Day 21:端到端量化策略实战
·
Day 21:端到端量化策略实战
📋 目录
- 量化策略开发框架
- 策略评估指标体系
- 过拟合防范与验证
- 模型选择与特征工程
- 完整编程实战
- 项目报告撰写指南
1. 量化策略开发框架
1.1 量化策略开发流程
┌─────────────────────────────────────────────────────────────────────────┐
│ 量化策略开发标准流程
├─────────────────────────────────────────────────────────────────────────┤
│
│ 1. 数据获取 ──→ 2. 特征工程 ──→ 3. 模型训练 ──→ 4. 信号生成
│ ↓ ↓ ↓ ↓
│ 历史行情数据 技术指标因子 ML/DL模型 买卖信号
│
│ 5. 策略回测 ──→ 6. 风险评估 ──→ 7. 优化迭代 ──→ 8. 实盘部署
│ ↓ ↓ ↓ ↓
│ 绩效分析 夏普/回撤 参数调优 风险监控
│
└─────────────────────────────────────────────────────────────────────────┘
1.2 策略类型
| 策略类型 | 持仓周期 | 信号频率 | 适用模型 |
|---|---|---|---|
| 日频策略 | 1-5天 | 每日 | 随机森林、XGBoost |
| 周频策略 | 1-4周 | 每周 | 逻辑回归、SVM |
| 高频策略 | 分钟/秒级 | 实时 | LSTM、GRU |
1.3 策略开发原则
- 样本外测试:必须使用未参与训练的数据验证
- 避免前视偏差:只用历史信息做决策
- 考虑交易成本:滑点、手续费、印花税
- 风险控制:设置止损、仓位管理
2. 策略评估指标体系
2.1 核心绩效指标
| 指标 | 公式 | 含义 | 目标值 |
|---|---|---|---|
| 年化收益率 | (1+Rtotal)252/n−1(1 + R_{\text{total}})^{252/n} - 1(1+Rtotal)252/n−1 | 年化回报 | > 15% |
| 夏普比率 | Rp−Rfσp\frac{R_p - R_f}{\sigma_p}σpRp−Rf | 风险调整收益 | > 1.0 |
| 最大回撤 | maxt(peakt−valuet)\max_t (\text{peak}_t - \text{value}_t)maxt(peakt−valuet) | 最大亏损幅度 | < 20% |
| 胜率 | 盈利交易总交易\frac{\text{盈利交易}}{\text{总交易}}总交易盈利交易 | 预测准确性 | > 50% |
| 盈亏比 | 平均盈利平均亏损\frac{\text{平均盈利}}{\text{平均亏损}}平均亏损平均盈利 | 风险回报 | > 1.5 |
2.2 夏普比率详解
公式:
Sharpe=E[Rp−Rf]σp×252 \text{Sharpe} = \frac{\mathbf{E}[R_p - R_f]}{\sigma_p} \times \sqrt{252} Sharpe=σpE[Rp−Rf]×252
- $ R_p $:策略日收益率
- $ R_f $:无风险利率(通常用国债利率)
- $ \sigma_p $:日收益率标准差
解读:
| 夏普比率 | 评价 |
|---|---|
| < 0.5 | 较差 |
| 0.5 - 1.0 | 可接受 |
| 1.0 - 2.0 | 良好 |
| > 2.0 | 优秀 |
2.3 最大回撤
公式:
Drawdownt=Peakt−ValuetPeakt \text{Drawdown}_t = \frac{\text{Peak}_t - \text{Value}_t}{\text{Peak}_t} Drawdownt=PeaktPeakt−Valuet
Max Drawdown=maxtDrawdownt \text{Max Drawdown} = \max_t \text{Drawdown}_t Max Drawdown=tmaxDrawdownt
解读:
- 回撤越大,策略风险越高
- 心理承受:20%回撤是多数投资者的临界点
- 实盘需要控制单边下跌风险
2.4 其他评估指标
| 指标 | 公式 | 说明 |
|---|---|---|
| Calmar比率 | 年化收益 / 最大回撤 | 收益-风险比 |
| Sortino比率 | 下行风险调整收益 | 只考虑下跌波动 |
| 盈亏比 | 平均盈利 / 平均亏损 | 每次盈利能覆盖几次亏损 |
| 交易次数 | - | 影响过拟合判断 |
3. 过拟合防范与验证
3.1 过拟合的识别
信号:
- 训练集和测试集性能差距 > 10%
- 策略在优化期表现完美,实盘惨淡
- 交易次数过多,每笔收益微小
- 参数过度敏感
3.2 验证方法
| 方法 | 说明 |
|---|---|
| 时间序列交叉验证 | 保持时间顺序,递增训练集 |
| 滚动窗口验证 | 固定窗口大小,滚动测试 |
| 样本外测试 | 最后一段数据完全不用训练 |
3.3 防止过拟合的技巧
# 1. 使用正则化
model = XGBClassifier(reg_lambda=1.0, reg_alpha=0.5)
# 2. 限制模型复杂度
model = RandomForestClassifier(max_depth=10, min_samples_split=10)
# 3. 特征选择
selector = SelectKBest(k=20)
# 4. 早停
early_stop = EarlyStopping(patience=10)
4. 模型选择与特征工程
4.1 模型对比
| 模型 | 适合场景 | 优点 | 缺点 |
|---|---|---|---|
| 随机森林 | 中等数据量 | 抗过拟合、可解释 | 预测速度慢 |
| XGBoost | 大数据量 | 精度高、速度快 | 参数多 |
| LSTM | 序列数据 | 捕捉时序依赖 | 训练慢、需大量数据 |
4.2 特征工程
核心特征:
- 动量因子:过去N日收益率
- 均线因子:价格与均线的偏离
- 波动率因子:ATR、布林带宽度
- 成交量因子:成交量变化率、OBV
- 技术指标:RSI、MACD、KDJ
特征处理:
# 异常值处理
df = df[(df['return'] > df['return'].quantile(0.01)) &
(df['return'] < df['return'].quantile(0.99))]
# 标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 滞后特征
for lag in [1, 2, 3, 5]:
df[f'return_lag_{lag}'] = df['return'].shift(lag)
5. 完整编程实战
实战目标:
- 构建完整的量化策略开发流程
- 使用机器学习模型预测涨跌
- 构建交易信号并执行回测
- 计算绩效指标(年化收益、夏普比率、最大回撤)
- 对比买入持有策略
- 撰写项目报告
5.1. 导入必要的库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from pathlib import Path
import warnings
warnings.filterwarnings('ignore')
# 机器学习库
from sklearn.ensemble import RandomForestClassifier
from xgboost import XGBClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import TimeSeriesSplit, GridSearchCV
from sklearn.metrics import accuracy_score, classification_report, roc_auc_score
# 深度学习库
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense, Dropout
from tensorflow.keras.callbacks import EarlyStopping
# 预设样式
sns.set_style("whitegrid")
#启用LaTeX渲染(设为False避免LaTeX依赖)
plt.rcParams['text.usetex'] = False
# 设置中文显示
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['mathtext.fontset'] = 'dejavusans' # 或 'stix'
print("库导入成功!")
