ENHANCING PERSONA FOLLOWING AT DECODINGTIME VIA DYNAMIC IMPORTANCE ESTIMATION FORROLE-PLAYING AGENTS
1 论文介绍
关于人格动态的心理学研究,包括 认知—情感人格系统理论,已经表明:人的行为并不是由固定人格静态决定的,而是由特定场景下被激活的人格属性所产生的。
与此类似,大语言模型也应该能够在不同上下文场景中,动态识别哪些人设属性与当前场景相关,并在生成时遵循预先定义的人设档案。作者将这种能力称为 Persona Following,即“人设遵循能力”。
现有的人设遵循方法主要可以分为两类:非参数化学习方法和参数化训练方法。
非参数化方法包括直接提示、上下文学习,以及检索增强生成(RAG)
这类方法的核心机制依赖于模型对 prompt 文本的语义识别,模型往往无法真正深入理解输入中包含的人设属性。因此,它们不能根据具体场景动态调整行为模式或偏好表达。这一根本限制阻碍了智能体在交互过程中实现真正的动态人设遵循。
为了解决这些问题,参数化方法通常通过监督微调或 LoRA,在大规模整理好的语料上优化模型,例如角色对话数据,从而增强模型的人设遵循能力。但是,这些方法需要大量计算资源和标注数据。
为了解决现有方法的局限,作者提出了 Persona Dynamic Decoding,PDD,即“人设动态解码”。这是一种推理阶段的人设遵循框架,能够根据不同场景动态调整人设属性的重要性,并且在不进行任何微调的情况下引导模型生成。
PDD 包含两个关键组成部分:
- Persona Importance Estimation,PIE,即人设重要性估计模块。它能够在不同场景下自适应地量化各个人设属性的重要性。
- Persona-Guided Inference-Time Alignment,PIA,即人设引导的推理时对齐范式。它将 PIE 估计得到的重要性分数加入奖励函数中,用这个奖励函数调节模型输出,从而在推理阶段使模型与目标人设对齐。
2 相关工作
2.1 Role-Playing Language Agents
大语言模型的发展显著推动了角色扮演语言智能体的兴起。这类智能体能够模拟某个角色的情绪、行为和语气,并允许用户自由定制角色进行交互,因此吸引了学术界和工业界的广泛关注,例如 Glow 和 Character.AI 等应用。
为了提升角色扮演性能,已有方法通常利用高质量的角色专属对话数据,采用训练方法或提示方法来实现。早期研究主要通过 prompt engineering,利用大语言模型的指令遵循能力和知识获取能力,在提示中加入特定角色档案或少量示例,从而引导模型进行角色扮演。
近期研究中,MMRole 将角色扮演场景扩展到了多模态领域;TimeChara 则通过创新性的提示设计,解决角色扮演语言智能体中的时空幻觉问题。
为了通过参数化训练实现角色定制,一些专用大语言模型通过整合多种来源的数据构建而成,包括文学作品抽取、LLM 合成对话和人工标注等。Neeko 使用 LoRA 微调来实现特定角色扮演。近期还有一些工作通过激活干预优化方法进一步增强人格特质。
