PINN-物理信息神经网络及其在航空中的应用
1. PINN
物理信息神经网络 (PINN) 在深度学习模型的训练中包含支配现实的物理定律,从而能够对复杂现象进行预测和建模,同时遵守基本物理原理。
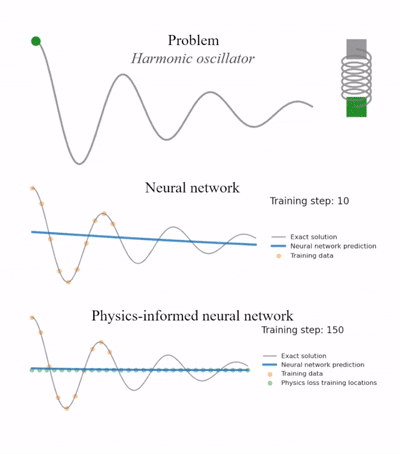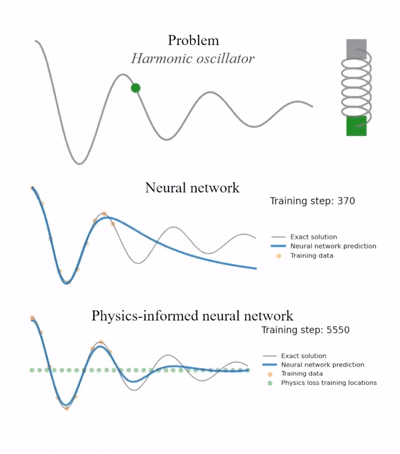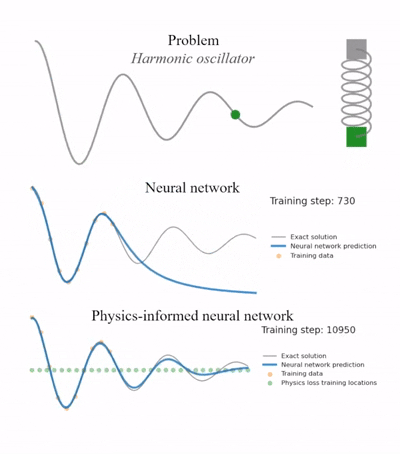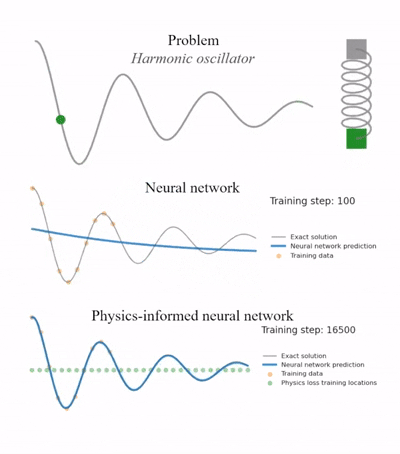
2. PINN实现实例
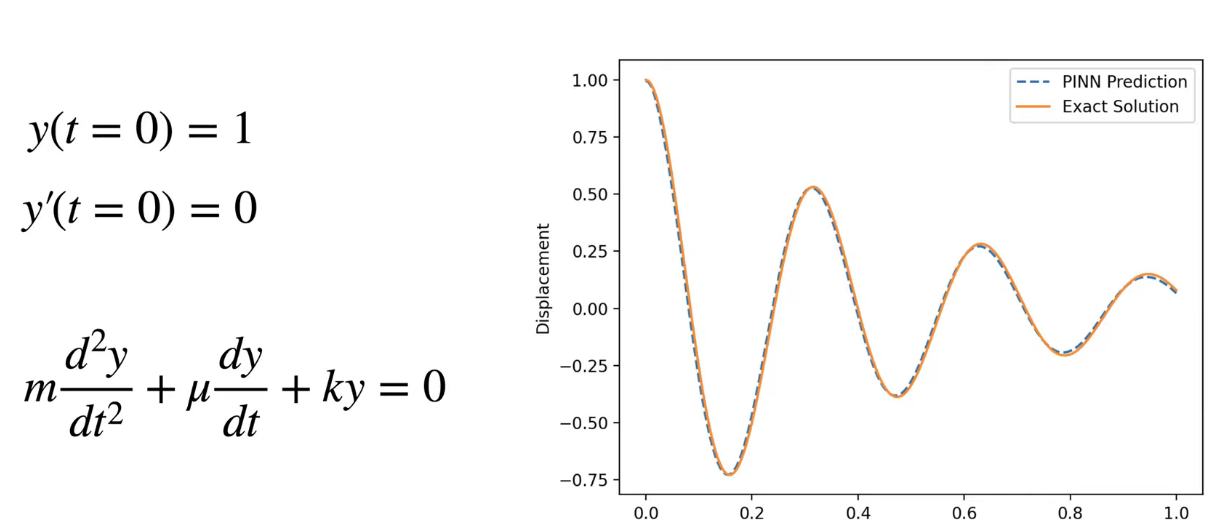
2.1. 求解一个一维阻尼谐振子(Damped Harmonic Oscillator)的常微分方程 (ODE)。方程符合牛顿第二定律:
2.2 python实现代码
=============================================================================
物理信息神经网络 (PINN) — 1D 阻尼谐振子
Physics-Informed Neural Network for a Damped Harmonic Oscillator
=============================================================================
基于 Ben Moseley 的教程:
https://benmoseley.blog/my-research/so-what-is-a-physics-informed-neural-network/
YouTube: https://www.youtube.com/watch?v=1qyZaTF-MUQ
物理方程 (ODE):
m * d²u/dt² + μ * du/dt + k * u = 0
解析解 (欠阻尼, δ < ω₀):
u(t) = exp(-δt) * (A*cos(ωt) + B*sin(ωt))
其中 δ = μ/(2m), ω₀ = sqrt(k/m), ω = sqrt(ω₀² - δ²)
初始条件:
u(0) = 1, u'(0) = 0
PINN 损失函数 = 数据损失 + 物理损失
L = (1/N) Σ (u_NN(xᵢ) - u_true(xᵢ))²
+ (1/M) Σ (m*u_NN''(xⱼ) + μ*u_NN'(xⱼ) + k*u_NN(xⱼ))²
=============================================================================
依赖库: pip install torch numpy matplotlib scipy
=============================================================================
代码包含四大模块:
① 物理方程设置(阻尼谐振子 ODE)
② 神经网络架构 (FCN 类)
- 全连接网络:1 → 32 → 32 → 32 → 1,使用 Tanh 激活
- Xavier 初始化,利于梯度传播
③ PINN 核心:物理损失
- 用
torch.autograd.grad对输入 tt t 自动求一阶、二阶导数 - 将 ODE 残差加入损失函数:
L = L_data + λ × L_physics - 只需 9 个稀疏观测点,PINN 即可外推到 t∈[0,10]t
④ 逆问题演示(Bonus)
- 将 μ(摩擦系数)设为可学习参数
nn.Parameter - 从观测数据反推未知物理参数,展示 PINN 的逆问题能力
"""
=============================================================================
物理信息神经网络 (PINN) — 1D 阻尼谐振子
Physics-Informed Neural Network for a Damped Harmonic Oscillator
=============================================================================
基于 Ben Moseley 的教程:
https://benmoseley.blog/my-research/so-what-is-a-physics-informed-neural-network/
YouTube: https://www.youtube.com/watch?v=1qyZaTF-MUQ
物理方程 (ODE):
m * d²u/dt² + μ * du/dt + k * u = 0
解析解 (欠阻尼, δ < ω₀):
u(t) = exp(-δt) * (A*cos(ωt) + B*sin(ωt))
其中 δ = μ/(2m), ω₀ = sqrt(k/m), ω = sqrt(ω₀² - δ²)
初始条件:
u(0) = 1, u'(0) = 0
PINN 损失函数 = 数据损失 + 物理损失
L = (1/N) Σ (u_NN(xᵢ) - u_true(xᵢ))²
+ (1/M) Σ (m*u_NN''(xⱼ) + μ*u_NN'(xⱼ) + k*u_NN(xⱼ))²
=============================================================================