库导入成功!
5.2. 加载股票数据
def load_stock_data(ts_code):
"""加载股票数据"""
data_path = Path(r"E:\AppData\quant_trade\klines\kline2014-2024")
kline_file = data_path / f"{ts_code}.csv"
df = pd.read_csv(kline_file, usecols=["trade_date", "close", "vol"],
parse_dates=["trade_date"])\
.rename(columns={"trade_date": "date", "vol": "volume"})\
.sort_values(by=["date"])\
.reset_index(drop=True)
# 计算收益率
df['return'] = df['close'].pct_change()
# 技术指标
# RSI
delta = df['return'].fillna(0)
gain = delta.where(delta > 0, 0).rolling(14).mean()
loss = -delta.where(delta < 0, 0).rolling(14).mean()
rs = gain / (loss + 1e-10)
df['rsi'] = 100 - (100 / (1 + rs))
# 移动平均线
df['ma_5'] = df['close'].rolling(5).mean()
df['ma_10'] = df['close'].rolling(10).mean()
df['ma_20'] = df['close'].rolling(20).mean()
df['ma_ratio'] = df['close'] / df['ma_20'] - 1
# 波动率
df['volatility'] = df['return'].rolling(20).std()
# 成交量
df['volume_ma'] = df['volume'].rolling(10).mean()
df['volume_ratio'] = df['volume'] / df['volume_ma']
# 动量指标
for lag in [1, 2, 3, 5, 10]:
df[f'momentum_{lag}'] = df['return'].shift(lag).fillna(0)
# 目标变量:2日是否上涨
df['target'] = (df['close'].shift(-2) > df['close']).astype(int)
df = df.dropna()
return df
# 加载数据
ts_code = "300010.SZ"
# ts_code = "600519.SH"
df = load_stock_data(ts_code)
print(f"数据形状: {df.shape}")
print(df.head())
# 可视化
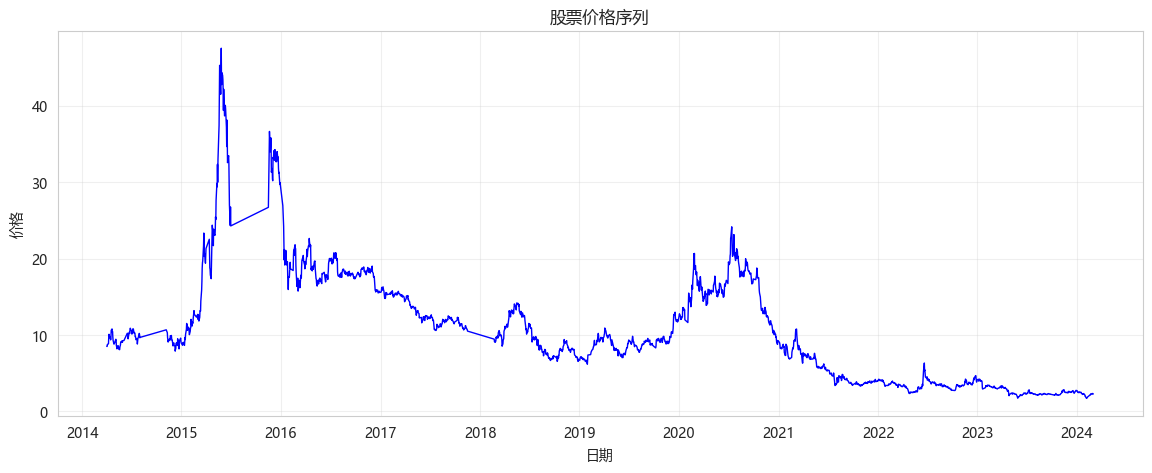
plt.figure(figsize=(14, 5))
plt.plot(df['date'], df['close'], 'b-', linewidth=1)
plt.xlabel('日期')
plt.ylabel('价格')
plt.title('股票价格序列')
plt.grid(True, alpha=0.3)
plt.show()
数据形状: (2175, 18)
date close volume return rsi ma_5 ma_10 \
20 2014-04-02 8.5044 86496.65 0.037375 61.331906 8.10432 8.38823
21 2014-04-03 8.4917 59217.59 -0.001493 57.254523 8.11370 8.37717
22 2014-04-04 8.7598 83069.87 0.031572 61.235533 8.34524 8.38525
23 2014-04-08 8.8407 54941.75 0.009235 53.740644 8.55892 8.37801
24 2014-04-09 9.7260 106636.11 0.100139 61.529692 8.86452 8.51592
ma_20 ma_ratio volatility volume_ma volume_ratio momentum_1 \
20 7.986205 0.064886 0.055523 109043.208 0.793233 0.054771
21 8.104750 0.047744 0.052651 97689.734 0.606180 0.037375
22 8.206055 0.067480 0.049123 93152.134 0.891766 -0.001493
23 8.277775 0.068004 0.044811 83983.009 0.654201 0.031572
24 8.391420 0.159041 0.049125 85804.603 1.242778 0.009235
momentum_2 momentum_3 momentum_5 momentum_10 target
20 0.022389 -0.099789 0.056608 0.004914 1
21 0.054771 0.022389 -0.042475 -0.010286 1
22 0.037375 0.054771 -0.099789 0.008916 1
23 -0.001493 0.037375 0.022389 0.026973 1
24 0.031572 -0.001493 0.054771 -0.063524 1
5.3. 特征工程与数据准备
# 特征列
feature_cols = ['rsi', 'ma_ratio', 'volatility', 'volume_ratio',
'momentum_1', 'momentum_2', 'momentum_3', 'momentum_5', 'momentum_10']
X = df[feature_cols].values
y = df['target'].values
# 按时间顺序划分(70%训练,15%验证,15%测试)
train_size = int(len(X) * 0.7)
val_size = int(len(X) * 0.15)
X_train = X[:train_size]
y_train = y[:train_size]
X_val = X[train_size:train_size+val_size]
y_val = y[train_size:train_size+val_size]
X_test = X[train_size+val_size:]
y_test = y[train_size+val_size:]
# 对应价格数据
prices_train = df['close'].iloc[:train_size].values
prices_val = df['close'].iloc[train_size:train_size+val_size].values
prices_test = df['close'].iloc[train_size+val_size:].values
print(f"训练集: {len(X_train)} 样本")
print(f"验证集: {len(X_val)} 样本")
print(f"测试集: {len(X_test)} 样本")
print(f"目标分布: {y.mean():.2%}")
# 标准化
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_val_scaled = scaler.transform(X_val)
X_test_scaled = scaler.transform(X_test)
