【码动四季】科研里的很多弯路,都是从没有先做最小测试开始的——一次 Codex 多模型接入踩坑记录
01 昨天又被一个看起来很小的问题卡住了。
一开始,我只是想在 Codex 里配置几个不同的模型,方便实验流程切换使用。
这个想法本身并不复杂:
同一个命令行工具,同一套工作流,不同模型按需切换。
我原本以为,只要填好 API Key、base_url、模型名称,再改一下 provider 配置,应该就可以顺利跑起来。
但真正开始之后才发现,事情并没有想象中那么简单。
模型一直无法正常调用,我开始怀疑是不是 key 写错了,是不是模型名称不对,是不是 base_url 少了一段路径,甚至怀疑是不是 Codex 的配置文件没有生效。
于是我开始反复改配置。
改模型名。
改 provider。
改 base_url。
改环境变量。
改 Codex 版本。
每改一次,就重新启动一次;每启动一次,又看到一个新的报错。
这类问题最消耗人的地方在于,它一开始并不像一个"大问题"。
它不会明确告诉你研究思路错了,也不会告诉你代码逻辑错了。
它只是让你在一堆看起来差不多的报错里来回试探,然后慢慢意识到:
可能不是某一行配置写错了,而是整条工具链从一开始就没有对齐。
02 表面上是配置问题,本质上是协议问题
我一直使用的是 Codex 0.122.0。它在我写下这篇文章的时候已经不是最新版本了,但在当时的使用过程中,我并没有第一时间意识到问题可能和 Codex 版本有关。
后来查了一圈官方文档才发现,问题可能比这些表层配置更底层。
OpenAI 在 2025 年 3 月推出了新的 Responses API,也就是:
/v1/responses
而很多第三方模型还没有跟进支持,实际兼容的通常是传统的接口:
/v1/chat/completions
也就是说,我遇到的情况大概是:
Codex0.122.0期望走/v1/responses
第三方模型主要支持 /v1/chat/completions
两边协议没有完全对上
所以表面上看,问题是:
模型接不进去。
但更深一层看,问题其实是:
工具链使用的协议和模型服务支持的协议不一致。
这也是这次排错里最关键的地方。
我一开始总是在配置层面找问题,但真正的问题可能在更底层:
不是 key 错了,不是模型名错了,而是 Codex 发出的请求格式和第三方服务能接收的格式不一样。
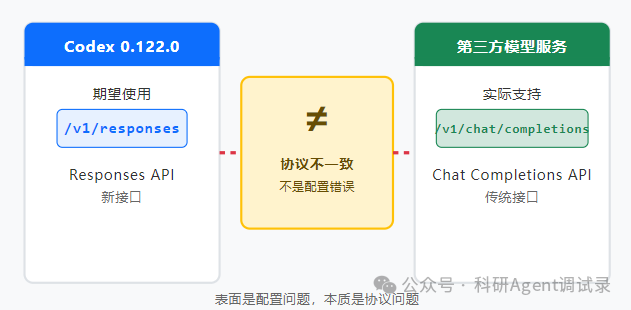
图1:协议差异示意图 - Codex 0.80.0以上的版本期望的接口与第三方模型实际支持的接口不同
03 后来我为什么降到 Codex 0.80.0
在确认问题可能和协议有关之后,我才开始考虑降级。
后来我尝试使用 Codex 0.80.0。
相比 0.122.0,0.80.0 对 wire_api = "chat" 这条路线更友好,也更适合接入主要兼容 /v1/chat/completions 的第三方模型服务。
简单来说,我当时面对的是这样一个选择:
|
版本 |
优势 |
问题 |
|---|---|---|
|
Codex 0.122.0 |
更适合较新的 OpenAI 模型 |
部分第三方模型不支持 |
|
Codex 0.80.0 |
更容易接入 Chat Completions 类第三方模型 |
对高版本模型支持受限 |
降级之后,问题逐渐变得清楚。
这不是一个简单的"哪个版本更好"的问题,而是要看你要接的模型服务到底支持什么协议。
如果服务商只支持 /v1/chat/completions,那你在强依赖 /v1/responses 的 Codex 版本里硬接,就很容易出问题。
所以真正需要问的不是:
这个模型是否兼容 OpenAI API?