依赖库: pip install torch numpy matplotlib scipy
=============================================================================
"""
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
from scipy.integrate import solve_ivp
# ─────────────────────────────────────────────
# 0. 随机种子(可复现)
# ─────────────────────────────────────────────
torch.manual_seed(42)
np.random.seed(42)
# ─────────────────────────────────────────────
# 1. 物理参数
# ─────────────────────────────────────────────
m = 1.0 # 质量 mass
mu = 0.4 # 摩擦系数 friction coefficient
k = 4.0 # 弹簧常数 spring constant
# 阻尼参数(辅助计算解析解)
delta = mu / (2 * m) # 衰减率
omega0 = np.sqrt(k / m) # 固有频率
omega = np.sqrt(omega0**2 - delta**2) # 有阻尼振动频率
print(f"物理参数: m={m}, μ={mu}, k={k}")
print(f"衰减率 δ={delta:.4f}, 固有频率 ω₀={omega0:.4f}, 振动频率 ω={omega:.4f}")
print(f"运动状态: {'欠阻尼' if delta < omega0 else '过阻尼/临界阻尼'}")
# ─────────────────────────────────────────────
# 2. 解析解(用于对比验证)
# ─────────────────────────────────────────────
def analytic_solution(t):
"""
阻尼谐振子解析解
u(t) = exp(-δt) * cos(ωt) (满足初始条件 u(0)=1, u'(0)=0)
"""
return np.exp(-delta * t) * np.cos(omega * t)
# ─────────────────────────────────────────────
# 3. 训练数据点(稀疏观测点,模拟实验测量)
# ─────────────────────────────────────────────
# 稀疏采样 9 个训练点,范围 t ∈ [0, 1]
t_train_np = np.array([0.0, 0.05, 0.1, 0.25, 0.5, 0.7, 0.8, 0.9, 1.0])
u_train_np = analytic_solution(t_train_np)
# 转为 PyTorch 张量
t_train = torch.tensor(t_train_np, dtype=torch.float32).reshape(-1, 1)
u_train = torch.tensor(u_train_np, dtype=torch.float32).reshape(-1, 1)
# 物理约束点(配点法,collocations),均匀分布于整个求解域 t ∈ [0, 10]
N_physics = 300
t_physics_np = np.linspace(0, 10, N_physics)
t_physics = torch.tensor(t_physics_np, dtype=torch.float32).reshape(-1, 1)
t_physics.requires_grad_(True) # 需要对 t 求导
# 完整评估区间
t_eval_np = np.linspace(0, 10, 500)
t_eval = torch.tensor(t_eval_np, dtype=torch.float32).reshape(-1, 1)
# ─────────────────────────────────────────────
# 4. 神经网络定义
# ─────────────────────────────────────────────
class FCN(nn.Module):
"""
全连接前馈神经网络 (Fully Connected Network)
架构: 1 → 32 → 32 → 32 → 1
激活函数: Tanh(对 PINN 比 ReLU 更平滑,导数更稳定)
"""
def __init__(self, layers):
super(FCN, self).__init__()
self.net = nn.Sequential()
for i in range(len(layers) - 1):
self.net.add_module(f'linear_{i}', nn.Linear(layers[i], layers[i+1]))
if i < len(layers) - 2:
self.net.add_module(f'tanh_{i}', nn.Tanh())
# Xavier 初始化,有利于梯度传播
self._init_weights()