然而,现有方法主要依赖大量训练数据和计算资源来优化角色扮演表现,仍然难以实现上下文自适应和真正的人设遵循。
2.2 Inference-Time Alignment
早期基于奖励模型的研究已经证明,解码阶段算法对于可控文本生成是有效的。在生成与人物属性对齐的输出任务中,近期工作进一步探索了 token 级个性化奖励,用来根据个体偏好调整基础模型的预测结果。
总体而言,已有的解码阶段对齐工作主要关注如何使模型与特定用户偏好对齐;而本文的方法则将角色扮演语言智能体中定义的多个人设属性视为多个对齐目标。作者构建了一个多目标奖励函数,从而实现由人设引导的推理时对齐。
3 方法
主要包括两个部分:Persona Importance Estimation,PIE,即人设重要性估计模块;以及 Persona-Guided Inference-Time Alignment,PIA,即人设引导的推理时对齐范式。
给定一个场景上下文 C,一个包含多个人设属性的角色人设集合:,以及一个用户问题
x,PIE 会估计每个人设属性 对当前场景的贡献程度
。随后,PIA 利用这些重要性分数来解决多重人设属性对齐问题,引导大语言模型
在推理阶段生成一个忠实符合角色人设的回答
y。
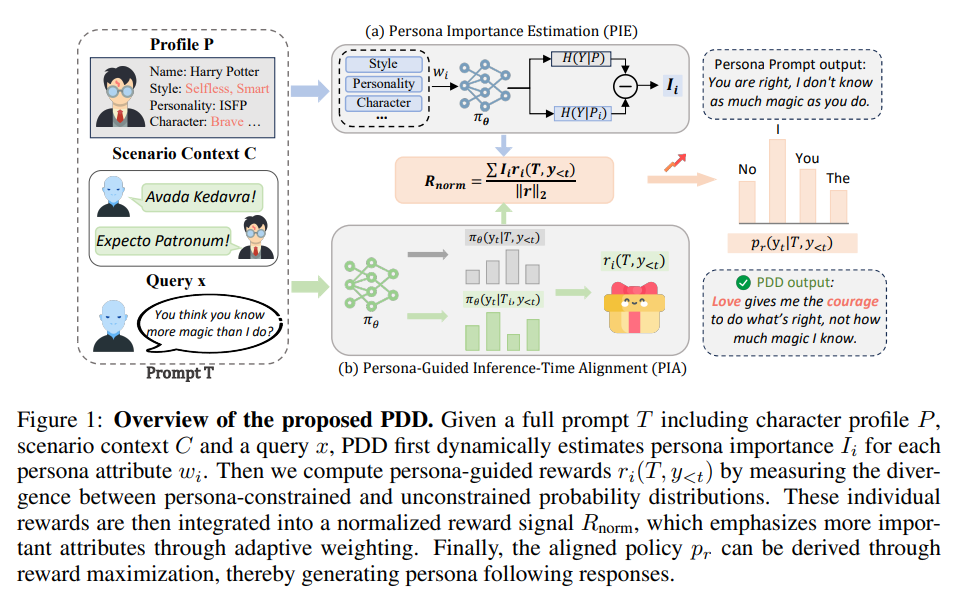
3.1 自监督人设重要性估计(PIE)
标准语言模型生成概率
给定完整提示:
其中包含其中包含场景上下文 、角色人设集合
和用户问题
。大语言模型
生成一个回答:
这个回答的整体生成概率可以表示为每一个 token 条件概率的连乘:
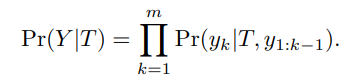
也就是说,生成整句话的概率等于模型每一步生成下一个 token 的概率相乘。
用条件互信息衡量属性贡献
根据信息论,某个特定人设属性 对输出
的贡献,可以通过它与输出
之间的条件互信息来衡量:
![]()
其中 ,表示从完整 prompt
中去掉第
个人设属性
后得到的提示。
:表示在缺少属性
的情况下,生成输出
的不确定性。
,
等价于
,表示在完整 prompt 下生成输出
Y 的不确定性。
衡量加上属性
后,模型对输出
Y的不确定性减少了多少。也就是说
很大、
较小,
很大,说明这个属性很重要
命题 3.1:假设存在一个标准答案 GT,它代表了一个满足人设要求的输出。那么,条件熵可以近似为:![]()
于是,公式 2 可以被近似为: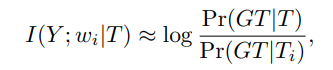
基于上述推导,人设重要性可以定义为: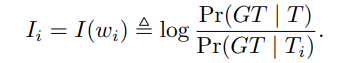
原本的条件熵:
于是作者用一个代表性输出GT来近似整个分布
也就是说GT是一个符合该人设的标准回答,看这个标准回答在“完整人设”和“缺少某属性”的条件下概率差多少。
这也带来了一个挑战:标准答案通常不可得
命题 3.2:令 G 表示模型在完整 prompt T 下生成的回答,令 GT 表示潜在但不可获得的标准答案。作者提出,可以使用模型生成的回答 G 来近似 GT。
Remark:为什么用 G 代替 GT 是合理的?
