LLM CLI:终端原生的人工智能工作流革命
LLM CLI:终端原生的人工智能工作流革命
访问大型语言模型的命令行工具和 Python 库
引言
在 AI 工具爆炸式增长的今天,Simon Willison 开发的 LLM CLI 项目为开发者提供了一个独特而强大的解决方案:完全在终端中访问和管理大型语言模型。这个项目不仅是一个工具,更代表了一种全新的 AI 交互哲学——开源、本地可控、终端原生。
项目地址:https://github.com/simonw/llm
官方文档:https://llm.datasette.io/
一、项目概述
1.1 什么是 LLM CLI?
LLM 是一个命令行工具和 Python 库,用于与各种大型语言模型(LLM)进行交互。它支持:
- OpenAI(GPT-4o、GPT-4o-mini 等)
- Anthropic Claude 系列
- Google Gemini 系列
- Meta Llama 系列
- 数十种其他模型(通过插件系统)
- 本地运行的模型(通过 Ollama、llama.cpp 等)
1.2 核心特性
# 安装
pip install llm
# 设置 API 密钥
llm keys set openai
# 运行提示词
llm "为我的宠物鹈鹕起 10 个有趣的名字"
# 从图像中提取文本
llm "提取文本" -a scanned-document.jpg
# 使用系统提示分析代码
cat myfile.py | llm -s "解释这段代码"
1.3 项目统计数据
- GitHub Stars: 10,000+ ⭐
- 最新版本: 持续更新(见 Changelog)
- 插件生态: 50+ 官方和社区插件
- 支持模型: 100+(通过插件系统)
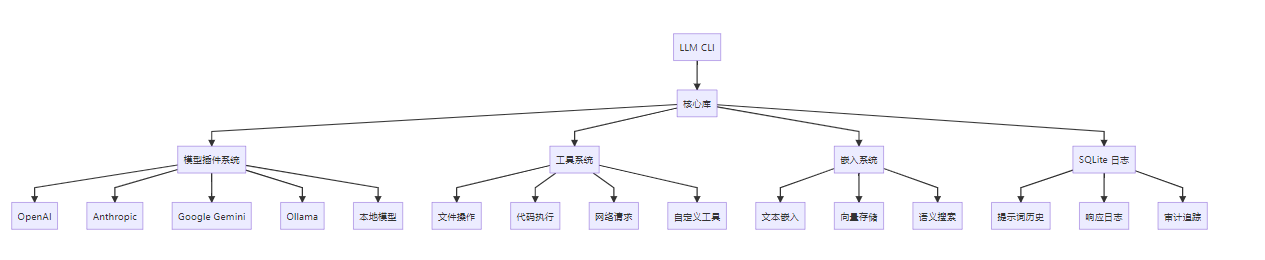
二、架构设计
2.1 核心架构
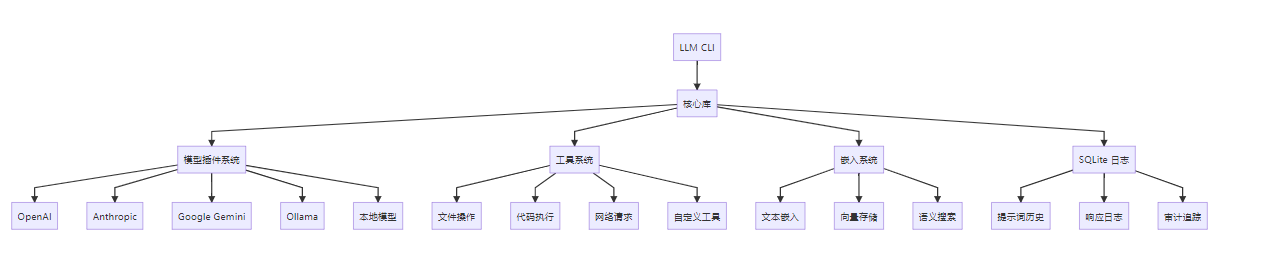
2.2 插件架构
LLM 采用微内核 + 插件架构:
┌─────────────────────────────────────┐
│ LLM Core │
│ - 命令行解析 │
│ - 密钥管理 │
│ - SQLite 日志 │
│ - 插件加载器 │
└─────────────────────────────────────┘
│
┌──────┴──────┐
│ │
▼ ▼
┌─────────┐ ┌─────────┐
│ llm- │ │ llm- │
│ openai │ │ ollama │
└─────────┘ └─────────┘
2.3 数据流
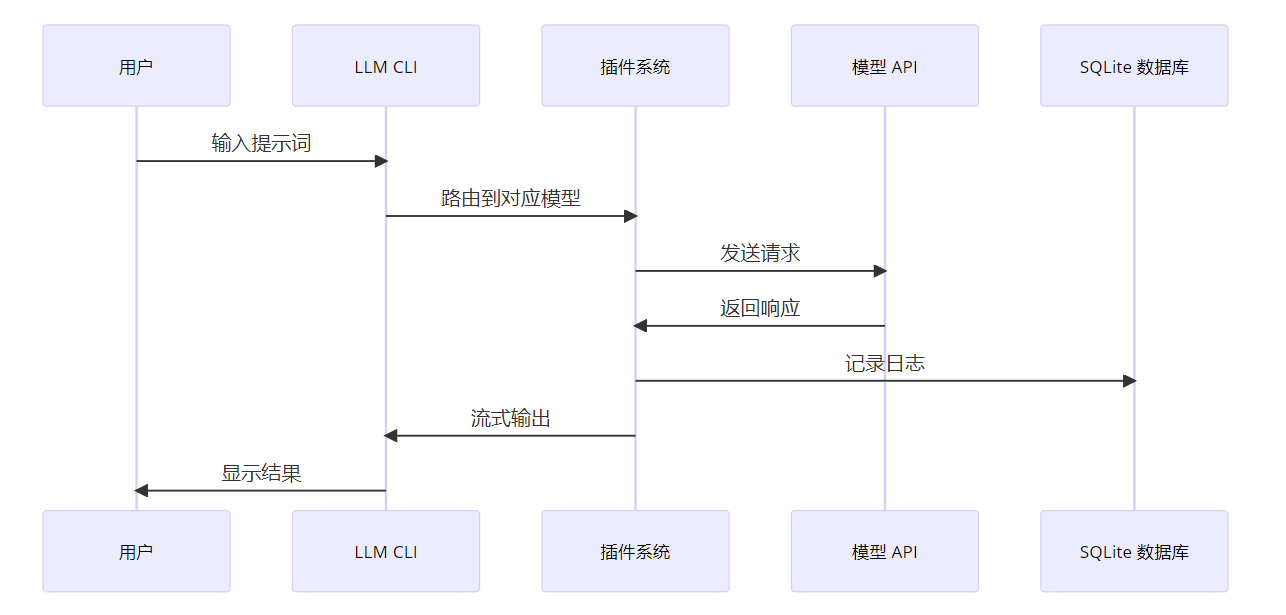
三、解决的问题
3.1 痛点分析
| 问题 | 传统方案 | LLM CLI 方案 |
|---|---|---|
| 模型切换困难 | 每个模型需要不同的客户端 | 统一接口,一键切换 |
| 提示词管理混乱 | 分散在各个聊天窗口 | SQLite 集中存储,可查询 |
| 自动化集成复杂 | 需要调用各平台 API | 标准 CLI,易于脚本化 |
| 成本不透明 | 难以追踪各模型使用量 | 统一日志,便于分析 |
| 本地模型访问 | 需要单独配置 | 通过插件统一管理 |
3.2 实际应用场景
场景 1:批量处理文档
# 批量提取 PDF 文本并总结
for pdf in *.pdf; do
pdftotext "$pdf" - | llm -s "总结这份文档的关键点" >> summaries.md
done
场景 2:代码审查自动化
# 对 Git diff 进行 AI 代码审查
git diff HEAD~1 | llm -s "审查这段代码变更,指出潜在问题"
场景 3:多模型对比测试
# 同一提示词在多个模型上运行
llm -m gpt-4o "解释量子计算" > gpt4o.txt
llm -m claude-3-5-sonnet "解释量子计算" > claude.txt
llm -m gemini-1.5-pro "解释量子计算" > gemini.txt
四、技术栈分析
4.1 核心技术
| 组件 | 技术选型 | 说明 |
|---|---|---|
| 语言 | Python 3.10+ | 现代 Python 特性 |
