从0到1:企业级AI项目迭代日记 Vol.23|系统边界、业务授权、知识库的门——企业AI落地的三个真实卡点
今天讨论了一个看起来很小的问题:工具调用到了 10 次上限,系统该怎么办?
但这个问题越讨论越大,最后扯出了三件事:确认交互的设计哲学、流式输出的工程意义、以及企业 AI 落地真正卡住的地方在哪里。
一、两种“确认”,千万不能混
原来的处理方式:工具调用到 10 次,直接中断,会话失败。体验很差,但至少逻辑清晰。
改进方向是引入用户确认——让用户决定要不要继续。但“确认”这件事,今天理清楚了一个容易混淆的区别:
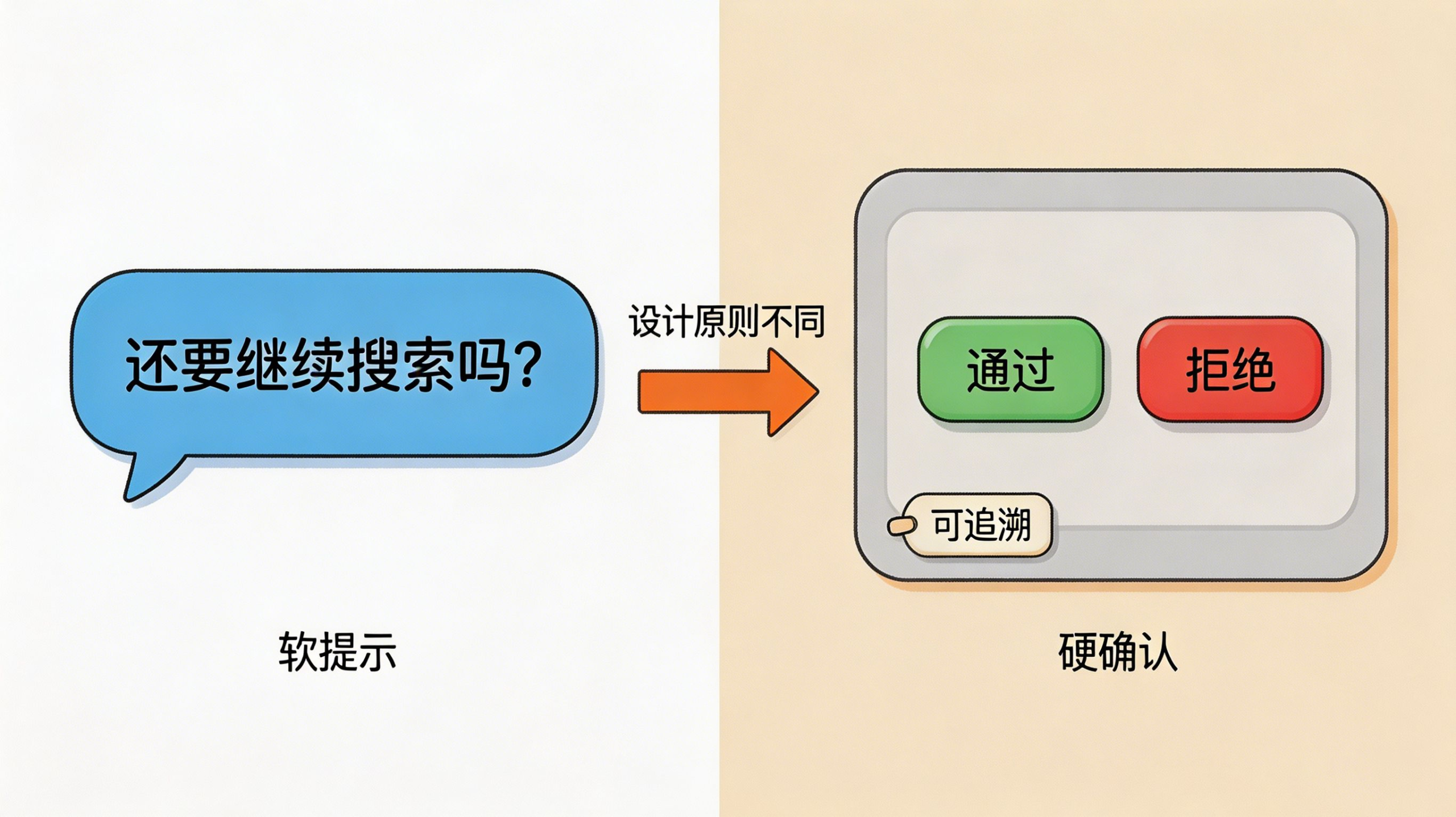
第一种:系统边界提示。
工具调用次数到了,系统不确定用户是否还想继续,需要问一下。这种情况,适合软提示——由 LLM 生成一句自然语言,大意是“我已经搜索了很多次,还没找到你想要的,要继续吗”。它本质上是一次对话,不是一个流程节点。
第二种:业务审批确认。
工作流执行到需要人工授权的步骤——比如报销单提交、合同发起——这里需要的是硬确认:一个卡片,明确的“通过”和“拒绝”按钮,有操作记录,可追溯。它是一个业务节点,不是一次对话。
这两种确认的设计原则完全不同。前者是“系统在问你”,后者是“业务在等你”。 如果把业务审批做成软提示,用户不知道这个操作会有什么后果;如果把系统边界做成硬卡片,用户会觉得莫名其妙,为什么点个按钮才能继续搜索。
把两者区分清楚,才能做出合适的交互。
二、出错了和没完成,系统的处理策略应该不一样
