ai时代企业适用的一体化方案(作为设计方向的借鉴)
背景:
先回答问题,一体化的有必要自研吗?
结合我的部分企业场景(在ai背景下)
- 合规要求高, 需要(金融、医疗、政务、上市企业) → 需要统一审计、统一权限、统一数据治理。
- 年营收超过5亿或员工超过500人→ 管理复杂度已达临界点,一体化带来的标准化收益远高于定制成本。
-
上线一个新功能需要协调3个以上团队/系统变更 → 开发运维割裂,需要一体化DevOps+应用架构。
-
业务系统超过5个且互不相通 → 数据孤岛严重,手工对账成本高,必须一体化打通。
总结下:合规风险要求 或者 有可量化的效率, 这两个踩中一点 就有必要去搭建了,
(ps:购买的场景是新的业务线,评估之前流程为0, 并且没有历史的包袱流程在, 那么就可以购买)
需求背景:
有CI/CD流程, 有统一权限的平台和sdk的封装, web3/增长/金融/基建/大数据 等等团队的前后端项目,团队比较多,变更涉及 工单提交, 会议沟通,建群, 项管推流程,运维管理网络配置 分配域名等, 环节松散, 人工参与且不成体系
目标:
设定需求后->需求管理->分支管理->ci/cd->发布计划->变更管理->可观测->故障管理
架构图流程:
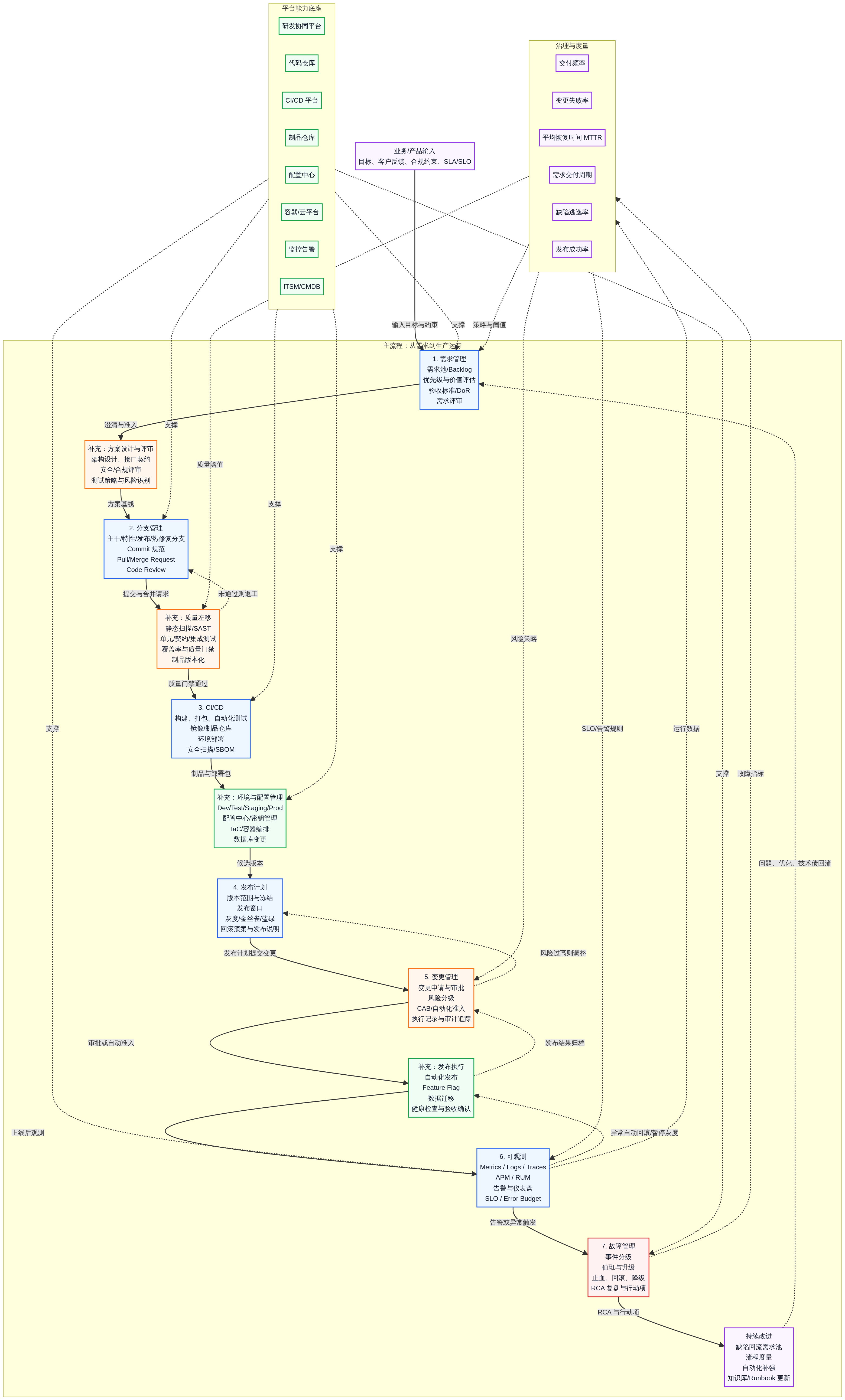
解决的问题是:
- 环境逃逸: 冲突不断,环境分支不断出现污染, 分支管理混乱
- 相同故障重复出现
- 需求和分支和发版不挂钩出现的发布环境的混乱
- 发布记录遗漏,数据孤岛, 复盘的时候困难, 故障追踪不友好
- 减轻团队认知负担, 平台太多, 上手困难
落地模块:
模块1:统一门户与权限中心
-
功能:单点登录、集中权限申请与审批、角色与资源绑定(应用/集群/中间件)、操作审计。
-
价值:避免多系统跳转,权限可追溯。
模块2:应用全生命周期管理
-
功能:应用注册、代码仓库集成、CI模板与流水线、制品管理、配置管理、版本管理。
-
价值:从创建代码到产出二进制/镜像的一站式管理。
模块3:容器化交付与集群治理
-
功能:多集群管理、Helm模板、容器权限控制(授权/命令策略)、应用发布/回滚/重启/扩缩容、发布执行可视化(滚动/灰度)、工单审批流。
