【大模型】深度拆解 Harness 七层架构:为什么别人家的 AI 那么稳,你的总在翻车边缘
疑问拆解Harness七层架构
1、引言
小屌丝:鱼哥,你上次说 Harness 不是某一个组件,是套在模型外面的一整套系统。道理我懂了,但具体是哪些东西?我该从哪下手?
小鱼:问得好。今天就给你拆开——我把 Harness 拆成了七层,每一层都讲清楚它是什么、干什么、在 Claude Code 里对应什么、你该怎么落地。看完这张图,你就知道自己目前卡在哪一层。
小屌丝:七层?这么多?
小鱼:别怕。不是每一层都需要你从零搭建。如果你用的是 Claude Code 这类成熟工具,很多层它已经帮你做了。但你得知道它们的存在,才能在出了问题的时候,知道往哪使劲。
小屌丝:行,小板凳搬好了。

2、先看全貌:Harness 七层架构总图
整个流程分三个阶段:输入处理 → 模型推理 → 输出验证。
下面一层一层拆。读完别急着全部落地,先诊断自己卡在哪一层。

3、输入处理阶段:模型看到什么,决定它能做什么
3.1 第一层:认知层 — 角色·范围·约束
它解决什么:模型知不知道自己是谁、该干什么、不该干什么。
听起来简单,但大部分人在用 AI 的时候,这层是空的。打开对话框就开始提需求,模型完全不知道你的项目背景、技术栈、代码规范,它只能靠猜。
在 Claude Code 里,认知层对应的就是 CLAUDE.md。
你在项目根目录放一个 CLAUDE.md,写清楚:这个项目用什么技术栈、代码风格是什么、有哪些不能碰的东西、测试怎么跑。模型每次启动都会读到这些信息,相当于你给它发了一份“入职手册”。
一个典型的 CLAUDE.md 示例:
# 项目认知配置
- 技术栈:Tauri v2 + React 19 + Rust
- 前端:TypeScript 严格模式,函数式组件,禁用 class 写法
- 状态管理:Zustand
- 测试:Vitest,覆盖率要求 > 80%
- 禁止:不允许使用 any 类型,不允许直接操作 DOM
这些写了之后,模型生成的代码风格就跟项目一致了,不用每次手动纠正。认知层做得好不好,决定了后面所有层的起点。就像给新员工的入职培训——第一天没讲清楚,后面天天在纠错。
小屌丝:原来那个文件这么重要?我之前都是空的。
小鱼:大部分人都这样,这就是第一层没建好。
3.2 第二层:工具层 — 排序·去重·截断
它解决什么:模型能用哪些工具,工具返回的信息怎么处理。
这里有个关键词:截断。
模型的上下文窗口是有限的(虽然新模型已经很大了,但依然有限)。你让它搜一个代码库,搜出来 500 个结果,全塞进去?模型直接懵了。工具层要做的就是排序、去重、截断,把最相关的信息筛出来,控制在模型能消化的范围内。
Claude Code 内置了一整套工具:读文件、写文件、跑终端命令、搜代码、Glob 匹配、LSP 类型查询——这些本质上就是工具层。你不需要自己搭,但你需要知道它们的存在,才能在对话里有效地引导模型去用。
一个常见的对比:
| 指令方式 | 效果 |
|---|---|
“帮我找一下所有用到 getUserInfo 的地方” |
模型自动调用 Grep 工具精准搜索,一步到位 |
| “帮我优化一下代码” | 模型不知道该从哪开始找,可能乱搜一通 |
指令越具体,工具层的命中率越高。
核心原则:
- 工具数量要精简,单 Agent 建议少于 10 个高相关工具
- 工具返回结果要经过排序、去重、长度截断三道工序
- 敏感工具(删文件、发邮件、执行 SQL)必须加权限控制
3.3 第三层:契约层 — Schema·类型·校验
它解决什么:模型的输出必须符合什么格式。不是靠 Prompt 里写“请用 JSON 格式返回”这种祈祷式约束,而是用 Schema 做硬性校验。
这是很多人忽略的一层,但它可能是最影响输出质量的一层。
打个比方。你让模型帮你生成一个 API 接口的返回值,你在 Prompt 里说“请返回 JSON”——模型可能给你一个干净的 JSON,也可能返回一段解释文字加一个 JSON,还可能返回一个格式不对的 JSON。这就是“指令”的局限性:模型可以选择不听。
契约层要做的是:用结构化 Schema 硬约束模型的输出格式。
核心能力包括:
- JSON Schema 约束生成:确保输出 100% 符合指定结构
- 类型校验:整数字段不会返回字符串,必填字段不会被漏掉
- 格式自动修复:在模型输出不符合 Schema 时,启动重试或自动修复
- Pydantic / Zod 集成:在工程代码中直接用类型系统定义输出契约
到 2026 年,OpenAI、Anthropic、Google Gemini 都已原生支持 。OpenAI 的 Structured Outputs 在 strict 模式下,通过 grammar-constrained decoding 在生成层面直接限制 Token 概率分布,从数学上保证输出格式正确。
4、执行控制阶段:模型怎么干活
4.1 第四层:编排层 — 路由·循环·回退
它解决什么:模型要做一件事,该走哪条路、分几步走、失败了怎么办。
编排层是执行控制阶段的第一站,它的核心职责有三件事:
第一,路由(Routing) 。当一个任务进来,编排层要决定走哪条流水线。是直接生成答案?还是先检索再回答(RAG)?还是需要多 Agent 协作?
