RAGular:适合知识库体质的 OCR 助手
这篇长文可歌可泣地记录了人类和 AI 早期战斗的珍贵影像。
缘起
我一直在找更便利、更准确的 OCR 方法。2025 年 2 月 DeepSeek 爆火,对本地部署一窍不通的我,在淘宝 API 贩子的指导下,开始用起了 Cherry Studio,也因为学英语的需要开始了对知识库的一系列探索。
我比较习惯读电子书,所以把所有纸质书都扫描成了电子版,放到了 Cherry Studio 的知识库里。知识库是有价值的,模型回答问题时如果有知识库的加持,回答会更好更准确。
Cherry Studio 是一个不错的软件,虽然它每次更新都会出一些 bug,它的 UI 常常劝退我,不过它的功能设计比较贴心,它的知识库已经是市面上比较好用的了。我曾经有几次想要逃离 Cherry Studio, 也尝试过 AnythingLLM、LobeChat、Msty 等平台,但因为功能不合适等种种原因,最终还是留在了 Cherry Studio 里。
既然我没能“逃走”,我就还是得面对在 Cherry Studio 里优化知识库的问题。

在使用和调试过程中,我觉得影响知识库质量的因素有三个:
1、嵌入和重排模型的能力
2、制作知识库时,嵌入/重排模型具体参数的设定
3、知识库文件的质量
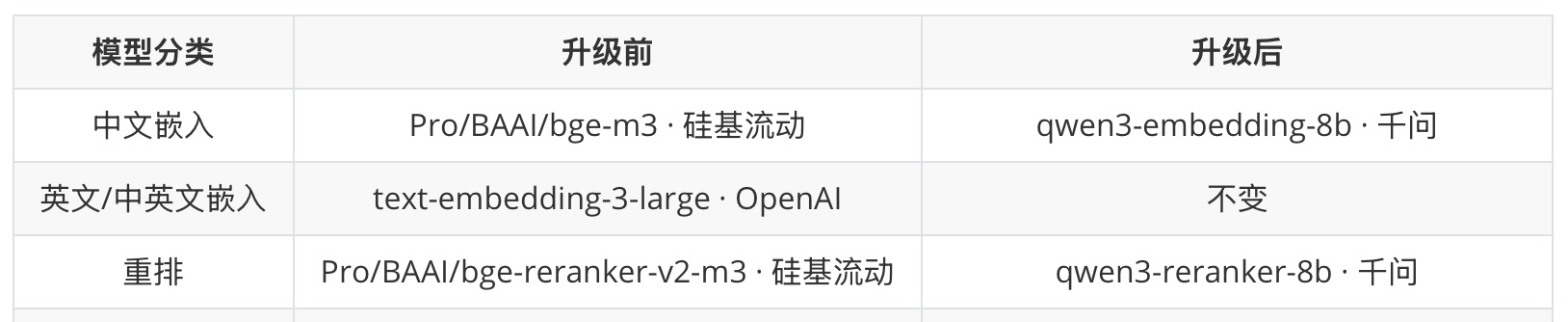
其中第一个因素取决于大模型的进化。这方面只能靠模型厂商们的努力了,我什么都做不了。在 2025 年底,我把嵌入和重排模型从硅基流动换成了千问,效果是肉眼可见的提升。
第二个因素也比较重要。比如不同类型的知识库文件,需要切成大小不同的 chunk,重叠部分也有一些说道。不过,这个因素对于知识库不会有根本性的影响,所以即使参数设置不够好,也不会让我太焦虑。
第三个因素非常重要。知识库文件内容的准确性、可被识别性都会直接影响到模型答案。 而且前两个因素多少还和模型能力有关,但知识库文件可赖不着模型了,因为文件都是我自己做的。如果因为文件做得不好,影响了知识库的质量,那就只能怪我不努力了。那我就会非常焦虑!
如果一件事情做到最后发现,因为自己做的不好,影响了结果,那可太难受了。

