第七章:序列模型与记忆的边界
第七章:序列模型与记忆的边界
[!info]
第五章中,卷积神经网络把"局部感受野"和"权重共享"编码进了结构中,彻底改变了图像识别的格局。第六章中,我们拆解了深度学习的工程内功:优化器从 SGD 进化到 Adam,BatchNorm 让深层网络稳定运行,PyTorch 把调试变回了写普通 Python 代码的感觉,GPU 和 CUDA 提供了矩阵运算的硬件加速。架构对了,工具齐了。然而,这一切辉煌成就都发生在图像的世界里——一个二维的、空间的、相邻像素彼此相关的世界。当我们把目光从图像转向语言,问题的性质从根本上变了。
本章的起点,是卷积网络留下的一个问题:文本和时间序列数据没有"空间局部性",CNN 不适用,怎么办?
[!question]
语言是有顺序的,上下文可以跨越很长的距离——循环神经网络能捕捉这种时序依赖吗?如果能,为什么后来还需要改进?
7.1、一个大学生的毕业论文
1991 年,慕尼黑工业大学(TU Munich)的一名本科生正在写他的毕业论文。他的名字叫塞普·霍赫赖特(Sepp Hochreiter),他选了一个几乎没人觉得值得深入研究的题目:为什么循环神经网络很难训练?
当时,循环神经网络(Recurrent Neural Network,RNN)的基本想法已经存在了好几年。1986 年,Rumelhart、Hinton 和 Williams 发表了反向传播算法,顺带提出了"随时间反向传播"(Backpropagation Through Time,BPTT)——这使得训练具有时间记忆的网络在理论上成为可能。可是在实践中,研究者们普遍发现一个令人沮丧的现象:RNN 能记住最近发生的事,却几乎无法学到早期信息对当前输出的影响。
这不是玄学,而是有数学原因的。霍赫赖特花了大量时间,一步步推导梯度在时间轴上的传播过程。他的结论令人不安:在长序列上,梯度要么消失,要么爆炸——这两种情况都让训练陷入了僵局。
他把这些分析整理成了毕业论文,交给他的导师尤尔根·施密德胡贝尔(Jürgen Schmidhuber)。施密德胡贝尔看完后大吃一惊——这个学生不仅准确地诊断了一个困扰整个领域的病症,而且提出了一个具有可行性的治疗方案。六年之后,1997 年,两人共同发表了那篇奠基性的论文,提出了长短期记忆网络(Long Short-Term Memory,LSTM)。
但这个故事的奇特之处在于:1997 年的这篇论文几乎被忽视了。
不是因为它错了,而是因为当时没有人真正在乎。1990 年代末,机器学习的主流是 SVM,循环网络是一个小众领域,而 LSTM 的论文晦涩难懂,充满了数学符号。它在安静中度过了漫长的岁月,直到 2000 年代中期,当深度学习开始崛起,当人们开始认真对待神经网络,才有人重新拿起这篇论文,惊讶地发现:原来十年前就已经有人解决了这个问题。
这种"发现了答案,但没人听见"的故事,在 AI 的历史里并不罕见。但 LSTM 的际遇格外戏剧化——它沉睡了将近二十年,然后突然变成了整个行业的基础设施。
要理解为什么 LSTM 如此重要,我们需要先理解一件更基本的事:语言到底有什么特别的?
7.2、语言的特殊性:为什么 CNN 在这里失效
在开始讨论循环网络之前,我们需要直面一个问题:第五章中大放异彩的卷积神经网络,为什么不能直接用来处理文本?
7.2.1 图像与语言:两种截然不同的结构
让我们想象两种不同的信息:一张猫的照片,和一句话"那只猫坐在毯子上"。
对于图像,相邻像素之间有强烈的空间局部相关性——猫耳朵上的毛发颜色,和旁边几个像素的颜色高度相关。同时,一个特征(比如猫耳朵的形状)出现在图像的任何位置,它都是猫耳朵。这两个性质——局部相关性和平移等变性——正是 CNN 卷积核设计的出发点。
但语言完全不同:
第一,顺序至关重要。 “张三打了李四"和"李四打了张三”,用词完全相同,但意思相反。在图像中,把一只耳朵从左边移到右边,还是同一只耳朵;在语言中,一个词的位置变化就足以颠覆语义。
第二,依赖关系可以跨越任意长的距离。 "那只昨天在我回家的路上、趴在我邻居家门口晒太阳的小猫,它今天不见了。"主语"那只猫"和代词"它"之间,隔了二十多个词。CNN 的感受野有限,要捕捉这种长距离依赖,需要很深很深的网络,而且效率极低。
第三,序列长度是可变的。 CNN 处理的图像可以规范化成固定大小(比如 224×224224×224224×224),但一句话可以是三个词,也可以是三百个词。这对固定结构的网络是个挑战。
7.2.2 "时间步"的思维模型
在处理序列之前,我们需要确立一个思维模型。
想象你一个人在读一段文字。你的眼睛一个字一个字地扫过去,但你的大脑并不是每次都从零开始的——你携带着前文的记忆往前走。当你读到"它今天不见了"的时候,你已经在前文建立起了"那只猫"的心理表征,所以你自然知道"它"指的是谁。
这个"携带记忆,步步推进"的过程,就是循环网络的核心比喻。我们把处理序列的每个步骤叫做一个时间步(time step)——每一步处理一个输入元素(比如一个词),同时维护一个隐状态(hidden state),记录截止到目前为止读到的信息。
这个隐状态,就是网络的"记忆"。
7.3、词的表示:从词汇表到语义空间
我们能将图像输送给 CNN 进行处理,是因为图像本质上就是由像素点组成的矩阵,而像素点通常使用如 RGB 三颜色通道编码,其背后本质上就是 0-255 区间内的一组数字,天然的可以进行数值操作。
可是文字怎么办?
在把语言喂给任何神经网络之前,我们必须先解决一个根本性的工程问题:词是字符串,神经网络只能处理数字。把"猫"这个词变成一个向量,这件事本身,就有一段值得讲述的历史。
7.3.1 独热编码:简单但代价高昂
最朴素的方案是独热编码(One-Hot Encoding)。假设词汇表有 10 万个词,就用一个 10 万维的向量表示每个词——向量里只有一个位置是 1,其余全是 0。"猫"可能对应第 4723 个位置,"狗"对应第 12891 个位置。
这个方案有两个灾难性的问题。
第一,维度诅咒:10 万维的向量,存储和计算代价极高。一个10万×10万的词嵌入矩阵,参数量是 100亿——光是存储就需要 40GB。
第二,语义真空:独热向量里,所有词之间的距离都是一样的。“猫"和"狗"之间的距离,与"猫"和"月球"之间的距离,在数学上完全相同。这个表示方式没有携带任何语义信息——向量里没有"猫是动物”、"猫和狗都是宠物"这样的知识。
研究者们很早就意识到:关于词,好的表示应该把语义编码进距离——意思相近的词,应该在向量空间里彼此接近。这个想法早在 1980 年代就有人提出(分布式表示,Distributed Representation,Hinton 早期工作的一部分),但真正让这个想法变得实用、变得轰动,是 2013 年的一篇论文。
7.3.2 词向量:从符号到数字的关键转折
在第 4 章中,我们已经介绍过 Word2Vec 的概念——用神经网络从大规模文本中学习词的分布式表示(Distributed Representation)。每个词不再是一个 10 万维的稀疏独热向量,而是变成了一个 100-300 维的稠密向量,其中语义相似的词在向量空间里距离更近。
但这只是故事的前半截。真正重要的是:这个转变对序列模型意味着什么?