第二,循环控制(Loop Control) 。ReAct 模式的 Think → Act → Observe 循环就是编排层的典型实现。编排层要管循环深度(最多循环几步)、超时断路(循环太久直接截断)、死循环检测(连续 3 轮输出相同结果直接终止)。
第三,回退策略(Fallback) 。工具调用失败了怎么办?模型输出了非法格式怎么办?编排层不能“调一次失败就崩溃”。每次失败都应该有降级策略——换备用工具、简化任务重试、或者友好地向用户说明当前能力边界。
小屌丝:这不就是 ReAct 那套控制逻辑吗?
小鱼:对,ReAct Agent 就是编排层最常见的一种实现形态。但编排层不光管“怎么循环”,还管“走哪条路”和“摔了怎么爬起来”。你上次写那个 ReAct 循环里的 max_steps 就是编排层最基础的配置。
4.2 第五层:记忆与状态层 — 存储·检索·更新
它解决什么:Agent 跑长任务时,怎么记住前面发生的事情,怎么在不同会话之间保留关键信息。
大模型天生只有一种记忆——上下文窗口。窗口满了,前面的内容就被挤掉。这就是为什么你跑一个 24 小时的 Agent 任务,跑一半它就“忘了自己刚才在干什么”——不是模型变笨了,是上下文被挤没了。
记忆与状态层的核心组件包括:
会话内记忆(上下文管理) :哪些信息该保留在当前的上下文窗口中,哪些可以丢弃?上下文快满时,要有一个“压缩-摘要”机制,把关键信息凝练保留,次要信息丢弃。
跨会话记忆(向量数据库) :哪些信息需要跨会话持久化?用 Milvus、Chroma 等向量数据库存储历史记忆,下次 Agent 启动时可以语义检索。Anthropic 的 Managed Agents 已经示范了“Milvus 向量数据库 + Agent”的搭配方案。
状态持久化(工作流状态) :Agent 当前做到哪一步了?当前任务的状态快照保存在哪?任务中断后能不能从断点恢复?这需要状态机的支持,而不是简单存几个变量。
演进趋势:进入 2026 年,纯向量数据库已经不够用。“向量数据库 + 知识图谱”的双模混合架构正在成为企业级 Agent 记忆的标准方案——向量数据库负责模糊召回非结构化内容,知识图谱负责多跳关系推理。
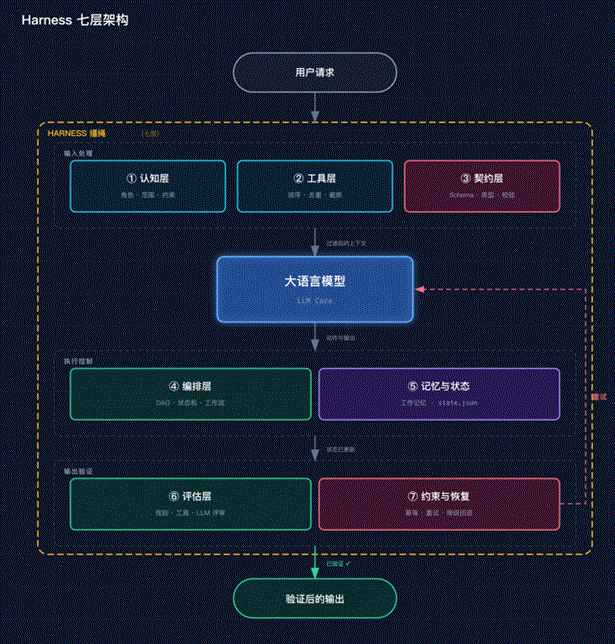
5、输出验证阶段:交付前最后关卡
5.1 第六层:评估层 — 打分·比对·评审
它解决什么:模型输出的东西到底对不对、好不好,不能凭感觉,必须有量化的评估机制。
评估层的职责不是“跑完就算完了”,而是建立一套持续验证的闭环。它像一条自动化质检流水线,持续对 Agent 的输出进行质量监控。
评估层要回答的核心问题:
| 评估维度 | 问题 | 工具/方法 |
|---|---|---|
| 格式合规 | 输出是否符合契约层定义的 Schema? | 自动 Schema 校验 |
| 内容质量 | 回答是否准确、完整、相关? | G-Eval、LLM-as-Judge |
| 幻觉检测 | 有没有编造事实、虚构引用? | SelfCheckGPT、RAGAS-faithfulness |
| 安全性 | 有没有泄露敏感信息、越权操作? | 敏感词扫描、权限校验 |
| 任务完成度 | 多步任务是否每一步都完成了? | 步骤完成率追踪 |
工程实践要点:
- 评估必须是自动化的,不能靠人工抽查