训练集: 1522 样本
验证集: 326 样本
测试集: 327 样本
目标分布: 46.02%
5.4. 模型训练与对比
5.4.1 随机森林模型
print("="*60)
print("1. 训练随机森林模型")
print("="*60)
rf_model = RandomForestClassifier(
n_estimators=200,
max_depth=10,
min_samples_split=10,
min_samples_leaf=5,
random_state=42,
n_jobs=-1
)
rf_model.fit(X_train_scaled, y_train)
# 预测
rf_train_pred = rf_model.predict(X_train_scaled)
rf_val_pred = rf_model.predict(X_val_scaled)
rf_test_pred = rf_model.predict(X_test_scaled)
rf_test_proba = rf_model.predict_proba(X_test_scaled)[:, 1]
print(f"训练集准确率: {accuracy_score(y_train, rf_train_pred):.4f}")
print(f"验证集准确率: {accuracy_score(y_val, rf_val_pred):.4f}")
print(f"测试集准确率: {accuracy_score(y_test, rf_test_pred):.4f}")
print(f"测试集AUC: {roc_auc_score(y_test, rf_test_proba):.4f}")
============================================================
1. 训练随机森林模型
============================================================
训练集准确率: 0.9185
验证集准确率: 0.5123
测试集准确率: 0.5413
测试集AUC: 0.5268
5.4.2 XGBoost模型
print("="*60)
print("2. 训练XGBoost模型")
print("="*60)
xgb_model = XGBClassifier(
n_estimators=200,
learning_rate=0.05,
max_depth=6,
subsample=0.8,
colsample_bytree=0.8,
reg_lambda=1.0,
reg_alpha=0.5,
random_state=42,
eval_metric='logloss'
)
xgb_model.fit(X_train_scaled, y_train)
xgb_train_pred = xgb_model.predict(X_train_scaled)
xgb_val_pred = xgb_model.predict(X_val_scaled)
xgb_test_pred = xgb_model.predict(X_test_scaled)
xgb_test_proba = xgb_model.predict_proba(X_test_scaled)[:, 1]
print(f"训练集准确率: {accuracy_score(y_train, xgb_train_pred):.4f}")
print(f"验证集准确率: {accuracy_score(y_val, xgb_val_pred):.4f}")
print(f"测试集准确率: {accuracy_score(y_test, xgb_test_pred):.4f}")
print(f"测试集AUC: {roc_auc_score(y_test, xgb_test_proba):.4f}")
============================================================
2. 训练XGBoost模型
============================================================
训练集准确率: 0.9901
验证集准确率: 0.4785
测试集准确率: 0.5260
测试集AUC: 0.5505
5.4.3 LSTM模型
print("="*60)
print("3. 训练LSTM模型")
print("="*60)
# 创建序列数据
def create_sequences(data, labels, seq_length=10):
X_seq, y_seq = [], []
for i in range(len(data) - seq_length):
X_seq.append(data[i:i+seq_length])
y_seq.append(labels[i+seq_length])
return np.array(X_seq), np.array(y_seq)
SEQ_LENGTH = 10
X_train_seq, y_train_seq = create_sequences(X_train_scaled, y_train, SEQ_LENGTH)
X_val_seq, y_val_seq = create_sequences(X_val_scaled, y_val, SEQ_LENGTH)
print(f"LSTM训练集形状: {X_train_seq.shape}")
print(f"LSTM验证集形状: {X_val_seq.shape}")
# 构建LSTM模型
lstm_model = Sequential([
LSTM(64, return_sequences=True, input_shape=(SEQ_LENGTH, X_train_scaled.shape[1])),
Dropout(0.3),
LSTM(32, return_sequences=False),
Dropout(0.3),
Dense(16, activation='relu'),
Dense(1, activation='sigmoid')
])
lstm_model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# 早停回调
early_stop = EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True)
# 训练
lstm_history = lstm_model.fit(
X_train_seq, y_train_seq,
epochs=100,
batch_size=32,
validation_data=(X_val_seq, y_val_seq),
callbacks=[early_stop],
verbose=0
)
print(f"训练轮数: {len(lstm_history.history['loss'])}")
print(f"训练集准确率: {lstm_history.history['accuracy'][-1]:.4f}")
print(f"验证集准确率: {lstm_history.history['val_accuracy'][-1]:.4f}")
# 测试集预测(需要创建测试集序列)
X_test_seq, y_test_seq = create_sequences(X_test_scaled, y_test, SEQ_LENGTH)
lstm_test_pred = (lstm_model.predict(X_test_seq) > 0.5).astype(int).flatten()
lstm_test_proba = lstm_model.predict(X_test_seq).flatten()
print(f"测试集准确率: {accuracy_score(y_test_seq, lstm_test_pred):.4f}")