| CLI 框架 | Click | 强大的命令行工具库 |
| 数据存储 | SQLite | 轻量级、零配置 |
| HTTP 客户端 | httpx | 异步 HTTP 库 |
| 配置管理 | JSON + TOML | 灵活的配置格式 |
| 插件系统 | entry_points | Python 标准插件机制 |
4.2 依赖关系
llm
├── click (CLI)
├── httpx (HTTP)
├── sqlite-utils (SQLite)
├── click-default-group (子命令)
├── pydantic (数据验证)
└── pip (插件管理)
4.3 安装方式
# 方式 1: pip
pip install llm
# 方式 2: Homebrew (macOS)
brew install llm
# 方式 3: pipx (推荐,隔离环境)
pipx install llm
# 方式 4: uv (现代 Python 包管理器)
uv tool install llm
五、核心功能详解
5.1 模型管理
列出可用模型
llm models
输出示例:
OpenAI Chat: gpt-4o-mini (default)
OpenAI Chat: gpt-4o
OpenAI Chat: o1-preview
Anthropic: claude-3-5-sonnet
Gemini: gemini-1.5-pro
Ollama: llama3.2:latest
设置默认模型
llm models default claude-3-5-sonnet
模型别名
llm aliases set my-favorite claude-3-5-sonnet
llm -m my-favorite "提示词"
5.2 密钥管理
# 设置 API 密钥
llm keys set openai
# 输入密钥(隐藏输入)
# 列出已保存的密钥
llm keys
# 查看密钥存储位置
llm keys path
# 输出:~/.config/io.datasette.llm/keys.json
5.3 附件系统(多模态)
# 分析图像
llm "描述这张图片" -a photo.jpg
# 多个附件
llm "比较这两张图片" -a img1.jpg -a img2.jpg
# 从 URL 加载
llm "提取文本" -a https://example.com/document.png
5.4 工具系统(Tools)
LLM 支持函数调用,让模型可以执行实际操作:
# 启用工具
llm "查询今天的天气" --tool weather_api
# 自定义工具示例
# tools.py
def get_weather(city: str) -> str:
"""获取城市天气"""
# 调用天气 API
return f"{city}: 晴朗,25°C"
# 注册工具
llm tools register get_weather
5.5 嵌入(Embeddings)
# 生成嵌入向量
llm embed "这是一段文本" -m sentence-transformers/all-MiniLM-L6-v2
# 存储到数据库
llm embed "文档内容" --collection my-docs --id doc1
# 语义搜索
llm embed-search "相关主题" --collection my-docs
5.6 模板系统
# 创建模板
llm templates save code-review -s "审查这段代码的安全性和性能问题"
# 使用模板
cat app.py | llm -t code-review
# 列出模板
llm templates list
六、插件生态
6.1 官方插件
| 插件 | 功能 | 安装命令 |
|---|---|---|
llm-claude |
Anthropic Claude | llm install llm-claude |
llm-gemini |
Google Gemini | llm install llm-gemini |
llm-ollama |
Ollama 本地模型 | llm install llm-ollama |
llm-gpt4all |