- 评估结果要驱动调整——评估不通过自动触发修正流程,形成 “规划-执行-评估-反馈-重做” 的完整闭环
- 评估层不参与执行,但它决定了哪个版本的 Agent 可以发布。“Eval Harness 是 Agent 的监考老师,它用数据化的指标消除开发者对模型能力的‘体感错觉’”
5.2 第七层:约束与恢复层 — 阻断·回滚·熔断
它解决什么:模型出错了、跑偏了、越权了,怎么办。这一层是整个 Harness 的最后一道防线。
约束与恢复层的核心机制:
约束(阻断越界) :
- 权限控制:Agent 能碰什么文件、能调什么 API、能访问什么数据库
- 行为边界:禁止执行高危命令(如
rm -rf、DROP TABLE) - 输出边界:敏感信息脱敏、禁止输出内容过滤
- 摩根大通的研究指出,具备处理不可信输入 + 访问敏感数据 + 外部操作权限这三项能力的 Agent,需要“强健、持续的强制执行和监控”
恢复(出错兜底) :
- 自动回滚:Agent 删错了文件?自动恢复到操作前的快照
- 熔断机制:Agent 连续失败 N 次?直接停掉,不让你继续烧 Token
- 降级策略:主模型不可用?自动切换到备用模型
- 人工介入:遇到无法自动处理的情况,暂停并通知人类审核
约束与恢复层是典型的“平时没存在感,出事时救命”的层。你可以把它理解为整个 Harness 的“安全气囊”——99% 的时间你看不到它,但那 1% 的时候它是唯一能救你的东西。
6、全貌总结:七层架构的底层逻辑
回过头来,七层架构的本质是什么?
在前面的三篇对话里,我们拆过 Agent 的四种设计模式和四种工作模式。七层架构将它们放在一张更大的图上:
输入三层的共同逻辑——“喂对东西”:认知层告诉模型它是谁、不该干什么;工具层管模型能拿什么信息、拿多少;契约层管模型输出必须长什么样。三层一起决定了“模型看到什么”,也就是决定了模型的上限。
中间两层——“管好干活的过程”:编排层管路由、管循环、管失败回退;记忆与状态层管记住什么、忘掉什么。两层一起决定了 Agent 能不能跑长任务、能不能在出问题时自愈。
输出两层——“守好底线”:评估层用量化指标告诉你做得好不好,约束与恢复层在出问题时兜底。前者帮你发现问题,后者帮你止损。
七层不是七座孤岛,而是一条流水线。 每一层出问题,都会传导到下一层。认知层没建好 → 模型方向偏了 → 后面的工具调用全白费 → 评估全挂。这就是为什么诊断比搭建更重要——你得先知道自己卡在哪一层,才知道该往哪使劲。
小屌丝:感觉七层搭完,工作量不小啊。
小鱼:不需要你一次性搭完。Claude Code 这类工具已经帮你做了大部分层(工具层、编排层、评估层它都有内建实现)。你真正需要从头搭建的,其实就是认知层(CLAUDE.md)、契约层(Schema 定义)、约束与恢复层(权限和安全兜底)。其他层,你在现有工具上做配置和扩展就行。关键不是“全搭完”,是知道每一层的存在,缺哪层补哪层。
我是小鱼:
- CSDN 博客专家;
- AIGC 技术MVP专家;
- 阿里云 专家博主;
- 51CTO博客专家;
- 企业认证金牌面试官;
- 多个名企认证&特邀讲师等;
- 名企签约职场面试培训、职场规划师;
- 多个国内主流技术社区的认证专家博主;
- 多款主流产品(阿里云等)评测一等奖获得者;

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)