RAG:PDF解析难在哪,主流方案是什么
提示词优化再优化,模型一换再换,从固定chunk到语义动态chunk,单一或多路召回,粗排、精排、前置后置过滤、混合检索等等策略,回头发现只能是垃圾进,垃圾出。
文档格式设计
我们常见的文档格式中DOCX、HTML 和 PDF 是完全不同的三种设计。
DOCX:内容优先,渲染交给应用程序
DOCX 本质是一个 ZIP 压缩包,解压后得到一系列 XML 文件,明确声明内容的语义结构,由应用程序决定如何渲染。
解析 DOCX 的程序遍历 XML 树,语义是显式编码在文件里的,解析过程不需要任何空间推断。
HTML:语义标签 + 层叠样式,内容与表现分离
HTML 同样以语义为核心,比如,<h1> 到 <h6> 声明标题层级,<table>/<tr>/<td> 声明表格结构。CSS 样式是可以完全覆盖元素的视觉表现,虽然一个 <h1> 可以被渲染成极小的字号,但它在语义上依然是一级标题。
解析 HTML 是读取标签的问题,而非推断视觉关系的问题。
PDF:渲染优先,内容服务于像素
PDF(Portable Document Format)由 Adobe 于 1993 年发布,基于 PostScript 的子集演化而来,本质是一套页面描述语言(Page Description Language)。
PDF解决的问题是在实现文档的跨平台、跨设备的可移植性,确保无论在什么操作系统、什么打印机(或屏幕)上,文档的布局和字体渲染保持一致。
PDF 没有段落、没有标题、没有表格这些语义概念。有的只是坐标、字形(glyph)、线段、颜色,以及绘图操作符序列。
解析器需要自己去推断这些线段和文字之间的空间关系,才能还原出表格结构,而这种推断在合并单元格、多级表头的情况下很容易出错。
PDF 结构
一个 PDF 文件由四个部分构成:Header、Body、Cross-Reference Table、Traile。

Body 是核心,由大量 COS 对象(Carousel Object System)组成,包括:
| 对象类型 | 作用 |
|---|---|
| 字典(Dictionary) | << /Type /Page /MediaBox [...] >>描述结构 |
| 流(Stream) | 实际内容数据 |
| 数组(Array) | 页面树、字体列表等 |
| 字符串(String) | 文本内容 |
| 间接引用(Indirect Reference) | 50R表示引用第5号对象 |
xref 表是 PDF 的索引,记录每个对象在文件中的字节偏移量。PDF 读取器通过 xref 实现随机访问,可以直接跳转到任意对象而无需扫描整个文件。
文字内容存储在每个页面的内容流(Content Stream)中,通过操作符序列描述渲染指令。字体、图像等资源通过资源字典(Resource Dictionary)以间接引用的方式关联到页面。
