强化学习4.2:基于价值——DQN算法
概念
DQN,即深度Q网络(Deep Q-network),是指基于深度学习的Q-Learning算法。
在传统的Q-learning中,我们需要维护一张巨大的表格(Q表)来记录在每一个状态下,采取每一个动作能得到的未来奖励总和。但现实世界的状态是无穷无尽的(比如游戏画面中像素的无数种组合),根本无法用一张有限的表格来记录。
DQN使用一个深度神经网络来近似替代这张Q表,这个神经网络被称为Q网络。DQN用神经网络 Q(s,a;θ)来拟合最优动作价值函数 Q∗(s,a)。网络的输入是状态 s(例如游戏原始像素帧),输出是为每个动作计算出的 Q值,网络的目标是让预测的Q值逼近真实的长期期望回报
简单来说,DQN 就是把传统 Q-Learning 里的那张“Q 表”换成了一个深度神经网络
核心创新
A.经验回放 (Experience Replay)
-
问题:强化学习的数据是前后关联的(比如开车的连续画面)。神经网络如果按顺序学习,容易产生严重的过拟合。
-
对策:设置一个记忆库(Replay Buffer)。智能体把经历过的
存进去。训练时,从库里随机抽取一个小批量(Mini-batch)数据。
-
好处:打破了数据间的相关性,让数据分布更平稳,就像让网络“温故而知新”。
B.目标网络 (Target Network)
-
问题:在更新
时,我们的目标是
。如果只用一个网络,你更新参数
的同时,目标值也在动。这就像“一边跑一边画终点线”,网络很难收敛。
-
对策:准备两个一模一样的网络:
-
估计网络 (Policy Network):负责计算当前
-
目标网络 (Target Network):负责计算目标
固定不动
-
-
操作:每隔几千步,才把估计网络的参数同步给目标网络。这保证了在一段时间内,“终点线”是固定的。
核心公式
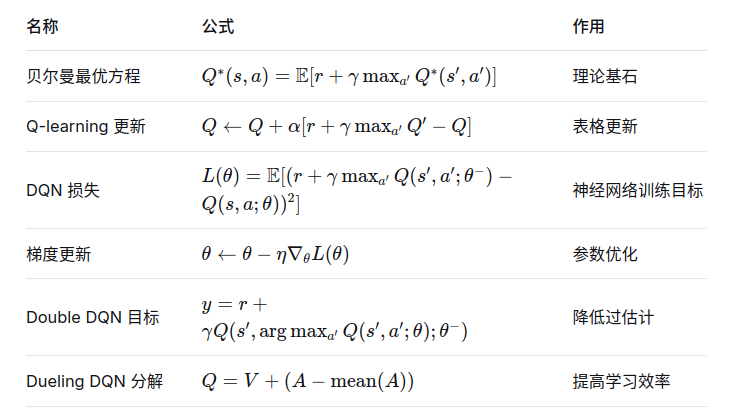
算法流程
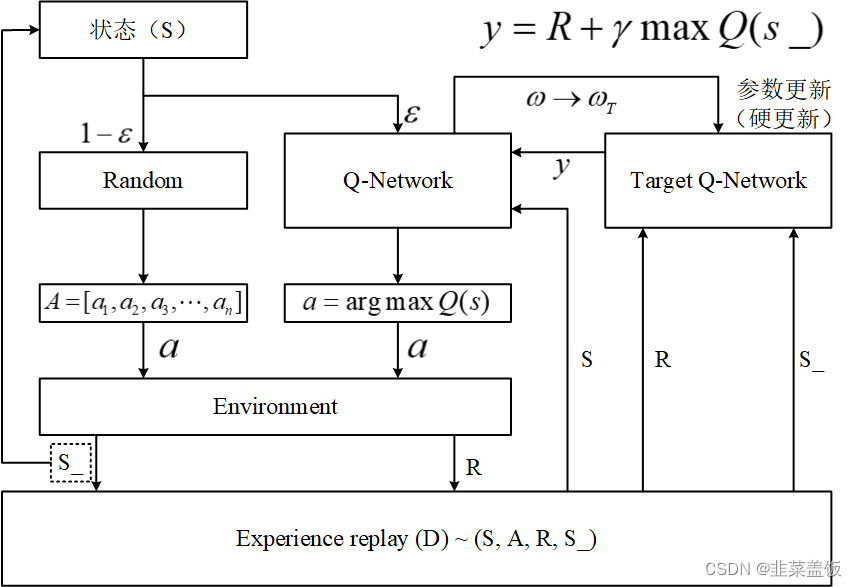
初始化: 准备好记忆库D,在线网络参数θ(随机),目标网络参数θ⁻(=θ)
对于每个episode:
获取初始状态s
对于每一步:
选择动作:用ε-greedy策略/随机试错/选Q值最大的动作
执行动作a,获得奖励r和下一状态s',将元组(s, a, r, s')存储到D中
从D中随机采样一小批元组
对每个样本,若episode结束,则目标值
否则,(注意,这里用的是目标网络)
对损失函数执行一次梯度下降,更新在线网络θ
每C步,将在线网络参数θ同步给目标网络:
重复步骤4,直至episode结束
重复步骤2,直至模型收敛
代码实现
import gymnasium as gym
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
from collections import deque
import random
# 超参数
ENV_NAME = 'CartPole-v1' # 环境名称
GAMMA = 0.99 # 折扣因子
LR = 1e-4 # 学习率
BATCH_SIZE = 64 # 批量大小
MEMORY_SIZE = 10000 # 经验池容量
EPSILON_START = 1.0 # 初始探索率
EPSILON_END = 0.01 # 最小探索率
EPSILON_DECAY = 2000 # 探索率衰减步数(线性衰减)
TARGET_UPDATE = 50 # 目标网络更新频率(步数)
NUM_EPISODES = 800 # 训练的总回合数
MAX_STEPS = 500 # 每个回合的最大步数
# 判断是否使用GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 1. 定义Q网络(简单的全连接网络)
class QNetwork(nn.Module):
def __init__(self, state_size, action_size):
super(QNetwork, self).__init__()
self.fc1 = nn.Linear(state_size, 64)
self.fc2 = nn.Linear(64, 64)
self.fc3 = nn.Linear(64, action_size)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
return self.fc3(x)
# 2. 经验回放缓冲区
class ReplayBuffer:
def __init__(self, capacity):
self.buffer = deque(maxlen=capacity)
def push(self, state, action, reward, next_state, done):
self.buffer.append((state, action, reward, next_state, done))
def sample(self, batch_size):
batch = random.sample(self.buffer, batch_size)
state, action, reward, next_state, done = zip(*batch)
return (np.array(state), np.array(action), np.array(reward, dtype=np.float32),
np.array(next_state), np.array(done, dtype=np.uint8))
def __len__(self):
return len(self.buffer)
# 3. 初始化环境、网络、优化器和经验池
env = gym.make(ENV_NAME)
state_size = env.observation_space.shape[0]
action_size = env.action_space.n
policy_net = QNetwork(state_size, action_size).to(device)