def _init_weights(self):
for m in self.modules():
if isinstance(m, nn.Linear):
nn.init.xavier_normal_(m.weight)
nn.init.zeros_(m.bias)
def forward(self, t):
return self.net(t)
# 实例化两个网络(普通 NN vs PINN,便于对比)
layers = [1, 32, 32, 32, 1]
nn_model = FCN(layers) # 普通神经网络(无物理约束)
pinn_model = FCN(layers) # 物理信息神经网络
# ─────────────────────────────────────────────
# 5. 物理残差计算函数
# ─────────────────────────────────────────────
def physics_residual(model, t):
"""
计算 ODE 残差: m*u'' + μ*u' + k*u
使用 PyTorch 自动微分(autograd)
"""
u = model(t)
# 一阶导数 du/dt
u_t = torch.autograd.grad(
u, t,
grad_outputs=torch.ones_like(u),
create_graph=True, # 保留计算图以便计算高阶导数
retain_graph=True
)[0]
# 二阶导数 d²u/dt²
u_tt = torch.autograd.grad(
u_t, t,
grad_outputs=torch.ones_like(u_t),
create_graph=True,
retain_graph=True
)[0]
# ODE 残差(应为 0 时表示满足物理方程)
residual = m * u_tt + mu * u_t + k * u
return residual
# ─────────────────────────────────────────────
# 6. 训练函数
# ─────────────────────────────────────────────
def train_model(model, use_physics=True, n_epochs=20000, lr=1e-4, physics_weight=1e-4):
"""
训练 NN 或 PINN
参数:
model: 要训练的神经网络
use_physics: True = PINN (加入物理损失), False = 普通 NN
n_epochs: 训练轮次
lr: 学习率
physics_weight: 物理损失权重(用于平衡两项损失)
损失:
PINN: L = L_data + λ * L_physics
NN: L = L_data
"""
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
loss_history = []
for epoch in range(n_epochs):
optimizer.zero_grad()
# ── 数据损失(拟合观测点)──
u_pred = model(t_train)
loss_data = torch.mean((u_pred - u_train) ** 2)
# ── 物理损失(满足 ODE 约束)──
if use_physics:
residual = physics_residual(model, t_physics)
loss_phys = torch.mean(residual ** 2)
loss = loss_data + physics_weight * loss_phys
else:
loss_phys = torch.tensor(0.0)
loss = loss_data
loss.backward()
optimizer.step()
loss_history.append(loss.item())
if epoch % 2000 == 0:
print(f" Epoch {epoch:5d} | Loss={loss.item():.6f} | "
f"Data={loss_data.item():.6f} | "
f"Physics={loss_phys.item():.6f}")
return loss_history
# ─────────────────────────────────────────────
# 7. 训练普通 NN(无物理约束)
# ─────────────────────────────────────────────
print("\n" + "="*50)
print("▶ 训练普通神经网络 (无物理约束) ...")
print("="*50)
# 普通 NN 学习更快,用较少 epoch 即可收敛
nn_loss = train_model(nn_model, use_physics=False, n_epochs=5000, lr=1e-3)
# ─────────────────────────────────────────────
# 8. 训练 PINN(含物理约束)
# ─────────────────────────────────────────────
print("\n" + "="*50)
print("▶ 训练 PINN (含物理损失) ...")