结构性解析难点
基于上述格式,PDF 解析有几个结构性问题:
无显式阅读顺序
PDF 中的字符对象按渲染顺序存储,不是阅读顺序。对于单栏文档,两者通常一致。但对于双栏学术论文,PDF 生成工具可能先写完左栏所有文字再写右栏,也可能按视觉从左到右逐行交替写入,取决于生成工具的具体实现。解析器必须基于字符坐标重建阅读顺序,对于任意复杂度的多栏布局,没啥太好的方案。
表格无数据结构
PDF 表格是用线段和坐标定位的文字在视觉上模拟出来的。解析器需要检测线段并判断是否构成表格边框,根据交点确定单元格边界,将字符分配到对应的单元格坐标,处理合并单元格(内部线段缺失导致边界推断失败)。任何一步出错都会导致表格结构崩溃,合并单元格是最高频的失败场景。
字体编码映射
PDF 存储的是字体内部的字形 ID(glyph ID),而非 Unicode 字符。解析器需要通过字体的 ToUnicode CMap(Character Map)将字形 ID 映射为 Unicode 码位。
一般导致映射失败或不完整,比如部分 PDF 生成工具不嵌入完整的 ToUnicode 表;Type 3 字体允许完全自定义字形形状,解析器无法推断其 Unicode 含义;复合字体(CIDFont)的映射关系更复杂;文字可能被拆分为单个字形分别渲染,字形在字节流中不相邻,解析器需要靠坐标推断归属。这类问题的典型表现是提取结果出现乱码、词语内部有异常空格,或部分字符缺失。
扫描件无文本层
基于图像扫描的 PDF 内部没有任何文本流,只有光栅图像对象。对这类文档调用文本提取函数返回空结果。必须先对图像做 OCR 将像素还原为字符,才能进入正常的解析流程。
解析原理:从字节流到可读文本
常见的 PDF 解析方案可以归纳为三种不同的技术体系。
原生文本提取
这是最快、资源消耗最低的路线,适用于原生 PDF(由 Word、LaTeX、Adobe InDesign 等软件直接生成,含完整文本层)。
主要流程:
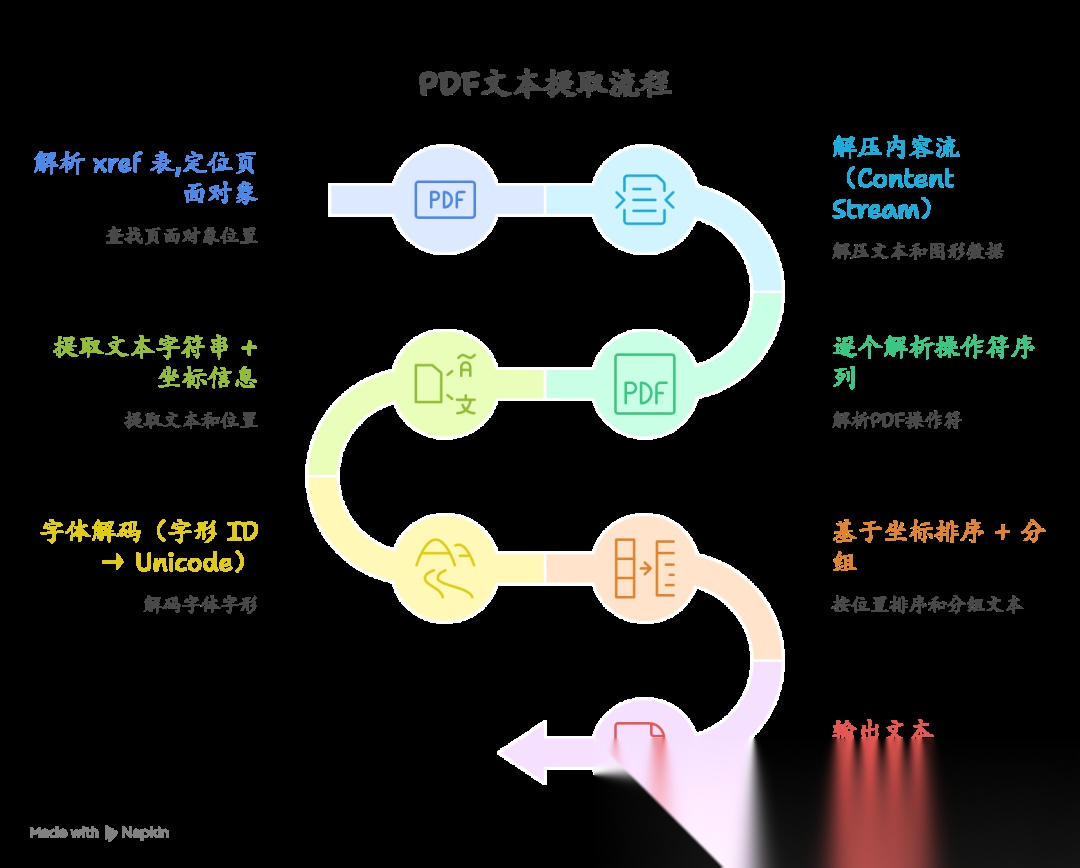
PDF 内容流的核心文本操作符序列如下:
BT % Begin Text object /F1 12 Tf % 选择字体 F1,大小 12pt 72 720 Td % 移动到坐标 (72, 720) (Hello, PDF!) Tj % 显示字符串 0 -14 Td % 移动到下一行(行距 14pt) [(Rag) 20 ( pipeline)] TJ % TJ 操作符:允许字形间距调整ET % End Text object
解析器逐条读取这些操作符,维护一个图形状态机(Graphics State Machine),追踪当前变换矩阵(CTM)、当前字体、文字矩阵(Text Matrix)等状态,最终得到每个字符的绝对页面坐标。