我不能难受。所以我开始琢磨怎么做文件。
幼年期 1:未掌握 Python 的胡乱探索阶段
对于 PDF 扫描书而言,知识库文件质量的奥义,在于把 PDF 内容变成准确的文本。文件格式我选择了 markdown(下称“md”)。
这个阶段我用了很多很笨拙的方法去处理 PDF,因为是大概一年前的事了,我只记得过程挺苦的。整个过程笨笨咔咔的,出了很多力,但效果又不好。
我在 PDF 文件、PNG 图片、Word、宏、WPS、正则表达式里折腾了一圈,最终选择了这条路径:把裁切干净的 PDF 先转成 Word 文档,然后用 MinerU 把 Word 文档转成 md 文件。虽然结果还是会有不少错字,但是整体上还过得去。
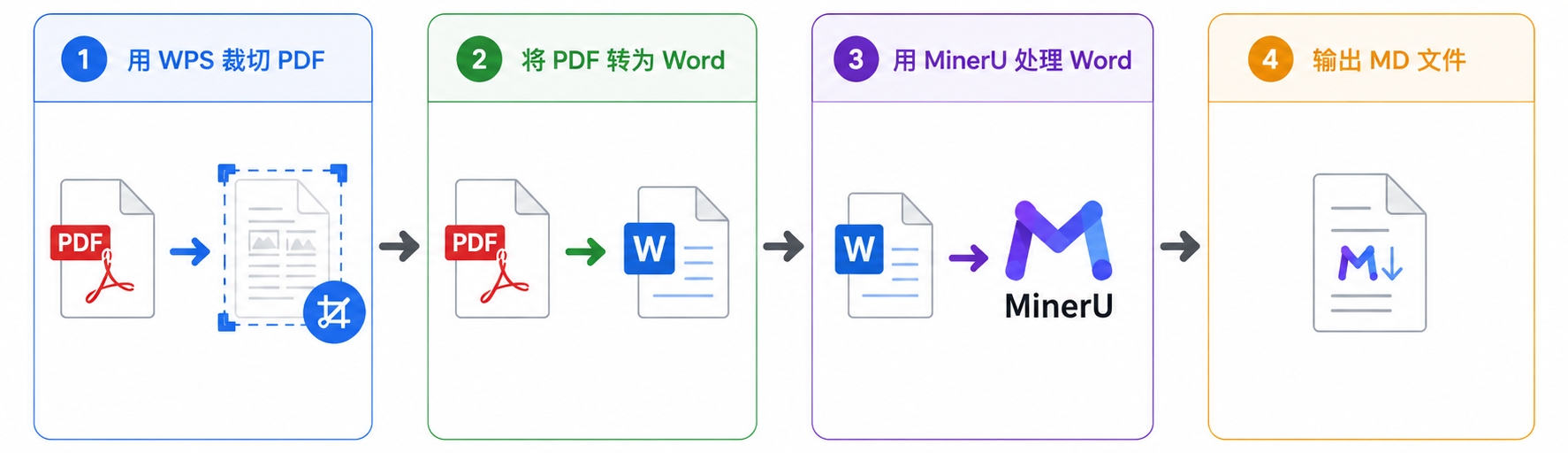
这期间的探索也有很多收获:
1、WPS 适合处理 PDF 的“噪声”:页码、logo、和正文无关的样式文字都是噪声,可以用裁剪页面、分割页面和擦除功能进行处理。
2、Typora 是很好用的 md 阅读软件,但读不了太大的文件,Obsidian 能读取。
3、MinerU 这个软件的识别能力是不错的。
在这个阶段,AI 能力也有限,给不出关于知识库的更好建议,有时候还会瞎说。

幼年期 2:学习“老马”,尝试 ABBYY
马健老师是电子书处理方面非常有名的一位老师,网名是“老马”。他开发了一套配有详细教程的 PDF 处理软件。这套教程我收藏了好久,我觉得这一定是一套处理 PDF 的神器。但看着教程里那么多文档,拖延把我当时发作,我决定要等到不得不处理 PDF 时再学习老马的软件。
然而,不得不处理的时候很快就来了。
二月的某个普通的学习日,我问 AI:这是功夫熊猫 4 的对白,in the know 和 not without 都是什么意思,用法是什么?