Word2Vec的革命在于:它用一个简单的自监督学习任务(预测上下文词),让神经网络自发地把语义结构编码进了向量。 一旦有了这样的词向量,把它们作为 LSTM 的输入,网络就能直接"看到"词之间的语义关系。从而,LSTM 可以更高效地学习什么是"动词"、“名词”、"情感词"等语言模式。
这种词向量的预训练和复用,成为了整个 NLP 工程的标准做法。一个在大规模新闻语料上训练好的词向量模型,可以被所有下游任务重复使用——在情感分析、实体识别、机器翻译等各种任务上,都比随机初始化的词向量要好得多。这是迁移学习在 NLP 里最早也最有效的实践。
7.3.3 词向量的根本局限:一词一向量的困境
然而,Word2Vec 和 GloVe 都有一个致命的限制:每个词只有一个固定的向量,无论它出现在什么上下文里。
语言充满了多义词:
- “bank” 可以是金融机构,也可以是河边的土堤
- “apple” 可以是水果,也可以是科技公司
- “set” 在英语里有超过 400 种含义
一词一向量的后果是模型无法真正理解多义词,只能学到一个"加权平均"的模糊表示,往往代表那个词的最常见意思。对于较少见的含义,模型会做出不准确的预测。
这个限制,在短文本任务上还勉强可以忍受。但在长文本、复杂句式、需要精细语义理解的任务上,它成了一道难以跨越的天花板。
正是由于存在这个根本局限,在 2018 年催生了一个新的研究方向:上下文相关的词表示(Contextual Word Representations)。
ELMo(Embeddings from Language Models,来自 Facebook AI)是第一个真正解决这个问题的工作。它的关键洞察很简单,但很深刻:与其用一个固定向量表示每个词,不如用一个深层神经网络(双向 LSTM),在给定完整句子的上下文后,动态生成这个词的表示。 同一个词 “bank” 在不同句子里,会得到不同的向量。
ELMo 的出现,标志着 NLP 进入了一个新时代。接下来的 BERT、GPT 等预训练语言模型,都是在这个"上下文决定表示"的思想基础上,用更强大的架构(Transformer)去实现。这是我们将在第十章详细讲述的故事。
词向量经历了从 Word2Vec 到 ELMo 的转变,Word2Vec 证明了"好的表示可以被学习而不必手工设计"和"表示是可以跨任务迁移的"。但 ELMo 进一步证明了"表示必须是动态的,要取决于上下文"。这两个观念的结合,成为了现代 NLP 的基石。
7.4、循环神经网络:记忆的第一次尝试
7.4.1 基本结构:一个带有自我引用的神经元
1986 年,Rumelhart 等人在反向传播论文中提出了循环网络的基本想法。这个想法用一句话可以表达:让网络的输出反馈成为下一步的输入。
一个标准的前馈神经网络,信息只朝一个方向流动:输入 → 隐藏层 → 输出。但如果我们给隐藏层加上一个"自我循环"——把上一时刻的隐状态作为这一时刻的输入之一——网络就获得了记忆能力。
形式上,RNN 在每个时间步 ttt 执行这样的计算:ht=tanh(Whh⋅ht−1+Wxh⋅xt+b)yt=Why⋅ht\begin{align} h_t &= \tanh(W_{hh} \cdot h_{t-1} + W_{xh} \cdot x_t + b) \\[1.2ex] y_t &= W_{hy} \cdot h_t \end{align}htyt=tanh(Whh⋅ht−1+Wxh⋅xt+b)=Why⋅ht
其中:
- xtx_txt 是当前时间步的输入(比如当前词的向量表示)
- ht−1h_{t-1}ht−1 是上一时间步的隐状态(“记忆”)
- hth_tht 是更新后的隐状态
- yty_tyt 是当前时间步的输出
- WhhW_{hh}Whh、WxhW_{xh}Wxh、WhyW_{hy}Why 是权重矩阵(在所有时间步之间共享)
- tanh\tanhtanh 是激活函数
注意这里的一个关键设计:所有时间步共享同一组权重。这和 CNN 的卷积核共享权重一样,是一种优雅的归纳偏置——我们假设"处理语言"这件事,在每个位置的方式应该是一致的。处理第 1 个词的网络,和处理第 100 个词的网络,是同一个网络,只是携带的记忆不同。

图 7.1:RNN 的展开图。左边展示 RNN 的折叠形式——一个节点带有自指向的循环箭头(表示隐状态传递)。右边展示时间轴上展开后的形式:一排网络节点,每个节点接收当前输入 xtx_txt 和上一隐状态 ht−1h_{t-1}ht−1,输出新的隐状态 hth_tht。时间从左向右流动,如同电影胶片。
7.4.2 展开图:把"循环"变成"深度"
理解 RNN 的一个技巧是展开(unrolling):把时间轴拉开,把 RNN 想象成一个沿时间方向展开的深度网络。
一个处理 10 个词的 RNN,展开之后就是一个 10 层的"深度网络"——只不过每层用的是同一组权重,而且层与层之间的连接方式是固定的(通过隐状态)。
这个视角很有用,因为它让我们立刻看到了 RNN 的一个潜在问题:梯度需要沿着时间轴反向传播。要让网络知道"序列开头的某个词影响了 100 步之后的输出",梯度必须在时间轴上传播 100 步。这和深度网络的梯度消失问题非常相似——只是方向不同,一个是在"层"的方向上消失,一个是在"时间"的方向上消失。
7.4.3 为什么 RNN 能工作
在正式讨论 RNN 的问题之前,我们需要公平地承认:在某些任务上,RNN 确实工作得相当好。
1990 年代,研究者们用 RNN 做了很多有趣的实验:
- 语言模型:给定前几个词,预测下一个词。RNN 学到了相当不错的统计规律。
- 手写识别:读取笔迹的时间序列,识别字符。在某些数据集上,RNN 的表现超越了之前的方法。
- 简单的语音识别:一些研究者用 RNN 尝试了短词汇的语音识别,取得了初步成果。
这些成果证明"循环结构"的基本想法是对的。问题不是这个思路错了,而是这个思路还不够用——一旦序列变长,一旦依赖关系跨越很多步,RNN 就开始失效。
7.4.4 双向 RNN:同时向前看和向后看
标准 RNN 只能单向处理序列——从左到右,每个时间步的隐状态只携带"过去"的信息。但理解语言往往需要同时参考前后上下文。
试想这个句子:“他把苹果放进了篮子,因为它太重了。”
"它"指的是苹果还是篮子?要回答这个问题,需要看"它"之后的信息——"太重"可能指装满苹果的篮子,也可能指单个苹果。只向前看的 RNN 无法利用这种后续上下文。
1997 年,双向 RNN(Bidirectional RNN,BiRNN) 提出了一个直觉简单但效果显著的扩展:同时训练两个 RNN,一个从左到右,一个从右到左,然后把两个方向在每个位置的隐状态拼接起来。
ht→=RNN(xt,ht−1→)(正向)ht←=RNN(xt,ht+1←)(反向)ht=[ht→;ht←] (拼接)\begin{align} \overrightarrow{h_t} &= \text{RNN}(x_t, \overrightarrow{h_{t-1}}) \qquad \text{(正向)} \\[1.2ex] \overleftarrow{h_t} &= \text{RNN}(x_t, \overleftarrow{h_{t+1}}) \qquad \text{(反向)} \\[1.2ex] h_t &= [\overrightarrow{h_t}; \overleftarrow{h_t}] \,\qquad \qquad \quad\text{(拼接)} \end{align}hththt=RNN(xt,ht−1)(正向)=RNN(xt,ht+1)(反向)=[ht;ht](拼接)
拼接之后,每个位置 ttt 的表示同时包含"此前所有词"和"此后所有词"的信息——对于需要完整上下文的分类任务,这比单向 RNN 要丰富得多。
双向 LSTM(BiLSTM) 在 NLP 任务中几乎成了标配:
- 命名实体识别:判断 “apple” 是水果还是公司,通常需要看后面几个词才能确定
- 情感分析:某些句子的情感极性要到句尾才变得明朗(“我觉得这部电影……还不错”)
- 词性标注:同一个词在不同句子位置可以有不同词性,前后文都有帮助
一个重要限制:双向 RNN 不能用于生成任务的解码阶段。生成文本时,"未来"的词还没有生成,无法提供"向右看"的信息。因此,Seq2Seq 模型中,编码器可以是双向的,但解码器只能是单向的。这个区分在后来的预训练模型中同样适用:BERT 采用双向架构(擅长理解),GPT 采用单向架构(擅长生成)。
7.4.5 多层堆叠:让 RNN 也变"深"
单层 RNN 在时间维度上展开,形成了横向的序列处理能力;但与前馈网络可以堆叠多层一样,RNN 同样可以纵向堆叠多层,形成更深的表示能力。
堆叠 LSTM(Stacked LSTM) 的结构很直观:第一层 LSTM 在每个时间步的输出序列,整体作为第二层 LSTM 的输入;第二层的输出,再作为第三层的输入……每一层都完整处理整个序列,但基于上一层的表示,而非原始输入。
直觉上,不同层次的 LSTM 可能学到不同抽象级别的语言特征:
- 底层:词法和局部句法模式(词根、词缀、常见短语搭配)
- 中层:短语结构和句子成分(主谓宾、从句关系)
- 高层:语义和话语层面的抽象(逻辑推断、情感倾向、话题连贯)
这种层次化分工是否真的按如此整齐的方式发生,研究者仍有争议,但多层堆叠确实带来了性能提升。Sutskever 等人在 2014 年的 Seq2Seq 论文中, 编码器和解码器各用了 4 层 LSTM,每层 1000维隐状态——这在当时是相当激进的计算投入,但实验证明,更深的网络翻译质量明显优于单层。
实践中,2-4 层的堆叠是最常见的工程选择。超过 4 层之后,收益边际递减,而训练时间和内存消耗线性增加。层数的选择,和隐状态维度一样,是一个需要在模型容量与计算成本之间权衡的超参数决策。
7.5、梯度的消失:时间轴上的幽灵
霍赫赖特在他的毕业论文里做了一件当时几乎没人做过的事:他不只是说"RNN 很难训练",他一步步推导了为什么很难训练,并量化了梯度是如何随时间步数增加而衰减的。
7.5.1 反向传播穿越时间
要理解梯度消失,我们需要追踪梯度是如何反向传播的。
设想一个任务:RNN 读完一段 100 个词的文章,在最后输出一个答案。训练时,我们希望调整网络权重,让最后的输出更准确。反向传播需要计算:“如果我稍微改动第 1 步(最早的输入)的权重,最终输出会如何变化?”
