SpringCloud+原生LangChain双栈改造Vol.1 流式聊天架构落地
为 Spring Cloud 微服务体系引入 Python AI 引擎,从零搭建可流式输出的智能聊天助手。
一、背景与目标
项目为家政 O2O 平台,包含机构端 PC、管理后台 PC、移动端 App 三个前端,后端为 Java Spring Cloud 微服务。目标是给机构端和服务人员端添加一个 AI 助手,初期实现流式聊天,后续扩展 LangChain / LangGraph Agent 能力。
核心原则:最小侵入现有系统,Python AI 引擎独立部署,Java 侧负责安全与业务数据。
业务服务
| 模块 | 职责 |
|---|---|
jzo2o-gateway |
API 网关,统一鉴权与路由 |
jzo2o-api |
Feign 接口定义(纯接口,无实现) |
jzo2o-foundations |
服务类型/服务项/区域管理 |
jzo2o-market |
优惠券管理 |
jzo2o-customer-dev_01 |
用户/机构/服务人员/评价 |
jzo2o-publics |
微信/短信/地图/文件上传 |
jzo2o-orders/ |
订单服务聚合(base/manager/seize/dispatch/history) |
jzo2o-ai/ 🚧 |
AI助手Java中间层(鉴权/过滤/持久化) |
jzo2o-ai-engine/ 🚧 |
AI大模型推理引擎(Python) |
二、方案选型
2.1 整体架构
| 方案 | 描述 | 优缺点 |
|---|---|---|
| A. Gateway 直连 Python | 前端 → Gateway → Python FastAPI | 路径最短,但 Gateway 需处理 SSE 代理,Python 要自己搞定鉴权 |
| B. Java 中转 (采用) | 前端 → Gateway → Java jzo2o-ai → Python jzo2o-ai-engine | 多一跳,但职责清晰,Java 管鉴权/持久化,Python 只管 AI 推理 |
| C. Java 内嵌 Python | 在 Java 进程里调 Python | 部署简单,但耦合重,不适合后续 Agent 扩展 |
选择方案 B,理由:Java 和 Python 各司其职,后续 LangChain Agent 需要 Python 生态,独立服务便于升级和扩容。
Python侧方案:初期MVP开发采用最小可行性方案:用Flask框架+OpenAI SDK快速实现,用拼接对话的方式实现最简单的记忆功能
对话存储方案:先采用MySQL存储,后期后续再添加向量数据库+其他数据库做增强检索和持久化
2.2 职责边界
┌──────────────────────────────────────┐
│ jzo2o-ai (Java) │
│ 鉴权、敏感词初滤、对话持久化、流量整形│
│ 严禁: Prompt 编排、向量检索 │
└──────────────┬───────────────────────┘
│ HTTP/SSE
┌──────────────┴──────────────────────────┐
│ jzo2o-ai-engine (Python FastAPI) │
│ Prompt 编排、LangChain、工具调用、LLM适配│
│ 严禁: 直连生产DB、执行业务操作 │
└─────────────────────────────────────────┘
2.3 通信协议
| 方案 | 流式支持 | 复杂度 |
|---|---|---|
| HTTP REST + SSE (采用) | 原生支持 | 低,FastAPI StreamingResponse + Spring SseEmitter |
| gRPC | 原生支持 | 高,需 proto 定义 |
HTTP REST 完全满足流式输出需求,且 Spring Cloud Gateway (WebFlux) 已有 Reactor 基础设施。
2.4 AI 接口
选用兼容 OpenAI 接口的 API,.env 中配置 LLM_API_BASE 即可切换 DeepSeek / OpenAI / 本地模型等任意后端。
三、模块结构
jzo2o-ai-engine/ ← Python FastAPI
├── main.py # 启动入口 (uvicorn)
├── requirements.txt # fastapi, uvicorn, openai, python-dotenv
├── .env.example # LLM_API_BASE, LLM_API_KEY, LLM_MODEL
└── app/
├── api/chat.py # POST /chat/completions → 纯文本 token 流
├── core/
│ ├── config.py # 环境变量 → Settings
│ └── llm_client.py # AsyncOpenAI 客户端, 迭代 token
└── schemas/chat.py # Pydantic 请求/响应模型
jzo2o-ai/ ← Java Spring Boot