难点: 提取出来的是离散的字形点,解析器需要将它们重新组合成词、句、段落。PyMuPDF、pdfplumber 等库的核心差异就在于这个聚合算法的实现质量。
OCR
对于扫描件或图像型 PDF,必须先将页面光栅化为图像,再用 OCR 引擎识别字符。
主要流程:
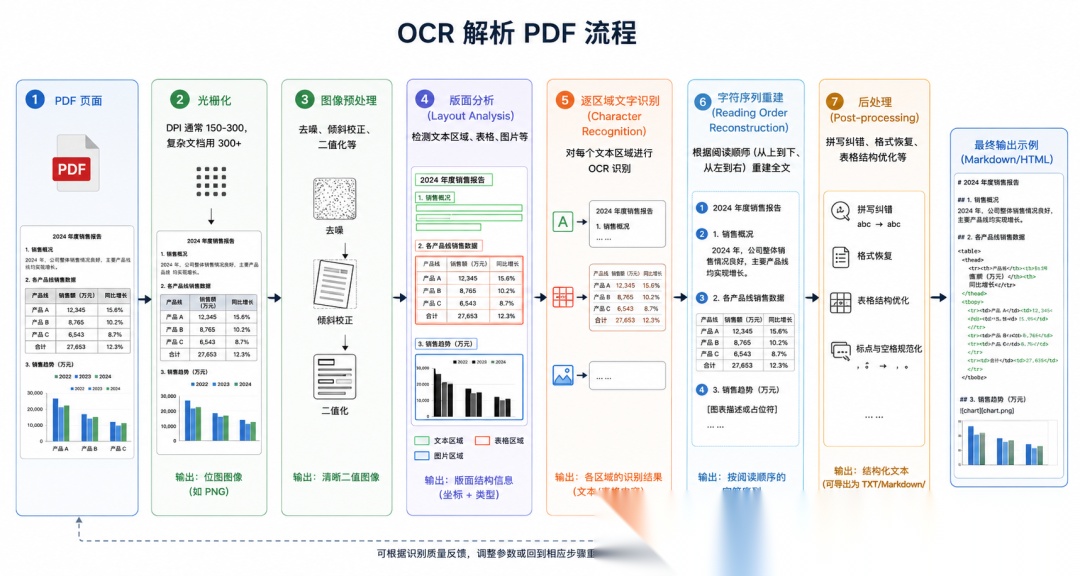
Tesseract 首先对二值图像做连通分量分析找到字符候选,然后用 LSTM 网络对文字行图像做序列到序列的转录。它预设文档是单栏的,多栏处理依赖启发式的列分割,在复杂布局上表现不稳定。
PaddleOCR 引入了独立的版面分析模型,在识别字符之前先检测文档区域,然后对每个区域独立 OCR。。
难点:
- • 表格识别:OCR 引擎识别出文字后,还需要额外的表格结构恢复模块才能还原单元格关系
- • 版面分析错误的级联效应:一旦区域检测出错,该区域内所有文字的阅读顺序都会乱序
视觉语言模型
VLM(视觉模型) 将整个页面作为图像输入,直接输出结构化文本,绕过了坐标提取、字体解码、阅读顺序重建等所有中间步骤。
主要流程:
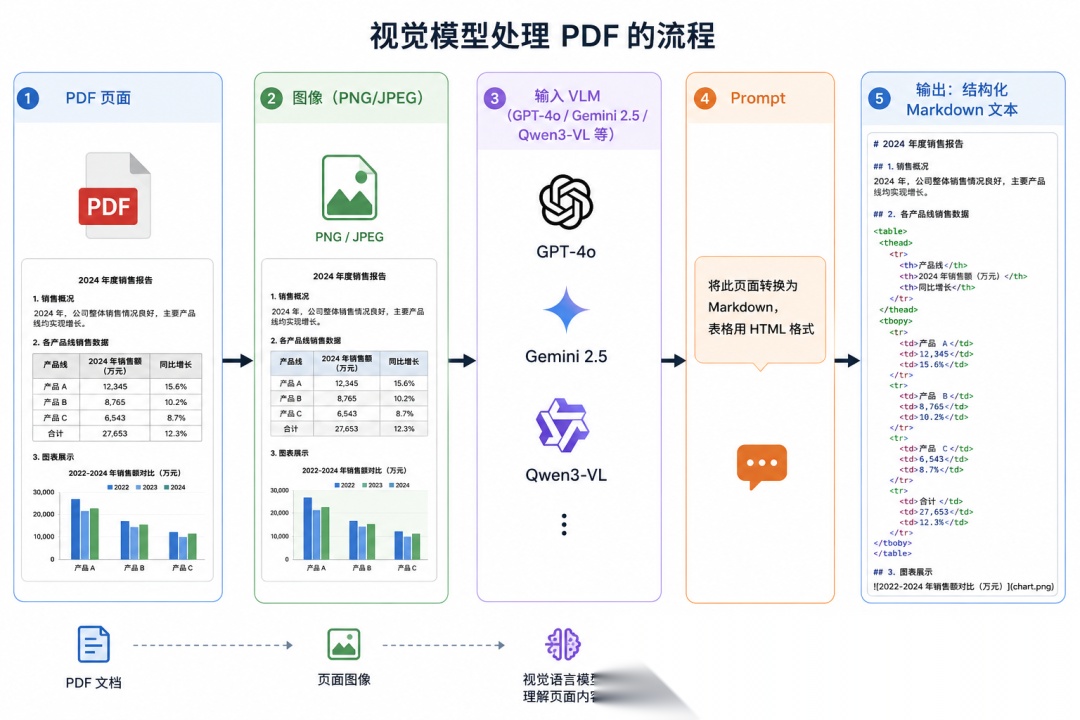
优势:
- • 自然处理复杂布局:多栏、嵌套表格、混排图文
- • 对合并单元格、跨页表格有理解能力
- • 直接输出语义结构,不需要后处理
难点:
模型会产生幻觉,另外就是成本问题;当然,老生常谈的数据合规和隐私某些时候也是个问题。
主流解析方案
目前常见的PDF 解析工具可以分为:
-
- 轻量文本提取库:PyMuPDF、pdfplumber、pypdf, 原生文本提取路线,速度极快
-
- AI 增强开源框架:Docling、MinerU、Marker-PDF , 集成布局分析模型,面向 RAG 场景
-
- 收费 API:各大云厂商都有提供API ,托管服务,开箱即用
-
- VLM 直接调用:GPT-4o、Gemini 2.5、Qwen3-VL ,最高理解能力,成本最高
轻量文本提取库
这类工具的基本上都是直接读取 PDF 内容流中的字符坐标,按坐标排序后输出文本;不做版面分析,速度相对来说非常极快,但处理能力受制于 PDF 格式本身的局限。
(我这里使用的是langchain封装的解析器)
PyMuPDF
底层基于 MuPDF 引擎,对 PDF 规范的高兼容性(说是说MuPDF 的渲染质量接近 Adobe Reader),文本提取准确率在格式规整的文档上表现稳定。
PyMuPDF4LLM 是面向 LLM 场景的扩展,在原始提取结果上加了 Markdown 格式化层,处理标题层级、列表识别,以及基于坐标的简单表格重建。
pdfplumber
基于 pdfminer.six,专注于表格提取,在页面上找到所有水平和垂直线段,计算交点,以交点网格为单元格边界提取文字。
