拒绝硬编码:基于助睿ETL的高扩展性学生考勤数据处理方案(实验2)
1. 项目背景与目标
本实验依托“数智教育”大赛提供的真实数据集,旨在利用助睿(Uniplore)数据集成平台构建一套自动化的ETL(抽取-转换-加载)处理管道。核心目标是根治传统人工Excel统计存在的效率瓶颈与口径偏差问题,通过对多源数据的清洗与融合,输出标准化的多维度考勤台账,为校园精细化管理提供可靠的数据底座。
2. 技术栈与环境
-
处理引擎:助睿数智(Uniplore)ETL平台。
-
存储层:MySQL 关系型数据库。
-
数据资产:大赛提供的7张业务表(核心聚焦考勤域)。
-
硬件环境:具备网络访问权限及平台运行环境的计算机终端。
3. 数据架构与模型
实验采用星型模型构建数据仓库逻辑,剥离出三张关键表形成“事实-维度”闭环:
|
数据表 |
角色定位 |
核心功能 |
关键映射字段 |
|---|---|---|---|
|
3_kaoqin.csv |
事实表 (Fact) |
记录每一次打卡的流水明细,是统计的基数来源。 |
|
|
4_kaoqintype.csv |
维度表 (Dimension) |
定义考勤行为的语义,将代码转化为可读的标签。 |
|
|
2_student_info.csv |
维度表 (Dimension) |
丰富学生画像,提供分群分析的基础属性。 |
|
4. 标签与口径设计
为确保统计结果的业务可用性,我们将输出标签划分为基础属性、画像衍生、行为指标三个层次,并严格定义了计算逻辑。
4.1 静态属性标签(Who)
直接从源表同步,用于回答“谁”的问题。
-
涵盖字段:学号、姓名、班级ID、班级名称。
-
特殊处理:对于性别、出生日期、政治面貌等字段,若源数据为空,统一填充为“未知”,以保证数据完整性。
4.2 动态画像标签(Which Group)
基于业务规则进行二次加工,用于回答“属于哪类群体”的问题。
|
衍生字段 |
加工规则 |
业务含义 |
|---|---|---|
|
年级 |
解析 |
识别“高一/高二/高三”,非标准命名归为“未知”。 |
|
住宿状态 |
映射 |
1为住校,0为走读,空值为“未知”。 |
|
校区归属 |
解析 |
依据前缀“白-”或“东-”判定为新校区,其余为老校区。 |
4.3 行为统计标签(What & How Many)
基于关键词匹配与逻辑过滤,量化考勤表现。
|
统计指标 |
计算逻辑详解 |
设计考量 |
|---|---|---|
|
迟到/晚到 |
统计描述中含“迟到”或“晚到”且不含“请假”的记录。 |
排除因请假导致的迟到,避免误伤合规行为。 |
|
早退 |
统计描述中含“早退”且不含“请假”的记录。 |
同上,确保统计的是违规早退。 |
|
请假 |
统计描述中含“请假”关键词的所有记录。 |
涵盖事假、病假等全量请假类型,不区分细节。 |
|
校服违规 |
统计描述中含“校服”关键词的记录。 |
依据数据集说明,“校服[移动考勤]”特指未穿校服。 |
5. 处理流程与价值
5.1 流水线逻辑
数据接入 → 实体关联(补齐学生信息与行为定义) → 标签衍生(计算年级/住宿/校区) → 指标聚合(按学生/班级汇总) → 落库。
5.2 预期成效
各组件功能说明如下:
|
组件 |
作用 |
|
表输入 |
读取数据库中的原始数据表 |
|
排序记录 |
按照指定字段对数据进行排序,为记录集连接做准备 |
|
记录集连接 |
按关联字段连接两表,补充考勤行为名称或学生属性 |
|
字段选择 |
移除冗余字段,仅保留核心必要字段 |
|
JavaScript脚本 |
执行脚本逻辑,通过关键词匹配提取异常考勤记录,生成二进制标记 |
|
分组 |
按指定维度分组,使用SUM函数聚合统计各类异常次数 |
|
替换NULL值 |
将空值字段替换为"未知",避免下游出现空指针 |
|
值映射 |
将住校状态编码(0/1)映射为"否"/"是" |
|
表输出 |
将最终结果输出至数据库目标表 |
4 实验步骤
4.1 创建实验项目
步骤一: 点击"新建项目"。
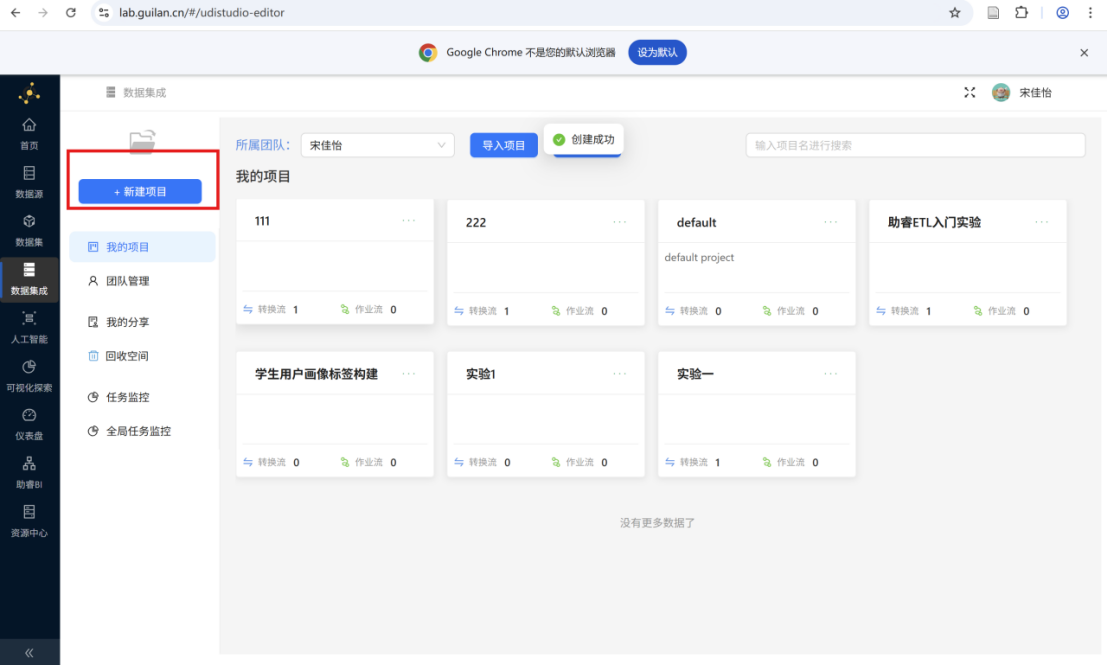
步骤二: 输入项目名称 "学生用户画像标签构建",点击"确定"。
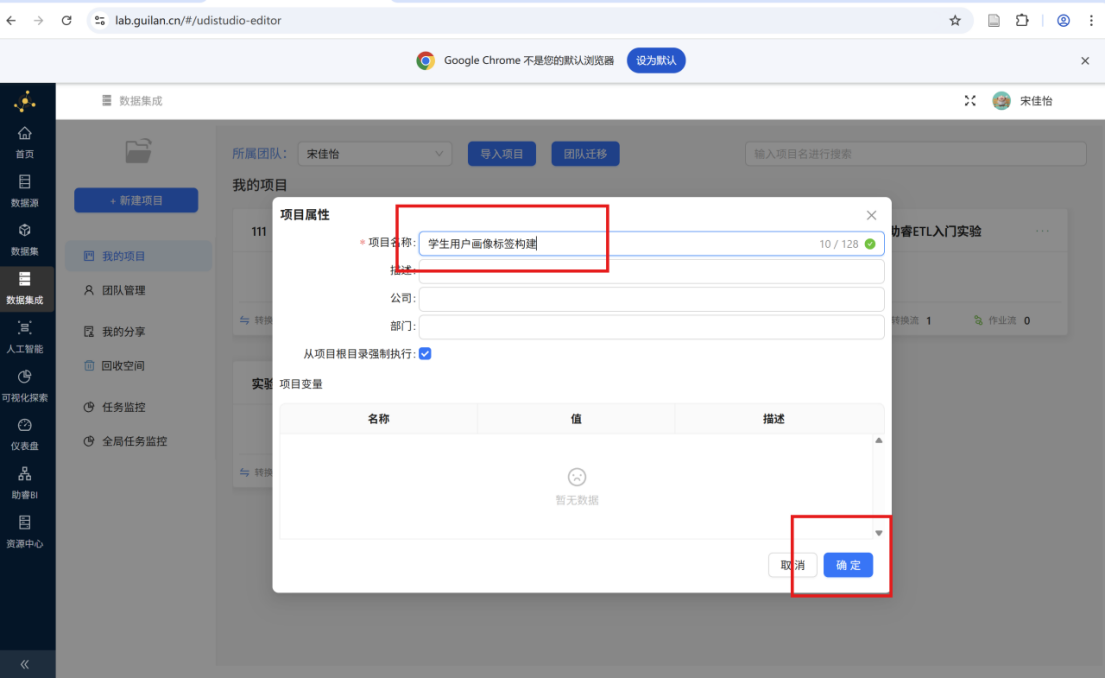
步骤三: 创建成功后即可在数据集成页面看到新创建的项目。
4.2 数据资源获取
为方便后续的数据使用,我们可以将原始数据导入团队私有数据库。
4.2.1 导入原始数据文件
步骤一: 项目创建成功后,点击该项目右上角 "...",点击 "打开项目"。
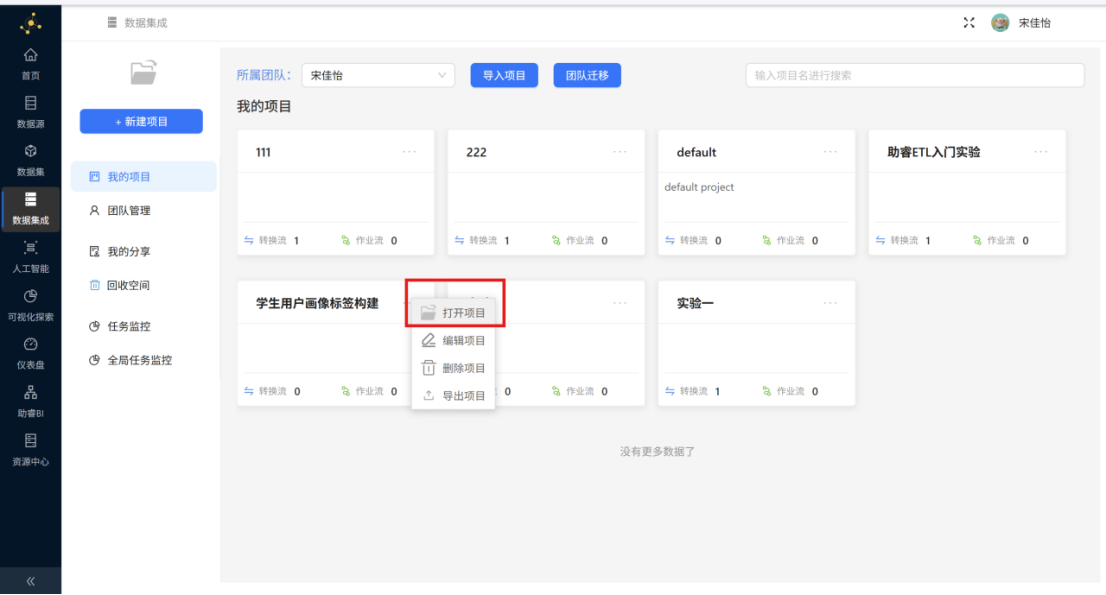
步骤二: 在项目页面,可以看到左侧有 3 个菜单:
|
菜单 |
功能说明 |
|
资源库 |
用于对工作流的管理,包括新建、删除、修改、查看工作流的信息;导出导入工作空间;调度管理等操作 |
|
文件库 |
用于保存工作流中需要用到的文件和工作流产生的文件 |
|
元数据管理 |
助睿 ETL 的重要基石,可以为工作流定义"运行配置"、"数据库"、"Flink 集群"等配置 |
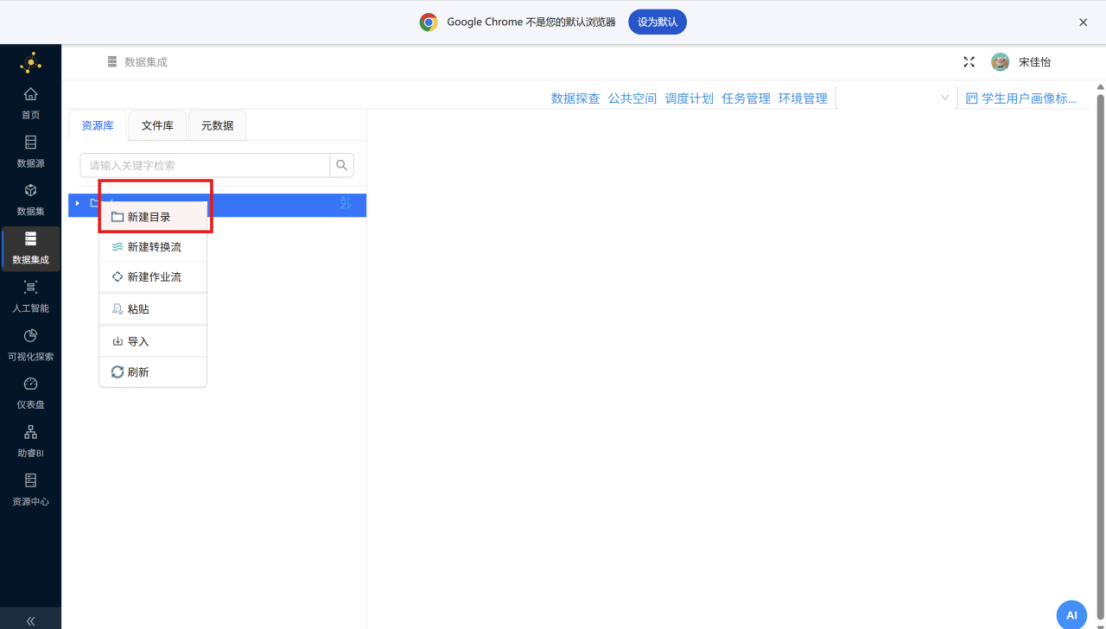
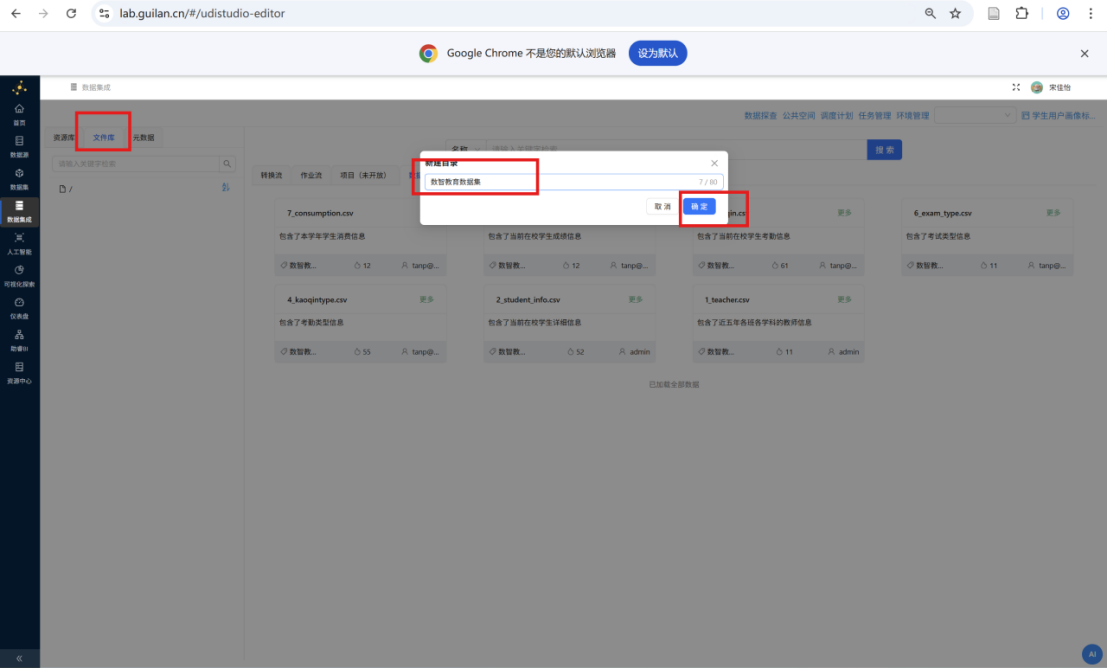
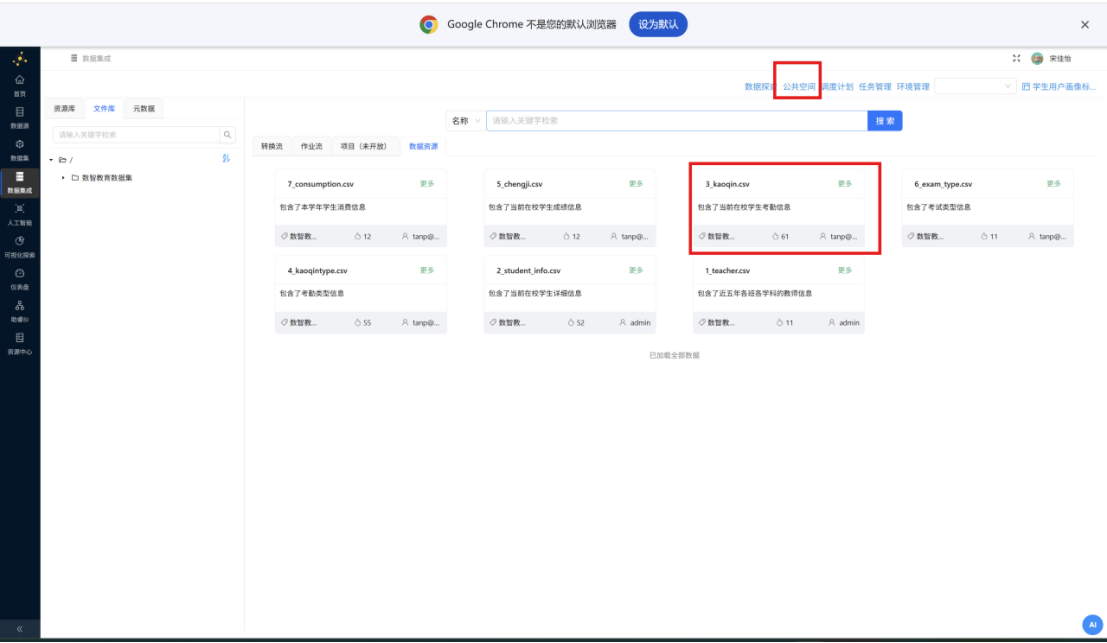
步骤三: 点击 "3_kaoqin.csv" 卡片右上角的 "更多",并点击 "导出"。
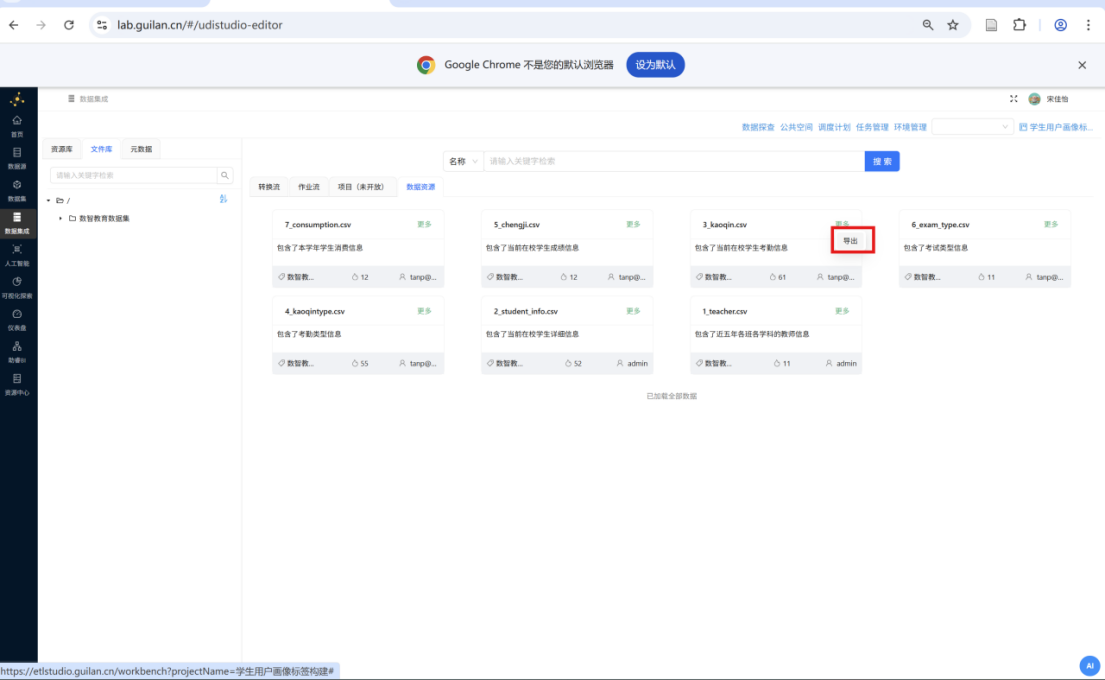
步骤四: 在弹出的窗口中选择导出到刚刚新创建的目录下。
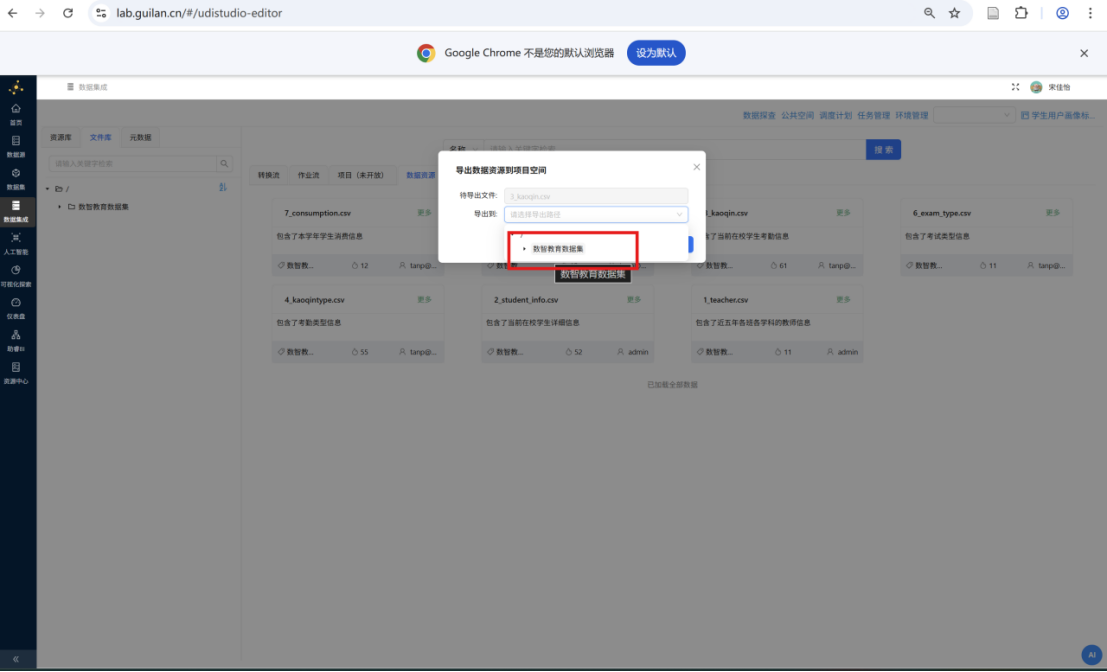
步骤五: 点击 "确定"。
步骤六: 可以看到在"数智教育数据集"的目录下,新增了 3_kaoqin.csv。
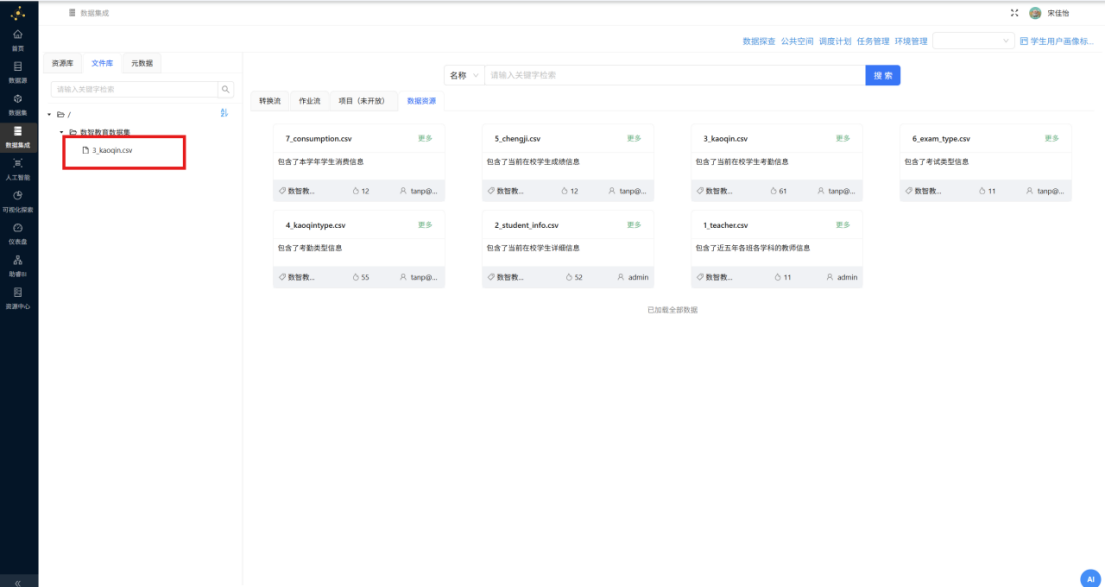
步骤七: 重复以上导出操作,将本次实验用到的数据表 4_kaoqintype.csv 和 2_student_info.csv 都导出到 "数智教育数据集"。
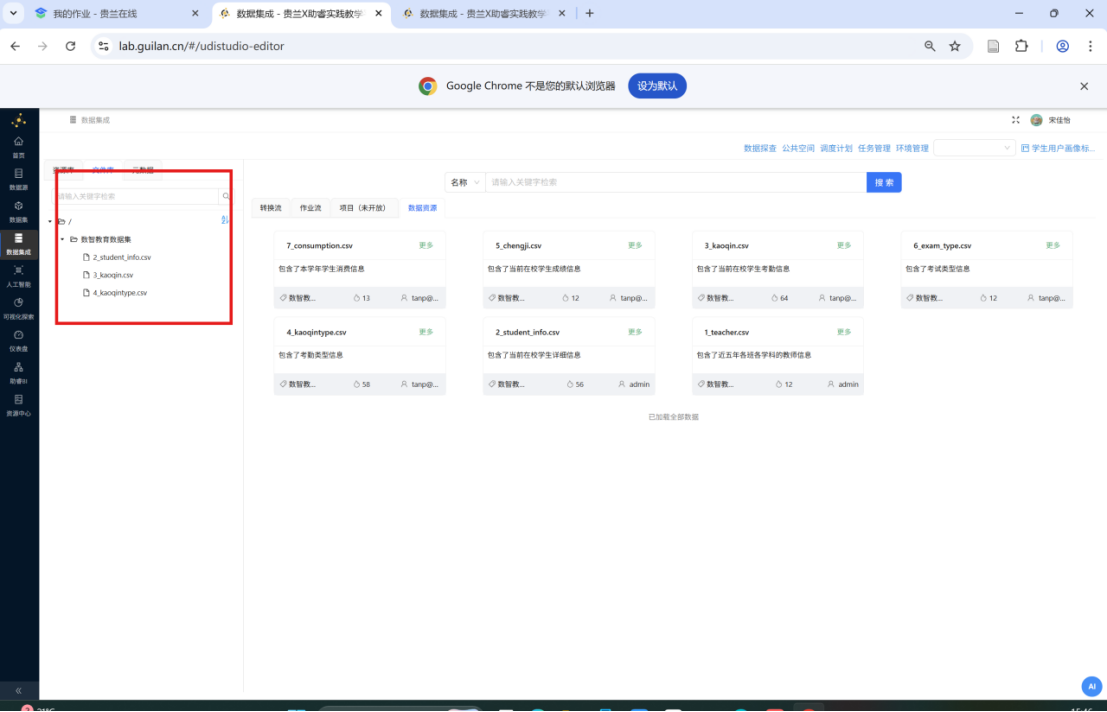
4.2.2 建立数据源连接
步骤一: 在 元数据 tab 页,右键点击 "关系数据库" 打开菜单,选择 "新建数据源"。
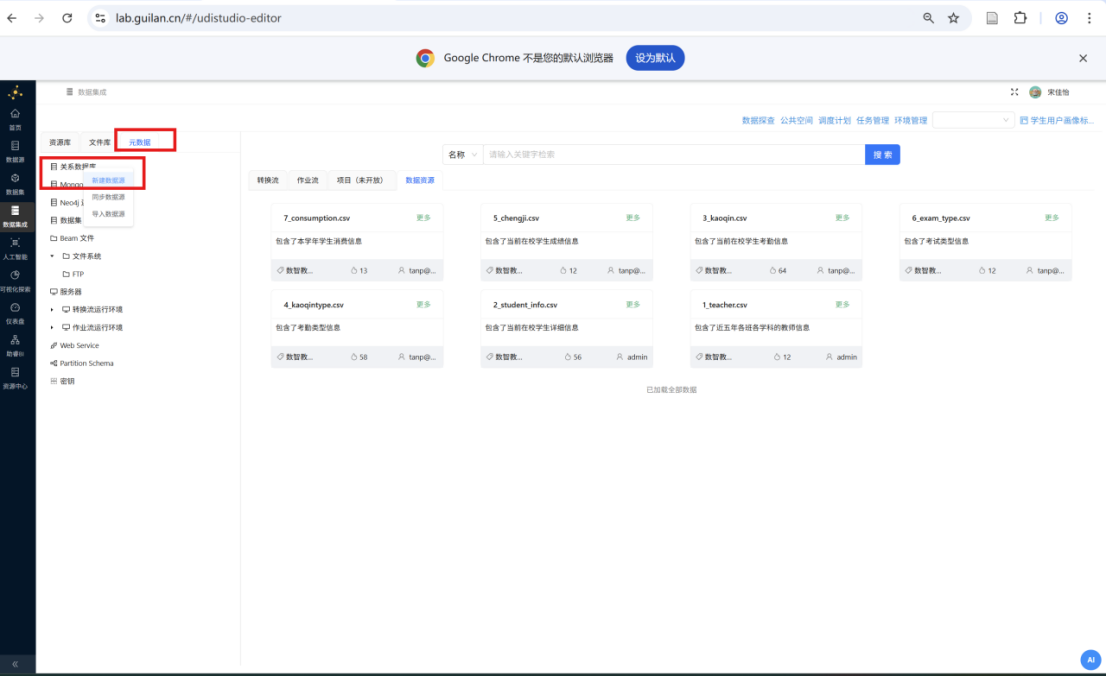
步骤二: 弹出新建数据库连接窗口,按以下信息填写:
|
