干过深度学习检测项目才懂:我不是算法工程师,我是标注工程师
深度学习做视觉检测,为什么最后都卡在了“标注”上?
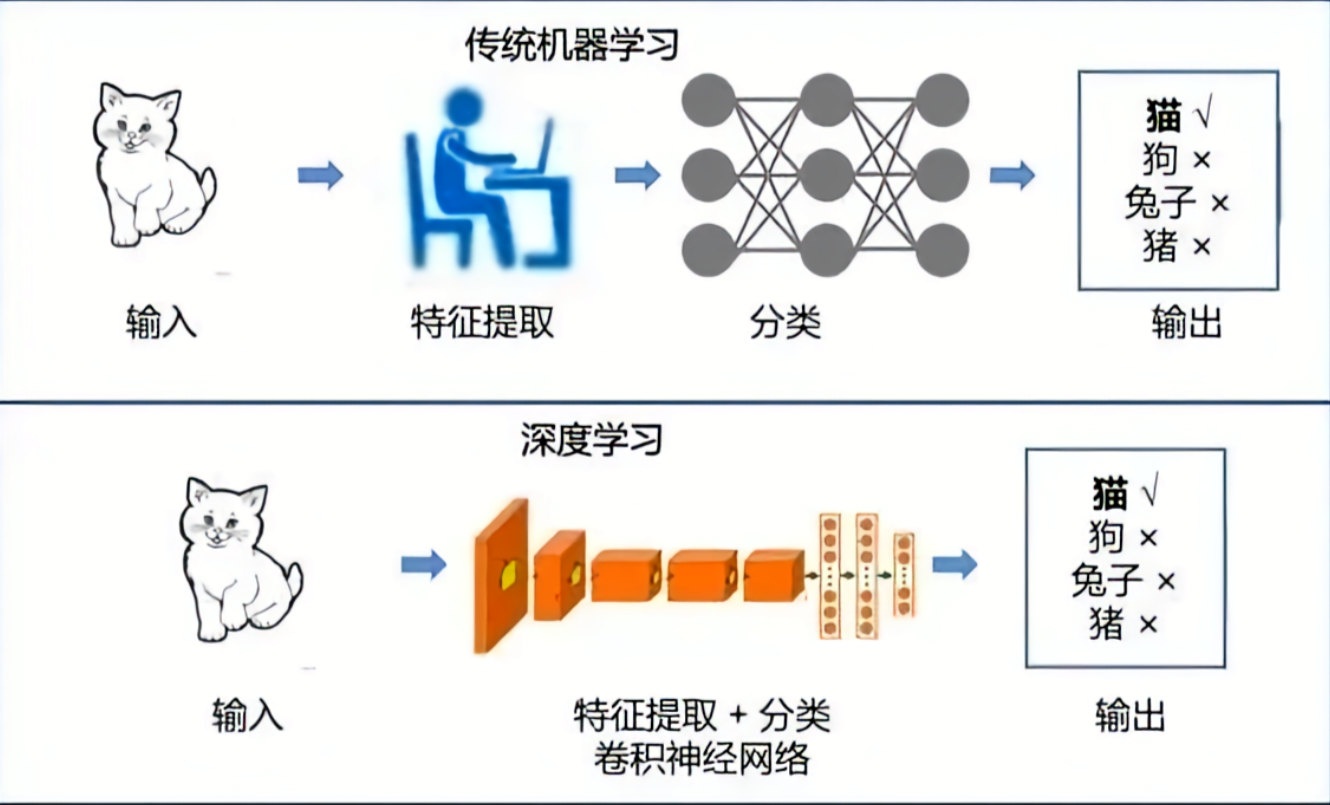
深度学习很强。
但它不是魔法。
尤其放到工业机器视觉现场,它的痛苦,往往从“标注”才刚刚开始。
很多人一听深度学习,就觉得高级、智能、自动化。
仿佛只要把图片丢进去,模型自己就能学会识别缺陷。
但真正做过项目的人都知道:
深度学习不是不用人,而是把很多人变成了标注工程师。
01
深度学习到底在工业视觉里干什么?
简单来说,深度学习就是让机器通过大量数据学习规律。
在工业机器视觉里,它常见的应用,就是让机器“看图识缺陷”。
比如识别:
划伤。
脏污。
破损。
变形。
异物。
表面异常。
通过不断喂给模型图片和对应标注,让它慢慢学会判断什么是良品,什么是缺陷。
听起来很美好。
但真正进入项目现场,你会发现第一个问题马上来了:
数据谁来准备?缺陷谁来标?标准谁来定?