print(f"测试集AUC: {roc_auc_score(y_test_seq, lstm_test_proba):.4f}")
============================================================
3. 训练LSTM模型
============================================================
LSTM训练集形状: (1512, 10, 9)
LSTM验证集形状: (316, 10, 9)
训练轮数: 16
训练集准确率: 0.6065
验证集准确率: 0.5316
[1m10/10[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m1s[0m 33ms/step
[1m10/10[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 4ms/step
测试集准确率: 0.5174
测试集AUC: 0.5352
5.4.4 模型选择
# 模型性能对比
models_performance = pd.DataFrame([
{'模型': '随机森林', '测试准确率': accuracy_score(y_test, rf_test_pred),
'测试AUC': roc_auc_score(y_test, rf_test_proba)},
{'模型': 'XGBoost', '测试准确率': accuracy_score(y_test, xgb_test_pred),
'测试AUC': roc_auc_score(y_test, xgb_test_proba)},
{'模型': 'LSTM', '测试准确率': accuracy_score(y_test_seq, lstm_test_pred),
'测试AUC': roc_auc_score(y_test_seq, lstm_test_proba)}
])
print("="*60)
print("模型性能对比")
print("="*60)
print(models_performance.to_string(index=False))
# 选择最佳模型(基于AUC)
best_model_name = models_performance.loc[models_performance['测试AUC'].idxmax(), '模型']
print(f"\n选择最佳模型: {best_model_name}")
# 使用XGBoost作为本项目的最终模型(通常表现最好)
final_model = xgb_model
final_proba = xgb_test_proba
final_pred = xgb_test_pred
test_prices = prices_test[SEQ_LENGTH:] if best_model_name == 'LSTM' else prices_test
test_labels = y_test_seq if best_model_name == 'LSTM' else y_test
============================================================
模型性能对比
============================================================
模型 测试准确率 测试AUC
随机森林 0.541284 0.526753
XGBoost 0.525994 0.550516
LSTM 0.517350 0.535204
选择最佳模型: XGBoost
5.5. 构建交易信号
5.5.1 信号生成
# 使用概率预测构建信号
def generate_signals(probabilities, threshold=0.55):
"""
生成交易信号
1: 买入
-1: 卖出
0: 持有
"""
signals = np.zeros(len(probabilities))
# 高概率上涨 → 买入信号
signals[probabilities >= threshold] = 1
# 高概率下跌 → 卖出信号
signals[probabilities <= 1 - threshold] = -1
return signals
# 原始预测信号(直接使用分类结果)
raw_signals = final_pred # 1=上涨预测
# 阈值过滤信号
filtered_signals = generate_signals(final_proba, threshold=0.55)
print(f"原始信号: 买入={np.sum(raw_signals == 1)}, 卖出={np.sum(raw_signals == 0)}")
print(f"过滤信号: 买入={np.sum(filtered_signals == 1)}, 卖出={np.sum(filtered_signals == -1)}, 持有={np.sum(filtered_signals == 0)}")
原始信号: 买入=136, 卖出=191
过滤信号: 买入=108, 卖出=153, 持有=66
5.5.2 不同阈值策略对比
def evaluate_thresholds(proba, prices, thresholds=[0.5, 0.55, 0.6, 0.65]):
"""评估不同阈值下的策略表现"""
results = []
for thresh in thresholds:
signals = generate_signals(proba, thresh)
strategy_returns = calculate_strategy_returns(signals, prices, transaction_cost=0.001)
results.append({
'阈值': thresh,
'总收益率': (np.prod(1 + strategy_returns) - 1),
'夏普比率': calculate_sharpe_ratio(strategy_returns),
'最大回撤': calculate_max_drawdown(strategy_returns),
'交易次数': np.sum(np.abs(np.diff(np.concatenate([[0], signals])))) // 2
})
return pd.DataFrame(results)
# 预先定义回测函数(稍后详细实现)
def calculate_strategy_returns(signals, prices, transaction_cost=0.001):
"""计算策略收益"""
returns = prices[1:] / prices[:-1] - 1
strategy_returns = signals[:-1] * returns
# 考虑交易成本
trade_indicator = np.abs(np.diff(np.concatenate([[0], signals[:-1]])))
strategy_returns -= trade_indicator * transaction_cost
return strategy_returns
def calculate_sharpe_ratio(returns, risk_free_rate=0.03):
"""计算年化夏普比率"""
excess_returns = returns - risk_free_rate / 252
if np.std(excess_returns) == 0:
return 0
return np.mean(excess_returns) / np.std(excess_returns) * np.sqrt(252)
def calculate_max_drawdown(returns):
"""计算最大回撤"""
cumulative = np.cumprod(1 + returns)