配置项 |
填写内容 |
|
连接类型 |
MySQL |
|
连接名称 |
团队私有数据库 |
|
服务器主机名 |
rm-2vc3qok06bag39a5n.mysql.cn-chengdu.rds.aliyuncs.com |
|
端口号 |
3306 |
|
数据库名 |
助教提供的数据库名称 |
|
用户名 |
助教提供的账号 |
|
密码 |
助教提供的密码 |
|
驱动类型 |
MySQL 8+ |
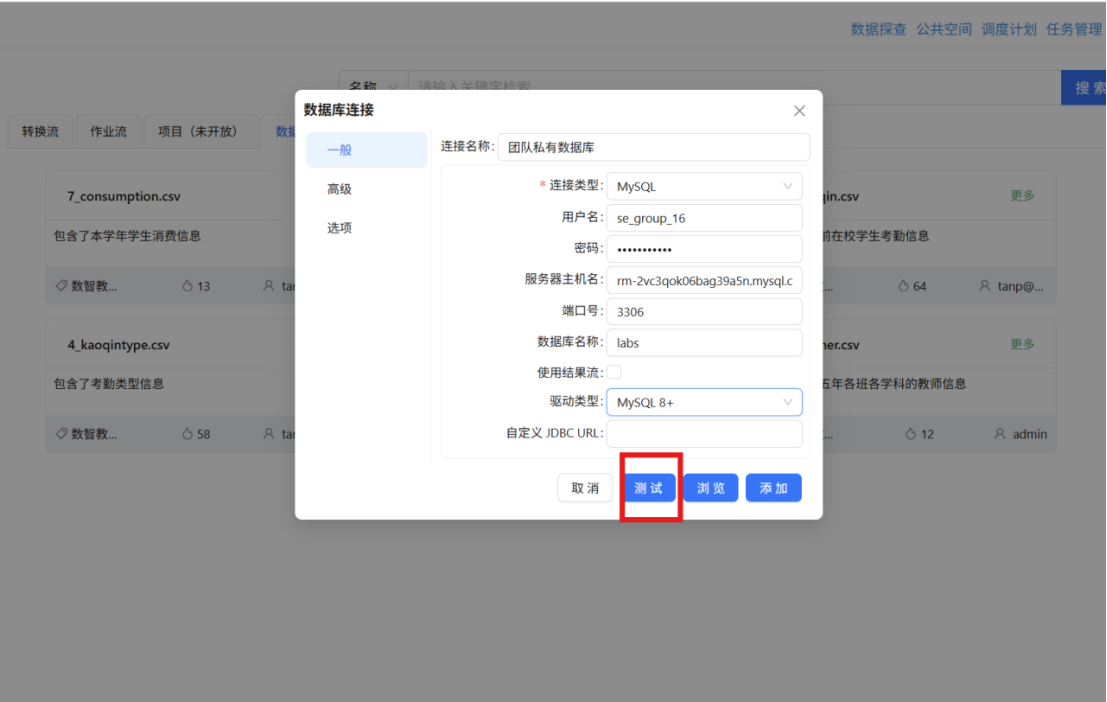
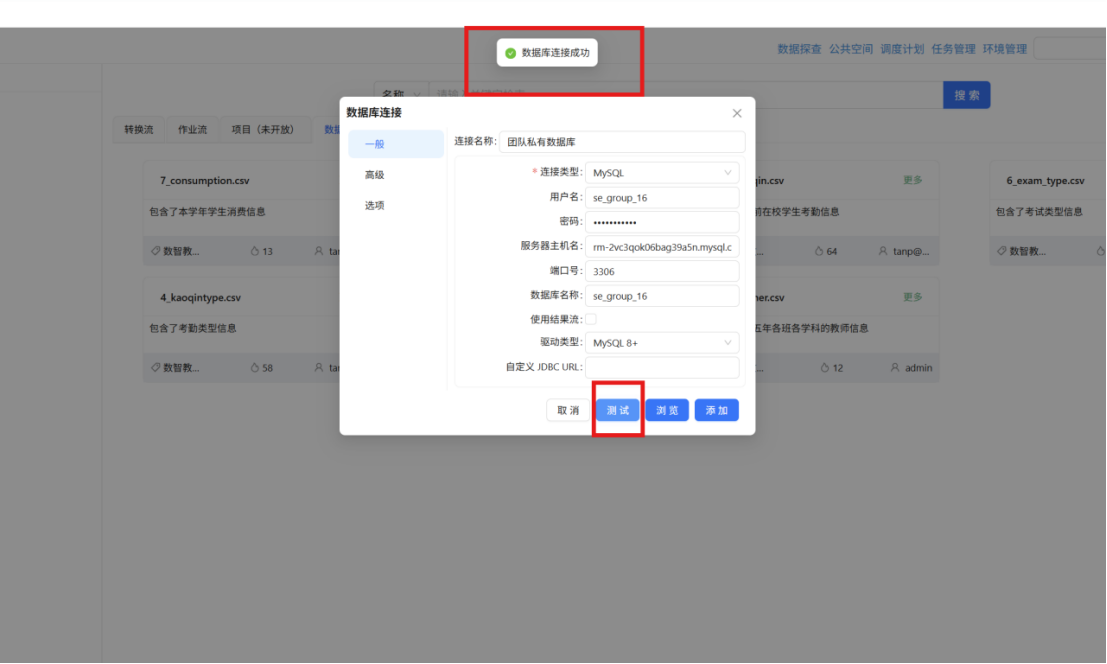
步骤三: 完成后运行转换流,运行过程会定时刷新组件状态,并在画布下方显示执行日志。
4.2.3 数据导入团队私有数据库
4.2.3.1 原始考勤记录表数据导入
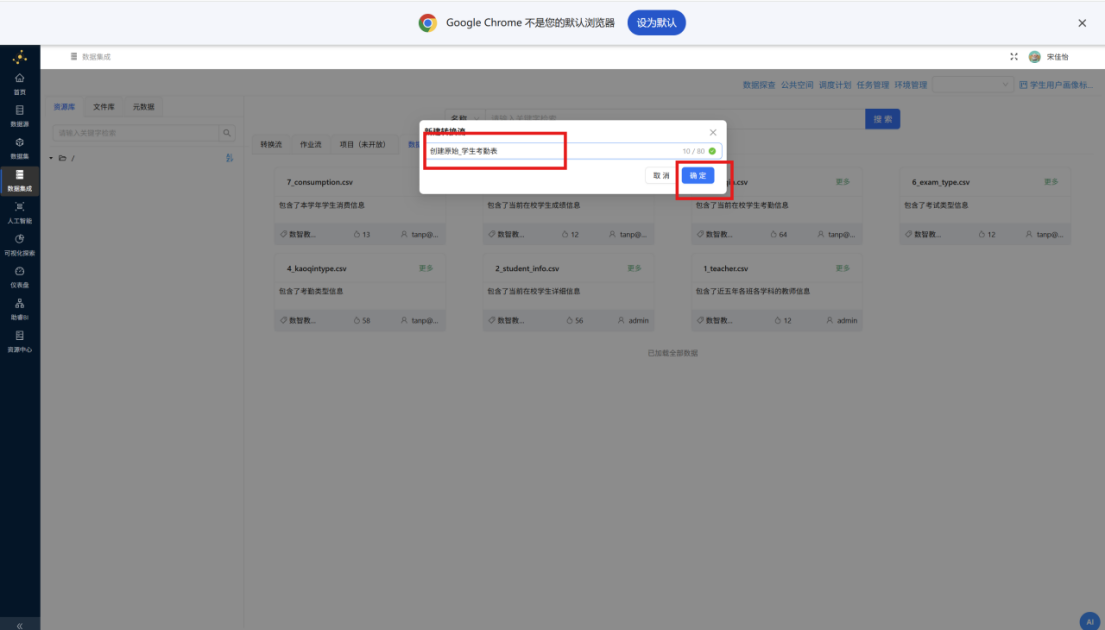
(1)创建原始_学生考勤表
步骤一: 新建转换工作流,并将其命名为 "创建原始_学生考勤表",从组件面板中拖拽 "执行一个SQL脚本" 组件至画布,通过执行 SQL 脚本来创建学生考勤原始数据表。整个转换流如下所示:
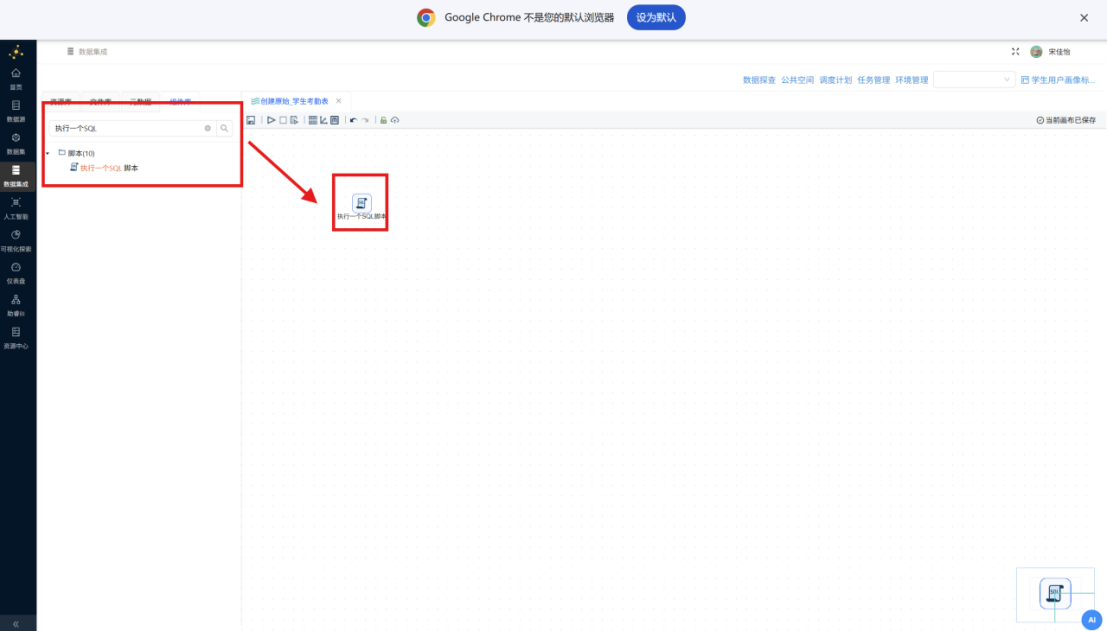
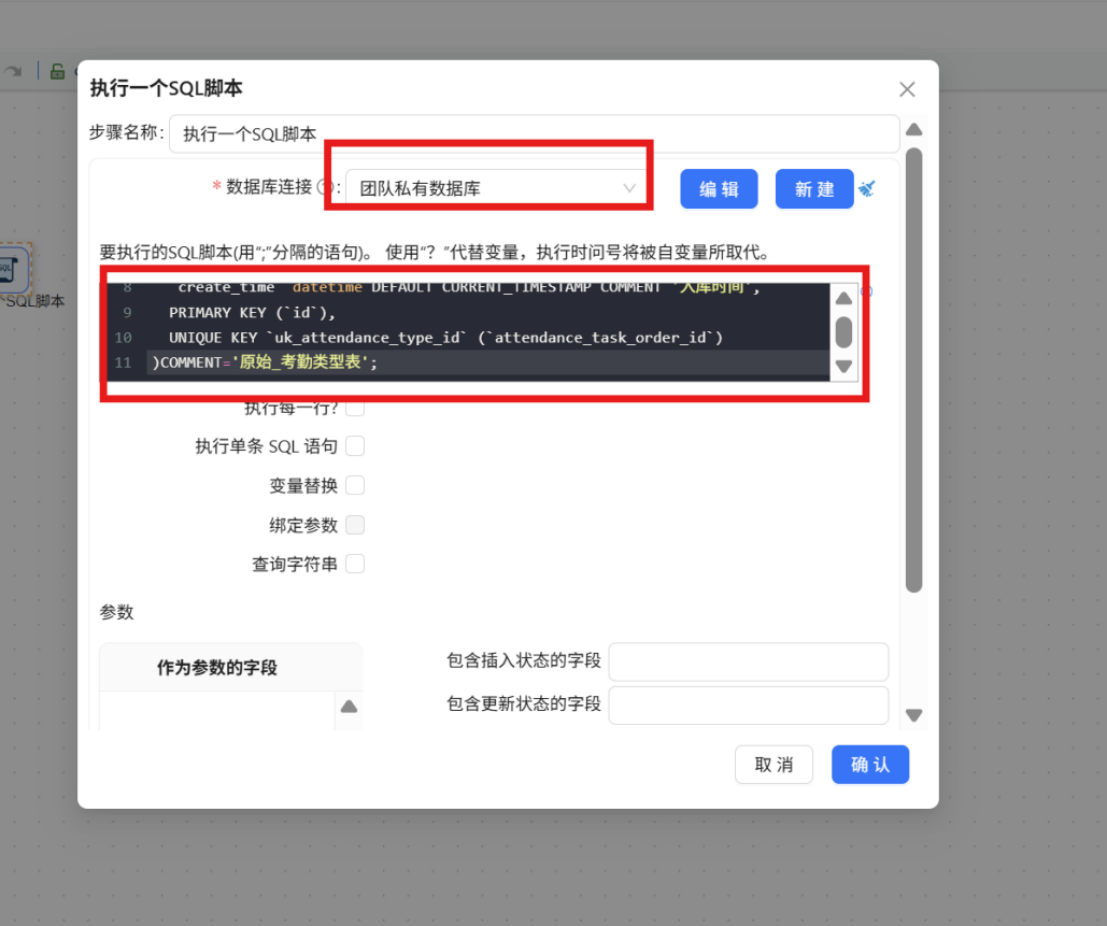
步骤二: 双击组件进行参数配置。
配置说明: 在组件中填写建表 SQL 脚本,数据库连接选择 "团队私有数据库",确保具备脚本执行权限。
SQL 脚本如下:
CREATE TABLE IF NOT EXISTS `raw_attendance` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '自增ID',
`attendance_id` varchar(64) DEFAULT NULL COMMENT '考勤ID',
`learn_term` varchar(30) DEFAULT NULL COMMENT '学期',
`data_datetime` varchar(50) DEFAULT NULL COMMENT '时间和日期',
`attendance_type_id` varchar(64) DEFAULT NULL COMMENT '考勤类型ID',
`attendance_name` varchar(100) DEFAULT NULL COMMENT '考勤名称',
`attendance_task_order_id` varchar(64) DEFAULT NULL COMMENT '考勤事件ID',
`stu_id` varchar(64) DEFAULT NULL COMMENT '学生ID',
`stu_name` varchar(100) DEFAULT NULL COMMENT '学生姓名',
`cla_name` varchar(100) DEFAULT NULL COMMENT '班级名',
`cla_id` varchar(64) DEFAULT NULL COMMENT '班级ID',
`create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '入库时间',
PRIMARY KEY (`id`),
KEY `idx_student_id` (`stu_id`),
KEY `idx_term` (`learn_term`)
) COMMENT='原始_学生考勤表';其余参数保持默认即可,配置完成后的界面如下:
步骤三: 点击运行按钮执行转换流,运行过程中组件状态会实时刷新,画布下方同步输出执行日志。
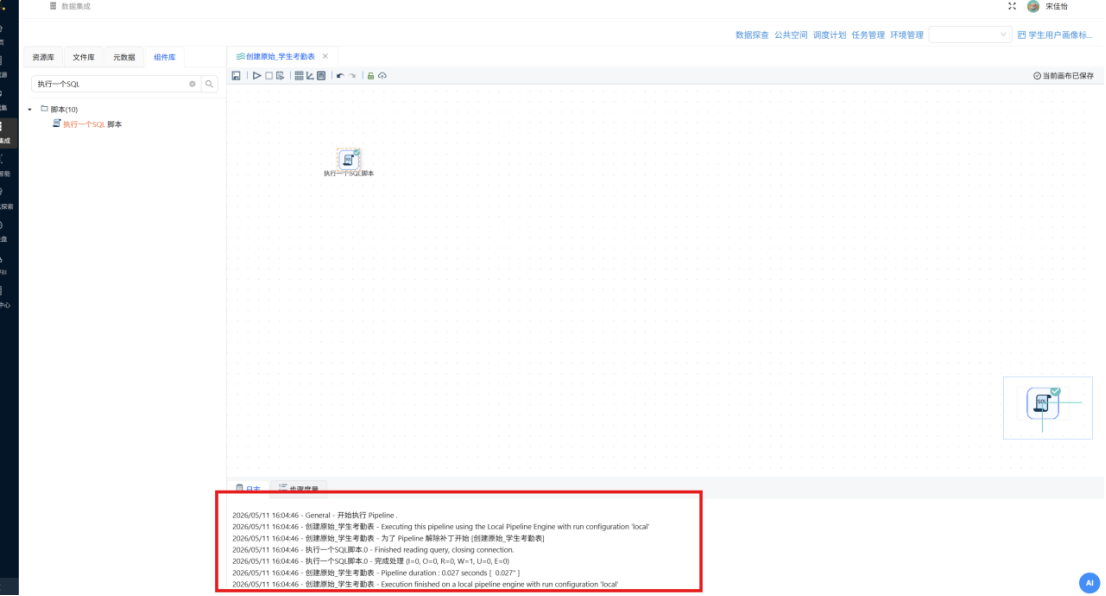
(2)导入原始考勤数据
步骤一: 新建转换工作流,命名为 "导入原始考勤数据",将 "CSV文件输入" 组件拖入画布区域。
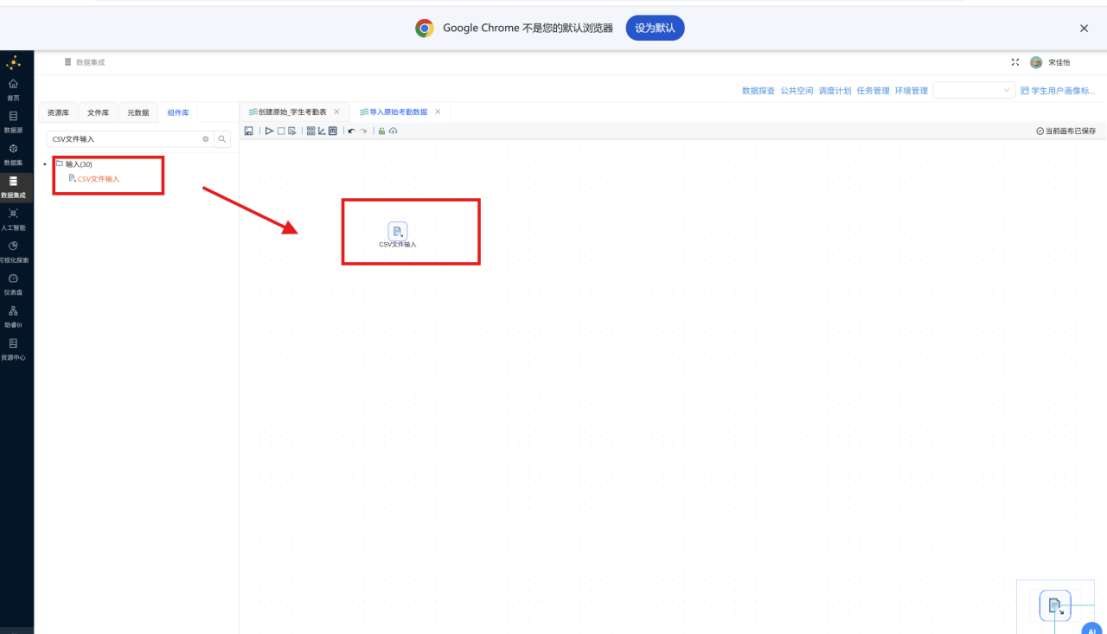
步骤二: 双击该组件打开配置窗口,在步骤名称栏填入 "考勤记录"。
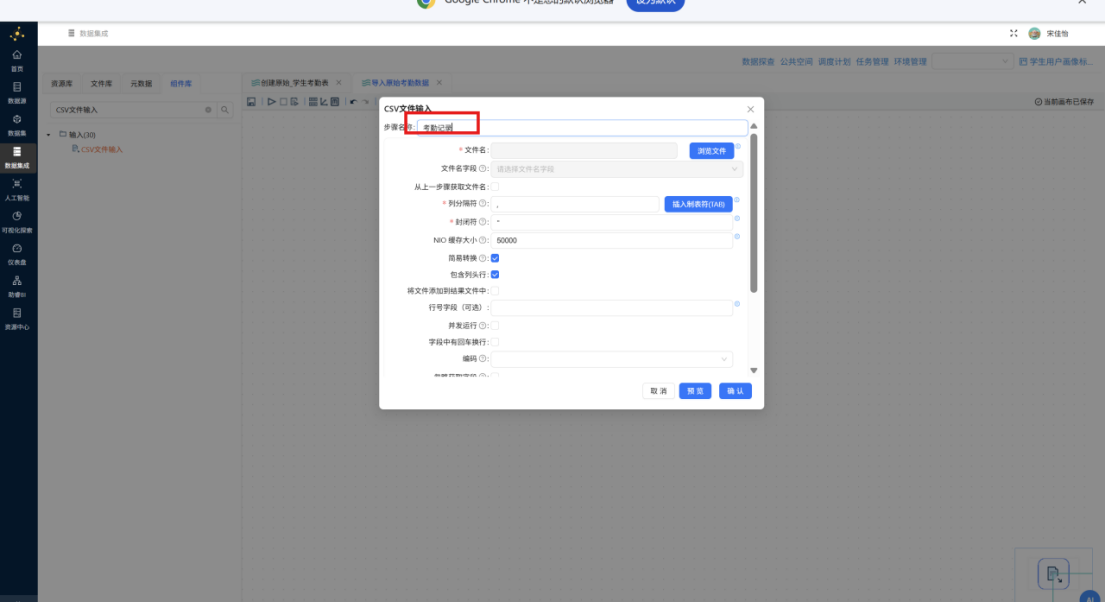
步骤三: 点击文件名右侧的 "浏览文件" 按钮,在弹出的文件选择窗口中定位并选择 "3_kaoqin.csv",随后点击 "确定" 完成文件绑定。
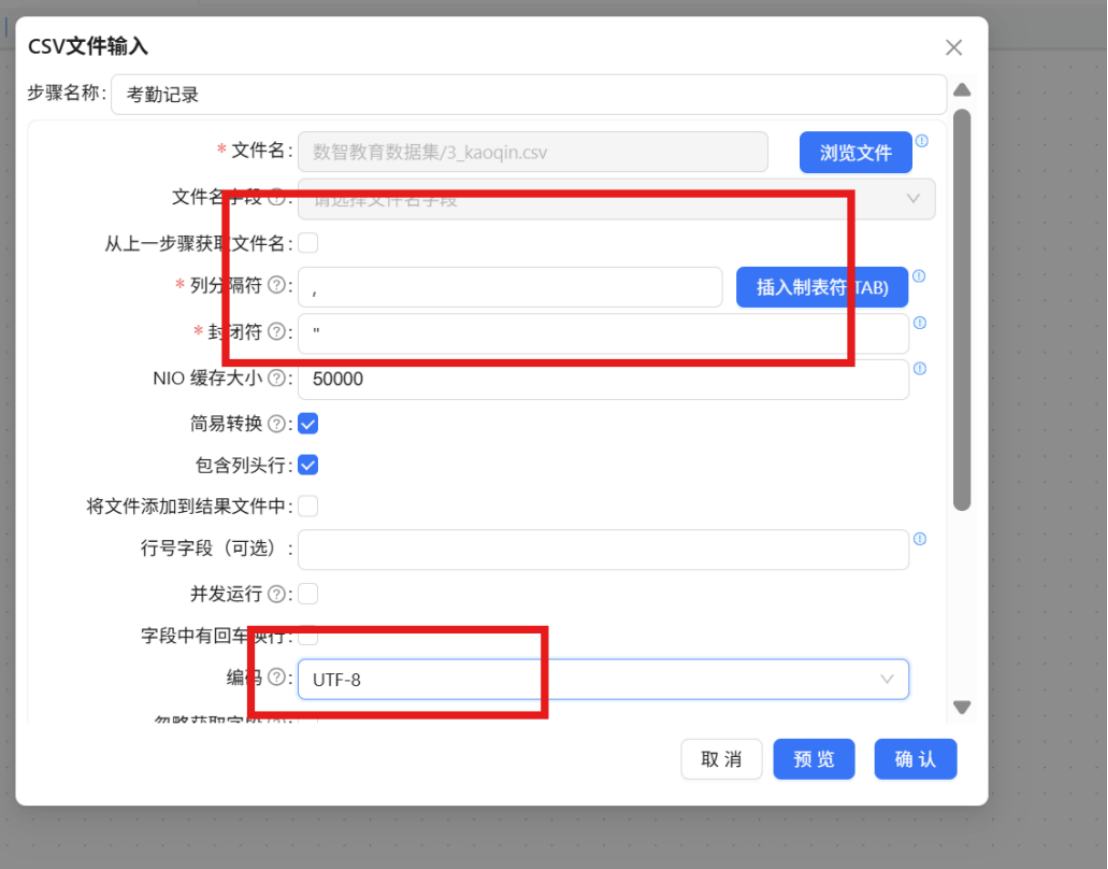
 步骤四: 接下来拖拽一个“表输出”组件到画布,并创建“考勤记录”CSV文件输入组件到“表输出”组件的连线,连线类型选择“主输出步骤”
步骤四: 接下来拖拽一个“表输出”组件到画布,并创建“考勤记录”CSV文件输入组件到“表输出”组件的连线,连线类型选择“主输出步骤”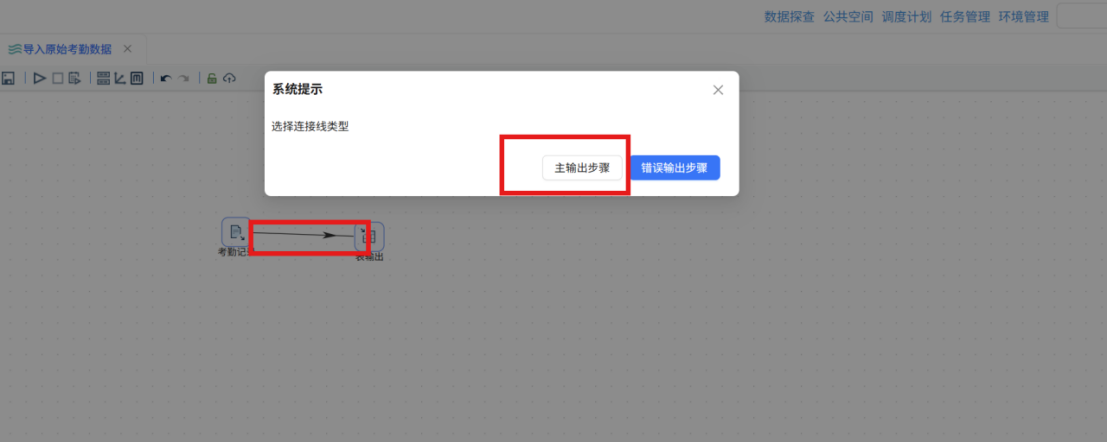 步骤五: 双击“表输出”组件,基本配置中,数据库连接选择“团队私有数据库”,目标表输入我们使用SQL组件创建的“raw_attendance”,具体配置如下:
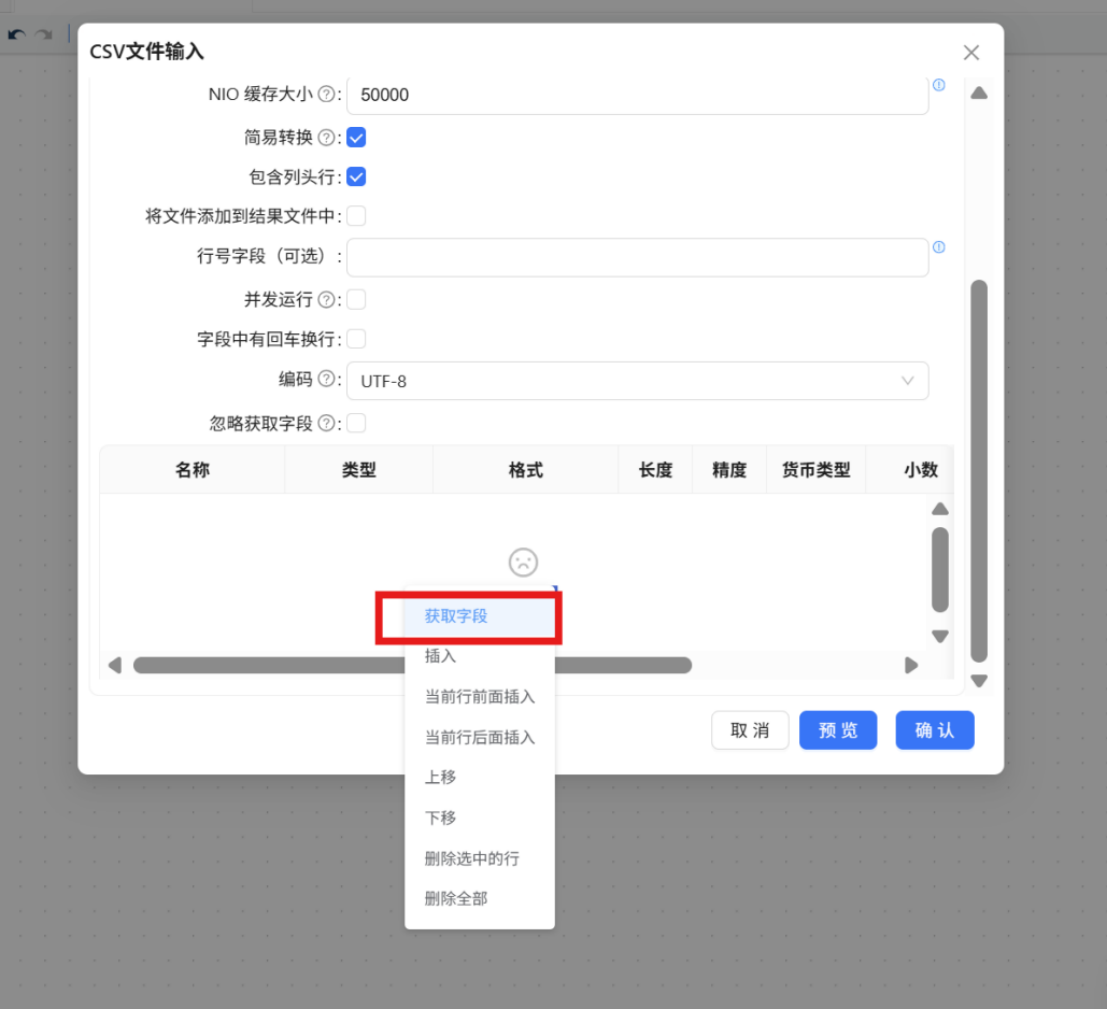
步骤五: 双击“表输出”组件,基本配置中,数据库连接选择“团队私有数据库”,目标表输入我们使用SQL组件创建的“raw_attendance”,具体配置如下: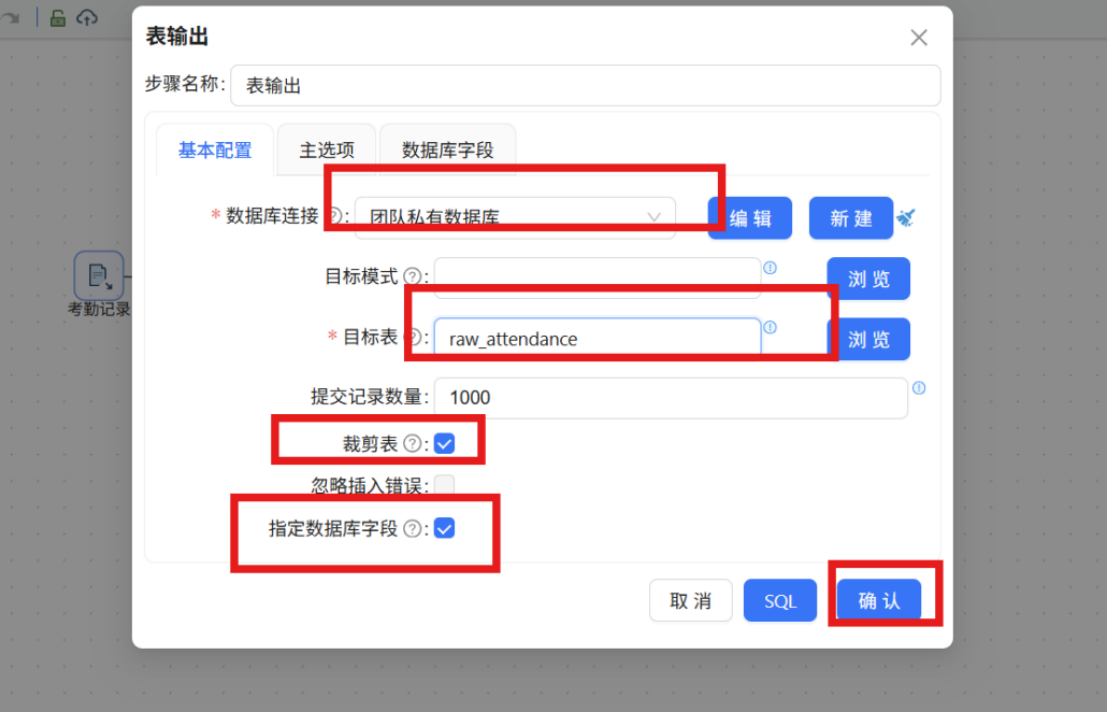 步骤六: 点击“数据库字段”,在空白处右键“获取字段”
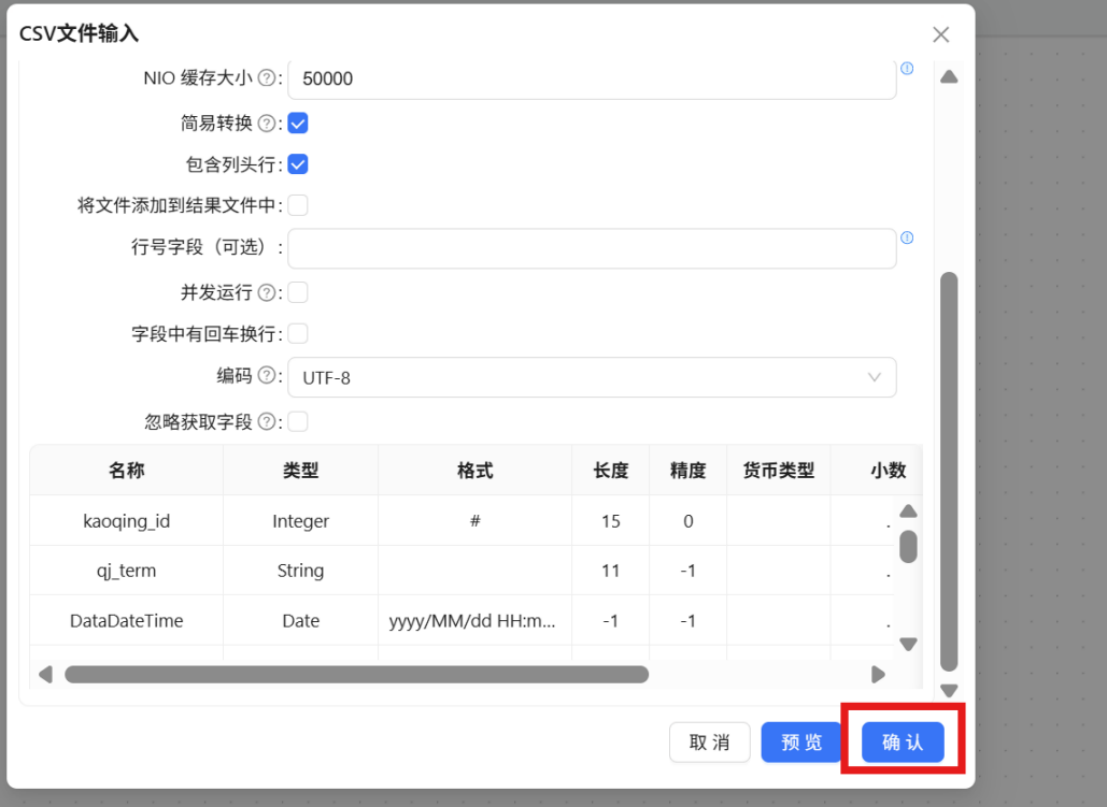
步骤六: 点击“数据库字段”,在空白处右键“获取字段”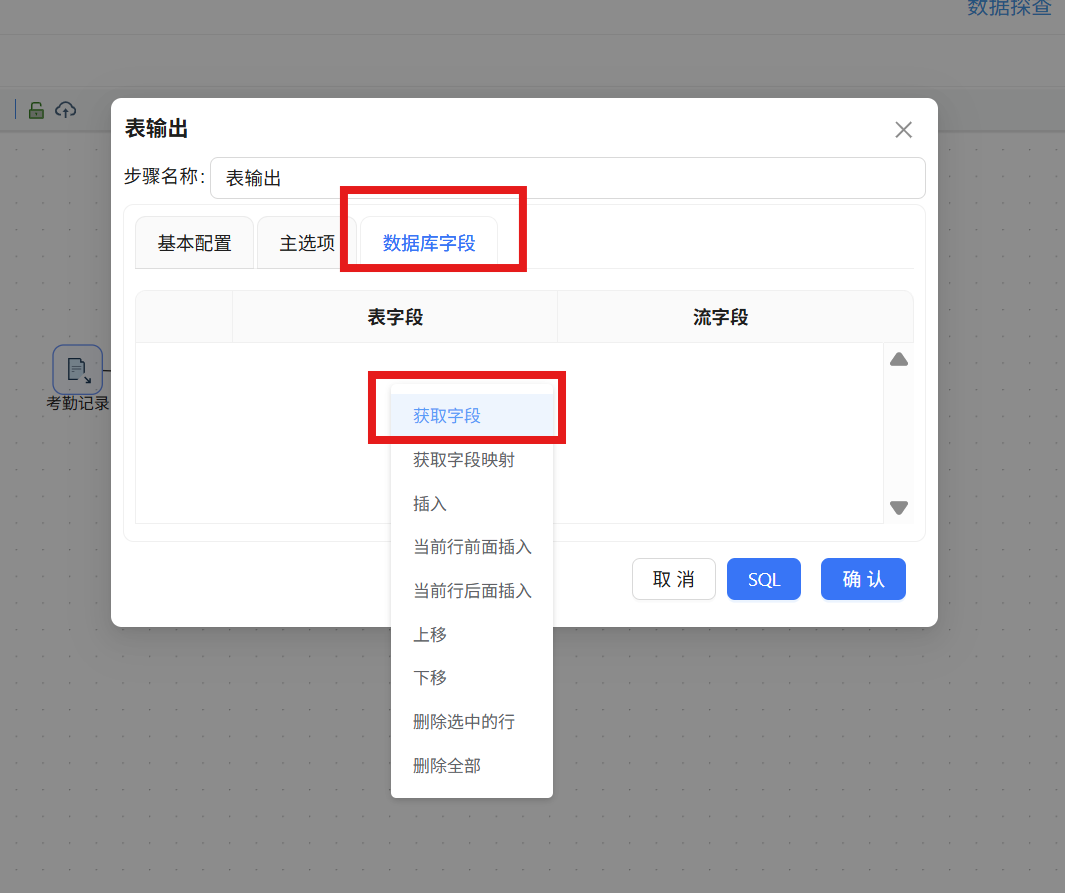 步骤七: 将表字段修改为建表语句中对应的字段,点击“确认”
步骤七: 将表字段修改为建表语句中对应的字段,点击“确认”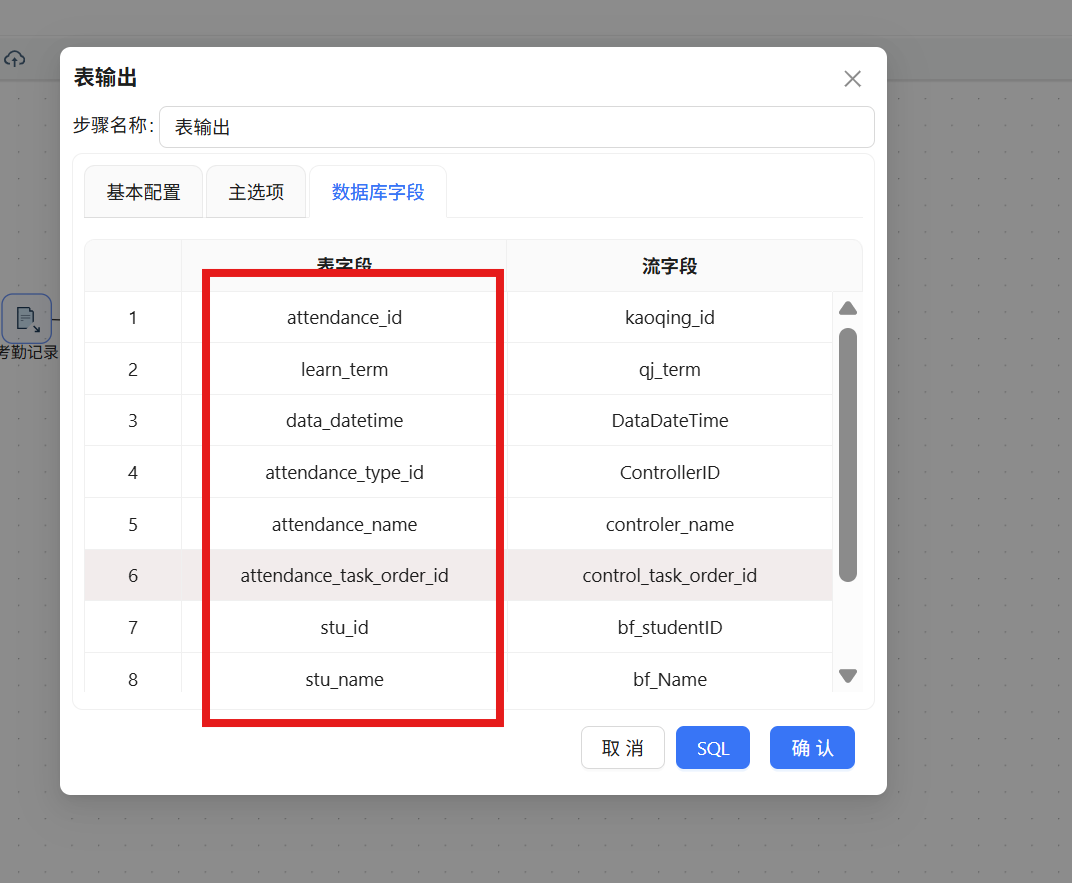 步骤八: 完成后运行转换流,运行过程会定时刷新组件状态,并画布下面显示执行日志。
步骤八: 完成后运行转换流,运行过程会定时刷新组件状态,并画布下面显示执行日志。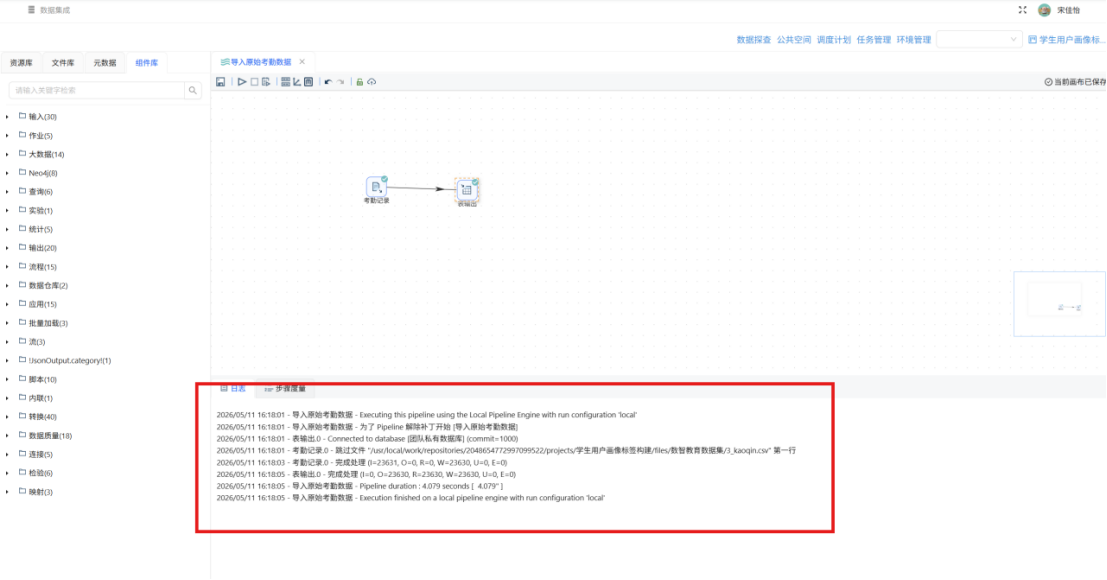
4.2.3.2 原始考勤类型表数据导入
参照 "4.2.3.1 原始考勤记录表数据导入" 小节的实验操作流程,完成原始考勤类型表 "4_kaoqintype.csv" 的数据导入工作,将其写入团队私有数据库。
(1)创建原始_考勤类型表
