04|Netty Pipeline 源码分析:从 IO 事件到业务 Handler 的责任链
04|Netty Pipeline 源码分析:从 IO 事件到业务 Handler 的责任链
Netty 最优雅的设计之一,就是:
ChannelPipeline
我学 Pipeline,不只是为了知道 Netty 里 channelRead 怎么传。
更重要的是,它给了我一个理解“网关类系统”的通用模型:
- 外部消息进入系统;
- 先经过协议边界;
- 再经过解析、过滤、业务消费、转发、防回环;
- 最后决定是否继续向下游传播。
在边缘侧和云端协同里,边缘侧有一个 MQTT Gateway,它很像一个边缘消息网关:
云端 MQTT Broker <-> 边缘侧 gateway <-> 本地 MQTT Broker / 内部服务
它不一定使用 Netty Pipeline,但它面对的问题和 Pipeline 很像:
- 消息从哪一侧进来?
- 是否需要先被 gateway 自己消费?
- 是否要转发到另一侧 MQTT?
- 如何避免消息从本地转云端后又被转回本地?
- 哪些 topic 要过滤?
- 哪些消息要打来源标记?
比如 gateway 中的 anti-loop 逻辑,会对特定 topic 做过滤,并在 JSON payload 里加入类似:
bridge_source = inner
这样的标记,避免双向 MQTT bridge 产生消息回环。
所以这一篇看 Netty Pipeline,我重点想补的是一种架构判断:
复杂链路不能只靠一个大方法处理,而应该被拆成方向明确、边界清楚、可组合的处理节点。
如果说 EventLoop 解决的是:
事件在哪里循环,线程如何调度。
那么 Pipeline 解决的是:
IO 事件如何一步步变成业务处理。
原生 NIO 中,Selector 告诉你 socket 可读以后,你需要自己做很多事:
- 读取 ByteBuffer
- 拆包
- 解码
- 执行业务逻辑
- 编码响应
- 写回 socket
- 处理异常
- 关闭连接
Netty 把这些步骤拆成一组 Handler,并用 Pipeline 串起来。
本文就从源码主线看清楚:
- ChannelPipeline 是什么?
- ChannelHandlerContext 是什么?
- inbound 和 outbound 怎么传播?
- 为什么 Pipeline 是 Netty 扩展能力的核心?
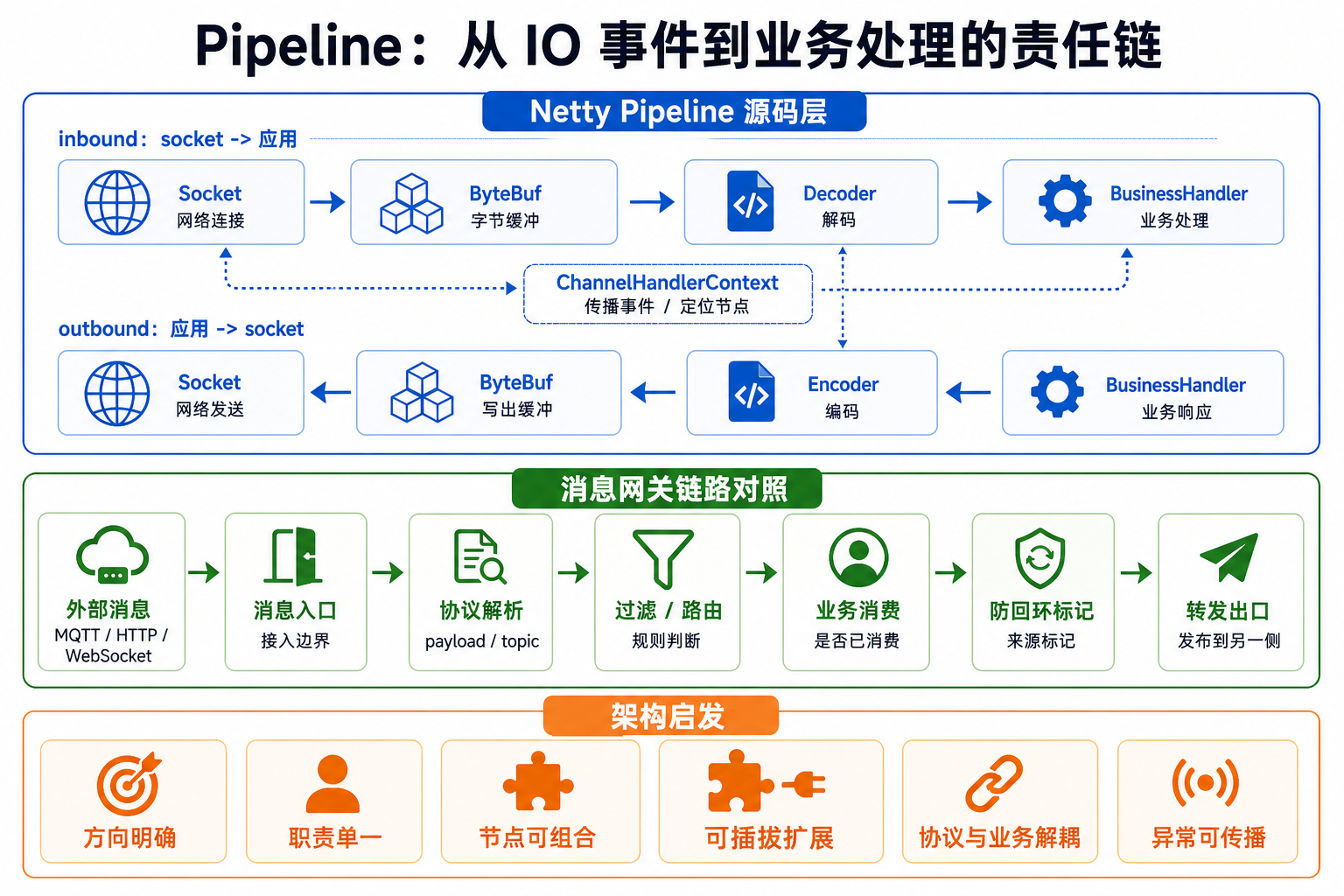
一、每个 Channel 都有一个 Pipeline
