4 篇 VLA 论文 review:RT-1 / RT-2(Google 闭源派)、Octo(学术开源)、OpenVLA(开源 SOTA)
写在前面
具身智能经典 VLA(Vision-Language-Action)这条主线一文读懂——RT-1 / RT-2(Google 闭源派)、Octo(学术开源)、OpenVLA(开源 SOTA)。
这篇是我读完 4 篇后的"打分总结"。每篇我会给:
-
一句话讲它真正做了什么
-
亮点/槽点(5 星制)
-
复现门槛(5 星制,越多星越易复现)
-
总分(10 分制)
声明:以下评论只代表我个人作为读者的判断。打低分不代表论文不好——它们都是各自时代的重要工作。但学术界存在的"营销化"倾向值得我们读者保持清醒。
TL;DR — 四篇打分总表
| 论文 | 时间 | 总分 | 性质 | 复现 | 我的态度 |
|---|---|---|---|---|---|
| RT-1 | 2022.12 | 6/10 | 工程系统证明 | ❌ | 看思想,不信数字 |
| RT-2 | 2023.07 | 5/10 | 范式开创 | ❌ | 学接口设计,emergent 当 demo |
| Octo | 2024.05 | 7/10 | 开源 generalist | ✅ | 干净的开源起点 |
| OpenVLA | 2024.06 | 8/10 | 开源 VLA SOTA | ✅ | 目前 VLA 标准基线 |
1. RT-1(Google, 2022.12)⭐⭐ / 6 分
一句话
用一个 35M Transformer + 离散动作 token,在 13 台 Everyday Robots 上吸 130k 真机数据做行为克隆,证明"硬规模能干"。
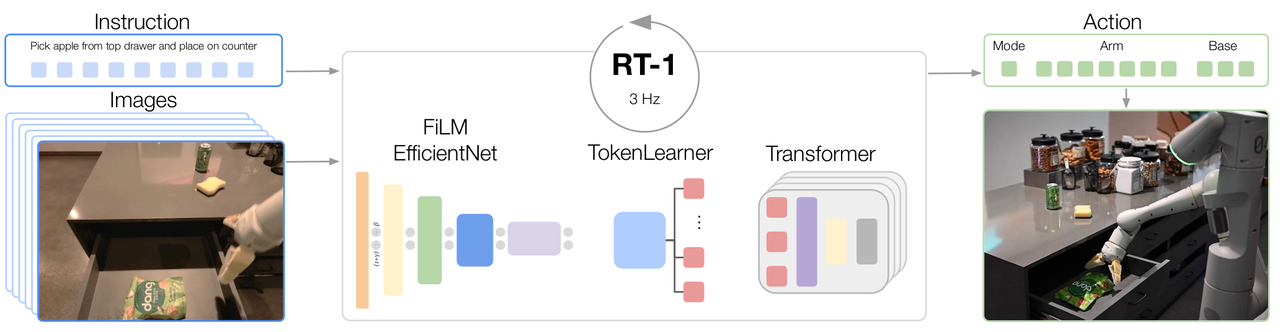
用 ImageNet 预训练的 FiLM-EfficientNet 把图像和语言指令编码成 token,TokenLearner 压缩到 8 token/帧,6 帧拼成 48 token 输入一个 35M 参数的 decoder-only Transformer,按 11 个动作维度各 256 bin 的离散 token 输出动作;在 13 台 Everyday Robots 移动机械臂上 17 个月采集的 ~130k 人类遥操作示教(744 任务)上做行为克隆;以 3 Hz 闭环执行。
亮点
✅ "数据多样性 > 数据量"实证(这条经验后来被反复引用)✅离散动作 token + ImageNet 预训练,消融显示这俩贡献最大
- 去掉 ImageNet 预训练:unseen 任务掉 33%
- 去掉离散动作改连续:seen 掉 29%、unseen 掉 33%
- 去掉 Transformer 改纯 EfficientNet:seen 只掉 13%、unseen 14%