新建转换工作流并命名为 "创建原始_考勤类型表",向画布中拖入 "执行一个SQL脚本" 组件,通过执行 SQL 脚本完成考勤类型表的创建。
建表 SQL 脚本如下:
CREATE TABLE IF NOT EXISTS `raw_attendance_type` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '自增ID',
`attendance_type_id` varchar(64) NOT NULL COMMENT '考勤类型id',
`attendance_type_name` varchar(100) DEFAULT NULL COMMENT '考勤类型名称',
`attendance_task_order_id` varchar(64) DEFAULT NULL COMMENT '考勤事件id',
`attendance_task_name` varchar(100) DEFAULT NULL COMMENT '考勤事件名',
`create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '入库时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_attendance_type_id` (`attendance_task_order_id`)
) COMMENT='原始_考勤类型表';执行 "创建原始_考勤类型表" 转换流:
(2)导入原始考勤类型数据
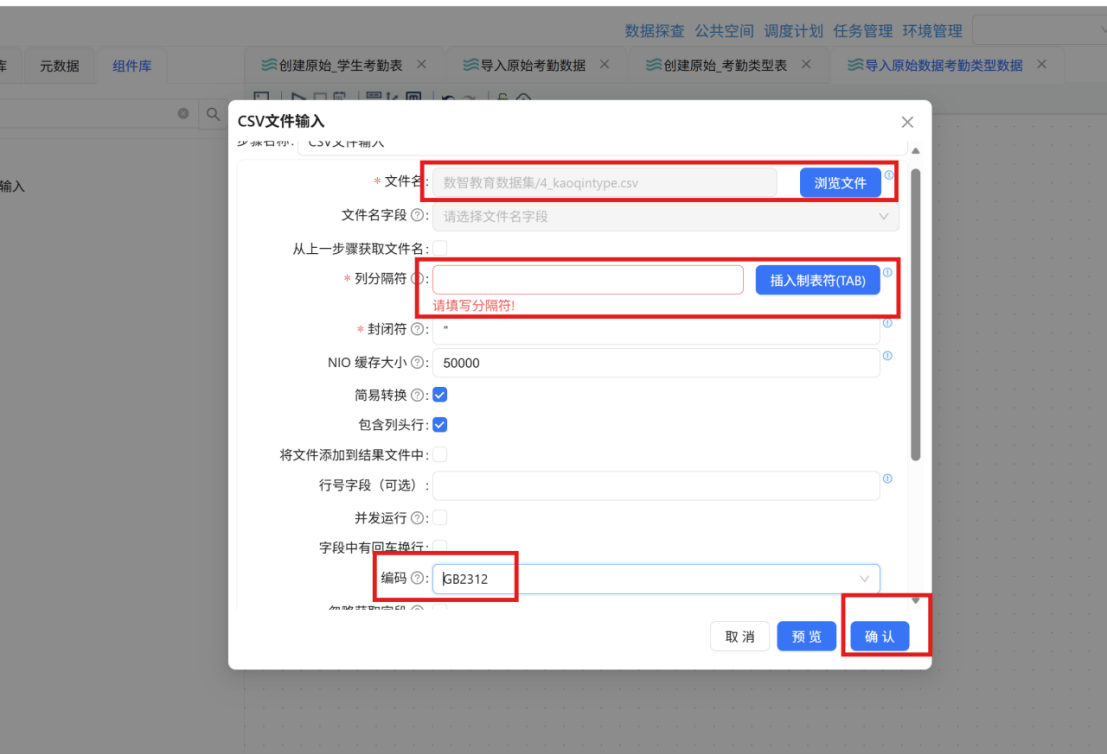
⚠️ 特别说明: 使用 "CSV文件输入" 组件时,考勤类型原始表的列分隔符与考勤记录表不同。在配置中需要进行如下特殊设置:
- 列分隔符: 选择 "插入制表符(TAB)"
- 编码方式: 设置为 "GB2312"
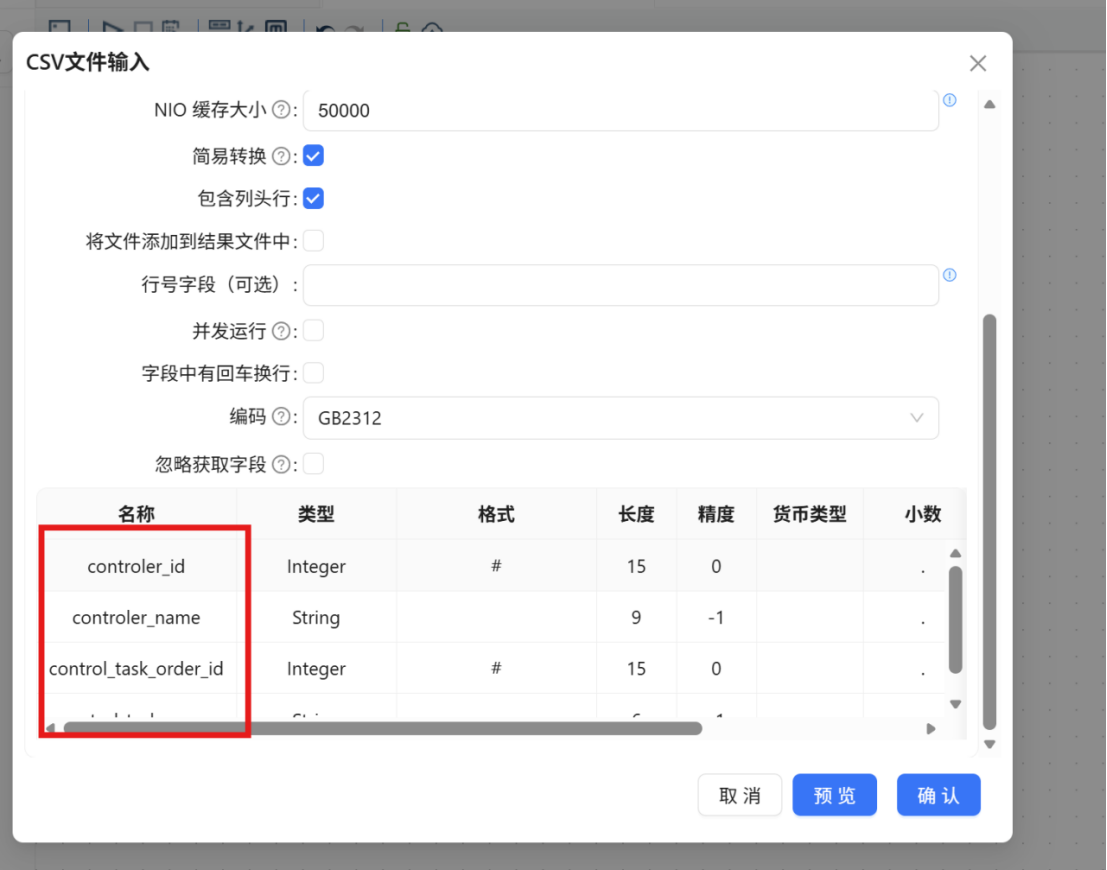
表输出组件 的配置方法与 "2.2.3.1 原始考勤记录表数据导入" 小节中的配置完全一致,目标表选择 raw_attendance_type。
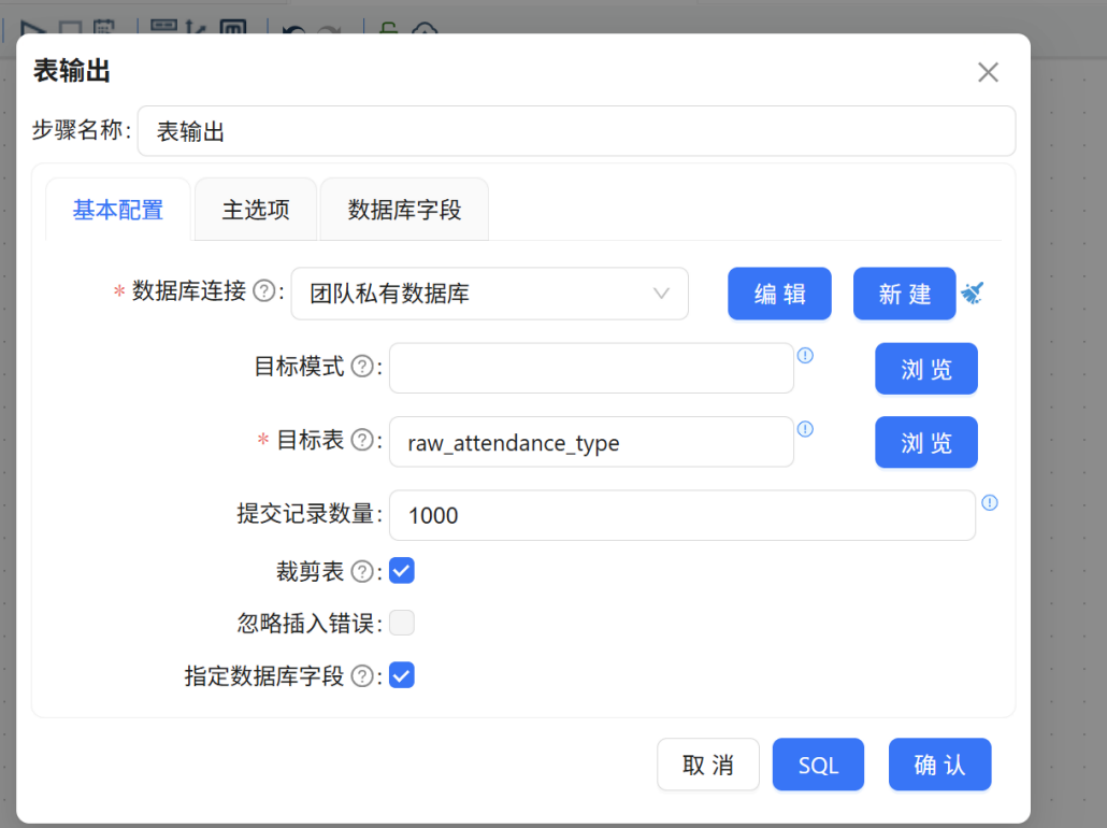
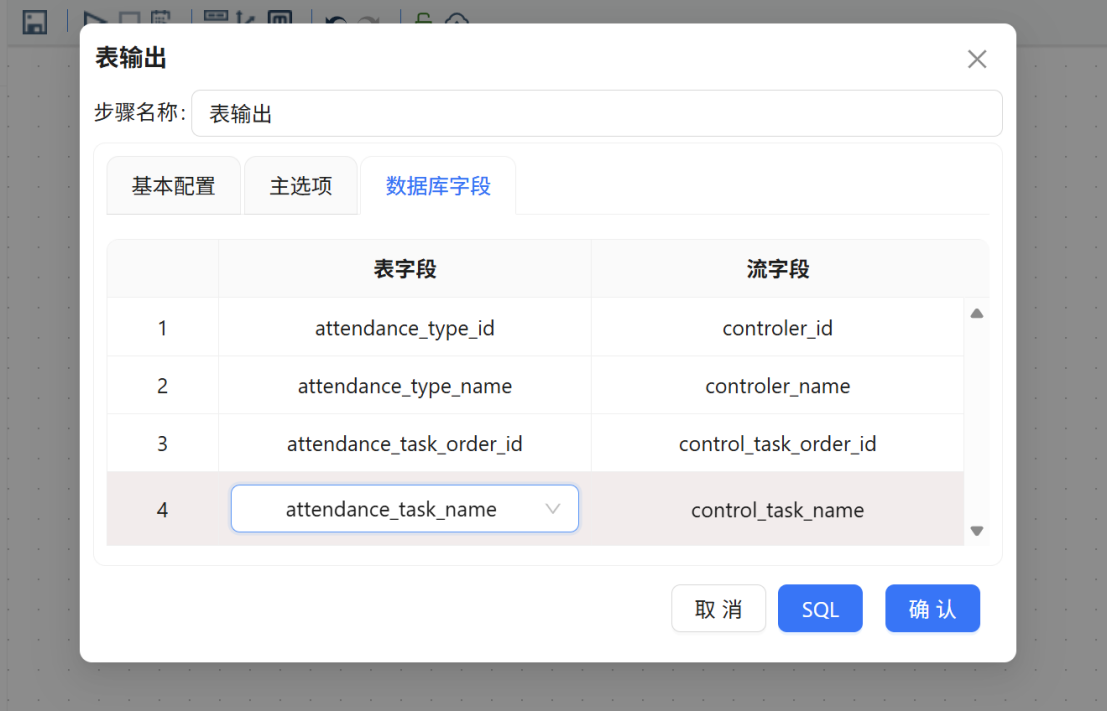
配置完成后执行转换流,运行过程中各组件状态会定期刷新,画布下方将同步输出执行日志。
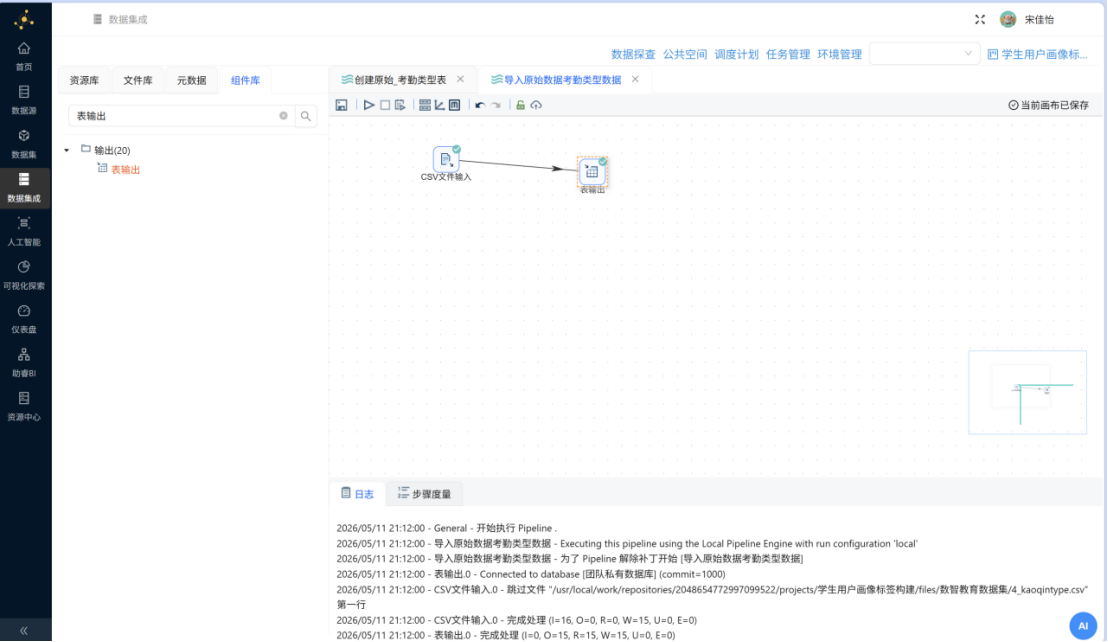
4.2.3.3 原始学生基本信息表数据导入
参照 "2.2.3.1 原始考勤记录表数据导入" 小节的实验操作流程,完成原始学生基本信息表 "2_student_info.csv" 的数据导入工作,将其写入团队私有数据库。
(1)创建原始_学生信息表
建表 SQL 脚本如下:
CREATE TABLE IF NOT EXISTS `raw_student_info` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '自增ID',
`stu_id` varchar(64) NOT NULL COMMENT '学生ID',
`stu_name` varchar(100) DEFAULT NULL COMMENT '学生姓名',
`stu_sex` varchar(10) DEFAULT NULL COMMENT '性别',
`stu_nation` varchar(50) DEFAULT NULL COMMENT '民族',
`born_date` varchar(10) DEFAULT NULL COMMENT '出生日期(年)',
`cla_name` varchar(100) DEFAULT NULL COMMENT '班级名',
`native_place` varchar(200) DEFAULT NULL COMMENT '家庭住址',
`residence_type` varchar(50) DEFAULT NULL COMMENT '家庭类型',
`policy` varchar(50) DEFAULT NULL COMMENT '政治面貌',
`cla_id` varchar(64) DEFAULT NULL COMMENT '班级ID',
`cla_term` varchar(30) DEFAULT NULL COMMENT '班级学期',
`live_on_campus` varchar(10) DEFAULT NULL COMMENT '是否住校',
`leave_school` varchar(10) DEFAULT NULL COMMENT '是否退学',
`dormitory_no` varchar(50) DEFAULT NULL COMMENT '宿舍号',
`create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '入库时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_student_id` (`stu_id`),
KEY `idx_cla_id` (`cla_id`)
) COMMENT='原始_学生信息表';执行 "创建原始_学生信息表" 转换流:
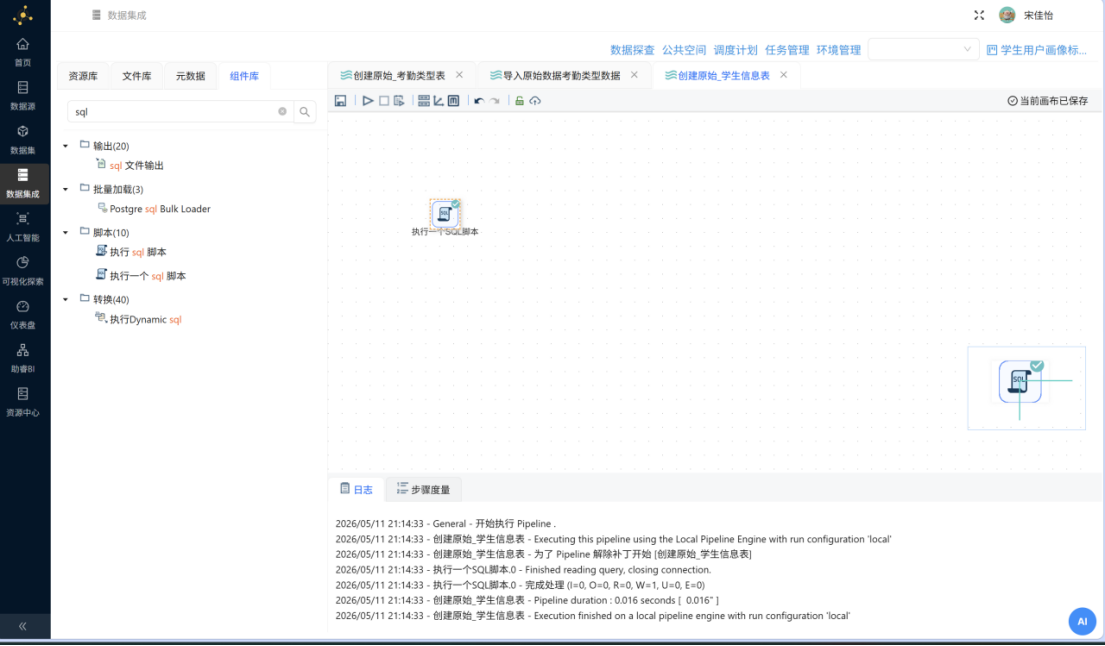
(2)导入原始学生信息数据
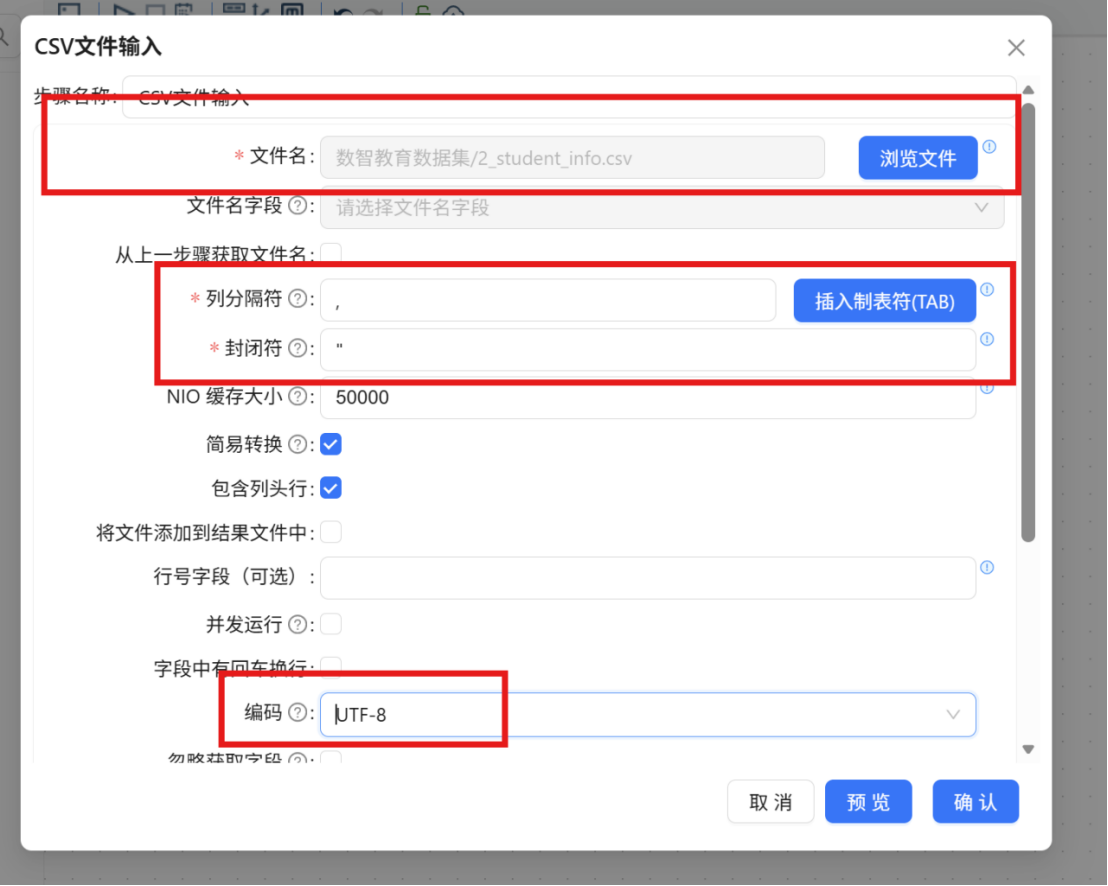
使用 "CSV文件输入" 组件读入 "2_student_info.csv" 数据文件。
在获取字段时,需要将 "bf_leaveSchool" 字段的类型手动修改为 "String",避免因类型识别错误导致数据导入异常。
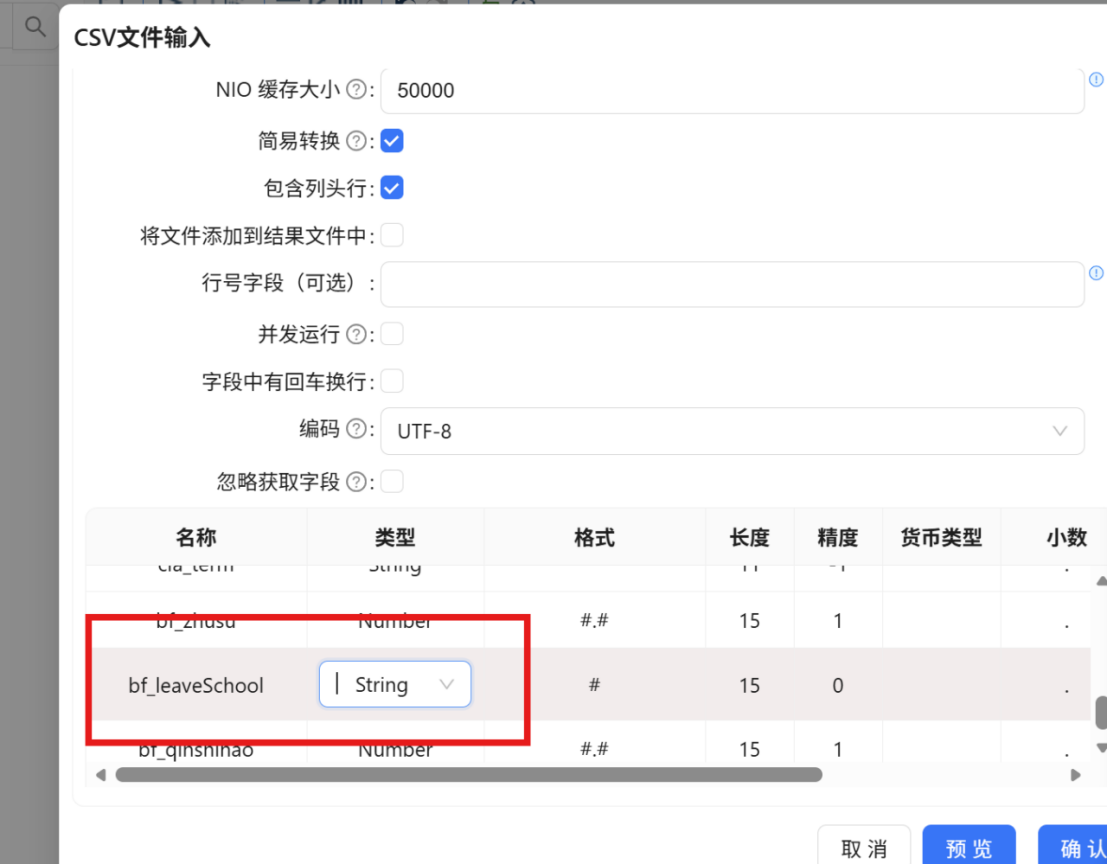
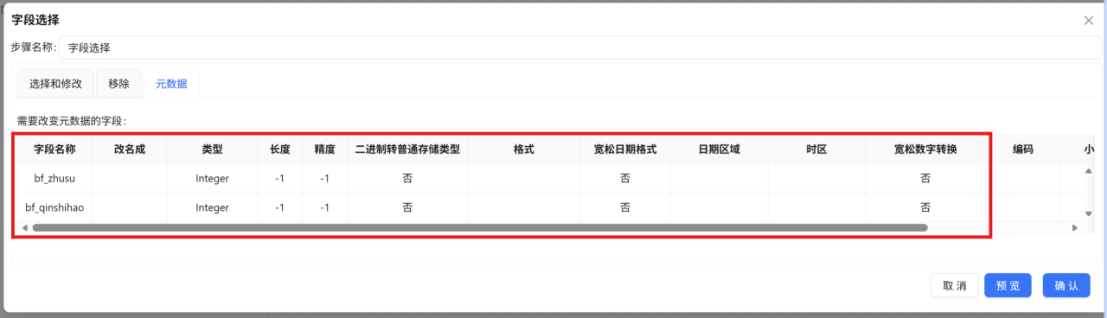
⚠️ 特别说明: bf_zhusu 和 bf_qinshihao 这两个字段在原始数据中为 Integer 类型。为避免在后续处理中出现小数(如 1.0、101.0 等),需要使用 "字段选择" 组件对其进行类型固化与规范化处理。
步骤一: 拖拽 "字段选择" 组件至画布中,创建从 "CSV文件输入" 组件到 "字段选择" 组件的连接线,连线类型选择 "主输出步骤"。
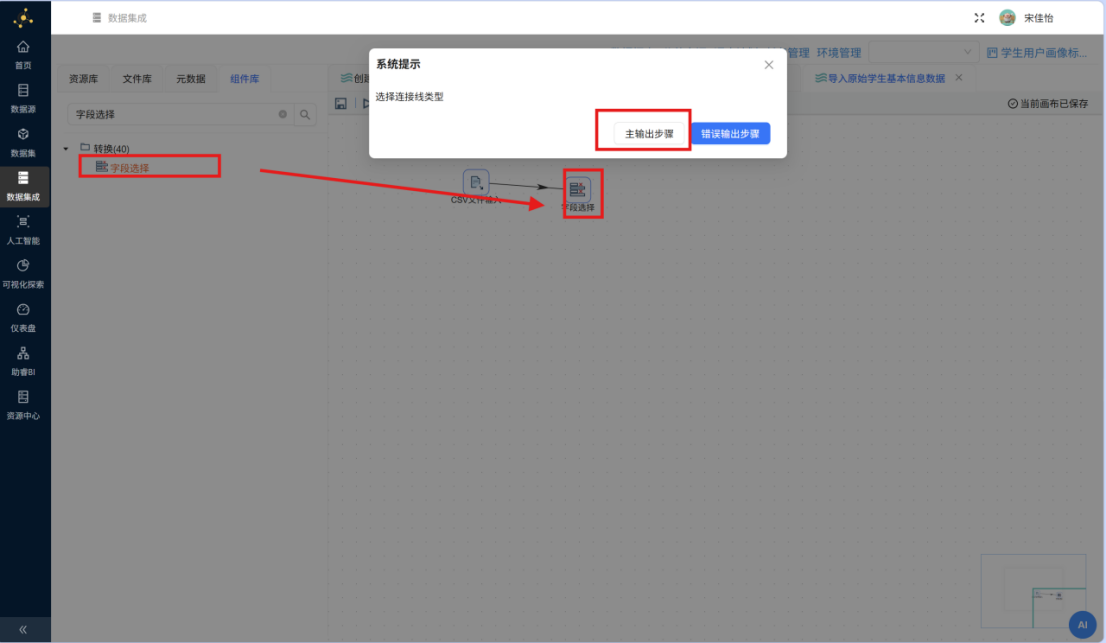
步骤二: 双击 "字段选择" 组件,在配置窗口中切换至 "元数据" Tab 页,在空白处右键点击插入 2 行新记录,分别将 bf_zhusu 和 bf_qinshihao 字段的元数据进行如下规范化设置:
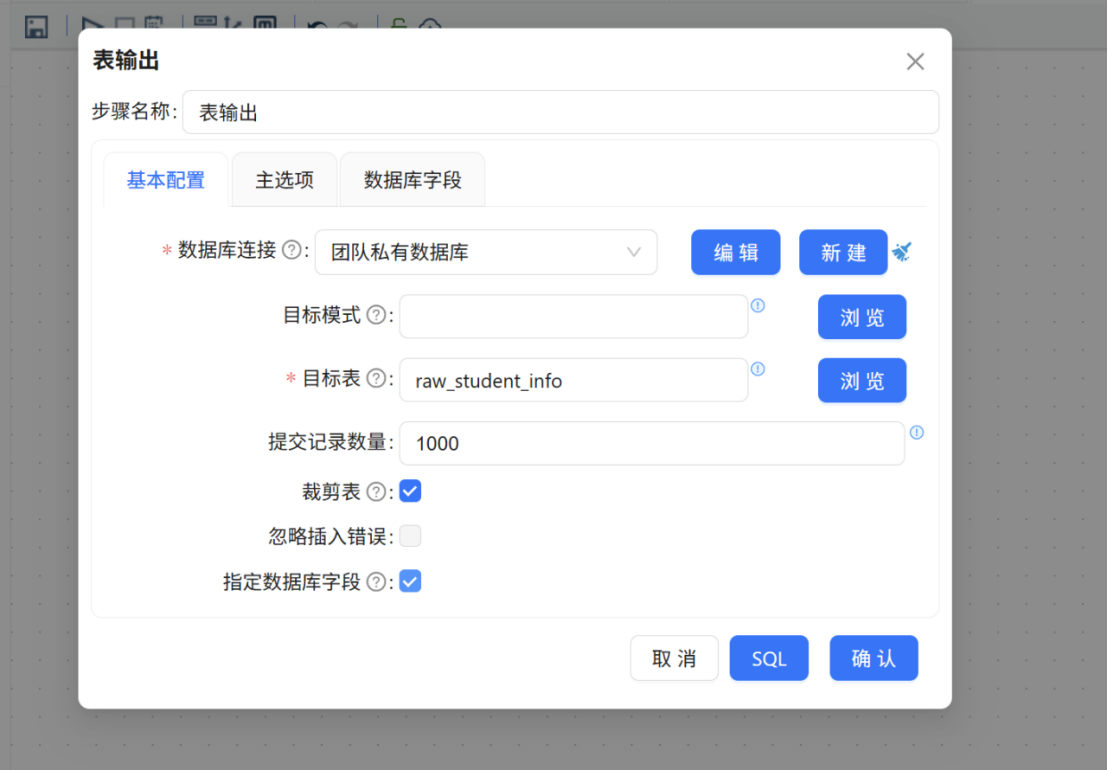
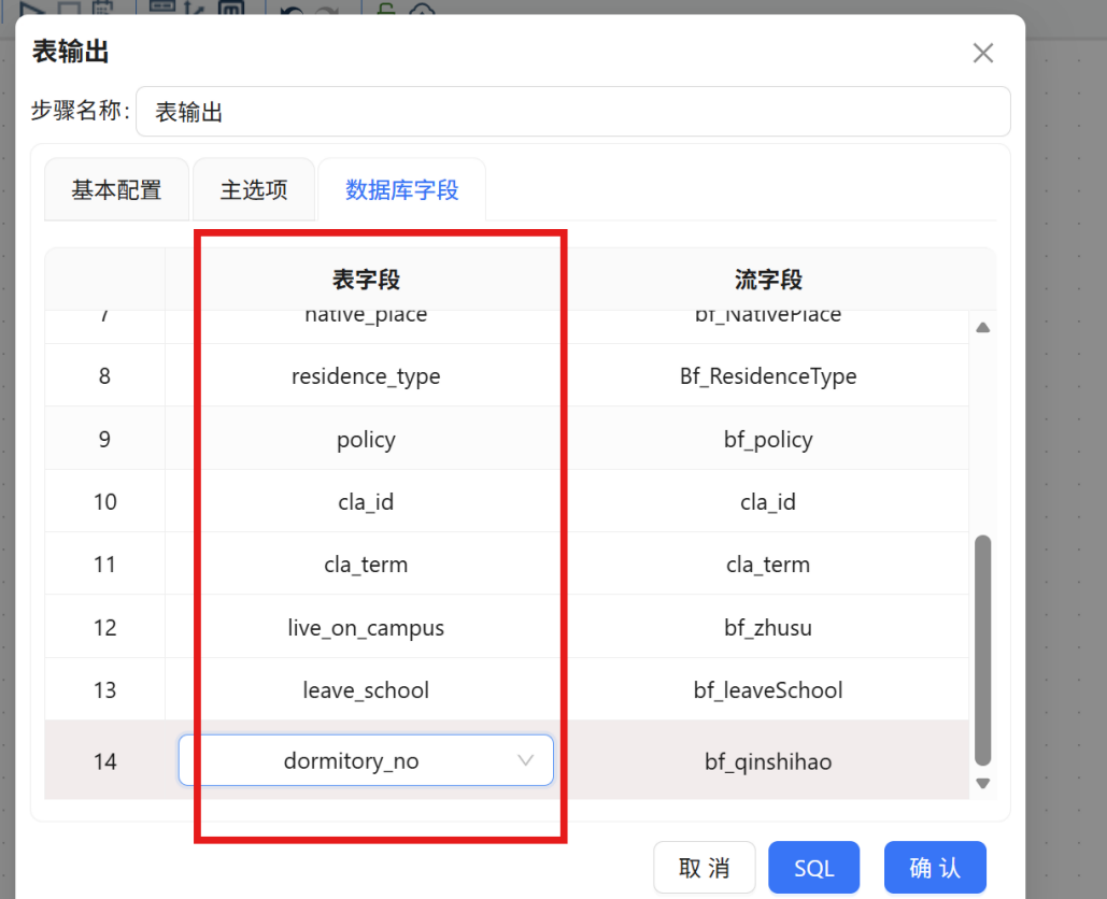
步骤三: 使用 "表输出" 组件,将 "2_student_info.csv" 数据写入团队私有数据库的 raw_student_info 表中。
配置完成后,执行转换流,确认学生信息数据成功写入数据库:
4.2.4 创建学生考勤主题标签表
新建转换工作流,将其命名为 "创建学生考勤主题标签表",在该工作流中拖入 "执行一个SQL脚本" 组件,通过 SQL 脚本来创建最终的考勤主题标签汇总表。整个转换流结构如下所示:
配置说明: 在组件中填写下方 SQL 脚本,目标数据库连接选择 "团队私有数据库",确保该连接具备建表执行权限。
SQL 脚本如下:
CREATE TABLE IF NOT EXISTS student_attendance_stats (
id INT PRIMARY KEY AUTO_INCREMENT COMMENT '自增主键',
student_id INT NOT NULL COMMENT '学生ID',
student_name VARCHAR(50) NOT NULL COMMENT '学生姓名',
class_id INT NOT NULL COMMENT '班级ID',
class_name VARCHAR(50) NOT NULL COMMENT '班级名称',
grade VARCHAR(10) NOT NULL COMMENT '年级',
gender VARCHAR(10) NOT NULL COMMENT '性别',
birth_date VARCHAR(10) NOT NULL COMMENT '出生日期',
political_status VARCHAR(20) NOT NULL COMMENT '政治面貌',
is_boarder VARCHAR(10) NOT NULL COMMENT '是否住校',
campus_type VARCHAR(10) NOT NULL COMMENT '校区类型',
late_count INT NOT NULL DEFAULT 0 COMMENT '迟到次数',
early_leave_count INT NOT NULL DEFAULT 0 COMMENT '早退次数',
leave_count INT NOT NULL DEFAULT 0 COMMENT '请假次数',
uniform_violate_count INT NOT NULL DEFAULT 0 COMMENT '没穿校服次数',
create_time DATETIME DEFAULT CURRENT_TIMESTAMP COMMENT '统计入库时间',
INDEX idx_student (student_id),
INDEX idx_class (class_id),
INDEX idx_grade (grade)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='学生考勤主题标签表';其余参数保持默认配置即可
完成配置后运行转换流,运行过程中各组件状态会实时刷新,画布下方同步输出执行日志,确认标签表创建成功。
4.3 学生考勤主题标签构建
4.3.1 数据转换流逻辑说明
本转换流按照 "数据接入 → 清洗整合 → 维度拆解 → 标签标记 → 指标计算 → 结果落地" 的处理链路依次展开:
- 数据接入: 分别接入考勤原始打卡表、考勤类型码表、学生信息基础表
- 数据整合: 通过多表关联,为原始打卡记录绑定学生班级、住校属性及考勤事件名称
- 标签标记: 根据考勤事件名称中的关键词,自动识别迟到、早退、请假、未穿校服等异常行为
- 指标计算: 按日核算在校时长,按多维度聚合统计各类异常次数
- 结果落地: 将计算结果统一写入考勤统计结果表,供报表展示、条件查询和深度分析直接调用
整体转换流逻辑如下:
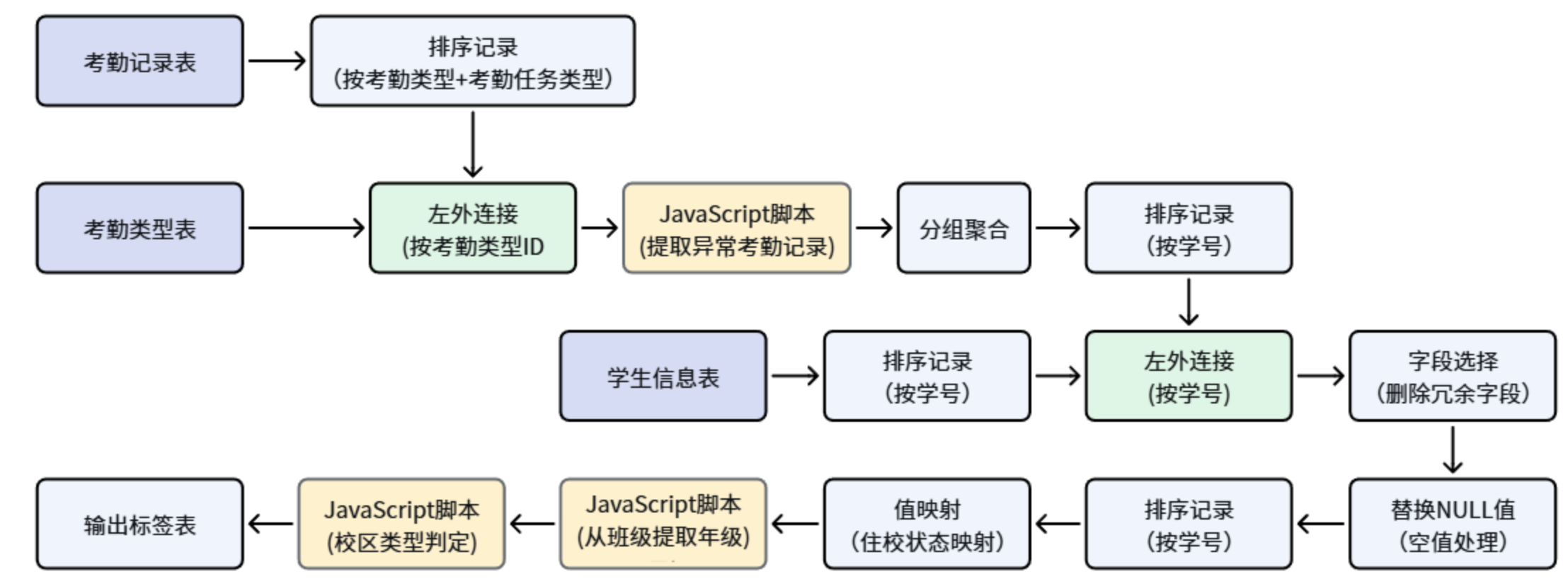
各组件功能说明如下:
|
组件 |
作用 |
|
表输入 |
读取数据库中的原始数据表 |
|
排序记录 |
按照指定字段对数据进行排序,为记录集连接做准备 |
|
记录集连接 |
按关联字段连接两表,补充考勤行为名称或学生属性 |
|
字段选择 |
移除冗余字段,仅保留核心必要字段 |
|
JavaScript脚本 |
执行脚本逻辑,通过关键词匹配提取异常考勤记录,生成二进制标记 |
|
分组 |
按指定维度分组,使用SUM函数聚合统计各类异常次数 |
|
替换NULL值 |
将空值字段替换为"未知",避免下游出现空指针 |
|
值映射 |
将住校状态编码(0/1)映射为"否"/"是" |
|
表输出 |
将最终结果输出至数据库目标表 |
4.3.2 数据接入:获取考勤记录、考勤类型数据、学生信息数据
在构建标签之前,首先需要将三份基础数据分别接入转换流。其中,考勤记录表记录了每位学生每天的打卡行为;考勤类型表定义了各类考勤行为所对应的类型名称(如正常考勤、没穿校服等);学生信息表则提供了学生姓名、班级、是否住校等核心属性。只有将这三份数据完整接入并在后续环节进行关联,才能准确判断每次考勤属于正常还是违纪,同时支撑住校维度等多角度的统计分析。
具体操作步骤如下:
步骤一: 切换到资源库视图,右键点击根目录,选择 "新建转换流"。
步骤二: 在弹出的窗口中输入转换流名称 "学生考勤主题标签",点击 "确定" 完成创建。
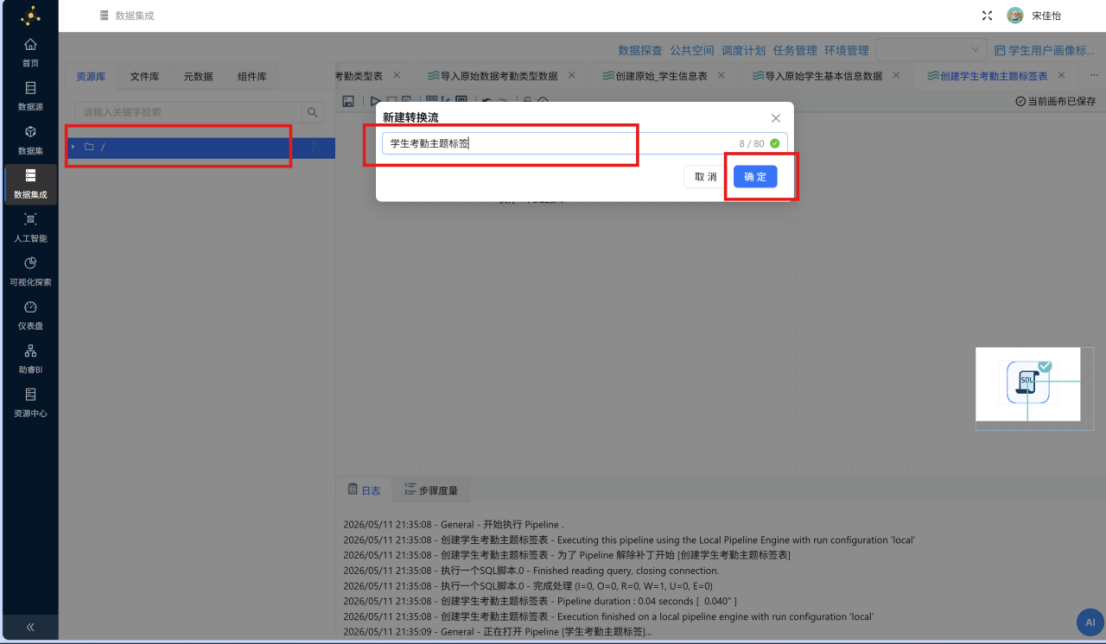
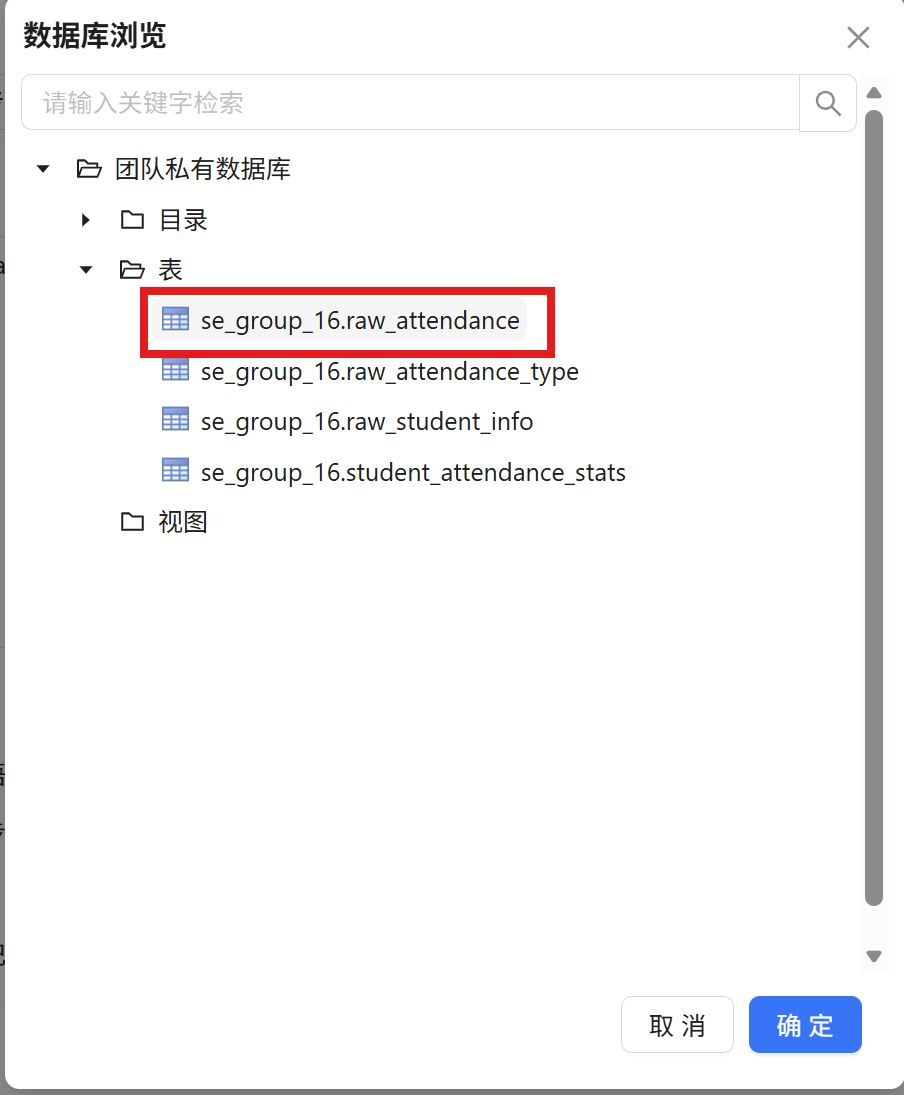
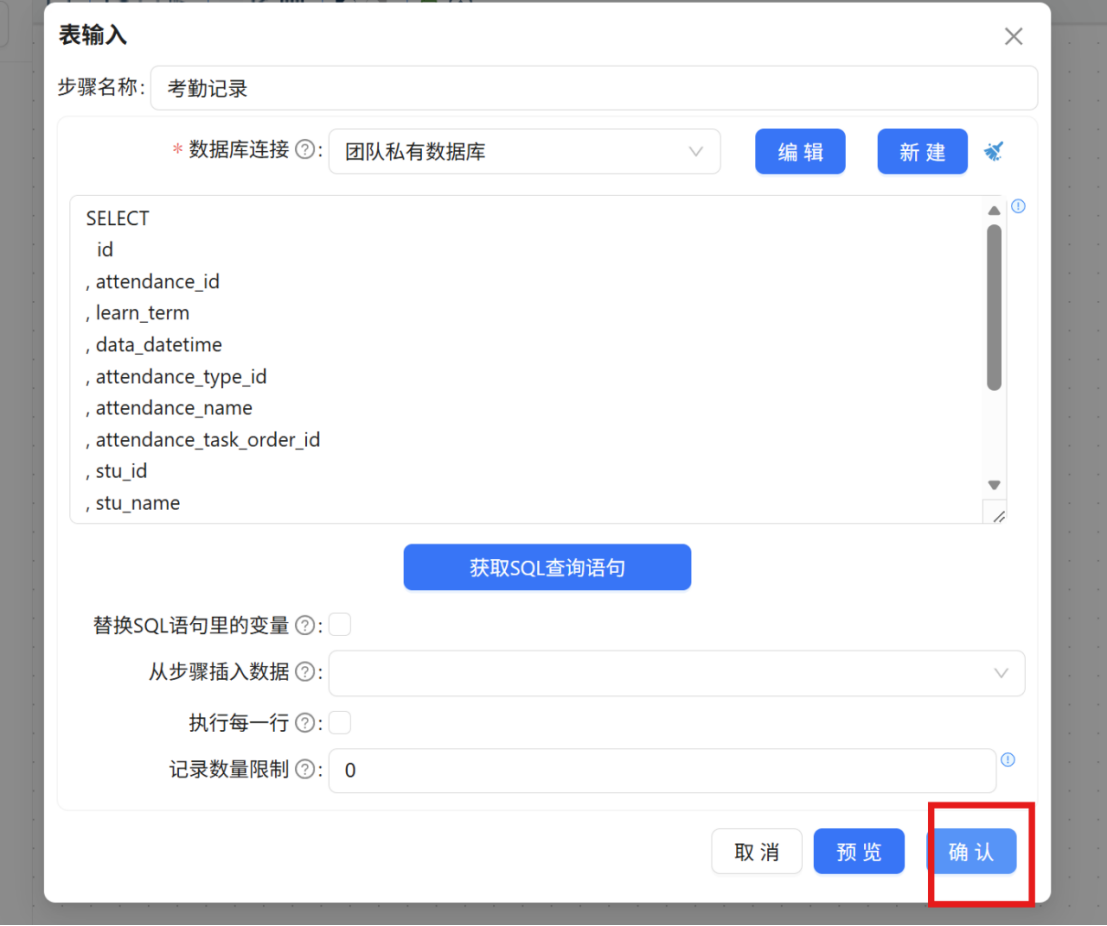
步骤三: 从组件库中拖拽一个 "表输入" 组件至画布,双击打开配置窗口,将其命名为 "考勤记录"。在数据库连接中选择 "团队私有数据库",点击 "获取SQL查询语句" 按钮,在系统弹窗中点击 "确认",自动获取 raw_attendance 考勤记录表的全部字段。
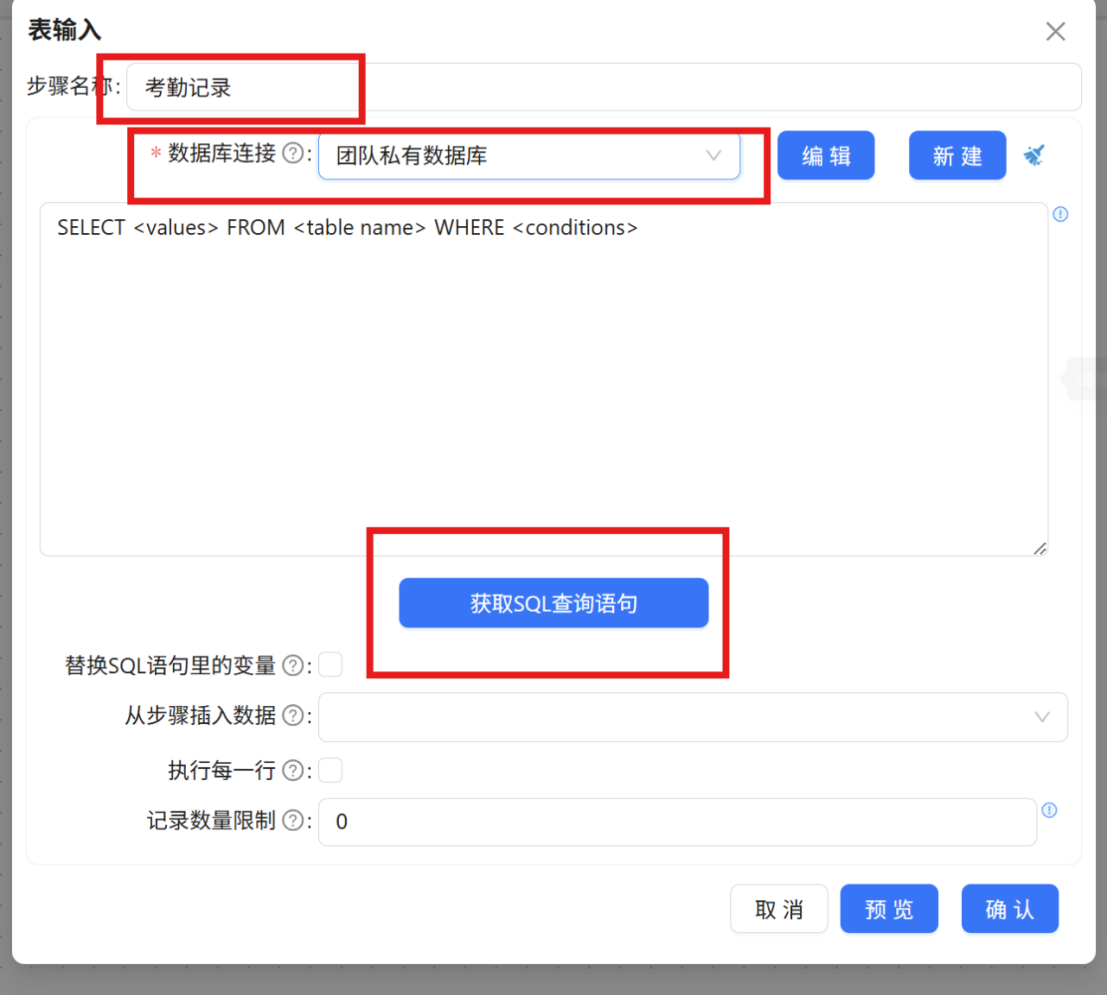
获取到 SQL 查询语句后,点击 "确认" 保存配置。
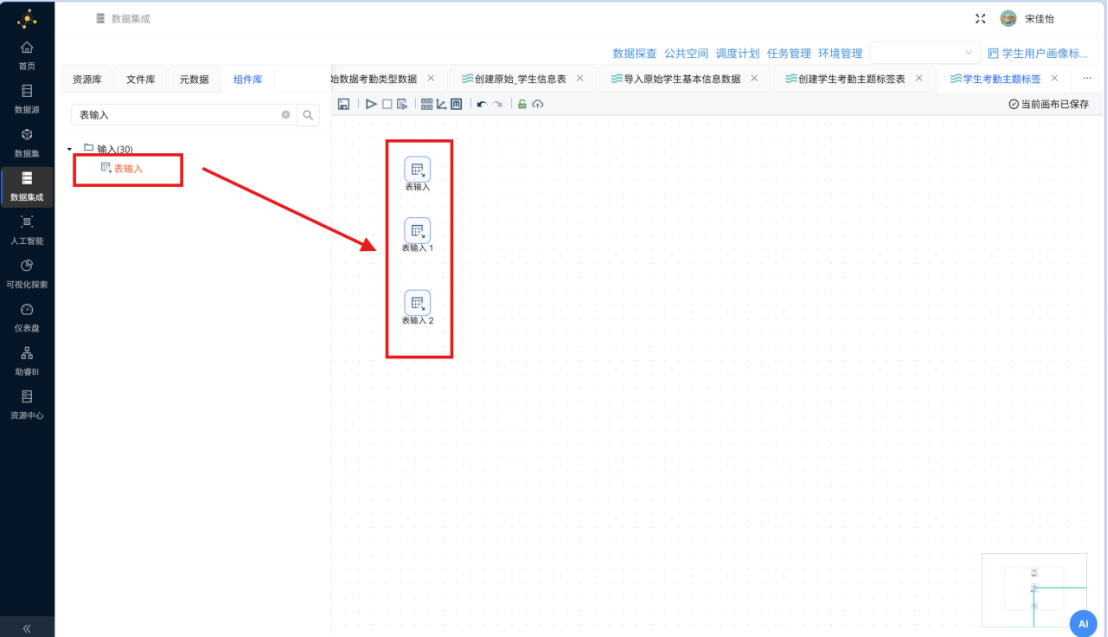
步骤四: 参照上述操作,继续向画布中添加两个 "表输入" 组件,分别进行如下配置:
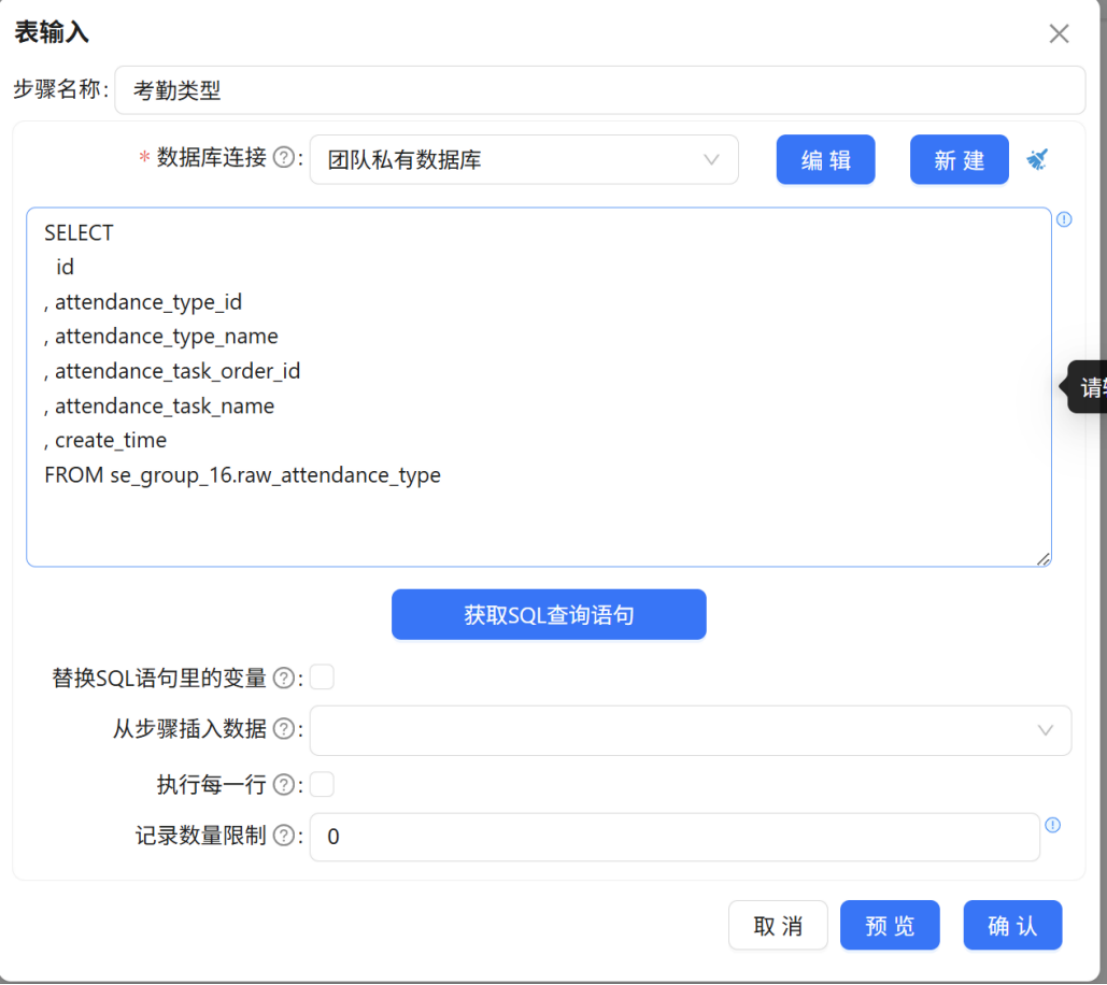
- 将 "表输入 1" 命名为 "考勤类型",获取 raw_attendance_type(原始_考勤类型表)的所有字段数据
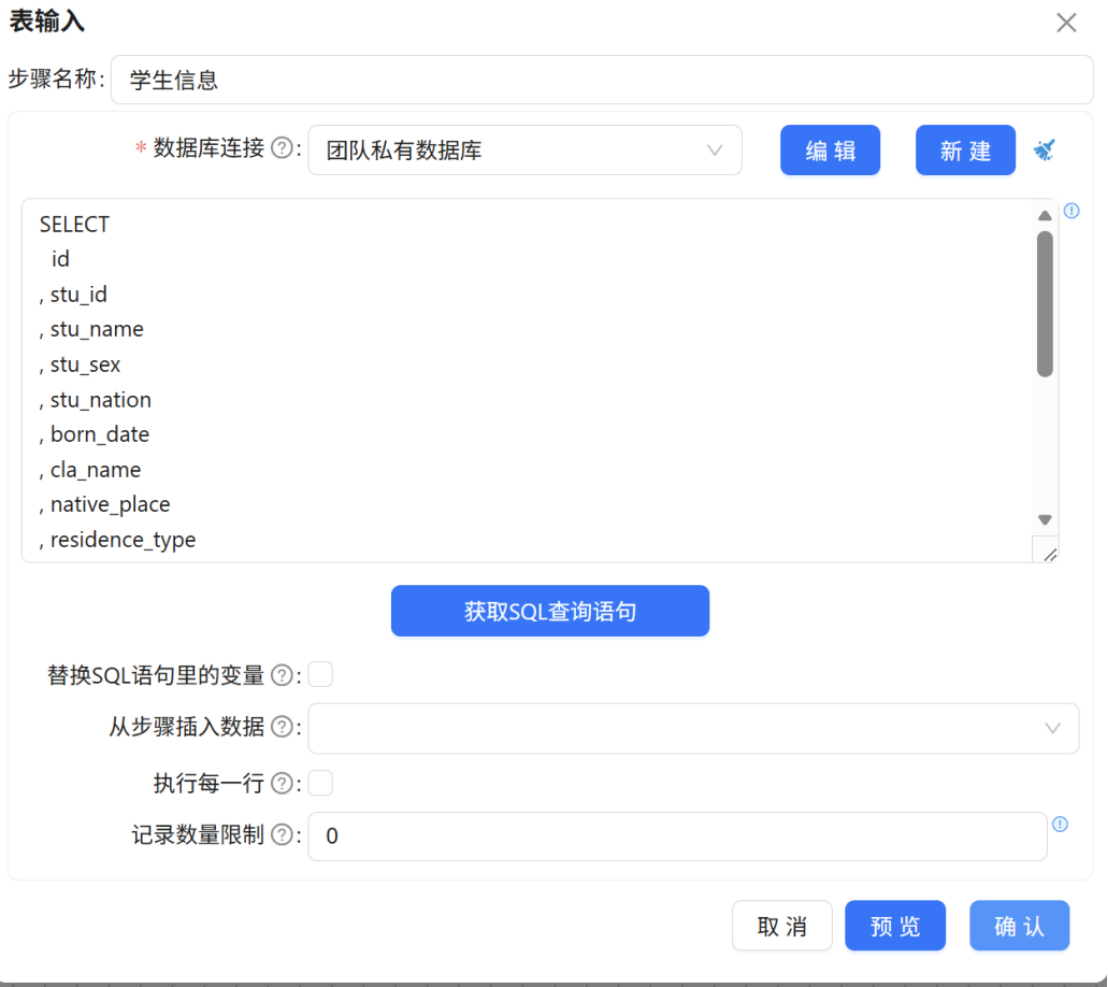
- 将 "表输入 2" 命名为 "学生信息",获取 raw_student_info(原始_学生信息表)的所有字段数据
至此,三份基础数据源均已成功接入转换流,后续将通过记录集连接组件完成多表关联与数据整合。
4.3.3 数据关联:关联考勤记录+考勤类型
完成数据接入后,需要通过 记录集连接 组件将考勤记录与考勤类型进行关联,补充关键的业务语义信息,为后续的标签标记与指标计算奠定基础。
关联背景: 考勤记录表中仅存储了考勤类型ID(attendance_type_id)和考勤任务顺序ID(attendance_task_order_id),缺少具体的考勤行为名称。通过记录集连接组件将考勤主表与考勤类型码表进行关联,即可为每条打卡记录补充"正常考勤""没穿校服""迟到""请假"等具体行为描述,从而确保后续能够精准识别各类考勤行为。
具体操作步骤如下:
步骤一: 在组件库中搜索 "记录集连接" 组件,将其拖拽至画布区域。
步骤二: 创建从 "考勤记录" 表输入组件到 记录集连接 组件的连接线。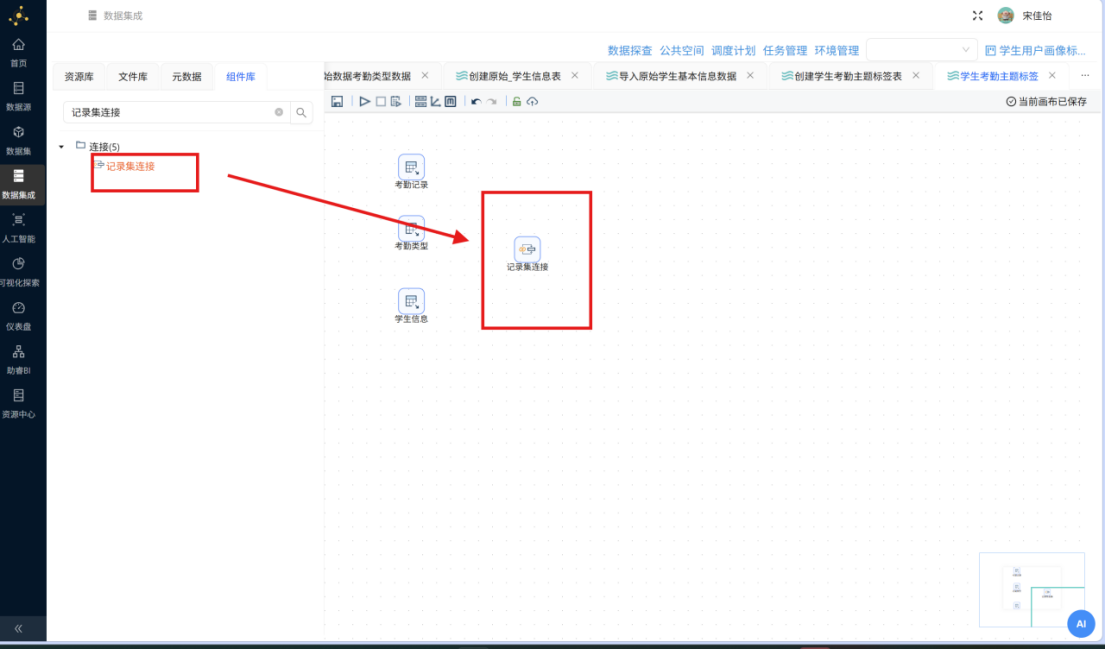
步骤三: 在建立连接线时,系统会弹出 "排序需要" 的提示。这是因为记录集连接组件按照接收数据的顺序进行记录匹配,若输入数据未经排序,可能导致连接结果出现错误。
步骤四: 为避免排序问题导致连接结果异常,在 "考勤记录" 组件与 "记录集连接" 组件之间插入一个 "排序记录" 组件。
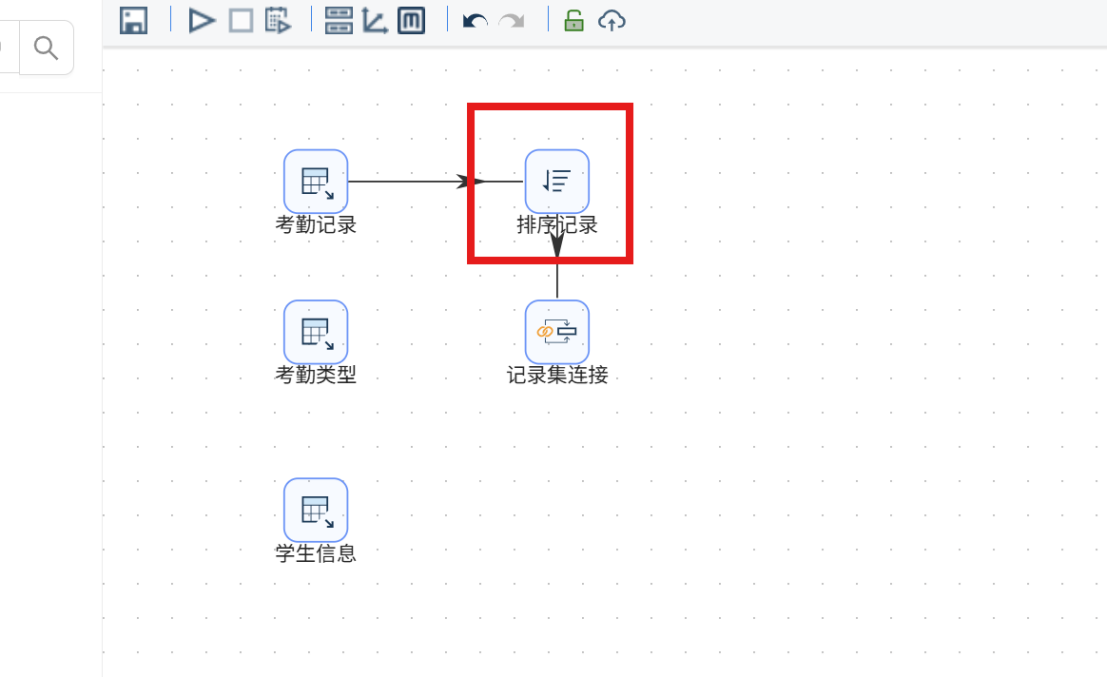
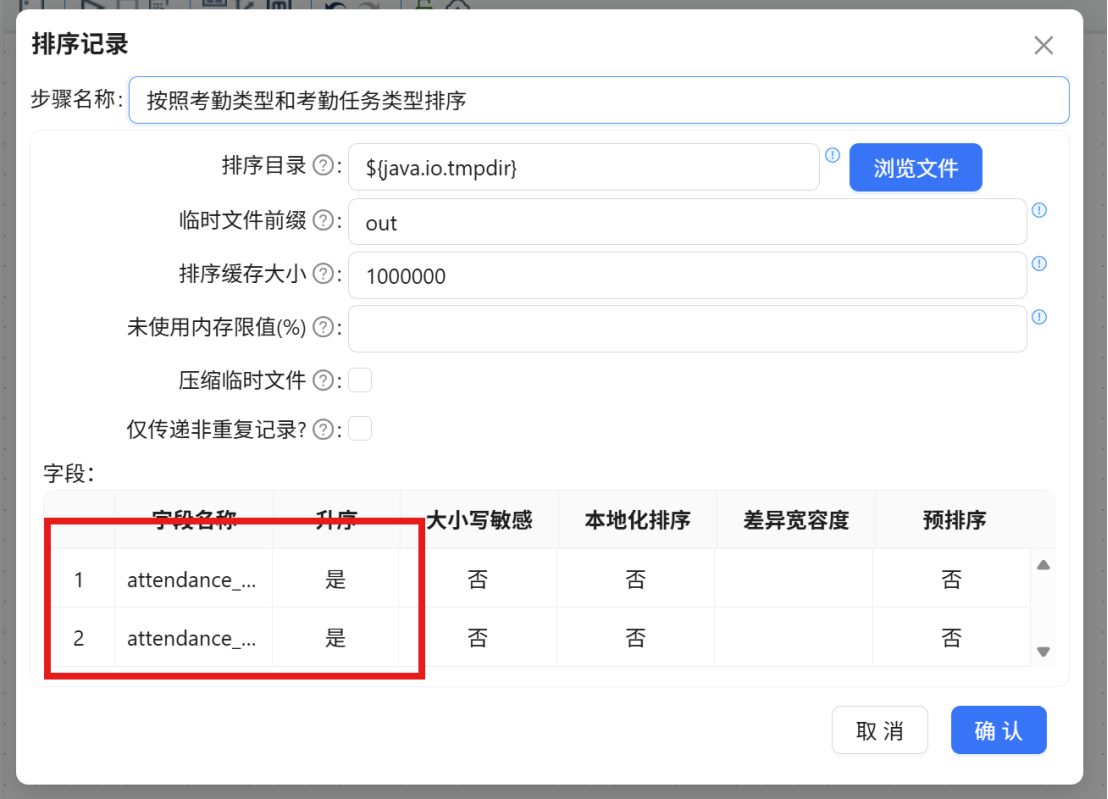
步骤五: 双击 "排序记录" 组件,通过 "获取字段" 功能加载字段列表,删除多余字段,仅保留 attendance_type_id 和 attendance_task_order_id 两个字段。由于下一步的表连接正是基于这两个字段进行匹配,因此需要按照它们对记录进行排序。最后将步骤名称设置为 "按照考勤类型和考勤任务类型排序"。
步骤六: 创建从 "考勤类型" 表输入组件到 记录集连接 组件的连接线。由于考勤类型表中的记录默认已按 attendance_type_id 和 attendance_task_order_id 升序排列,因此无需额外添加排序步骤。
步骤七: 双击 记录集连接 组件,配置考勤记录与考勤类型两张表的关联关系。在下拉列表中分别选择数据来源:第一个 Transform 选择 "按照考勤类型和考勤任务类型排序",第二个 Transform 选择 "考勤类型",连接类型设置为 LEFT OUTER(左外连接)。
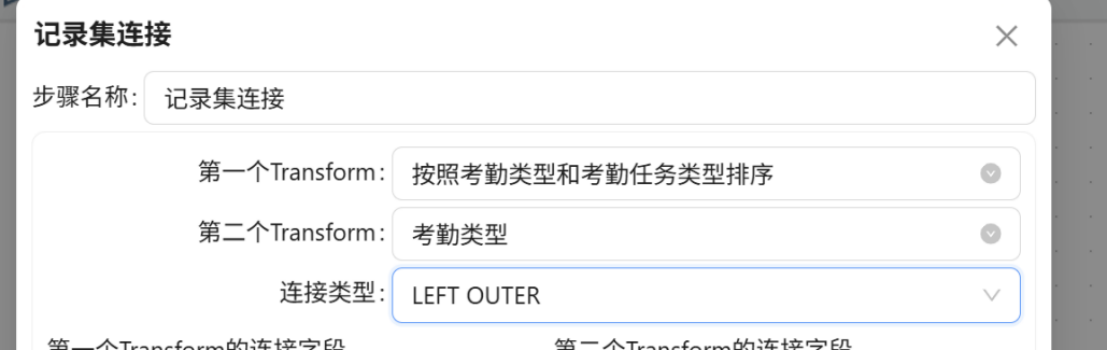
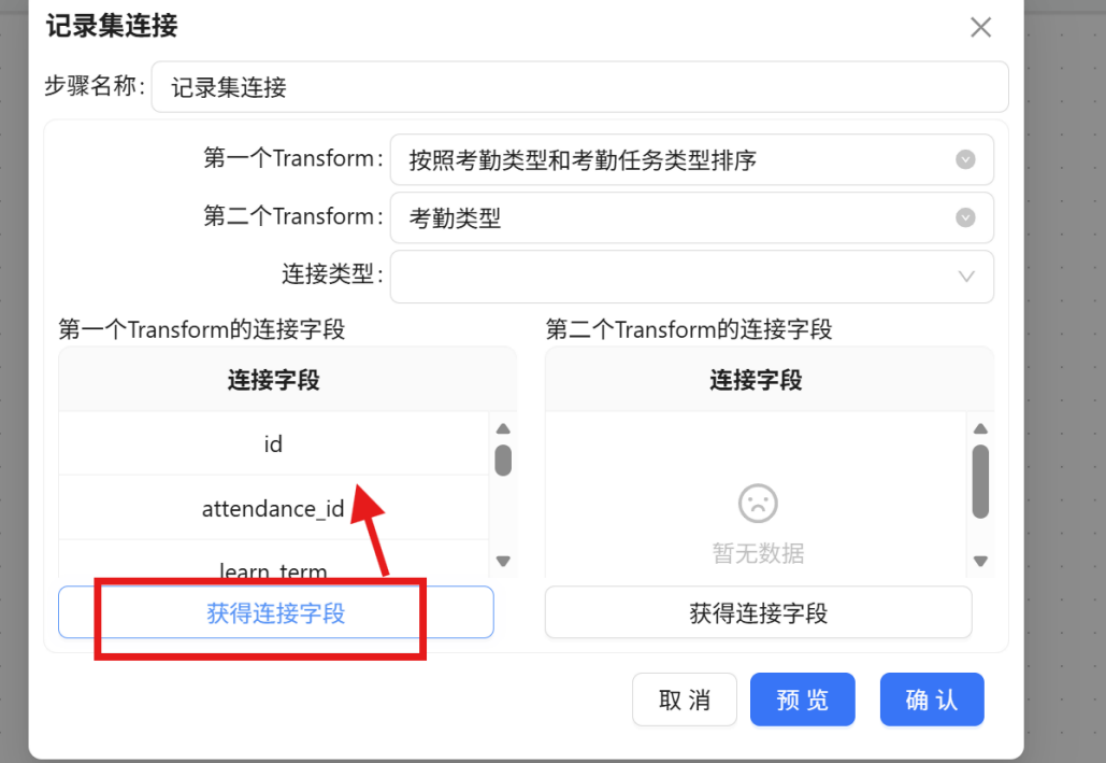
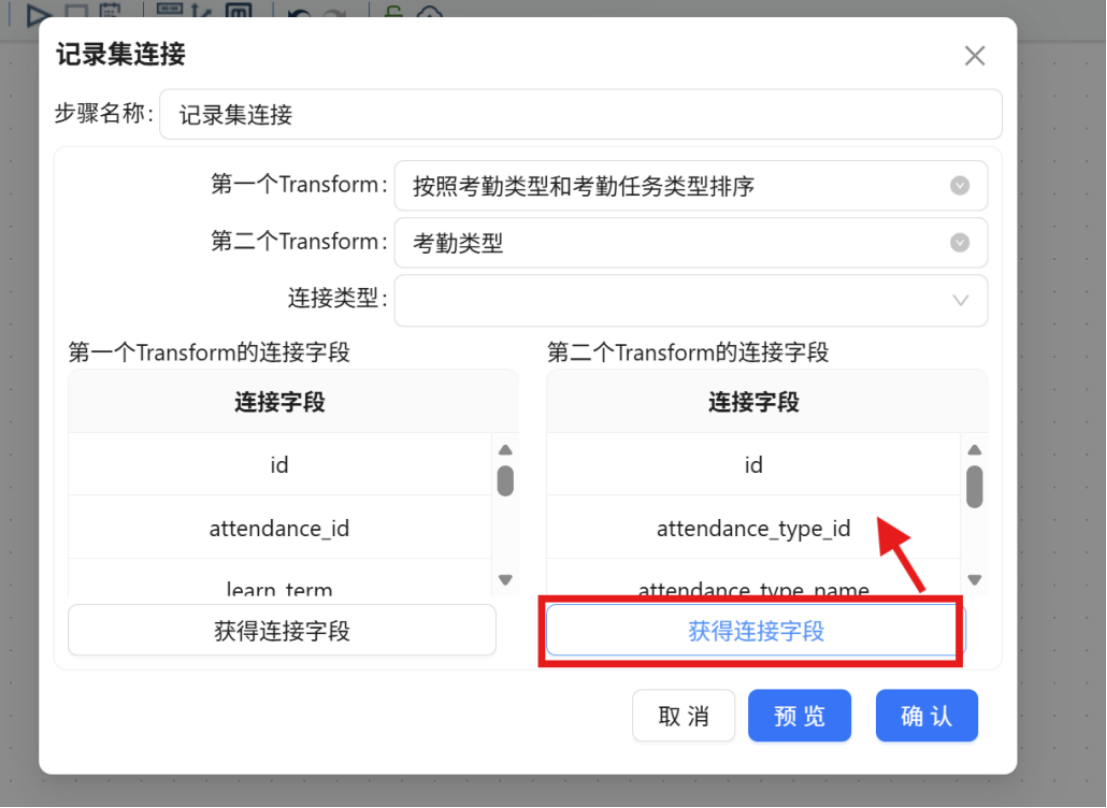
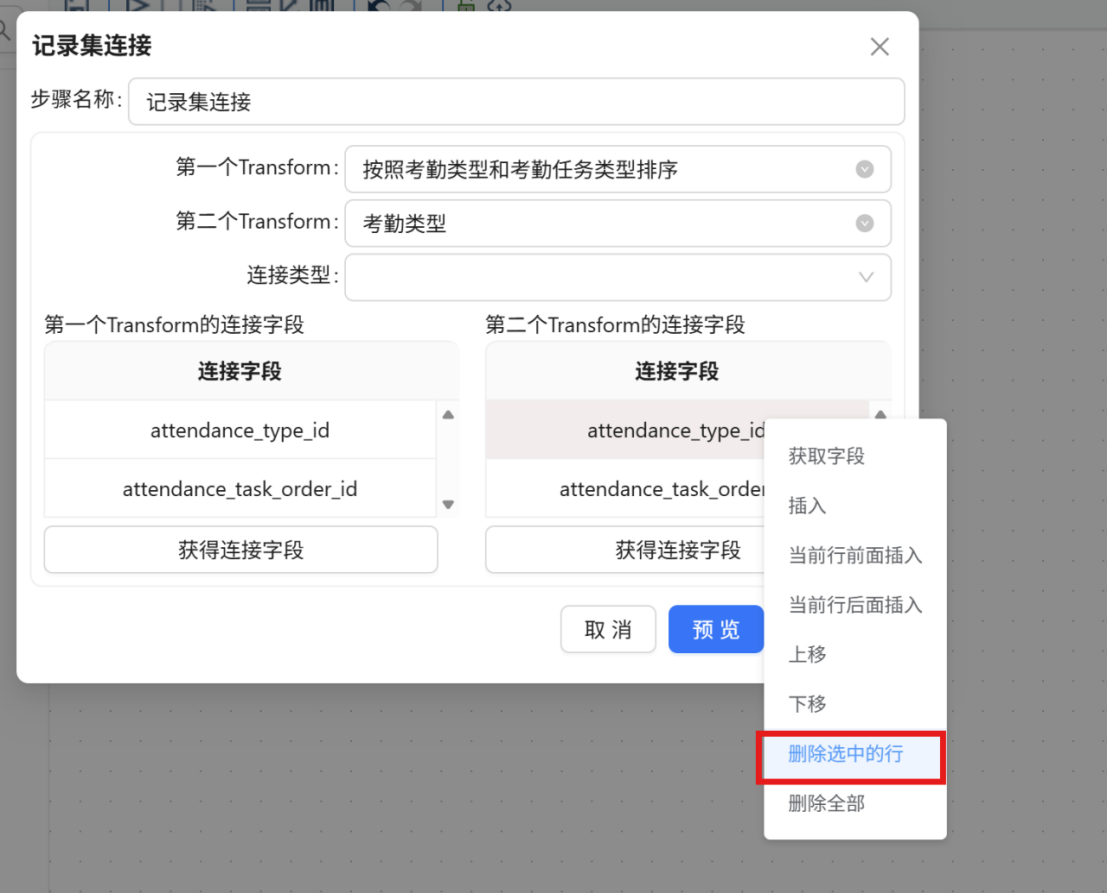
步骤八: 删除关联后产生的冗余字段,仅保留后续计算所需的核心字段。完成删除后点击 "确认"。若误删字段,可重新点击"获取连接字段"进行恢复。
4.3.4 行为标签衍生:统计学生异常考勤次数
完成数据关联后,需要通过 JavaScript 脚本 对每条考勤记录进行行为判断,生成二进制标记字段(1 = 是,0 = 否),为后续的聚合统计提供精准的计算依据。
具体操作步骤如下:
步骤一: 从组件库中添加 "JavaScript 代码" 组件至画布,并将其对接 "记录集连接" 组件的输出端,通过关键词匹配逻辑生成考勤行为的二进制判断标签。
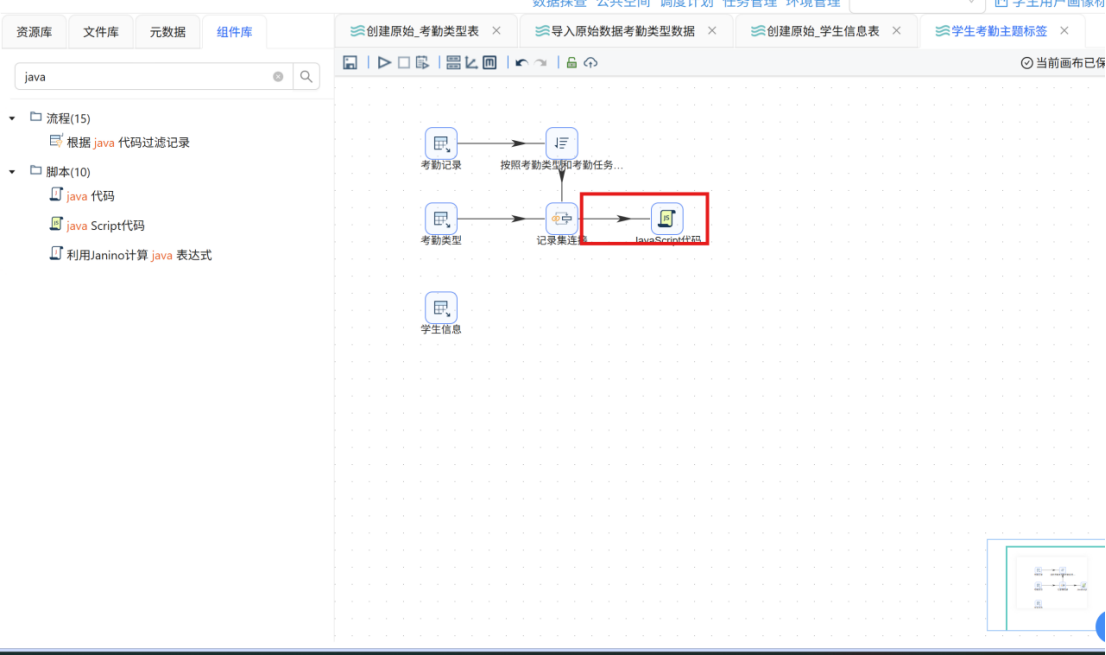
步骤二: 双击 "JavaScript代码" 组件,将步骤名称修改为 "提取异常考勤记录",在 Script1 编辑区域中输入以下 JavaScript 脚本:
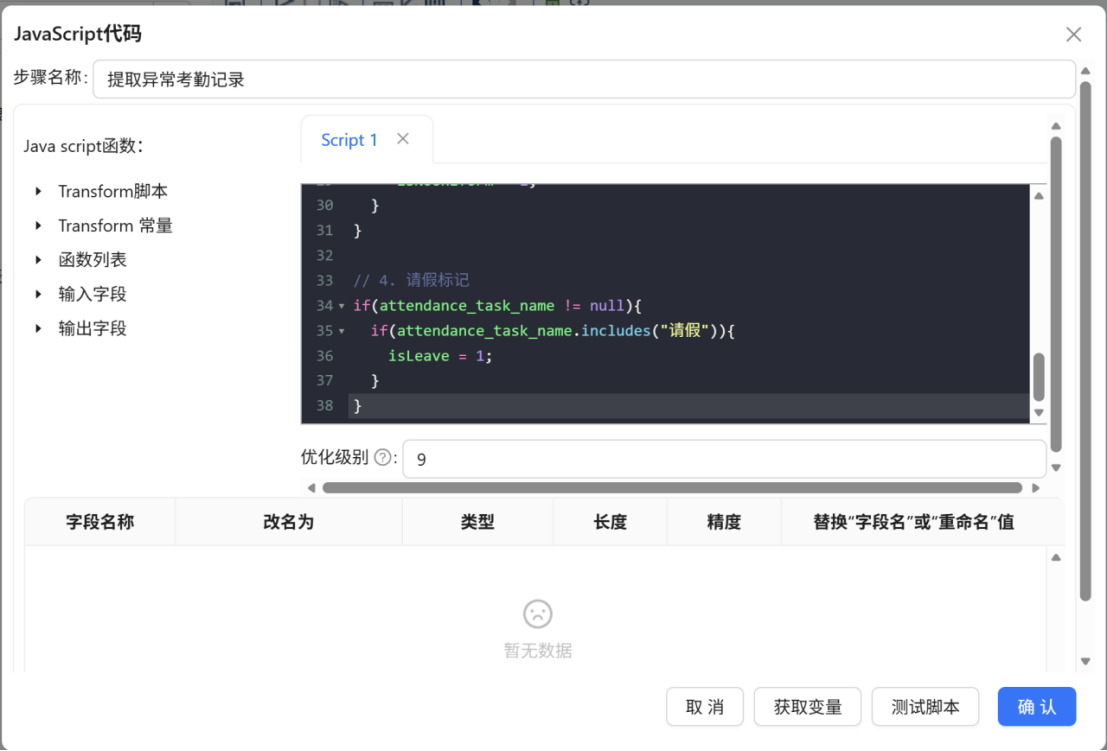
脚本代码如下:
// 初始化变量(迟到、早退分开)
var isLate = 0;
var isEarly = 0;
var isLeave = 0;
var isNoUniform = 0;
// 判断条件
if(attendance_type_name != null && attendance_task_name != null)
{
// 1. 迟到判断(包含迟到、晚到,排除请假)
if((attendance_type_name.includes("迟到") ||
attendance_type_name.includes("晚到") ||
attendance_task_name.includes("迟到") ||
attendance_task_name.includes("晚到")) &&
!attendance_task_name.includes("请假")){
isLate = 1;
}
// 2. 早退判断(排除请假)
if((attendance_type_name.includes("早退") ||
attendance_task_name.includes("早退")) &&
!attendance_task_name.includes("请假")){
isEarly = 1;
}
// 3. 没穿校服标记
if(attendance_type_name.includes("校服") ||
attendance_task_name.includes("校服")){
isNoUniform = 1;
}
}
// 4. 请假标记
if(attendance_task_name != null){
if(attendance_task_name.includes("请假")){
isLeave = 1;
}
}步骤三: 点击 "获取变量" 按钮获取输出字段,系统将自动解析脚本中定义的变量,生成对应的输出字段列表。
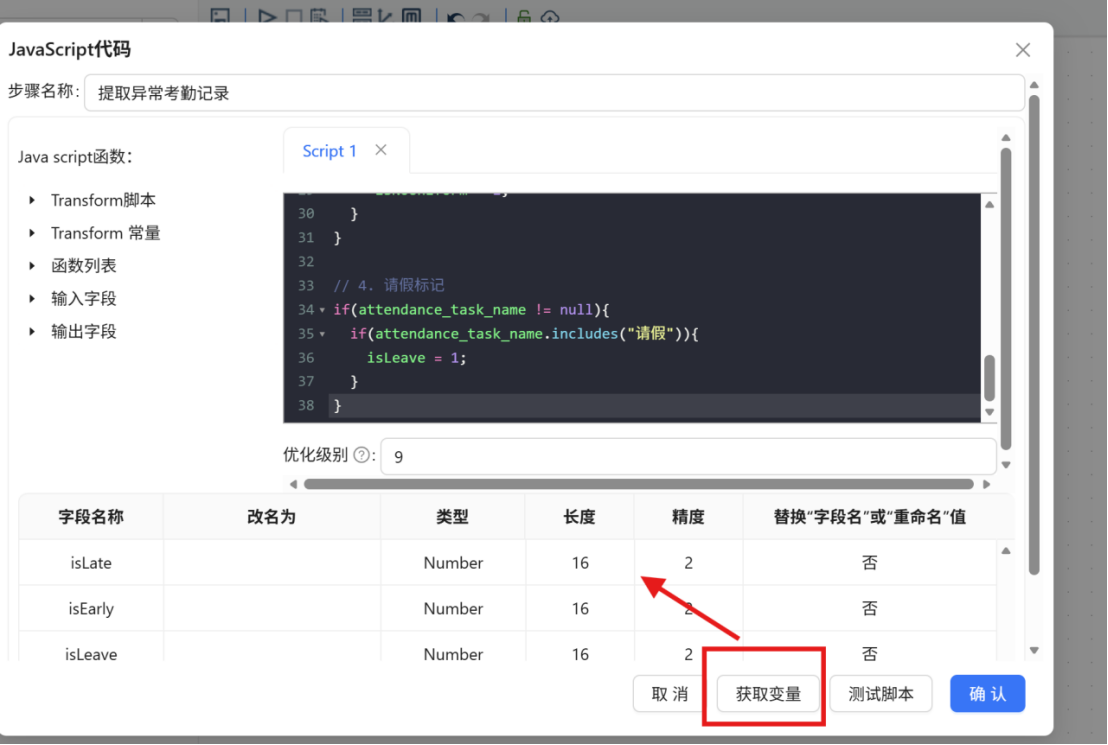
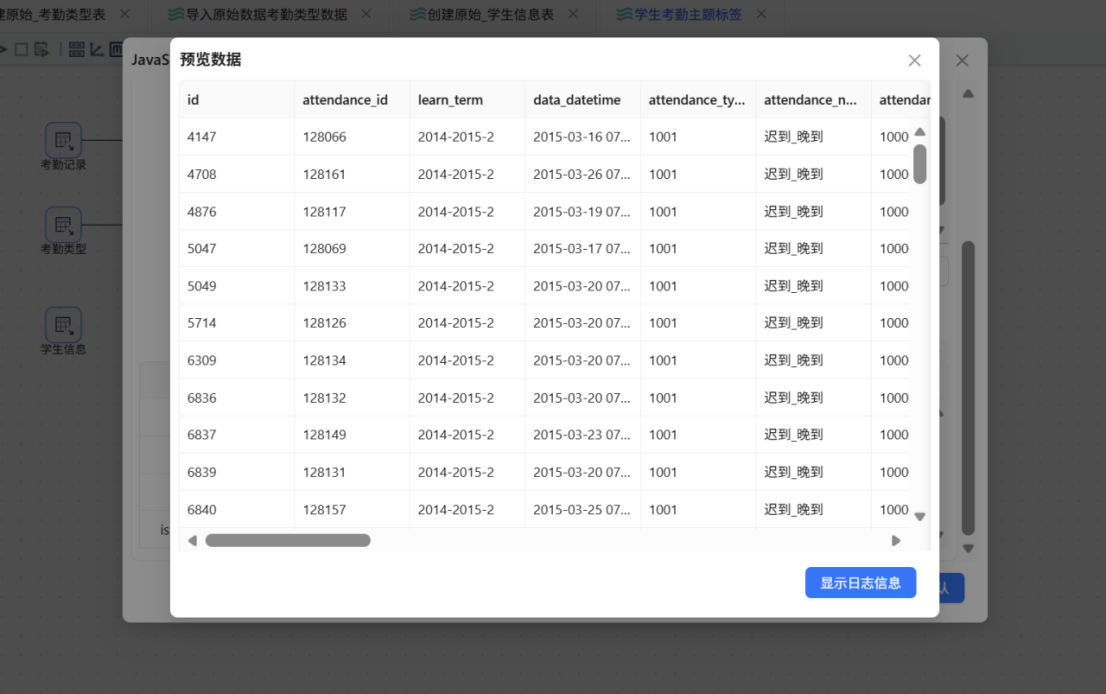