AI 引用的知识库切片里,有一条关于“not without”的解释来自陈用仪的《英语常用词疑难用法手册》。这个词条有两个释义,都表示肯定,只不过肯定的程度不同。
第 1 条释义的肯定程度:相当大;
第 2 条释义的肯定程度:有一点但不多。
动画片这句话用的是第 1 条释义,但是知识库切片只找到第 2 条释义,而且第 1 条释义压根儿就没有出现。这就很离谱了。我把切片找出来,第 1 条释义确实只出现了一个尾巴。这个词条被错误地切分成了两段。

这是我用了大半年以来第一次发现引用有问题。我这次之所以能够发现错误,是因为我前不久在这本书里读过 not without 这个词条,我知道它说错了。
当你看到一只蟑螂时,屋子里至少已经有蟑螂扎窝了。 这也意味着,知识库文件已经很不好了,以前可能有很多回答引用得都不对,只不过我没在原书里读过,不知道它错了。
我决心要面对这个问题,改掉这个错误,用更好的 OCR 方式做知识库文件。
于是我硬着头皮打开了老马的教程。在 Claude 和 GPT 的陪读下,我学了一部分老马教程,又很快关闭了。
这次学习让我有了两个收获:
1、老马教程适合处理 PDF 的清晰度,不太适合处理我当前的 OCR 问题。
2、让文档变清晰的这个功能,老马教程我没学下去,WPS 的傻瓜操作更适合我。

我开始尝试用业内最有名的 OCR 识别软件 ABBYY 去做,摸索出来最适合 ABBYY 的一条路:首先用 WPS 把 PDF 变成图片式 PDF,然后用 ABBYY 的增强识别变成 html 格式。不过还是有些问题,ABBYY 遇到斜体和下划线的单词就会识别错误。
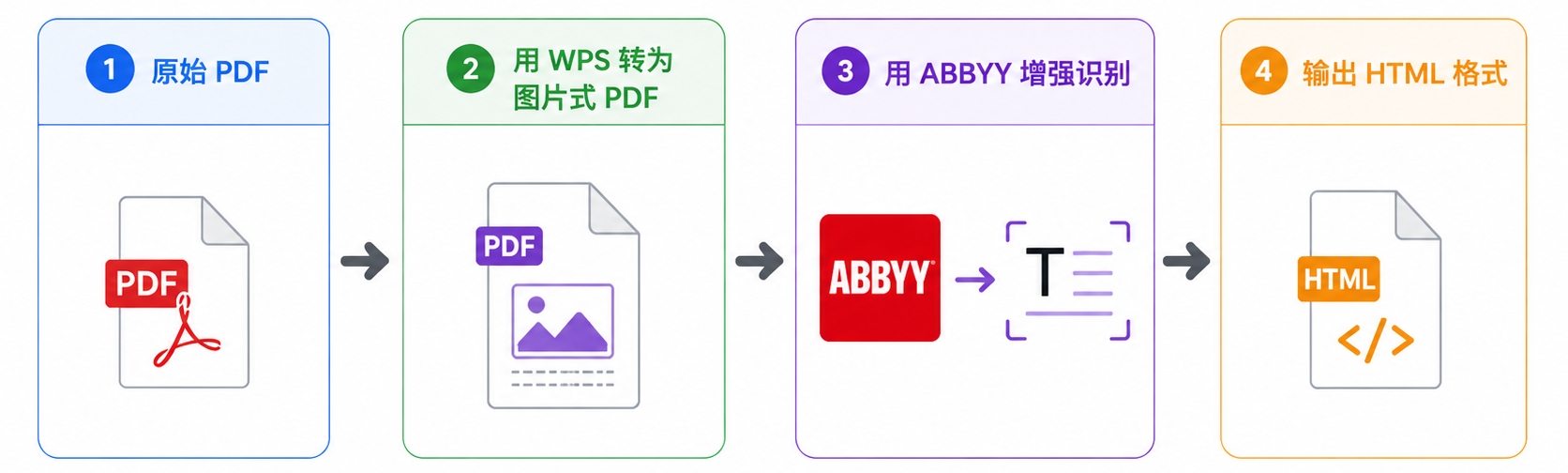
但对 ABBYY 的这一轮探索也让我有了重要的收获:人眼看起来舒服的文件,未必适合软件消化。 比如,和高清图片相比,WPS 生成的图片式 PDF 巨糊,但 ABBYY 消化得最好;反而 ABBYY 转出漂亮的 html,看起来超舒服,但喂给知识库的话,需要把大量的 html 格式标签清洗掉才行。
这样想想,人还真是挺金贵的生物,要不怎么说精加工的食物才好吃呢,人嘴太刁。
成长期:多模态大模型的惊喜
在我发愁时,Claude 给我出了个主意:用多模态的大模型去做 OCR。因为传统 OCR 软件是在像素级别识别字符,但多模态大模型是"看懂"内容,所以能够理解斜体、下划线这些格式,可能会解决 ABBYY 的痛点。但 GPT 强烈反对,它觉得模型识别会有幻觉。
我让 Claude Opus 试着识别了一页,效果惊人的好!一字不差!格式都对!于是我开始琢磨大模型 OCR 这条路。
Claude 写了一段给多模态模型的 Prompt,放到了一个 Python 脚本里(下称“py 脚本”)。Prompt 用来约束多模态模型,要求模型忠实转录+保留词典分隔符+忽略页码+输出 txt,py 脚本负责把 txt 结果进行拼接,按照分隔符切成 md 文件。