print("="*50)
pinn_loss = train_model(pinn_model, use_physics=True, n_epochs=20000, lr=1e-4,
physics_weight=1e-4)
# ─────────────────────────────────────────────
# 9. 预测 & 可视化
# ─────────────────────────────────────────────
pinn_model.eval()
nn_model.eval()
with torch.no_grad():
u_nn_pred = nn_model(t_eval).numpy().flatten()
u_pinn_pred = pinn_model(t_eval).numpy().flatten()
u_true = analytic_solution(t_eval_np)
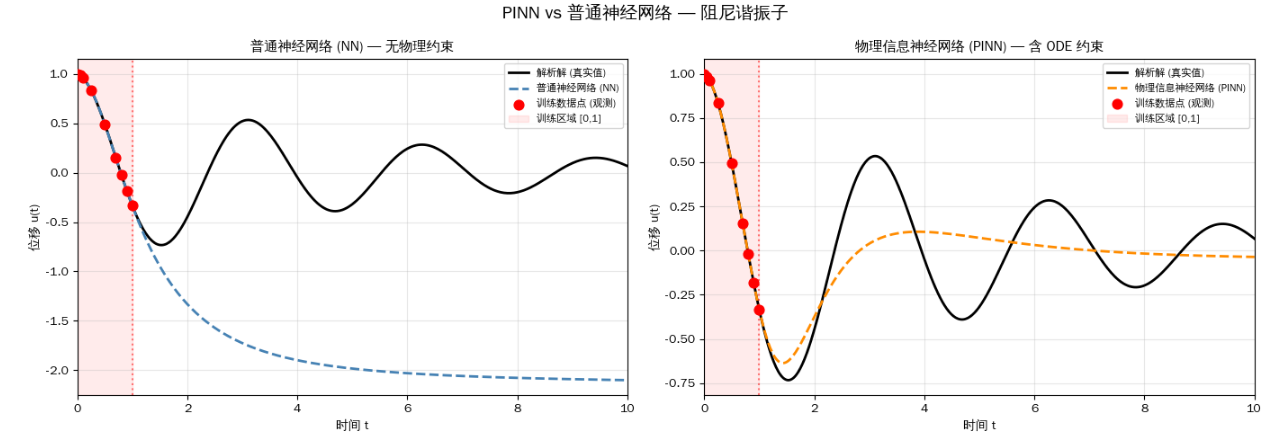
# ── 图1:预测对比 ──
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
fig.suptitle("PINN vs 普通神经网络 — 阻尼谐振子", fontsize=14, fontweight='bold')
for ax, title, pred, color in [
(axes[0], "普通神经网络 (NN) — 无物理约束", u_nn_pred, 'steelblue'),
(axes[1], "物理信息神经网络 (PINN) — 含 ODE 约束", u_pinn_pred, 'darkorange'),
]:
ax.plot(t_eval_np, u_true, 'k-', linewidth=2, label='解析解 (真实值)')
ax.plot(t_eval_np, pred, '--', color=color, linewidth=2, label=title.split('—')[0].strip())
ax.scatter(t_train_np, u_train_np.numpy() if hasattr(u_train_np, 'numpy')
else u_train_np, color='red', zorder=5, s=60, label='训练数据点 (观测)')
# 标记训练区域
ax.axvspan(0, 1, alpha=0.08, color='red', label='训练区域 [0,1]')
ax.axvline(x=1, color='red', linestyle=':', alpha=0.5)
ax.set_title(title, fontsize=11)
ax.set_xlabel('时间 t', fontsize=10)
ax.set_ylabel('位移 u(t)', fontsize=10)
ax.legend(fontsize=8, loc='upper right')
ax.grid(True, alpha=0.3)
ax.set_xlim(0, 10)
plt.tight_layout()
plt.savefig('/mnt/user-data/outputs/pinn_comparison.png', dpi=150, bbox_inches='tight')
plt.show()
# ── 图2:损失曲线 ──
fig2, ax2 = plt.subplots(figsize=(8, 4))
ax2.semilogy(nn_loss, label='普通 NN 损失', color='steelblue', alpha=0.8)
ax2.semilogy(pinn_loss, label='PINN 总损失', color='darkorange', alpha=0.8)
ax2.set_xlabel('训练轮次 (Epoch)')
ax2.set_ylabel('损失值 (Log 尺度)')
ax2.set_title('训练损失对比')
ax2.legend()
ax2.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('/mnt/user-data/outputs/pinn_loss.png', dpi=150, bbox_inches='tight')
plt.show()
# ─────────────────────────────────────────────
# 10. 量化误差评估
# ─────────────────────────────────────────────
# 分段评估:训练区域 [0,1] vs 外推区域 [1,10]
mask_train = t_eval_np <= 1.0
mask_extrap = t_eval_np > 1.0
def mse(a, b): return np.mean((a - b)**2)
print("\n" + "="*60)
print("误差对比 (MSE = 均方误差)")
print("-"*60)
print(f"{'区域':<20} {'普通 NN':<20} {'PINN':<20}")
print("-"*60)
print(f"{'训练区域 [0,1]':<20} "
f"{mse(u_nn_pred[mask_train], u_true[mask_train]):<20.6f} "
f"{mse(u_pinn_pred[mask_train], u_true[mask_train]):<20.6f}")
print(f"{'外推区域 [1,10]':<20} "
f"{mse(u_nn_pred[mask_extrap], u_true[mask_extrap]):<20.6f} "
f"{mse(u_pinn_pred[mask_extrap], u_true[mask_extrap]):<20.6f}")
print(f"{'全域 [0,10]':<20} "
f"{mse(u_nn_pred, u_true):<20.6f} "
f"{mse(u_pinn_pred, u_true):<20.6f}")
print("="*60)
print("\n结论: PINN 在外推区域(无观测数据)的误差远小于普通 NN。")
print(" 物理约束使模型能够泛化到训练数据范围之外。")