在 Netty 中,每个 Channel 都有一个自己的 Pipeline:
ChannelPipeline pipeline = channel.pipeline();
它可以理解为:
这个连接上的 IO 事件处理链。
比如一个简单的 HTTP 服务,Pipeline 可能是:
对于自定义协议,可能是:
同一个 Pipeline 里也可能有出站编码器,例如:
要注意,解码器和编码器可以在同一条 Pipeline 中,但 inbound 和 outbound 的传播方向不同。
Pipeline 的意义是:
把网络读写、协议编解码、业务逻辑拆开。
这就是 Netty 能支撑 HTTP、RPC、IM、自定义 TCP 协议的关键。
二、DefaultChannelPipeline 的结构
Netty 默认实现是:
DefaultChannelPipeline
它内部不是简单的 List。
而是一条双向链表。
链表节点是:
ChannelHandlerContext
大致结构:
每个 Context 包装一个 Handler。
也就是说:
- Pipeline 存的不是裸 Handler,
- 而是 HandlerContext。
为什么要有 Context?
因为 Handler 本身只负责业务逻辑。
而 Context 负责:
- 知道自己在 Pipeline 中的位置
- 持有 Channel
- 持有 Pipeline
- 持有 EventExecutor
- 负责向前或向后传播事件
所以可以这样理解:
- Handler 是处理逻辑;
- Context 是链表节点和传播上下文。
三、HeadContext 和 TailContext
Pipeline 创建时,默认会有两个特殊节点:
HeadContextTailContext
HeadContext 靠近底层 socket。
它负责和 Unsafe 交互,最终执行真正的底层 IO 操作。
比如:
bindconnectwriteflushreadclose
出站事件最后通常会走到 HeadContext。
TailContext 是入站事件的尾节点。
如果一个入站事件一路传播到 TailContext 还没有被处理,TailContext 可以做兜底处理。
比如:
- 未处理的 inbound 消息释放
- 异常兜底传播
所以 Pipeline 不是只有用户添加的 Handler。
它天生就有:
HeadContextTailContext
这两个节点把用户 Handler 和底层 IO 连接起来。
四、Inbound 事件怎么传播?