为了回答这个问题,梯度需要从第 100 步一路向前传播到第 1 步。每经过一个时间步,梯度要乘上一个因子(来自激活函数的导数和权重矩阵)。
问题在于 tanh\tanhtanh 激活函数的导数:dtanh(x)dx=1−tanh2(x)\frac{\mathrm{d}\tanh(x)}{\mathrm{d}x} = 1 - \tanh^2(x)dxdtanh(x)=1−tanh2(x)
tanh\tanhtanh 的值域是 (−1,1)(-1, 1)(−1,1),所以 tanh2(x)∈(0,1)\tanh^2(x) \in (0, 1)tanh2(x)∈(0,1),导数的取值在 (0,1)(0, 1)(0,1) 之间。这意味着每经过一个时间步,梯度至少会乘上一个小于 1 的数。
100 步之后:(0.9)100≈0.000027(0.9)^{100} \approx 0.000027(0.9)100≈0.000027。梯度变成了原来的万分之三。
这就是梯度消失(Vanishing Gradient) 问题的本质。到了第 1 步,梯度已经小到数值精度无法表示,网络实际上不会根据最早的信息做任何调整。
梯度消失的反面是梯度爆炸(Exploding Gradient)——当权重矩阵的特征值大于 1 时,梯度随时间步指数增长,直到产生 NaN。这个问题相对容易处理(梯度裁剪:超过阈值就截断),但梯度消失没有这么简单的解决方案。
7.5.2 记忆的困境:金鱼的七秒
梯度消失意味着什么,换个方式说会更直接:RNN 事实上只有短期记忆。
给 RNN 读一篇文章,它对最近几个词的理解是准确的,但"很久以前"读到的信息,已经从隐状态中消散。就像一条传说中只有七秒记忆的金鱼——虽然这个传说是假的,但 RNN 的困境是真实的。
举一个具体的例子:英语中,主谓一致(subject-verb agreement)要求动词随主语的单复数变化。考虑这个句子:
“The cat that the dogs chased was frightened.”(那只被狗追赶的猫,害怕了。)
主语是 “The cat”(单数),谓语是 “was”(单数),但在主语和谓语之间,插入了一个从句 “that the dogs chased”。网络需要在记住 “cat” 是单数的同时,跳过 “dogs”(复数)的干扰,这需要跨越多个时间步的稳定记忆。
对于人类,这是自然而然的事。但对于 1990 年代的 RNN,这是一个难以完成的挑战。
这里有一个很直觉的比喻,想象一个接力游戏,信息从第 1 号选手传给第 2 号,再传给第 3 号……每次传递,手中的信息都会"打折"——稍微褪色,稍微模糊。传到第 50 号的时候,最初的信息已经面目全非。循环 RNN 的隐状态,就是在做这种不断打折的传递。
这个困境,就是霍赫赖特在 1991 年识别出的根本问题。而他也设计了解决方案——只是那个解决方案被忽视了将近十年。
7.5.3 梯度爆炸与梯度裁剪:简单粗暴却有效
梯度消失有一个对立面,同样能让训练彻底崩溃:梯度爆炸(Exploding Gradient)。
当 RNN 权重矩阵的主特征值大于 1 时,梯度随时间步指数增长。考虑一个简单的例子:如果每步梯度乘以 1.1,经过100步之后变成 1.1100≈13,7801.1^{100} \approx 13{,}7801.1100≈13,780;经过 200 步,就是 1.1200≈1.9×1081.1^{200} \approx 1.9 \times 10^{8}1.1200≈1.9×108。权重更新的幅度远超合理范围,参数在几次迭代内就会变成 NaN,训练彻底崩溃。
观察梯度爆炸很直观:如果训练日志里损失值突然变成 nan 或 inf,这时第一反应就应该怀疑是梯度爆炸的问题。
梯度爆炸有一个相对简单但极为有效的工程解法:梯度裁剪(Gradient Clipping)。
方法是:在每次反向传播之后、参数更新之前,计算所有参数梯度组成的总向量的 L2L_2L2 范数。如果超过了预设阈值(通常设为 1.0 到 5.0 之间),就按比例缩小所有梯度,使范数恰好等于阈值:
如果 ∥g∥>threshold,g←threshold∥g∥⋅g\text{如果 } \|\mathbf{g}\| > \text{threshold},\quad \mathbf{g} \leftarrow \frac{\text{threshold}}{\|\mathbf{g}\|} \cdot \mathbf{g}如果 ∥g∥>threshold,g←∥g∥threshold⋅g
在 PyTorch 中,这只需要一行代码:
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=5.0)
这个操作的关键性质是,它只改变梯度的大小,不改变梯度的方向——参数仍然朝正确方向更新,只是更新步幅被限制在合理范围内。几乎所有训练 RNN 的工程师都会把梯度裁剪作为默认配置。
梯度爆炸和梯度消失的不对称性揭示了一个有趣的工程哲学:上界问题(爆炸)往往比下界问题(消失)更容易解决。我们可以强行截断过大的梯度,但无法强行"放大"趋向于零的梯度——后者必须通过架构设计从根本上解决,这正是 LSTM 细胞状态的使命。
7.6、LSTM:三道门的工程美学
1997 年,霍赫赖特和施密德胡贝尔发表了 LSTM 论文。这篇论文的核心思路,可以用一句话概括:与其让记忆在时间步之间自动衰减,不如设计一个可以主动选择"记什么"、“忘什么”、"输出什么"的机制。
7.6.1 从"被动传递"到"主动管理"
传统 RNN 的隐状态是被动的,在每一步中,新信息和旧记忆会进行混合后再经过激活函数,旧记忆不可避免地被"覆盖"和"淡化"。这就像一块会随时间自动褪色的黑板——我们没有办法控制哪些字会保留,哪些字会消失。
LSTM 的设计思路则截然不同,它引入门(Gate) 机制。门是一种可学习的"开关",它的输出值在 0 到 1 之间——0 表示"完全关闭,什么都不通过",1 表示"完全打开,全部通过"。通过三道门的组合,LSTM 可以精确控制信息流。
霍赫赖特和施密德胡贝尔把这个关键的内部记忆叫做细胞状态(Cell State)——区别于"隐状态",细胞状态是一条专门用来传递长期记忆的"高速公路",设计上尽量让梯度通过时不产生衰减。
7.6.2 三道门详解
让我们逐一拆解 LSTM 的三道门。每道门都接收同样的输入:当前词的向量 xtx_txt 和上一时刻的隐状态 ht−1h_{t-1}ht−1。不同的门用不同的权重矩阵对它们进行变换,然后输出一个 0 到 1 之间的值,作为"这道门开多大"的控制信号。
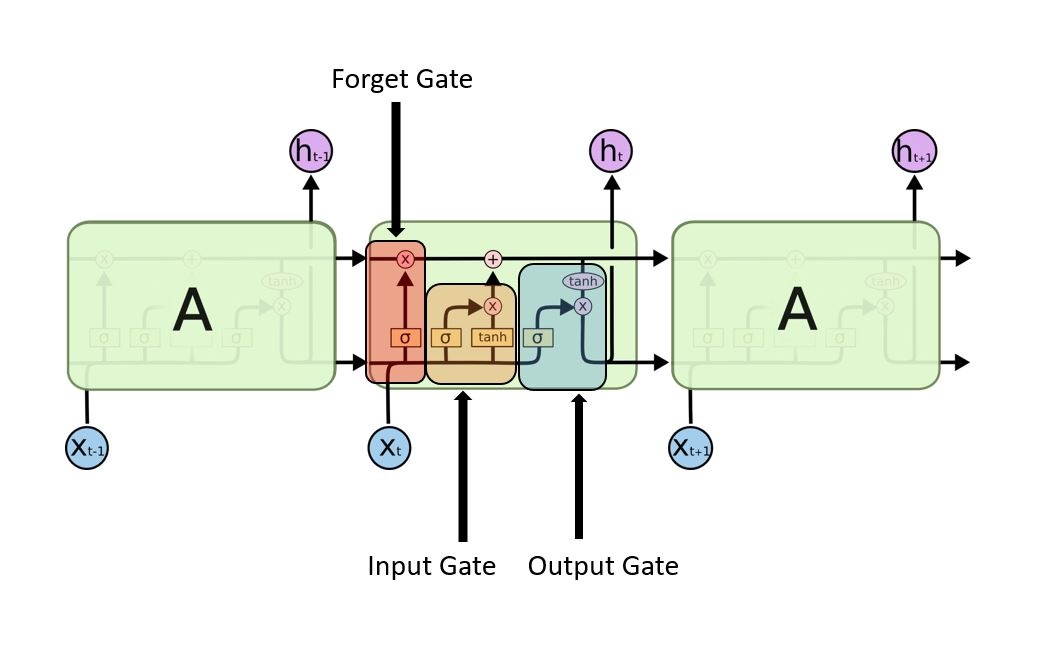