步骤四: 点击组件中的 "测试脚本" 按钮,对标记结果进行验证。确认各标记字段(isLate、isEarly、isLeave、isNoUniform)仅输出 1 和 0 两种值,且标签判断逻辑准确——例如包含"迟到"关键词的记录对应 isLate=1,正常出勤记录则全部标记字段均为 0,无异常情况。
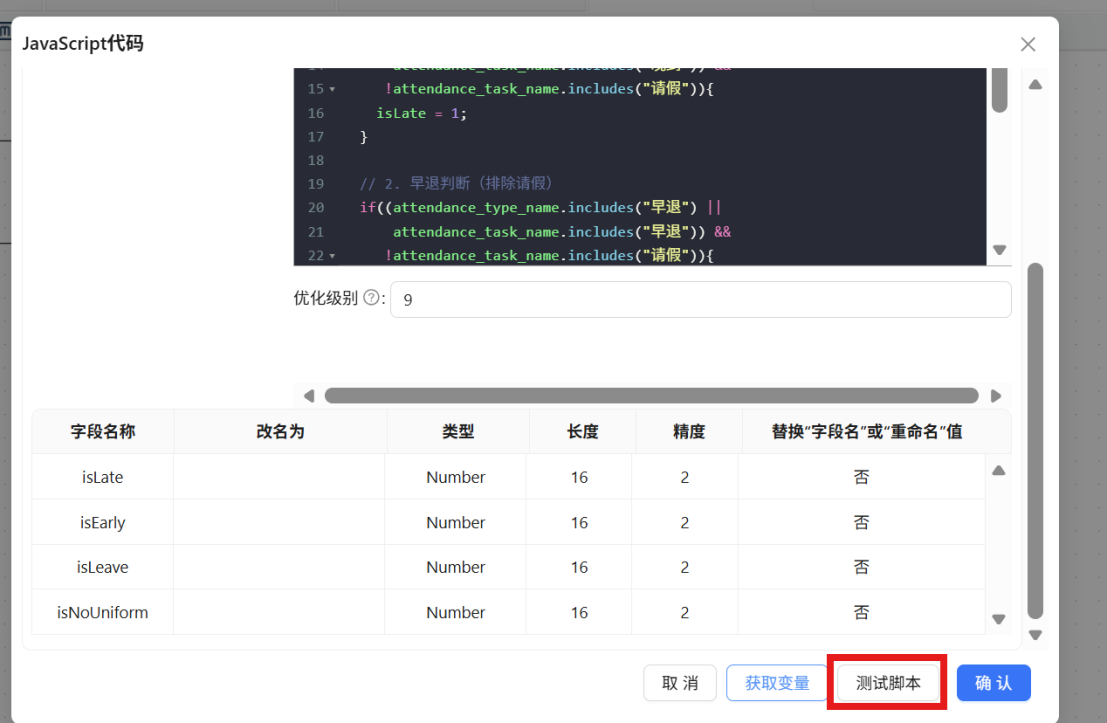
预览数据如下:
4.3.5 多维度分组聚合统计
本环节是整个转换流的核心计算步骤——将逐条的明细数据按照指定维度进行分组聚合,转化为可直接使用的统计指标,满足多层级考勤管理的分析需求。
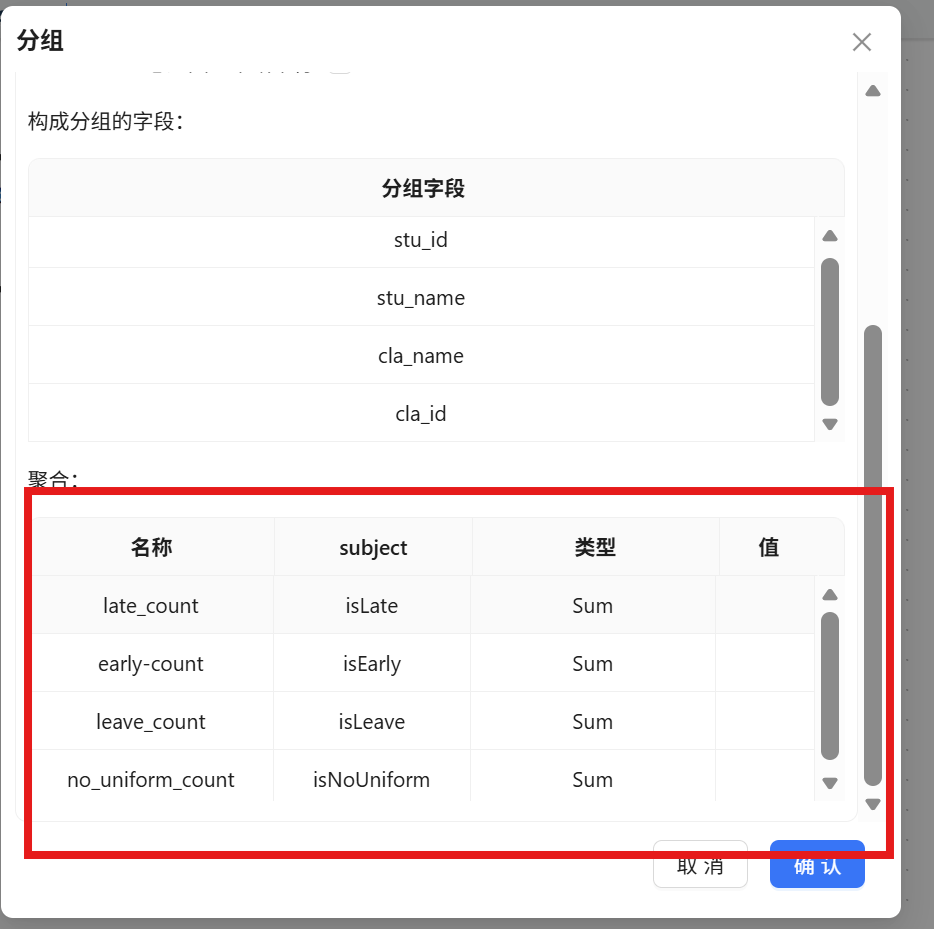
聚合规则如下:
|
聚合函数 |
标记字段 |
输出指标 |
|
SUM(迟到标记) |
isLate |
迟到次数(late_count) |
|
SUM(早退标记) |
isEarly |
早退次数(early_count) |
|
SUM(请假标记) |
isLeave |
请假次数(leave_count) |
|
SUM(没穿校服标记) |
isNoUniform |
没穿校服次数(no_uniform_count) |
具体操作步骤如下:
步骤一: 在组件库中搜索 "分组" 组件,将其拖拽至画布中,并与上一步 "用户自定义Java表达式" 组件建立连接线。创建连线时在弹窗中选择 "主输出步骤"。
步骤二: 双击 "分组" 组件,进入配置界面,设置分组维度字段。根据实际统计需求,选择需要作为分组依据的维度字段(如学生ID、班级ID等)。
步骤三: 在聚合区域配置聚合字段,依次添加 late_early_count、leave_count、no_uniform_count、compliant_count、total_attendance 等聚合指标,并将聚合函数统一设置为 SUM。
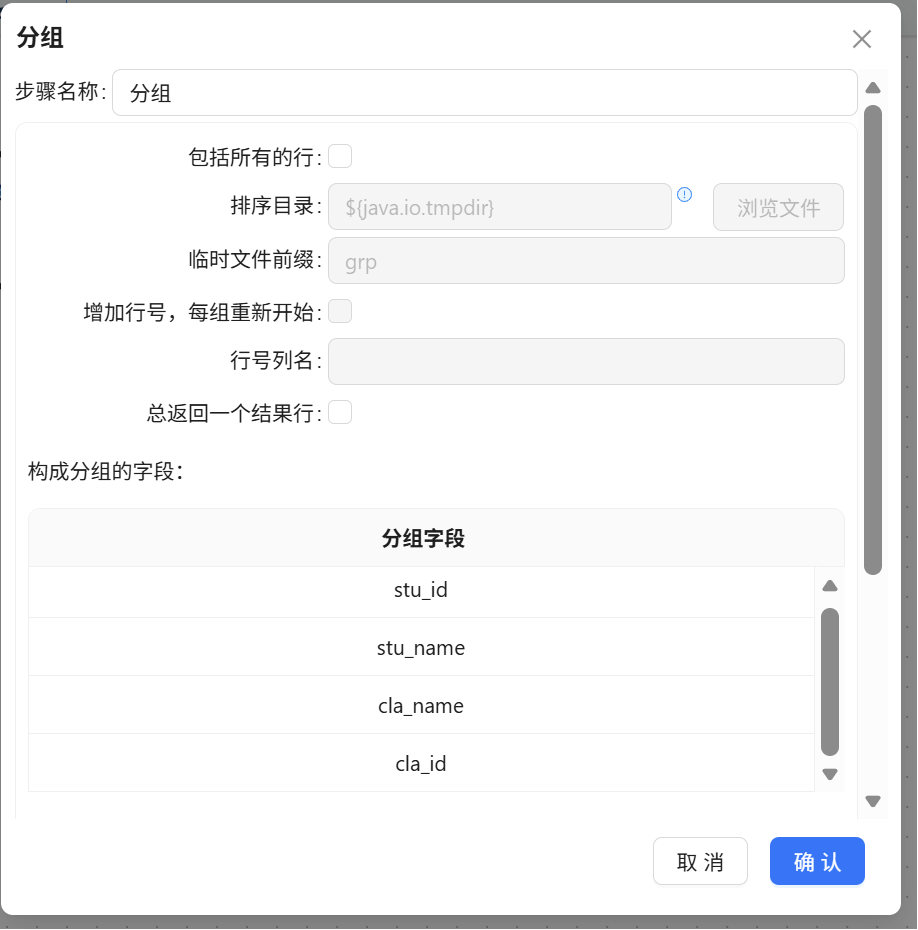
配置完成后点击 "确认" 保存设置。
4.3.6 关联学生信息
在完成考勤行为的分组聚合后,还需要将统计结果与学生信息表进行关联。这是因为考勤记录表中仅包含学生ID和班级ID,缺少学生是否住校等核心属性信息。通过按学生ID关联学生信息表,可以为每条聚合记录补全姓名、性别、住校状态等维度字段,支撑后续住校相关维度的深度统计分析。
具体操作步骤如下:
步骤一: 由于 "学生信息" 数据表中的学号并非按升序排列,因此在进行记录关联之前需要先对数据进行排序。从组件库中添加一个 "排序记录" 组件,并建立从 "学生信息" 表输入组件到该排序组件的连接线。
步骤二: 双击该 "排序记录" 组件,利用 "获取字段" 功能加载字段列表,删除无关字段,仅保留 stu_id 字段。因为后续连接操作正是基于该字段进行匹配,所以需按此字段对记录排序。最后将步骤名称设置为 "按照学生编号进行排序"。
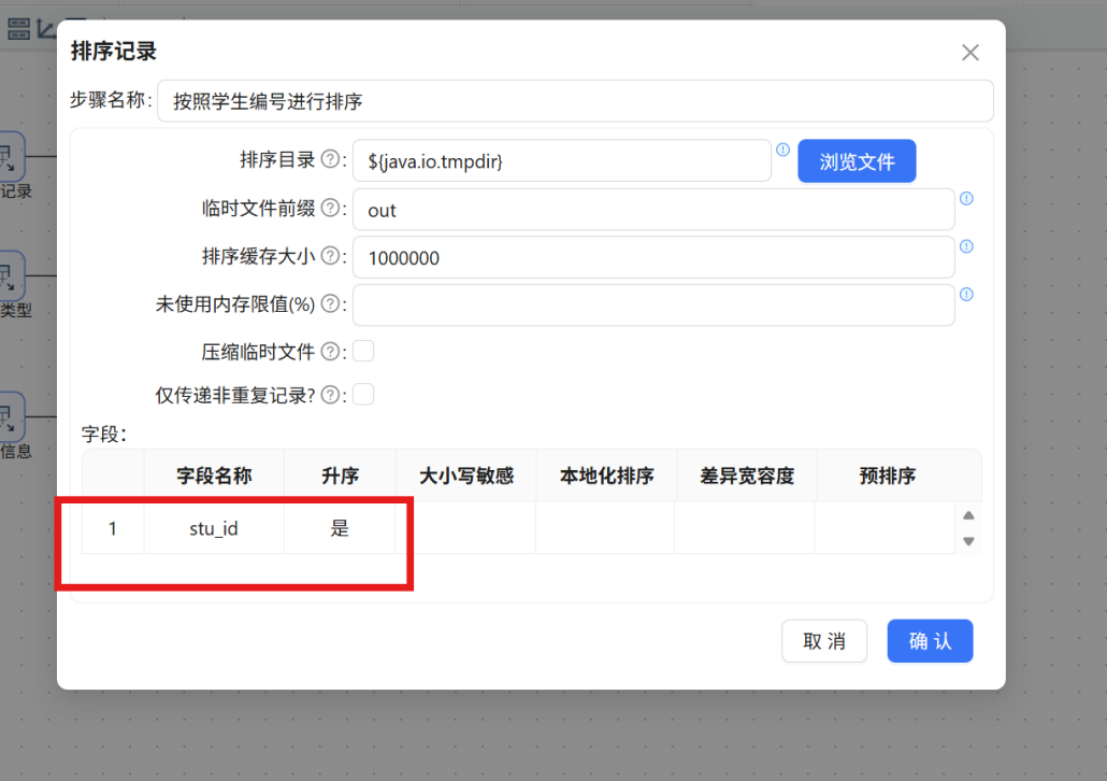
步骤三: 拖拽一个新的 "记录集连接" 组件至画布中,创建从 "按照学生编号进行排序" 排序记录组件到 "记录集连接 1" 组件的连接线。
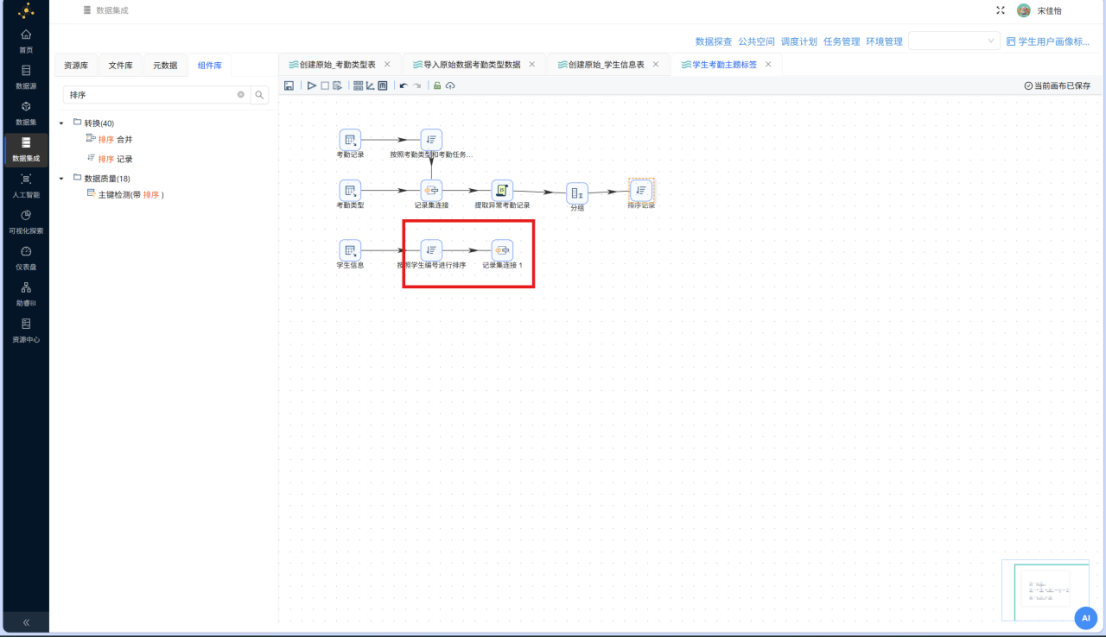
步骤四: 同样地,由于上一步输出的考勤聚合数据也并非按学号升序排列,在关联前同样需要排序处理。再添加一个 "排序记录" 组件,建立从前序 "分组" 组件到该排序组件的连接线。
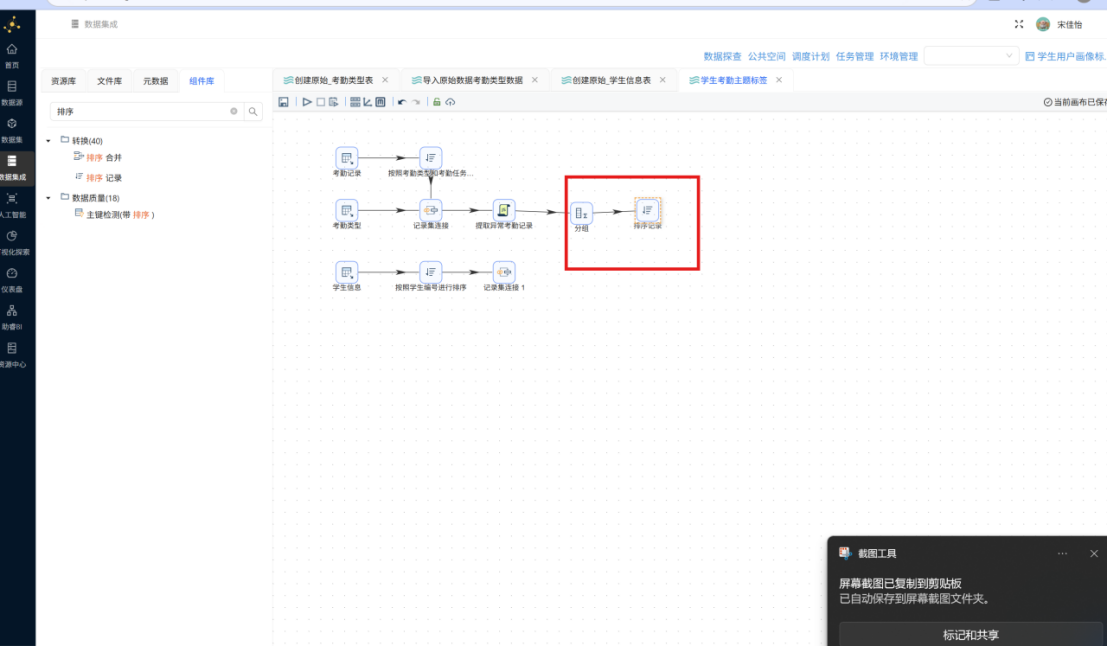
步骤五: 双击该排序组件,按照下图进行配置:将步骤名称设置为 "考勤数据按学号排序",排序字段选择 stu_id。
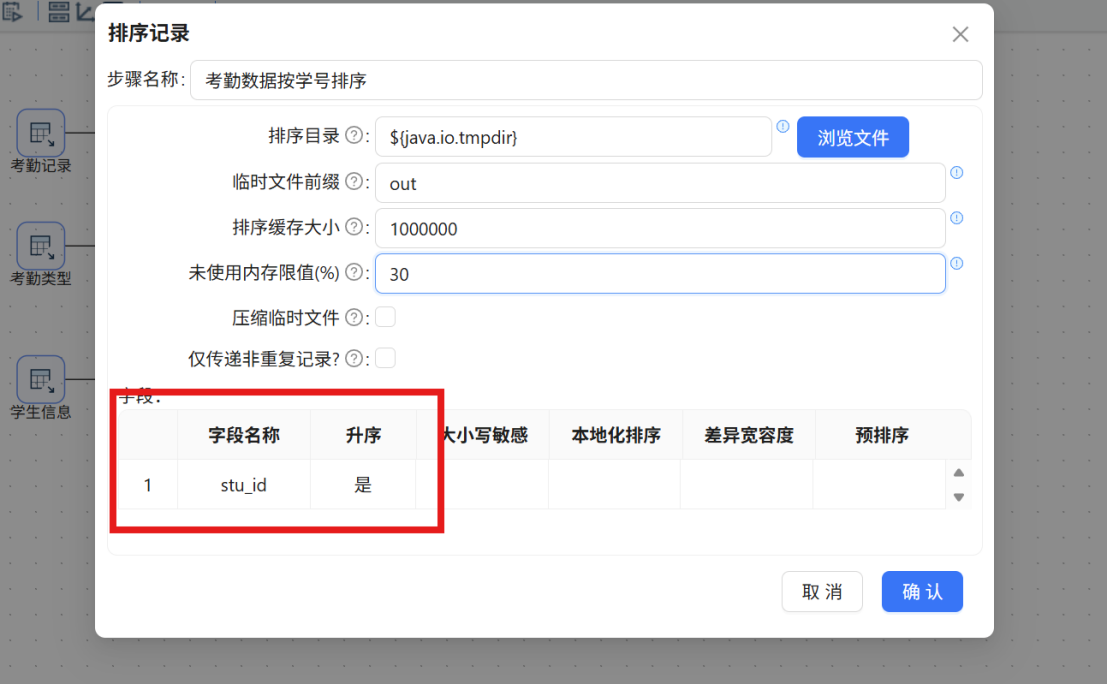
步骤六: 创建从 "考勤数据按学号排序" 排序组件到 "记录集连接 1" 组件的连接线,将学生信息与考勤统计数据汇聚到同一个连接节点。
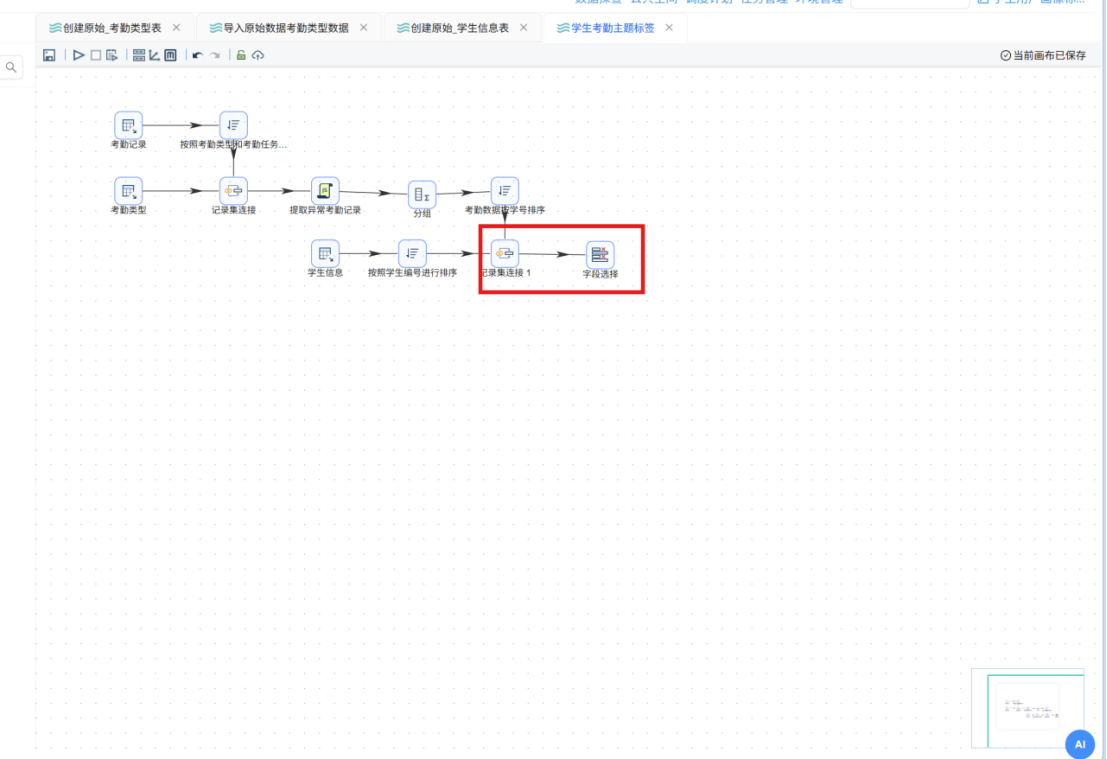
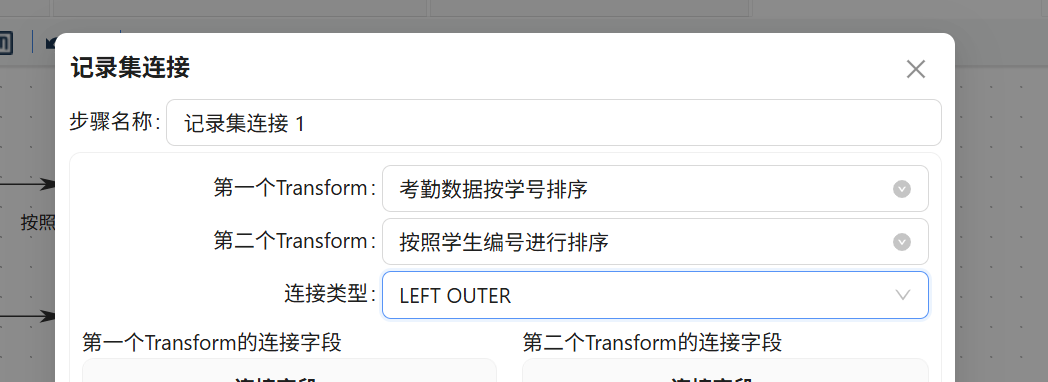
步骤七: 双击 "记录集连接 1" 组件进行关联配置。在下拉列表中分别选择数据来源:第一个 Transform 选择 "考勤数据按学号排序",第二个 Transform 选择 "按照学生编号进行排序",连接类型设置为 LEFT OUTER(左外连接)。
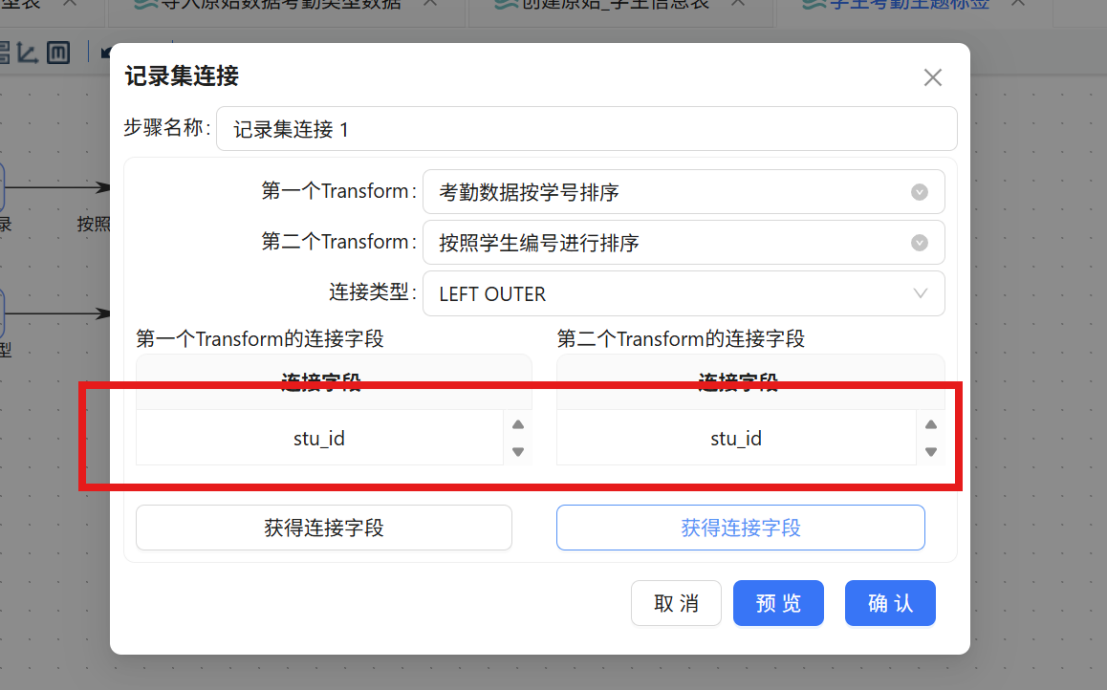
步骤八: 分别点击两个 Transform 连接字段区域中的 "获得连接字段" 按钮,系统将自动加载各自的可用字段。第一个 Transform 的连接字段保留 stu_id,第二个 Transform 的连接字段同样保留 stu_id。这样配置表示使用考勤统计记录中的 stu_id 字段与学生信息表中的 stu_id 字段进行左外连接匹配。
步骤九: 确认关联字段配置无误后,点击 "确认" 保存。若在操作过程中误删了字段,可通过重新点击"获得连接字段"按钮恢复并重新进行配置。
4.3.7 字段选择:移除冗余字段
经过多轮表关联和数据接入,当前数据集中包含了大量与考勤统计无关的冗余字段(如学生信息表中的非必要属性)。这些多余字段不仅会增加数据处理的资源开销,还可能对后续的聚合计算产生干扰。因此,需要及时清理冗余字段,仅保留核心有用字段,以提升处理效率并确保统计逻辑清晰可控。
具体操作步骤如下:
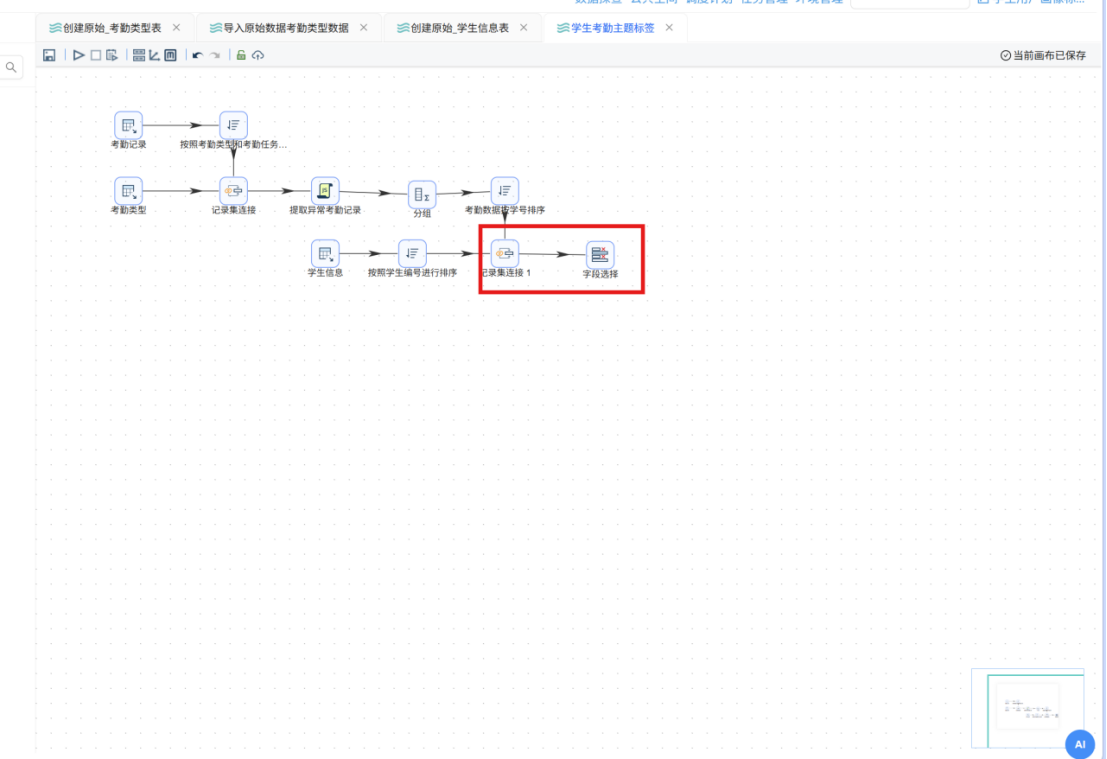
步骤一: 在组件库中搜索 "字段选择",将其拖拽至画布中,并创建从 "记录集连接 1" 组件到 "字段选择" 组件的连接线。
步骤二: 双击 "字段选择" 组件打开配置弹窗,在步骤名称栏中输入 "移除冗余字段"。随后切换至 "移除" Tab 标签页,在空白区域点击鼠标右键,选择 "获取字段",系统将自动加载当前所有可用字段列表。根据实际需求,保留考勤统计所需的核心字段,将其余无关字段标记为移除。
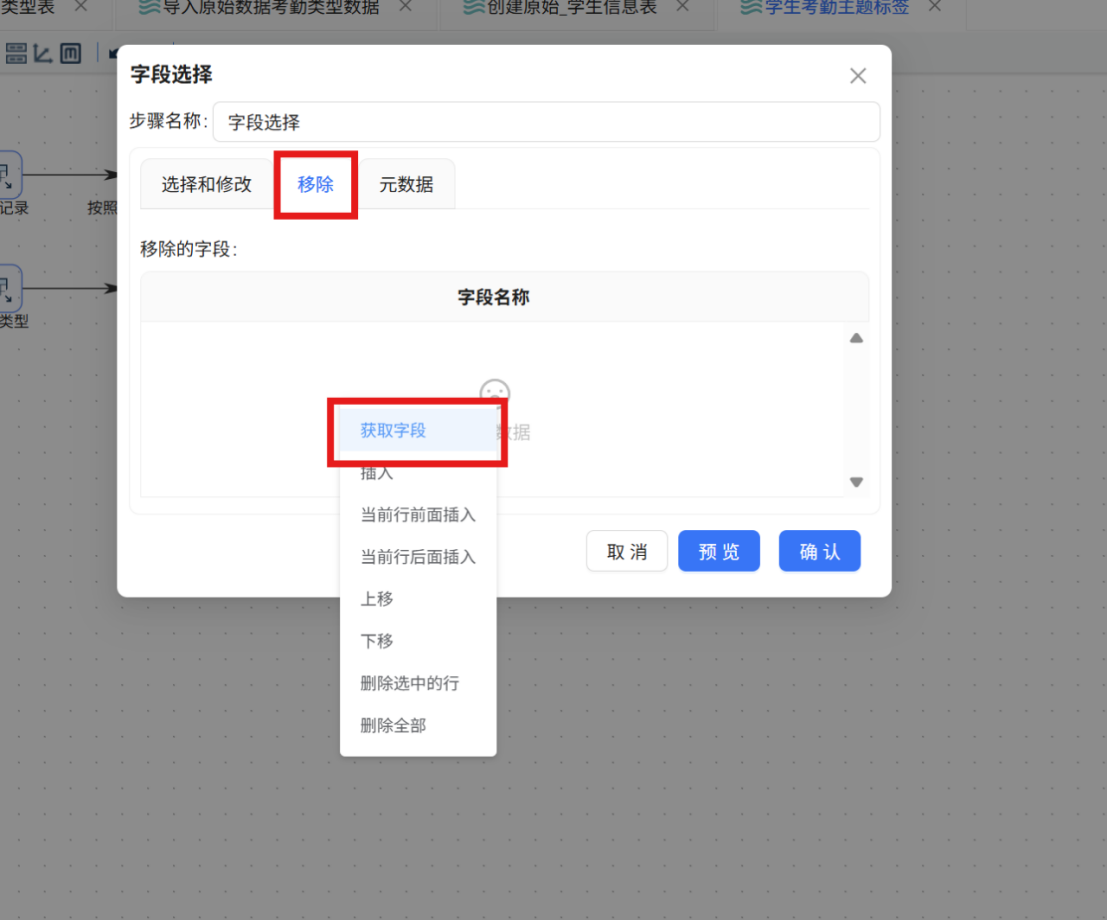
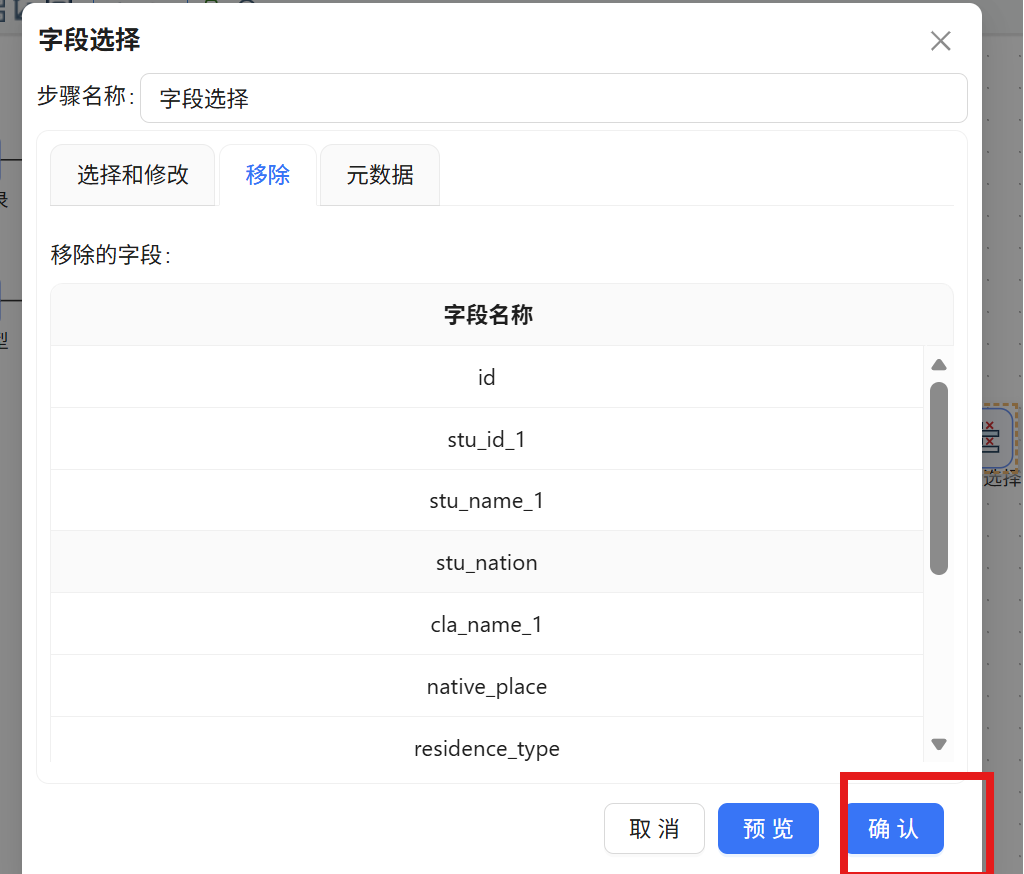
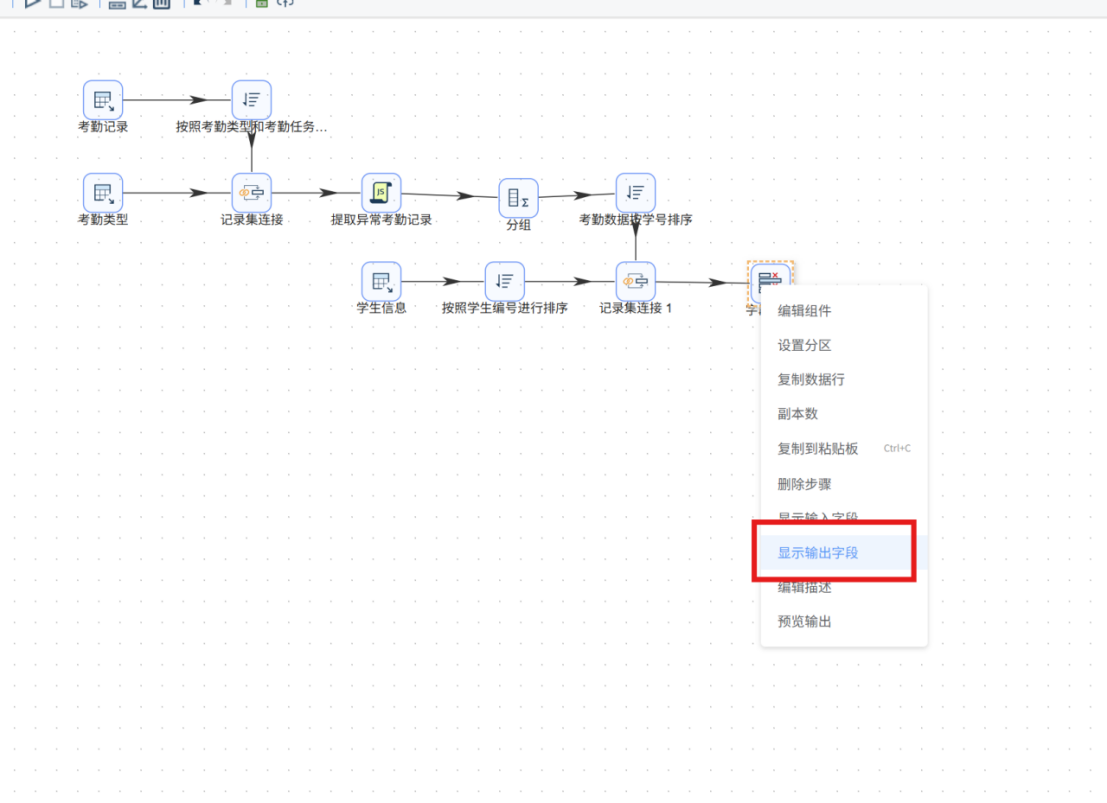
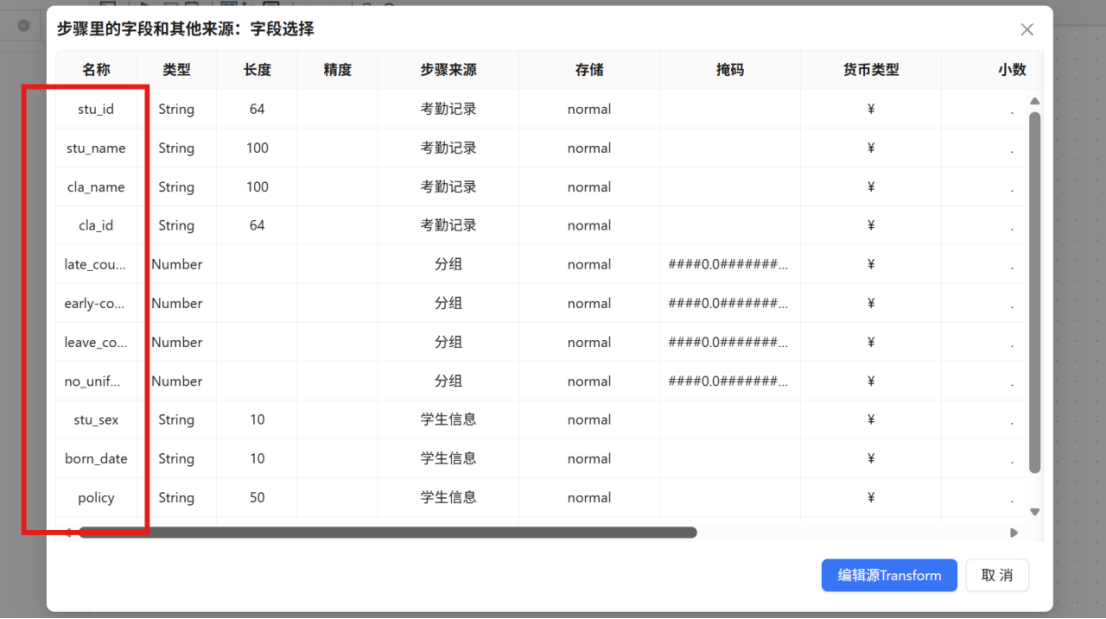
步骤三: 配置完成后,在 "字段选择" 组件上点击鼠标右键,在弹出菜单中选择 "显示输出字段",核查经过筛选后的输出字段是否符合预期,确认无误后完成配置。
4.3.8 空值处理