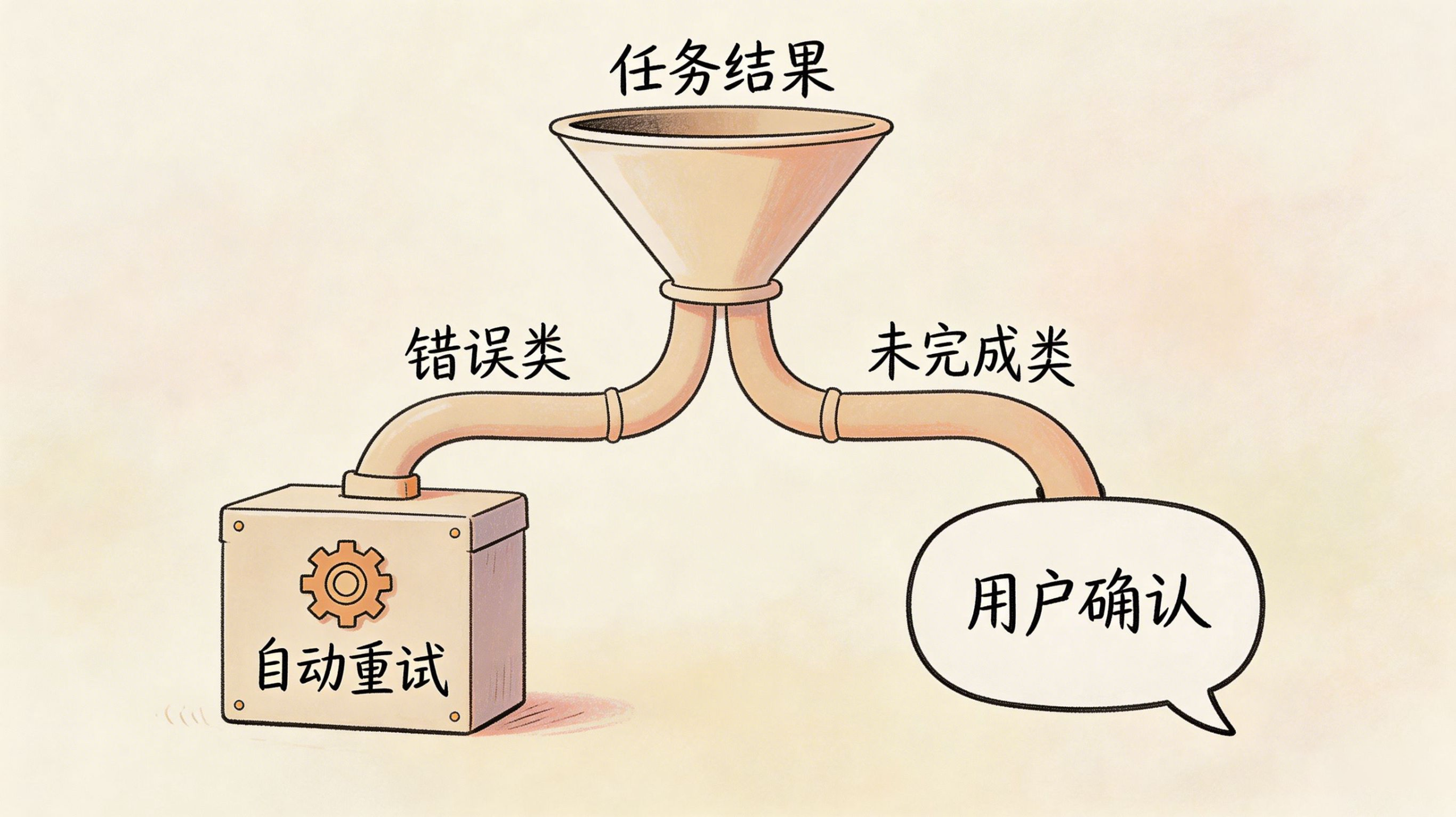
顺着上面这个问题,还有一个更深的讨论:用户派了一个任务,系统跑了 10 次工具没找到,到底是“任务无法完成”还是“任务还没完成”?
大多数情况下,用户布置任务的时候是相信这件事能做到的。他让系统去找一份文件,系统找了 10 次没找到,用户的预期是“继续找”,不是“放弃”。
但工具调用失败又是另一回事。如果是因为接口报错、超时、服务不可用,这是系统层面的技术问题,不应该让用户来决策,而应该由系统自己处理——比如指数退避重试(Exponential Backoff):第一次失败等 1 秒重试,第二次等 2 秒,第三次等 4 秒,这类策略本来就是为了应对瞬时错误设计的。
“没完成”让用户决定要不要继续;“出错了”系统自己去重试。
这两种情况不能用同一套机制处理,否则要么把技术问题甩给用户,要么让任务在用户不知情的情况下悄悄失败。
三、流式输出不只是体验优化,是信任问题
飞书端目前的输出方式是:等所有内容生成完毕,再一次性返回。用户侧的感受是——发出去,等 30 秒,什么动静都没有,然后一堆文字突然出现。
流式输出要解决的,不只是让字一个个蹦出来,而是让用户知道系统没死。
飞书本身支持流式输出,而且提供了一套状态标机制:完成状态、耗时、调用的模型、缓存命中情况、上下文长度——这些信息可以在消息卡片上实时展示。用户看到“已运行 12 秒 · 使用 GPT-4 · 上下文 3200 tokens”,和看到一片空白等了 12 秒,心理状态是完全不同的。