令 I_true 表示由标准答案 GT 计算得到的重要性,令 I_model 表示由模型生成回答 G 计算得到的重要性。如果模型生成 G 和生成 GT 的概率是正相关的,那么 I_model 就可以作为 I_true 差异的可靠代替。
模型自己生成的回答虽然不一定完美,但它通常和合理答案有一定相关性。
如果一个属性对“正确角色回答”重要,那么它通常也会影响模型当前生成的角色回答。所以用
G来替代GT,虽然不是完美,但可以得到一个可用的重要性排序。
最终公式:令G = πθ(T),即 G 是模型在完整 prompt T 下生成的回答。该方法能够在不需要标准答案的情况下,根据当前场景 C 自适应地、具有理论基础且实践可靠地量化人设重要性:
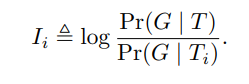
完整流程:
1. 输入完整 prompt T = {C, P, x}
2. 模型先生成一个回答 G
3. 对每个属性
构造去掉
4. 计算 G 在完整 prompt 下的概率
5. 计算 G 在去掉
6. 用二者比值的 log 作为属性重要性
3.2 人设引导的推理时对齐(PIA)
本节提出了一种新的、无需训练的、由人设引导的推理时对齐方法。
该方法可以迁移到不同角色上。作者首先形式化定义了多重人设属性对齐问题,然后将前面的人设重要性估计结果与奖励函数连接起来,从而推导出一种引导式解码算法,以确保模型在推理阶段能够遵循人设。
首先,作者定义了一个带有 KL 约束的强化学习目标,用于通过奖励函数调节模型行为,使其符合特定人设属性:
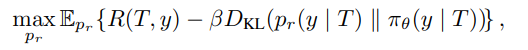
其中, 表示需要被对齐的原始生成模型分布,
表示对齐之后的模型分布,
是奖励函数,用来衡量完整
与生成结果
之间的偏好程度。
表示 KL 散度,
是一个正则化超参数。
这个公式想做的事:目标 = 人设奖励 - 偏离原模型的惩罚
优化一个新的生成分布
,这个分布要同时满足两个目标:人设奖励高,新的生成分布不能偏离原模型太远
- β 大,模型更保守,更接近原始模型。
- β 小,人设奖励影响更强,生成更容易被 persona 控制。
作者的目标是让智能体回答与角色档案 对齐。这等价于最大化未约束模型策略与由 P 约束后的策略之间的 KL 散度。因此,对于每个人设属性
,作者可以将 KL 项写成模型在 m 个生成步骤中预测结果的期望 log 比值:
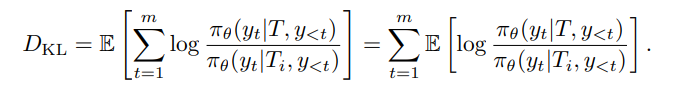 其中 TTT 是包含完整人设属性的 prompt,
其中 TTT 是包含完整人设属性的 prompt,是去掉第
个人设属性后的 prompt。
比较两种条件下模型生成同一个 token 的概率:
如果某个 token 在完整人设下概率更高,而在去掉某属性后概率变低,说明这个 token 很可能体现了这个属性。
接下来,作者利用上述分解,为每个人设属性 定义一个逐步的人设奖励:
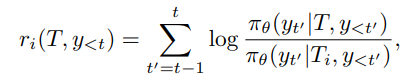
其中, 表示在包含人设属性
的完整 prompt 下,模型对下一个 token 的预测分布;
表示在去掉该属性后的 prompt 下,模型对下一个 token 的预测分布。
公式 9 就是把“完整属性”和“缺失属性”的概率差异变成 reward。
