Agent 的错误恢复机制设计:优雅降级的艺术
Agent 的错误恢复机制设计:优雅降级的艺术
标题选项
- 《Agent生产级落地必看:错误恢复机制设计与优雅降级的艺术》
- 《从99%可用到99.99%:聊聊Agent系统的全链路容错降级方案》
- 《大模型Agent崩溃救星:一文搞懂错误恢复、熔断与降级的落地逻辑》
- 《拒绝Agent“摆烂”:手把手教你设计高可用的容错机制》
引言
痛点引入
你有没有过这样的经历:花了几周时间打磨的Agent demo,本地跑通了所有测试用例,回答准确、工具调用丝滑,一上线就频频翻车:大模型限流返回503、搜索工具接口超时、代码执行器突然报错、返回格式不符合预期导致整个链路卡死,用户看到的要么是加载中圈圈转半天,要么是一串看不懂的堆栈错误,甚至直接返回“系统异常”,本来期待的AI助手直接变成了“人工智障”。
据2024年大模型应用生产现状报告显示,80%的Agent应用上线后可用性不足99%,其中60%的故障来自于依赖服务(大模型、第三方工具、API)的异常,而非核心逻辑本身。很多开发者把精力放在了Agent的能力提升上,却忽略了容错机制的设计,导致再好的能力也无法稳定交付给用户。
文章内容概述
本文将从核心概念到落地实现,全链路讲解Agent系统的错误恢复机制,重点拆解优雅降级的设计思路、实现方案和最佳实践。我们会从错误分类开始,一步步带你实现重试、熔断、分级降级、上下文回滚等完整的容错能力,还会提供可直接复用的代码示例、架构设计和测试方案。
读者收益
读完本文你将:
- 搞懂Agent系统的常见错误类型和全链路容错逻辑
- 能够独立设计生产级Agent的错误恢复机制,把系统可用性从99%提升到99.99%以上
- 掌握优雅降级的设计原则和各场景下的落地策略
- 学会用混沌测试验证容错机制的有效性,避开常见的容错坑
准备工作
技术栈/知识要求
- 熟悉Agent的基本组成:规划模块、记忆模块、工具调用模块、执行模块
- 有Python后端开发基础,了解异常处理、装饰器等基本语法
- 了解大模型应用开发的常见痛点,有过LangChain或其他Agent框架的使用经验更佳
环境/工具要求
- Python 3.9+ 运行环境
- 已安装大模型SDK(如OpenAI、文心一言、通义千问等)
- 可选:
tenacity(重试库)、pybreaker(熔断器)、chaostoolkit(混沌测试工具)
核心概念
在动手实现之前,我们先把核心概念理清楚,避免后续走弯路。
什么是Agent的错误?
Agent的全链路可以分为5层,每一层都可能出现错误,我们按照链路分类如下:
| 错误层级 | 常见错误场景 | 影响范围 |
|---|---|---|
| 输入层 | 用户输入包含敏感词、输入格式不符合要求、输入意图模糊 | 单请求 |
| 大模型层 | 限流、超时、返回格式错误、内容违规、服务不可用 | 全量/部分请求 |
| 工具层 | 第三方API超时、权限不足、返回格式错误、服务不可用 | 依赖该工具的请求 |
| 执行层 | 代码执行报错、内存溢出、依赖缺失、状态冲突 | 单请求 |
| 输出层 | 返回内容包含敏感词、格式不符合业务要求、前后逻辑矛盾 | 单请求 |
我们还可以按照错误的可恢复性分为两类:
- 偶发性错误:网络闪断、大模型偶发限流、第三方API瞬时5xx,这类错误重试即可解决
- 持续性错误:大模型服务宕机、第三方API下线、依赖服务故障,这类错误需要熔断+降级解决
错误恢复的核心目标
Agent的错误恢复和传统后端系统的容错有相似之处,但也有其特殊性:传统后端系统的容错目标是“不崩溃、返回正确结果”,而Agent的容错目标有三个优先级:
- 不崩溃:绝对不能返回堆栈错误、系统异常等用户看不懂的内容
- 尽量完成请求:优先用重试、降级等方式返回符合用户需求的结果,哪怕是次优结果
- 透明告知:实在无法完成请求时,要给出友好的、可理解的提示,告诉用户应该怎么做,而不是直接拒绝
优雅降级的定义
优雅降级是指当系统的部分依赖出现故障时,不是直接报错,而是通过牺牲非核心功能、降低输出精度、使用兜底方案等方式,保证核心功能可用,或者给用户提供可接受的次优结果,尽量降低用户的故障感知。
重试、熔断、降级的区别
很多开发者容易把这三个概念搞混,我们做一个清晰的对比:
| 对比维度 | 重试 | 熔断 | 降级 |
|---|---|---|---|
| 适用场景 | 偶发性错误,重试后大概率可以成功 | 持续性错误,避免无效调用导致雪崩 | 依赖不可用,提供次优方案保证核心体验 |
| 核心目标 | 恢复正常执行,完全满足用户需求 | 保护系统资源,避免故障扩散 | 降低用户故障感知,尽量交付价值 |
| 对用户的影响 | 基本无感知,仅响应时间略微增加 | 感知较强,会收到功能不可用提示 | 感知较弱,要么收到次优结果,要么收到友好引导 |
| 资源消耗 | 低,仅重复调用几次故障依赖 | 极低,直接拒绝调用,不占用资源 | 中等,调用降级逻辑的资源 |
| 使用优先级 | 最高,优先尝试重试 | 次之,重试无效且故障持续时熔断 | 最后,熔断后走降级逻辑 |
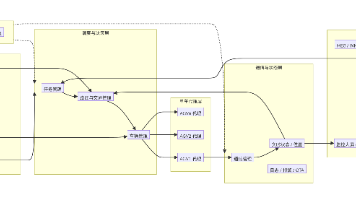