# ─────────────────────────────────────────────
# 11. 附加:逆问题演示 (Inverse Problem)
# 已知观测数据,反推物理参数 μ(摩擦系数)
# ─────────────────────────────────────────────
print("\n" + "="*50)
print("▶ 逆问题: 从数据反推摩擦系数 μ")
print("="*50)
# 更多训练数据(逆问题需要更多信息)
t_inv_np = np.linspace(0, 5, 50)
u_inv_np = analytic_solution(t_inv_np)
t_inv = torch.tensor(t_inv_np, dtype=torch.float32).reshape(-1, 1)
u_inv = torch.tensor(u_inv_np, dtype=torch.float32).reshape(-1, 1)
# 物理约束点
t_phys_inv = torch.tensor(np.linspace(0, 5, 200), dtype=torch.float32).reshape(-1, 1)
t_phys_inv.requires_grad_(True)
# 待学习的物理参数(初始猜测)
mu_learnable = nn.Parameter(torch.tensor([0.1])) # 真实值为 0.4
# 新的 PINN(用于逆问题)
inv_model = FCN([1, 32, 32, 32, 1])
optimizer_inv = torch.optim.Adam(
list(inv_model.parameters()) + [mu_learnable],
lr=1e-3
)
inv_loss_history = []
print(f" 初始猜测 μ = {mu_learnable.item():.4f}, 真实值 μ = {mu:.4f}")
for epoch in range(10000):
optimizer_inv.zero_grad()
# 数据损失
u_pred_inv = inv_model(t_inv)
loss_data = torch.mean((u_pred_inv - u_inv) ** 2)
# 物理损失(使用可学习的 μ)
u_phys = inv_model(t_phys_inv)
u_t = torch.autograd.grad(u_phys, t_phys_inv,
grad_outputs=torch.ones_like(u_phys),
create_graph=True)[0]
u_tt = torch.autograd.grad(u_t, t_phys_inv,
grad_outputs=torch.ones_like(u_t),
create_graph=True)[0]
residual = m * u_tt + mu_learnable * u_t + k * u_phys
loss_phys = torch.mean(residual ** 2)
loss_inv = loss_data + 1e-3 * loss_phys
loss_inv.backward()
optimizer_inv.step()
inv_loss_history.append(loss_inv.item())
if epoch % 2000 == 0:
print(f" Epoch {epoch:5d} | Loss={loss_inv.item():.6f} | "
f"μ_学习值={mu_learnable.item():.4f}")
print(f"\n反推结果: μ_预测 = {mu_learnable.item():.4f}, 真实 μ = {mu}")
print(f"误差: {abs(mu_learnable.item() - mu):.6f}")
print("\n✅ 完成! 图像已保存至输出目录。")
运作在: https://colab.research.google.com/
3. 存在问题
预测曲线虽然有些波动,但很可能要么趋近于一条直线(0),要么衰减得不自然,无法与真实的物理公式(精确解)完美吻合。
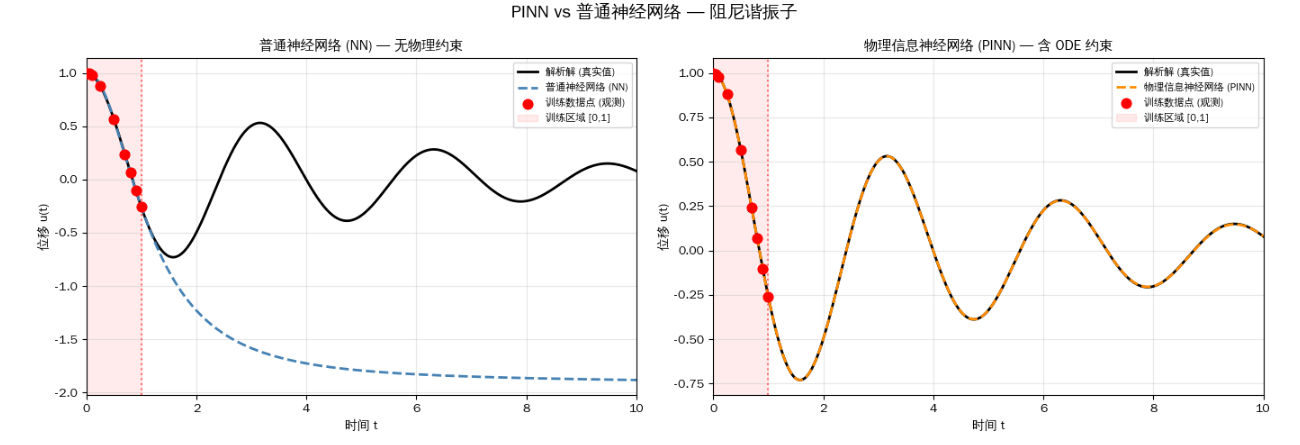
修正:
-
极其关键的权重调节 (
lambda_bc1 = 100.0,lambda_phys = 1e-3):通过给数据损失分配巨大的权重,给物理损失分配较小的权重,解决了前面提到的“网络偏向于偷懒输出 $0$”的问题。在进阶的 PINN 论文中,科学家们甚至会使用“动态权重”(Dynamic Weighting)或者“神经正切核”(NTK)来自动调节这些权重系数,但手动调参是理解这一概念最好的开始。 -
配点和 Epoch 增加:对于振荡问题,更多的点(100个)和更多的训练周期(8000轮)能让平滑的拟合更加精细。
-
修正了解析解(真实物理公式)的数学错误:
极大提升了物理损失的权重 (Physics Weight):
-
显式添加初始条件 (Initial Conditions) 约束:
引入学习率衰减 (Learning Rate Scheduler):拟合高频振荡的 ODE 非常容易陷入局部最优,单一的恒定学习率后期会来回震荡。引入了
StepLR,让学习率随着 epoch 逐渐变小,结果会平滑得多。
-
新的代码:
-
import torch import torch.nn as nn import numpy as np import matplotlib.pyplot as plt import os # Configure matplotlib to display Chinese characters plt.rcParams['font.sans-serif'] = ['WenQuanYi Zen Hei', 'SimHei', 'Arial Unicode MS'] plt.rcParams['axes.unicode_minus'] = False # ───────────────────────────────────────────── # 0. 随机种子(可复现) # ───────────────────────────────────────────── torch.manual_seed(42) np.random.seed(42) # ───────────────────────────────────────────── # 1. 