-
价值:将K8s复杂操作产品化、工单化、可观测。
模块4:发布计划与协同
-
功能:项目/版本维度的发布窗口管理、需求范围关联、多应用发布编排、多级审批链、步骤执行跟踪、历史审计。
-
价值:多人多应用大型协作流程固化为可执行计划。
模块5:资源与中间件管理
-
功能:主机资产、服务树(组织/业务拓扑)、资源申请流程、中间件实例目录与部署视图。
-
价值:统一资源台账,避免资产散落。
模块6:可观测与工单治理
-
功能:监控告警(含业务指标)、日志检索与回捞、调用链探针管理、工单系统(所有高风险操作纳管为票据,待办/审批/全量查询)。
-
价值:事前预警、事中定位、事后审计闭环。
重点几个环节的说明:
分支管理:
应用全生命周期管理-> 比如是gitlab 此时为了把流程接入一体化, 需要把open api重写个微服务, 加上工单和审批: 工单沿用系统中的就行, 审批用的是沟通软件比如飞书, 接api做审批
发布计划(作为流程衔接的节点,是一体化比较重要的部分)
前端向导收集元数据 + 后端状态机驱动审批流 + 工单系统记录执行动作 + 关联容器发布工单
流程图:
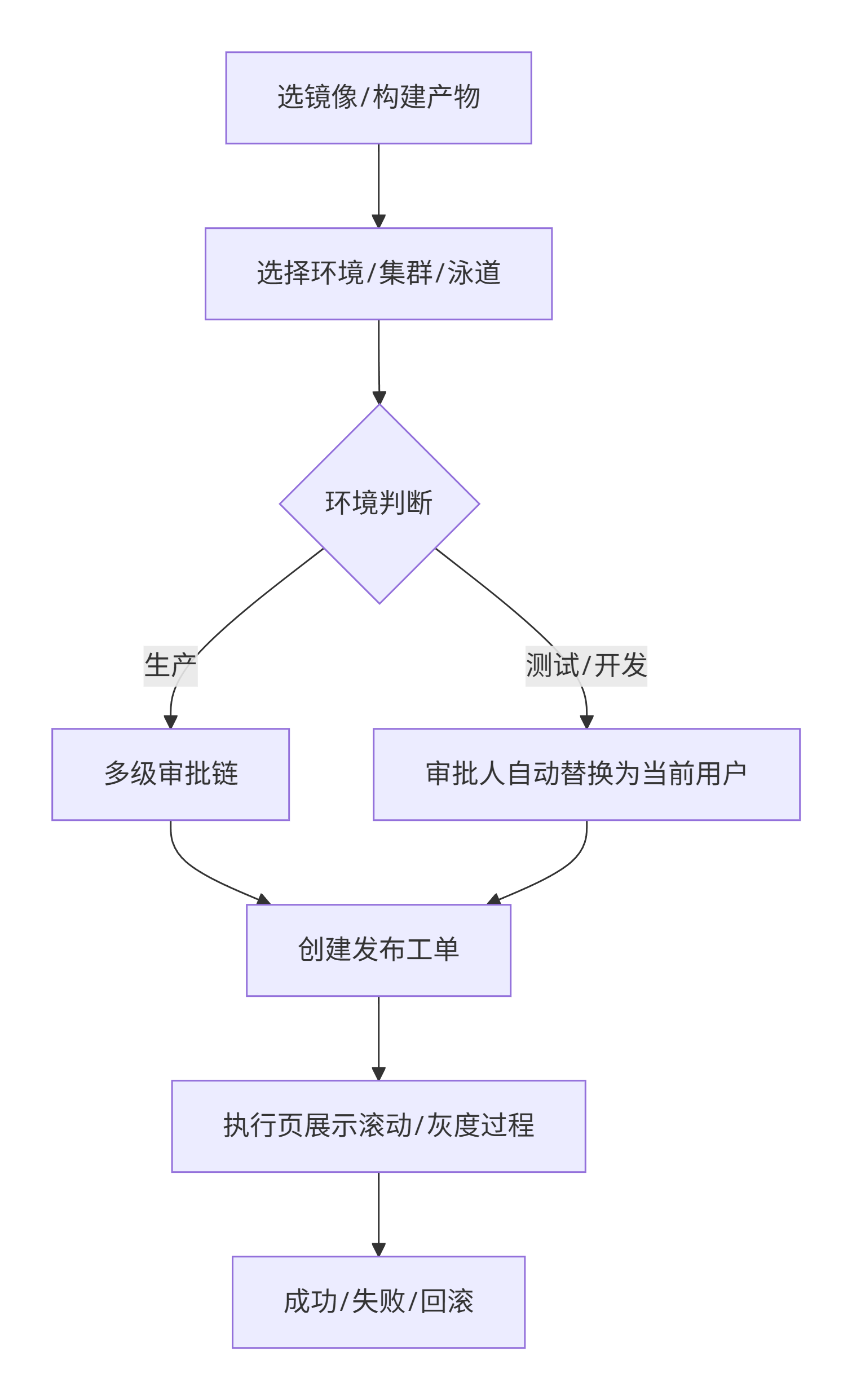
实现步骤(3步向导式创建)
-
基础信息:名称、上线时间、业务线、类型(常规/紧急)
-
需求范围:关联需求ID(可对接Meegle等外部系统),每个需求下挂载多个应用
-
审批链:定义研发→测试→运维多级审批人(测试环境自动将审批人替换为当前用户)
执行与跟踪
-
计划详情页:展示需求列表、每个应用的影响面/灰度方案/回滚方案、发布验收步骤(含执行人/状态/备注)
-
流程图视图:展示审批与发布步骤的DAG,当前节点高亮
-
步骤审核:顺序审批,任意节点拒绝即阻断;通过后状态自动流转
-
历史记录:保留所有变更与执行日志
与容器发布的联动
在容器发布弹窗中选择releasePlanId,将单次部署关联到发布计划,实现执行层(K8s)与治理层(计划)数据打通。
数据库/状态字段(典型)
-
计划状态:草稿、审批中、待执行、执行中、已完成、已取消
-
审批记录:审批人、审批时间、审批意见
-