而是:
它兼容的是
/v1/chat/completions,还是/v1/responses?
这两个问题完全不一样。

图2:版本选择对比图 - 根据模型服务支持的接口选择合适的 Codex 版本
04 这次真正的教训:不要一上来就大改配置
这次问题真正给我的教训,不是"遇到问题就降级"。
而是:
做复杂工具链配置之前,应该先做最小可验证测试。
我一开始犯的错误是,直接在 Codex 的配置文件里反复修改。
这种方式看起来是在排错,但其实很容易把问题越搞越复杂。
因为当你直接在一个完整工具链里调试时,你根本不知道问题到底出在哪一层。
可能是 API Key 不对。
可能是 base_url 不对。
可能是模型名不对。
可能是 Codex 配置文件没有生效。
可能是服务商不支持对应接口。
也可能是 Codex 版本升级之后,底层调用协议已经变了。
当这些问题叠在一起时,每一次修改都像是在盲猜。
你以为自己在解决问题,其实只是把更多变量混在了一起。
更稳妥的做法应该是:
先跳过 Codex,直接用 curl 测试模型服务本身。
05 用 curl 做最小接口测试
以后再遇到类似问题,我会先做两个最小测试。
第一个测试:
确认服务是否支持 Chat Completions API。
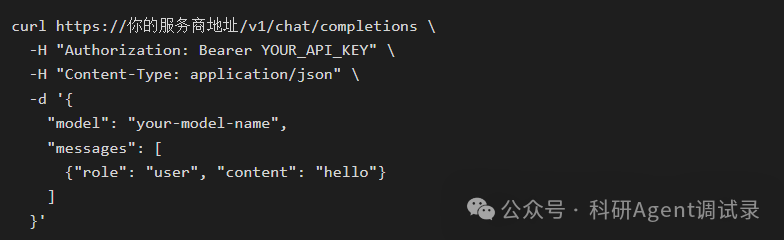
如果这个能通,说明这个服务至少支持:
/v1/chat/completions
第二个测试:
确认服务是否支持 Responses API。
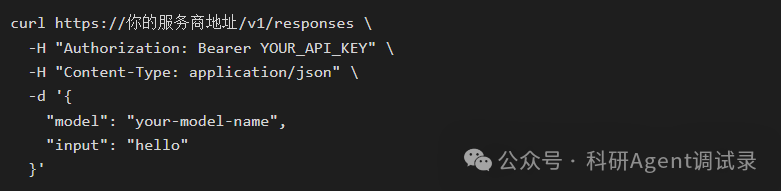
如果第一个能通,第二个不通,那么问题就清楚很多了。
这说明这个服务可能只是兼容 Chat Completions API,并不支持新版 Codex 更依赖的 Responses API。
这时候就不要继续在新版 Codex 里反复改配置了。
更合理的选择可能是:
-
使用支持 chat 接口的旧版 Codex
-
使用协议转换代理
-
换一个真正支持 responses 的模型服务
这个过程本质上是在把复杂问题拆开。
先确认服务能不能通。
再确认接口支不支持。
最后才去改 Codex 配置。
顺序一旦反过来,就很容易浪费大量时间。
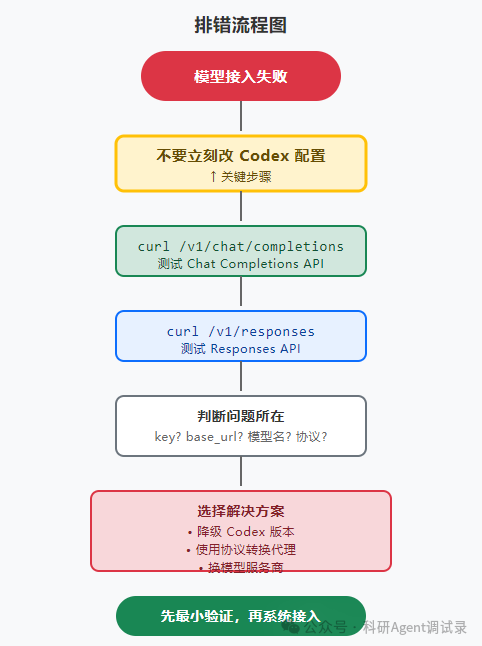
图3:排错流程图 - 先用 curl 做最小测试,再决定后续方案
06 最消耗人的,不是报错,而是不知道是哪一层错了
这次排错让我感触比较深的一点是:
很多工程问题最让人疲惫的,并不是报错本身,而是你不知道自己在和哪一层系统对抗。
有时候你以为自己只是在改一个配置文件。
但实际上,你同时碰到了:
工具版本 API 协议 模型服务兼容性 provider 配置 环境变量 命令行工具行为
当这些层没有被拆开时,排错就会变成一种很低效的试错。