├── pom.xml # 父 POM: jzo2o-parent
├── AiApplication.java # @SpringBootApplication
├── controller/consumer/ChatController.java # POST /ai/consumer/chat/completions
├── service/impl/ChatServiceImpl.java # 鉴权 → 持久化 → 调Python → SSE
├── client/AiEngineClient.java # WebClient 调 Python
├── model/domain/AiChatRecord.java # ai_chat_record 实体
├── mapper/AiChatRecordMapper.java # MyBatis-Plus BaseMapper
├── config/WebClientConfig.java # WebClient Bean
├── properties/AiEngineProperties.java # Python 引擎连接配置
├── resources/bootstrap.yml # Nacos 服务注册
└── resources/db/migration/V1.0__create_ai_chat_record.sql
四、开发过程
4.1 第一步:搭 Python 引擎
核心流水线:
POST /chat/completions {messages: [...]}
→ AsyncOpenAI.chat.completions.create(stream=True)
→ async for chunk: yield token + "\n"
→ StreamingResponse (text/plain)
关键代码 (chat.py):
@router.post("/completions")
async def chat_completions(request: ChatCompletionRequest):
messages_dict = [m.model_dump() for m in request.messages]
async def generate():
try:
async for content_chunk in stream_chat(messages_dict):
yield content_chunk + "\n" # 纯文本,换行分隔
yield "[DONE]\n"
except Exception as e:
yield f"[ERROR] {str(e)}\n"
return StreamingResponse(generate(), media_type="text/plain")
Python 层只做纯文本换行分流,不封装 SSE 格式,避免网络分片粘包解析问题
4.2 第二步:搭 Java 中转层
核心职责:从 UserContext 取当前用户 → 持久化用户消息 → 调 Python 引擎 → SSE 代理到前端。
public SseEmitter chat(ChatRequestDTO request) {
CurrentUserInfo user = UserContext.currentUser();
saveRecord(user.getId(), user.getUserType(), sessionId, ROLE_USER, userContent);
SseEmitter emitter = new SseEmitter(300000L); // 5分钟超时
aiEngineClient.streamChat(messages).subscribe(
rawChunk -> {
for (String token : splitTokens(rawChunk)) {
emitter.send(SseEmitter.event().data(token)); // SSE 包装发前端
responseBuilder.append(token);
}
},
error -> emitter.completeWithError(error),
() -> {
saveRecord(userId, userType, sessionId, ROLE_ASSISTANT, responseBuilder.toString());
emitter.complete();
}
);
return emitter;
}
4.3 第三步:Gateway 路由
- id: ai
uri: lb://jzo2o-ai
predicates:
- Path=/ai/**
filters:
- Token
4.4 第四步:前端悬浮聊天窗
在 project-xzb-PC-vue3-java 的 src/layouts/index.vue 引入:
<ChatFloatingButton :visible="showChat" @toggle="showChat = !showChat" />
<ChatWindow :visible="showChat" @close="showChat = false" />