这样一来,每一个词条对应一个 md 文件,就不会再被 chunk 误切了。
我抽出 3 页书,挑了 4 个市面上口碑不错的多模态大模型进行测试,Sonnet 4.6 在准确性、速度方面以大比分获胜。而且出乎我的意料,它居然比 Opus 还要好。

不过,以 Sonnet 的价格来看,处理这本 940 页的词典,大概要 22 美元,合人民币 150 元左右。 嚯~!比我扫描 PDF 还贵。我算了笔账,我如果识别这一本也还好,毕竟是大部头、经典书目。但像这样的书我还有很多,我还有一两千页的书……我有中文书,英语书……
我闹心了。我睡觉时都在想,真的吗,这一本书处理起来真的要 150 块钱吗?我有点后悔了,我让 Claude 给我推荐 OCR 模型时一再强调:“我不在乎花钱,只在乎怎么样把流程跑通!” 然后真的把流程跑通我又觉得贵了,Claude 不会嫌我抠吧……
我好不容易找到了这么好的办法,但我的荷包在滴血!我痛苦!
第二天一早,我让 Claude 给我推荐一些有“性价比”的多模态模型。我又进行了一轮测试。哎哟不错哟,性价比模型组 Qwen-VL-Max 胜出。我没想到 Qwen-VL-OCR 的 OCR 能力居然没有 Max 厉害。
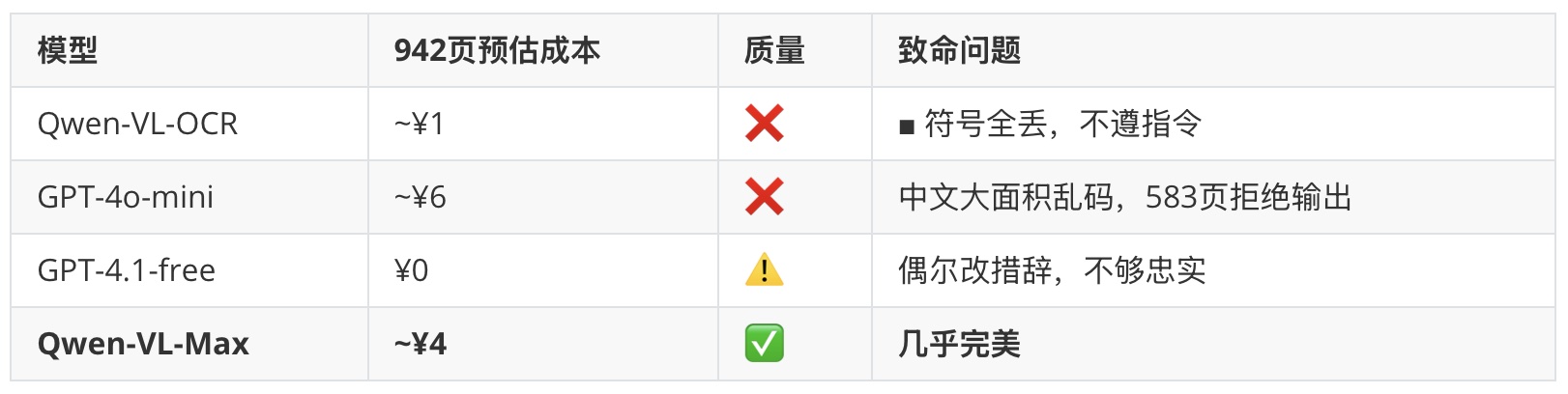
荷包吐血组和性价比组的两名优胜选手参加了决赛,能力上两人不分胜负,但 Qwen-VL-Max 以它仅仅 1/40 的价格,在成本方面获得了压倒性的胜利!
4 块钱,只要 4 块钱!一本 942 页的大部头,把价格从 150 元打到 4 块钱! 我一鼓作气,让 Claude 把并发数量增加到 10,当天就把这本书全部 OCR 了。
我把全书 2169 个词条 md 文件导入 Cherry Studio 的知识库,选好嵌入和重排模型,调好参数,然后选择同样的模型,又问了一次同样的问题:
At least not without someone in the know. 这是功夫熊猫 4 的对白,in the know 和
not without 都是什么意思,用法是什么?
这次,模型给出了很好的答案:既正确引用了释义 1,也对比了释义 2,切片和理解都是对的。
我看了两次引用的对比图,这一顿折腾没有白费。