如果某个 token 在完整人设下更可能出现,
而在去掉某属性后不太可能出现,
那么这个 token 对应该属性的 reward 就高。
为了使角色档案中的多个人设属性都能与当前上下文对齐,作者提出了一个多目标策略对齐框架。基于传统多目标对齐方法,并考虑到不同属性在不同上下文中的优先级,作者引入了动态加权机制。
具体来说,作者为每个人设属性 分配一个人设重要性分数
,并使用这些分数构建一个加权奖励函数:
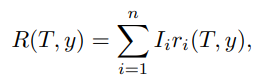
前面 PIE 得到:
表示每个属性当前有多重要。
PIA 中每个属性有自己的奖励:
于是总奖励就是:总奖励 = 属性重要性 × 属性奖励 的加权和
Challenge:直接加权奖励的问题
虽然这种加权方案可以实现多目标对齐,但它有一个关键局限:如果不加约束地优化,可能会推动所有 同时最大化,从而模糊不同目标之间的重要性层级,妨碍生成具有个性化、偏好感知的 Pareto 最优解。
上面的公式只是简单加权,如果只追求总奖励最大,模型可能会试图同时把所有属性都表现出来。
所以作者提出了归一化奖励,目的是保持重要性层级。
命题 3.3:作者提出一个归一化奖励函数,用来鼓励模型保持期望的人设属性排序,即如果 ,那么也希望
,从而保留不同对齐目标之间的优先级:
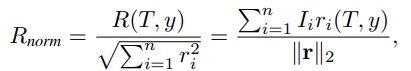
其中:r=[r1,r2,…,rn]T 表示各个人设属性奖励组成的向量。
不只是看 reward 总和大不大,而是看 reward 方向是否和重要性方向一致。
重要性向量和奖励向量方向接近,说明重要属性得到了更高奖励;不重要属性没有被过度强化。
如果 r 只是所有维度都很大,但方向不对,就不一定好。
根据柯西-施瓦茨不等式:
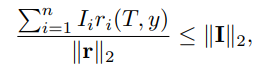
表示人设重要性分数向量。当且仅当 r 与 I 成比例时,即:r∝I 等号成立。
这意味着,最大化 会鼓励每个属性奖励
的排序与其重要性分数
保持一致,从而在人设对齐过程中显式保留人设属性的层级结构。
如果想让
最大,最好的情况是奖励向量 r 和重要性向量 I 方向一致。
基于上述定义,作者将多重人设属性对齐问题定义为:
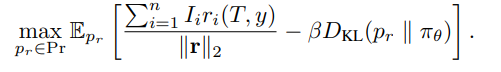
模型要在推理阶段最大化归一化的人设奖励,同时通过 KL 约束避免对齐后的分布过度偏离原始语言模型分布。
推理最优解
将前面定义的人设重要性分数和奖励函数代入公式 13 后,作者可以推导出在第 个时间步上的最优解
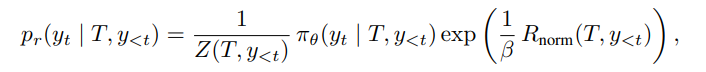
其中,分区函数定义为:
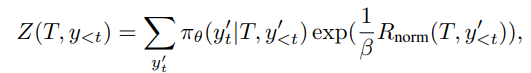
对齐后的 token 概率=
基础模型原本给这个 token 的概率
× 这个 token 符合当前重要人设属性的程度
÷ 所有候选 token 的总权重Z = 所有候选 token 的加权概率总和
某个 token 的最终概率 = 该 token 的加权分数 / 所有 token 的加权分数总和
PDD完整过程

- 输入:完整 prompt,包括场景上下文、人设属性和用户问题。
- 输出:模型生成的回答。
- 根据公式 6 计算每个人设属性的重要性分数。(PIE)