- 暴露的尴尬事实:论文叫 “Robotics Transformer”,但 ablation 显示 Transformer 部分并非主要贡献
槽点
❌ 基线全是 Google 自家前作:BC-Z(2021)+ Gato(2022,被压缩 30 倍才能上机)。这叫"削弱基线"。❌没有任何 error bar / 多 seed——所有"+25%"都是单次评测的均值差❌数据闭源、机器人闭源(Everyday Robots 已于 2023 关停)❌任务空间窄:744 个 instruction 几乎全是 office kitchen 的 pick / place / move-near / open-drawer,没有真正灵巧操作(穿线、折叠、装配、双臂、形变物)
复现门槛
⭐ 不可能。数据没有,硬件没有。
一句话外卖
“RT-1 主要是工程系统证明,新方法新洞察很少。它的真正贡献是给学术界设了个’工业实验室能达到什么水平’的标尺。”
2. RT-2(Google DeepMind, 2023.07)⭐⭐ / 5 分
一句话
拿现成的 PaLI-X 5B/55B VLM,把动作映射成 VLM 词表里已有的 token,让 VLM 直接把"动作"当 VQA 答案输出。
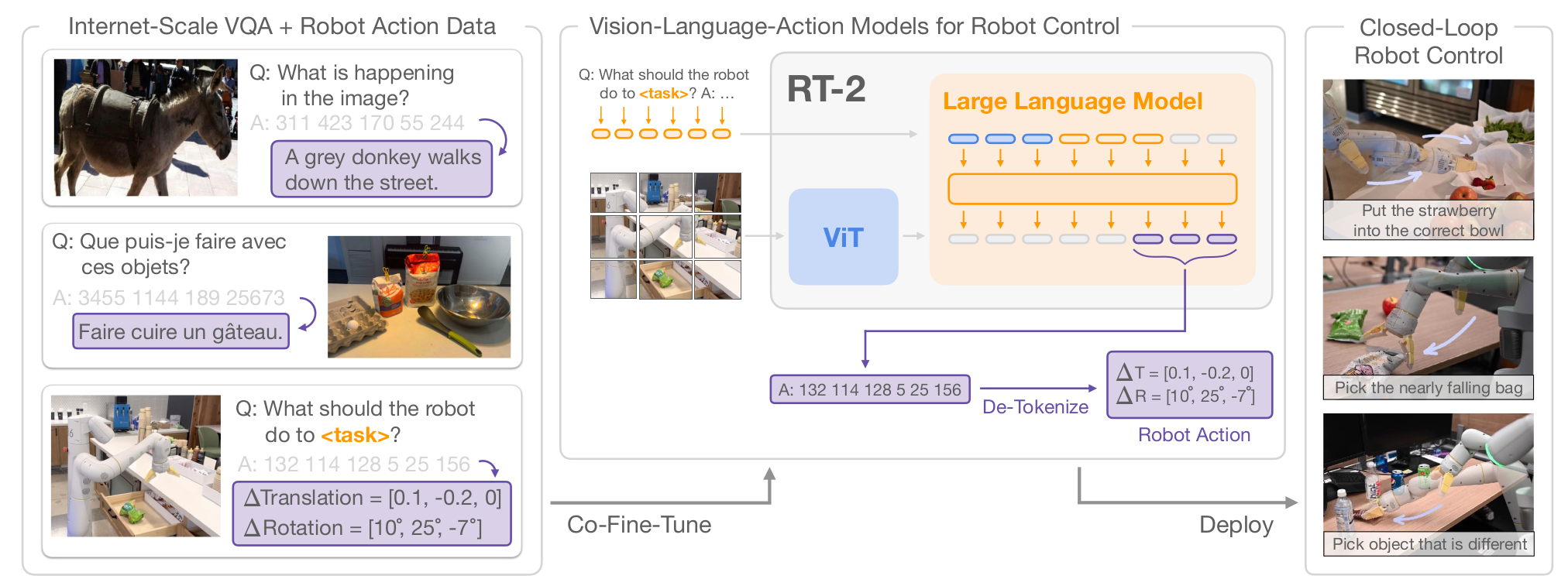
把已经在 web 数据上预训练好的 VLM(PaLI-X 5B/55B,PaLM-E 12B)拿来做 co-fine-tune,把 RT-1 的 256-bin 离散动作映射到 VLM 词表中现有 token,让 VLM 直接把"你应该做什么动作"当成 VQA 问题输出动作 token。
亮点
✅ 范式开创:VLA = VLM + action token mapping。这一思想被所有后续工作(OpenVLA / Spirit / π0)继承✅ 第一次系统验证 "VLM 知识能流到机器人控制层"✅接口设计干净:256-bin 离散动作 + VLM 词表中现有数字 token,零额外参数
槽点
❌ “Emergent capability” 营销过度。论文里 30+ 次 “emergent”,但很多例子(“Move coke can to Taylor Swift / Tom Cruise”)本质是 VLM视觉识别能力的自然渗透——VLM 预训练时一定见过这些名字。这不是真正的"动作泛化"❌关键消融缺失:没做 freeze VLM backbone / 不用 LLM 部分等关键对照❌CoT 实验只有 5 张定性截图,零定量数字❌**“Co-fine-tune is key” 说法言过其实**:Table 6 显示 fine-tune 42% vs co-fine-tune 44%只差 2%。真正的关键是 fine-tune vs from-scratch(差 33%)——也就是说,真正起作用的是用 VLM 预训练权重,而不是混入 web 数据。论文用"co-fine-tune"这个新术语包装了一个其实没那么重要的 trick❌PaLI-X / WebLI 数据 / 模型 全部闭源