每一次修改都不确定有没有意义。
每一次失败也不知道提供了什么信息。
所以后来我越来越觉得,科研里的工程能力,不只是会写代码,也不只是会调模型。
更重要的是:
能不能把一个混乱的问题,拆成几个可以验证的小问题。
这句话说起来很简单,但真正卡在报错里时,很容易忘记。
07 科研里的"可复现",不是最后才出现的词
以前我总觉得,"可复现"是论文或者实验报告里最后才需要写的东西。
比如记录数据集、参数、随机种子、实验环境。
但这次问题让我意识到,可复现其实从很早就开始了。
从你选择哪个工具版本开始。
从你使用哪套 API 协议开始。
从你有没有记录每一次修改开始。
从你有没有先做最小测试开始。
一个看起来很小的配置项,如果没有被记录清楚,后面就可能变成一个很难解释的问题。
尤其是在科研开发里,很多系统并不是一次性写完的,而是在不断试错、调整、迁移中慢慢长出来的。
如果每一次排错都只是靠记忆和感觉,后面很容易忘记自己为什么这样改,也很难向别人解释这个环境为什么这样配置。
所以这次之后,我给自己定了一个很简单的原则:
任何复杂工具链接入之前,先做最小测试,再进入完整系统。
不是先改一堆配置。
不是先猜哪里错了。
而是先问一个最朴素的问题:
这个接口本身,到底能不能被调用?
08 这次踩坑后的一个小总结
这次 Codex 多模型接入的问题,最后让我重新理解了 curl 的价值。
它很简单,甚至看起来有点原始。
但正因为它简单,所以它更诚实。
当一个复杂工具链跑不通时,curl 可以帮你暂时绕开工具链,只测试最核心的那一层:
服务是否存在? 认证是否正确? 模型名是否有效? 接口是否支持? 返回是否符合预期?
这些问题没有确认之前,直接去改 Codex 配置,很可能只是在复杂系统里反复盲试。
所以这次真正的收获不是"我最后用了哪个版本",而是一个更通用的排错习惯:
先最小验证,再系统接入。
这句话以后应该会帮我少走很多弯路。
科研里的很多崩溃,往往不是因为问题真的有多难,而是因为我们太早进入了复杂系统,忘了先把问题拆小。
一个配置项、一个 API 协议、一个工具版本,看起来都很小。
但当它们没有对齐时,整个工作流就会变得不稳定。
所以,下一次再遇到类似问题,我希望自己先停一下。
不要急着改配置。
不要急着降版本。
不要急着怀疑模型。
先打开终端,写一个最小的 curl 请求。
因为很多时候,最朴素的测试,反而是最可靠的开始。
下一篇文章,我会继续记录:
如何用 MoonBridge 在 Responses API 和 Chat Completions API 之间做一层转换,以及它到底能不能解决 Codex 接入第三方模型的问题。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 22
22 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)