图 7.2:LSTM 内部结构 。顶部水平方向的箭头表示细胞状态 CtC_tCt 的传递(长期记忆高速公路)。底部接收输入 xtx_txt 和上一隐状态 ht−1h_{t-1}ht−1。三道门用不同颜色标注:遗忘门(红色)控制细胞状态的哪些部分被删除,输入门(黄色)控制新信息如何写入,输出门(蓝色)控制输出什么。所有门都用 sigmoid 激活(输出 0-1),细胞状态更新用 tanh。
第一道门:遗忘门(Forget Gate)
ft=σ(Wf⋅[ht−1,xt]+bf)f_t = \sigma(W_f \cdot [h_{t-1}, x_t] + b_f)ft=σ(Wf⋅[ht−1,xt]+bf)
遗忘门决定"上一时刻的细胞状态,有多少应该保留?“。σ\sigmaσ 是 sigmoid 函数,输出值在 0 到 1 之间:接近 0 意味着"完全忘掉”,接近 1 意味着"完整保留"。
这里有一个直觉,假设你在读一篇对话文本,当对话主题从"讨论足球"切换到"讨论音乐"时,遗忘门应该学会"忘掉之前关于足球的细节",为新话题腾出空间。
第二道门:输入门(Input Gate)
输入门实际上由两部分组成:it=σ(Wi⋅[ht−1,xt]+bi)C~t=tanh(WC⋅[ht−1,xt]+bC)\begin{align} i_t &= \sigma(W_i \cdot [h_{t-1}, x_t] + b_i) \\[1.2ex] \tilde{C}_t &= \tanh(W_C \cdot [h_{t-1}, x_t] + b_C) \end{align}itC~t=σ(Wi⋅[ht−1,xt]+bi)=tanh(WC⋅[ht−1,xt]+bC)
iti_tit 决定"要不要写入新信息"(0-1),C~t\tilde{C}_tC~t 是"候选新信息"(通过 tanh\tanhtanh 压缩到 -1 到 1 的范围)。两者相乘,得到实际写入的内容。
细胞状态更新:
Ct=ft⊙Ct−1+it⊙C~tC_t = f_t \odot C_{t-1} + i_t \odot \tilde{C}_tCt=ft⊙Ct−1+it⊙C~t
⊙\odot⊙ 表示逐元素乘法。这一步是 LSTM 设计的精髓:细胞状态的更新是加法而非乘法。旧的记忆乘以遗忘门的输出后,直接加上新的候选信息。这个加法结构让梯度可以在时间轴上"畅通无阻"地传播——梯度不需要穿越 tanh\tanhtanh 的导数,可以直接沿着细胞状态的高速公路传回去。这正是解决梯度消失的核心机制。
第三道门:输出门(Output Gate)
ot=σ(Wo⋅[ht−1,xt]+bo)ht=ot⊙tanh(Ct)\begin{align} o_t &= \sigma(W_o \cdot [h_{t-1}, x_t] + b_o) \\[1.2ex] h_t &= o_t \odot \tanh(C_t) \end{align}otht=σ(Wo⋅[ht−1,xt]+bo)=ot⊙tanh(Ct)
输出门决定"细胞状态的哪些部分应该作为当前时间步的输出"。注意输出门读取的是经过 tanh\tanhtanh 压缩的细胞状态(输出范围 -1 到 1),再通过输出门的控制,决定实际传递给下一层的隐状态 hth_tht。
一个整体类比:想象 LSTM 是一位编辑在处理一份持续更新的档案(细胞状态):
- 遗忘门 = 他决定"上次的档案里,哪些内容已经过时,可以划掉"
- 输入门 = 他决定"今天收到的新信息,哪些值得写入档案"
- 输出门 = 他决定"向外汇报时,档案里的哪些内容需要提取出来"
这位编辑不是被动地接受信息,而是在主动地管理记忆。
(选读内容)为什么细胞状态的更新是加法而不是乘法,对梯度传播如此重要?
在传统 RNN 中,隐状态的更新是:ht=tanh(Wht−1+⋯ )h_t = \tanh(W h_{t-1} + \cdots)ht=tanh(Wht−1+⋯)。反向传播时,梯度需要穿越 tanh\tanhtanh 函数(其导数最大为 1,通常小于 1),并与权重矩阵 WWW 相乘。经过 TTT 步后,梯度约为 (W⋅tanh′)T(W \cdot \tanh')^T(W⋅tanh′)T。当 W⋅tanh′<1W \cdot \tanh' < 1W⋅tanh′<1 时,这个值指数级衰减。
而 LSTM 的细胞状态更新 Ct=ft⊙Ct−1+⋯C_t = f_t \odot C_{t-1} + \cdotsCt=ft⊙Ct−1+⋯ 是加法。梯度从 CtC_tCt 传回 Ct−1C_{t-1}Ct−1 的路径上,只有遗忘门 ftf_tft 这一个乘法因子。如果遗忘门被训练成接近 1(“不忘记”),梯度就几乎可以无损地传播。这不是"完全消除梯度消失",而是"让网络自己学会什么时候应该保持梯度通道畅通"——一个更动态、更灵活的解法。
7.6.3 一个被遗忘的细节:LSTM 在 1997 年有什么不同
1997 年的原始 LSTM 论文中,实际上没有包含遗忘门——遗忘门是 Felix Gers、施密德胡贝尔和 Fred Cummins 在 2000 年的后续工作中加入的。
这个细节的有趣之处在于,现代几乎所有人说"LSTM 有三道门"的时候,指的是 2000 年的改进版,不是 1997 年的原版。原始 LSTM 只有输入门和输出门,缺少遗忘门意味着细胞状态只能积累信息,无法主动清空——这在某些任务上是个问题。
一个真正完整的技术,往往不是在最初发表的论文里就定型的,而是在随后的迭代中逐步打磨成形。
7.7、GRU:把三道门变成两道门
LSTM 的设计是有效的,但也是复杂的——三道门、两个状态(隐状态和细胞状态)、大量参数。
2014 年,来自蒙特利尔大学的赵·克雷格·楚(Kyunghyun Cho)等人提出了门控循环单元(Gated Recurrent Unit,GRU),它是 LSTM 的一个简化版本。

图 7.3:GRU 结构图,GRU 的更新门 ≈ LSTM 的遗忘门 + 输入门(反向);GRU 的重置门类似 LSTM 的输入门。LSTM 使用的参数量约为 GRU 的 1.5 倍。
GRU 的核心改动主要有如下三个方面:
- 合并细胞状态和隐状态为一个状态向量
- 合并遗忘门和输入门为一个更新门(Update Gate)
- 额外引入一个重置门(Reset Gate)
直觉上,更新门 ztz_tzt 决定"用多少新信息替换旧信息"(ztz_tzt 接近 1 → 大量更新;ztz_tzt 接近 0 → 保持旧状态);重置门 rtr_trt 决定"计算新候选状态时,旧隐状态参与多少"
那么,关于 GRU vs LSTM,我们应该怎么选?