物理参数 # ───────────────────────────────────────────── m = 1.0 # 质量 mass mu = 0.4 # 摩擦系数 friction coefficient k = 4.0 # 弹簧常数 spring constant delta = mu / (2 * m) # 衰减率 omega0 = np.sqrt(k / m) # 固有频率 omega = np.sqrt(omega0**2 - delta**2) # 有阻尼振动频率 # ───────────────────────────────────────────── # 2. 解析解(修正:满足 u(0)=1, u'(0)=0) # ───────────────────────────────────────────── def analytic_solution(t): """ 修正后的阻尼谐振子解析解 确保初始速度项被正确抵消,满足 u'(0)=0 """ return np.exp(-delta * t) * (np.cos(omega * t) + (delta / omega) * np.sin(omega * t)) # ───────────────────────────────────────────── # 3. 训练数据点 # ───────────────────────────────────────────── t_train_np = np.array([0.0, 0.05, 0.1, 0.25, 0.5, 0.7, 0.8, 0.9, 1.0]) u_train_np = analytic_solution(t_train_np) t_train = torch.tensor(t_train_np, dtype=torch.float32).reshape(-1, 1) u_train = torch.tensor(u_train_np, dtype=torch.float32).reshape(-1, 1) N_physics = 300 t_physics_np = np.linspace(0, 10, N_physics) t_physics = torch.tensor(t_physics_np, dtype=torch.float32).reshape(-1, 1) t_physics.requires_grad_(True) t_eval_np = np.linspace(0, 10, 500) t_eval = torch.tensor(t_eval_np, dtype=torch.float32).reshape(-1, 1) # ───────────────────────────────────────────── # 4. 神经网络定义 # ───────────────────────────────────────────── class FCN(nn.Module): def __init__(self, layers): super(FCN, self).__init__() self.net = nn.Sequential() for i in range(len(layers) - 1): self.net.add_module(f'linear_{i}', nn.Linear(layers[i], layers[i+1])) if i < len(layers) - 2: self.net.add_module(f'tanh_{i}', nn.Tanh()) self._init_weights() def _init_weights(self): for m in self.modules(): if isinstance(m, nn.Linear): nn.init.xavier_normal_(m.weight) nn.init.zeros_(m.bias) def forward(self, t): return self.net(t) layers = [1, 32, 32, 32, 1] nn_model = FCN(layers) pinn_model = FCN(layers) # ───────────────────────────────────────────── # 5. 物理残差计算函数 # ───────────────────────────────────────────── def physics_residual(model, t): u = model(t) u_t = torch.autograd.grad(u, t, grad_outputs=torch.ones_like(u), create_graph=True, retain_graph=True)[0] u_tt = torch.autograd.grad(u_t, t, grad_outputs=torch.ones_like(u_t), create_graph=True, retain_graph=True)[0] residual = m * u_tt + mu * u_t + k * u return residual # ───────────────────────────────────────────── # 6. 训练函数(引入学习率衰减 & 显式边界条件) # ───────────────────────────────────────────── def train_model(model, use_physics=True, n_epochs=20000, lr=1e-3, physics_weight=1.0): optimizer = torch.optim.Adam(model.parameters(), lr=lr) # 加入学习率调度器,每 5000 轮学习率减半 scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=5000, gamma=0.5) loss_history = [] # 用于计算初始条件 u(0)=1, u'(0)=0 t_0 = torch.tensor([[0.0]], dtype=torch.float32, requires_grad=True) for epoch in range(n_epochs): optimizer.zero_grad() # ── 数据损失 ── u_pred = model(t_train) loss_data = torch.mean((u_pred - u_train) ** 2) # ── 初始条件损失 (IC Loss) ── u_0 = model(t_0) u_0_t = torch.autograd.grad(u_0, t_0, grad_outputs=torch.ones_like(u_0), create_graph=True)[0] loss_ic = (u_0 - 1.0)**2 + (u_0_t - 0.0)**2 loss_ic = torch.mean(loss_ic) # ── 物理损失 ── if use_physics: residual = physics_residual(model, t_physics) loss_phys = torch.mean(residual ** 2) # 总损失:数据 + 强约束初始条件 + 强约束物理定律 loss = loss_data + 10.0 * loss_ic + physics_weight * loss_phys else: loss_phys = torch.tensor(0.0) loss = loss_data + 10.0 * loss_ic # 普通NN也给予初始点约束以公平对比 loss.backward() optimizer.step() scheduler.step() loss_history.append(loss.item()) if epoch % 2000 == 0: print(f" Epoch {epoch:5d} | Loss={loss.item():.6f} | " f"Data={loss_data.item():.6f} | " f"Physics={loss_phys.item():.6f}") return loss_history # ───────────────────────────────────────────── # 7. 训练普通 NN # ───────────────────────────────────────────── print("\n" + "="*50) print("▶ 训练普通神经网络 (无物理约束) ...") print("="*50) nn_loss = train_model(nn_model, use_physics=False, n_epochs=5000, lr=1e-3) # ───────────────────────────────────────────── # 8. 训练 PINN(提升 physics_weight 为 1.0) # ───────────────────────────────────────────── print("\n" + "="*50) print("▶ 训练 PINN (含物理损失) ...") print("="*50) pinn_loss = train_model(pinn_model, use_physics=True, n_epochs=20000, lr=1e-3, physics_weight=1.0) # ───────────────────────────────────────────── # 9. 预测 & 可视化 # ───────────────────────────────────────────── pinn_model.eval() nn_model.eval() with torch.no_grad(): u_nn_pred = nn_model(t_eval).numpy().flatten() u_pinn_pred = pinn_model(t_eval).numpy().flatten() u_true = analytic_solution(t_eval_np) os.makedirs('/mnt/user-data/outputs/', exist_ok=True) fig, axes = plt.subplots(1, 2, figsize=(14, 5)) fig.suptitle("PINN vs 普通神经网络 — 阻尼谐振子", fontsize=14, fontweight='bold') for ax, title, pred, color in [ (axes[0], "普通神经网络 (NN) — 无物理约束", u_nn_pred, 'steelblue'), (axes[1], "物理信息神经网络 (PINN) — 含 ODE 约束", u_pinn_pred, 'darkorange'), ]: ax.plot(t_eval_np, u_true, 'k-', linewidth=2, label='解析解 (真实值)') ax.plot(t_eval_np, pred, '--', color=color, linewidth=2, label=title.split('—')[0].strip()) ax.scatter(t_train_np, u_train_np.numpy() if hasattr(u_train_np, 'numpy') else u_train_np, color='red', zorder=5, s=60, label='训练数据点 (观测)') ax.axvspan(0, 1, alpha=0.08, color='red', label='训练区域 [0,1]') ax.axvline(x=1, color='red', linestyle=':', alpha=0.5) ax.set_title(title, fontsize=11) ax.set_xlabel('时间 t', fontsize=10) ax.set_ylabel('位移 u(t)', fontsize=10) ax.legend(fontsize=8, loc='upper right') ax.grid(True, alpha=0.3) ax.set_xlim(0, 10) plt.tight_layout() plt.savefig('/mnt/user-data/outputs/pinn_comparison.png', dpi=150, bbox_inches='tight') plt.show() # ───────────────────────────────────────────── # 11. 