Agent错误处理全链路架构
我们用Mermaid架构图展示全链路的错误处理逻辑:
可用性提升的数学模型
为什么容错降级能大幅提升系统可用性?我们用数学公式来计算:
假设系统有nnn个依赖服务,每个依赖的可用性为AiA_iAi(0 < AiA_iAi < 1),如果没有任何容错机制,整个系统的可用性为所有依赖可用性的乘积:
Atotal=∏i=1nAiA_{total} = \prod_{i=1}^{n} A_iAtotal=i=1∏nAi
举个例子,如果你有3个依赖,每个依赖的可用性是99%(即全年宕机时间约3.65天),那么没有容错的话总可用性是0.993=0.97030.99^3 = 0.97030.993=0.9703,即全年宕机时间约10.8天,对于生产级应用来说完全不可接受。
如果每个依赖都有降级方案,降级后的可用性为BiB_iBi,那么整个系统的可用性为:
Atotal=∏i=1n(Ai+(1−Ai)∗Bi)A_{total} = \prod_{i=1}^{n} (A_i + (1-A_i)*B_i)Atotal=i=1∏n(Ai+(1−Ai)∗Bi)
还是上面的例子,假设每个降级方案的可用性是99.9%,那么总可用性是(0.99+0.01∗0.999)3≈0.9997(0.99 + 0.01*0.999)^3 ≈ 0.9997(0.99+0.01∗0.999)3≈0.9997,全年宕机时间只有约2.6小时,达到了生产级应用的可用性标准。
错误与恢复策略的实体关系
我们用ER图展示错误、恢复策略、配置之间的关系:
手把手实战:从零搭建错误恢复机制
步骤一:错误分类与全链路打点
要做错误恢复,首先要能准确识别错误、分类错误,所以第一步我们要做全链路的错误埋点,把每一层的错误都打上标签,方便后续处理和排查。
核心思路
我们用装饰器模式给每个模块的函数加上错误监控逻辑,自动捕获异常、分类打点、抛出统一包装的Agent异常,避免上层处理各种零散的异常类型。
代码实现
import functools
import logging
from enum import Enum
from typing import Optional
# 定义错误类型枚举
class ErrorType(Enum):
INPUT_ERROR = "input_error"
LLM_ERROR = "llm_error"
TOOL_ERROR = "tool_error"
EXECUTION_ERROR = "execution_error"
OUTPUT_ERROR = "output_error"
# 定义错误等级枚举
class ErrorLevel(Enum):
FATAL = "fatal" # 系统级故障,影响所有用户
ERROR = "error" # 单请求故障,不影响其他用户
WARN = "warn" # 轻微异常,不影响请求执行
INFO = "info" # 正常打点,无异常
# 统一的Agent异常类
class AgentError(Exception):
def __init__(self,
error_type: ErrorType,
error_level: ErrorLevel,
message: str,
original_error: Optional[Exception] = None):
self.error_type = error_type
self.error_level = error_level
self.message = message
self.original_error = original_error
super().__init__(message)
# 错误监控装饰器
def error_monitor(error_type: ErrorType, error_level: ErrorLevel):
def decorator(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
try:
return func(*args, **kwargs)
except Exception as e:
# 打点日志,可接入Prometheus、ELK等监控系统
logging.error(
f"[ErrorMonitor] func={func.__name__}, error_type={error_type.value}, "
f"error_level={error_level.value}, error_msg={str(e)}",
exc_info=True
)
# 抛出包装后的统一异常
raise AgentError(error_type, error_level, str(e), original_error=e)
return wrapper
return decorator
代码解释
- 我们把所有错误分为5类、4个等级,方便后续根据不同的错误类型和等级做不同的恢复策略
- 统一的
AgentError类包装了原始异常,上层不需要关心底层的异常类型,只需要处理AgentError即可 - 装饰器