两者的实验表现在大多数任务上非常接近。GRU 参数更少,训练更快,在数据量有限时往往更合适;LSTM 表达能力更强,在需要更精细记忆管理的任务上有时更好。工程实践中,没有一个通用的"GRU 更好"或"LSTM 更好"的结论——两者都是工具,选哪个取决于具体任务和资源限制。
今天来看,GRU 和 LSTM 都已经被 Transformer 大幅取代,它们的竞争本身已经不那么重要了。但 GRU 的设计思路——寻找必要的最小复杂度——是一种值得铭记的工程哲学。
7.8、Seq2Seq:两个 RNN 的接力
2014 年,循环网络领域发生了一个真正改变行业格局的事件:Ilya Sutskever、Oriol Vinyals 和 Quoc Le 在 Google Brain 发表了论文《Sequence to Sequence Learning with Neural Networks》,提出了 Seq2Seq 架构,在机器翻译任务上取得了当时最好的成绩。
7.8.1 机器翻译:一个持续几十年的硬问题
要理解 Seq2Seq 为什么重要,需要先了解机器翻译在此之前有多难。
机器翻译的研究几乎和 AI 一样古老。1954 年,IBM 和乔治城大学联合演示了一个能将 60 个俄语句子翻译成英语的系统,乐观地预测"五年内机器翻译问题将得到解决"。这个预测错得非常彻底——五年后,翻译质量仍然很差,以至于美国政府削减了这个领域的资金。
在此后几十年里,机器翻译走的是规则和统计结合的路:语言学家设计翻译规则,统计方法处理概率,系统被设计成短语的对应和拼接。这些系统确实有效,Google 翻译在 2014 年之前用的就是这类方法(统计机器翻译,SMT)。但它有明显的上限:每一种语言对需要单独设计,系统维护成本极高,而且对"非标准"句子经常产生滑稽的翻译结果。
Sutskever 等人的贡献,是用一个简洁、统一的神经网络框架,做出了可以和最好的 SMT 系统媲美的翻译质量——而且这个框架对所有语言对都是通用的。
7.8.2 编码器-解码器:两个 RNN 的接力
Seq2Seq 的核心架构是编码器-解码器(Encoder-Decoder):
编码器(Encoder):一个 LSTM(或 RNN),读取输入序列(比如中文句子),一个词一个词地处理,把整个句子的信息"压缩"进最后一个时间步的隐状态 hench_{\text{enc}}henc 中。这个最终的隐状态,被叫做上下文向量(Context Vector)——它是编码器对整个输入句子的理解,通常用一个固定大小的向量表示。
解码器(Decoder):另一个 LSTM,接收编码器的上下文向量作为初始隐状态,然后一个词一个词地生成输出序列(比如英语翻译)。每生成一个词,这个词又 被作为下一步的输入,直到生成结束符号。
形象地说:编码器负责"读懂",解码器负责"说出"。中间的上下文向量是两者之间传递的信息。
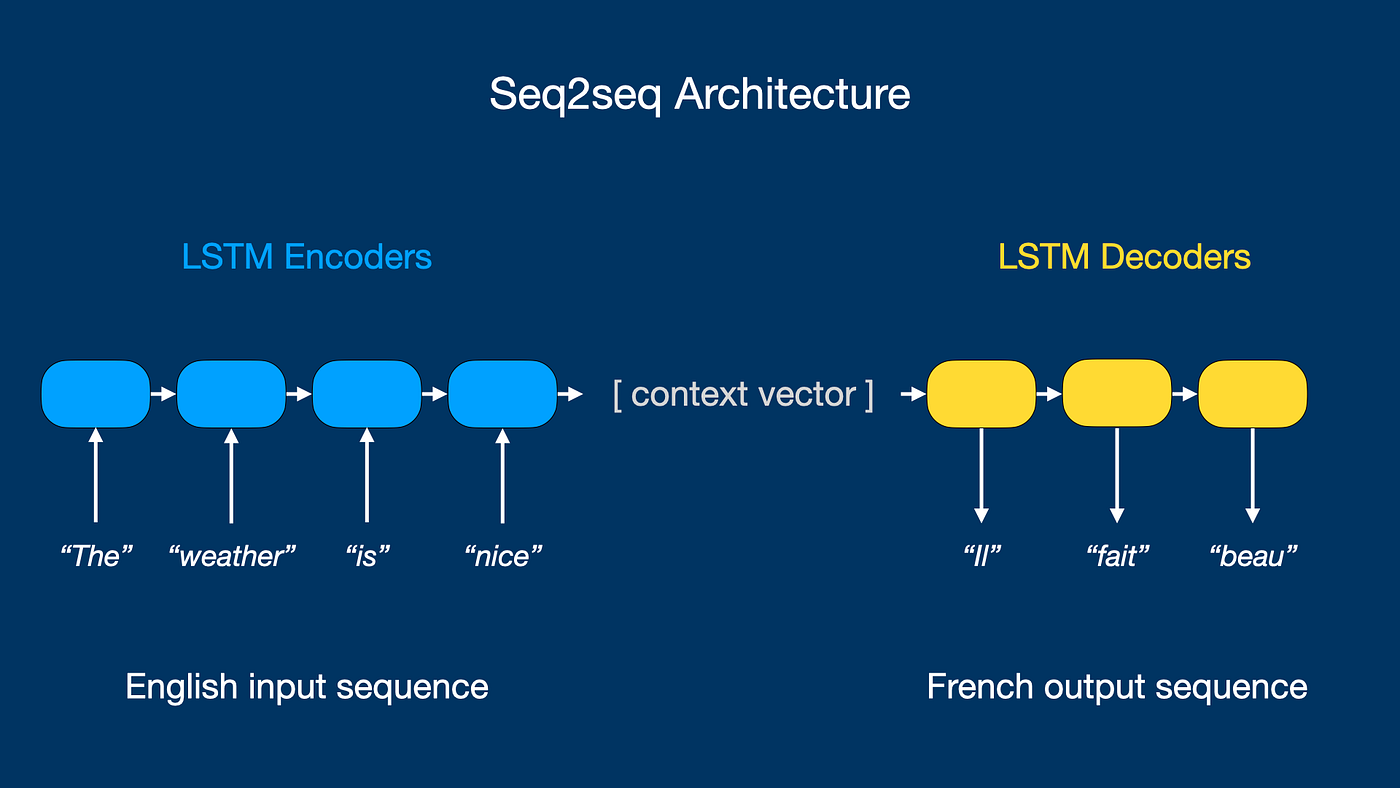
图 7.4:Seq2Seq 编码器-解码器架构。左侧是编码器(蓝色 LSTM 链),从左到右依次处理源语言词语(如 “The/weather/is/nice”),最后一个隐状态汇聚成"上下文向量"。右侧是解码器(黄色 LSTM 链),以上下文向量为初始隐状态,从左到右依次生成目标语言词语(如 “II/fait/beau”)。
7.8.3 高分实验结果
Sutskever 等人的论文发表时,机器翻译领域用 BLEU 分数(一种衡量翻译质量的标准指标,0-100)来评估系统。当时最好的 SMT 系统在 WMT’14 英法翻译数据集上能达到大约 33 BLEU 分。
而他们的 Seq2Seq 模型,达到了 34.8 BLEU 分——超过了经过十多年精心调优的最先进统计机器翻译系统。而且这是在没有使用任何专门的语言学知识的情况下做到的。
这个数字对机器翻译领域的影响是巨大的,Google 很快开始将神经机器翻译应用到实际产品中。两年后,2016年,Google 发布了 Google Neural Machine Translation(GNMT) 系统,宣布 Google 翻译全面切换到神经网络方法——翻译质量的单次提升幅度,超过了此前十年的总和。
此后,每当有人问"深度学习到底能做什么真实的、有价值的事",机器翻译都是一个无可辩驳的答案。
7.8.4 Seq2Seq 的威力:统一的框架
Seq2Seq 最深远的影响,不只是机器翻译。它提供了一个通用框架,用于所有"序列到序列"的任务:
- 机器翻译:源语言句子 → 目标语言句子
- 文本摘要:长文章 → 短摘要
- 对话系统:用户输入 → 系统回复
- 代码生成:自然语言描述 → 代码
- 语音识别:音频序列 → 文字序列
这种统一性本身就是一种美。在此之前,每一类任务都需要专门设计的架构和算法;Seq2Seq 之后,研究者们意识到,这些看似不同的任务,有一个共同的深层结构:读取一个序列,输出另一个序列。
这种统一性的背后,是一种令人激动的哲学:也许语言的处理,乃至更广泛的认知能力,都可以在一个统一的神经网络框架下描述和实现。这个想法,在后来的 Transformer 时代得到了更彻底的体现。
7.8.5 Teacher Forcing:训练捷径带来的隐患
Seq2Seq 的训练过程藏着一个微妙但重要的工程决策:解码器在训练时和推理时,工作方式并不相同。
推理时,解码器是自回归的——每步用自己上一步生成的词作为下一步的输入。如果第 3 步生成错了,第 4 步会在错误的基础上继续,错误从此累积。
如果训练时也这样做,会遇到一个效率问题:训练初期模型几乎什么都学不会,早期步骤的预测几乎都是错的,后续每一步都在"错上加错",梯度信号极其嘈杂,收敛极慢——就像一个学生从头到尾都在错误的知识框架上死磕,进步极慢。
1989 年,Williams 和 Zipser 提出了一个后来被广泛采用的训练技巧:Teacher Forcing(教师强制)。
所谓的教师强制规则其实很简单:训练时,无论上一步模型预测了什么,下一步的输入统一使用真实的目标词(Ground Truth)替换掉。就像一位严格的老师,每当学生答错,立刻给出正确答案并让他继续往下做——而不是让他在自己的错误上继续推演。
Teacher Forcing 大幅加速了训练收敛速度,成为 Seq2Seq 训练的标准做法。但它引入了一个长期困扰研究者的问题:曝光偏差(Exposure Bias)。
训练时,解码器每步都收到"完美的"前文;推理时,它只能依赖自己可能不完美的生成。两种情况的输入分布存在系统性差异——模型在训练中从未学过"如何从自己的错误中恢复",导致推理时小的早期错误被一路放大。
尽管后来研究者们提出了"计划采样(Scheduled Sampling)“作为缓解方案:训练过程中,以逐渐增大的概率,用模型自身输出代替真实词,让模型慢慢"断奶”。但这个问题直到 Transformer 出现才被从架构层面更彻底地规避——Transformer 的并行训练机制不需要 Teacher Forcing,天然避开了曝光偏差。
7.8.6 Beam Search:在指数级空间里进行高质量搜索
解码器每步要从几万个候选词中选一个。对于 20 步的序列,可能的输出组合达到 500002050000^{20}5000020——一个彻底无法穷举的天文数字。如何在这个搜索空间里找到最好的翻译结果?