对于有清晰边框线的表格,效果很好。对于无线框表格(靠列间距对齐的纯文本表格)或有合并单元格的表格,效果很差。
(https://docs.langchain.com/oss/python/integrations/document_loaders#pdfs)
AI 增强开源框架
这类工具在文本提取的基础上,引入了布局分析模型对页面进行区域分类,能处理复杂版面问题。
Docling
Docling 底层使用 PyMuPDF 做文本提取获取字符坐标,中间层用 DocLayNet 布局分析模型将页面划分为标题、段落、表格、图片等语义区域,上层用 TableFormer 模型专门处理表格结构恢复。
Docling 引入了统一的中间表示 DoclingDocument,不是纯文本字符串,而是一棵完整保留层级结构的文档树,每个节点带有类型标签(标题/段落/表格/图片)、在文档层级中的位置、以及页面坐标。
这棵树可以导出为 Markdown、HTML、JSON 或 DocTags 格式,这个设计使得下游的分块逻辑可以直接按文档语义结构操作,而不是在纯文本上做启发式切割。
MinerU
MinerU 的架构以 PaddleOCR 作为字符识别引擎,配合 PDF-Extract-Kit 布局检测模型,在处理中文文档和包含 LaTeX 公式的学术论文上效果比较好。
Marker-PDF
Marker 是多格式统一入口,支持 PDF、DOCX、PPTX、XLSX、EPUB、HTML 以及各种图像格式,对需要统一处理异构文档库的场景有便利性优势。
商业 API
可以直接各大厂的API或者一些垂直领域的API,我这里就不再多余分析了。
VLM 直接调用
VLM 将 PDF 页面光栅化为图像后直接输入多模态模型,由模型输出结构化文本。直接就绕过了复杂的坐标提取、字体解码、阅读顺序重建的所有中间步骤,对多栏、嵌套表格、合并单元格、手写内容的处理能力是应该是最强的了。
| 场景 | 模型 |
|---|---|
| 综合最强(闭源) | Gemini 2.5 Pro |
| 综合最强(开源) | Qwen2.5-VL-72B、InternVL3 |
| 文档 OCR | Gemma 3、LLaMA 3.2 Vision、DeepSeek-OCR |
| 轻量部署 | Phi-4、Pixtral 12B、DeepSeek-VL2 |
| 中文场景 | Qwen2.5-VL、GLM-4.5V |
常见解析问题
RAG应用在生产环境中的PDF解析问题主要在解析层和内容层。
多栏混排导致阅读顺序错乱
问题描述
多栏布局是 RAG 解析中影响最大的单一问题。PDF 的物理存储顺序不保证阅读顺序,左栏和右栏的文字在内容流中可能交错排列。轻量解析库按存储顺序提取字符,不关心区域归属,导致左右栏文字被交织拼接,形成语义完全断裂的混合文本。