error_monitor可以很方便的给每个模块的函数加上监控,不需要修改业务逻辑 - 所有错误都会打点到日志系统,后续可以做统计分析,优化容错策略
步骤二:重试机制设计
重试是处理偶发性错误的首选方案,但是重试不能盲目做,否则会导致重试风暴,把本来就有故障的依赖彻底打垮。
核心设计原则
- 只重试可重试的错误:比如网络超时、大模型限流、5xx错误可以重试,参数错误、权限不足、4xx错误、敏感内容错误不要重试
- 有限重试次数:最多重试3-5次,避免无限重试占用资源
- 指数退避+抖动:重试间隔按照指数增长,加上随机抖动,避免大量请求同时重试导致惊群效应
- 保证幂等性:对于写操作的工具调用(比如创建订单、发送短信),要加幂等键,避免重试导致重复操作
代码实现
我们用tenacity库来实现重试逻辑,不需要自己手写重试循环:
from tenacity import retry, stop_after_attempt, wait_exponential_jitter, retry_if_exception_type, before_sleep
# 定义大模型的可重试异常
class LLMRetryableError(AgentError):
pass
# 大模型调用的重试策略:最多重试3次,指数退避加抖动,间隔1-10秒
@retry(
stop=stop_after_attempt(3),
wait=wait_exponential_jitter(multiplier=1, min=1, max=10),
retry=retry_if_exception_type(LLMRetryableError),
before_sleep=lambda retry_state: logging.info(f"Retrying LLM call, attempt {retry_state.attempt_number}...")
)
@error_monitor(ErrorType.LLM_ERROR, ErrorLevel.ERROR)
def call_llm(prompt: str, model: str = "gpt-4") -> str:
import openai
try:
response = openai.ChatCompletion.create(
model=model,
messages=[{"role": "user", "content": prompt}],
timeout=10
)
return response.choices[0].message.content
except (openai.error.Timeout, openai.error.RateLimitError, openai.error.ServiceUnavailableError) as e:
# 可重试的错误,包装成LLMRetryableError
raise LLMRetryableError(ErrorType.LLM_ERROR, ErrorLevel.ERROR, str(e))
except Exception as e:
# 不可重试的错误,直接抛出AgentError
raise AgentError(ErrorType.LLM_ERROR, ErrorLevel.ERROR, str(e))
最佳实践
- 重试装饰器要放在熔断器装饰器的内层,熔断之后就不需要重试了
- 对于工具调用的重试,要根据工具的特性调整重试次数,比如搜索工具可以重试3次,支付工具最多重试1次
- 重试的次数和间隔要做成可配置的,方便线上调整
步骤三:熔断机制设计
当某个依赖持续出现错误时,重试不仅没用,还会浪费大量资源,甚至导致自己的服务雪崩,这时候就需要熔断器来切断对故障依赖的调用。
熔断器的三个状态
- 关闭状态:正常调用依赖服务,统计失败次数,失败次数达到阈值后切换到打开状态
- 打开状态:直接拒绝所有调用,走降级逻辑,等待一段时间后切换到半开状态
- 半开状态:放少量请求过去,看看依赖是否恢复,如果成功则切换到关闭状态,失败则回到打开状态
代码实现
我们用pybreaker库来实现熔断器:
import pybreaker
# 定义大模型的熔断器:失败5次就熔断,30秒后进入半开状态
llm_circuit_breaker = pybreaker.CircuitBreaker(
fail_max=5,
reset_timeout=30,
on_failure=lambda exc: logging.warning(f"LLM call failed, failure count: {llm_circuit_breaker.fail_counter}"),
on_open=lambda: logging.warning("LLM circuit breaker opened, reject calls for 30s"),
on_close=lambda: logging.warning("LLM circuit breaker closed, back to normal")
)
# 把熔断器装饰器加到大模型调用函数上,注意顺序:熔断器在外层,重试在内层
@llm_circuit_breaker
@retry(...)