成熟期:从 Minimax Agent 火速退坑
我尝到了甜头,打算把这个流程做成工作流,这样就能把其他书也都处理成非常准确的 OCR,重构知识库。
那顿时间 Minimax 2.5 非常火。在 Minimax 的桌面客户端里,可以制作自己的“专家 Agent”。我试了一下觉得还不错。
Minimax 这个 Agent 制作是黑盒机制,只要告诉“专家编辑”,我想要的功能是什么。专家编辑就会表示它听懂了,包在它身上。然后一顿操作。

过了十几分钟,专家编辑表示 Agent 已经制作好,欢迎我尝试。
看到没有,这才应该叫 Vibe Coding!完全自然语言,完全不需要人工参与。对嘛,就不应该需要我做什么,要是用我干活儿,显得 AI 多没用啊。
我一边感慨 Minimax 果然牛,一边跃跃欲试地把测试文档喂给编辑专家刚做好的“文档处理小专家”。
只见小专家收到文件,一顿操作。边操作边念念有词,一直 thinking,我点开一看,好家伙,thinking 过程全是英文。小专家一边干活一边汇报,先分析文档,再开始处理,建好输出目录,再有序输出,每做完 10 页就会跟我汇报一下。

这活儿干的叫一个漂亮!让我觉得我前一天吭哧吭哧的显得有点愚蠢。我本来以为 Minimax 只是风很大,没想到真的有这把刷子。前一天千问模型带给我的震撼还历历在目,Minimax 也即将亮瞎我的狗眼。我真是小看了国产模型,国产模型早就不是 2024 年的时候了!
完成了!Minimax 给我了一份漂亮的报告,包括文档概况、输出路径、目录结构和质量评分,真好啊,Agent 是人类之光!我迫不及待地点开了输出文档,然后发现,它识别出来的文档——
不存在。
我不敢相信。我在文件夹里找了又找,它一步一步给我做的啊,还进行了质量检测来着,我只看到一个 4000 字左右的文档,里面写着每一章的摘要。
……我难以相信。我血压高了。
我愤怒地质问它,它检查了一下,和我诚恳道了歉。

我先是气笑了,然后又突然觉得好委屈,好无语啊。这得是什么傻子才能把自己 OCR 的结果都不保存啊?我不能理解,作为咨询师我可以理解人类,但我不能理解 AI。
让我觉得最生气的是,Minimax 先是做了很漂亮的框架,告诉我它在做什么,然后告诉我它本来可以做得很精美,只是都没有保存而已。
这招真是挺高的,这是镜花水月最高级别的呈现,我将终身学习。

生气归生气,我后面让这个小专家进行了修复,但是小专家还是会出一些不太稳定的 bug,一直没办法稳定地给出下载路径,每次的错误也不太一样。我让专家编辑去修改,但也改不好。
我那天真的很痛苦,情绪非常复杂,那是上当受骗后的恼羞成怒。 Claude 和 GPT 关于这件事的解读是:小专家 Agent 每次会生成不同的 py 脚本,相当于每次重新写代码,所以每次结果不一样,也不稳定。我接受了这个结果,放弃了幻想,重新回到“老老实实做工作流”的路径上。
现在我的软件已经做出来了,刚才因为写文章找素材,所以重新看了一下小专家的架构。吐槽归吐槽,其实 Minimax 有做得不错的地方。
比如,Minimax 很擅长做文档和规则管理。 它甚至自己做了特别漂亮的Devlog,里面翔实地记录了我对 Agent 的诉求和调试方向。它其实用了 5 个 Skills 作为 Agent 的架构,而且用一篇长达 295 行的 md 去管理这些 Skills,这个 md 长文档写得也很好。只是模型没有能力遵守那么长的 Prompt,所以每次会失控。