正确阅读顺序: [左栏] Introduction [右栏] Abstract [左栏] We propose... [右栏] Recent work...PyMuPDF 默认提取结果(部分文档): Introduction Abstract ← 从左栏跳到右栏第一行 We propose... Recent work... ← 又跳回左栏
LLM 处理这种交错文本时,看到的是两段完全无关内容的混合,无法推断语义关系,上下文理解质量大幅下降。
处理方案
按坐标排序是最基础的改善,对提取出的文字块按 y 坐标(从上到下)和 x 坐标(从左到右)重新排序,可以部分解决简单双栏问题,但对三栏以上、图文混排或非标准版式可能还是会出问题。
最好的解决方案是进行版面分析,比如先用布局检测模型(DocLayNet 或 PP-StructureV2 等)将页面划分为独立的文本区域,标记每个区域的类型和阅读顺序,然后按区域顺序拼接文字。
对于无法通过版面分析解决的极复杂版式(杂志排版、广告页面、非标准布局),那就得试试VLM了。
字体编码缺失导致乱码
问题描述
当 PDF 生成工具未嵌入完整的 ToUnicode CMap,或使用了自定义字体编码时,解析器无法将字形 ID 映射回 Unicode 字符,输出结果为乱码、方框(□□□□)或空白。比如:使用 Type 3 自定义字体、字体子集嵌入不完整、中文字体 Unicode 映射缺失、文档经过 PDF 优化压缩工具处理后编码表被裁剪。(可以用编辑器,比如cursor的,打开pdf,底部可以修改调整编码,然后就可以看到下面的内容~)
PDF 中显示:Attention Is All You NeedPyPDF2 提取:偛整匯數整數搔搔数搔數
处理方案
不同解析库对字体编码的处理能力存在差异,同一份出现乱码的 PDF,换用 PyMuPDF(MuPDF 引擎)可能正常提取,反之亦然。所以有时候可以先试试别的解析器。
如果多个解析器都无法正常提取,说明可能是字体映射信息在 PDF 层面确实缺失。此时绕过文本层、直接对页面图像做 OCR 是可行的替代方案,OCR 从像素识别字符,完全不依赖 PDF 内部的字体编码。
对于"视觉显示正常但文本提取乱码"的 PDF,最常见的就是字体编码缺失的情况,OCR 通常能比较好的解决。极少数情况下(例如 Type 3 字体 + 完全自定义字形形状),可能OCR 也无法正确识别,那就只能回到文档源头重新生成或寻找原始可编辑版本。
跨页内容断裂
问题描述
物理分页(基于纸张尺寸的固定分割)与逻辑分段(基于语义的可变分割)两者天然无法对齐。解析器按页面处理文档时,每个页面作为独立单元,跨越页面边界的内容被物理截断。
| 跨页类型 | 出现频次 | 可能导致的问题 |
|---|---|---|
| 段落跨页 | 常见 | 段落语义断裂,上下文不完整 |