贪心解码(Greedy Decoding):每步选当前概率最高的词。速度快,但容易陷入局部最优——某一步放弃了一个概率略低的词,而那个词可能开启了后续更顺畅的路径。
穷举搜索:计算所有可能序列的概率,选最高者。理论上最优,但实际计算上完全不可行。
Beam Search(束搜索) 是两者之间的实用折中。它维护一个大小为 kkk 的"候选序列集合"(“beam”),通常 k=4k=4k=4 或 k=8k=8k=8:
- 第 1 步:选概率最高的 kkk 个词,形成 kkk 条初始路径
- 第 ttt 步:对每条候选路径,扩展出所有可能的下一个词(k×Vk \times Vk×V 种候选),计算每条扩展路径的累积对数概率,保留前 kkk 条
- 所有路径生成结束符后,选择整体概率最高的那条
Beam Search 通过同时保持多条"看起来最有希望"的路径,避免贪心搜索的短视。实验上,k=4k=4k=4 比贪心解码平均提升约2-3个BLEU分,对翻译系统来说是显著的进步。
代价是推理时间增加到贪心解码的 kkk 倍。超过 k=8k=8k=8 之后,收益快速递减,而计算成本线性增加。k=4k=4k=4 到 k=8k=8k=8 是目前Seq2Seq系统的通行配置。

图 7.5:Beam Search 过程示意图,每次只选择最佳的前 2 个候选者进行后续扩展。
7.9、记忆的边界:Seq2Seq 的致命短板
然而,就在 Seq2Seq 大获成功的同时,一个根本性的缺陷开始暴露出来。
7.9.1 信息瓶颈:把百科全书压成一张便利贴
Seq2Seq 的设计要求编码器把整个输入序列的信息压缩进一个固定大小的向量。
对于短句子,这没什么问题——比如把"我爱你"翻译成"I love you",仅仅三个词的信息,一个小的上下文向量也可以装得下。
但当输入变长呢?想象你需要把一篇 500 词的技术文档翻译成另一种语言。编码器需要用同一个固定大小的向量(比如 512 维),存下所有 500 个词的信息:每个词的含义,每个词与上下文的关系,整体的逻辑结构……这就像要把一本书的全部内容写在一张便利贴上——不是摘要,是全部。
Bahdanau 等人(2014 年,与 Sutskever 的论文同年!)在他们的注意力机制论文里,用实验数据量化了这个问题:当句子长度超过 30 个词时,Seq2Seq 的翻译质量开始明显下降;当超过 50 个词时,质量已经大幅劣化。
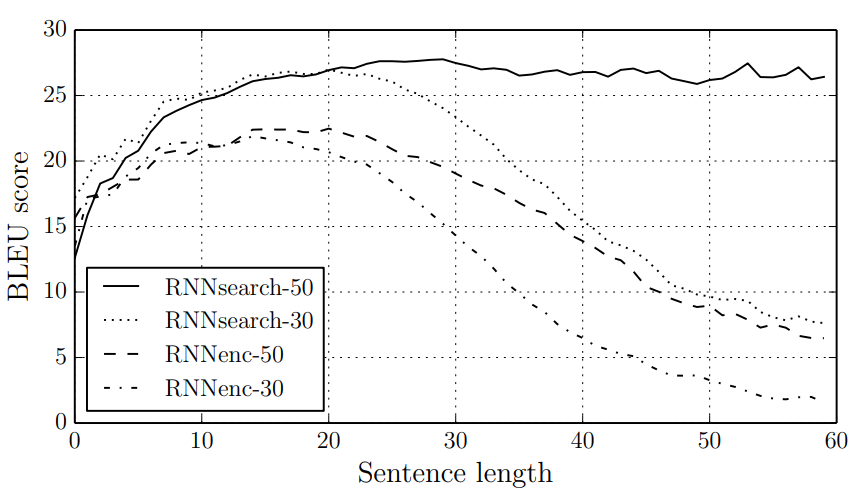
图 7.6:翻译质量随句子长度的变化,横轴是源语言句子长度(词数),纵轴是 BLEU 分数(翻译质量)。来源:Bahdanau et al., 2014 论文图 2。
7.9.2 无法并行:必须一步一步走
除了信息瓶颈,RNN 还有一个架构层面的根本限制:Seq2seq 的顺序结构导致其从根本上无法并行计算。
RNN 的本质是时间步上的顺序依赖——要计算第 ttt 步的隐状态,必须先完成第 t−1t-1t−1 步。要计算第 t−1t-1t−1 步,必须先完成第 t−2t-2t−2 步……这个依赖链意味着,RNN 在时间轴上只能串行执行,无法利用 GPU 的大规模并行计算能力。
在 2012 年深度学习革命的背景下,CNN 能大放异彩,很大程度上是因为它能高效利用 GPU——卷积操作天然并行。而 RNN 在这方面有根本性的劣势:不管 GPU 有多少核,RNN 在时间轴上只能一步一步前进。
这意味着,即使你有最强大的计算集群,一个需要处理 1000 步序列的 RNN,在时间轴上就是要走 1000 步,没有捷径。
对于工业级应用来说,这个限制是严重的。Google 翻译每天需要处理亿级的翻译请求,每一个请求的延迟都必须控制在几百毫秒以内。如果模型不能充分利用并行计算,无论准确率有多高,都很难在生产环境中部署。
7.9.3 长距离依赖的残留问题
即使 LSTM 在很大程度上缓解了梯度消失,它也没有完全解决超长距离依赖的问题。
在真实的语言中,信息的依赖关系有时会跨越整个段落。在一篇关于某人生平的文章里,开头提到的"他的童年经历"可能在最后才产生意义。在代码里,一个函数的定义和它的调用可能相距数百行。在对话系统里,用户在十轮之前提到的偏好,也可能会影响到当前的回答。
LSTM 的细胞状态虽然是一条"高速公路",但它仍然是单车道的——信息只能顺序传递,而且在每个时间步都可能被遗忘门部分清除。当序列足够长时,即使是最精心设计的 LSTM,也会面临"记忆容量"的上限。
7.10、工程实践:在序列数据上的炼丹术
在技术原理讨论清楚之后,真正的考验才刚刚开始。当工程师坐下来训练一个 Seq2Seq 翻译模型,他们面对的不只是论文里的公式,而是一系列需要在真实约束下做出决策的工程挑战——数据该如何处理、模型的优化该如何衡量、出现过拟合又该如何应对。这些问题,和模型架构设计同样重要。
7.10.1 序列数据的预处理:把不规则的语言变成规整的张量
神经网络训练需要批量处理,但语言有一个天生的"不整齐"的性质,句子长度各不相同。同一个批量里,有的句子 3 个词,有的 30 个词——如何把它们装进同一个矩阵中?