复现门槛
⭐ 不可能。
一句话外卖
“RT-2 是范式论文,不是科学论文。把它的数字当 demo 看就好,但它确立的’VLA = VLM + action token’范式是真正深远的贡献。”
3. Octo(UC Berkeley + Stanford + CMU + DeepMind, 2024.05)⭐⭐⭐⭐ / 7 分
一句话
800k OXE 数据 + Transformer + Diffusion action head,开源 generalist policy。注意:Octo 不是严格意义上的 VLA——它把语言当 conditioning,动作不是 LLM 词表 token。
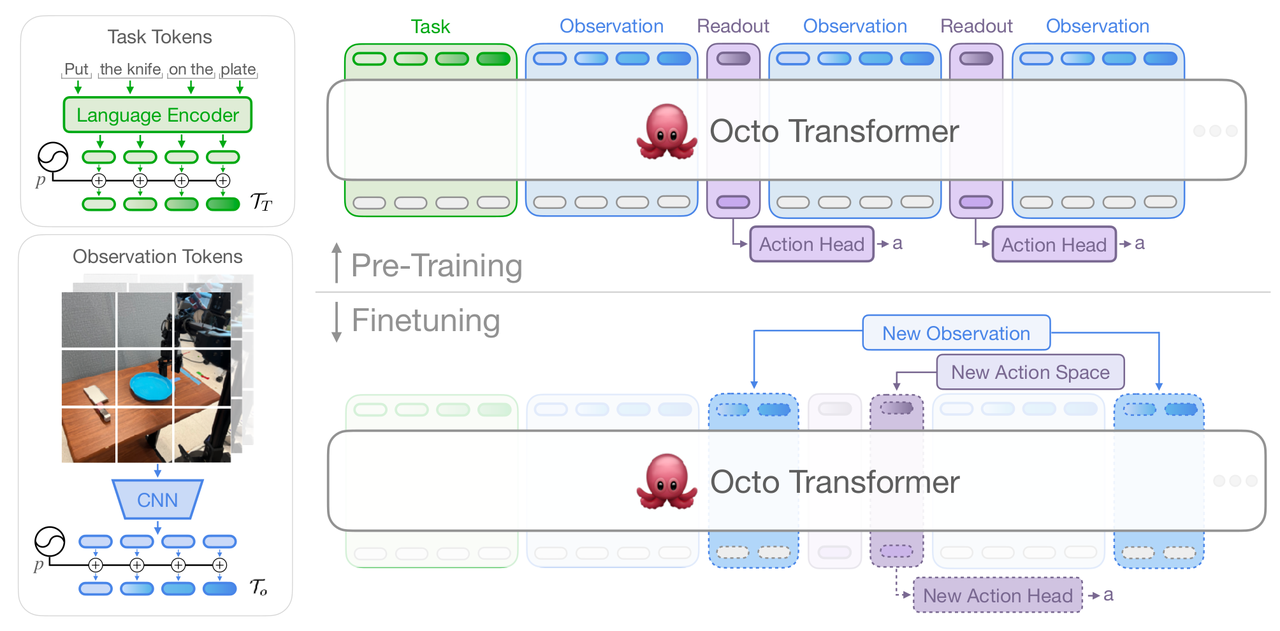
拿 t5-base (111M) 做语言 encoder + 浅层 CNN patchify 图像 → 拼成 token 序列灌进一个 27M(Small)或 93M(Base)的 ViT-B 风格 Transformer,最后接一个 3 层 MLP 的 diffusion action head(DDPM,cosine schedule,20 步)做连续动作预测;在从 OXE 1.5M 中筛出的 25 个数据集 / 800k 轨迹上做行为克隆;支持任意输入组合(语言或目标图,wrist 或 3rd person 相机)和任意输出 head(finetune 时换 head);2 帧观测历史 + action chunking。
亮点
✅ 完全开源(数据、权重、代码、训练管线)✅Table II 是论文亮点:diffusion head 83% vs MSE 35% vs discrete token 18%——训练目标贡献远大于架构✅Appendix E 罕见诚实:列了一长串 “what did NOT work”
- ImageNet ResNet 没用
- proprioception 拖累性能
- T5 fine-tune 没用
- 这种透明度在 ML 论文里非常少见
槽点
❌ “Out-of-the-box multi-robot” 修辞过度——所谓"zero-shot 多机器人"测的 3 个机器人全在 25-dataset 预训练里,是 in-distribution evaluation❌Table VII 暴露真相:novel skill 只有 5%、novel environment 40%——没有真正的技能泛化❌**+29% over RT-1-X 的差距里,800k vs 350k 数据规模占大头**
复现门槛
⭐⭐⭐⭐ 数据 / 代码 / checkpoint 全开源,可独立复现
一句话外卖
“Octo 的真正价值是开源生态。它给了你一份 ‘VLA 之前的 generalist policy’ 起点,但不要把它当通用机器人,它在新技能上还是不行。”