| 句子跨页 | 一般 | 句子在页面边界处被截断,语义无法理解 |
| 表格跨页 | 一般 | 表头在一页,数据在下一页,行列关系丢失 |
| 图表与说明跨页 | 一般 | 图片和其对应说明文字被分离 |
| 列表跨页 | 一般 | 编号或项目符号列表被切断,后续条目失去上下文 |
| 代码块跨页 | 少见 | 代码缩进结构和上下文丢失 |
表格跨页影响比较大,比如表头行留在第1页末尾(有些复杂的可能注脚都占了很多内容~),数据行从第2页开始,解析器分别处理两页,输出的两段文字都缺乏完整语义。RAG 检索时若只命中其中一段,LLM 无法还原行列对应关系。
处理方案
段落和句子跨页的最常见的方案是分块阶段设置 overlap(相邻 chunk 之间保留若干 token 的重叠),可以确保跨页处的句子在某个 chunk 中是完整的。另外,就是语义分块(基于 embedding 检测语义边界后切割)效果更好。
表格跨页就不能依赖通用的 overlap 方法。可行方案是在解析阶段检测当前页是否以未结束的表格收尾(最后一个检测到的结构是表格行,但没有表格边框的结束信号),并将下一页开头的表格行与当前页合并后再处理。Docling 对这种场景有内置处理逻辑,MinerU 同样支持跨页表格连接。
版面分析也是解决跨页的比较好的方案。
页眉页脚污染索引
问题描述
页眉页脚在每一页重复出现,内容通常是文档标题、公司名称、页码、日期等。比如,一份100页的文档,相同或高度相似的页眉文字会出现 100次。这些内容一方面会产生大量近似重复的 chunk,另外一方面就是不同页的 chunk 因共享相同页眉而向量相似度偏高,影响检索的区分能力。
处理方案
位置过滤和跨页重复检测。
因为页眉页脚通常出现在页面顶部和底部固定区,所以过滤 y 坐标落在页面顶部 8%(这个具体数值具体调试着看看) 和底部 8% 区域内的文字块。这个方法对布局规整的文档效果稳定,对将页脚放在页面中下部的特殊排版可能过滤不足或过滤过度。
跨页重复检测就简单粗暴了。统计每行文字在全文档各页中出现的频率,将出现比例超过阈值(这个具体数值也得具体调试着看看)的行标记为重复内容并过滤。比如,可以遍历所有页面的文本,以行为单位统计跨页出现频次,频次 / 总页数超过阈值的行视为页眉或页脚候选,从所有 chunk 中移除。
图表信息丢失
问题描述
纯文本解析对嵌入 PDF 的图片、图表、流程图的处理结果是完全丢失的,在提取后不留任何内容,相关的引用文字在 RAG 中也就成了空引用。
处理方案
纯文本提取 + OCR 可以恢复图表中的文字内容(如表格、标注文字),但无法理解图表的视觉语义(趋势方向、比较关系、空间布局等等),这个时候唯一能解决就只有VLM。
先用文本解析构建索引并完成检索(一般来说文本内容足以定位相关页面),检索到相关页面后,将页面光栅化为图像再输入 VLM 进行深度理解,最后将文本内容与 VLM 输出结合生成回答。