- 当生成序列尚未结束时,循环执行以下步骤。
- 计算完整人设约束下的下一个 token 概率分布。
- 对每一个人设属性
。
- 对奖励进行归一化,得到
- 根据公式 14 构造对齐后的生成策略。
- 从对齐后的概率分布中采样下一个 token,并将其加入生成序列。
- 返回最终生成回答
4 实验
4.1 实验设置
4.1.1 数据集
通用角色数据集
- CharacterEval:包含 1785 组多轮角色扮演对话,涉及 77 个来自中文小说和剧本的角色。
- BEYOND DIALOGUE:包含 280 个中文角色和 31 个英文角色,以及 3552 组基于场景的对话。
特定人格数据集
- PERSONALITYBENCH:评估模型遵循大五人格特质的能力,包含 180000 个开放式问题,专门设计用来探测大五人格的不同维度。
4.1.2 Baseline
- Simple Prompting,SP:简单提示方法,使用一个简单形容词来引导模型表现出不同人设。
- Persona Prompting,PP:人设提示方法,通过 prompt 输入详细的角色档案或人格设定,例如人物关系、背景等。
- In-context Learning,ICL:上下文学习,使用一组 few-shot 示例,引导模型生成更好的回答。
- NPTI:基于神经元的人格特质诱导方法。它通过识别与人格相关的神经元,并操控这些神经元的激活,从而使模型输出表现出相应的人格特质。
- OPAD:即时偏好对齐解码方法。它在推理过程中使模型输出与预定义的单一偏好目标对齐。
- PAS:训练一个探针,用来寻找与某种人格特质相关的注意力头,并在测试时利用这些注意力头调整模型人格表现。
- 闭源模型:GPT-4o 、 DeepSeek-R1
4.1.3 评价指标
LLM-as-a-Judge
将两组回答成对输入 GPT-4o,让 GPT-4o 判断 PDD 的回答相对于 baseline 的回答是否更好,并计算胜率。
Dataset-Specific Reward Models & Metrics
CharacterEval 提供了 CharacterRM,这是一个角色扮演奖励模型,可以从多个主观维度评价角色扮演语言智能体。作者选择了与人设遵循相关的指标,例如:PU:Persona-Utterance alignment
PB:Persona-Behavior alignment
在实际操作中,在 PIA 过程中,作者只对人设重要性最高的前两个属性进行对齐,以平衡人设忠实性和计算效率。
4.1.4 实现细节
实验在单张 NVIDIA L40S GPU 上完成。作者使用两个大语言模型作为基础模型:LLaMA-3-8B-Instruct和Qwen2.5-7B-Instruct
生成回答时采用贪婪解码,并将超参数 设置为 1.0。
在对齐目标选择方面,CharacterEval 和 BEYOND DIALOGUE 直接从角色档案中对单个属性进行评分;而 PERSONALITYBENCH 则从段落式人格描述中提取关键关键词用于评分。
4.2 主要结论
PIE模块评估
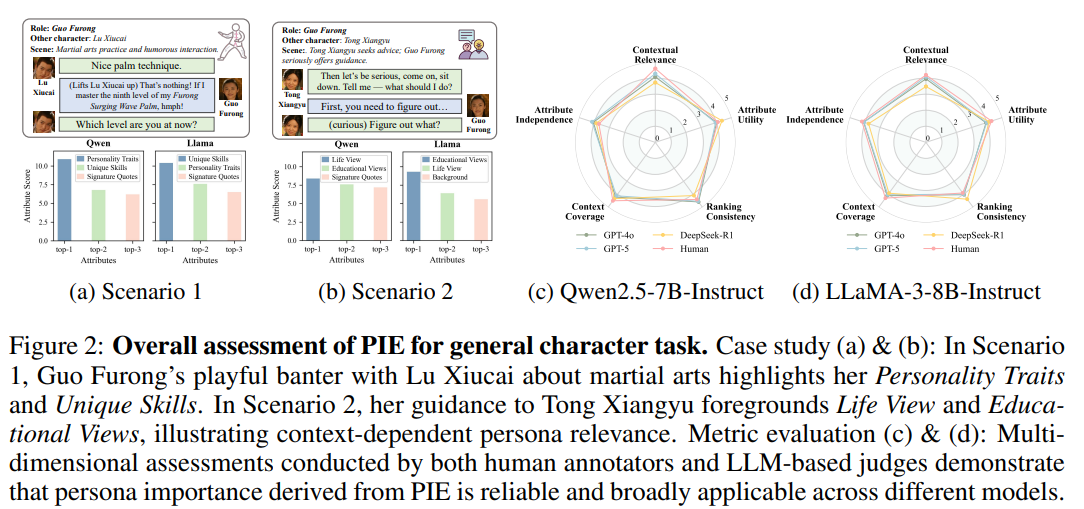
图 2(a):场景 1
角色:郭芙蓉
对话对象:吕秀才
场景:练武和幽默互动
- 吕秀才:好掌法。
- 郭芙蓉:那算什么!如果我练成第九重排山倒海掌,哼!