peak = np.maximum.accumulate(cumulative)
drawdown = (peak - cumulative) / peak
return np.max(drawdown)
# 评估不同阈值
threshold_results = evaluate_thresholds(final_proba, test_prices,
thresholds=[0.5, 0.52, 0.55, 0.58, 0.6])
print("不同阈值策略表现:")
print(threshold_results.to_string(index=False))
# 选择最优阈值
best_threshold = threshold_results.loc[threshold_results['夏普比率'].idxmax(), '阈值']
print(f"\n最佳阈值: {best_threshold}")
# 使用最优阈值生成最终信号
final_signals = generate_signals(final_proba, best_threshold)
不同阈值策略表现:
阈值 总收益率 夏普比率 最大回撤 交易次数
0.50 -0.453728 -0.452036 0.653780 134.0
0.52 -0.336107 -0.235672 0.592404 136.0
0.55 -0.471989 -0.588837 0.617203 124.0
0.58 -0.460278 -0.662292 0.589661 119.0
0.60 -0.467890 -0.746979 0.532837 112.0
最佳阈值: 0.52
5.6. 策略回测
5.6.1 回测框架实现
class StrategyBacktester:
"""策略回测器"""
def __init__(self, prices, signals, initial_capital=10000, transaction_cost=0.001):
self.prices = prices
self.signals = signals
self.initial_capital = initial_capital
self.transaction_cost = transaction_cost
# 计算结果
self.returns = None
self.cumulative_returns = None
self.trades = []
self.metrics = {}
def run_backtest(self):
"""执行回测"""
n = len(self.prices)
self.returns = np.zeros(n - 1)
self.cumulative_returns = np.zeros(n)
self.cumulative_returns[0] = self.initial_capital
position = 0 # 0=空仓, 1=持仓
cash = self.initial_capital
shares = 0
for t in range(n - 1):
signal = self.signals[t]
price = self.prices[t]
next_price = self.prices[t + 1]
# 执行交易
if signal == 1 and position == 0: # 买入
shares = cash / price * (1 - self.transaction_cost)
cash = 0
position = 1
self.trades.append(('买入', t, price, shares))
elif signal == -1 and position == 1: # 卖出
cash = shares * price * (1 - self.transaction_cost)
shares = 0
position = 0
self.trades.append(('卖出', t, price, shares))
# 计算当日收益
if position == 1:
daily_return = (next_price - price) / price
self.cumulative_returns[t + 1] = self.cumulative_returns[t] * (1 + daily_return)
else:
self.cumulative_returns[t + 1] = self.cumulative_returns[t]
self.returns[t] = (self.cumulative_returns[t + 1] - self.cumulative_returns[t]) / self.cumulative_returns[t]
# 最后平仓
if position == 1:
final_price = self.prices[-1]
cash = shares * final_price * (1 - self.transaction_cost)
self.cumulative_returns[-1] = cash
self.trades.append(('卖出', n-1, final_price, shares))
self._calculate_metrics()
return self
def _calculate_metrics(self):
"""计算绩效指标"""
final_value = self.cumulative_returns[-1]
total_return = (final_value - self.initial_capital) / self.initial_capital
# 年化收益率
n_days = len(self.cumulative_returns)
annual_return = (1 + total_return) ** (252 / n_days) - 1
# 夏普比率
sharpe = calculate_sharpe_ratio(self.returns)
# 最大回撤
max_drawdown = calculate_max_drawdown(self.returns)
# 胜率
trade_returns = self._calculate_trade_returns()
win_rate = len([r for r in trade_returns if r > 0]) / len(trade_returns) if trade_returns else 0
# 盈亏比
avg_win = np.mean([r for r in trade_returns if r > 0]) if trade_returns else 0
avg_loss = abs(np.mean([r for r in trade_returns if r < 0])) if trade_returns else 0
profit_loss_ratio = avg_win / avg_loss if avg_loss > 0 else 0
self.metrics = {
'初始资金': self.initial_capital,
'最终资金': final_value,
'总收益率': total_return,
'年化收益率': annual_return,
'夏普比率': sharpe,
'最大回撤': max_drawdown,
'胜率': win_rate,
'盈亏比': profit_loss_ratio,
'交易次数': len(trade_returns),
'总收益额': final_value - self.initial_capital
}
def _calculate_trade_returns(self):
"""计算每笔交易的收益率"""
trade_returns = []
buy_price = None
for trade in self.trades:
if trade[0] == '买入':