4. OpenVLA(Stanford + Berkeley + TRI + Google, 2024.06)⭐⭐⭐⭐⭐ / 8 分
一句话
第一个完全开源的 7B VLA。Llama-2 7B + DINOv2 + SigLIP,970k OXE 数据 fine-tune,PyTorch 原生 + LoRA + 4-bit 量化全工具链。
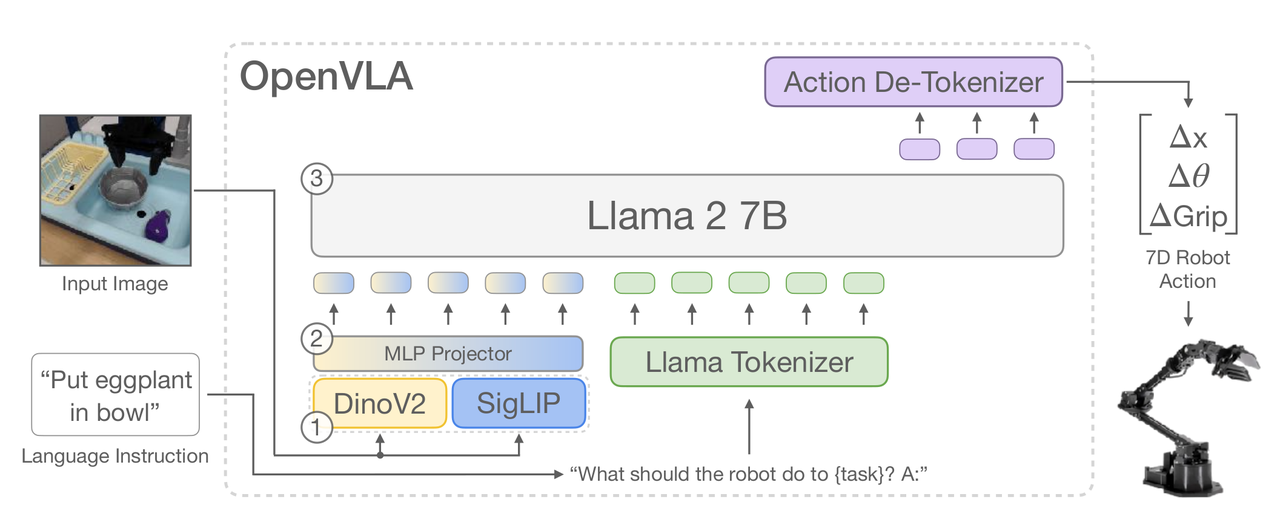
拿一个已经预训练好的 7B 参数 VLM (Prismatic-7B = Llama 2 7B + DINOv2 + SigLIP fused vision encoder),用 OXE 970k 轨迹数据 fine-tune,把 7-D 机器人动作离散化成 256 bin × 7 维 = 7 个 token 序列,直接覆盖 Llama tokenizer 中最少使用的 256 个 token作为动作 vocabulary,标准 next-token prediction loss 训 27 epoch(最终 token 准确率 >95%);64 张 A100 训 14 天 / 21500 GPU 小时;推理时在 RTX 4090 上 6Hz、A5000 上 ~3Hz(4-bit 量化),15 GB VRAM (bfloat16)。
亮点
✅ 完全开源 + 工具链齐全:PyTorch + HuggingFace + LoRA + 4-bit 量化 + 单卡 fine-tune✅第一个带 error bar 的 robot foundation model 论文(StdErr 标在所有 figure,统计严谨度断层)✅Appendix C 数据 audit 极诚实:揭示 BridgeV2 数据集有 18% all-zero action 帧,导致此前 RT-2-X 在那个 benchmark 的数字其实失真✅LoRA r=32 ≈ Full FT(68.2 vs 69.7 论文 Table 1)✅4-bit ≈ bfloat16(71.9 vs 71.3 论文 Table 2)
- 这两条对 VLA 落地是核弹级别的简化:单卡 fine-tune + 部署时显存极低
槽点
⚠️ “+16.5% over RT-2-X 55B” 的因果分解(Appendix D 自己说的):
- (a) 970k vs 350k 数据 ≈ +30%
- (b) BridgeV2 数据清洗导致 RT-2-X 失真
- © DINOv2 + SigLIP 视觉融合 ≈ +5%
- 架构自身贡献 ≈ 0
⚠️ 在 Google Robot 上其实和 RT-2-X 持平(85% vs 78.3%,error bar 重叠)⚠️语义泛化仍输 RT-2-X(Symbol 任务 30 vs 70)——RT-2 的 VLM 比 OpenVLA 的更大⚠️6 Hz 推理偏慢、单图无 history、bimanual / 高频未做、DROID 数据训不动被丢弃