- 吕秀才:那你现在练到第几重了?
PIE 给出的 top-3 属性主要集中在:性格特征、特殊技能、标志性台词
图 2(b):场景 2
角色:郭芙蓉
对话对象:佟湘玉
场景:佟湘玉寻求建议,郭芙蓉认真指导
- 佟湘玉:那咱们认真说,来,坐下,告诉我该怎么办?
- 郭芙蓉:首先,你得弄清楚……
- 佟湘玉:弄清楚什么?
这个场景不是展示武功,而是展示郭芙蓉如何看待问题、如何给建议。因此 PIE 给出的重要属性更偏向:人生观、教育观、人物背景
这说明 PIE 能根据场景切换关注点。它们会给与当前上下文相关的人设属性分配更高权重,同时抑制与当前场景无关的属性。这验证了该方法的合理性和跨模型稳定性。
为了进一步验证 PIE 理论模块在实践中的有效性,作者引入了五个评价指标:
- Context Relevance(上下文相关性):排名靠前的人设属性应该与当前上下文密切相关。
- Attribute Utility(属性效用):排名靠前的人设属性应该能够增强角色在当前语境中的合理性或自然性。
- Context Coverage(上下文覆盖度):排名靠前的人设属性应该能够较广泛地覆盖当前上下文中的关键要素。
- Attribute Independence(属性区分度):排名靠前的人设属性应当在较大程度上彼此独立,从而避免冗余。
- Ranking Consistency(排序一致性):属性的整体排序应该与它们在当前上下文中的相关程度相一致。
作者使用了三个大语言模型作为评审器:DeepSeek-R1、GPT-4o、GPT-5
如图 2(c)(d) 所示,该方法在所有评价维度上都取得了持续较强且可接受的分数。这说明 PIE 能够通过捕捉模型输出与人设属性之间的相关性,可靠地估计人设重要性。
通用角色任务实验结果
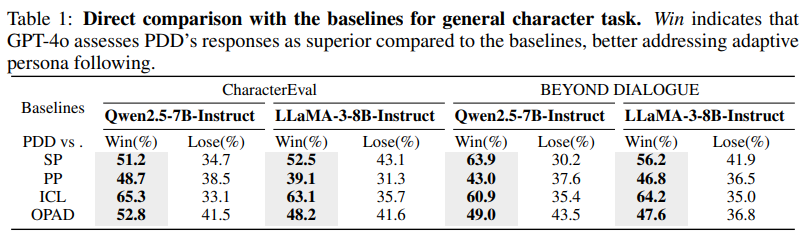