入站事件是从底层 socket 往业务方向传播。
常见 inbound 事件包括:
channelRegisteredchannelActivechannelReadchannelReadCompleteexceptionCaughtchannelInactive
严格说,exceptionCaught 是异常传播回调,通常沿 inbound 方向传播;这里把它放在一起,是为了说明它也通过 Pipeline 机制传递。
以 channelRead 为例。
当 EventLoop 读到数据后,会触发:
pipeline.fireChannelRead(byteBuf)
主线类似:
如果当前 Handler 处理完以后希望继续往后传播,就调用:
ctx.fireChannelRead(msg);
这会找到下一个 inbound Handler。
所以 inbound 传播方向可以理解为:
Head -> Tail
数据读取流程大致是:
五、Outbound 事件怎么传播?
出站事件是从业务方向往底层 socket 传播。
常见 outbound 事件包括:
bindconnectwriteflushclose
比如业务代码调用:
ctx.writeAndFlush(response);
主线类似:
outbound 传播方向和 inbound 相反。
可以理解为:
Tail -> Head
实际会从当前 Context 往前找 outbound Handler。
写出流程大致是:
六、Inbound 和 Outbound 为什么要分开?
因为读和写的方向不同。
入站是:
socket -> 应用
出站是:
应用 -> socket
如果不区分方向,Pipeline 中的处理顺序会很混乱。
Netty 把 Handler 分成:
ChannelInboundHandlerChannelOutboundHandler
也可以用:
ChannelDuplexHandler
同时处理入站和出站。
这让编解码器的职责很清晰。
例如:
Decoder:
处理 inbound,把 ByteBuf 转成业务对象。Encoder:
处理 outbound,把业务对象转成 ByteBuf。
七、ChannelHandlerContext 的价值
很多人刚学 Netty 会混淆:
ChannelPipelineHandlerContext
可以这样区分:
Channel:
一条连接。Pipeline:
这条连接上的处理链。Handler:
处理逻辑。Context:
Handler 在 Pipeline 中的节点上下文。
Context 的价值是:
控制事件从哪里继续传播。
比如:
ctx.fireChannelRead(msg);
是从当前 Context 往后传播。
而:
ctx.pipeline().fireChannelRead(msg);
是从 Pipeline 头部重新开始传播。
这两个行为并不一样。
同理:
ctx.write(msg);
是从当前 Context 往前找 outbound Handler。
而:
ctx.channel().write(msg);
通常会从 Pipeline 尾部开始走 outbound。
理解这一点,对调试 Handler 顺序非常重要。
八、Handler 是共享的吗?
默认情况下,Handler 通常不应该被多个 Channel 随便共享。
如果一个 Handler 没有状态,可以加:
@ChannelHandler.Sharable
表示可以被多个 Pipeline 共享。
如果 Handler 内部有状态,比如:
- 计数器
- 临时缓存
- 用户上下文
- 协议解析状态
就不应该共享。
因为一个 Handler 可能被多个 Channel 的 EventLoop 调用。
共享有状态 Handler 容易产生并发问题。
所以一般建议:
- 无状态 Handler 可以共享;
- 有状态 Handler 每个 Channel 创建一个。
九、异常如何传播?