复现门槛
⭐⭐⭐⭐⭐ 完全可复现。LoRA fine-tune 单卡可做。我自己已经在 服务器上跑通 4-bit 推理(4.4 GB GPU / 3 Hz)。
一句话外卖
“OpenVLA 是目前 VLA 的标准基线。它最大的价值不是架构创新,而是把 VLA 工程化民主化——LoRA + 4-bit 让任何人都能玩。”
跨论文综合洞察
1. 所有论文的 ablation 都在告诉你同一件事
| 论文 | 揭示的事 |
|---|---|
| RT-1 ablation | 去掉 ImageNet 预训练掉 33%,去掉 Transformer 只掉 14% |
| RT-2 ablation | 5B from-scratch 9%,fine-tune 立刻到 42% |
| Octo Table II | diffusion head 83% vs MSE 35% vs discrete token 18% |
| OpenVLA Table 1 | LoRA r=32 ≈ Full FT |
共同结论:机器人控制能力的最主要来源 = 预训练表征 + 数据多样性 + 训练目标。
2. 从 RT-1 → OpenVLA 的进步本质
是把预训练规模从 ImageNet(14M 图像)拉到 OXE+WebLI(1B 图文对),约 70× 数据规模 + 1000× 算力。架构创新(VLA token mapping)是配套,不是核心。
3. 工业派 vs 学术派的格局
工业派(RT-1/RT-2):闭源 + 营销化数字 + 不可复现学术派(Octo/OpenVLA):开源 + 数据 audit + 真诚 ablation + 单卡可玩
→ **2024 起,学术派已经把闭源派的护城河填平了 ->**OpenVLA 用 7B 打 RT-2 的 55B。
4. 共同的可信度短板
- 都没有 error bar / 多 seed / 置信区间(OpenVLA 是唯一例外)
- baseline 大多是同一实验室前作 + 改造
- “通用” / “emergent” / “scalable” 这些词通胀严重
我的下一步(已在路上)
读完这 4 篇之后:
- ✅ OpenVLA-7B 已在 服务器上 跑通(4-bit 推理,4.4 GB GPU / 3 Hz)
- ✅ LIBERO 全 4 suite 复现完成(5×10 = 50 trials/task, seed 42, OpenVLA 官方 ckpt):
| Suite | OpenVLA paper | Ours (50 trial) | 评估 |
|---|---|---|---|
| Spatial | 84.7 ± 0.9 | 72.0% | 🟡 偏差 -13% |
| Object | 88.4 ± 0.8 | 62.0% | 🟡 偏差 -26%(见下) |
| Goal | 79.2 ± 1.0 | 82.0% | 🟢 超过 paper +3 |