另外,我当时的能力也不够。 那时我并不熟悉 Skill,甚至我是今天回看时才看懂这个架构,也才找到正确的调试路径。我觉得 Minimax 在路径上是有一些问题的,包括模型的输出路径,读取文件路径以及调试路径。
这次失败的、情感复杂的尝试,让我坚定了要从黑盒走向白盒的决心。 我也更明确了我所认同的理念:我接受问题存在,但我不接受解决问题的方式是含含糊糊的;我离问题的答案可能很远,但是明确我和答案“到底有多远”的那一刻起,我和答案就已经是线段两端了。
面对现实和接受现实,就是这样迷人。最开始觉得很冲击,很痛苦,不想面对,也不愿接受。但一旦接受了现实,人就会调动起积极性,又开始充满活力。
我血条满了,开始下一个挑战。
完全体:RAGular 上线
我本来以为我有了比较好的流程、成功的案例和 Minimax 的失败经验,这会是一个按部就班推进的项目。但是我错了,这个项目是我觉得最困难的。
我把这个软件叫做 “RAGular”,也是取了regular 的谐音,希望软件能够把 OCR 的流程变得常规化和标准化,让 RAG 知识库的制作更加便利。
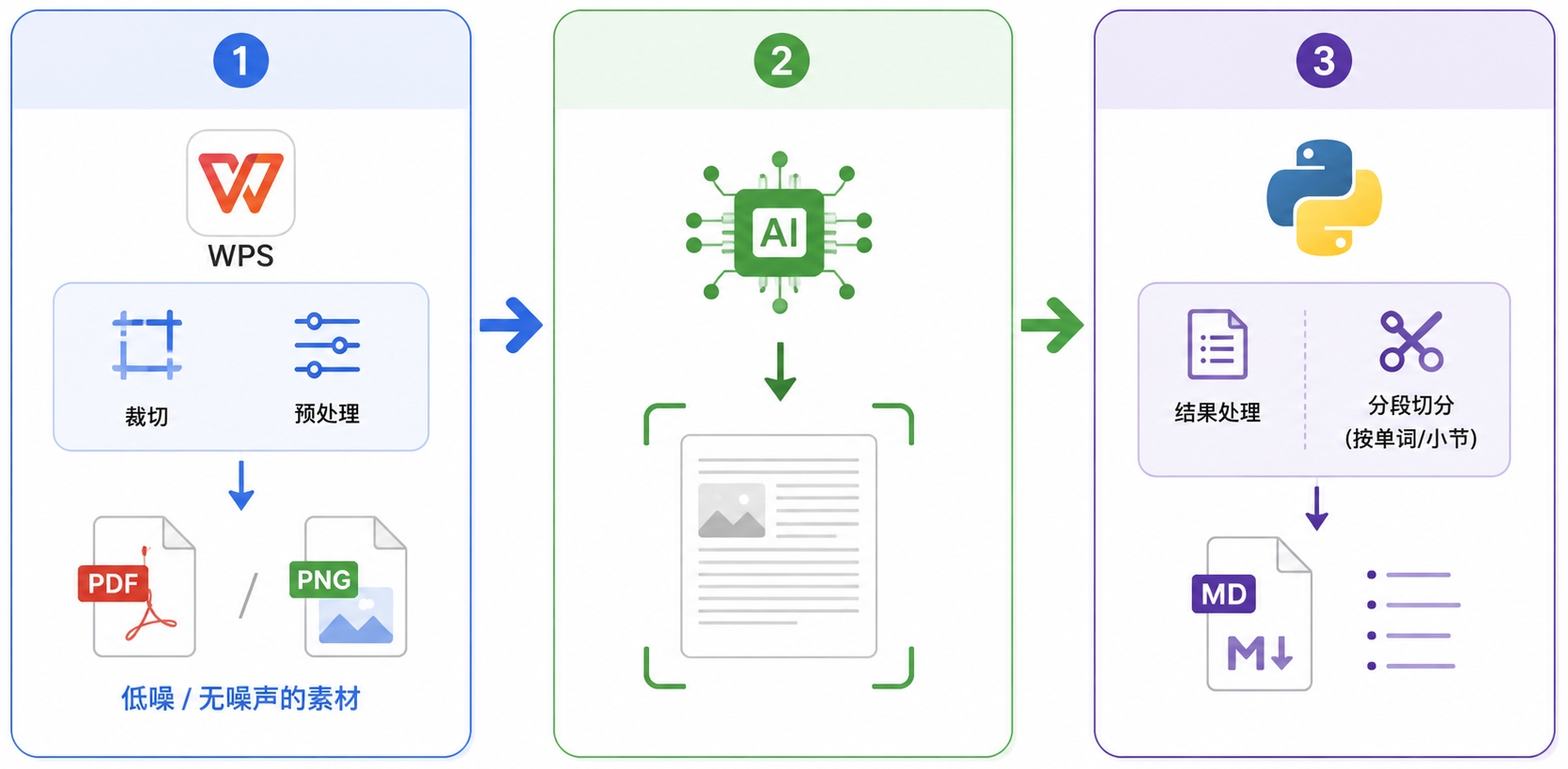
RAGular 这个软件的流程构想是:
1、我用 WPS 完成裁切和预处理,做出低噪或者无噪声的 PDF/PNG 图片素材。
2、多模态模型识别素材,进行 OCR。
3、Python 对 OCR 结果进行处理,变成以单词或者小节为单位的 md 文档。
虽然我希望能够完全解放双手,但是考虑到模型能力,噪声预处理这个部分还是我来操作。