target_net = QNetwork(state_size, action_size).to(device)
target_net.load_state_dict(policy_net.state_dict())
target_net.eval() # 目标网络不训练
optimizer = optim.Adam(policy_net.parameters(), lr=LR)
memory = ReplayBuffer(MEMORY_SIZE)
steps_done = 0 # 用于epsilon衰减
# 4. 选择动作的epsilon-greedy策略
def select_action(state, epsilon):
if np.random.random() < epsilon:
return env.action_space.sample() # 随机探索
else:
with torch.no_grad():
state = torch.FloatTensor(state).unsqueeze(0).to(device)
q_values = policy_net(state)
return q_values.argmax().item()
# 5. 训练步骤
def optimize_model():
if len(memory) < BATCH_SIZE:
return
# 从经验池采样
states, actions, rewards, next_states, dones = memory.sample(BATCH_SIZE)
states = torch.FloatTensor(states).to(device)
actions = torch.LongTensor(actions).unsqueeze(1).to(device)
rewards = torch.FloatTensor(rewards).unsqueeze(1).to(device)
next_states = torch.FloatTensor(next_states).to(device)
dones = torch.FloatTensor(dones).unsqueeze(1).to(device)
# 计算当前Q值
current_q = policy_net(states).gather(1, actions)
# 计算目标Q值:贝尔曼最优方程
with torch.no_grad():
next_q = target_net(next_states).max(1, keepdim=True)[0]
target_q = rewards + (GAMMA * next_q * (1 - dones))
# 计算损失
loss = nn.MSELoss()(current_q, target_q)
# 优化
optimizer.zero_grad()
loss.backward()
# 梯度裁剪,防止梯度爆炸
for param in policy_net.parameters():
param.grad.data.clamp_(-1, 1)
optimizer.step()
# 6. 主训练循环
episode_rewards = []
for episode in range(NUM_EPISODES):
state,info = env.reset()
total_reward = 0
epsilon = max(EPSILON_END, EPSILON_START - steps_done / EPSILON_DECAY)
for t in range(MAX_STEPS):
# 选择动作
action = select_action(state, epsilon)
# 执行动作
next_state, reward, terminated, truncated, _ = env.step(action)
done = terminated or truncated
total_reward += reward
# 存储经验
memory.push(state, action, reward, next_state, done)
state = next_state
steps_done += 1
# 训练模型
optimize_model()
if done:
break
# 更新目标网络
if episode % TARGET_UPDATE == 0:
target_net.load_state_dict(policy_net.state_dict())
episode_rewards.append(total_reward)
print(f"Episode {episode}, Reward: {total_reward}, Epsilon: {epsilon:.3f}")
print("训练完成!")
# 7. 测试训练好的策略
def test(episodes=5):
for episode in range(episodes):
state, info = env.reset()
total_reward = 0
while True:
env.render() # 如果渲染出错,可以注释掉或设置 render_mode
action = select_action(state, epsilon=0.0)
next_state, reward, terminated, truncated, _ = env.step(action)
done = terminated or truncated
state = next_state
total_reward += reward
if done:
break
print(f"Test Episode {episode}, Reward: {total_reward}")
env.close()
test()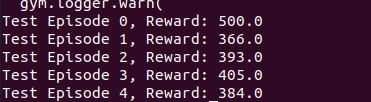

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)