步骤执行记录:步骤名、执行人、开始/结束时间、备注
数据模型简表(核心字段)
| 实体 | 关键字段 | 说明 |
|---|---|---|
| 集群 | clusterId, capacity, nodeList | 资源池 |
| Helm模板 | templateId, language, chartVersion | 部署范式 |
| 容器权限记录 | user, namespace, action, commandPolicy | 授权+命令级控制 |
| 发布工单 | ticketNo, appId, env, cluster, imageTag, releasePlanId, approveStatus, deployStatus | 全流程追踪 |
| 发布执行详情 | stage, podStatus, eventMsg, canaryInfo | 实时状态 |
质检
阶段: ci阶段, 平台维护base ci脚本, 不同的项目类型有不同的base ci
静态分析与格式化: 项目ci中不同阶段的script中自发选择校验 比如我选择生产前端:ESLint + Prettier, Python项目使用Black + Flake8/Pylint,Go语言使用golangci-lint
AI智能审查: SonarQube的AI Code Assurance,对Java、JavaScript、Python等主流语言支持良好,可与IDE集成提供实时建议, 并且质检结果有现成的网页地址+第三方 LLM API做代码二次审查, 二次审查 仅仅把告警优先级作为warning放到发布计划中
自动化门禁: 审查的结果作为门禁, ai审查中完整的应该设立可反馈的agent, 依据规则引擎,去卡点, 决策出哪些是不能继续,需要立即退出ci,但是第一版,ai仅仅设立上下文, 对金融场景的高频异常 做出评判, 然后阻断ci, 报告会发在一体化平台上, 就在分支管理的部分, 因为mr是通过分支管理提出来的, 所以关联的ci可以理解反应在分支管理中,做人工审查, 人工如果认为没问题, 可以强制ci, 也就是下一轮会跳过ai审查。
ps: 企业落地首先考虑的是: AI审查会泄露我们的代码机密吗?