三张数据表完成关联后,部分记录在 stu_sex(性别)、born_date(出生日期)、policy(政治面貌)、live_on_campus(是否住校)等字段中存在空值。若不对这些空值进行处理,将影响后续的值映射、维度统计等环节的准确性。因此需要使用 "替换NULL值" 组件,将上述字段中的空值统一替换为 "未知"。
具体操作步骤如下:
步骤一: 从组件库中拖拽 "替换NULL值" 组件至画布,创建从 "移除冗余字段" 字段选择组件到 "替换NULL值" 组件的连接线,连线类型选择 "主输出步骤"。
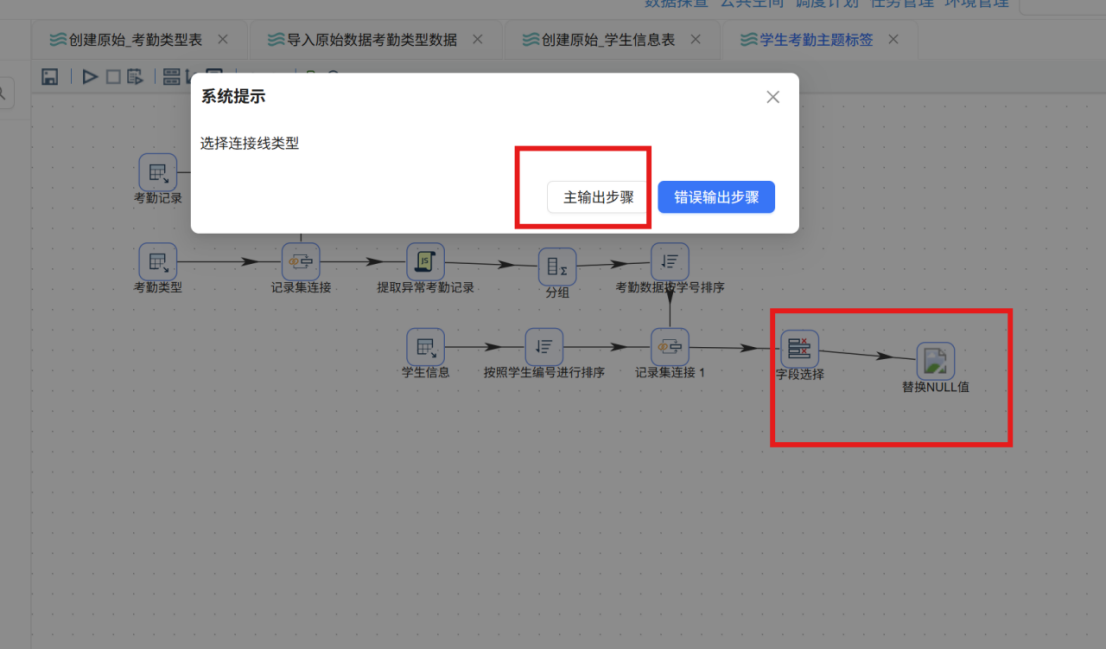
步骤二: 双击 "替换NULL值" 组件,在配置窗口中勾选 "选择字段" 选项,表示仅对指定字段进行空值替换,而非全部字段。
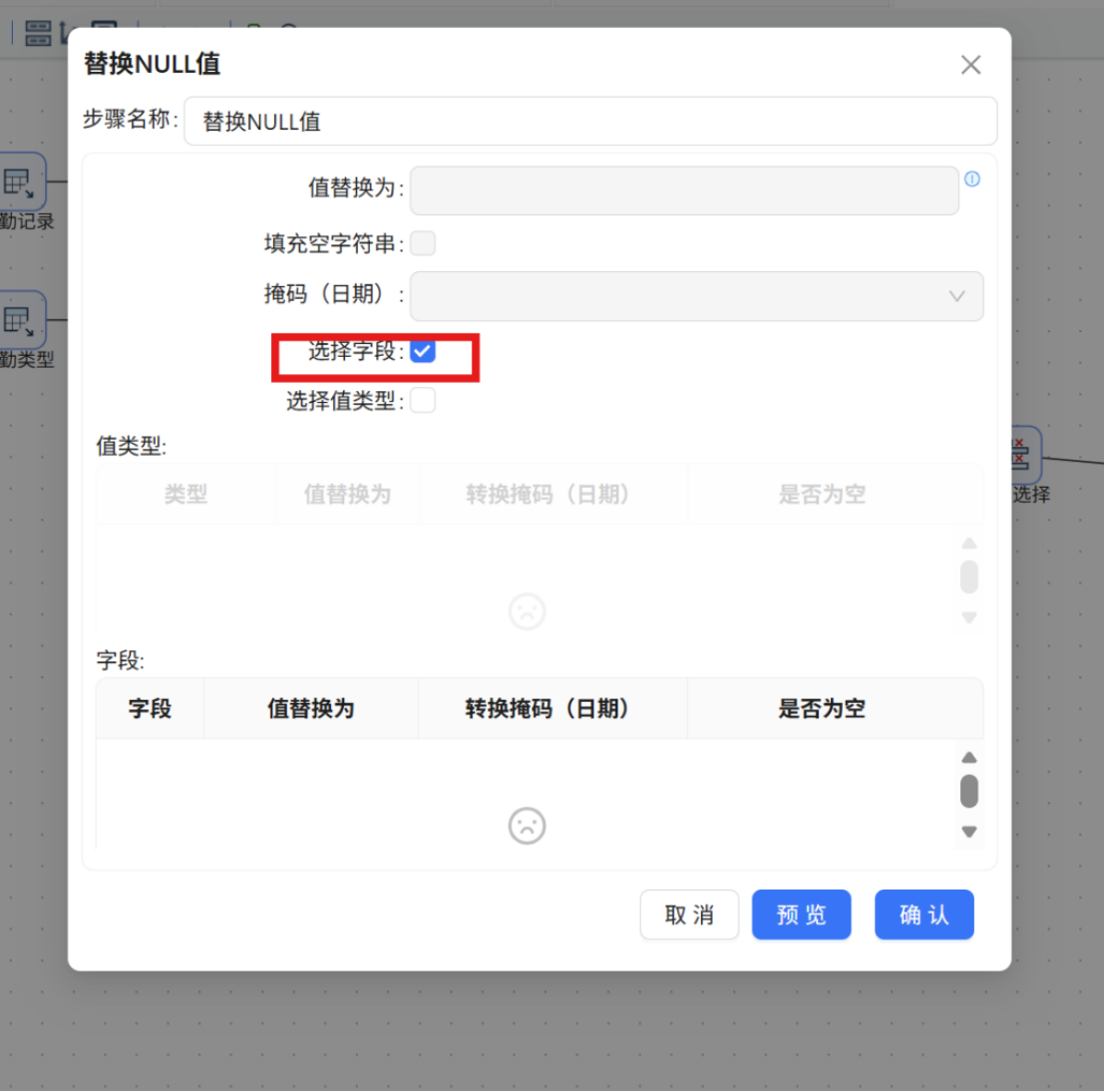
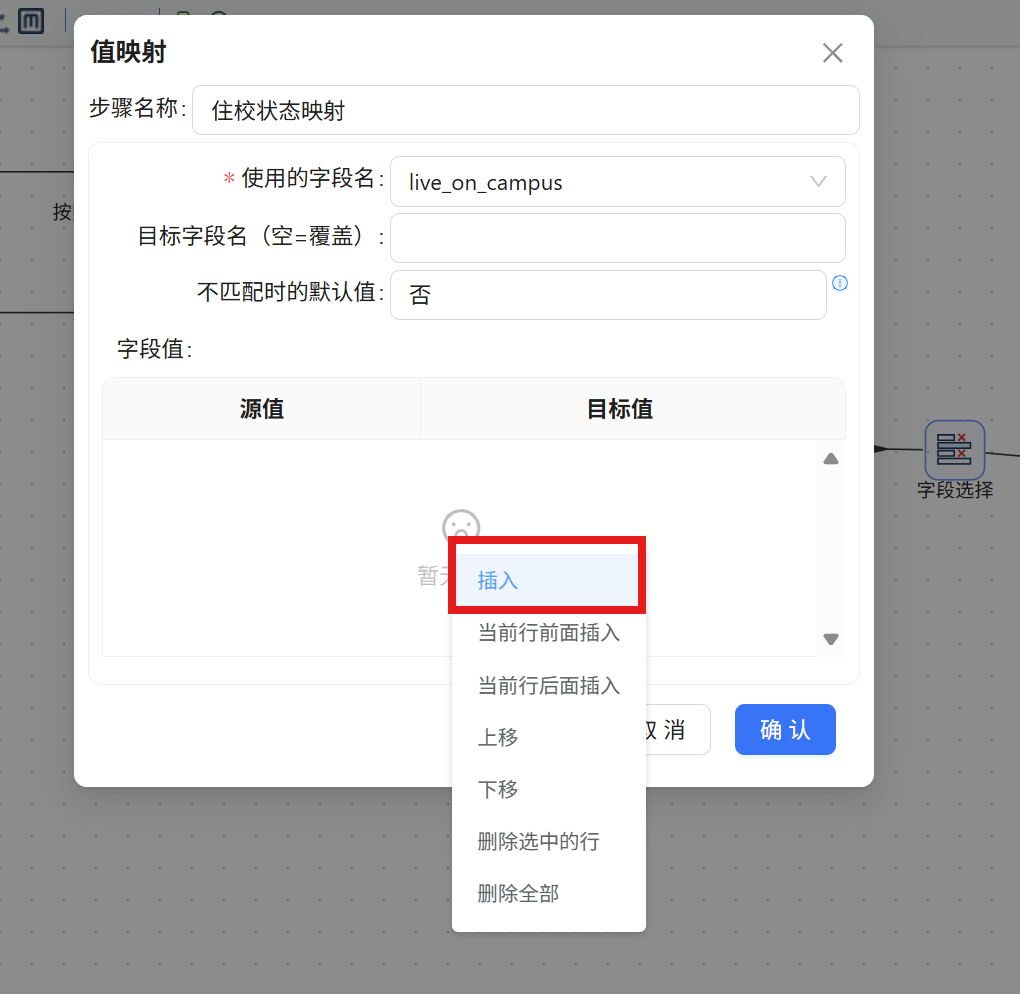
步骤三: 在下方的字段配置表格空白区域点击鼠标右键,选择 "插入" 添加一行新记录。
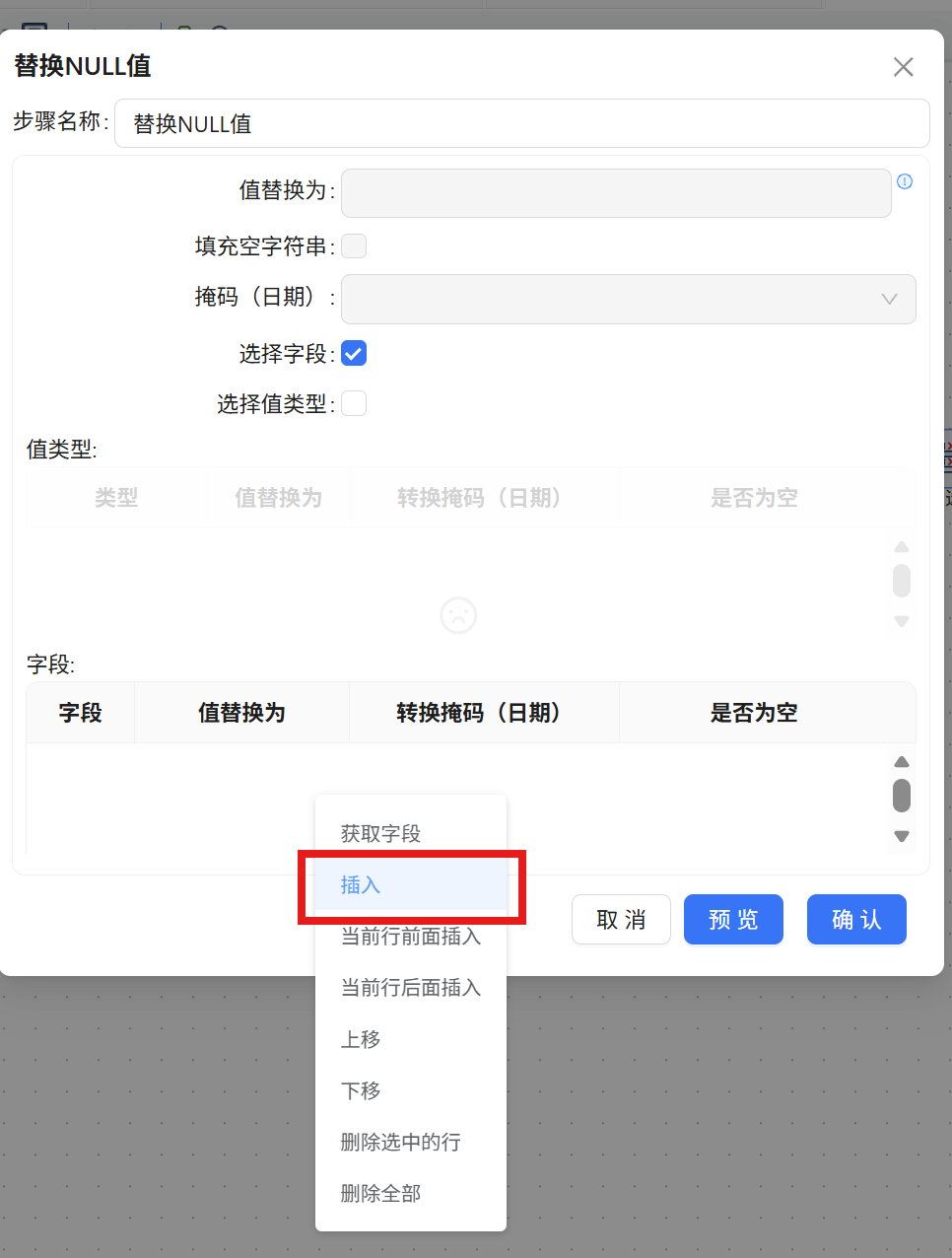
步骤四: 双击新插入的行,在字段名称下拉列表中选择 "stu_sex",替换值填写 "未知"。
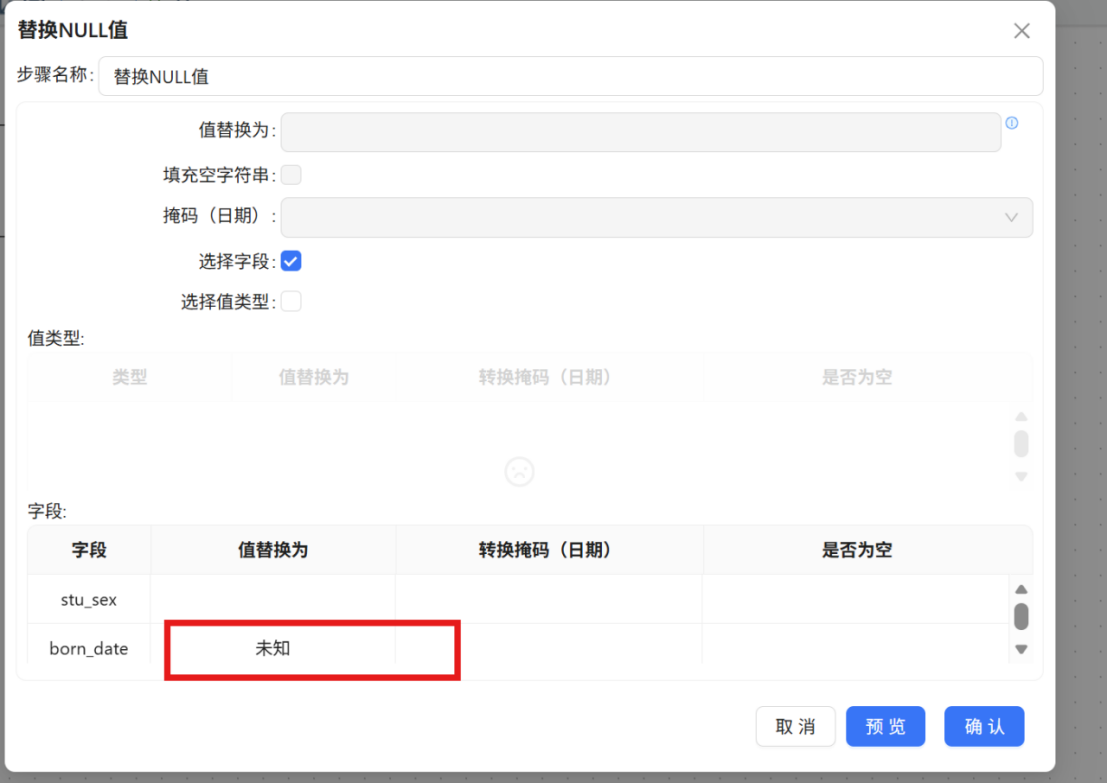
步骤五: 按照相同方法继续插入新行,依次将 born_date、policy、live_on_campus 三个字段的空值替换规则配置完成,替换值均设置为 "未知"。最终配置如下:
|
字段名称 |
替换值 |
|
stu_sex |
未知 |
|
born_date |
未知 |
|
policy |
未知 |
|
live_on_campus |
未知 |
配置完成后点击 "确认" 保存设置。
4.3.9 学生基础属性标准化处理
经过多表关联与字段筛选后,原始数据中仍存在以下问题:住校状态以编码值存储,可读性差;数据集中缺少年级、校区类型等画像分析所必需的维度字段,无法直接用于学生考勤标签的输出与后续用户画像分析。因此,需要对学生基础属性进行 标准化映射 与 缺失字段衍生,统一数据格式、补齐分析维度,确保最终标签表规范可用。
4.3.9.1 住校状态映射
原始住校状态字段以数字编码(0/1)形式存储,可读性差且存在空值情况。通过值映射组件将编码转换为规范的文本描述,同时对未匹配项设置默认值,使标签表更加直观易读,并满足住校与走读学生考勤对比分析的需求。
具体操作步骤如下:
步骤一: 从组件库中添加 "值映射" 组件至画布,并创建从 "替换NULL值" 组件到 "值映射" 组件的连接线,连线类型选择 "主输出步骤"。
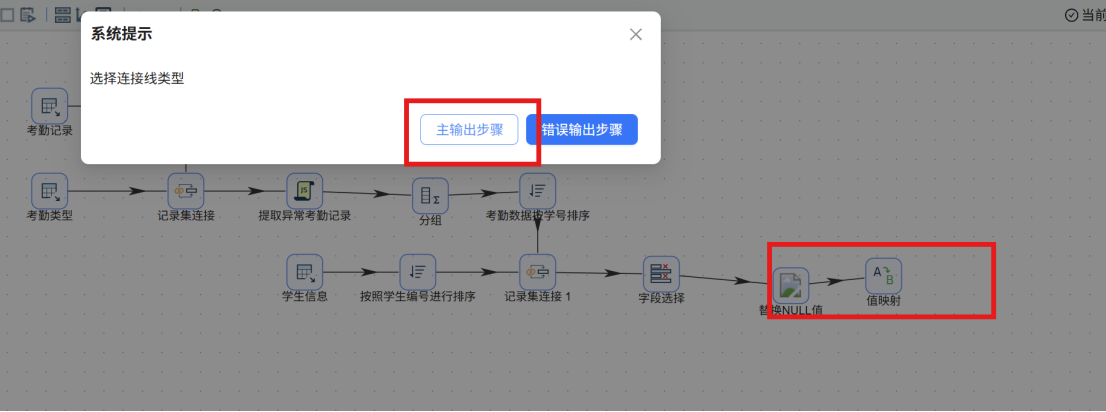
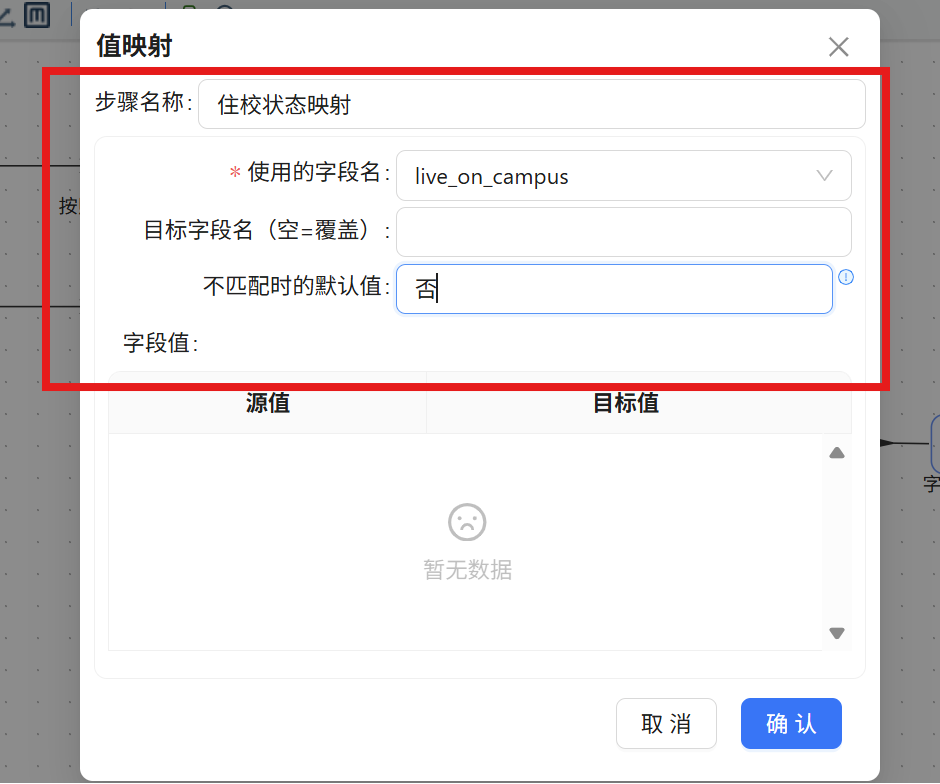
步骤二: 双击 "值映射" 组件,将步骤名称修改为 "住校状态映射"。在配置窗口中进行如下设置:
- 使用的字段名: live_on_campus
- 不匹配时的默认值: 否
步骤三: 在映射规则表格中插入第一行,源值输入 "0",目标值输入 "否"。
步骤四: 继续插入第二行,源值输入 "1",目标值输入 "是"。配置完成后点击 "确认" 保存。
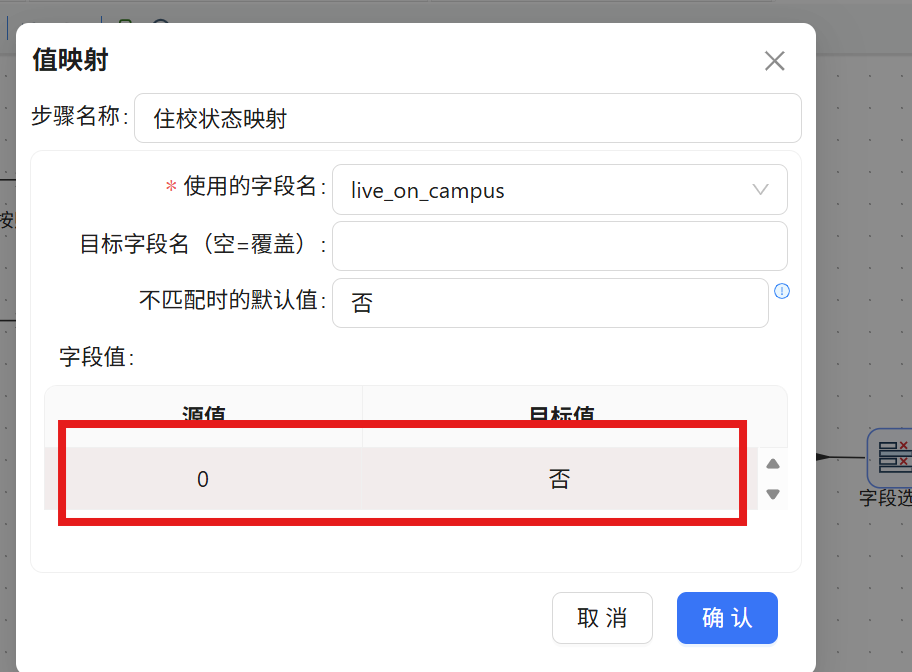
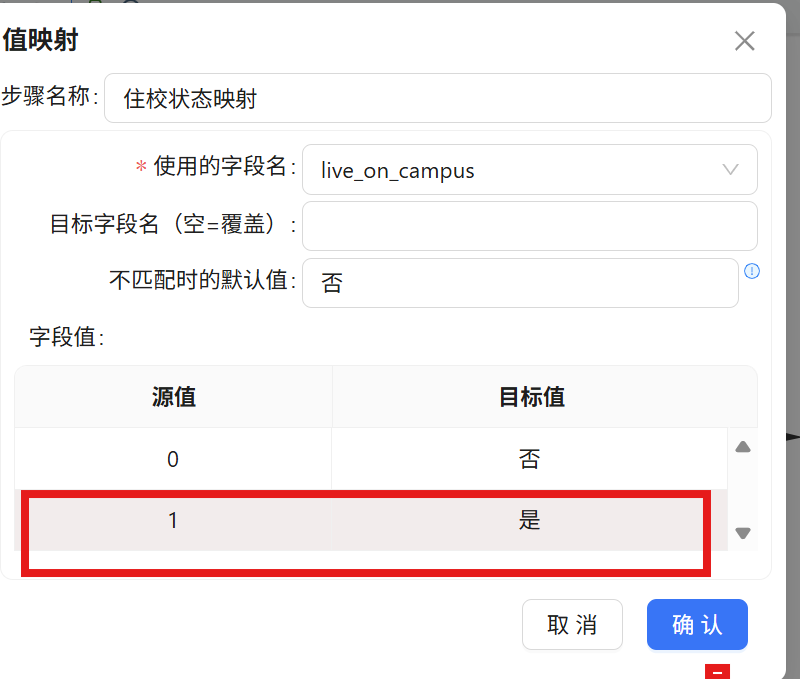
最终映射规则汇总如下:
|
源值 |
目标值 |
说明 |
|
0 |
否 |
走读生 |
|
1 |
是 |
住校生 |
|
其他/空值 |
否 |
默认值兜底 |
4.3.9.2 从班级名提取年级
原始数据中没有独立的年级字段,无法按年级维度进行考勤统计与画像分群。通过 JavaScript 脚本从班级名称中提取年级关键词,自动衍生出年级字段,补齐这一关键分析维度,支撑年级层面的考勤对比分析。
具体操作步骤如下:
步骤一: 从组件库中拖拽 "JavaScript代码" 组件至画布,创建从 "住校状态映射" 值映射组件到该 JavaScript 组件的连接线。
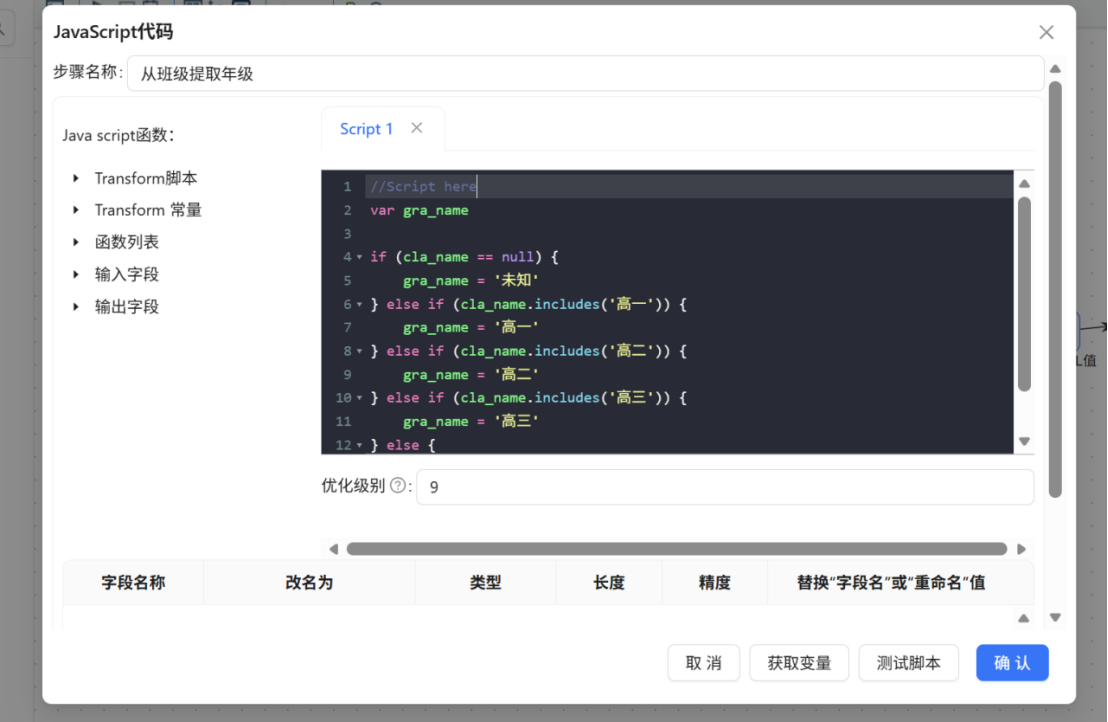
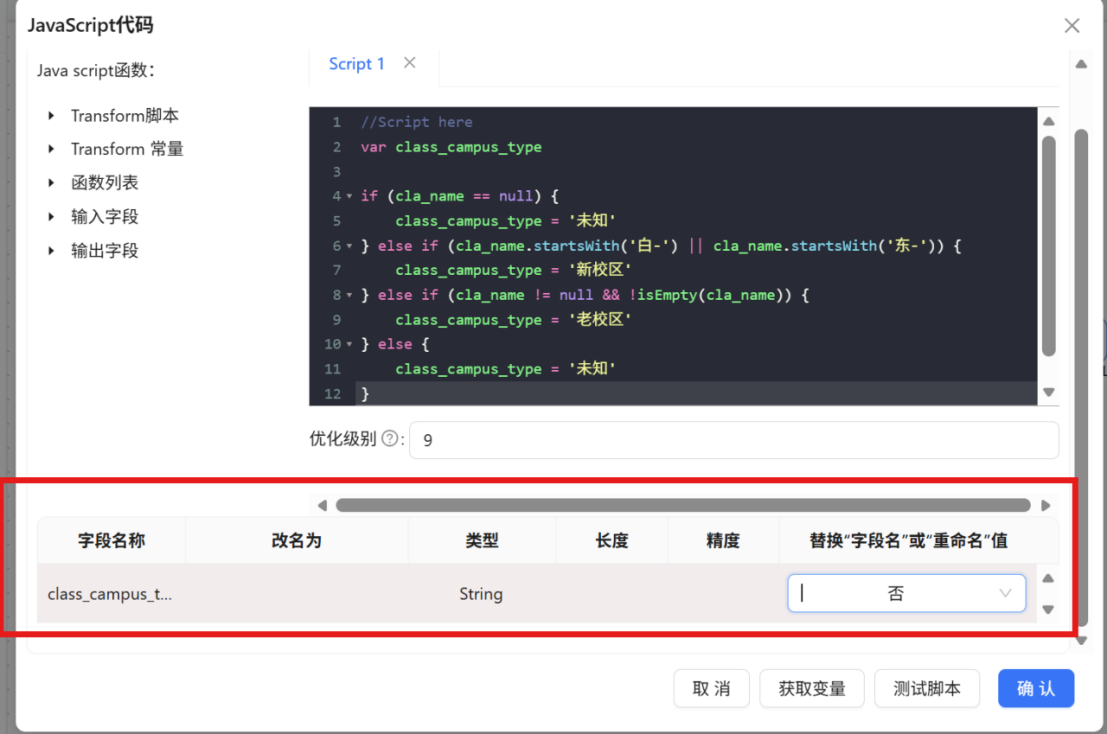
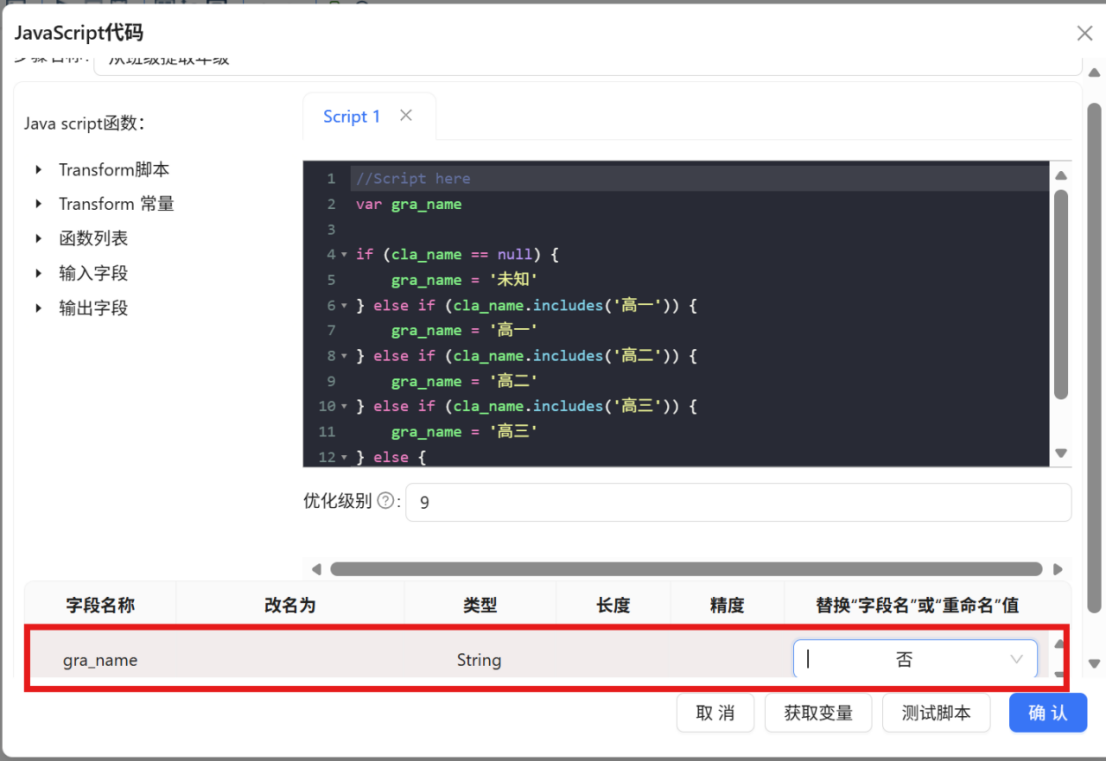
步骤二: 双击 "JavaScript代码" 组件,将步骤名称修改为 "从班级提取年级",在 Script1 编辑区域中输入以下脚本代码:
var gra_name;
if (cla_name == null) {
gra_name = '未知';
} else if (cla_name.contains("高一") || cla_name.contains("高1")) {
gra_name = '高一';
} else if (cla_name.contains("高二") || cla_name.contains("高2")) {
gra_name = '高二';
} else if (cla_name.contains("高三") || cla_name.contains("高3")) {
gra_name = '高三';
} else {
gra_name = '未知';
}
步骤三: 在配置窗口下方的输出字段表格空白处点击鼠标右键,选择 "插入" 添加一行新字段定义。
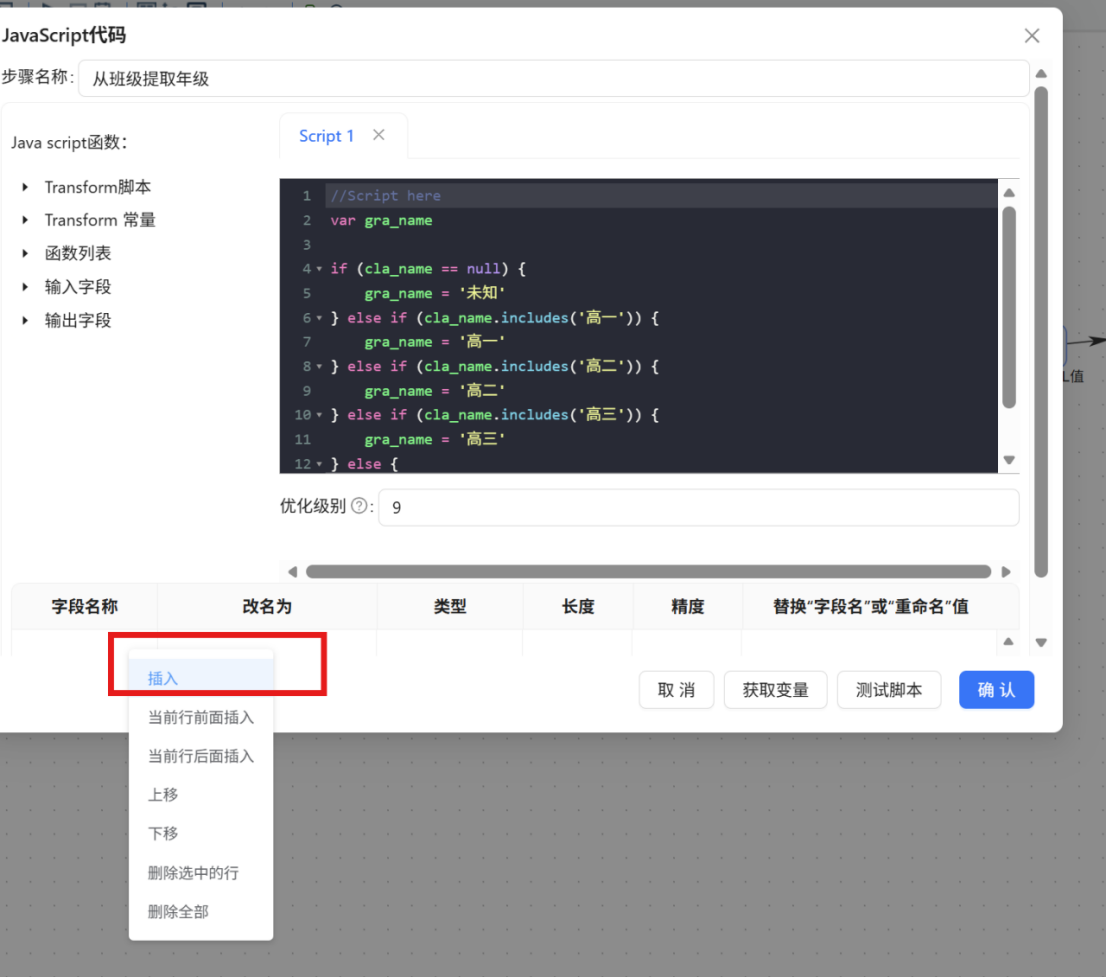
步骤四: 在新插入行中进行如下配置,完成后点击 "确认" 保存:
|
配置项 |
值 |
|
字段名称 |
gra_name |
|
类型 |
String |
|
替换"字段名"或"重命名"值 |
否 |
4.3.9.3 校区类型判定
原始数据中同样缺少校区类型字段,而不同校区在管理口径与考勤规则上往往存在差异。通过 JavaScript 脚本根据班级名称的前缀规则自动判定老校区或新校区归属,增加校区分析维度,使考勤标签更贴合校园实际管理场景。
具体操作步骤如下:
步骤一: 参照 "4.3.9.2 从班级名提取年级" 的操作步骤,从组件库中添加 "JavaScript代码" 组件至画布,并与上一步组件建立连接线。
步骤二: 双击该组件,将步骤名称修改为 "校区类型判定",在 Script1 编辑区域中输入以下脚本代码:
var class_campus_type;
if (cla_name == null) {
class_campus_type = '未知';
} else if (cla_name.startsWith('白-') || cla_name.startsWith('东-')) {