4 个新组件:ChatFloatingButton / ChatWindow / ChatMessageList / ChatInput,原生 fetch + ReadableStream 消费 SSE。
4.5 第五步:富文本渲染升级
AI 聊天窗原本只支持纯文本显示。为了支持代码高亮、数学公式、流程图,引入三套渲染引擎:
| 库 | 用途 | 语法 |
|---|---|---|
| markdown-it | Markdown → HTML | **粗体** # 标题 - 列表 |
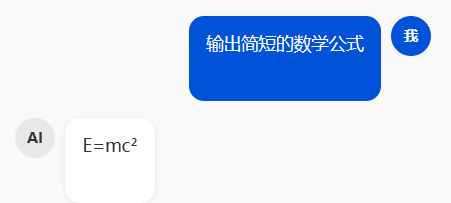
| KaTeX | LaTeX 数学公式 | $E=mc^2$ $$\int_0^\infty$$ |
| Mermaid | 流程图/时序图 | ` ```mermaid\ngraph TD\n…\n```` |
架构设计:
前端 chat.ts: SSE 流解析 → 每行补 \n → 拼接完整文档
↓
ChatMarkdown.vue: v-html 渲染
↓
markdown.ts:
1. LaTeX 预处理: $...$ / $$...$$ → KaTeX HTML → 纯字母占位符
2. markdown-it 渲染 → HTML
3. 恢复占位符 → KaTeX HTML
↓
ChatMarkdown.vue onMounted: mermaid.run() → SVG
LaTeX 占位符设计要点:必须使用纯字母数字组合(如 KATEXINLINE0000END),避免与 markdown 语法冲突。初版用 __KATEX__(双下划线),被 markdown-it 当成粗体语法 <strong> 包裹,导致 KaTeX HTML 还原失败。
五、踩坑记录
5.1 前端收不到 AI 回复 — PackResultFilter 劫持 SSE 响应
现象:Java 日志显示调用成功、Python 200、DeepSeek 200,但前端收不到任何消息,Network 面板显示空 data: 行。
根因:项目的 PackResultFilter 会用 ResponseWrapper 劫持所有 HTTP 响应、包装成项目统一 JSON 格式 {"code":200,...}。SseEmitter 是异步写入,其输出被 ResponseWrapper 的缓冲区捕获后丢弃,前端收到的是一行行空的 data:。
修复:在 PackResultFilter.doFilter() 的跳过条件中增加 SSE 端点:
if (requestURI.contains(".") ||
requestURI.contains("/swagger") ||
requestURI.contains("/api-docs") ||
requestURI.contains("/inner") ||
requestURI.contains("/chat/completions")) { // 新增
filterChain.doFilter(servletRequest, servletResponse);
return;
}
教训:在 Servlet Filter 使用
ResponseWrapper的项目中,SSE / WebSocket 等长连接响应必须显式排除,否则异步写入会失效。
5.2 前端仍不显示 — WebClient Flux 碎片化与 SSE 解析竞态
现象:跳过 Filter 后,前端收到 data: 但后面始终没有内容。
根因:最初 Python 端自己包 SSE 格式 (data: {token}\n\n),Java 端用 WebClient.bodyToFlux(String.class) 接收后解析 data: 前缀。但 bodyToFlux 按网络缓冲区切分数据,一条完整的 data: 你好\n\n 可能被切成 "data: " 和 "你好\n\n" 两个元素,Java 的 extractContent 无法处理碎片化的 SSE。
修复:让 Python 抛弃 SSE 格式,改发纯文本 token(换行分隔 \n)。Java 收到后按 \n 拆分,再用 SseEmitter.event().data() 包装成 SSE 发给前端。两个方向各管各的格式,谁也不再解析谁的。
Python → Java: token1\ntoken2\n... (text/plain, 简单换行)
Java → 前端: data: token1\n\ndata: token2\n\n (text/event-stream)
5.3 Markdown/Mermaid/LaTeX 全部不渲染 — 换行符传输链丢失
现象:前端 AI 对话只有粗体/斜体(行内语法)生效,所有块级语法(# 标题、- 列表、> 引用、`` ```代码块 `````)以及 Mermaid 图表、LaTeX 公式全部不显示。
排查过程:
- Node.js 测试 markdown-it + KaTeX 管道 — 全部语法正常输出 HTML,确认渲染引擎本身无问题
- 浏览器 Elements 面板检查 — 发现所有内容挤在
<code>标签内无换行,mermaid和graph之间无空格,确认换行符丢失 - Java 端代码审查 — 发现
