java |
2 |
|
入门 |
1, 2 |
|
放弃 |
1 |
|
精通 |
2 |
当用户搜索 “入门” 时,ES 直接去倒排索引表里找 “入门” 这个关键字,瞬间就能知道文档 1 和文档 2 都包含它,然后返回结果。
而如果用 MySQL 的like '%入门%',它会把所有文档都读一遍,逐个检查是否包含 “入门” 两个字,速度自然天差地别。
倒排索引的小细节
-
分词列表(Term)是不重复的,比如 “入门” 只会出现一次
-
停用词(的、地、得、a、an、the)不会被加入分词列表,因为它们没有实际搜索意义
-
不需要搜索的字段(比如图片 URL)不会参与分词,节省空间
二、中文分词神器:IK 分词器的安装与自定义
ES 默认的分词器对中文很不友好,它会把 “我爱中国” 分成 “我”、“爱”、“中”、“国” 四个单字,完全不符合我们的搜索习惯。
这时候就需要用到IK 分词器,它是目前最流行的中文分词器,支持两种分词模式:
-
ik_smart:粗粒度分词,适合搜索时使用(比如 “清华大学” 会分成 “清华大学”) -
ik_max_word:细粒度分词,适合写入数据时使用(比如 “清华大学” 会分成 “清华大学”、“清华”、“大学”)
1. 安装 IK 分词器
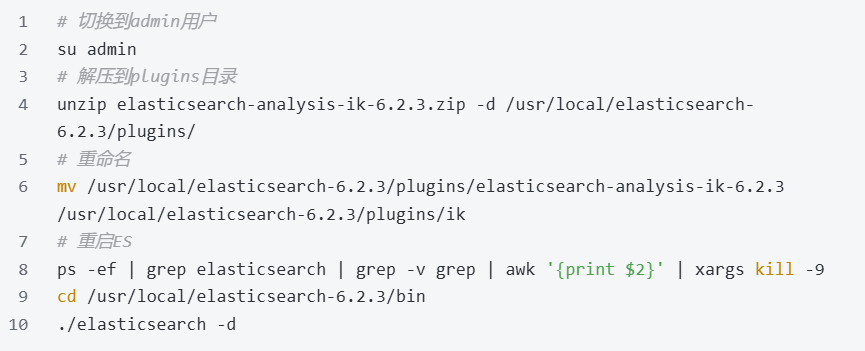
超级简单,只要把 IK 分词器的压缩包解压到 ES 的plugins目录下,并重命名为ik即可:
2. 自定义词典
IK 分词器虽然强大,但还是会有一些网络热词或者专业术语识别不出来,比如 “奥里给”、“ES 入门”。这时候我们可以自定义词典:
-
编辑
/usr/local/elasticsearch-6.2.3/plugins/ik/config/IKAnalyzer.cfg.xml

-
在
main.dic里添加你想要的新词,每行一个:

-
在
stopword.dic里添加你想要过滤的停用词:

✅ 注意:词典文件必须保存为UTF-8 编码,否则会乱码!修改完重启 ES 生效。
三、字段(Field)详解:写对映射,搜索效率翻倍
ES 的字段(Field)相当于 MySQL 的列,字段类型和属性的设置直接影响搜索的效率和准确性。
1. 常用字段类型
|
类型 |
说明 |
|
text |
会被分词,适合存储长文本(比如课程描述、文章内容) |
|
keyword |
不会被分词,适合存储精确值(比如手机号、邮箱、分类 ID) |
|
integer |
整数类型 |
|
long |
长整数类型 |
|
float |
单精度浮点数 |
|
double |
双精度浮点数 |
2. 核心字段属性
-
type:字段的数据类型,这是最基础的属性 -
analyzer:写入数据时使用的分词器,一般设为ik_max_word -
search_analyzer:搜索时使用的分词器,一般设为ik_smart -
index:是否为该字段建立倒排索引,不需要搜索的字段设为false,节省空间 -
_source:是否存储该字段的原始值,不需要展示的字段可以排除
3. 字段属性设置标准(记住这三条就够了)
-
type:看分词是否有意义。比如 “课程名” 分词有意义,用
text;“课程 ID” 分词没意义,用keyword -
index:看是否需要搜索。比如 “图片 URL” 不需要搜索,设为
false -
_source:看是否需要展示。比如一些内部字段不需要返回给前端,可以排除
实战:创建一个合理的 Type 映射
发送 POST 请求到 http://192.168.61.135:9200/java06/_course/_mapping:

四、ES 客户端与 Spring Boot 整合
最后说一下 Java 项目中怎么使用 ES。ES 提供了两种客户端:
-
TransportClient:基于 TCP 协议,ES 8.0 后会被删除,不推荐使用 -
RESTHighLevelClient:基于 HTTP 协议,官方推荐使用
在 Spring Boot 项目中,我们可以直接使用启动器:

然后在配置文件中指定 ES 的地址,就可以通过ElasticsearchRestTemplate来操作 ES 了,非常方便。
五、面试高频考点总结
-
ES 为什么比 MySQL 快?核心是倒排索引
-
正排索引和倒排索引的区别?
-
IK 分词器的两种模式及使用场景?
-
主分片数量为什么创建后不能修改?
-
text 和 keyword 的区别?
六、写在最后
ES 作为现在最流行的全文检索引擎,已经成为 Java 后端开发的必备技能。很多同学觉得 ES 难,其实是被它的概念吓到了 —— 只要搞懂了倒排索引这个核心,其他的都是水到渠成。
下一篇我会带大家做一个完整的课程搜索功能,从前端输入关键词到后端 ES 查询,一步步实现一个生产级别的搜索接口,敬请期待!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)