@error_monitor(...)
def call_llm(prompt: str, model: str = "gpt-4") -> str:
# 大模型调用逻辑
...
最佳实践
- 每个依赖服务要单独配置熔断器,不要共用一个熔断器
- 熔断器的阈值要根据依赖的SLA来调整,比如SLA99.9%的依赖,失败阈值可以设为5,SLA99%的依赖可以设为10
- 熔断器的状态要接入监控系统,线上可以实时查看每个依赖的熔断器状态
步骤四:优雅降级设计(核心)
降级是容错机制的最后一道防线,也是保证用户体验的核心,我们按照链路分层讲解每个层级的降级策略。
降级的三个等级
我们把降级分为三个等级,按照优先级从高到低尝试:
- 精度降级:降低输出精度,不改变功能,比如GPT4挂了用GPT3.5,高精度模型挂了用低精度量化模型
- 功能降级:砍掉非核心功能,保证核心功能可用,比如搜索工具挂了就用本地知识库回答,不需要最新信息
- 兜底降级:核心功能也不可用的时候,返回友好的引导话术,告诉用户接下来应该怎么做
降级设计原则
- 核心优先:永远优先保证核心功能可用,非核心功能可以直接砍掉
- 无感知优先:尽量让用户感知不到故障,返回的次优结果要明确标注,避免误导用户
- 降级逻辑简单:降级逻辑要尽量简单,避免降级逻辑本身出现故障,最后一层兜底一定是静态字符串,不会出错
- 可监控可配置:降级的次数、类型要打点监控,降级开关要可配置,方便应急处理
各层降级实现
1. 大模型层降级实现
from datetime import datetime
# 大模型降级策略类
class LLMDegradeStrategy:
@staticmethod
def degrade_to_gpt35(prompt: str) -> tuple[Optional[str], bool]:
"""精度降级:从GPT4降级到GPT3.5"""
logging.info("Degrading LLM to GPT-3.5")
try:
return call_llm(prompt, model="gpt-3.5-turbo"), True
except Exception as e:
logging.warning(f"GPT-3.5 call failed: {str(e)}")
return None, False
@staticmethod
def degrade_to_local_llm(prompt: str) -> tuple[Optional[str], bool]:
"""精度降级:从公有云模型降级到本地量化模型"""
logging.info("Degrading LLM to local Llama2-7B")
try:
# 调用本地量化Llama2的逻辑,比如用llama-cpp-python
from llama_cpp import Llama
llm = Llama(model_path="./llama-2-7b-chat.ggmlv3.q4_0.bin")
output = llm.create_chat_completion(
messages=[{"role": "user", "content": prompt}],
max_tokens=256
)
return output["choices"][0]["message"]["content"], True
except Exception as e:
logging.warning(f"Local LLM call failed: {str(e)}")
return None, False
@staticmethod
def degrade_to_preset_response(prompt: str) -> tuple[str, bool]:
"""兜底降级:返回预设话术"""
logging.info("Degrading LLM to preset response")
# 简单的关键词意图匹配
if "天气" in prompt:
return "现在天气查询功能正在维护哦,你可以稍后再试,或者访问https://tianqi.com查询最新天气~", True
elif "时间" in prompt:
return f"现在的时间是{datetime.now().strftime('%Y-%m-%d %H:%M:%S')}哦~", True
elif "订单" in prompt:
return "现在订单查询功能有点忙,你可以点击「我的订单」直接查看哦~", True
else:
return "现在咨询的人太多啦,我有点忙不过来,你可以稍后再问我哦~", True
# 带降级的大模型调用函数
def call_llm_with_degrade(prompt: str, model: str = "gpt-4") -> str:
try:
# 首先尝试正常调用
return call_llm(prompt, model)
except (AgentError, pybreaker.CircuitBreakerError) as e:
logging.warning(f"Normal LLM call failed: {str(e)}, start degrading...")