通用角色任务中与 baseline 的直接对比。Win 表示 GPT-4o 认为 PDD 的回答优于对应 baseline 的回答,即 PDD 能更好地实现自适应人设遵循。
可以看到在CharacterEval 和 BEYOND DIALOGUE上整体优于这些 baseline
CharacterEval 通用角色任务上的自动评价
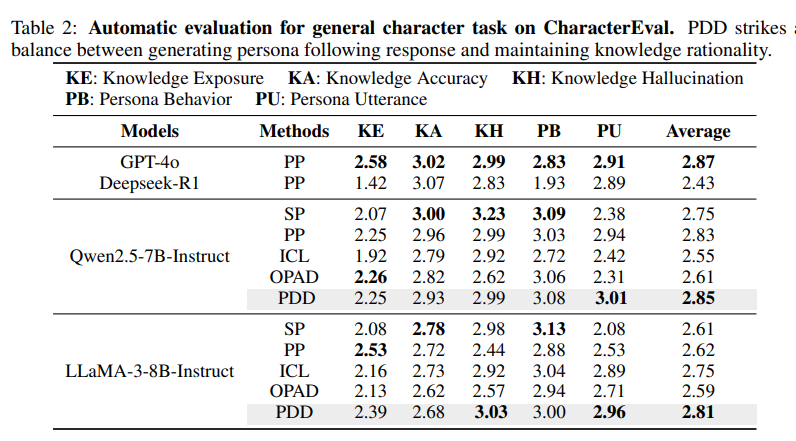
PDD 在各个单项指标上都位于前列,并且在两个基础模型上都取得了最高的平均分,体现出较强的鲁棒性。
Specific Personality 特定人格任务实验结果
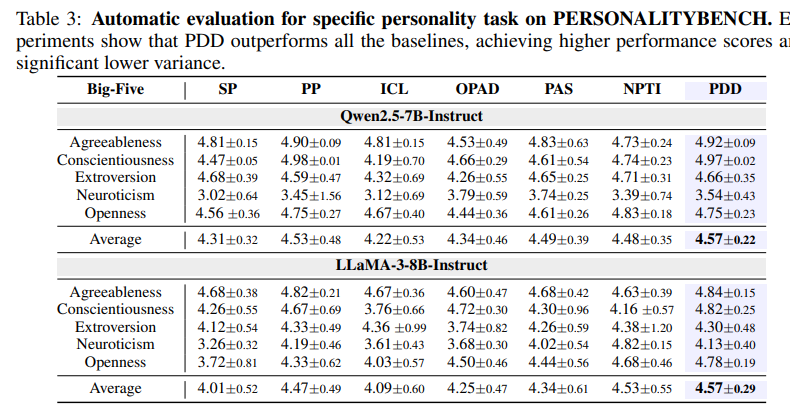
在 PERSONALITYBENCH 特定人格任务上的自动评价。实验表明,在五种不同人格特质上,PDD 都稳定地优于所有 baseline 方法,并且统计显著性达到 。PDD 获得了最高的平均分和最低的方差,这说明该方法具有较强的鲁棒性和可泛化的适应能力。
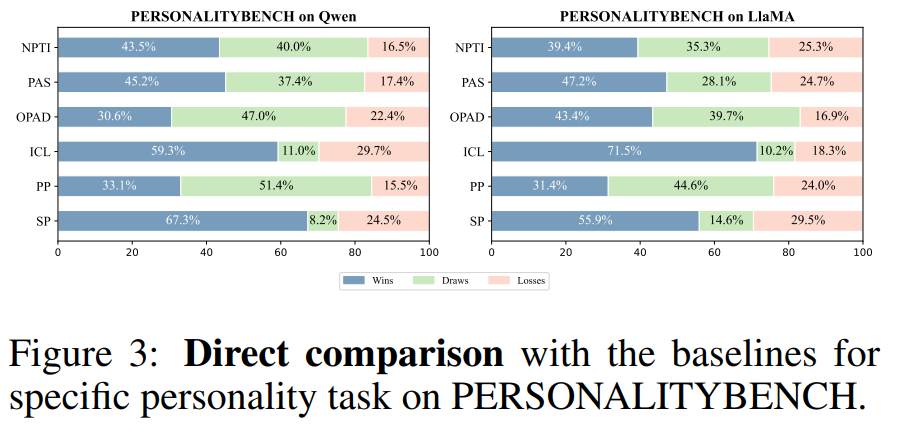
在 PERSONALITYBENCH 特定人格任务中与 baseline 的直接比较。
4.3 消融实验
消融实验主要验证三个设计
- Reward normalization 是否有效;
- 选择多少 persona attributes 最合适;
- PIE 是否依赖高质量初始生成 G。
奖励函数归一化是否有效
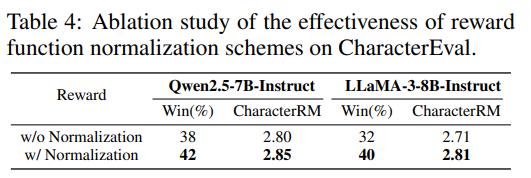
在 CharacterEval 上对奖励函数归一化方案有效性的消融实验。
奖励函数归一化能够生成更加忠实于指定人设配置的输出。通过引导模型优先关注显著的人设属性,而不是无差别地优化所有未归一化奖励,该方案提升了回答质量和一致性。
对齐属性数量的影响
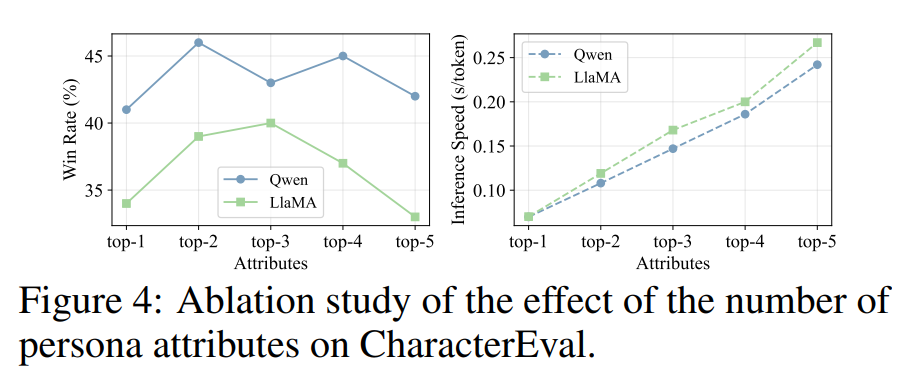