这是“慢不是问题,断才是”这句话在具体实现层的落地。 让等待有信息密度,而不是让用户在沉默里猜测系统是否还在运行。
四、知识库做好了,但用户的 100 份文档进不来
今天最后讨论了一个落地层面的实际问题,也是目前系统最接近“完成”却又卡住的地方。
系统有了知识库,有了 RAG 检索,有了工作流——但企业用户真正想用的时候,第一步就卡住了:他电脑里有 100 份文档,没有办法批量导进来。
这不是一个功能缺失的问题,而是一道物理隔离:本地文件系统和云端知识库之间,没有桥。用户没有办法像操作网盘一样,把本地文件夹同步进去。
方案讨论了几个方向:
-
做一个轻量的桌面客户端,映射本地文件夹到知识库
-
接 WebDAV,让用户把文件“拖进”一个挂载的虚拟磁盘
-
或者写一个极简的上传服务,定时扫描指定目录批量入库

无论哪种,本质是一样的:企业 AI 的价值在于调用企业自己的数据,但数据在哪里、怎么进来,这道门没打开,智能系统就是空转。
知识库入库是最后需要解决的一公里。解决了,系统才算真正可用。
这,是第二十三天。
《从0到1:企业级AI项目迭代日记》记录一个企业级 AI 项目从创意、架构到落地的真实过程。不讲神话,只记录进化。
如果你也在做企业 AI 落地,欢迎留言来聊。或者,把这篇转发给一个正在踩同样坑的朋友。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 12
12 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)