GPT4All 本地模型 | llm install llm-gpt4all |
llm-sentence-transformers |
本地嵌入模型 | llm install llm-sentence-transformers |
6.2 开发插件
# llm-my-model.py
import llm
@llm.hookimpl
def register_models(register):
register(MyCustomModel())
class MyCustomModel(llm.Model):
model_id = "my-custom-model"
def execute(self, prompt, stream, response, conversation):
# 实现模型逻辑
yield "响应内容"
6.3 插件目录
# 查看已安装插件
llm plugins
# 安装新插件
llm install llm-anthropic
# 卸载插件
llm uninstall llm-anthropic
七、使用指南
7.1 快速开始
步骤 1:安装
pipx install llm
步骤 2:设置 API 密钥
llm keys set openai
# 粘贴你的 OpenAI API 密钥
步骤 3:运行第一个提示词
llm "用三句话解释机器学习"
步骤 4:探索更多功能
# 查看帮助
llm --help
# 查看模型列表
llm models
# 查看使用记录
llm logs
7.2 高级用法
交互式聊天
llm chat -m gpt-4o
# 进入交互模式
> 你好
> 解释一下量子纠缠
> quit
管道组合
# 结合 Unix 工具
grep "ERROR" app.log | llm "分析这些错误的原因"
# 多步骤处理
cat code.py | llm "添加注释" | llm "翻译成中文"
批量处理
# 处理多个文件
for file in *.md; do
llm -s "总结" -i "$file" >> summaries.txt
done
八、竞品对比
| 特性 | LLM CLI | Cursor | Continue | 官方 CLI |
|---|---|---|---|---|
| 开源 | ✅ 完全开源 | ❌ 专有 | ✅ 开源 | 部分开源 |
| 本地模型 | ✅ 通过插件 | ⚠️ 有限 | ✅ | ❌ |
| 多模型支持 | ✅ 50+ | ⚠️ 有限 | ⚠️ 有限 | ❌ 单模型 |
| SQLite 日志 | ✅ 内置 | ❌ | ❌ | ❌ |
| 插件系统 | ✅ 完善 | ❌ | ⚠️ 有限 | ❌ |
| 终端原生 | ✅ 完全 | ❌ GUI | ⚠️ IDE 插件 | ✅ |
| 工具调用 | ✅ | ✅ | ✅ | ⚠️ 部分 |
| 嵌入向量 | ✅ | ❌ | ❌ | ❌ |
九、实际应用场景
9.1 开发者工作流
# Git 提交信息生成
git diff --staged | llm -s "生成简洁的提交信息"
# 代码解释
cat complex_function.py | llm -s "用通俗语言解释这段代码"
# 测试生成
cat src/*.py | llm "为这些函数编写单元测试"
9.2 内容创作
# 博客大纲生成
llm "为'AI 命令行工具'主题生成博客大纲" -m claude-3-5-sonnet
# 多语言翻译
cat article.md | llm "翻译成中文,保持技术术语准确"
9.3 数据分析
# JSON 数据分析
cat data.json | llm "提取关键指标并总结趋势"
# CSV 处理
csvkit csvstat data.csv | llm "解释这些统计结果"
9.4 系统管理
# 日志分析
journalctl -u nginx | llm "找出最近的问题并建议解决方案"
# 安全审计
nmap -sV target.com | llm "分析开放端口的安全风险"
十、局限性与改进建议
10.1 当前局限
| 问题 | 影响 | 临时解决方案 |
|---|---|---|
| 流式输出偶尔卡顿 | 用户体验下降 | 使用 --no-stream |
| 部分插件文档不足 | 学习曲线陡峭 | 参考源码和示例 |