在多重人设属性对齐中,选择多少个对齐目标会对输出质量和计算效率产生关键影响。
从图中可以看到,在 CharacterEval 上不同属性数量下 对于
随着纳入的属性数量增加,模型性能一开始会提升;但是,如果加入过多属性,就会引入与当前上下文无关的噪声。同时,属性数量增加也会带来更高的计算开销,并放大数值不稳定性,最终导致性能下降。
关于 G 质量的影响。

作者基于 Qwen2.5-7B-Instruct,使用随机解码策略,例如 top-k sampling,故意降低模型生成回答 的质量,并进一步根据 CharacterRM 选出质量最低的样本。然后,作者基于这些退化后的输出重新计算 PIE 重要性分数,并使用两类方式进行评价:
- 第一,使用作者提出的人设重要性诊断指标;
- 第二,计算它与原始高质量估计结果之间的 Top-5 overlap。
如表 5 所示,即使 的质量显著降低,PIE 仍然保持了相当稳定的表现。诊断指标和 Top-5 重叠率都表明,PIE 仍然能够正确识别与上下文相关的关键人设属性,说明该方法对生成样本中的不完美具有较强鲁棒性。
使用了两种解码方法,Beam和Top-k,Beam 生成质量较高,Top-k 生成质量较低
从表中可以看到虽然Top-k 的生成质量更低,但 PIE 的大部分指标并没有大幅降低。
PIE 不强依赖一个完美的初始回答 G。
5 结论
在本文中,作者提出了 PDD,这是一种新的框架,用于在解码阶段,使角色扮演语言智能体在多样化上下文场景中与预先定义的人设档案保持一致。
PDD 将人设重要性与上下文信息进行解耦,从而使模型能够动态适应不同场景。
实验结果表明,PDD 优于现有角色扮演方法,并且在多角色人设和不同基础模型上都表现出较强的泛化能力。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)