02
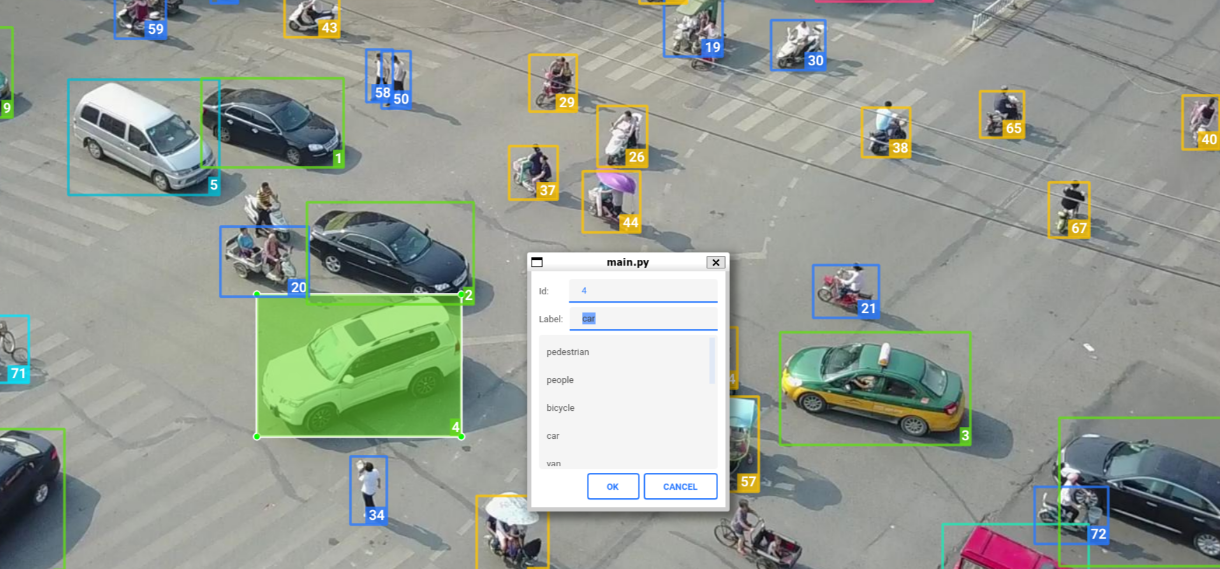
深度学习最累的不是训练,而是标注
很多人以为,深度学习项目的核心是算法。
实际上,很多工业视觉项目里,最消耗人的,往往是标注。
每一张图。
每一个缺陷。
每一处边界。
每一种类别。
都要人工确认。
你不能随便框。
不能框错。
不能漏标。
也不能今天一个标准,明天一个标准。
否则模型学到的东西就会乱。
这也是为什么很多项目做着做着,工程师会发现:
自己每天不是在做算法,而是在打标签。
一开始以为自己是机器视觉工程师。
后来发现自己是标注工程师。
最后变成了“标注返工工程师”。
03
纯靠标注输入,过程很容易失控
深度学习在工业检测中的一个大问题是:
输入过程不可控。
传统视觉方法虽然有局限,但很多逻辑是明确的。
阈值怎么设。
边缘怎么提。
面积怎么筛。
形态学怎么处理。
这些步骤相对可解释。
但深度学习更多依赖数据驱动。
你给它什么样的数据,它就学什么样的规律。
如果标注不准,模型就会学偏。
如果样本不全,模型就会漏检。
如果数据分布不均,模型就会误判。
如果缺陷类型变化,模型可能又要重新训练。
更痛苦的是,很多问题不是一开始就暴露。
模型训练时看起来效果不错。
一到现场,换一批产品、换一个光照、换一个批次,问题就出来了。
这时候你才发现:
模型不是不聪明,而是它只学会了你给它看的那一部分世界。
04
过拟合:训练集很好看,现场很难看
深度学习项目里,还有一个常见问题:
过拟合。
什么意思?