Netty 中异常也通过 Pipeline 传播。
常见方法是:
exceptionCaught(ChannelHandlerContext ctx, Throwable cause)
如果当前 Handler 不处理,可以继续传播:
ctx.fireExceptionCaught(cause);
如果处理了,比如关闭连接:
ctx.close();
异常传播机制让错误处理也可以模块化。
例如:
- 协议解析异常
- 鉴权异常
- 业务异常
- 连接异常
可以在不同 Handler 层处理。
十、Pipeline 的核心价值
Pipeline 的设计让 Netty 具备非常强的扩展能力。
它把网络处理拆成多个小组件:
- 拆包
- 解码
- 鉴权
- 业务处理
- 编码
- 压缩
- 加密
- 日志
- 限流
每个组件只关注一件事。
这就是为什么 Netty 适合做:
HTTP Server- RPC 框架
- IM 长连接
- 游戏网关
- 消息队列通信层
- 自定义协议网关
因为这些系统本质上都需要:
- 把字节流组织成协议消息,
- 再把协议消息交给业务逻辑。
十一、从 Pipeline 对照消息 Gateway
不是说消息 Gateway 就等同于 Netty Pipeline,而是二者都在处理“消息进入、转换、过滤、消费、转发”这类链路组织问题。用 Pipeline 的视角去对照消息 Gateway,会更容易看清方向、职责和边界。
本地到云端方向大致可以抽象成:
云端到本地方向也类似:
这里有几个点和 Netty Pipeline 很像。
第一,方向很重要。
Netty 分 inbound / outbound:
socket -> 应用
应用 -> socket
边缘侧 gateway 也有方向:
本地 MQTT -> 云端 MQTT
云端 MQTT -> 本地 MQTT
第二,处理节点要分层。
Netty 里可以把 decoder、auth、business、encoder 拆开。
gateway 里也应该把这些职责拆开:
- 日志记录
- topic 过滤
- 桥接标记检查
- 业务消费
- 消息转发
- 异常处理
第三,网关不能只是无脑转发。
业务处理器返回 boolean,本质上就是在表达:
这条消息是否已经被 gateway 自己消费?
如果已经消费,就不应该继续转发。
如果没有消费,并且不是单 MQTT 地址部署,就继续桥接到另一侧。
第四,双向桥接必须处理回环。
当本地消息被转发到云端后,云端侧如果又把同一条消息转回本地,就会形成循环。
所以需要:
- topic 过滤规则;
- payload 来源标记;
- 重复桥接识别;
- 命中后直接停止传播。
这和 Pipeline 里的“事件是否继续 fire 下去”非常像。
不是所有消息都应该继续传播。
有些消息应该被消费,有些应该被过滤,有些应该被转换后再发出去。
十二、架构师视角:这篇对我有什么用?
学完 Pipeline 后,我以后设计网关或消息桥接系统时,会先问:
- 这条链路有哪些明确方向?
- 入口消息先经过哪些节点?
- 哪些逻辑属于协议边界,哪些属于业务消费?
- 哪些节点可以独立测试和替换?
- 消息被消费后是否还应该继续传播?
- 双向转发时如何避免回环?
- 异常、日志、监控、鉴权、限流应该作为独立节点,还是散落在业务代码里?
这也是我从 Netty Pipeline 学到的最大价值。
它不是一个“链表源码知识点”,而是一种组织复杂流程的方法。
对于边缘侧 MQTT gateway 这种系统,Pipeline 思想可以帮助我把消息链路拆成:
- 入口
- 方向
- 过滤
- 解析
- 业务消费
- 桥接转发
- 回环防护
- 观测与异常处理
这样看系统时,就不会只看到某个 listener 或 handler,而能看到整条消息流的责任边界。
十三、结论
Netty Pipeline 可以总结为:
- 每个 Channel 拥有一个 Pipeline。
- Pipeline 是一条 HandlerContext 双向链表。
- Handler 负责处理逻辑。
- Context 负责事件传播。
- Inbound 事件从 Head 到 Tail。
- Outbound 事件从 Tail 到 Head。
- HeadContext 连接底层 IO。
- TailContext 做入站兜底。
它的核心价值是:
把复杂网络处理拆成可组合的责任链。
理解 Pipeline 后,再看编解码器、HTTP 处理、RPC 协议、Gateway 请求转发,就会清楚很多。
下一篇我们继续看 Netty 的另一个核心:
ByteBuf 和内存管理。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)