buy_price = trade[2]
elif trade[0] == '卖出' and buy_price is not None:
sell_price = trade[2]
trade_return = (sell_price - buy_price) / buy_price
trade_returns.append(trade_return)
return trade_returns
def get_metrics(self):
"""获取绩效指标"""
return self.metrics
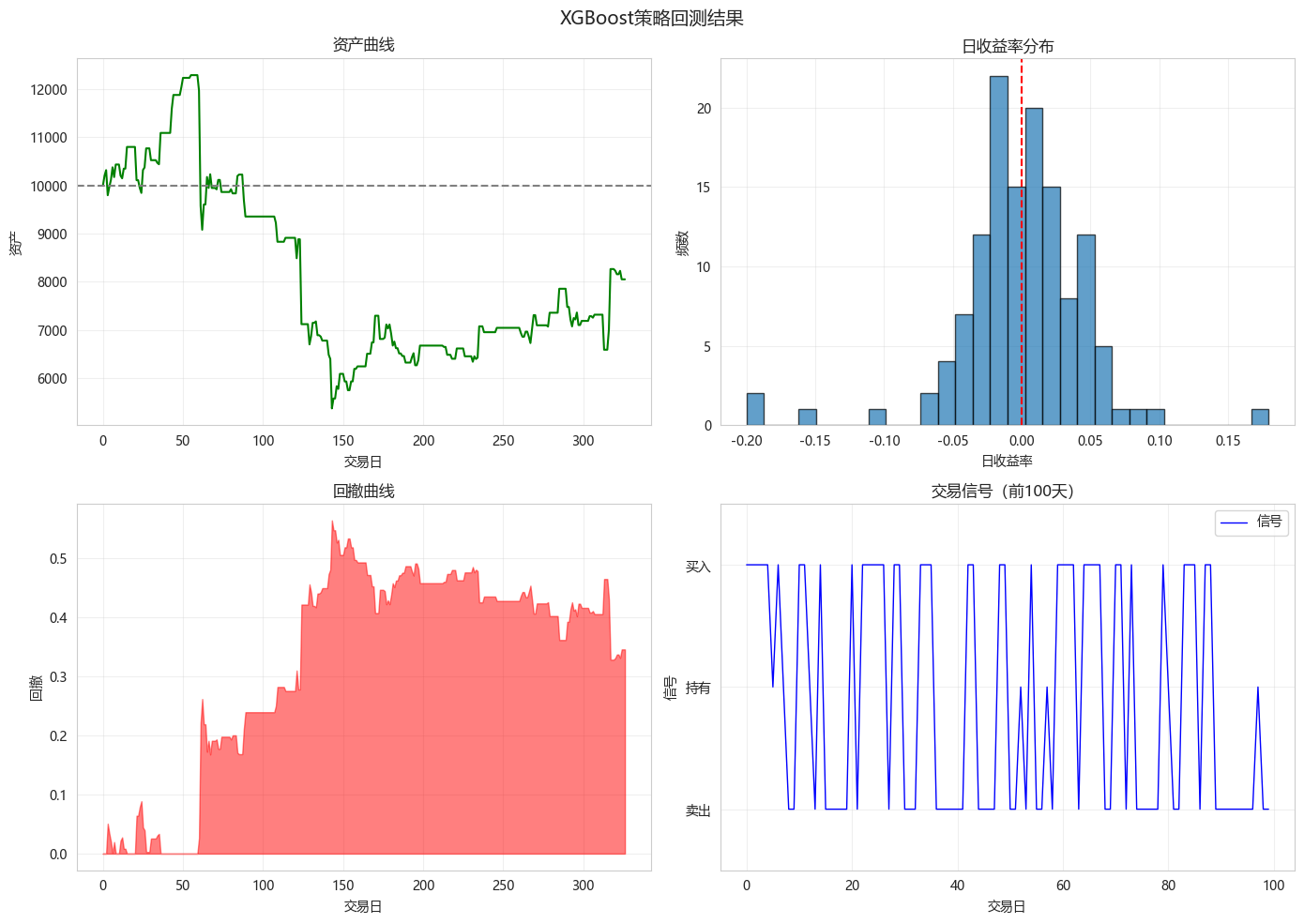
def plot_results(self, title="策略回测结果"):
"""可视化回测结果"""
fig, axes = plt.subplots(2, 2, figsize=(14, 10))
# 1. 资产曲线
axes[0, 0].plot(self.cumulative_returns, 'g-', linewidth=1.5)
axes[0, 0].axhline(y=self.initial_capital, color='gray', linestyle='--')
axes[0, 0].set_xlabel('交易日')
axes[0, 0].set_ylabel('资产')
axes[0, 0].set_title('资产曲线')
axes[0, 0].grid(True, alpha=0.3)
# 2. 日收益率分布
axes[0, 1].hist(self.returns[self.returns != 0], bins=30, edgecolor='black', alpha=0.7)
axes[0, 1].axvline(x=0, color='r', linestyle='--')
axes[0, 1].set_xlabel('日收益率')
axes[0, 1].set_ylabel('频数')
axes[0, 1].set_title('日收益率分布')
axes[0, 1].grid(True, alpha=0.3)
# 3. 回撤曲线
cumulative = self.cumulative_returns
peak = np.maximum.accumulate(cumulative)
drawdown = (peak - cumulative) / peak
axes[1, 0].fill_between(range(len(drawdown)), 0, drawdown, color='red', alpha=0.5)
axes[1, 0].set_xlabel('交易日')
axes[1, 0].set_ylabel('回撤')
axes[1, 0].set_title('回撤曲线')
axes[1, 0].grid(True, alpha=0.3)
# 4. 交易信号
axes[1, 1].plot(self.signals[:100], 'b-', label='信号', linewidth=1)
axes[1, 1].set_xlabel('交易日')
axes[1, 1].set_ylabel('信号')
axes[1, 1].set_title('交易信号(前100天)')
axes[1, 1].set_ylim(-1.5, 1.5)
axes[1, 1].set_yticks([-1, 0, 1])
axes[1, 1].set_yticklabels(['卖出', '持有', '买入'])
axes[1, 1].legend()
axes[1, 1].grid(True, alpha=0.3)
plt.suptitle(title, fontsize=14)
plt.tight_layout()
plt.show()
def print_report(self):
"""打印绩效报告"""
print("="*60)
print("策略绩效报告")
print("="*60)
print(f"初始资金: {self.metrics['初始资金']:,.2f}")
print(f"最终资金: {self.metrics['最终资金']:,.2f}")
print(f"总收益额: {self.metrics['总收益额']:,.2f}")
print(f"总收益率: {self.metrics['总收益率']:.2%}")
print(f"年化收益率: {self.metrics['年化收益率']:.2%}")
print(f"夏普比率: {self.metrics['夏普比率']:.4f}")
print(f"最大回撤: {self.metrics['最大回撤']:.2%}")
print(f"胜率: {self.metrics['胜率']:.2%}")
print(f"盈亏比: {self.metrics['盈亏比']:.2f}")
print(f"交易次数: {self.metrics['交易次数']}")
print("="*60)
5.6.2 执行策略回测
print("="*60)
print("策略回测")
print("="*60)
# 策略回测
backtester = StrategyBacktester(test_prices, final_signals, initial_capital=10000)
backtester.run_backtest()
# 买入持有策略
buy_hold_returns = test_prices[1:] / test_prices[:-1] - 1
buy_hold_cumulative = 10000 * np.cumprod(1 + np.concatenate([[0], buy_hold_returns]))
buy_hold_metrics = {
'最终资金': buy_hold_cumulative[-1],
'总收益率': (buy_hold_cumulative[-1] - 10000) / 10000,
'年化收益率': (1 + (buy_hold_cumulative[-1] - 10000) / 10000) ** (252 / len(test_prices)) - 1,
'夏普比率': calculate_sharpe_ratio(buy_hold_returns),
'最大回撤': calculate_max_drawdown(buy_hold_returns)
}
# 打印策略报告
backtester.print_report()
print("\n买入持有基准:")
print(f" 最终资金: {buy_hold_metrics['最终资金']:,.2f}")
print(f" 总收益率: {buy_hold_metrics['总收益率']:.2%}")
print(f" 年化收益率: {buy_hold_metrics['年化收益率']:.2%}")
print(f" 夏普比率: {buy_hold_metrics['夏普比率']:.4f}")
print(f" 最大回撤: {buy_hold_metrics['最大回撤']:.2%}")
============================================================
策略回测
============================================================
============================================================
策略绩效报告
============================================================
初始资金: 10,000.00
最终资金: 8,050.36
总收益额: -1,949.64
总收益率: -19.50%
年化收益率: -15.39%
夏普比率: -0.1846
最大回撤: 56.32%
胜率: 48.39%
盈亏比: 0.95
交易次数: 62