模型识别的难点有两个: 一是排版比较复杂,模型难以判断标题层级,影响文档切分;二是表格、图片识别不够准确,而且图表标注容易被混淆为正文。
而且我当时打算把这个项目作为我的作品集推上线,经历了 Minimax 的挫败,整个人有些焦躁,所以没有按照我的常规流程去做。
我此前的常规流程是:先和 GPT+Claude+Gemini 的最好模型讨论,表达我的软件构想,然后让三家各出方案、互找漏洞,经过两轮讨论,再由 Claude 定方案+GPT 审核两轮,然后再开始做。
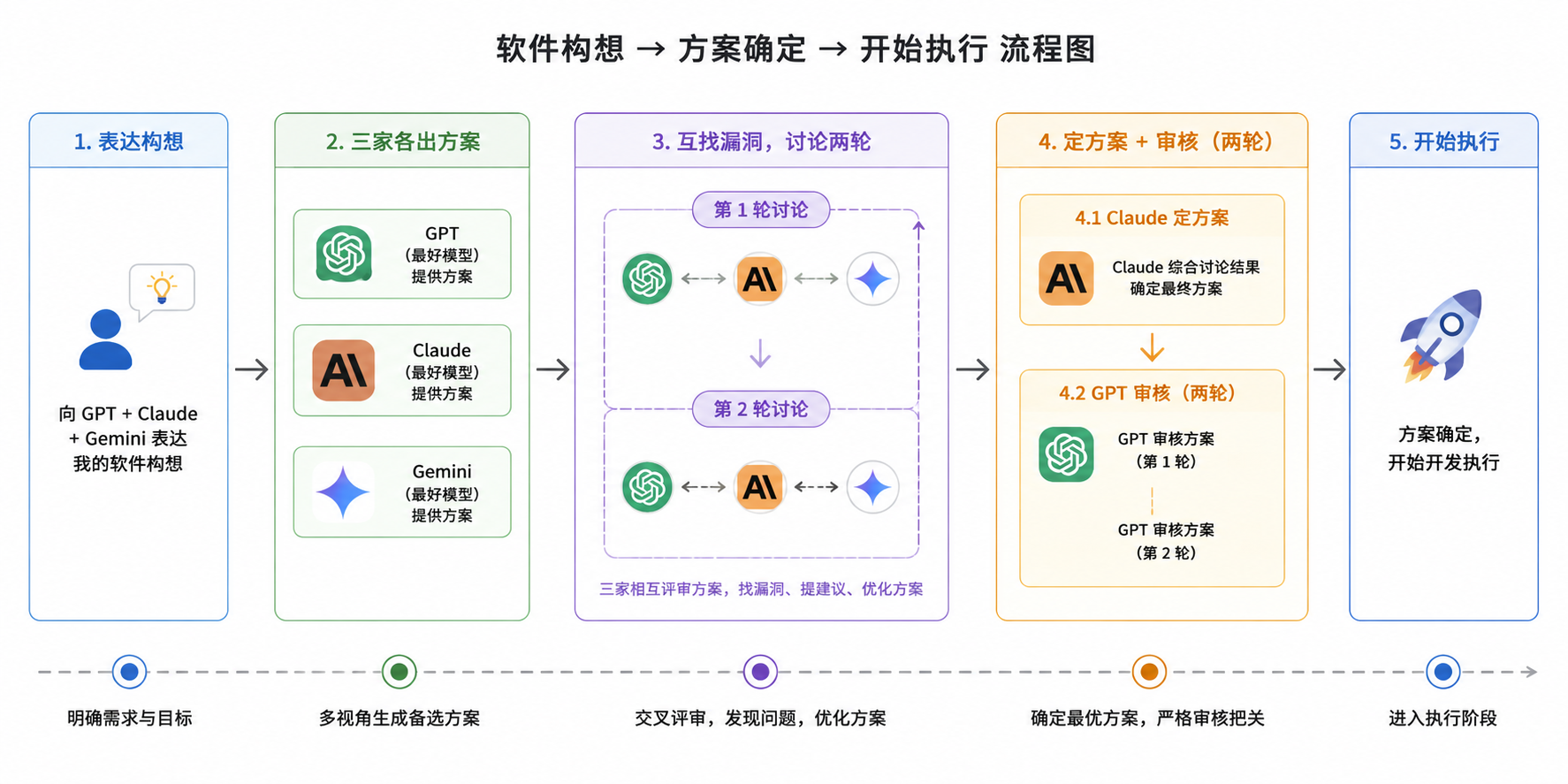
但这次我只是让 Claude 在原有基础上做,然后用 Codex 修正,赶上网络变差模型降智,后来越来越混乱。现在挂载在我网站上的试用版是 V3,前面有两个大失败的版本。
我之所以选择多模态模型,是因为我希望它能够“看” PDF,了解文档的结构。为了让模型了解排版的复杂性,我还找了 10 本不同语言、不同排版、不同类型的样书,让模型建立不同的识别和切分标准。
V1 版本结果还不错,10 本样书都切分成很漂亮的 md 文档。我找了样本库以外的一本书测试,发现结果很差。我再试了两本,效果也不好。我觉得很困惑,这几本书的结构明明比较简单,怎么会这样呢?
排查 bug 之后我崩溃了——给我做软件的 Codex 哄我玩儿呢。Codex 做的 V1 软件投机取巧。 软件把样书的名字记住了,一个名字对应一个切分流程,它不是看图切分,是看人下菜碟。这样不仅识别不出样书库以外的书,哪怕是把样书换个名字,它都切不好。