# 第一步:降级到GPT3.5
res, ok = LLMDegradeStrategy.degrade_to_gpt35(prompt)
if ok:
return res
# 第二步:降级到本地模型
res, ok = LLMDegradeStrategy.degrade_to_local_llm(prompt)
if ok:
return res
# 第三步:兜底降级到预设话术
res, _ = LLMDegradeStrategy.degrade_to_preset_response(prompt)
return res
2. 工具层降级实现
以搜索工具为例:
# 搜索工具降级策略类
class SearchDegradeStrategy:
@staticmethod
def degrade_to_local_kb(query: str) -> tuple[Optional[str], bool]:
"""功能降级:从联网搜索降级到本地知识库"""
logging.info("Degrading search to local knowledge base")
try:
# 调用本地向量数据库查询相关知识
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
db = Chroma(persist_directory="./kb", embedding_function=OpenAIEmbeddings())
docs = db.similarity_search(query, k=3)
if docs:
content = "\n".join([doc.page_content for doc in docs])
return f"(以下信息来自知识库,可能不是最新的)\n{content}", True
return None, False
except Exception as e:
logging.warning(f"Local KB query failed: {str(e)}")
return None, False
@staticmethod
def degrade_to_user_guide(query: str) -> tuple[str, bool]:
"""兜底降级:引导用户手动操作"""
return "现在搜索功能暂时不可用哦,你可以直接去百度搜索相关内容,我会等你回来继续聊~", True
# 带降级的搜索工具调用
def search_with_degrade(query: str) -> str:
try:
# 正常调用搜索API
return call_search_api(query)
except (AgentError, pybreaker.CircuitBreakerError) as e:
logging.warning(f"Search call failed: {str(e)}, start degrading...")
res, ok = SearchDegradeStrategy.degrade_to_local_kb(query)
if ok:
return res
res, _ = SearchDegradeStrategy.degrade_to_user_guide(query)
return res
3. 其他层降级要点
- 输入层:用户输入违规不要直接报错,引导用户修改,比如“你刚才的内容包含违规信息哦,换个说法试试吧”;用户输入模糊不要说听不懂,给出选项引导,比如“你是想问A、B还是C呢?”
- 执行层:代码执行失败不要报错,把代码返回给用户,比如“这段代码我现在运行不了哦,你可以复制到本地运行试试:
python xxx” - 输出层:返回内容包含敏感词不要直接输出,过滤敏感内容或者返回兜底话术,比如“这个问题我不方便回答哦,换个话题聊聊吧”
步骤五:上下文回滚与记忆一致性保证
Agent是有记忆的,如果执行到一半出错,已经修改了记忆或者中间状态,就会导致记忆污染,出现前后矛盾的回答,所以我们需要做上下文快照和回滚机制。
核心思路
每执行一个步骤之前,给当前的上下文(记忆、执行步骤、中间状态)拍一个快照,如果执行出错,就回滚到上一个快照,保证记忆的一致性。
代码实现
import copy
from typing import List, Dict
class AgentContext:
def __init__(self):
self.memory: List[Dict] = [] # 对话记忆
self.steps: List[Dict] = [] # 本次请求的执行步骤
self.snapshots: List[Dict] = [] # 上下文快照栈
def take_snapshot(self):
"""拍摄当前上下文的快照,压入栈中"""
snapshot = {
"memory": copy.deepcopy(self.memory),
"steps": copy.deepcopy(self.steps)
}
self.snapshots.append(snapshot)
logging.info(f"Take context snapshot, total snapshots: {len(self.snapshots)}")
def rollback(self):
"""回滚到上一个快照"""
if not self.snapshots:
logging.warning("No snapshot to rollback")
return
snapshot = self.snapshots.pop()
self.memory = snapshot["memory"]
self.steps = snapshot["steps"]
logging.info(f"Rollback to previous snapshot, remaining snapshots: {len(self.snapshots)}")