私有部署成本高 后期维护优化模型,都有成本, 最方便的是购买外部llm企业版, 例如gemini 按照官方的说法,是保证数据隔离和私有的
变更管控(从安全性上非常重要)
发布计划是针对代码层面的一体化
但是对于资源类型的变更, 一体化中需要加入变更管控,主要针对中间件资源,云资源做变更治理, 总结一句话就是记录变更
但是如果仅仅是记录 是没有太多价值的 roi也低, 所以完善的变更管控, 是有open api的 搭配中间件资源平台 比如nacos xxljob等重构平台, 对接变更管控open api 做到管理
举例:
nacos出现冲突问题,会丢失记录, 并且复盘困难, 止血也不方便, 此时的解决方案就是重写nacos客户端, 假如审批流程, 卡点全量发布和灰度发布 并且自动提交变更单, 走审核, 此时在系统层面, 通过防碰撞的方式+工单状态校验的方式,来解决这个问题,此方案达到的效果就是可以完全让nacos发布做到可控并且权限不会膨胀,不会出现混乱的情况 也可以直接通过变更单,快速止血
可观测(不能少)
链路追踪的数据来源, 也是止血的依据, 一体化的设计中, apm是发布之后,发布看板里面这个应用的对应的一个可视化窗口, 点击进入apm 就可以看到最新的观测数据,可以直接看服务状态是否健康
指标监控(Metrics)
-
基础设施指标:CPU、内存、磁盘、网络IO、节点健康
-
容器指标:Pod CPU/内存、重启次数、就绪/存活探针状态
-
应用指标:QPS、延迟(P50/P90/P99)、错误率、饱和度(如连接池、队列长度)
-
业务指标:订单量、支付成功率、登录次数等自定义埋点
-
资源画像:资源使用趋势、闲置/浪费识别、成本分摊
资源画像往后衍生的是成本治理, 还可以假如agent做定期巡检 和开关机识别和遥控, 这个指标的重要性是针对, 客户百万的来说的,服务器众多, 这个治理可以给企业每个月节省 几十万到上百万不等,因为服务器部署的不规范 未治理 在未来业务的增长期 一定会成为一个卡点, 因为成本太高
容器指标 + 基础设施指标 + 应用指标是作为后面衍生的巡检和故障止血的一个核心数据
告警指标: 无论前后端, 链路的完整是告警及时的前提, 也是为了维持服务稳定必须要的兜底
定期巡检分为四块:
- 中间件巡检: 健康度检查,看消息或者集群的情况, 巡检结果也会通过飞书机器人发到工作群,优先级高的会作为告警直接发送责任人
- 交互巡检: 使用ai巡检, 移动端和web端都通过构建的ui自动巡检平台, 主要巡检的点是核心业务交互: 比如对于交易的转账 下单, 基础操作, 以前是测试同学人工做, 现在可以自动巡检平台对固定场景 定时巡检 并且接入报告很告警
- 定期压测巡检,频率和影响面不会太大, 主要对核心的几个接口做定期巡检, 压测有专门的压测平台 无论是短链接 长连接或者dubbo都有压测场景, 在非繁忙期, 开启定期巡检, 对阈值的指标 给出告警, 通知开发及时介入, 同时也是为了当流量来的时候 能接的住
- 资源巡检: 成本治理的一部分, 上面也提到过主要用到的指标是资源画像,作为一体化的系统的原因也是因为只有统一的权限和资源申请, 才能对资源做到绝对的掌控,否则对于企业来说这个开销是非常大的
ps: apm平台的数据源来源于服务端上报,大前端(web+移动端)上报,prometheus和其他运维组件上报,云服务商监控数据等
其他:
对于其他模块各自衍生的比如
快速止血(要保证止血正确,所以对agent要能够足够的收敛,设计可规则引擎), 迭代步骤的话, 前期可以先在apm中集成一个open api用外部llm 对观测数据 给出报告结果,这个报告是给开发和产品看的, 表现形式可以是日志数据和图标(chart这块主要给产品看的, 例如了解投放区域的使用情况, 为后面怎么调整资源作为数据源)
管控智能化: harness agent 建立晚上的风控指标, 对于迭代周期块的, 应该碰到过, 因为错误配置文件,或者配置信息导致的线上事故, 而这个事故一方面通过上面的变更管控可以都到治理, 另一方面结合风控智能体可以提前拦截,和变更管控一起把控风险
总结
上面落地模块 也是将来 一个成熟的基建 应该去落地和关注的。
一体化作为基建的一部分,实现以下几个目的:
省钱: 运营成本省钱, 开发效率上去了,投入的人力少了,也是变相的创收
维稳: 这个非常重要, 无论服务,前后端应用,资源, 维稳是业务增长的基石,当ai出来的代码或者人工+ai的代码成为屎山代码,一体化的作用一方面去让他可控,减少风险, 另一方面也是加快业务迭代,快速放出产品,抢占市场

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)