填充(Padding) 是最普遍使用的方案:把短句子用特殊符号(通常记为 <PAD>)补齐到当前 batch 中最长句子的长度。但填充会带来新的问题——模型不应该在 <PAD> 位置做有意义的计算,也不应该让 <PAD> 的损失参与梯度更新。实践中需要引入掩码(Mask) 机制:一个与序列等长的二值向量,告诉模型哪些位置是真实内容,哪些是填充。RNN 可以在遇到 <PAD> 时冻结隐状态,不再更新,这种技术叫动态序列长度处理。
截断(Truncation) 处理过长的序列:超过设定上限(比如 512 个词)的部分被截断。截断方式本身就是一个工程决策:从头部截?从尾部截?保留开头和结尾各一半?没有通用答案,要取决于具体的任务——摘要任务中文章的结论往往在结尾,那就应该优先保留尾部。
词汇表(Vocabulary)的构建:把文本词汇映射到整数索引。词汇表大小是关键超参数——太小,罕见词都被标记为未知词(<UNK>),丢失信息;太大,模型嵌入矩阵参数量会急剧增加。实践中,按词频降序排列,取前 30,000 到 100,000 个高频词,其余视为 <UNK>,是主流做法。
分词(Tokenization):中文处理需要先分词(词边界不明显);英文可以按空格切词,但有更精细的选择。字节对编码(Byte-Pair Encoding,BPE) 把词切分成更小的子词单元(如"unhappy" → “un” + “happy”),使词汇表可控的同时,大幅减少未知词问题。BPE 后来成为 GPT 等大模型的标准分词策略。
7.10.2 困惑度:语言模型的度量衡
评估机器翻译的质量,通常使用 BLEU 分数,评估语言模型(预测下一个词的任务,是 LSTM 最自然的应用场景之一)的质量,标准指标是困惑度(Perplexity,PPL)。
困惑度的直觉是,一个好的语言模型,应该对测试文本中实际出现的词汇给出高概率——模型越"不困惑",说明它的预测越准确。
数学上,困惑度是平均每词"不确定性"的度量:
PPL=exp(−1N∑i=1NlogP(wi∣w1,…,wi−1))\text{PPL} = \exp\left(-\frac{1}{N}\sum_{i=1}^{N} \log P(w_i \mid w_1, \ldots, w_{i-1})\right)PPL=exp(−N1i=1∑NlogP(wi∣w1,…,wi−1))
困惑度越低,模型越好。一个困惑度为 100 的模型,大约意味着在预测每个词时,模型等效地在 100 个词之间"犹豫";完全随机猜测的困惑度等于词汇表大小(几万);人类水平的语言模型困惑度大约在 20-50 之间(取决于领域和任务)。
实际训练中,困惑度是追踪语言模型训练进展的核心日志指标。当我们看到 PPL 从 3000 下降到500,再到 100,意味着模型正在从"几乎随机"逐步收敛到"有意义的语言理解"。困惑度对学习率、模型大小等超参数的变化非常敏感,是调参时最重要的监控信号之一。
7.10.3 RNN 中的 Dropout:为什么不能直接用标准方法
在第六章中,我们提到 Dropout 是深度学习中最有效的正则化手段之一——训练时随机"断开"一部分神经元。RNN 同样面临过拟合问题,同样需要正则化,但标准 Dropout 直接应用在 RNN 的时间步之间,会造成严重的性能损害。
原因在于 Dropout 在时间步之间的"随机性"破坏了 RNN 的核心机制:每一步丢弃不同的维度,意味着隐状态在时间轴上传递的信息被不同模式的随机噪声干扰,模型无法学到稳定的长期依赖——而这正是 RNN 设计的出发点。实验证实,在时间步之间施加标准 Dropout,LSTM 的性能会大幅下降。
而正确的做法是采用变分 Dropout(Variational Dropout),由 Gal 和 Ghahramani 在 2016 年提出,核心思路是在同一条序列的所有时间步,使用相同的 Dropout 掩码。每条序列开始时随机生成一次掩码(决定哪些维度被关闭),然后在这条序列的所有时间步里,同一组维度始终保持关闭状态。
这样,Dropout 的噪声在时间维度上是一致的,不会破坏 RNN 传递信息的能力——被关闭的那些维度在整条序列里始终缺席,网络学会在其余维度上完成任务;同时,随机性依然存在(不同序列、不同训练步骤用不同的掩码),正则化效果得以保留。
PyTorch 的 LSTM 内建的 dropout 参数采用了类似策略,但仅在层间连接上施加(不在时间步间施加),这是目前最常见的工程配置。
7.10.4 超参数的炼丹现场
在训练 LSTM 时,没有现成的公式告诉我们应该该选什么样的超参数。但整个社区的工程师们还是积累了众多的工程经验:
隐状态维度:越大模型容量越强,但参数量和计算量成平方级增长(WhhW_{hh}Whh 是 hidden_size × hidden_size 的矩阵)。简单任务用 256 或 512;复杂任务(如机器翻译)用 1024 或 2048。选太大容易过拟合,选太小欠拟合——在没有大量数据的情况下,宁小勿大。
序列最大长度:分析训练数据的长度分布,选择覆盖 95% 以上样本的长度作为上限。设置过长,填充比例高,大量计算浪费在 <PAD> 上;设置过短,截断丢失信息,尤其对长文本任务影响严重。
批大小:RNN 的一个特殊挑战是,一个 batch 里每条序列的所有时间步都必须同时加载进显存,内存消耗比前馈网络更敏感。在序列很长的情况下,可能需要用梯度累积 来模拟更大的有效批大小——每 NNN 步才做一次参数更新,但梯度在这 NNN 步里持续累积。
Dropout 率:通常在 0.2-0.5 之间。数据充足时可以用较小的值(0.2-0.3),数据少时需要更强的正则化(0.3-0.5)。经验规则是可以先不加 Dropout 观察模型是否可以收敛,当确认可以达到过拟合是,再考虑添加 Dropout 观察验证集损失的改善。
这些超参数之间存在复杂的相互作用——改变隐状态维度会影响过拟合程度,进而影响最优 Dropout 率的选择。没有一次性找到完美配置的捷径,只有系统的消融实验(Ablation Study):每次只改变一个变量,记录其对验证集困惑度或 BLEU 分的影响,逐步收敛到相对最优的配置。
7.11、两条新路
2014 年,面对 Seq2Seq 的信息瓶颈,研究者们几乎同时想到了同一个方向:解码器不应该只依赖一个压缩的上下文向量,而应该能够"回头看"编码器的所有中间状态。
这个想法,就是注意力机制(Attention Mechanism)——下一章的主角。
同样在 2014 年,另一组研究者开始从另一个角度思考:既然 RNN 的问题根源在于它的顺序结构,有没有可能完全抛弃循环,设计一种不依赖时间顺序也能处理序列的架构?
这个问题的最终答案,来自 2017 年——那就是 Transformer。
但在那之前,有一个更直接、更优雅的过渡:先给 RNN 装上"注意力之眼",让它在每一步都能主动查阅之前的所有信息,而不是依赖一个越来越模糊的"记忆"。
这个"注意力之眼",是接下来整个 NLP 革命的关键前置发明。它来自一个直觉:人在翻译一句话的时候,是有"选择性关注"的——翻译"猫"这个词时,你会重点看源语言中和猫有关的词,而不是平均关注所有词。这种"按需提取,而非压缩储存"的机制,正是打破信息瓶颈的钥匙。
7.12、知识自检
读完本章,你应该能做到:
- 用三句话向非技术朋友解释 RNN 是如何处理序列的,以及为什么普通 RNN 会"忘事"
- 解释为什么独热编码不足以表示词语的语义,以及 Word2Vec 用什么训练任务学到了词的分布式表示
- 用"King - Man + Woman = Queen"这个例子说明词向量的语义几何性质
- 画出 LSTM 三道门(遗忘门、输入门、输出门)的示意图,并说出每道门做什么决定
- 解释 Seq2Seq 的编码器-解码器结构,以及中间的"上下文向量"是什么
- 说出 LSTM 相比普通 RNN 在处理梯度消失问题上的核心改进(加法更新 vs 乘法更新)
- 指出 Seq2Seq 的两个主要局限(信息瓶颈 + 无法并行),并解释为什么这两个问题"在当前框架内很难解决"
- 解释 Word2Vec 的根本局限(一词一向量),以及这个局限为什么成为了后来 ELMo 和 BERT 的直接动机
- 说明双向RNN(BiLSTM)比单向RNN多了什么信息,以及为什么它不能用于生成任务的解码阶段
- 解释 Teacher Forcing 的做法、它带来的曝光偏差问题,以及为什么训练分布和推理分布不一致会导致性能下降
- 说明 Beam Search 比贪心解码的优势在哪里,以及 kkk 值如何影响搜索质量与计算成本的权衡
- 解释为什么标准 Dropout 不能直接用于RNN的时间步之间,以及变分Dropout的解决思路
- 用"困惑度"这个指标解释:一个困惑度为100的语言模型,意味着什么
7.13、常见误解
❌ “Word2Vec 学到的词向量能处理多义词,因为它从大量文本里训练”
✅ 实际上:Word2Vec 给每个词只分配一个固定向量,无论上下文如何。"苹果"在"吃苹果"和"苹果公司"里的向量是完全相同的。这是 Word2Vec 的根本局限。ELMo(2018)和 BERT(2018)的核心创新正是用上下文相关的模型动态生成词向量,同一个词在不同句子里得到不同的向量。
❌ “LSTM 完全解决了梯度消失问题”
✅ 实际上:LSTM 的细胞状态通过加法更新缓解了梯度消失,但并没有完全消除。在超长序列(数百步以上),梯度仍然可能消失。LSTM 的改进是让网络能自适应地控制梯度流,而不是强制保持梯度不变。
❌ “RNN 和 LSTM 现在已经完全没用了,被 Transformer 取代了”