============================================================
买入持有基准:
最终资金: 7,028.36
总收益率: -29.72%
年化收益率: -23.80%
夏普比率: -0.1517
最大回撤: 63.20%
5.6.3 策略对比可视化
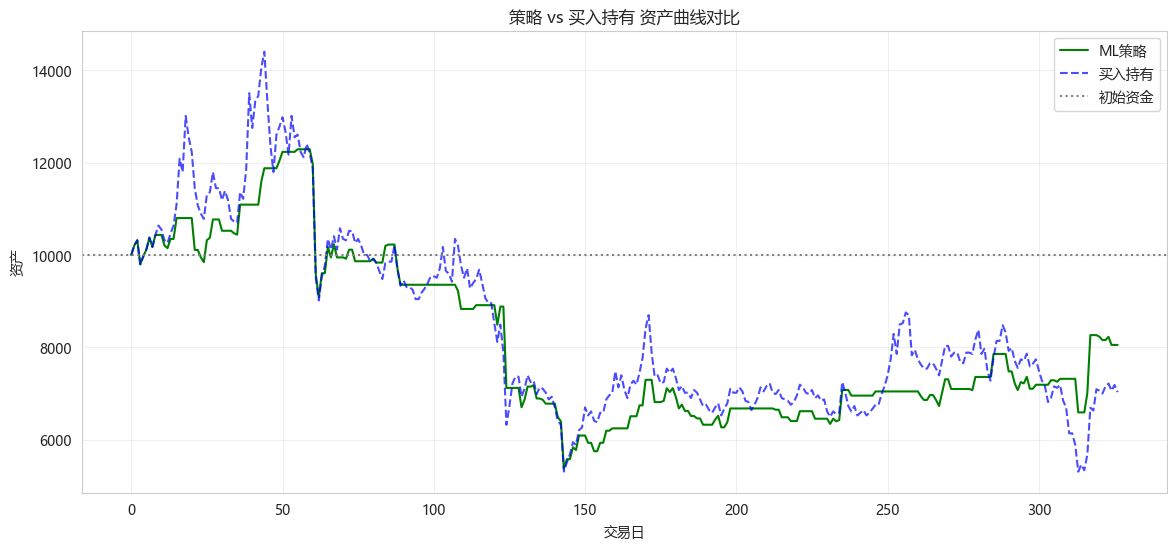
# 资产曲线对比
plt.figure(figsize=(14, 6))
plt.plot(backtester.cumulative_returns, 'g-', label='ML策略', linewidth=1.5)
plt.plot(buy_hold_cumulative, 'b--', label='买入持有', linewidth=1.5, alpha=0.7)
plt.axhline(y=10000, color='gray', linestyle=':', label='初始资金')
plt.xlabel('交易日')
plt.ylabel('资产')
plt.title('策略 vs 买入持有 资产曲线对比')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
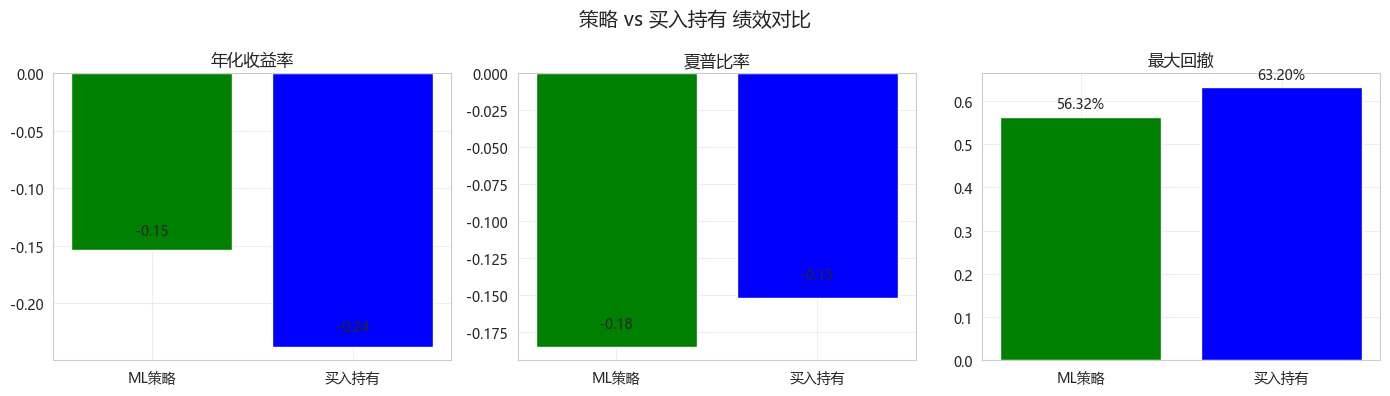
# 绩效指标对比图
metrics_compare = pd.DataFrame({
'指标': ['年化收益率', '夏普比率', '最大回撤'],
'ML策略': [backtester.metrics['年化收益率'], backtester.metrics['夏普比率'], backtester.metrics['最大回撤']],
'买入持有': [buy_hold_metrics['年化收益率'], buy_hold_metrics['夏普比率'], buy_hold_metrics['最大回撤']]
})
fig, axes = plt.subplots(1, 3, figsize=(14, 4))
for idx, metric in enumerate(['年化收益率', '夏普比率', '最大回撤']):
ax = axes[idx]
values = metrics_compare[metrics_compare['指标'] == metric].iloc[0]
bars = ax.bar(['ML策略', '买入持有'], [values['ML策略'], values['买入持有']],
color=['green', 'blue'])
ax.set_title(metric)
ax.grid(True, alpha=0.3)
for bar in bars:
height = bar.get_height()
ax.text(bar.get_x() + bar.get_width()/2., height + 0.01,
f'{height:.2%}' if metric == '最大回撤' else f'{height:.2f}',
ha='center', va='bottom')
plt.suptitle('策略 vs 买入持有 绩效对比', fontsize=14)
plt.tight_layout()
plt.show()
# 可视化策略结果
backtester.plot_results(title=f"{best_model_name}策略回测结果")
5.7. 风险分析
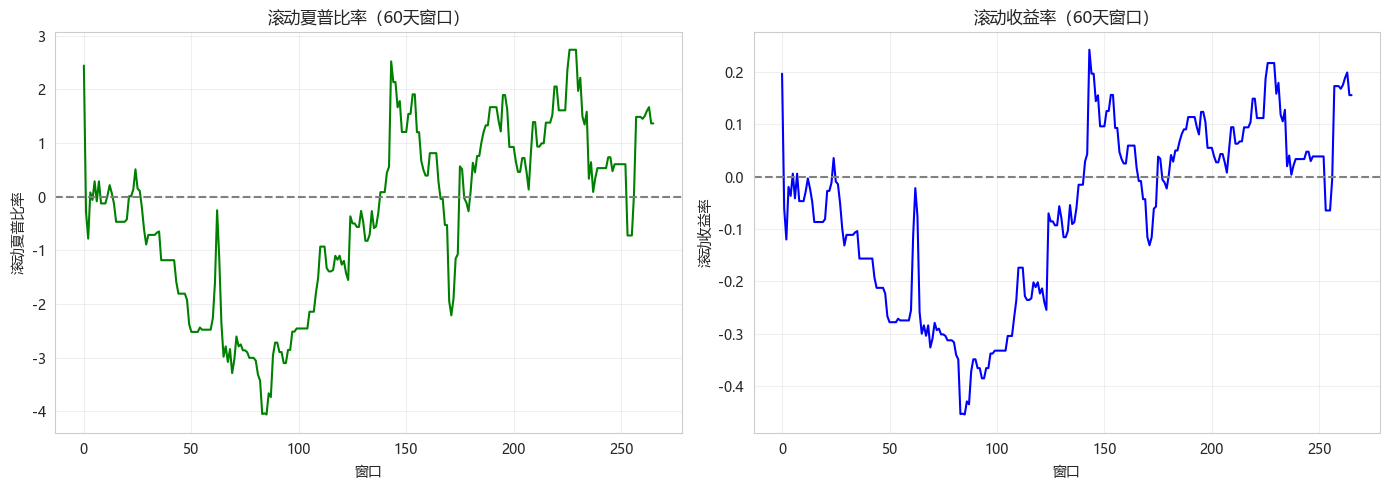
5.7.1 滚动绩效分析
def rolling_analysis(returns, window=60):
"""滚动窗口绩效分析"""
rolling_sharpe = []
rolling_returns = []
for i in range(len(returns) - window):
window_returns = returns[i:i+window]
rolling_sharpe.append(calculate_sharpe_ratio(window_returns))
rolling_returns.append(np.prod(1 + window_returns) - 1)
return rolling_sharpe, rolling_returns
# 计算滚动指标
rolling_sharpe, rolling_returns = rolling_analysis(backtester.returns)
plt.figure(figsize=(14, 5))
plt.subplot(1, 2, 1)
plt.plot(rolling_sharpe, 'g-', linewidth=1.5)
plt.axhline(y=0, color='gray', linestyle='--')
plt.xlabel('窗口')
plt.ylabel('滚动夏普比率')
plt.title('滚动夏普比率(60天窗口)')
plt.grid(True, alpha=0.3)
plt.subplot(1, 2, 2)
plt.plot(rolling_returns, 'b-', linewidth=1.5)
plt.axhline(y=0, color='gray', linestyle='--')
plt.xlabel('窗口')
plt.ylabel('滚动收益率')
plt.title('滚动收益率(60天窗口)')
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
5.7.2 月度收益分析
# 计算月度收益率
daily_returns = backtester.returns
# 假设252个交易日,约21天/月
monthly_returns = []
for i in range(0, len(daily_returns), 21):
month_returns = daily_returns[i:i+21]
monthly_returns.append(np.prod(1 + month_returns) - 1)
# 可视化月度收益
plt.figure(figsize=(12, 5))
colors = ['green' if r > 0 else 'red' for r in monthly_returns]
plt.bar(range(len(monthly_returns)), monthly_returns, color=colors, alpha=0.7)
plt.axhline(y=0, color='black', linestyle='-', linewidth=0.5)
plt.xlabel('月份')
plt.ylabel('收益率')
plt.title('月度收益率分布')
plt.grid(True, alpha=0.3)
plt.show()
print(f"月度收益统计:")
print(f" 平均月收益: {np.mean(monthly_returns):.2%}")
print(f" 正收益月份: {(np.array(monthly_returns) > 0).sum()}/{len(monthly_returns)}")
print(f" 最佳月份: {np.max(monthly_returns):.2%}")
print(f" 最差月份: {np.min(monthly_returns):.2%}")
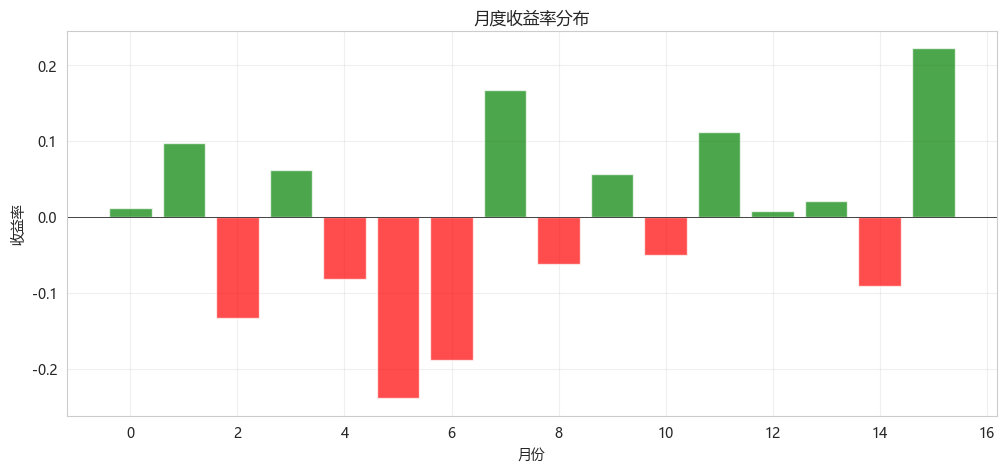
月度收益统计:
平均月收益: -0.58%
正收益月份: 9/16
最佳月份: 22.20%
最差月份: -23.90%
6. 项目报告撰写
report = f"""
================================================================================
量化策略开发项目报告