死骗子!大模型都是死骗子!时间紧迫,我收起我的崩溃,把 Codex 里给我做软件的 session 重命名加上“傻X”标签,然后赶紧开了新 session 去改 bug。 一番大修之后,V2 版本终于能够实现一些看图切分的能力了,我打算把它搬到我的网站上。
我本来是在 Streamlit 上做的,而且我找 Gemini 给我设计了每个处理过程的 UI。在我以为能顺利上线时,我才知道 Streamlit 不是自由前端框架,也就是说那些丑丑的按钮无法按照设计稿变成真正可用的交互,我的 UI 白做了。

这不行啊。之前用 Streamlit 做另一个软件Ankiflow时,功能比较简单,所以 UI 粗糙点没有太大的影响。但 RAGular 功能复杂,UI 的表达是会影响功能的。 我赶紧让 Lovable 做了前端,再由 Codex 把前端放到我的网站上,我搭了后端,变成了现在网站上的 V3 版本。
因为这个是求职作品集展示的试用版,所以文件上传有 10 页的限制。我放置了一些试用的样书文件,感兴趣的朋友可以体验一下这个软件。
网站链接:https://baomohan.com/ragular/
V4 版本还在筹备中,我会继续优化它的 OCR 速度和切分能力,也会把版面预处理的部分更多地交给 AI 去做。等它成为“究极体”时,我再来做更新。
尾声
这篇文章我本来打算写成一个软件操作的指南,但思来想去,还是记录下了我制作的整个流程。其实每一个和 AI 工作的“大坑”,如果展开详细讲,都能单独写一篇文章。
离密集制作这个软件已经过去一个多月了,甚至很多具体的操作,如果我不看当时的记录都不记得了。但是这次复盘时,回顾每一个雷到我的坑,我的困惑和愤怒,居然历历在目。
AI 是伪人,不是真人,它在一次又一次创飞我的过程里,教会我怎样和它工作。
人类和 AI,已经说不清到底是谁“驯服”谁啦。


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 23
23 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)