splitTokens()方法raw.split("\n").map(String::trim).filter(s -> !s.isEmpty())将 LLM 输出中的 markdown 换行符当作 token 分隔符丢弃 - 添加双向日志 — Java 端
[DEBUG] rawChunk+ 前端[DEBUG] chunk,对比发现 Java 日志中所有 chunkhasNewline=false,每个 Flux 元素恰好是原始内容的一行 - 定位行解码器 — WebClient
bodyToFlux(String.class)底层 Reactor Netty 使用行解码器,\n在到达 Java 代码之前就已被当作行边界丢弃
根因:三层协议设计缺陷叠加
- 原始设计:Python 用
\n做 token 分隔符(content_chunk + "\n"),Java 按\nsplit + trim + filter empty。LLM 输出本身含\n(markdown 段落换行),与分隔符同字符无法区分 - 后续发现:即使 Python 不添加分隔符,WebClient 的行解码器也会自动按
\n拆分响应流,\n字符在 Java 代码根本不可见
尝试过的失败方案:
| 方案 | 问题 |
|---|---|
分隔符改为 \x1e(ASCII RS) |
控制字符在 SSE/HTTP 传输中出现未定义行为 |
Java 转义 \n → \\n,前端解转义 |
LaTeX 命令 \nabla、\neq 中的 \n 被前端正则 /\\n/g 误匹配替换 |
最终方案:零分隔符 + 行末追加
Python: yield content_chunk (LLM token 原样输出)
Java: emitter.send(SseEmitter.event().data(rawChunk)) (每行直接发送)
前端: callbacks.onChunk(content + '\n') (每行末补 \n 还原文档)
为何这个方案正确:
- 每个 SSE event 是单行纯文本,SSE 协议零冲突
- 不做任何转义/解转义,LaTeX 命令(
\nabla、\neq等)完全不受影响 - 空白行自然保留:WebClient 行解码 →
""→ SSEdata:→ 前端补\n→ 输出"\n"空行 → markdown 段落分隔 - Mermaid 代码块内换行正确保留,
mermaid.render()SVG 渲染正常
教训:
- 传输层不要对内容做假设性拆分或转义。内容格式的语义应由渲染层理解,传输层职责仅限于可靠搬运
- 行解码器是隐式协议层。
bodyToFlux(String.class)的默认行为不是"按网络缓冲切分",而是"按行切分"。设计跨语言流式协议时必须明确每一层的编解码行为 - 分隔符方案天生有冲突风险。任何可能在内容中出现的字符都不适合做分隔符。追加式(在边界外补回结构信息)比转义式(修改内容本身)更稳健
- 双向日志对比是最有效的调试手段。在 Java 和前端同时打印 chunk 内容,可以精确定位数据在链路的哪一层丢失
5.4 占位符被 markdown-it 误解析
现象:LaTeX 公式无法渲染。
根因:用于保护 KaTeX HTML 的占位符 __KATEX_INLINE_0__ 两端的 __ 被 markdown-it 当作粗体语法 <strong>KATEX_INLINE_0</strong> 包裹,后续 restorePlaceholders 无法匹配到正确的占位符文本。
修复:改用纯字母数字组合 KATEXINLINE0000END,零 markdown 语义。
教训:在 markdown 管道中插入元数据时,占位符必须对 markdown 解析器透明。最简单的做法是使用不包含任何 markdown 特殊字符(
*、_、[、]等)的纯字母数字标识符。
最后
为什么要坚持走Java+Python的路线而不用Langchain4j或SpringAI?
相较于Java端,虽然没有相同技术栈的优势,在Java端和Python端之间通信时会有很多坑要踩(就像上面提到的),但Python端的Langchain框架是生态最丰富的,社区活跃度高,有更多的参考资料.而且双端是松耦合的,后续把双端通信协议设计得更完善后,我可以把精力集中在Python端专注agent的开发
后续有什么打算?
最首要: 完善通信协议,考虑到langchain的function calling等非纯文本传输,需要设计结构化的事件类型以支持更丰富的功能和划分文本职责.
还有,function calling必然会涉及到让Java端返回数据(查数据库),所以当前的纯SSE架构需要改,至于是大改成WebSocket或MQ或者是多暴露个http接口,后面再衡量
其次: 连接超时:Agent 循环期间无数据产出;
状态管理;
Java 持久化 vs LangGraph Checkpointing;
中止/取消机制;
前端流式内容组装逻辑…
总之就是先给Python端升级铺平道路
这是微服务项目集成Python端Agent系列的开篇之作.先做个MVP,摸索下方案,后续再继续完善.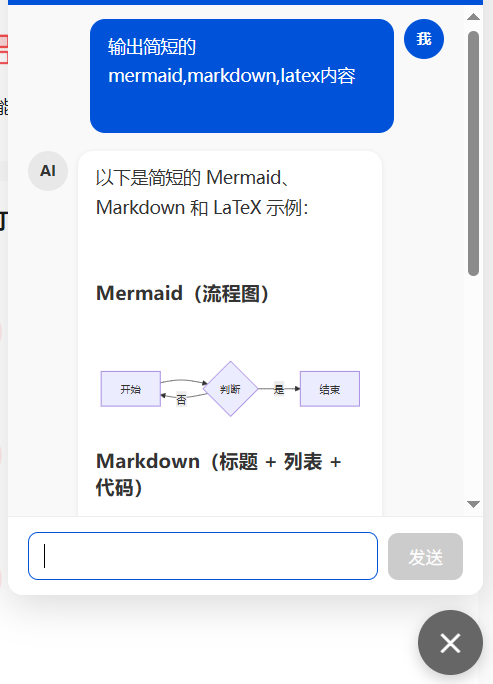

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)