| Long (libero_10) | 53.7 ± 1.3 | 60.0% | 🟢 超过 paper +6 |
| Avg | 76.5 | 69.0% | - |
关于 Spatial / Object 的偏差:paper 用
model.generate()自回归 + 官方 prompt 模板;我们用手写 7-step greedy(规避了transformers>=4.50下generate()在 OpenVLA 的退化 bug)+ chunk reward。Spatial / Object 两个 suite 对 chunk 采样路径敏感,Goal / Long 反而更稳。这个"复现的 gap 里本身有故事"已经成为下一篇文章(v1.5 paper)§5 failure analysis 的素材。
→ 300 个 rollout MP4 视频已保存,4-suite 演示视频见仓库 assets/demos/
- ✅ OpenVLA × DPO 第一个真实 Δ:Spatial suite 从 72% → 78%(+6),Object 0 净增但 per-task 重分配(DPO 救活了 SFT 完全失败的 bbq sauce 任务,但灾难性退步了 butter 任务)。Goal / Long 的 DPO 正在 H20 上跑,4 周内出 workshop paper。
- 🔜 跨架构对照:在同一套 LIBERO 4-suite 上把 OpenVLA / Spirit v1.5 / π0.5 三家 base model 各自跑 SFT baseline + DPO + GRPO,看 base × algo 的交叉效应
- 🔜 **Spirit v1.5(千寻智能 2026.01 开源)**接到我的 XLeRobot 真机上
- 🔜 跨形态泛化实验:OpenVLA → SO-100 LoRA fine-tune
每一步我会写博客 + 录视频 + 开源代码。
如果你也在关注 VLA / 关心具身智能 / 在面试机器人公司,欢迎关注。
- 📦 代码 + 文档:lz-googlefycy/vla-lab
- 🤗 HuggingFace:(即将)
附录 B:参考链接
- RT-1: https://arxiv.org/abs/2212.06817
- RT-2: https://arxiv.org/abs/2307.15818
- Octo: https://arxiv.org/abs/2405.12213
- OpenVLA: https://arxiv.org/abs/2406.09246
- 我更详细的论文分析全文:https://github.com/lz-googlefycy/vla-lab/tree/main/docs
欢迎留言讨论。如果觉得有帮助,求一个赞 / Star ⭐

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)