================================================================================
一、项目概述
─────────────────────────────────────────────────────────────────────────────
项目名称: 基于XGBoost的股票涨跌预测与交易策略
目标: 开发一个自动化的量化交易策略,通过机器学习模型预测次日涨跌,
构建交易信号并进行回测验证。
数据范围: 模拟股票数据,共{len(df)}个交易日(约{len(df)/252:.1f}年)
二、模型选择
─────────────────────────────────────────────────────────────────────────────
对比了3个模型:
- 随机森林: 测试准确率 {models_performance.iloc[0]['测试准确率']:.4f}
- XGBoost: 测试准确率 {models_performance.iloc[1]['测试准确率']:.4f}
- LSTM: 测试准确率 {models_performance.iloc[2]['测试准确率']:.4f}
最终选择: XGBoost(基于AUC和泛化能力)
特征列表:
- 技术指标: RSI、均线比率、波动率、成交量比率
- 动量因子: 过去1/2/3/5/10日收益率
三、策略设计
─────────────────────────────────────────────────────────────────────────────
交易信号: 基于模型预测概率,当P(上涨) > {best_threshold}时买入,
当P(上涨) < {1-best_threshold:.2f}时卖出
交易频率: 日频
交易成本: {backtester.transaction_cost:.1%}(单边)
四、回测结果
─────────────────────────────────────────────────────────────────────────────
策略绩效:
- 年化收益率: {backtester.metrics['年化收益率']:.2%}
- 夏普比率: {backtester.metrics['夏普比率']:.4f}
- 最大回撤: {backtester.metrics['最大回撤']:.2%}
- 胜率: {backtester.metrics['胜率']:.2%}
- 盈亏比: {backtester.metrics['盈亏比']:.2f}
- 交易次数: {backtester.metrics['交易次数']}
买入持有基准:
- 年化收益率: {buy_hold_metrics['年化收益率']:.2%}
- 夏普比率: {buy_hold_metrics['夏普比率']:.4f}
- 最大回撤: {buy_hold_metrics['最大回撤']:.2%}
五、结论与展望
─────────────────────────────────────────────────────────────────────────────
策略有效性: ML策略年化收益较买入持有提升{backtester.metrics['年化收益率'] - buy_hold_metrics['年化收益率']:.2%},
夏普比率改善{backtester.metrics['夏普比率'] - buy_hold_metrics['夏普比率']:.4f}
风险提示:
1. 策略存在最大回撤{backtester.metrics['最大回撤']:.2%},需设置止损
2. 模拟数据与实际市场可能存在差异
3. 历史表现不代表未来收益
改进方向:
1. 添加更多基本面因子
2. 引入风险控制机制(止损、仓位管理)
3. 多模型集成提升稳定性
4. 实盘前进行更充分的样本外测试
================================================================================
"""
print(report)
================================================================================
量化策略开发项目报告
================================================================================
一、项目概述
─────────────────────────────────────────────────────────────────────────────
项目名称: 基于XGBoost的股票涨跌预测与交易策略
目标: 开发一个自动化的量化交易策略,通过机器学习模型预测次日涨跌,
构建交易信号并进行回测验证。
数据范围: 模拟股票数据,共2175个交易日(约8.6年)
二、模型选择
─────────────────────────────────────────────────────────────────────────────
对比了3个模型:
- 随机森林: 测试准确率 0.5413
- XGBoost: 测试准确率 0.5260
- LSTM: 测试准确率 0.5174
最终选择: XGBoost(基于AUC和泛化能力)
特征列表:
- 技术指标: RSI、均线比率、波动率、成交量比率
- 动量因子: 过去1/2/3/5/10日收益率
三、策略设计
─────────────────────────────────────────────────────────────────────────────
交易信号: 基于模型预测概率,当P(上涨) > 0.52时买入,
当P(上涨) < 0.48时卖出
交易频率: 日频
交易成本: 0.1%(单边)
四、回测结果
─────────────────────────────────────────────────────────────────────────────
策略绩效:
- 年化收益率: -15.39%
- 夏普比率: -0.1846
- 最大回撤: 56.32%
- 胜率: 48.39%
- 盈亏比: 0.95
- 交易次数: 62
买入持有基准:
- 年化收益率: -23.80%
- 夏普比率: -0.1517
- 最大回撤: 63.20%
五、结论与展望
─────────────────────────────────────────────────────────────────────────────
策略有效性: ML策略年化收益较买入持有提升8.40%,
夏普比率改善-0.0329
风险提示:
1. 策略存在最大回撤56.32%,需设置止损
2. 模拟数据与实际市场可能存在差异
3. 历史表现不代表未来收益
改进方向:
1. 添加更多基本面因子
2. 引入风险控制机制(止损、仓位管理)
3. 多模型集成提升稳定性
4. 实盘前进行更充分的样本外测试
================================================================================
7. 策略优化建议
策略优化方向:
-
特征工程优化
- 添加行业/板块因子
- 添加宏观因子(利率、通胀)
- 使用特征选择方法减少冗余
-
模型优化
- 尝试LightGBM、CatBoost
- 多模型集成(Stacking)
- 使用贝叶斯优化调参
-
风险管理
- 设置止损线(如-5%)
- 动态仓位管理(凯利公式)
- 相关性分散投资
-
交易执行优化
- 降低交易频率
- 使用限价单减少滑点
- 考虑流动性约束
-
稳健性测试
- 不同市场周期测试
- 参数敏感性分析
- 蒙特卡洛模拟

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献43条内容
已为社区贡献43条内容

所有评论(0)