✅ 实际上:Transformer 在大多数 NLP 任务上确实超越了 RNN/LSTM,但循环网络在某些场景仍有优势:序列长度极长时内存更高效,需要流式处理(streaming)的场景中,以及某些时序预测任务里,RNN 仍是常用选择。技术的"取代"很少是 100% 的。
❌ “Seq2Seq 就是把两个神经网络串联起来,这不是什么新想法”
✅ 实际上:Seq2Seq 的关键创新不是"两个网络串联",而是提供了一个统一的端到端训练框架,能在没有任何语言学先验知识的情况下,直接从平行语料中学习翻译。这个框架能应用于所有"序列到序列"的任务,是真正意义上的范式转变。
❌ “LSTM 的遗忘门名字很直白,它负责’忘记’不重要的信息”
✅ 实际上:遗忘门控制的是"保留多少之前的细胞状态",而不是主动"识别并删除不重要信息"。当遗忘门输出接近 0 时,细胞状态被清空;接近 1 时,细胞状态被完整保留。它更像一个"保留程度"的旋钮,而不是一个"智能垃圾回收器"。
❌ “Seq2Seq 发明之前,机器翻译根本不能用”
✅ 实际上:基于统计的机器翻译(SMT)在 2014 年已经是相当成熟的工业技术,Google 翻译等产品都在使用。Seq2Seq 的贡献是用神经网络框架超越了精心调优的 SMT,而不是从零开始的突破。
❌ “Teacher Forcing 是训练技巧,不影响模型本身,所以可以放心用”
✅ 实际上:Teacher Forcing 引入了曝光偏差(Exposure Bias)——训练时模型总是接到正确的前文,推理时只能依赖自身输出,两种输入分布存在系统性差异。这会导致推理时早期错误被逐步放大,序列越长,差距越明显。Teacher Forcing 提升训练效率,但有真实的推理代价,并非无损的优化。
❌ “Beam Search 的 kkk 值越大,翻译结果一定越好”
✅ 实际上:kkk 值增大确实能提升译文质量,但收益快速递减。研究表明,kkk 从 1 增到 4 或 8 时提升显著,再往上几乎没有改善,但计算成本线性增加。而且过大的 kkk 有时反而导致"翻译过于保守"——Beam Search 倾向于选择高频、平庸的措辞,而非精准但罕见的表达。Nucleus Sampling 等更新的解码策略,正是为了解决这个问题。
❌ “在 RNN 上用 Dropout 就和普通前馈网络一样,随机关掉一些神经元即可”
✅ 实际上:在时间步之间随机施加 Dropout,会破坏 RNN 在时间轴上传递信息的能力——因为每步被关闭的维度不同,隐状态传递出现随机性断裂,长期依赖无法稳定学习。正确做法是变分 Dropout:同一条序列的所有时间步使用相同的掩码,只在不同序列之间引入随机性,保留了 Dropout 的正则化效果,又不破坏时间维度的信息传递。
本章关键词
| 词汇 | 简明定义 |
|---|---|
| 独热编码(One-Hot Encoding) | 用词汇表大小的稀疏向量表示词,缺少语义信息且维度极高 |
| 分布式表示(Distributed Representation) | 用低维稠密向量表示词,语义相似的词在向量空间中距离更近 |
| 词嵌入(Word Embedding) | 通过训练学到的词的低维稠密向量表示,包含语义和句法信息 |
| Word2Vec | 通过 CBOW 或 Skip-gram 任务训练词向量的方法,由 Mikolov 等人于 2013 年提出 |
| GloVe | 基于全局词共现统计训练词向量的方法,斯坦福大学 2014 年提出 |
| 循环神经网络(RNN) | 通过在时间步之间传递隐状态来处理序列数据的神经网络,每步权重共享 |
| 隐状态(Hidden State) | RNN 在每个时间步维护的"记忆"向量,携带截止到当前步的历史信息 |
| 梯度消失(Vanishing Gradient) | 梯度在反向传播过程中随时间步呈指数衰减,导致早期输入对训练几乎没有影响 |
| 随时间反向传播(BPTT) | 在展开的 RNN 中计算梯度的算法,梯度需要沿时间轴反向传播 |
| 长短期记忆(LSTM) | 通过三道门和细胞状态解决梯度消失问题的 RNN 变体,由 Hochreiter & Schmidhuber 于 1997 年提出 |
| 遗忘门(Forget Gate) | LSTM 中控制"上一时刻细胞状态保留多少"的门控机制 |
| 输入门(Input Gate) | LSTM 中控制"新信息以多大程度写入细胞状态"的门控机制 |
| 输出门(Output Gate) | LSTM 中控制"细胞状态有多少输出为当前隐状态"的门控机制 |
| 细胞状态(Cell State) | LSTM 中独立于隐状态的长期记忆通道,通过加法更新保持梯度流畅 |
| 门控循环单元(GRU) | 使用两道门的 LSTM 简化版,参数更少,计算更快 |
| Seq2Seq | 编码器-解码器架构,用于将一个序列映射到另一个序列,由 Sutskever 等人于 2014 年提出 |
| 编码器(Encoder) | Seq2Seq 中读取输入序列并压缩为上下文向量的 RNN |
| 解码器(Decoder) | Seq2Seq 中从上下文向量出发逐步生成输出序列的 RNN |
| 上下文向量(Context Vector) | 编码器最后一步的隐状态,代表整个输入序列的压缩表示,也是 Seq2Seq 的信息瓶颈所在 |
| 信息瓶颈(Information Bottleneck) | Seq2Seq 中整个输入被压缩成一个固定大小向量的结构限制,导致长序列翻译质量下降 |
| 双向RNN(Bidirectional RNN) | 同时训练正向和反向两个RNN,每个位置的表示同时包含前文和后文信息,适合分类和标注任务 |
| Teacher Forcing | 训练Seq2Seq时,用真实目标词而非模型自身预测词作为下一步输入,加速收敛但引入曝光偏差 |
| 曝光偏差(Exposure Bias) | Teacher Forcing导致的训练与推理分布不一致:训练时接受完美前文,推理时依赖自身输出 |
| 贪心解码(Greedy Decoding) | 每步选择当前概率最高的词,速度快但容易陷入局部最优 |
| 束搜索(Beam Search) | 维护 kkk 条候选路径的解码策略,比贪心解码更全局,比穷举搜索更可行 |
| 困惑度(Perplexity,PPL) | 语言模型质量的评估指标,反映模型对测试文本每个词的平均预测不确定性,越低越好 |
| 变分Dropout(Variational Dropout) | 对RNN每条序列所有时间步使用相同掩码的Dropout变体,避免破坏时间维度的信息传递 |
| 填充(Padding) | 用特殊符号将短序列补齐至batch内最长序列的长度,配合掩码使用 |
| 梯度裁剪(Gradient Clipping) | 在参数更新前限制梯度范数上限,防止梯度爆炸导致训练崩溃 |
延伸阅读
- 必读:Mikolov, T. 等(2013). “Efficient Estimation of Word Representations in Vector Space.” arXiv:1301.3781. — Word2Vec 原始论文,词向量革命的起点,语义算术的第一次展示
- 必读:Hochreiter, S., & Schmidhuber, J. (1997). Long Short-Term Memory. Neural Computation, 9(8), 1735-1780. — LSTM 原始论文,虽然数学符号密集,但第1-3节的动机阐述极为清晰。
- 必读:Sutskever, I., Vinyals, O., & Le, Q. V. (2014). Sequence to Sequence Learning with Neural Networks. NeurIPS 2014. — Seq2Seq 原论文,13页,可读性很强。
- 推荐:Cho, K., et al. (2014). Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. EMNLP 2014. — GRU 提出的论文,同时也是编码器-解码器架构的独立提出(与 Sutskever 同年)。
- 推荐:Karpathy, A. (2015). The Unreasonable Effectiveness of Recurrent Neural Networks. [博客文章] — 用 LSTM 生成莎士比亚风格文本、代码、维基百科文章等有趣实验,直观展示 LSTM 学到了什么。
- 推荐:Olah, C. (2015), Understanding LSTM Networks [博客文章] — 图解 LSTM 三门结构图,非常适合初学者进行学习。
- 深入:Gers, F. A., Schmidhuber, J., & Cummins, F. (2000). Learning to Forget: Continual Prediction with LSTM. Neural Computation, 12(10), 2451-2471. — 引入遗忘门的论文,完善了现代 LSTM 的三门设计。
[!tip]
下一章预告:信息瓶颈是 Seq2Seq 的阿喀琉斯之踵——把整个句子压进一个向量,翻译长句时质量急剧下滑。2014 年,Bahdanau 等人提出了一个简单得令人拍案叫绝的想法:解码的每一步,都让模型"回头看"编码器的所有隐状态,让模型自己决定"此刻应该重点关注哪些输入"。这就是注意力机制——而它的出现,将彻底改写深度学习的走向。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)