| Windows 兼容性 | 部分功能受限 | 使用 WSL2 |
| 工具安全性 | 潜在风险 | 仔细阅读工具代码 |
10.2 改进建议
-
增强安全性
- 添加工具执行的确认机制
- 实现权限分级系统
-
改进用户体验
- 添加交互式配置向导
- 提供更详细的错误信息
-
扩展功能
- 支持更多本地模型格式(GGUF、ONNX)
- 添加图形化日志查看器
-
性能优化
- 实现请求缓存
- 优化大文件处理
十一、技术评价总结
11.1 优势
✅ 开源透明:完全开源,无黑盒操作
✅ 本地优先:支持完全本地运行的模型
✅ 终端原生:完美融入 Unix 工作流
✅ 可扩展性:强大的插件系统
✅ 数据自主:SQLite 本地存储,完全可控
✅ 社区活跃:Simon Willison 维护,响应迅速
11.2 适用人群
- 开发者:需要将 AI 集成到开发流程
- DevOps 工程师:自动化运维和监控
- 数据分析师:批量处理和分析数据
- 隐私倡导者:偏好本地部署和开源方案
- 终端爱好者:喜欢命令行工作流
11.3 总体评分
| 维度 | 评分 | 说明 |
|---|---|---|
| 功能性 | ⭐⭐⭐⭐⭐ | 覆盖主流模型和场景 |
| 易用性 | ⭐⭐⭐⭐ | 学习曲线适中 |
| 文档质量 | ⭐⭐⭐⭐ | 详细但部分分散 |
| 社区支持 | ⭐⭐⭐⭐⭐ | 活跃且友好 |
| 创新性 | ⭐⭐⭐⭐⭐ | 重新定义 CLI+AI |
十二、快速参考卡片
# ============ 安装 ============
pipx install llm
llm install llm-ollama # 本地模型插件
# ============ 配置 ============
llm keys set openai # 设置 API 密钥
llm keys list # 查看密钥
# ============ 基本使用 ============
llm "提示词" # 运行提示
llm -m model "提示词" # 指定模型
llm -s "系统提示" "用户提示" # 系统提示
# ============ 文件处理 ============
llm -a image.jpg "描述图片" # 图像输入
cat file.py | llm "解释代码" # 管道输入
# ============ 模型管理 ============
llm models # 列出模型
llm models default <模型> # 设置默认
llm aliases set <别名> <模型> # 设置别名
# ============ 日志 ============
llm logs # 查看历史
llm logs -n 10 # 最近 10 条
llm logs --conversation <ID> # 查看会话
# ============ 插件 ============
llm plugins # 列出插件
llm install <插件名> # 安装插件
llm uninstall <插件名> # 卸载插件
十三、总结
LLM CLI 代表了 AI 工具发展的一个重要方向:开源、本地化、终端原生。它不仅仅是一个工具,更是一种理念——让人工智能真正融入开发者的日常工作流,而不是成为孤立的"聊天机器人"。
核心价值
- 统一接口:一个命令访问所有主流模型
- 数据自主:本地 SQLite 存储,完全可控
- 工作流集成:无缝融入现有终端工具链
- 隐私保护:支持完全本地运行的模型
- 开放生态:插件系统允许无限扩展
推荐使用场景
- ✅ 需要频繁切换不同模型
- ✅ 希望将 AI 集成到自动化脚本
- ✅ 重视数据隐私和本地部署
- ✅ 偏好终端工作流
- ✅ 需要审计和追踪 AI 使用记录
项目信息
- GitHub: https://github.com/simonw/llm
- 文档: https://llm.datasette.io/
- 作者: Simon Willison
- 许可: Apache 2.0
- Python 版本: 3.10+
本文基于 LLM CLI v0.23+ 版本编写,项目持续更新中,请以官方文档为准。
最后更新:2026 年 5 月 12 日

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)