# Agent执行主逻辑
def agent_run(user_input: str, context: AgentContext) -> str:
# 执行前拍摄快照
context.take_snapshot()
try:
# 1. 意图识别
intent = parse_intent(user_input)
context.steps.append({"type": "parse_intent", "result": intent})
# 2. 生成执行计划
plan = make_plan(intent)
context.steps.append({"type": "make_plan", "result": plan})
# 3. 执行每个步骤
for step in plan:
context.take_snapshot()
execute_step(step, context)
# 4. 生成结果
result = generate_result(context)
# 5. 保存到记忆
context.memory.append({"user": user_input, "assistant": result})
return result
except Exception as e:
# 出错回滚上下文
context.rollback()
logging.error(f"Agent run failed, rollback context: {str(e)}")
# 走降级逻辑
return agent_degrade_run(user_input, context)
优化点
如果上下文很大,每次深拷贝会占用很多内存,可以用写时复制(Copy on Write)技术,只有修改上下文的时候才拷贝,节省内存开销。
进阶探讨
1. 分布式多Agent的错误恢复
当多个Agent协作完成任务时,单Agent的错误恢复已经不够用了,需要用到分布式事务的Saga模式:给每个执行步骤定义补偿操作,当某个步骤出错时,按照逆序执行补偿操作,回滚之前所有步骤的修改,保证整个系统的状态一致性。比如订单Agent创建了订单,支付Agent支付失败,就执行取消订单的补偿操作。
2. 性能优化:海量数据下的降级策略
当Agent处理的请求量很大(比如QPS>1000)时,降级逻辑本身也可能成为瓶颈,这时候可以做:
- 降级逻辑提前预热,比如本地模型提前加载到内存,避免首次调用慢
- 热点请求的降级结果缓存,比如相同的问题多次请求,直接返回缓存的降级结果
- 降级开关灰度,新的降级策略先给10%的用户使用,没问题再全量
3. 可观测性建设
要知道你的容错机制是不是有效,需要建立完善的监控仪表盘,重点监控以下指标:
- 各层级的错误率、错误类型分布
- 重试次数、重试成功率
- 熔断器的状态、熔断次数
- 降级次数、降级类型分布
- 系统整体可用性、平均响应时间
4. 混沌测试验证
容错机制写完之后不能等线上出问题才验证,要做混沌测试,故意注入故障,验证容错逻辑是否正常工作:
- 注入大模型超时错误,验证是否会重试、熔断、降级
- 注入工具服务不可用错误,验证是否会走降级逻辑
- 注入执行层错误,验证是否会回滚上下文,记忆不会污染
- 可以用
chaostoolkit工具自动化执行混沌测试用例,每次上线前跑一遍
行业发展趋势
Agent容错技术的发展和Agent的落地阶段高度相关,我们整理了发展历程和未来趋势:
| 时间 | 阶段 | 核心技术 | 可用性目标 | 适用场景 |
|---|---|---|---|---|
| 2020年及以前 | 规则机器人阶段 | 简单重试、固定兜底 | 95% | 简单问答客服机器人 |
| 2021-2022年 | 大模型应用初期 | 重试+简单熔断、模型降级 | 99% | 单Agent demo、个人助理应用 |
| 2023年 | 生产级Agent阶段 | 全链路错误分类、分级降级、上下文回滚 | 99.9% | 企业级Agent、ToC高流量Agent应用 |
| 2024年及以后 | 分布式多Agent阶段 | 分布式Saga补偿、全局容错调度、AI驱动的智能降级 | 99.99% | 多Agent协作系统、Agent原生应用、工业级Agent |
未来的容错机制会越来越智能,不需要开发者手动配置降级策略,AI会根据故障类型、用户需求、业务场景自动选择最优的降级方案,真正做到用户完全无感知的故障恢复。
最佳实践Tips
- 降级逻辑一定要简单:不要在降级逻辑里写复杂的业务逻辑,避免降级逻辑本身出错,最后一层兜底一定是静态字符串,100%可用
- 高安全场景降级要保守:医疗、金融、法律等高安全场景的Agent,不要为了可用性返回错误的结果,宁可明确告知用户功能不可用,也不要误导用户
- 不要吃异常:所有异常都要打点日志,不要为了不报错就把异常吞了,导致出了问题找不到原因
- 要有紧急手动开关:线上出现故障时,可以手动打开降级开关,强制走降级逻辑,快速止损
- 混沌测试常态化:每次上线前都要跑混沌测试用例,保证容错机制正常工作
总结
本文从核心概念到落地实现,完整讲解了Agent系统的错误恢复机制和优雅降级的设计思路:
- 首先要做全链路的错误分类和打点,准确识别错误类型
- 用重试机制处理偶发性错误,用熔断机制防止故障扩散
- 按照精度降级、功能降级、兜底降级三个层级设计各链路的降级策略,保证用户体验
- 用上下文快照和回滚机制保证Agent记忆的一致性
- 用可观测性和混沌测试验证容错机制的有效性
通过这些方案,你可以把Agent的可用性从99%提升到99.99%以上,让你的Agent不管在什么故障场景下,都能给用户友好的反馈,而不是直接崩溃。
行动号召
如果你在Agent容错设计的过程中遇到了什么问题,或者有更好的实践经验,欢迎在评论区留言讨论!需要本文完整的代码示例和混沌测试用例的同学,可以关注我私信发送「Agent容错」获取。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献125条内容
已为社区贡献125条内容

所有评论(0)