就是模型在训练数据上表现很好,但到了真实现场,效果明显下降。
训练集准确率很漂亮。
验证结果看起来也不错。
汇报材料上的数字很诱人。
但一上线,就可能出现各种问题:
新缺陷识别不出来。
正常纹理被误判成缺陷。
背景变化导致误检。
产品批次变化导致漏检。
现场光源波动后结果不稳定。
这就是过拟合带来的典型风险。
模型记住了训练数据里的特征。
但它未必真正理解了工业场景里的缺陷规律。
所以深度学习不是“图片越多越好”那么简单。
更关键的是:
数据要有代表性,标注要有一致性,场景要尽量覆盖真实生产环境。
否则模型看起来很强,实际上很脆。
05
标注不是一次性工作,而是长期消耗
很多人低估了深度学习项目的后期维护。
以为前期把数据标完,模型训练好,就可以一劳永逸。
但工业现场不会这么配合。
产品规格会变。
材料批次会变。
表面纹理会变。
缺陷形态会变。
客户标准会变。
现场光照和机构状态也可能变。
一变,就可能影响模型效果。
模型效果下降怎么办?
继续采图。
继续筛图。
继续标注。
继续训练。
继续验证。
继续上线。
于是项目进入循环:
采集—标注—训练—测试—返工—再标注。
这就是为什么有人调侃:
深度学习做检测,标注传三代,人走标注还在。
这句话听起来夸张。
但做过项目的人,大多都懂。
06
技术很好,但钱包和人都很痛

深度学习不是不能用。
它当然能用。
而且在很多复杂场景下,它确实比传统视觉方法更有优势。
但问题是,它不是零成本。
首先是人力成本。
你需要懂现场的人参与标注。
需要懂缺陷标准的人确认样本。
需要工程师不断清洗数据、调整模型、验证效果。
其次是时间成本。
数据采集要时间。
缺陷积累要时间。
标注审核要时间。
模型训练和调参也要时间。
最后是硬件成本。
训练深度学习模型,往往需要较强的计算能力,很多场景还需要高性能 GPU 支撑。
所以很多企业不是不知道深度学习强。
而是算完账之后发现:
它强归强,但投入也是真的重。
工业项目不是技术秀。
最后一定要落到稳定性、交付周期、维护成本和投入产出比上。
07
深度学习什么时候值得上?

那么,工业机器视觉中到底什么时候适合用深度学习?
不是所有场景都适合。
如果缺陷特征清晰、规则明确、背景简单,传统图像处理方法就能稳定解决,那没必要为了“AI”而上 AI。
但如果遇到下面这些情况,深度学习就值得重点考虑:
产品背景复杂。
缺陷边界不明显。
缺陷形态变化大。
产品一致性较差。
传统规则很难写清楚。
人工经验难以转化成固定算法。
这类场景里,深度学习的优势会更明显。
它可以从大量样本中学习复杂特征,对传统算法难以描述的细微异常,具备更好的识别潜力。
一句话:
规则能解决的,先用规则。规则解决不了的,再考虑深度学习。
08
别神化深度学习,它只是工具
深度学习在工业机器视觉中,确实是一项强大的技术。
它可以提升复杂缺陷检测能力。
可以减少人工疲劳带来的漏检。
可以在复杂场景下提供更强的适应性。
但它也有明显代价。
标注很重。
过程不可控。
过拟合风险高。
数据迭代频繁。
现场维护压力大。
所以真正成熟的工业视觉项目,不是简单问:
“要不要用深度学习?”
而是要问:
这个场景真的需要吗?
数据能不能支撑?
标注成本能不能接受?
现场变化能不能覆盖?
后期维护有没有人负责?
投入产出比是否合理?
深度学习不是万能钥匙。
它更像一把锋利的刀。
用对了,能解决传统方法难以处理的问题。
用错了,就会变成一个长期消耗人力、时间和成本的深坑。
09
最后说句实在话
工业机器视觉最怕的,不是技术不先进。
而是为了先进而先进。
深度学习不是不能上。
但一定要想清楚再上。
如果你只看到了模型识别缺陷时的“智能”,却忽略了背后的数据采集、人工标注、过拟合风险、硬件投入和长期维护,那么项目很可能不是变简单了,而是换了一种方式变复杂。
真正可靠的方案,永远不是最炫的方案。
而是最适合现场、最稳定、最可维护、最能交付结果的方案。
深度学习可以是工业视觉的利器。
但前提是:
你要先准备好数据,也准备好耐心。
更要准备好接受一个现实:
机器变聪明之前,往往是人先变成了标注工程师。

1. 你做过深度学习缺陷检测项目吗?最痛苦的是标注、过拟合,还是现场迭代?欢迎评论区聊聊。
2. 你认为工业视觉项目中,传统算法和深度学习应该如何取舍?留言说说你的判断标准。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 16
16 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)