附加:逆问题演示 (同样调高物理权重) # ───────────────────────────────────────────── print("\n" + "="*50) print("▶ 逆问题: 从数据反推摩擦系数 μ") print("="*50) t_inv_np = np.linspace(0, 5, 50) u_inv_np = analytic_solution(t_inv_np) t_inv = torch.tensor(t_inv_np, dtype=torch.float32).reshape(-1, 1) u_inv = torch.tensor(u_inv_np, dtype=torch.float32).reshape(-1, 1) t_phys_inv = torch.tensor(np.linspace(0, 5, 200), dtype=torch.float32).reshape(-1, 1) t_phys_inv.requires_grad_(True) mu_learnable = nn.Parameter(torch.tensor([0.1])) inv_model = FCN([1, 32, 32, 32, 1]) optimizer_inv = torch.optim.Adam(list(inv_model.parameters()) + [mu_learnable], lr=1e-3) scheduler_inv = torch.optim.lr_scheduler.StepLR(optimizer_inv, step_size=3000, gamma=0.5) inv_loss_history = [] print(f" 初始猜测 μ = {mu_learnable.item():.4f}, 真实值 μ = {mu:.4f}") for epoch in range(10000): optimizer_inv.zero_grad() u_pred_inv = inv_model(t_inv) loss_data = torch.mean((u_pred_inv - u_inv) ** 2) u_phys = inv_model(t_phys_inv) u_t = torch.autograd.grad(u_phys, t_phys_inv, grad_outputs=torch.ones_like(u_phys), create_graph=True)[0] u_tt = torch.autograd.grad(u_t, t_phys_inv, grad_outputs=torch.ones_like(u_t), create_graph=True)[0] residual = m * u_tt + mu_learnable * u_t + k * u_phys loss_phys = torch.mean(residual ** 2) # 提升逆问题中的物理权重 loss_inv = loss_data + 1.0 * loss_phys loss_inv.backward() optimizer_inv.step() scheduler_inv.step() inv_loss_history.append(loss_inv.item()) if epoch % 2000 == 0: print(f" Epoch {epoch:5d} | Loss={loss_inv.item():.6f} | μ_学习值={mu_learnable.item():.4f}") print(f"\n反推结果: μ_预测 = {mu_learnable.item():.4f}, 真实 μ = {mu}") print(f"误差: {abs(mu_learnable.item() - mu):.6f}")...
-
4. PINN在机载系统中的应用
4.1. 结构健康监测系统 (SHM) 与疲劳评估
机载结构系统(如机翼、机身、起落架)在服役中会承受复杂的交变载荷。
-
全域应力场重构: 在飞机上布置高密度传感器是不现实的。PINN 可以利用机身表面少量、稀疏的应变计传感器数据,结合线弹性力学方程(作为物理损失),精确“内插”和计算出整个结构的三维应力/应变场。
-
逆问题与损伤检测: PINN 极其擅长求解逆问题。可以通过表面观测到的振动响应或应变异常,反演推断出结构内部参数的变化(如刚度下降),从而实现对微裂纹、脱粘或腐蚀等隐蔽损伤的实时定位与定量评估。
4.2. 机载热管理与环境控制系统 (ECS)
现代大型客机的用电设备功率越来越大,热管理成为核心瓶颈。
-
高热流密度组件的温度场预测: 针对雷达、高功率电子舱,PINN 可以求解对流传热方程(Navier-Stokes 与能量方程的耦合)。将少量的热电偶测温数据输入模型,PINN 能够实时输出整个设备舱的三维温度分布,帮助系统动态调整冷却液流速或风扇转速。
-
结冰与防除冰系统: 飞机在复杂气象条件下极易结冰。利用 PINN 模拟水滴撞击、热量传递和相变过程,可以帮助优化机翼前缘电热除冰系统的加热策略。
4.3. 航空发动机与推进控制系统
发动机是飞机的“心脏”,其内部涉及极端的流体、燃烧和热力学过程。
-
实时降阶模型 (ROM) / 代理模型: 传统的 CFD(计算流体力学)仿真极其缓慢,无法用于机载计算机的实时控制。PINN 可以通过离线学习 N-S 方程,生成高保真、低延迟的代理模型。一旦训练完成,机载计算机能在毫秒级时间内预测压气机或涡轮的内部流场状态,甚至预测喘振裕度。
-
数字孪生 (Digital Twin): 结合飞行数据实时微调发动机的 PINN 模型,可以打造伴随飞机全生命周期的数字孪生体,用于预测性维护(Predictive Maintenance),判断涡轮叶片何时需要大修。
4. 空气动力学与气动伺服弹性 (Aeroservoelasticity)
飞行控制系统需要极其精准的气动力数据。
-
流固耦合实时计算: 当飞机发生颤振(大柔度机翼的振动)时,气动力和结构变形会互相耦合。利用 PINN 融合飞行测试数据与空气动力学方程,可以更准确地评估飞行包线边界,为主动控制系统(如主动阵风减缓系统)提供超前预测。
-
基于尾迹的反演: 可以通过机载大气数据传感器(如空速管数据),利用 PINN 反推飞行器周围的整体流场状态,甚至是迎角和侧滑角的精确分布。
5. 机载电气与电源系统 (特别是多电/全电飞机)
-
电池健康与热失控预警: 全电飞机的核心是高能电池组。PINN 可以用来求解电池内部的电化学-热耦合方程(如 P2D 模型)。结合 BMS(电池管理系统)实时测量的电压、电流和表面温度,精确推演电池内部核心温度,提前预警热失控。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)