class_campus_type = '新校区';
} else if (cla_name != null && !isEmpty(cla_name)) {
class_campus_type = '老校区';
} else {
class_campus_type = '未知';
}判定逻辑说明:
|
条件 |
判定结果 |
说明 |
|
班级名称为空 |
未知 |
数据缺失兜底 |
|
班级名称以"白-"或"东-"开头 |
新校区 |
白云校区/东校区命名规则 |
|
班级名称非空且不匹配上述规则 |
老校区 |
其余均归入老校区 |
|
其他情况 |
未知 |
兜底处理 |
步骤三: 在输出字段表格中插入一行,进行如下配置,完成后点击 "确认" 保存:
|
配置项 |
值 |
|
字段名称 |
class_campus_type |
|
类型 |
String |
|
替换"字段名"或"重命名"值 |
否 |
4.3.10 结果入库
本环节是整个转换流的最终落地步骤——将经过清洗、关联、标记、聚合与标准化处理后的考勤统计结果写入数据库目标表,形成标准化的考勤统计台账,便于后续的报表查询、深度分析与历史追溯。
具体操作步骤如下:
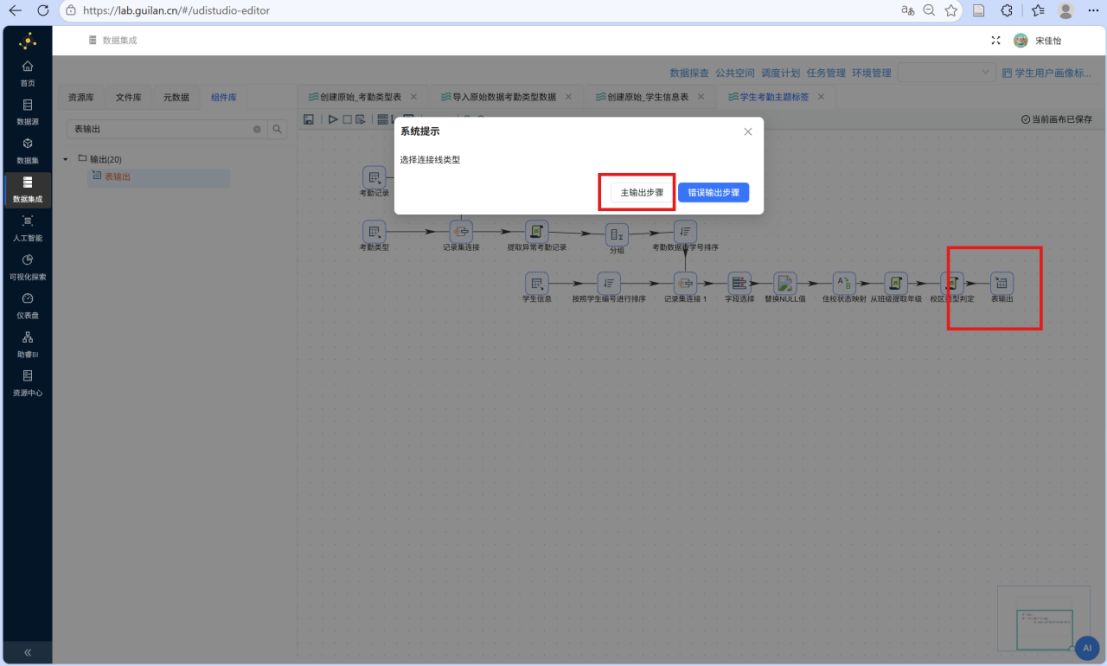
步骤一: 从组件库中添加 "表输出" 组件至画布,并创建从 "校区类型判定" JavaScript 代码组件到 "表输出" 组件的连接线。
步骤二: 双击 "表输出" 组件,在配置窗口中选择数据库连接为 "团队私有数据库",目标表选择 student_attendance_stats。
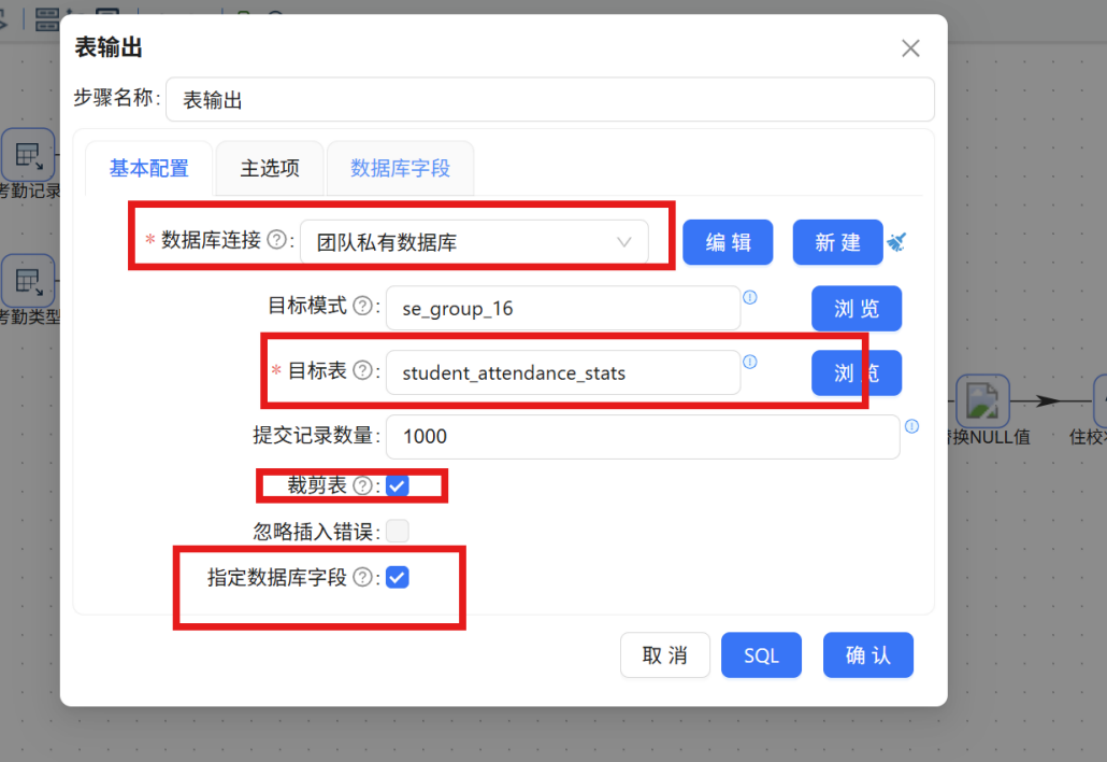
步骤三: 勾选 "裁剪表" 选项。启用该选项后,表输出组件在每次执行插入操作前会自动清空目标表中的原有数据,避免因重复执行导致数据重复插入。
步骤四: 勾选 "指定数据库字段" 选项,手动建立转换流中的工作流字段与数据库目标表字段之间的映射关系。勾选后,系统将激活 "数据库字段" Tab 页。切换至该 Tab 页后,在空白区域点击鼠标右键,选择 "获取字段",系统将自动加载数据库表中的全部字段。
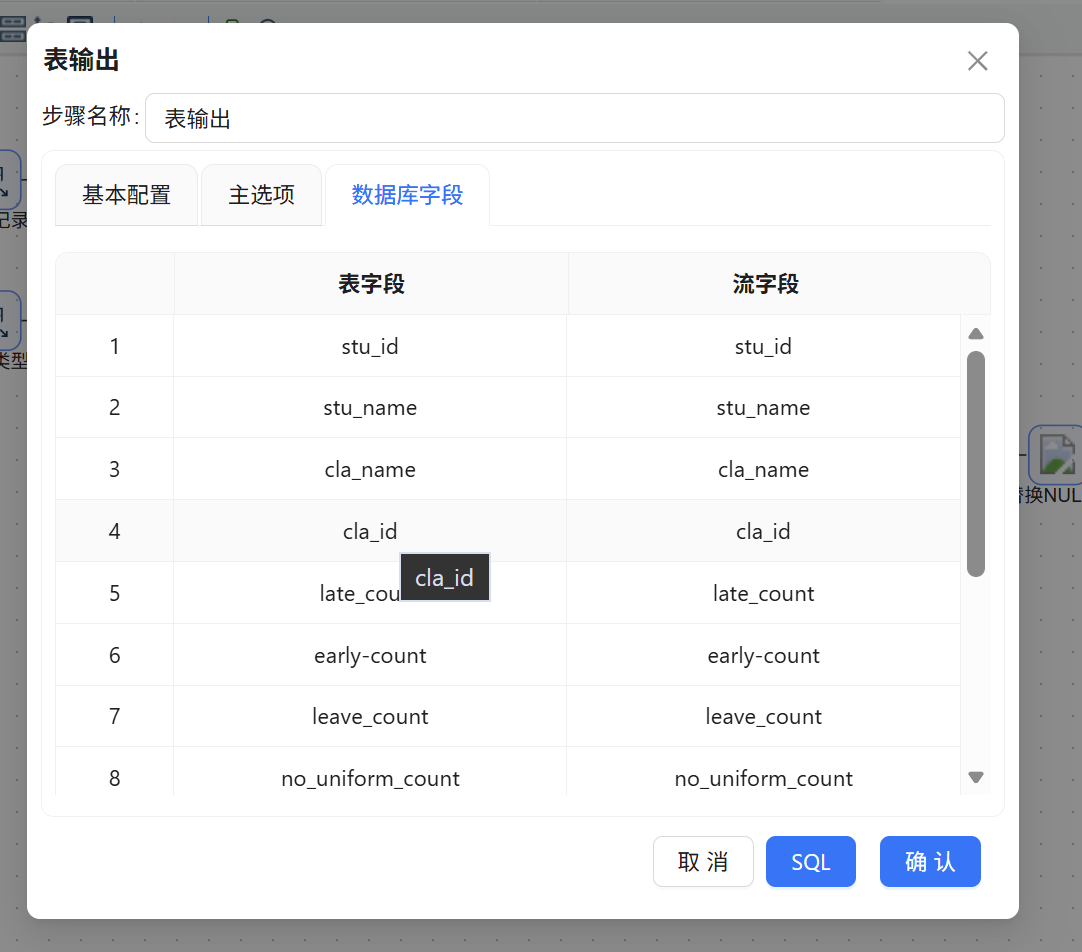
步骤五: 逐一双击表字段列表中的字段名称,在弹出的下拉框中选择与之对应的工作流输出字段,完成字段映射配置。确认所有字段映射关系无误后,点击 "确认" 保存。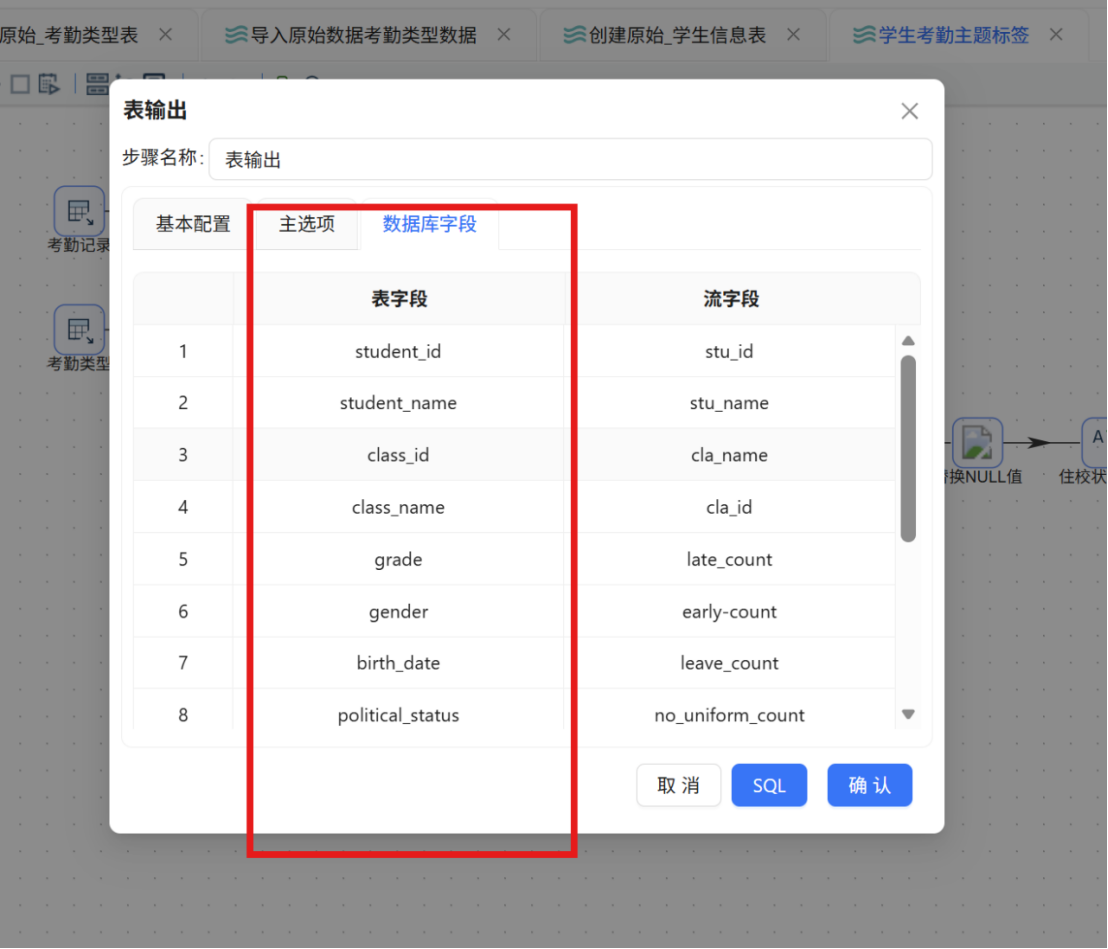
4.3.11 执行工作流
完成全部组件配置后,即可执行转换流,验证整体处理逻辑是否正确,并确认最终数据是否成功写入目标数据库。
具体操作步骤如下:
步骤一: 点击工具栏中的 "执行" 按钮,启动转换流。
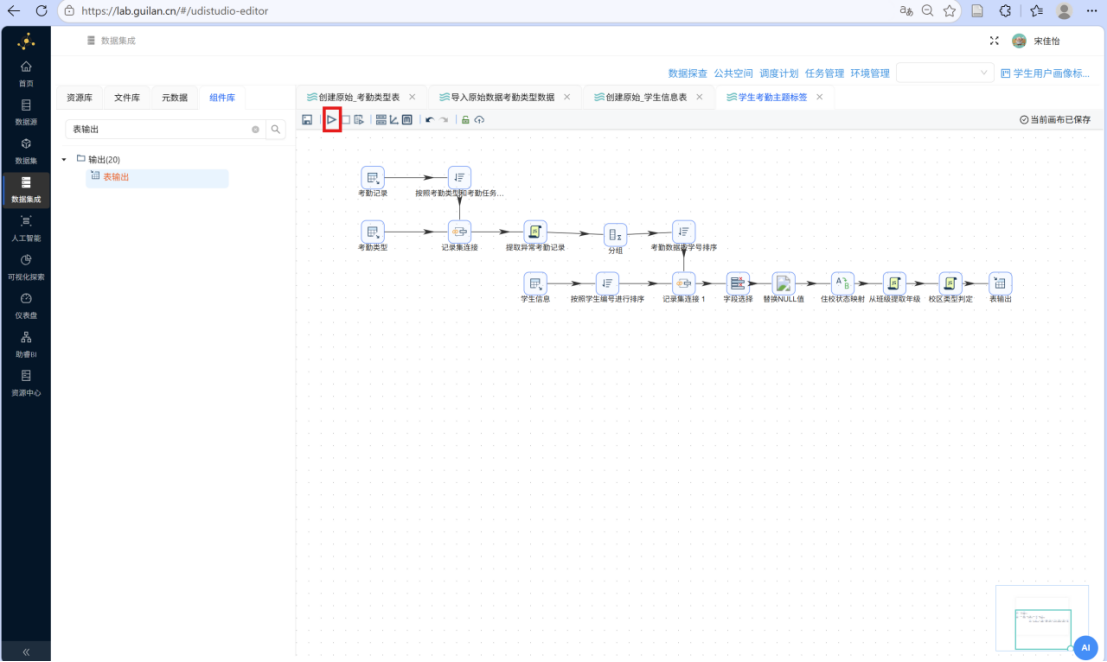
步骤二: 在弹出的执行配置窗口中,保持默认配置不变,直接点击 "启动" 按钮,开始执行工作流。
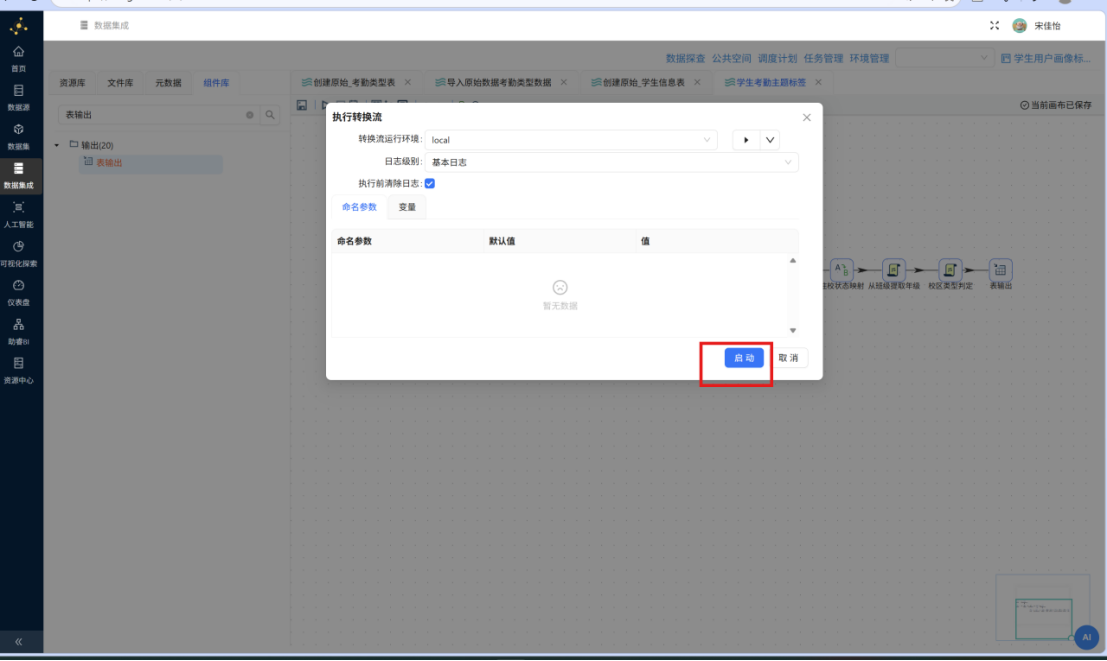
步骤三: 查看执行日志。工作流启动后,系统将自动打开日志页面,并定期刷新显示各组件的执行状态与处理记录数。确认所有组件均显示为绿色(执行成功),且无错误或警告信息。
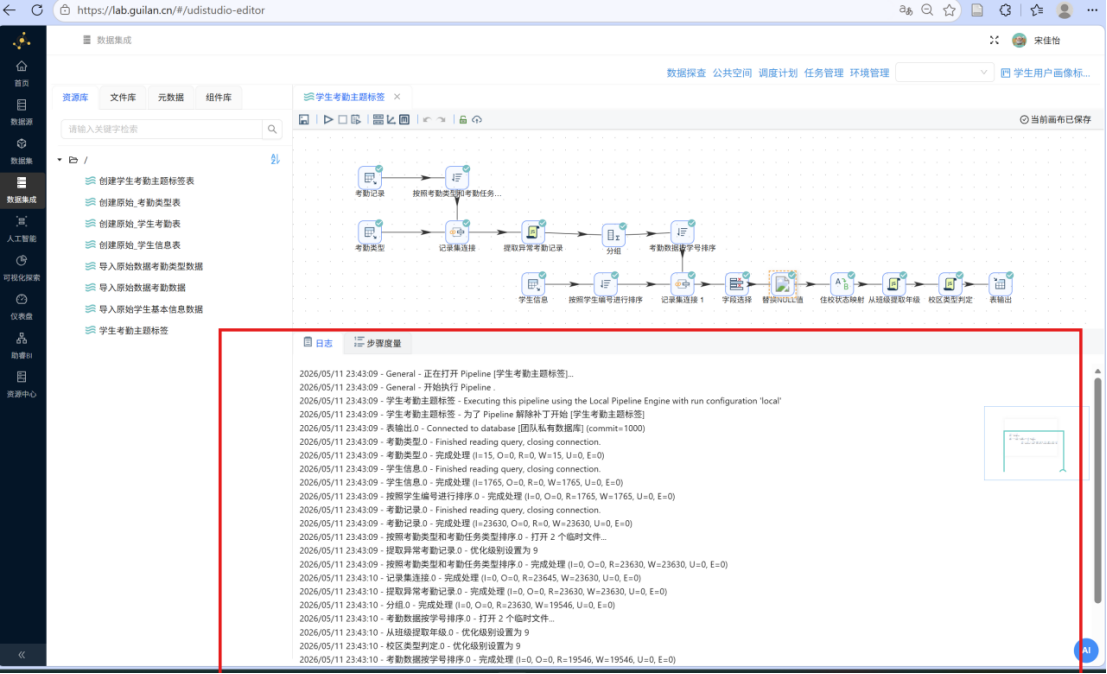
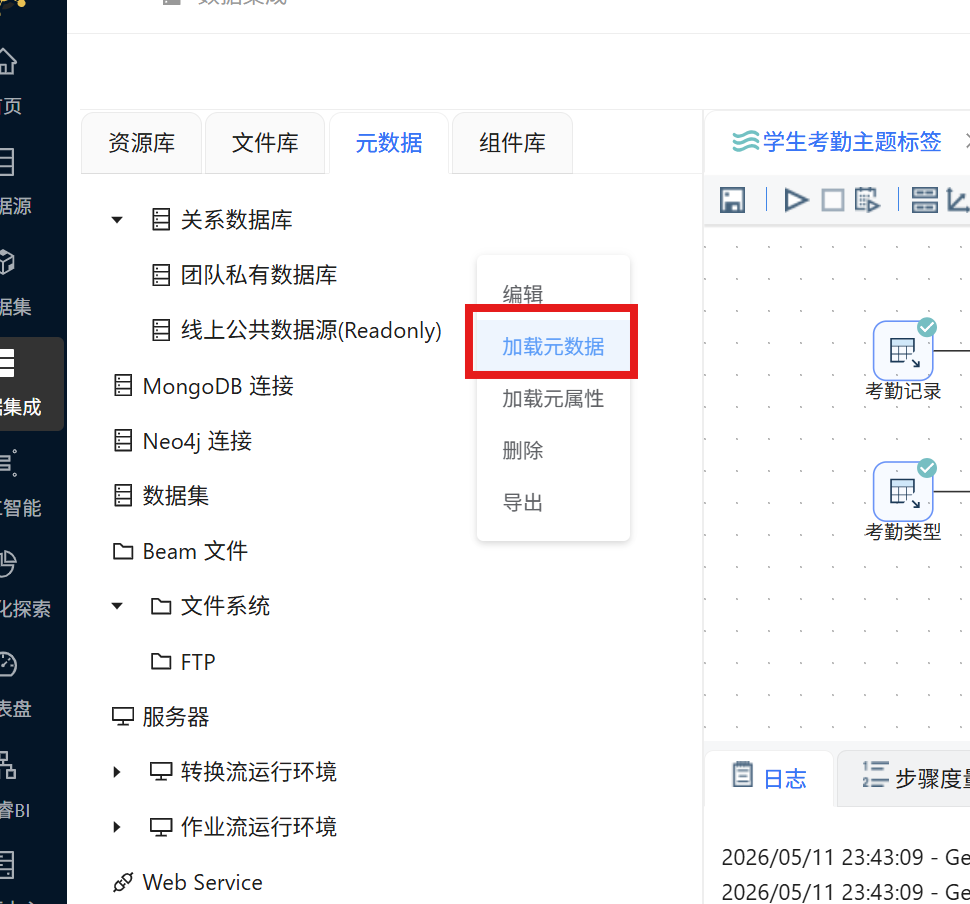
步骤四: 验证数据库写入结果。切换至 "元数据" Tab 页,在 "团队私有数据库" 连接上点击鼠标右键,选择 "加载元数据",刷新数据库表结构信息。
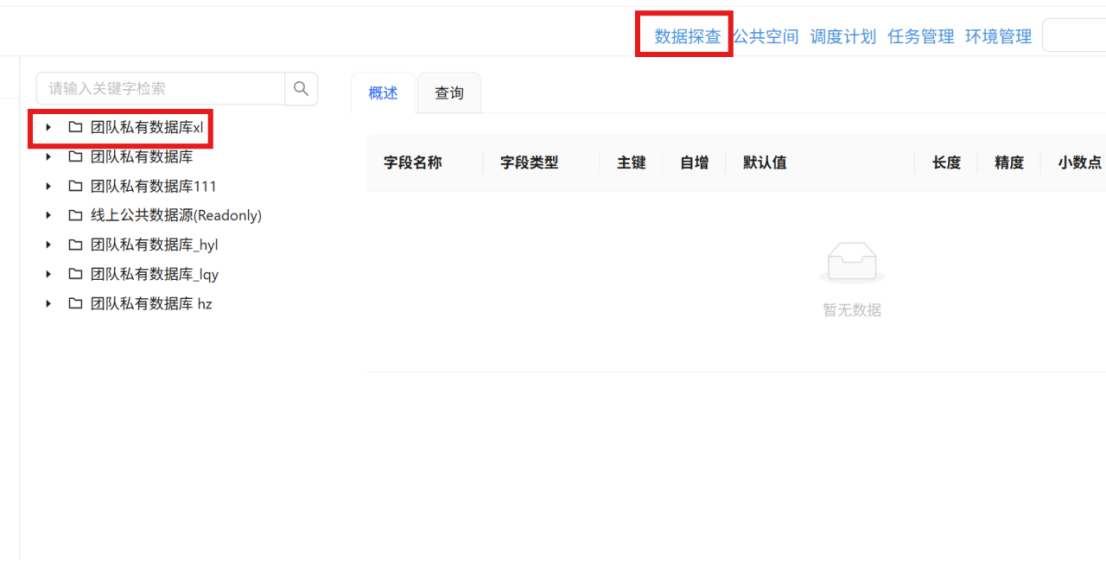
步骤五: 进入 "数据探查" 页面,展开 "团队私有数据库" 节点,找到目标表。
步骤六: 双击目标表 student_attendance_stats,在右侧页面中切换至 "查询" Tab 标签,执行数据查询。
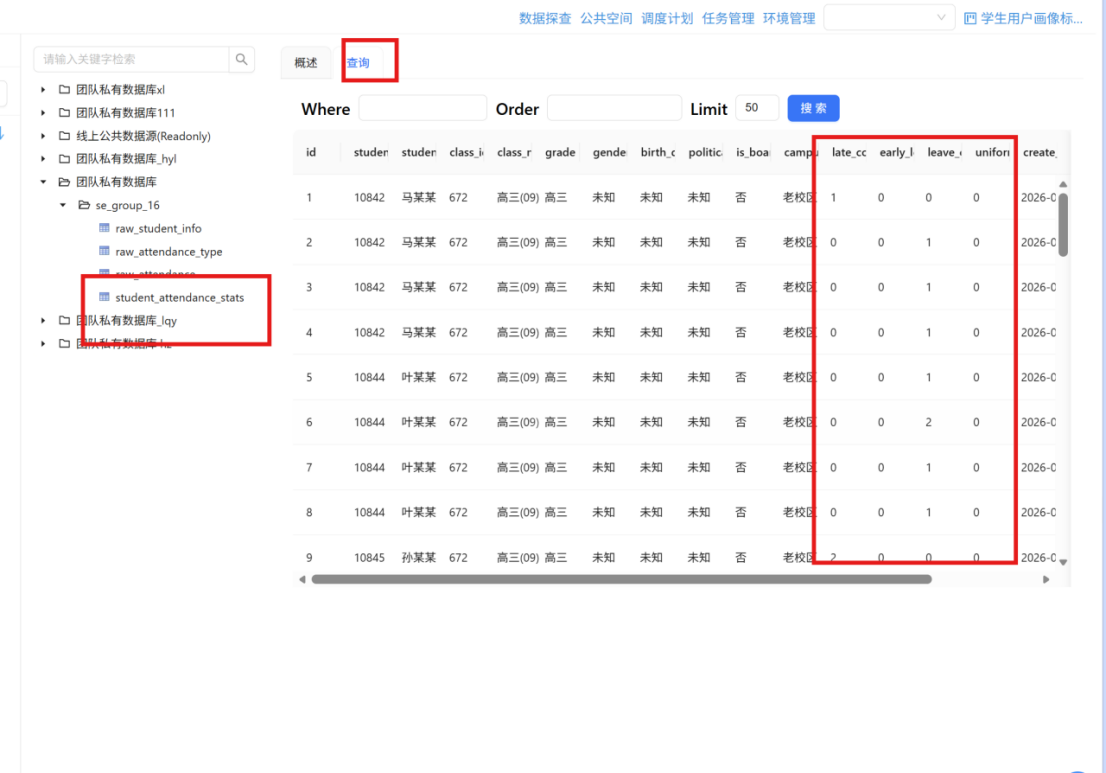
步骤七: 查看数据库表中的数据,核实各字段内容是否符合预期。重点检查以下内容:
|
检查项 |
预期结果 |
|
迟到次数(late_count) |
数值 ≥ 0,与明细标记一致 |
|
早退次数(early_count) |
数值 ≥ 0,与明细标记一致 |
|
请假次数(leave_count) |
数值 ≥ 0,与明细标记一致 |
|
没穿校服次数(no_uniform_count) |
数值 ≥ 0,与明细标记一致 |
|
住校状态(live_on_campus) |
仅含"是""否"两种值,无编码值残留 |
|
年级(gra_name) |
仅含"高一""高二""高三""未知"四种值 |
|
校区类型(class_campus_type) |
仅含"新校区""老校区""未知"三种值 |
|
性别/出生日期/政治面貌 |
无空值,空值已替换为"未知" |
确认数据完整、准确、无异常后,学生考勤主题标签的构建工作全部完成。
5 实验总结
本次实验围绕学生考勤主题标签构建展开,以考勤打卡记录、考勤类型码表和学生基本信息三份原始数据为输入,最终产出一张融合了性别、年级、校区、住校状态等属性维度,以及迟到、早退、请假、未穿校服四项异常行为统计指标的结构化标签宽表。
整个数据加工链路涵盖了表输入、排序记录、记录集连接、字段选择、JavaScript脚本、分组聚合、空值替换、值映射、表输出等9类组件,共计搭建15个处理节点。关键处理逻辑包括:利用两次左外连接完成考勤行为语义补全与学生属性关联,借助脚本中的关键词匹配规则将非结构化的考勤事件名称转化为可量化的二进制标记,再经分组求和将逐条明细压缩为学生粒度的汇总指标,最后通过字符串解析从班级名称中提取出年级与校区两个衍生维度。
与之前的基础ETL练习相比,本次实验在数据源数量、组件串联深度和业务逻辑复杂度上都有明显提升。整个流程在助睿数智(Uniplore)一站式数据科学实验平台(https://lab.guilian.cn/)上完成,通过这次实践,我对平台在多表关联、脚本扩展和数据质量治理方面的能力有了更加系统的理解。
接下来我计划结合成绩数据和消费数据,尝试构建更加立体的学生画像标签体系,届时会同步分享对应的操作记录与心得体会,感兴趣的同学可以持续关注!
觉得有用的话,别忘了点赞收藏加转发~
一起学习,一起成长!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)