参考文献与脚注处理
问题描述
参考文献和脚注在 PDF 中的物理位置与其被引用的位置相距较远,跟页脚还不一样的,解析器按页面顺序处理文档时,引用标记(比如,[1]、上标数字)所在的 chunk 和对应的参考文献/脚注内容所在的 chunk 会被分离到向量索引的不同位置。
脚注文字要么混入正文末尾,要么在页面分割时被截断丢失。比如,在法律和金融场景中,一般文档脚注常包含免责声明、例外条款丢失这些内容会导致 LLM 基于不完整信息生成误导性回答。
处理方案
版面分析模型能够区分正文区域和脚注区域,Docling 和 MinerU 的输出文档树中,脚注作为独立类型节点存在,可以选择将脚注内容附加到引用它的正文段落之后,或单独存储并在检索时通过元数据关联。
对于参考文献,完整的处理方案是在索引时解析引用链,将 [1] 对应的参考文献内容嵌入到引用它的 chunk 元数据中,检索时一并返回。这个方案在学术论文场景下效果最为明显,但实现复杂度高,需要先提取完整的参考文献列表并建立引用号到文献内容的映射。稍微简单点的方案是在检索后扩展上下文,也就是命中某个引用了 [1] 的 chunk 后,同时返回文档尾部参考文献章节的对应条目,由 LLM 综合两段内容生成回答。
标题层级在分块后丢失
问题描述
传统按 token 数固定分块的方式不感知文档层级结构,切割结果中每个 chunk 只包含该节的内容文字,不携带它在文档层级中的位置信息。
文档树的优势了吧?
处理方案
最简单的方法是在分块时,为每个 chunk 构建其在文档层级中的完整路径,然后作为元数据附加在 chunk 内容前。
复杂一点的方法是不按 token 数切割,而是按文档的语义边界(章节、小节)切割,确保每个 chunk 对应一个完整的语义单元,不跨越标题边界,但这需要解析器输出保留层级结构信息。
好像也有人使用父子 chunk 策略,用小 chunk(128-256 token)做 embedding 和检索,命中后返回其父节点(完整小节,512-1024 token)给 LLM 生成回答。检索基于小 chunk 的语义精度,生成基于大 chunk 的上下文完整性,两个目标分别优化。
结语
PDF 解析目前仍然没有完美解的解决方案。
格式的设计目的是根本原因,PDF 的页面描述语言架构导致语义信息在格式层面缺失,解析工具所做的,本质上都是在用启发式方法或统计模型还原这些缺失的语义。
总体来看,如果实际业务场景要求比较高,混合解析可能是折中的办法了,但是也会带来复杂度上升,特别是引入模型,还可能带来新的问题。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献217条内容
已为社区贡献217条内容

所有评论(0)